













Si vous avez créé un pipeline Azure DevOps comme solution pour un pipeline CI/CD, vous avez sans aucun doute rencontré des situations qui nécessitent la gestion dynamique des valeurs de configuration dans les builds et les releases. Que ce soit pour fournir une version de build à un script PowerShell, passer des paramètres dynamiques aux tâches de build ou utiliser des chaînes de caractères à travers les builds et les releases, vous avez besoin de variables.
Si vous vous êtes déjà posé des questions telles que :
- Comment utiliser les variables de build Azure DevOps dans un script PowerShell?
- Comment partager des variables entre les builds et les releases?
- Quelle est la différence entre les variables prédéfinies, utilisateur et secrètes?
- Comment fonctionnent les groupes de variables?
… alors vous avez de la chance ! Dans cet article, nous répondrons à chacune de ces questions et plus encore.
À la fin de cet article, vous comprendrez comment fonctionnent les variables de build Azure DevOps dans les pipelines Azure!
Quelles sont les variables de pipeline Azure DevOps?
Avant d’entrer dans les détails des variables, qu’est-ce que ce sont et comment vous aident-elles à créer et à automatiser des pipelines de build et de release efficaces?
Les variables vous permettent de transmettre des morceaux de données dans différentes parties de vos pipelines. Les variables sont idéales pour stocker du texte et des nombres qui peuvent changer tout au long du flux de travail d’un pipeline. Dans un pipeline, vous pouvez définir et lire des variables presque partout plutôt que de coder en dur des valeurs dans des scripts et des définitions YAML.
Note : Cet article se concentrera uniquement sur les pipelines YAML. Nous ne couvrirons aucune information concernant les pipelines classiques obsolètes. De plus, avec quelques exceptions mineures, vous n’apprendrez pas à travailler avec des variables via l’interface web. Nous nous en tiendrons strictement au YAML.
Les variables sont référencées et certaines définies (voir variables définies par l’utilisateur) au moment de l’exécution. Lorsqu’un pipeline initie un job, divers processus gèrent ces variables et transmettent leurs valeurs à d’autres parties du système. Ce système offre un moyen d’exécuter des jobs de pipeline de manière dynamique sans se soucier de changer les définitions de build et les scripts à chaque fois.
Ne vous inquiétez pas si vous ne saisissez pas le concept de variables à ce stade. Le reste de cet article vous apprendra tout ce que vous devez savoir.
Environnements de Variables
Avant de plonger dans les variables elles-mêmes, il est d’abord important de couvrir les environnements de variables de pipeline Azure. Vous verrez diverses références à ce terme tout au long de l’article.
À l’intérieur d’un pipeline, il existe deux endroits informellement appelés environnements où vous pouvez interagir avec les variables. Vous pouvez soit travailler avec des variables au sein d’une définition de build YAML appelée l’environnement pipeline, soit au sein d’un script exécuté via une tâche appelée l’environnement script.
Le Environnement de Pipeline
Lorsque vous définissez ou lisez des variables de construction à partir d’une définition de build YAML, cela s’appelle l’environnement de pipeline. Par exemple, ci-dessous, vous pouvez voir la section variables définie dans une définition de build YAML, définissant une variable appelée foo à bar. Dans ce contexte, la variable est définie dans l’environnement de pipeline
L’environnement de Script
Vous pouvez également travailler avec des variables à partir du code défini dans la définition YAML elle-même ou dans des scripts. Lorsque vous n’avez pas déjà créé de script existant, vous pouvez définir et lire des variables dans la définition YAML comme indiqué ci-dessous. Vous apprendrez la syntaxe sur la manière de travailler avec ces variables dans ce contexte plus tard.
Vous pourriez également rester dans l’environnement de script en ajoutant cette même syntaxe dans un script Bash et en l’exécutant. C’est le même concept général.
Variables d’Environnement
Dans l’environnement de script, lorsqu’une variable de pipeline est rendue disponible, cela se fait en créant une variable d’environnement. Ces variables d’environnement peuvent ensuite être accédées via les méthodes typiques du langage de choix.
Les variables de pipeline exposées en tant que variables d’environnement seront toujours en majuscules, et les points seront remplacés par des underscores. Par exemple, vous verrez ci-dessous comment chaque langage de script peut accéder à la variable de pipeline foo comme indiqué ci-dessous.
- Batch –
%FOO% - PowerShell –
$env:FOO - Script Bash –
$FOO
Phases d’exécution du pipeline
Lorsqu’un pipeline « s’exécute », il ne se contente pas de « s’exécuter ». Tout comme les étapes qu’il contient, un pipeline passe également par diverses phases lors de son exécution. En raison du manque de terme officiel dans la documentation Microsoft, je les appelle « phases d’exécution ».
Lorsqu’un pipeline est déclenché, il traverse trois phases approximatives – File d’attente, Compilation et Exécution. Il est important de comprendre ces contextes car si vous naviguez dans la documentation Microsoft, vous verrez des références à ces termes.
Temps de file d’attente
La première phase par laquelle passe un pipeline lorsqu’il est déclenché en file d’attente. À cette étape, le pipeline n’a pas encore démarré mais est en attente et prêt à être exécuté lorsque l’agent est disponible. Lors de la définition des variables, vous pouvez les configurer pour être disponibles au moment de la file d’attente en ne les définissant pas dans le fichier YAML.
Vous pourrez définir des variables au moment de la file d’attente lorsque le pipeline est initialement mis en file d’attente comme indiqué ci-dessous. Lorsque cette variable est ajoutée, elle sera ensuite disponible en tant que variable globale dans le pipeline et pourra être remplacée par le même nom de variable dans le fichier YAML.
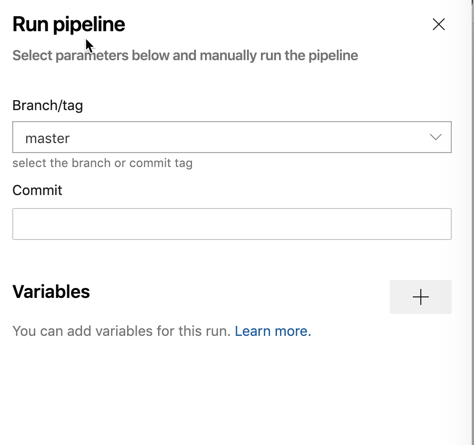
Compilation
Enfin, lorsque qu’un pipeline traite un fichier YAML et atteint les étapes qui nécessitent l’exécution de scripts, le pipeline se trouve dans la « phase » de compilation. Dans ce contexte, l’agent exécute le code défini dans les étapes du script.
Runtime
La phase suivante est l’exécution. C’est la phase pendant laquelle le fichier YAML est traité. Pendant cette phase, chaque étape, travail et script sont traités, mais ne exécutent aucun script.
Expansion de variable
Un autre sujet important à comprendre est l’expansion de variable. L’expansion de variable, en termes simples, se produit lorsque la variable renvoie une valeur statique. La variable s’étend pour révéler la valeur qu’elle détient. Cela se fait automatiquement lorsque vous lisez une variable, mais cette expansion peut se produire à différents moments lors de l’exécution d’un pipeline, ce qui peut vous dérouter.
Ce concept d’expansion de variable et de compilation par rapport à l’exécution reviendra souvent lorsque vous comprendrez la syntaxe des variables.
Comme vous l’avez appris ci-dessus, le pipeline couvre différentes « phases » lors de son exécution. Vous devrez probablement être conscient de ces phases lors du dépannage de l’expansion de variable.
Vous pouvez voir un exemple ci-dessous. Le concept de ces « phases » est étroitement lié aux environnements de variable.
Variables are expanded once when the pipeline run is started, and again, at the beginning of each step. Below you can see a simple example of this behavior.
Syntaxe des Variables
Comme vous l’avez appris, vous pouvez définir ou lire des variables dans deux « environnements » – l’environnement de pipeline et l’environnement de script. Pendant que vous êtes dans chaque environnement, la façon dont vous référencez les variables est un peu différente. Il y a quelques subtilités auxquelles vous devrez faire attention.
Variables de Pipeline
Les variables de pipeline sont référencées dans les définitions de build YAML et peuvent être référencées via trois méthodes syntaxiques différentes – macro, expression de modèle et expression d’exécution.
Syntaxe Macro
La syntaxe la plus courante que vous trouverez est la syntaxe macro. La syntaxe macro référence une valeur pour une variable sous la forme de $(foo). Les parenthèses représentent une expression qui est évaluée à l’exécution.
Lorsque Azure Pipelines traite une variable définie comme une expression macro, elle remplacera l’expression par le contenu de la variable. Lors de la définition de variables avec la syntaxe macro, elles suivent le modèle <nom de la variable>: $(<valeur de la variable>) par exemple foo: $(bar).
Si vous tentez de référencer une variable avec la syntaxe macro et qu’aucune valeur n’existe, la variable n’existera tout simplement pas. Ce comportement diffère un peu entre les types de syntaxe.
Syntaxe d’Expression de Modèle
Un autre type de syntaxe de variable est appelé expression de modèle. La définition des variables de pipeline de cette manière prend la forme de ${{ variables.foo }} : ${{ variables.bar }}. Comme vous pouvez le voir, c’est un peu plus long que la syntaxe de macro.
La syntaxe de l’expression de modèle a une fonctionnalité supplémentaire. En utilisant cette syntaxe, vous pouvez également étendre les paramètres du modèle. Si une variable définie avec la syntaxe de l’expression de modèle est référencée, le pipeline renverra une chaîne vide au lieu d’une valeur nulle avec la syntaxe de macro.
Les variables d’expression de modèle sont traitées au moment de la compilation, puis écrasées (si définies) au moment de l’exécution.
Syntaxe d’expression d’exécution
Comme le type de syntaxe, les variables d’expression d’exécution suggérées ne sont étendues qu’au moment de l’exécution. Ces types de variables sont représentés sous la forme $[variables.foo]. Tout comme les variables de syntaxe d’expression de modèle, ces types de variables renverront une chaîne vide si elles ne sont pas remplacées.
Tout comme la syntaxe de macro, la syntaxe d’expression d’exécution nécessite le nom de la variable du côté gauche de la définition, comme foo: $[variables.bar].
Variables de script
Travailler avec des variables à l’intérieur de scripts est un peu différent des variables de pipeline. La définition et la référence des variables de pipeline exposées dans les scripts de tâches peuvent se faire de deux manières : avec la syntaxe de commande de journalisation ou les variables d’environnement.
Commandes de journalisation
Une façon de définir et de référencer des variables de pipeline dans les scripts est d’utiliser la syntaxe des commandes de journalisation. Cette syntaxe est un peu complexe mais vous apprendrez qu’elle est nécessaire dans certaines situations. Les variables définies de cette manière doivent être définies comme une chaîne de caractères dans le script.
Pour définir une variable appelée foo avec une valeur de bar en utilisant la syntaxe des commandes de journalisation, cela ressemblerait à ce qui suit.
I could not find a way to get the value of variables using logging commands. If this exists, let me know!
Variables d’environnement
Quand les variables de pipeline sont transformées en variables d’environnement dans les scripts, les noms des variables sont légèrement modifiés. Vous constaterez que les noms de variables deviennent en majuscules et que les points se transforment en tirets bas. Vous constaterez que de nombreuses variables prédéfinies ou système contiennent des points.
Par exemple, si une variable de pipeline appelée [foo.bar](<http://foo.bar>) était définie, vous pourriez y faire référence via la méthode de référence native des variables d’environnement du script, telle que $env:FOO_BAR en PowerShell ou $FOO_BAR en Bash.
Nous avons couvert davantage de variables d’environnement dans la section Environnement de script ci-dessus.
Portée des variables
A pipeline has various stages, tasks and jobs running. Many areas have predefined variable scopes. A scope is namespace where when a variable is defined, its value can be referenced.
Il existe essentiellement trois portées de variables différentes dans une hiérarchie. Elles sont définies au niveau:
- racine, ce qui rend les variables disponibles pour tous les jobs dans le pipeline
- étape, ce qui rend les variables disponibles pour une étape spécifique
- job, ce qui rend les variables disponibles pour un job spécifique
Les variables définies aux niveaux « inférieurs », telles qu’un travail, remplaceront la même variable définie au niveau de la scène et de la racine, par exemple. Les variables définies au niveau de la scène remplaceront les variables définies au niveau de la « racine » mais seront remplacées par les variables définies au niveau du travail.
Vous pouvez voir ci-dessous un exemple de définition de construction YAML avec chaque portée utilisée.
Précédence des variables
Parfois, vous verrez une situation où une variable du même nom est définie dans diverses portées. Lorsque cela se produit, la valeur de cette variable sera écrasée selon une séquence spécifique, donnant la priorité à l' »action » la plus proche.
Vous verrez ci-dessous l’ordre dans lequel les variables seront écrasées, en commençant par une variable définie dans un travail. Cela aura la plus grande priorité.
- Variable définie au niveau du travail (définie dans le fichier YAML)
- Variable définie au niveau de la scène (définie dans le fichier YAML)
- Variable définie au niveau du pipeline (global) (définie dans le fichier YAML)
- Variable définie au moment de la file d’attente
- Variable de pipeline définie dans les paramètres de l’interface utilisateur du pipeline
Par exemple, jetez un œil à la définition YAML ci-dessous. Dans cet exemple, la même variable est définie dans de nombreux domaines différents mais finit par avoir la valeur définie dans le travail. Avec chaque action, la valeur de la variable est remplacée lorsque le pipeline descend jusqu’au travail.
Types de variables
Vous avez appris ce que sont les variables, à quoi elles ressemblent, les contextes dans lesquels elles peuvent être exécutées et bien plus encore dans cet article. Mais ce que nous n’avons pas couvert, c’est que toutes les variables ne se ressemblent pas. Certaines variables existent déjà lorsqu’un pipeline démarre et ne peuvent pas être modifiées, tandis que d’autres peuvent être créées, modifiées et supprimées à volonté.
Il existe quatre types généraux de variables – les variables prédéfinies ou systèmes, les variables définies par l’utilisateur, les variables de sortie et les variables secrètes. Passons à la couverture de chacun de ces types et comprenons chaque type de variable.
Variables prédéfinies
Dans toutes les constructions et les versions, vous trouverez de nombreuses variables différentes qui existent par défaut. Ces variables sont appelées prédéfinies ou système. Les variables prédéfinies sont toutes en lecture seule et, comme les autres types de variables, représentent des chaînes et des nombres simples.
Un pipeline Azure est composé de nombreux composants, de l’agent logiciel exécutant la construction, des travaux étant lancés lorsqu’un déploiement s’exécute et d’autres informations diverses. Pour représenter tous ces domaines, les variables prédéfinies ou variables système sont informellement divisées en cinq catégories distinctes :
- Agent
- Construction
- Pipeline
- Tâche de déploiement
- Système
Il existe des dizaines de variables réparties dans chacune de ces cinq catégories. Vous n’apprendrez pas toutes à leur sujet dans cet article. Si vous souhaitez obtenir une liste de toutes les variables prédéfinies, consultez la documentation Microsoft.
Variables définies par l’utilisateur
Lorsque vous créez une variable dans une définition YAML ou via un script, vous créez une variable définie par l’utilisateur. Les variables définies par l’utilisateur sont simplement toutes les variables que vous, en tant qu’utilisateur, définissez et utilisez dans un pipeline. Vous pouvez utiliser à peu près n’importe quel nom pour ces variables, à quelques exceptions près.
Vous ne pouvez pas définir de variables qui commencent par les mots endpoint, input, secret ou securefile. Ces étiquettes sont interdites car elles sont réservées à une utilisation système et elles ne sont pas sensibles à la casse.
De plus, les variables que vous définissez ne doivent contenir que des lettres, des chiffres, des points ou des caractères de soulignement. Si vous essayez de définir une variable ne suivant pas ce format, votre définition de build YAML ne fonctionnera pas.
Variables de sortie
A build definition contains one or more tasks. Sometimes a task sends a variable out to be made available to downstream steps and jobs within the same stage. These types of variables are called output variables.
Les variables de sortie sont utilisées pour partager des informations entre les composants du pipeline. Par exemple, si une tâche interroge une valeur dans une base de données et que les tâches ultérieures ont besoin du résultat retourné, une variable de sortie peut être utilisée. Vous n’avez alors pas besoin d’interroger la base de données à chaque fois. Vous pouvez simplement faire référence à la variable.
Note : Les variables de sortie sont limitées à une étape spécifique. Ne vous attendez pas à ce qu’une variable de sortie soit disponible à la fois dans votre étape de « build » et dans votre étape de « testing », par exemple.
Variables Secrètes
Le dernier type de variable est la variable secrète. Techniquement, ce n’est pas son propre type indépendant car elle peut être une variable définie par le système ou par l’utilisateur. Mais les variables secrètes doivent être dans leur propre catégorie car elles sont traitées différemment des autres variables.
A secret variable is a standard variable that’s encrypted. Secret variables typically contain sensitive information like API keys, passwords, etc. These variables are encrypted at rest with a 2048-bit RSA key and are available on the agent for all tasks and scripts to use.
– NE PAS définir les variables secrètes à l’intérieur de vos fichiers YAML
– NE PAS retourner les secrets en tant que variables de sortie ou informations de journalisation
Les variables secrètes doivent être définies dans l’éditeur de pipeline. Cela limite les variables secrètes au niveau global, les rendant ainsi disponibles pour les tâches dans le pipeline.
Les valeurs secrètes sont masquées dans les journaux mais pas complètement. C’est pourquoi il est important de ne pas les inclure dans un fichier YAML. Vous devez également savoir de ne pas inclure de données « structurées » en tant que secret. Si, par exemple, { "foo": "bar" } est défini comme un secret, bar ne sera pas masqué dans les journaux.
Les secrets ne sont pas automatiquement déchiffrés et mappés à des variables d’environnement. Si vous définissez une variable secrète, ne vous attendez pas à ce qu’elle soit disponible via
$env:FOOdans un script PowerShell, par exemple.
Groupes de Variables
Enfin, nous arrivons aux groupes de variables. Les groupes de variables, comme vous pouvez vous y attendre, sont des « groupes » de variables qui peuvent être référencés comme un seul. Le but principal d’un groupe de variables est de stocker des valeurs que vous souhaitez rendre disponibles dans plusieurs pipelines.
Contrairement aux variables, les groupes de variables ne sont pas définis dans le fichier YAML. Au lieu de cela, ils sont définis dans la page de la Bibliothèque sous Pipelines dans l’interface utilisateur.
Utilisez un groupe de variables pour stocker des valeurs que vous souhaitez contrôler et rendre disponibles dans plusieurs pipelines. Vous pouvez également utiliser des groupes de variables pour stocker des secrets et d’autres valeurs qui pourraient avoir besoin d’être transmises dans un pipeline YAML. Les groupes de variables sont définis et gérés dans la page de la Bibliothèque sous Pipelines comme indiqué ci-dessous.
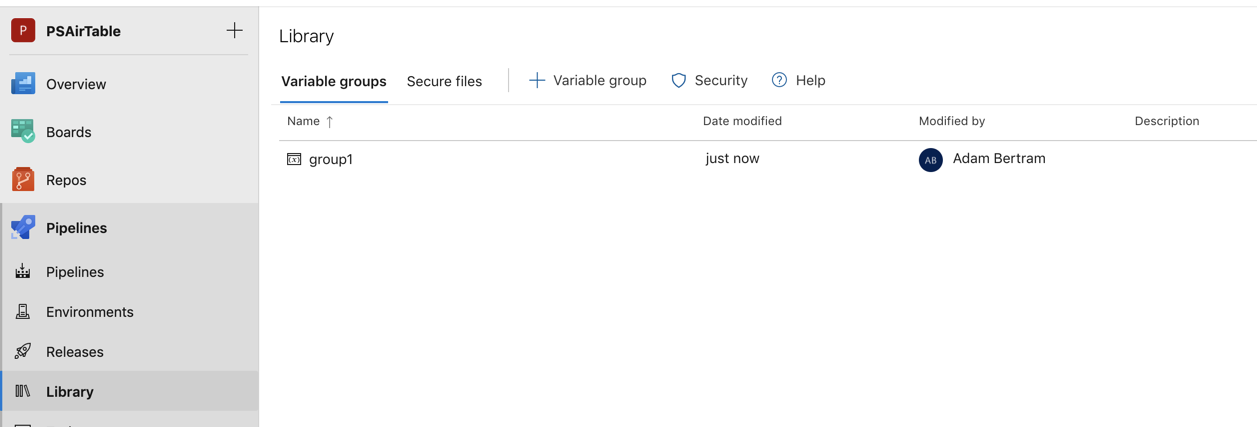
Une fois définis dans la bibliothèque de pipelines, vous pouvez ensuite accéder à ce groupe de variables dans le fichier YAML en utilisant la syntaxe ci-dessous.
Les groupes de variables ne sont pas, par défaut, disponibles pour tous les pipelines. Ce paramètre est disponible lors de la création du groupe. Les pipelines doivent être autorisés à utiliser un groupe de variables.
Une fois qu’un groupe de variables est accessible dans le fichier YAML, vous pouvez ensuite accéder aux variables à l’intérieur du groupe exactement comme vous le feriez pour toute autre variable. Le nom du groupe de variables n’est pas utilisé lors de la référence aux variables dans le groupe.
Par exemple, si vous avez défini un groupe de variables appelé group1 avec une variable appelée foo à l’intérieur, vous feriez référence à la variable foo comme toute autre, par exemple $(foo).
Les variables secrètes définies dans un groupe de variables ne peuvent pas être accédées directement via des scripts. Au lieu de cela, elles doivent être transmises en tant qu’arguments à la tâche.
Si une modification est apportée à une variable à l’intérieur d’un groupe de variables, cette modification sera automatiquement disponible pour tous les pipelines autorisés à utiliser ce groupe.
Résumé
Vous devriez maintenant avoir une connaissance solide des variables des pipelines Azure. Vous avez appris à peu près tous les concepts liés aux variables dans cet article ! Maintenant, mettez-vous en action, appliquez cette connaissance à vos pipelines Azure DevOps et automatisez toutes les tâches !
Source:
https://adamtheautomator.com/azure-devops-variables/