













Se você construiu um Pipeline do Azure DevOps como sua solução para um pipeline CI/CD, sem dúvida você se deparou com situações que exigem gerenciamento dinâmico de valores de configuração em compilações e lançamentos. Seja fornecendo uma versão de compilação para um script do PowerShell, passando parâmetros dinâmicos para tarefas de compilação ou usando strings em compilações e lançamentos, você precisa de variáveis.
Se você já se perguntou coisas como:
- Como eu uso variáveis de Pipeline de compilação do Azure DevOps em um script do PowerShell?
- Como eu compartilho variáveis entre compilações e lançamentos?
- Como diferem as variáveis pré-definidas, definidas pelo usuário e secretas?
- Como funcionam os grupos de variáveis?
…então você tem sorte! Neste artigo, responderemos a cada uma dessas perguntas e mais algumas.
Ao final deste artigo, você entenderá como as variáveis de compilação do Azure DevOps funcionam nos Pipelines do Azure!
O que são Variáveis de Pipeline do Azure DevOps?
Antes de mergulharmos nos detalhes das variáveis, o que são elas e como elas ajudam a construir e automatizar pipelines de compilação e lançamento eficientes?
As variáveis permitem que você passe pedaços de dados para várias partes de seus pipelines. As variáveis são ótimas para armazenar texto e números que podem mudar ao longo do fluxo de trabalho de um pipeline. Em um pipeline, você pode definir e ler variáveis quase em todos os lugares, em vez de codificar valores em scripts e definições YAML.
Nota: Este artigo irá focar apenas em pipelines YAML. Não iremos cobrir nenhuma informação sobre pipelines clássicos legados. Além disso, com algumas poucas exceções, você não aprenderá como trabalhar com variáveis através da interface web. Iremos aderir estritamente ao YAML.
As variáveis são referenciadas e algumas definidas (veja as variáveis definidas pelo usuário) durante a execução. Quando um pipeline inicia um job, diversos processos gerenciam essas variáveis e passam seus valores para outras partes do sistema. Esse sistema fornece uma maneira de executar jobs de pipeline dinamicamente sem se preocupar com a alteração das definições de build e scripts toda vez.
Não se preocupe se você ainda não entendeu o conceito de variáveis neste ponto. O restante deste artigo irá te ensinar tudo que você precisa saber.
**Ambientes de Variáveis**
Antes de entrar nas variáveis propriamente ditas, é importante primeiro cobrir os ambientes de variáveis do pipeline Azure. Você verá várias referências a este termo ao longo do artigo.
Dentro de um pipeline, existem dois lugares informalmente chamados de ambientes onde você pode interagir com variáveis. Você pode trabalhar com variáveis dentro de uma definição de build YAML chamada de ambiente pipeline ou dentro de um script executado através de uma task chamada de ambiente script.
O Ambiente do Pipeline
Ao definir ou ler variáveis de construção de dentro de uma definição de compilação YAML, isso é chamado de ambiente do pipeline. Por exemplo, abaixo você pode ver a seção variáveis definida em uma definição de compilação YAML configurando uma variável chamada foo para bar. Neste contexto, a variável está sendo definida dentro do ambiente do pipeline
O Ambiente de Script
Você também pode trabalhar com variáveis de dentro do código definido na própria definição YAML ou em scripts. Quando você não tem um script existente já criado, você pode definir e ler variáveis dentro da definição YAML conforme mostrado abaixo. Você aprenderá a sintaxe sobre como trabalhar com essas variáveis neste contexto posteriormente.
Alternativamente, você pode permanecer dentro do ambiente de script adicionando esta mesma sintaxe em um script Bash e executando-o. Este é o mesmo conceito geral.
Variáveis de Ambiente
Dentro do ambiente de script, quando uma variável de pipeline é disponibilizada, isso é feito criando uma variável de ambiente. Essas variáveis de ambiente podem então ser acessadas através dos métodos típicos da linguagem escolhida.
As variáveis de pipeline expostas como variáveis de ambiente sempre estarão em maiúsculas e quaisquer pontos serão substituídos por sublinhados. Por exemplo, você verá abaixo como cada linguagem de script pode acessar a variável de pipeline foo conforme mostrado abaixo.
- Lote –
%FOO% - PowerShell –
$env:FOO - Script Bash –
$FOO
Fases de “Execução de Pipeline”
Quando um pipeline “executa”, não é apenas uma execução direta. Assim como as etapas que contém, um pipeline também passa por várias fases durante a execução. Devido à falta de um termo oficial na documentação da Microsoft, estou chamando isso de “fases de execução”.
Quando um pipeline é acionado, ele passa por três fases aproximadas – Fila, Compilação e Tempo de Execução. É importante entender esses contextos porque, ao navegar pelos documentos da Microsoft, você encontrará referências a esses termos.
Tempo de Fila
A primeira fase pela qual um pipeline passa quando é acionado é o tempo de fila. Nesta fase, o pipeline ainda não começou, mas está enfileirado e pronto para iniciar quando o agente estiver disponível. Ao definir variáveis, você pode configurá-las para estar disponíveis no momento da fila, não as definindo no arquivo YAML.
Você poderá definir variáveis no momento da fila quando o pipeline for inicialmente enfileirado, conforme mostrado abaixo. Quando esta variável é adicionada, ela será então disponibilizada como uma variável global no pipeline e pode ser substituída pelo mesmo nome de variável no arquivo YAML.
Compilação
Finalmente, quando um pipeline processa um arquivo YAML e chega às etapas que exigem a execução de scripts, o pipeline está na fase de compilação. Nesse contexto, o agente executa o código definido nas etapas de script.
Tempo de execução
A próxima fase é o tempo de execução. Nesta fase, o arquivo YAML está sendo processado. Durante esta fase, cada estágio, tarefa e etapa estão sendo processados, mas não executando nenhum script.
Expansão de variáveis
Outro tópico importante a entender é a expansão de variáveis. A expansão de variáveis, em termos mais simples, ocorre quando a variável retorna um valor estático. A variável se expande para revelar o valor que ela contém. Isso é feito automaticamente quando você lê uma variável, mas essa expansão pode ser feita em momentos diferentes durante a execução do pipeline, o que pode causar confusão.
Esse conceito de expansão de variáveis e compilação versus tempo de execução será abordado com frequência quando você começar a entender a sintaxe das variáveis.
Como você aprendeu acima, o pipeline abrange diferentes “fases” durante sua execução. Você precisará estar ciente dessas fases provavelmente ao solucionar problemas de expansão de variáveis.
Você pode ver um exemplo abaixo. O conceito dessas “fases” está intimamente relacionado aos ambientes de variáveis.
Variáveis são expandidas uma vez quando a execução do pipeline é iniciada e novamente no início de cada etapa. Abaixo, você pode ver um exemplo simples desse comportamento.
Sintaxe de Variáveis
Como você aprendeu, é possível definir ou ler variáveis em dois “ambientes” – o ambiente do pipeline e o ambiente do script. Enquanto estiver em cada ambiente, a forma como você referencia as variáveis é um pouco diferente. Existem algumas nuances pelas quais você precisa ficar atento.
Variáveis de Pipeline
As variáveis de pipeline são referenciadas nas definições de build YAML e podem ser referenciadas por meio de três métodos de sintaxe diferentes – macro, expressão de modelo e expressão de tempo de execução.
Sintaxe de Macro
A sintaxe de macro é a mais comum que você encontrará. A sintaxe de macro referencia um valor para uma variável no formato $(foo). Os parênteses representam uma expressão que é avaliada durante o tempo de execução.
Quando o Azure Pipelines processa uma variável definida como uma expressão de macro, ele substituirá a expressão pelo conteúdo da variável. Ao definir variáveis com a sintaxe de macro, elas seguem o padrão <nome da variável>: $(<valor da variável>), por exemplo, foo: $(bar).
Se você tentar referenciar uma variável com a sintaxe de macro e um valor não existir, a variável simplesmente não existirá. Esse comportamento difere um pouco entre os tipos de sintaxe.
Sintaxe de Expressão de Modelo
Outro tipo de sintaxe de variável é chamado de expressão de modelo. Definir variáveis de pipeline desta forma assume a forma de ${{ variáveis.foo }} : ${{ variáveis.bar }}. Como você pode ver, é um pouco mais longo do que a sintaxe de macro.
A sintaxe de expressão de modelo também tem um recurso adicional. Usando esta sintaxe, você também pode expandir parâmetros de modelo. Se uma variável definida com a sintaxe de expressão de modelo for referenciada, o pipeline retornará uma string vazia em vez de um valor nulo com a sintaxe de macro.
As variáveis de expressão de modelo são processadas no momento da compilação e depois sobrescritas (se definidas) durante a execução.
Sintaxe de Expressão em Tempo de Execução
Como o tipo de sintaxe, as variáveis de expressão em tempo de execução sugeridas são expandidas apenas durante a execução. Esses tipos de variáveis são representados através do formato $[variáveis.foo]. Como as variáveis de sintaxe de expressão de modelo, esses tipos de variáveis retornarão uma string vazia se não forem substituídas.
Assim como a sintaxe de macro, a sintaxe de expressão em tempo de execução requer o nome da variável no lado esquerdo da definição, como foo: $[variáveis.bar].
Variáveis de Script
Trabalhar com variáveis dentro de scripts é um pouco diferente do que as variáveis de pipeline. Definir e referenciar variáveis de pipeline expostas em scripts de tarefas pode ser feito de duas maneiras; com sintaxe de comando de log ou variáveis de ambiente.
Comandos de Registro
Uma maneira de definir e referenciar variáveis de pipeline em scripts é usar a sintaxe de comandos de registro. Essa sintaxe é um pouco complicada, mas você aprenderá que é necessária em determinadas situações. As variáveis são definidas dessa maneira devem ser definidas como uma string no script.
Configurar uma variável chamada foo com um valor de bar usando a sintaxe de comandos de registro seria parecido com o exemplo abaixo.
I could not find a way to get the value of variables using logging commands. If this exists, let me know!
Variáveis de Ambiente
Quando as variáveis de pipeline são convertidas em variáveis de ambiente em scripts, os nomes das variáveis são ligeiramente alterados. Você perceberá que os nomes das variáveis ficam em maiúsculas e os pontos se tornam sublinhados. Muitas variáveis predefinidas ou do sistema têm pontos nelas.
Por exemplo, se uma variável de pipeline chamada [foo.bar](<http://foo.bar>) fosse definida, você a referenciaria através do método nativo de referência de variável de ambiente do script, como $env:FOO_BAR no PowerShell ou $FOO_BAR no Bash.
Cobrimos mais sobre variáveis de ambiente na seção Ambiente de Script acima.
Escopo da Variável
A pipeline has various stages, tasks and jobs running. Many areas have predefined variable scopes. A scope is namespace where when a variable is defined, its value can be referenced.
Existem essencialmente três escopos de variáveis diferentes em uma hierarquia. Elas são variáveis definidas em:
- o nível raiz, tornando as variáveis disponíveis para todos os trabalhos no pipeline
- o nível de estágio, tornando as variáveis disponíveis para um estágio específico
- o nível de trabalho, tornando as variáveis disponíveis para um trabalho específico
Variáveis definidas nos níveis “inferiores”, como em um trabalho, substituirão a mesma variável definida no nível do estágio e na raiz, por exemplo. Variáveis definidas no nível do estágio substituirão variáveis definidas no nível “raiz”, mas serão substituídas por variáveis definidas no nível do trabalho.
Abaixo, você pode ver um exemplo de definição de construção YAML em que cada escopo está sendo utilizado.
Precedência de Variável
Às vezes, você verá uma situação em que uma variável com o mesmo nome é definida em vários escopos. Quando isso acontece, o valor dessa variável será sobrescrito de acordo com uma sequência específica, dando precedência à “ação” mais próxima.
Abaixo, você verá a ordem em que as variáveis serão sobrescritas, começando com uma variável definida dentro de um trabalho. Isso terá a maior precedência.
- Variável definida no nível do trabalho (definida no arquivo YAML)
- Variável definida no nível do estágio (definida no arquivo YAML)
- Variável definida no nível do pipeline (global) (definida no arquivo YAML)
- Variável definida no momento da fila
- Variável do pipeline definida nas configurações de interface do usuário do Pipeline
Por exemplo, dê uma olhada na definição YAML abaixo. Neste exemplo, a mesma variável é definida em muitas áreas diferentes, mas acaba com o valor definido no trabalho. Com cada ação, o valor da variável é sobrescrito quando o pipeline chega ao trabalho.
Tipos de Variáveis
Você aprendeu sobre o que são variáveis, como elas se parecem, os contextos em que podem ser executadas e muito mais até agora neste artigo. Mas o que não cobrimos é que nem todas as variáveis são iguais. Algumas variáveis já existem quando um pipeline começa e não podem ser alteradas, enquanto outras você pode criar, alterar e remover à vontade.
Existem quatro tipos gerais de variáveis – variáveis predefinidas ou do sistema, variáveis definidas pelo usuário, variáveis de saída e variáveis secretas. Vamos abordar cada uma delas e entender cada tipo de variável.
Variáveis Predefinidas
Em todas as construções e lançamentos, você encontrará muitas variáveis diferentes que existem por padrão. Essas variáveis são chamadas de predefinidas ou do sistema. As variáveis predefinidas são todas somente de leitura e, como outros tipos de variáveis, representam strings simples e números.
Um pipeline Azure consiste em muitos componentes, desde o agente de software que executa a construção, trabalhos sendo iniciados quando uma implantação é executada e outras diversas informações. Para representar todas essas áreas, as variáveis predefinidas ou do sistema são informalmente divididas em cinco categorias distintas:
- Agente
- Construção
- Pipeline
- Trabalho de implantação
- Sistema
Há dezenas de variáveis espalhadas por cada uma destas cinco categorias. Você não vai aprender sobre todas elas neste artigo. Se deseja uma lista de todas as variáveis predefinidas, dê uma olhada na documentação da Microsoft.
Variáveis Definidas pelo Usuário
Ao criar uma variável em uma definição YAML ou via script, você está criando uma variável definida pelo usuário. Variáveis definidas pelo usuário são simplesmente todas as variáveis que você, o usuário, define e usa em um pipeline. Você pode usar praticamente qualquer nome que desejar para essas variáveis, com algumas exceções.
Você não pode definir variáveis que comecem com a palavra endpoint, input, secret ou securefile. Esses rótulos estão fora de alcance porque são reservados para uso do sistema e não fazem distinção entre maiúsculas e minúsculas.
Além disso, qualquer variável que você definir deve consistir apenas de letras, números, pontos ou caracteres de sublinhado. Se tentar definir uma variável que não siga este formato, sua definição de build YAML não funcionará.
Variáveis de Saída
A build definition contains one or more tasks. Sometimes a task sends a variable out to be made available to downstream steps and jobs within the same stage. These types of variables are called output variables.
As variáveis de saída são usadas para compartilhar informações entre os componentes do pipeline. Por exemplo, se uma tarefa consultar um valor de um banco de dados e as tarefas subsequentes precisarem do resultado retornado, uma variável de saída pode ser usada. Você então não precisa consultar o banco de dados toda vez. Em vez disso, pode simplesmente fazer referência à variável.
Nota: As variáveis de saída estão delimitadas a uma etapa específica. Não espere que uma variável de saída esteja disponível em sua etapa de “build” e também em sua etapa de “testing”, por exemplo.
Variáveis Secretas
O último tipo de variável é a variável secreta. Tecnicamente, esta não é sua própria tipo independente, porque pode ser uma variável definida pelo sistema ou pelo usuário. Mas as variáveis secretas precisam estar em sua própria categoria, pois são tratadas de maneira diferente das outras variáveis.
A secret variable is a standard variable that’s encrypted. Secret variables typically contain sensitive information like API keys, passwords, etc. These variables are encrypted at rest with a 2048-bit RSA key and are available on the agent for all tasks and scripts to use.
– NÃO defina variáveis secretas dentro de seus arquivos YAML
– NÃO retorne segredos como variáveis de saída ou informações de registro
As variáveis secretas devem ser definidas no editor de pipeline. Isso delimita as variáveis secretas no nível global, tornando-as disponíveis para tarefas na pipeline.
Os valores secretos são mascarados nos logs, mas não completamente. Por isso, é importante não incluí-los em um arquivo YAML. Você também deve saber que não deve incluir nenhum dado “estruturado” como um segredo. Se, por exemplo, { "foo": "bar" } for definido como um segredo, bar não será mascarado nos logs.
Os segredos não são automaticamente descriptografados e mapeados para variáveis de ambiente. Se você definir uma variável secreta, não espere que ela esteja disponível via
$env:FOOem um script PowerShell, por exemplo.
Grupos de Variáveis
Finalmente, chegamos aos grupos de variáveis. Grupos de variáveis, como você pode esperar, são “grupos” de variáveis que podem ser referenciadas como uma só. O propósito principal de um grupo de variáveis é armazenar valores que você deseja tornar disponíveis em várias pipelines.
Ao contrário das variáveis, os grupos de variáveis não são definidos no arquivo YAML. Em vez disso, eles são definidos na página da Biblioteca sob Pipelines na interface do usuário.
Use um grupo de variáveis para armazenar valores que você deseja controlar e disponibilizar em várias pipelines. Você também pode usar grupos de variáveis para armazenar segredos e outros valores que podem precisar ser passados para uma pipeline YAML. Os grupos de variáveis são definidos e gerenciados na página da Biblioteca sob Pipelines, conforme mostrado abaixo.
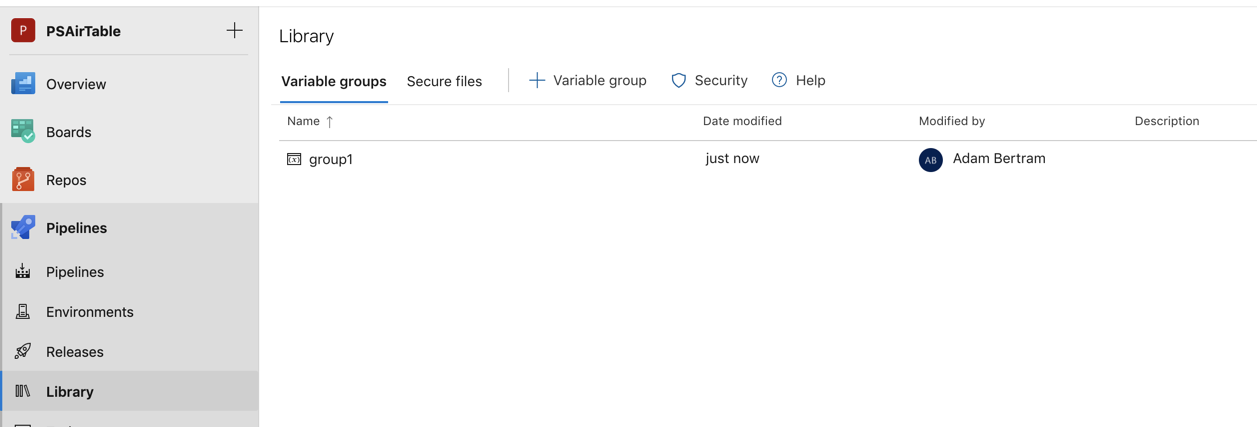
Depois de definido na biblioteca de pipelines, você pode então acessar esse grupo de variáveis no arquivo YAML usando a sintaxe abaixo.
Os grupos de variáveis não estão, por padrão, disponíveis para todas as pipelines. Essa configuração é disponibilizada ao criar o grupo. As pipelines devem estar autorizadas a usar um grupo de variáveis.
Depois que um grupo de variáveis é acessado no arquivo YAML, você pode então acessar as variáveis dentro do grupo exatamente como faria com qualquer outra variável. O nome do grupo de variáveis não é usado ao referenciar variáveis no grupo.
Por exemplo, se você definiu um grupo de variáveis chamado grupo1 com uma variável chamada foo dentro, você referenciaria a variável foo como qualquer outra, por exemplo. $(foo).
As variáveis secretas definidas em um grupo de variáveis não podem ser acessadas diretamente via scripts. Em vez disso, elas devem ser passadas como argumentos para a tarefa.
Se uma alteração for feita em uma variável dentro de um grupo de variáveis, essa alteração será automaticamente disponibilizada para todas as pipelines autorizadas a usar esse grupo.
Resumo
Deve agora ter um conhecimento sólido das variáveis do Azure Pipelines. Aprendeu praticamente todos os conceitos relacionados a variáveis neste artigo! Agora, ponha isso em prática, aplique este conhecimento aos seus Azure DevOps Pipelines e automatize todas as coisas!
Source:
https://adamtheautomator.com/azure-devops-variables/