













Введение
В этом учебнике вы создадите приложение на Python, способное извлекать аудио из входного видео, транскрибировать извлеченное аудио, создавать файл с субтитрами на основе транскрипции и затем добавлять субтитры к копии входного видео.
Для создания этого приложения вы будете использовать FFmpeg для извлечения аудио из входного видео. Вы будете использовать Whisper от OpenAI для создания транскрипции для извлеченного аудио, а затем использовать этот транскрипт для создания файла с субтитрами. Кроме того, вы будете использовать FFmpeg для добавления созданного файла с субтитрами к копии входного видео.
FFmpeg – мощный и свободно распространяемый программный пакет для обработки мультимедийных данных, включая задачи обработки аудио и видео. Он предоставляет инструмент командной строки, который позволяет пользователям конвертировать, редактировать и обрабатывать мультимедийные файлы с широким спектром форматов и кодеков.
Whisper от OpenAI – это система автоматического распознавания речи (ASR), разработанная для преобразования устной речи в письменный текст. Обученная на огромном объеме многоязычных и многозадачных данных с учителем, она отличается высокой точностью в транскрибации разнообразного аудиоконтента.
К концу этого учебника у вас будет приложение, способное добавлять субтитры к видео.
Предварительные требования
Чтобы следовать этому руководству, читателю понадобятся следующие инструменты:
-
FFmpeg установленный.
-
Базовое понимание Python. Вы можете следовать этой серии учебных пособий, чтобы научиться программировать на Python.
Шаг 1 — Создание корневого каталога проекта
В этом разделе вы создадите каталог проекта, загрузите исходное видео, создадите и активируете виртуальное окружение, а также установите необходимые пакеты Python.
Откройте окно терминала и перейдите в подходящее местоположение для вашего проекта. Выполните следующую команду, чтобы создать каталог проекта:
Перейдите в каталог проекта:
Загрузите это отредактированное видео и сохраните его в корневой каталог вашего проекта как input.mp4. Видео демонстрирует ребенка по имени Рашон, поющего песню Джермейна Эдвардса “Прекрасный день”. Отредактированное видео, которое вы собираетесь использовать в этом руководстве, было взято из следующего YouTube видео:
Создайте новую виртуальную среду и назовите ее env:
Активируйте виртуальную среду:
Теперь используйте следующую команду, чтобы установить необходимые пакеты для создания этого приложения:
С помощью приведенной выше команды вы установили следующие библиотеки:
-
faster-whisper: это переработанная версия модели Whisper от OpenAI, которая использует CTranslate2, высокопроизводительный движок вывода для моделей Transformer. Эта реализация достигает до четырехкратного увеличения скорости по сравнению с openai/whisper при сопоставимой точности, потребляя при этом меньше памяти. -
ffmpeg-python: это библиотека Python, которая предоставляет оболочку вокруг инструмента FFmpeg, позволяя пользователям легко взаимодействовать с функциями FFmpeg в сценариях Python. Через питонический интерфейс он позволяет выполнять задачи обработки видео и аудио, такие как редактирование, конвертация и манипуляция.
Запустите следующую команду, чтобы сохранить пакеты, установленные с использованием pip, в виртуальной среде, в файл с именем requirements.txt:
Файл requirements.txt должен выглядеть примерно следующим образом:
av==10.0.0
certifi==2023.7.22
charset-normalizer==3.3.2
coloredlogs==15.0.1
ctranslate2==3.20.0
faster-whisper==0.9.0
ffmpeg-python==0.2.0
filelock==3.13.1
flatbuffers==23.5.26
fsspec==2023.10.0
future==0.18.3
huggingface-hub==0.17.3
humanfriendly==10.0
idna==3.4
mpmath==1.3.0
numpy==1.26.1
onnxruntime==1.16.1
packaging==23.2
protobuf==4.25.0
PyYAML==6.0.1
requests==2.31.0
sympy==1.12
tokenizers==0.14.1
tqdm==4.66.1
typing_extensions==4.8.0
urllib3==2.0.7
В этом разделе вы создали каталог проекта, загрузили входное видео, которое будет использоваться в этом учебнике, настроили виртуальное окружение, активировали его и установили необходимые пакеты Python. В следующем разделе вы сгенерируете транскрипт для входного видео.
Шаг 2 — Генерация транскрипта видео
В данном разделе вы создадите сценарий на языке Python, в котором будет работать приложение. Внутри этого сценария вы будете использовать библиотеку ffmpeg-python для извлечения аудиодорожки из видео, загруженного в предыдущем разделе, и сохранения ее в формате WAV. Затем вы будете использовать библиотеку faster-whisper для создания транскрипции для извлеченного аудио.
В корневом каталоге вашего проекта создайте файл с именем main.py и добавьте в него следующий код:
Здесь код начинается с импорта различных библиотек и модулей, включая time, math, ffmpeg из ffmpeg-python и собственный модуль с именем WhisperModel из faster_whisper. Эти библиотеки будут использоваться для обработки видео и аудио, транскрибации и создания субтитров.
Далее код устанавливает имя входного видеофайла, сохраняет его в константу с именем input_video, а затем сохраняет имя видеофайла без расширения .mp4 в константе с именем input_video_name. Установка имени входного файла здесь позволит вам работать с несколькими входными видео, не перезаписывая файлы субтитров и выходных видео, созданных для них.
Добавьте следующий код в конец вашего файла main.py:
Код выше определяет функцию с именем extract_audio(), которая отвечает за извлечение аудио из входного видео.
Сначала устанавливается имя аудио, которое будет извлечено, путем добавления audio- к базовому имени входного видео с расширением .wav, и это имя сохраняется в константе с именем extracted_audio.
Затем код вызывает метод ffmpeg.input() библиотеки ffmpeg для открытия входного видео и создает объект входного потока с именем stream.
Затем код вызывает метод ffmpeg.output() для создания объекта выходного потока с входным потоком и заданным именем файла извлеченного аудио.
После установки выходного потока код вызывает метод ffmpeg.run(), передавая выходной поток в качестве параметра, чтобы начать процесс извлечения аудио и сохранить извлеченный аудиофайл в корневом каталоге вашего проекта. Дополнительно включается булевый параметр, overwrite_output=True, для замены любого существующего выходного файла новым, если такой файл уже существует.
Наконец, код возвращает имя извлеченного аудиофайла.
Добавьте следующий код ниже функции extract_audio():
Здесь код определяет функцию с именем run() и затем вызывает ее. Эта функция вызывает все необходимые функции для создания и добавления субтитров к видео.
Внутри функции код вызывает функцию extract_audio() для извлечения аудио из видео, а затем сохраняет возвращенное имя аудиофайла в переменной с именем extracted_audio.
Вернитесь в терминал и выполните следующую команду для запуска скрипта main.py:
После выполнения вышеуказанной команды, вывод FFmpeg будет отображен в терминале, и файл с именем audio-input.wav, содержащий аудио, извлеченное из входного видео, будет сохранен в корневом каталоге вашего проекта.
Вернитесь в свой файл main.py и добавьте следующий код между функциями extract_audio() и run():
Приведенный выше код определяет функцию с именем transcribe, ответственную за транскрибацию аудиофайла, извлеченного из входного видео.
Сначала код создает экземпляр объекта WhisperModel и устанавливает тип модели в small. У OpenAI’s Whisper есть следующие типы моделей: tiny, base, small, medium и large. Модель tiny является самой маленькой и быстрой, а модель large – самой большой и медленной, но наиболее точной.
Затем код вызывает метод model.transcribe() с извлеченным аудио в качестве аргумента, чтобы получить функцию сегментов и информацию об аудио, сохраняя их в переменных с именами info и segments соответственно. Функция сегментов представляет собой генератор Python, поэтому транскрибация начнется только при переборе кода. Транскрибацию можно завершить, собрав сегменты в list или for цикл.
Затем код сохраняет обнаруженный язык в аудио в константе с именем info и выводит его в консоль.
После вывода обнаруженного языка код собирает сегменты транскрипции в list, чтобы запустить транскрипцию, и сохраняет собранные сегменты в переменной с именем segments. Затем код выполняет цикл по списку сегментов транскрипции и выводит начальное время, конечное время и текст каждого сегмента в консоль.
Наконец, код возвращает обнаруженный язык в аудио и сегменты транскрипции.
Добавьте следующий код внутри функции run():
Добавленный код вызывает функцию транскрипции с извлеченным аудио в качестве аргумента и сохраняет возвращенные значения в константах с именем language и segments.
Вернитесь в терминал и выполните следующую команду для запуска сценария main.py:
Первый раз при запуске этого сценария код сначала загрузит и кэширует модель Whisper Small, последующие запуски будут намного быстрее.
После выполнения вышеуказанной команды вы должны увидеть следующий вывод в консоли:
…
Transcription language en
[0.00s -> 4.00s] This morning I wake up and I look in the mirror
[4.00s -> 8.00s] Every part of my body was in the place many people lie
[8.00s -> 11.00s] I don't wanna act too high and mighty
[11.00s -> 15.00s] Cause tomorrow I may fall down on my face
[15.00s -> 17.00s] Lord I thank You for sunshine
[17.00s -> 19.00s] Thank You for rain
[19.00s -> 20.00s] Thank You for joy
[20.00s -> 22.00s] Thank You for pain
[22.00s -> 25.00s] It's a beautiful day
[25.00s -> 28.00s] It's a beautiful day
Вывод выше показывает, что обнаруженный язык в аудио – английский (en). Кроме того, он показывает начальное и конечное время каждого сегмента транскрипции в секундах и текст.
Предупреждение: Хотя распознавание речи Whisper от OpenAI очень точно, оно не на 100% точно, оно может подвергаться ограничениям и случайным ошибкам, особенно в сложных лингвистических или аудиосценариях. Поэтому всегда убедитесь вручную проверять транскрипцию.
В этом разделе вы создали сценарий на языке Python для приложения. Внутри скрипта использовался ffmpeg-python для извлечения аудио из загруженного видео и сохранения его в формате WAV. Затем была использована библиотека faster-whisper для генерации транскрипта из извлеченного аудио. В следующем разделе вы сгенерируете файл с субтитрами на основе транскрипта, а затем добавите субтитры к видео.
Шаг 3 — Генерация и добавление субтитров к видео
В этом разделе сначала вы поймете, что такое файл с субтитрами и как он устроен. Затем вы будете использовать сгенерированные сегменты транскрипта из предыдущего раздела для создания файла с субтитрами. После создания файла с субтитрами вы будете использовать библиотеку ffmpeg-python для добавления файла с субтитрами к копии входного видео.
Понимание субтитров: структура и типы
A subtitle file is a text file that contains timed text information corresponding to spoken or written content in a video or film. It typically includes information about when each subtitle should appear and disappear on the screen. There are many subtitle formats, however, in this tutorial, we will focus on the widely used format named SubRip (SRT).
A subtitle file is organized into a series of subtitle entries, each typically following a specific format. The common structure of a subtitle entry includes:
-
Индекс субтитра: Последовательный номер, указывающий порядок субтитра в файле.
-
Временные метки: Начальные и конечные маркеры времени, которые указывают, когда текст субтитров должен отображаться. Временные метки обычно форматируются как
ЧЧ:ММ:СС,мсмсм(часы, минуты, секунды, миллисекунды). -
Текст субтитров: Фактический текст записи субтитров, представляющий собой произнесенный или написанный контент. Этот текст отображается на экране в течение указанного временного интервала.
Например, запись субтитров в файле SRT может выглядеть так:
1
00:00:10,500 --> 00:00:15,000
This is an example subtitle.
В этом примере индекс равен 1, временные метки указывают, что субтитры должны отображаться с 10.5 секунд по 15 секунд, а текст субтитров – Это пример субтитра.
Субтитры можно разделить на два основных типа:
-
Мягкие субтитры: Также известные как закрытые подписи, хранятся внешне в виде отдельных файлов (например, SRT) и могут быть добавлены или удалены независимо от видео. Они обеспечивают гибкость просмотра, позволяя переключать, переключаться на другие языки и настраивать параметры. Однако их эффективность зависит от поддержки видеоплеера, и не все плееры универсально поддерживают мягкие субтитры.
-
Жёсткие субтитры: Постоянно встроены в кадры видео во время редактирования или кодирования и остаются неизменной частью видео. Хотя они обеспечивают постоянную видимость, даже на плеерах, не поддерживающих внешние файлы субтитров, их изменение или отключение требует повторного кодирования всего видео, ограничивая контроль пользователя
Создание файла субтитров
Вернитесь к вашему файлу main.py и добавьте следующий код между функциями transcribe() и run():
Вот, код определяет функцию с именем format_time(), которая отвечает за преобразование начального и конечного времени сегмента транскрипции в секундах в формат субтитров, который отображает часы, минуты, секунды и миллисекунды (ЧЧ:ММ:СС,мс).
Сначала код вычисляет часы, минуты, секунды и миллисекунды из заданного времени в секундах, соответственно форматирует их, а затем возвращает отформатированное время.
Добавьте следующий код между функциями format_time() и run():
В добавленном коде определяется функция с именем generate_subtitle_file(), которая принимает в качестве параметров обнаруженный язык в извлеченном аудио и сегменты транскрипции. Эта функция отвечает за создание файла субтитров в формате SRT на основе языка и сегментов транскрипции.
Сначала код устанавливает имя файла субтитров как имя, сформированное путем добавления sub- и обнаруженного языка к базовому имени входного видео с расширением «.srt», и сохраняет это имя в константе с именем subtitle_file. Кроме того, код определяет переменную с именем text, где вы будете хранить записи субтитров.
Затем код проходит по сегментам транскрибации, форматирует начальное и конечное времена, используя функцию format_time(), использует эти отформатированные значения вместе с индексом сегмента и текстом, чтобы создать запись субтитров, а затем добавляет пустую строку для разделения каждой записи субтитров.
Наконец, код создает файл субтитров в корневом каталоге вашего проекта с ранее заданным именем, добавляет записи субтитров в файл и возвращает имя файла субтитров.
Добавьте следующий код в конец вашей функции run():
Добавленный код вызывает функцию generate_subtitle_file() с обнаруженным языком и сегментами транскрипции в качестве аргументов и сохраняет имя файла субтитров, возвращаемое функцией, в константу с именем subtitle_file.
Вернитесь в терминал и выполните следующую команду для запуска скрипта main.py:
После выполнения указанной команды в корневом каталоге вашего проекта будет сохранен файл субтитров с именем sub-input.en.srt.
Откройте файл субтитров sub-input.en.srt, и вы должны увидеть нечто подобное:
1
00:00:0,000 --> 00:00:4,000
This morning I wake up and I look in the mirror
2
00:00:4,000 --> 00:00:8,000
Every part of my body was in the place many people lie
3
00:00:8,000 --> 00:00:11,000
I don't wanna act too high and mighty
4
00:00:11,000 --> 00:00:15,000
Cause tomorrow I may fall down on my face
5
00:00:15,000 --> 00:00:17,000
Lord I thank You for sunshine
6
00:00:17,000 --> 00:00:19,000
Thank You for rain
7
00:00:19,000 --> 00:00:20,000
Thank You for joy
8
00:00:20,000 --> 00:00:22,000
Thank You for pain
9
00:00:22,000 --> 00:00:25,000
It's a beautiful day
10
00:00:25,000 --> 00:00:28,000
It's a beautiful day
Добавление субтитров к видео
Добавьте следующий код между функциями generate_subtitle_file() и run():
Здесь код определяет функцию с именем add_subtitle_to_video(), которая принимает в качестве параметров логическое значение, используемое для определения необходимости добавления мягких или жестких субтитров, имя файла субтитров и обнаруженный язык в транскрипции. Эта функция отвечает за добавление мягких или жестких субтитров к копии входного видео.
Сначала код использует метод ffmpeg.input() с входным видео и файлом субтитров, чтобы создать объекты входного потока для входного видео и файла субтитров и сохранить их в константах с именами video_input_stream и subtitle_input_stream соответственно.
После создания входных потоков код задает имя выходного видеофайла, которое формируется путем добавления префикса output- к базовому имени входного видео с расширением «.mp4», и сохраняет это имя в константе с именем output_video. Кроме того, задает имя субтитров, которое равно имени файла субтитров без расширения .srt, и сохраняет это имя в константе с именем subtitle_track_title.
Далее код проверяет, установлено ли логическое значение soft_subtitle в True, что указывает на необходимость добавления мягких субтитров.
Если это так, код вызывает метод ffmpeg.output() для создания объекта выходного потока с входными потоками, именем выходного видеофайла и следующими параметрами для выходного видео:
-
"c": "copy": Он указывает, что видеокодек и другие параметры видео должны быть скопированы напрямую из входного потока в выходной без повторного кодирования. -
"c:s": "mov_text": Указывает, что кодек и параметры субтитров также должны быть скопированы из входных данных в выходные данные без повторного кодирования.mov_text– это распространенный кодек субтитров, используемый в файлах MP4/MOV. -
"metadata:s:s:0": f"language={subtitle_language}": Устанавливает метаданные языка для потока субтитров. Язык устанавливается в значение, хранящееся вsubtitle_language -
"metadata:s:s:0": f"title={subtitle_track_title}": Устанавливает метаданные заголовка для потока субтитров. Заголовок устанавливается в значение, хранящееся вsubtitle_track_title
Наконец, код вызывает метод ffmpeg.run(), передавая поток вывода в качестве параметра, чтобы добавить мягкие субтитры к видео и сохранить выходной видеофайл в корневом каталоге вашего проекта.
Добавьте следующий код вниз вашей функции add_subtitle_to_video():
Выделенный код будет выполняться, если булево значение soft_subtitle установлено в False, что указывает на необходимость добавить жесткие субтитры.
Если это так, сначала код вызывает метод ffmpeg.output() для создания объекта выходного потока с входным видеопотоком, именем выходного видеофайла и параметром vf=f"subtitles={subtitle_file}". Параметр vf означает “видеофильтр” и используется для применения фильтра к видеопотоку. В данном случае применяется фильтр добавления субтитров.
Наконец, код вызывает метод ffmpeg.run(), передавая выходной поток в качестве параметра для добавления жестких субтитров к видео и сохранения выходного видеофайла в корневом каталоге вашего проекта.
Добавьте следующий выделенный код в функцию run():
Выделенный код вызывает функцию add_subtitle_to_video() с параметром soft_subtitle, установленным в True, именем файла субтитров и языком субтитров для добавления мягких субтитров к копии входного видео.
Вернитесь в терминал и выполните следующую команду для запуска скрипта main.py:
После выполнения указанной выше команды будет сохранен выходной видеофайл с именем output-input.mp4 в корневом каталоге вашего проекта.
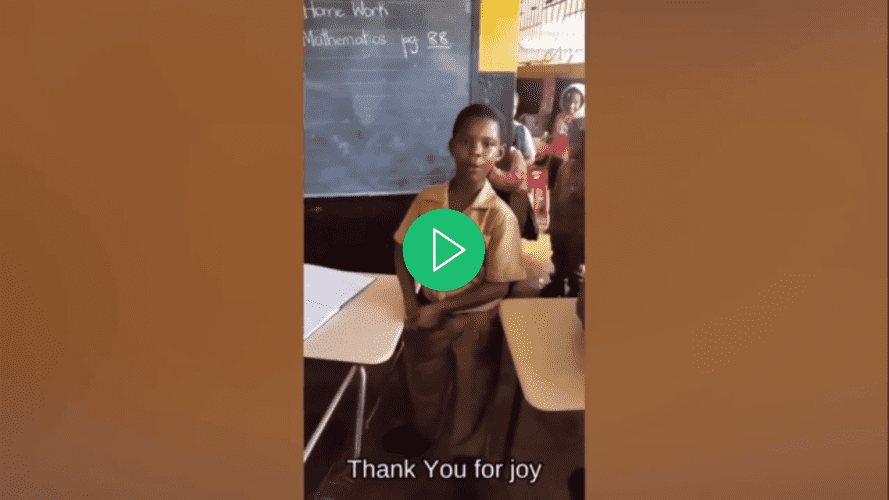
Откройте видео с помощью вашего предпочтительного видеоплеера, выберите субтитры для видео и обратите внимание, что субтитры не будут отображаться, пока вы их не выберете:
Вернитесь к файлу main.py, перейдите к функции run() и в вызове функции add_subtitle_to_video() установите параметр soft_subtitle в значение False:
Здесь вы устанавливаете параметр soft_subtitle в значение False, чтобы добавить жесткие субтитры к видео.
Вернитесь в ваш терминал и выполните следующую команду для запуска скрипта main.py:
После выполнения приведенной выше команды файл видео output-input.mp4, расположенный в корневом каталоге вашего проекта, будет перезаписан.
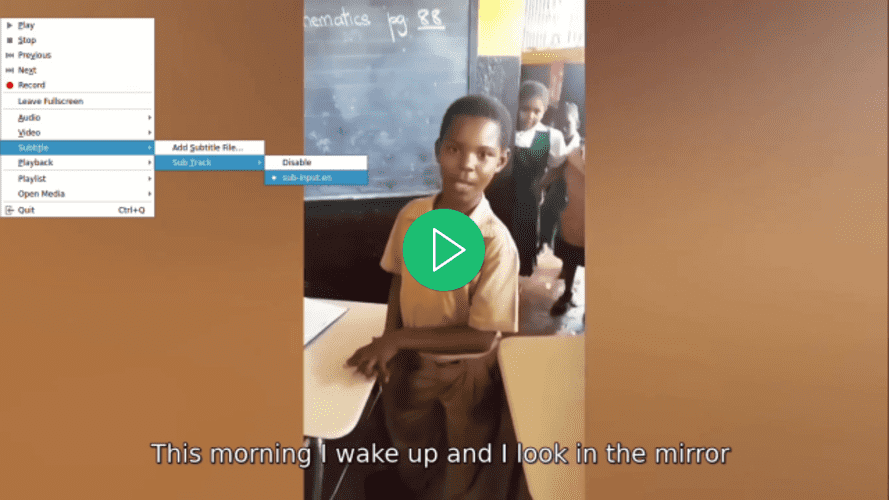
Откройте видео с помощью вашего предпочтительного видеоплеера, попробуйте выбрать субтитры для видео и обратите внимание, что они отсутствуют, хотя субтитры уже отображаются:

В этом разделе вы получили понимание структуры файла субтитров SRT и использовали сегменты транскрипции из предыдущего раздела, чтобы создать его. Затем была использована библиотека ffmpeg-python для добавления сгенерированного файла субтитров к видео.
Заключение
В этом уроке вы использовали библиотеки ffmpeg-python и faster-whisper на языке Python для создания приложения, способного извлекать аудио из входного видео, транскрибировать извлеченное аудио, генерировать файл субтитров на основе транскрипции и добавлять субтитры к копии входного видео.