













В ранние дни вычислений приложения обрабатывали задачи последовательно. С увеличением масштабов и миллионами пользователей этот подход стал непрактичным. Асинхронная обработка позволила обрабатывать несколько задач одновременно, но управление потоками/процессами на одном устройстве привело к ограничению ресурсов и сложности.
Здесь на помощь приходит распределенная параллельная обработка. Распределяя рабочую нагрузку между несколькими машинами, каждая из которых посвящена части задачи, она предлагает масштабируемое и эффективное решение. Если у вас есть функция для обработки большого пакета файлов, вы можете разделить рабочую нагрузку между несколькими машинами, чтобы обрабатывать файлы одновременно, а не обрабатывать их последовательно на одной машине. Кроме того, это улучшает производительность за счет объединения ресурсов и обеспечивает масштабируемость и отказоустойчивость. По мере увеличения требований вы можете добавлять больше машин для увеличения доступных ресурсов.
Создавать и запускать распределенные приложения в масштабе сложно, но существует несколько фреймворков и инструментов, которые могут помочь. В этом блоге мы рассмотрим один из таких фреймворков для распределенных вычислений с открытым исходным кодом: Ray. Мы также рассмотрим KubeRay, оператор Kubernetes, который обеспечивает бесшовную интеграцию Ray с кластерами Kubernetes для распределенных вычислений в облачных средах. Но прежде давайте поймем, где распределенный параллелизм помогает.
Где распределенная параллельная обработка помогает?
Любая задача, которая выигрывает от разделения своей нагрузки на несколько машин, может использовать распределенную параллельную обработку. Этот подход особенно полезен для таких сценариев, как обход веб-сайтов, анализ данных в большом масштабе, обучение моделей машинного обучения, обработка потоков реального времени, анализ геномных данных и видеорендеринг. Распределение задач по нескольким узлам значительно повышает производительность, сокращает время обработки и оптимизирует использование ресурсов, что делает его необходимым для приложений, требующих высокой производительности и быстрой обработки данных.
Когда Не Требуется Распределенная Параллельная Обработка
- Приложения малого масштаба: Для небольших наборов данных или приложений с минимальными требованиями к обработке издержки управления распределенной системой могут быть не оправданы.
- Сильные зависимости данных: Если задачи сильно взаимозависимы и не могут быть легко параллельно выполнены, распределенная обработка может принести мало пользы.
- Ограничения реального времени: Некоторые приложения реального времени (например, финансы и веб-сайты бронирования билетов) требуют крайне низкой задержки, которую может быть сложно достичь с добавленной сложностью распределенной системы.
- Ограниченные ресурсы: Если доступная инфраструктура не может поддержать издержки распределенной системы (например, недостаточная пропускная способность сети, ограниченное количество узлов), может быть лучше оптимизировать производительность одиночной машины.
Как Ray помогает с распределенной параллельной обработкой
Ray — это распределенная параллельная вычислительная платформа, которая объединяет все преимущества распределенных вычислений и решения обсуждаемых нами задач, таких как отказоустойчивость, масштабируемость, управление контекстом, связь и так далее. Это Python-ориентированная платформа, позволяющая использовать существующие библиотеки и системы для работы с ней. С помощью Ray программисту не нужно управлять частями слоя параллельной обработки данных. Ray позаботится о планировании и автоматическом масштабировании на основе заданных требований к ресурсам.
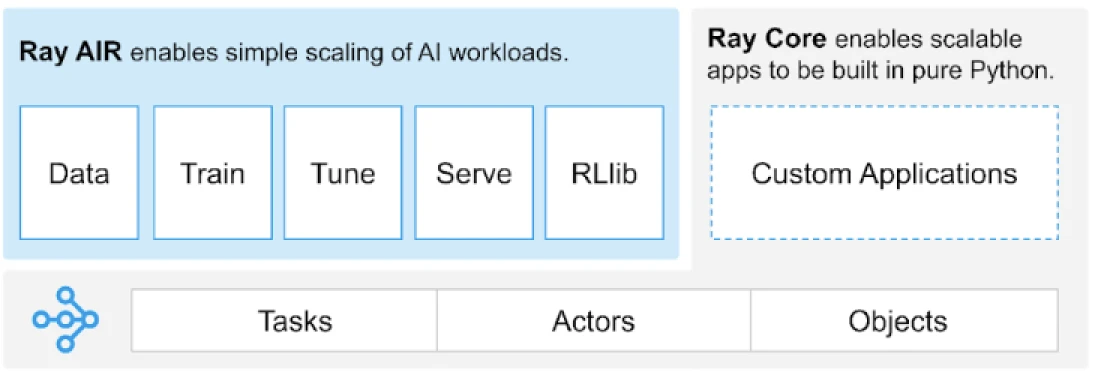
Ray предоставляет универсальный API для задач, актеров и объектов для создания распределенных приложений.
(Источник изображения)
Ray предоставляет набор библиотек, построенных на основных примитивах, т.е. Задачах, Актерах, Объектах, Драйверах и Заданиях. Эти библиотеки предлагают универсальный API, который помогает создавать распределенные приложения. Давайте рассмотрим основные примитивы, также известные как Ray Core.
Основные примитивы Ray
- Задачи: Задачи Ray – это произвольные функции Python, которые выполняются асинхронно на отдельных работниках Python в узле кластера Ray. Пользователи могут указывать свои требования к ресурсам в терминах ЦП, ГП и пользовательских ресурсов, которые используются планировщиком кластера для распределения задач для параллельного выполнения.
- Акторы: То, что задачи представляют собой функции, акторы представляют собой классы. Актор – это работник с состоянием, и методы актора планируются на этом конкретном работнике и могут получать доступ и изменять состояние этого работника. Как и задачи, акторы поддерживают требования к ресурсам ЦП, ГП и пользовательским ресурсам.
- Объекты: В Ray задачи и акторы создают и вычисляют объекты. Эти удаленные объекты могут храниться где угодно в кластере Ray. Ссылки на объекты используются для их обозначения, и они кэшируются в распределенном хранилище объектов общей памяти Ray.
- Драйверы: Корень программы, или «главная» программа: это код, который выполняет
ray.init() - Работы: Коллекция задач, объектов и акторов, происходящих (рекурсивно) от одного и того же драйвера и их рабочая среда
Для получения информации о примитивах вы можете обратиться к документации Ray Core.
Ключевые методы Ray Core
Ниже приведены некоторые из ключевых методов в Ray Core, которые часто используются:
-
ray.init()– Запустить время выполнения Ray и подключиться к кластеру Ray.import ray ray.init()
-
@ray.remote– Декоратор, который указывает, что функция или класс Python должны выполняться как задача (удаленная функция) или актер (удаленный класс) в другом процессе@ray.remote def remote_function(x): return x * 2
-
.remote– Постфикс для удаленных функций и классов; удаленные операции асинхронныresult_ref = remote_function.remote(10)
-
ray.put()– Поместите объект в хранилище объектов в памяти; возвращает ссылку на объект, используемую для передачи объекта в любую удаленную функцию или вызов метода.data = [1, 2, 3, 4, 5] data_ref = ray.put(data)
-
ray.get()– Получите удаленный объект(ы) из хранилища объектов, указав ссылку на объект(ы).result = ray.get(result_ref) original_data = ray.get(data_ref)
Вот пример использования большинства основных ключевых методов:
import ray
ray.init()
@ray.remote
def calculate_square(x):
return x * x
# Использование .remote для создания задачи
future = calculate_square.remote(5)
# Получение результата
result = ray.get(future)
print(f"The square of 5 is: {result}")Как работает Ray?
Кластер Ray похож на команду компьютеров, которые делятся работой по запуску программы. Он состоит из головного узла и нескольких рабочих узлов. Головной узел управляет состоянием кластера и планированием, в то время как рабочие узлы выполняют задачи и управляют акторами
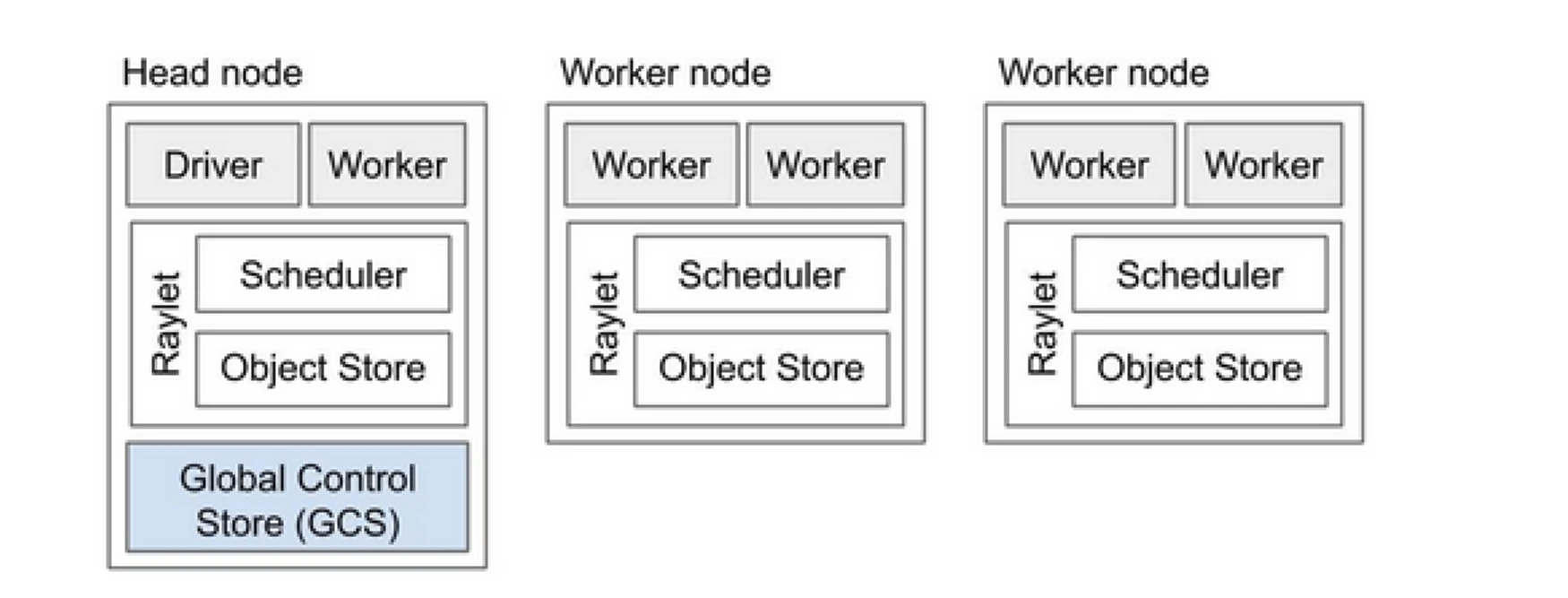
Компоненты кластера Ray
- Глобальное хранилище управления (GCS): GCS управляет метаданными и глобальным состоянием кластера Ray. Он отслеживает задачи, акторов и доступность ресурсов, обеспечивая консистентное представление системы на всех узлах.
- Планировщик: Планировщик распределяет задачи и акторов по доступным узлам. Он обеспечивает эффективное использование ресурсов и балансировку нагрузки, учитывая требования к ресурсам и зависимости задач.
- Головной узел: Головной узел оркестрирует весь кластер Ray. Он запускает GCS, обрабатывает планирование задач и контролирует состояние рабочих узлов.
- Рабочие узлы: Рабочие узлы выполняют задачи и акторов. Они осуществляют фактические вычисления и хранят объекты в своей локальной памяти.
- Raylet: Он управляет общими ресурсами на каждом узле и используется всеми одновременно выполняющимися заданиями.
Вы можете ознакомиться с документацией по архитектуре Ray v2 для получения более подробной информации.
Работа с существующими приложениями на Python не требует значительных изменений. Изменения будут в основном касаться функции или класса, которые необходимо естественным образом распределить. Вы можете добавить декоратор и преобразовать его в задачи или актеров. Давайте рассмотрим пример этого.
Преобразование функции Python в задачу Ray
# (Normal Python function)
def square(x):
return x * x
# Usage
results = []
for i in range(4):
result = square(i)
results.append(result)
print(results)
# Output: [0, 1, 4, 9]
# (Ray Implementation)
# Define the square task.
.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]
Преобразование класса Python в актера Ray
# (Regular Python class)
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create an instance of the Counter class
c = Counter()
# Call the incr method on the instance
for _ in range(10):
c.incr(1)
# Get the final state of the counter
print(c.get()) # Output: 10
# (Ray implementation in actor)
# Define the Counter actor.
.remote
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create a Counter actor.
c = Counter.remote()
# Submit calls to the actor. These
# calls run asynchronously but in
# submission order on the remote actor
# process.
for _ in range(10):
c.incr.remote(1)
# Retrieve final actor state.
print(ray.get(c.get.remote()))
# -> 10
Хранение информации в объектах Ray
import numpy as np
# (Regular Python function)
# Define a function that sums the values in a matrix
def sum_matrix(matrix):
return np.sum(matrix)
# Call the function with a literal argument value
print(sum_matrix(np.ones((100, 100)))) # Output: 10000.0
# Create a large array
matrix = np.ones((1000, 1000))
# Call the function with the large array
print(sum_matrix(matrix)) # Output: 1000000.0
# (Ray implementation of function)
import numpy as np
# Define a task that sums the values in a matrix.
.remote
def sum_matrix(matrix):
return np.sum(matrix)
# Call the task with a literal argument value.
print(ray.get(sum_matrix.remote(np.ones((100, 100)))))
# -> 10000.0
# Put a large array into the object store.
matrix_ref = ray.put(np.ones((1000, 1000)))
# Call the task with the object reference as argument.
print(ray.get(sum_matrix.remote(matrix_ref)))
# -> 1000000.0
Чтобы узнать больше о его концепции, перейдите в документацию Ключевая концепция Ray Core.
Ray против традиционного подхода к распределенной параллельной обработке
Ниже представлено сравнительное исследование традиционного (без Ray) подхода и Ray на Kubernetes для обеспечения распределенной параллельной обработки.
| Aspect | Traditional Approach | Ray on Kubernetes |
|---|---|---|
| Развертывание | Ручная настройка и конфигурация | Автоматизировано с помощью KubeRay Operator |
| Масштабирование | Ручное масштабирование | Автоматическое масштабирование с помощью RayAutoScaler и Kubernetes |
| Отказоустойчивость | Пользовательские механизмы отказоустойчивости | Встроенная отказоустойчивость с Kubernetes и Ray |
| Управление ресурсами | Ручное распределение ресурсов | Автоматизированное распределение и управление ресурсами |
| Балансировка нагрузки | Пользовательские решения для балансировки нагрузки | Встроенное балансирование нагрузки с Kubernetes |
| Управление зависимостями | Ручная установка зависимостей | Последовательная среда с контейнерами Docker |
| Координация кластера | Сложно и вручную | Упрощено с помощью обнаружения сервисов и координации Kubernetes |
| Дополнительные затраты на разработку | Высокие, требуются индивидуальные решения | Снижены, с Ray и Kubernetes, обрабатывающими многие аспекты |
| Гибкость | Ограниченная адаптивность к изменяющимся нагрузкам | Высокая гибкость с динамическим масштабированием и распределением ресурсов |
Kubernetes предоставляет идеальную платформу для запуска распределенных приложений, таких как Ray, благодаря своим мощным возможностям оркестрации. Ниже приведены ключевые моменты, которые подчеркивают ценность запуска Ray на Kubernetes:
- Управление ресурсами
- Масштабируемость
- Оркестрация
- Интеграция с экосистемой
- Легкое развертывание и управление
Оператор KubeRay позволяет запускать Ray на Kubernetes.
Что такое KubeRay?
Оператор KubeRay упрощает управление кластерами Ray на Kubernetes, автоматизируя такие задачи, как развертывание, масштабирование и обслуживание. Он использует пользовательские определения ресурсов Kubernetes (CRD) для управления ресурсами, специфичными для Ray.
CRD KubeRay
Он имеет три различных CRD:
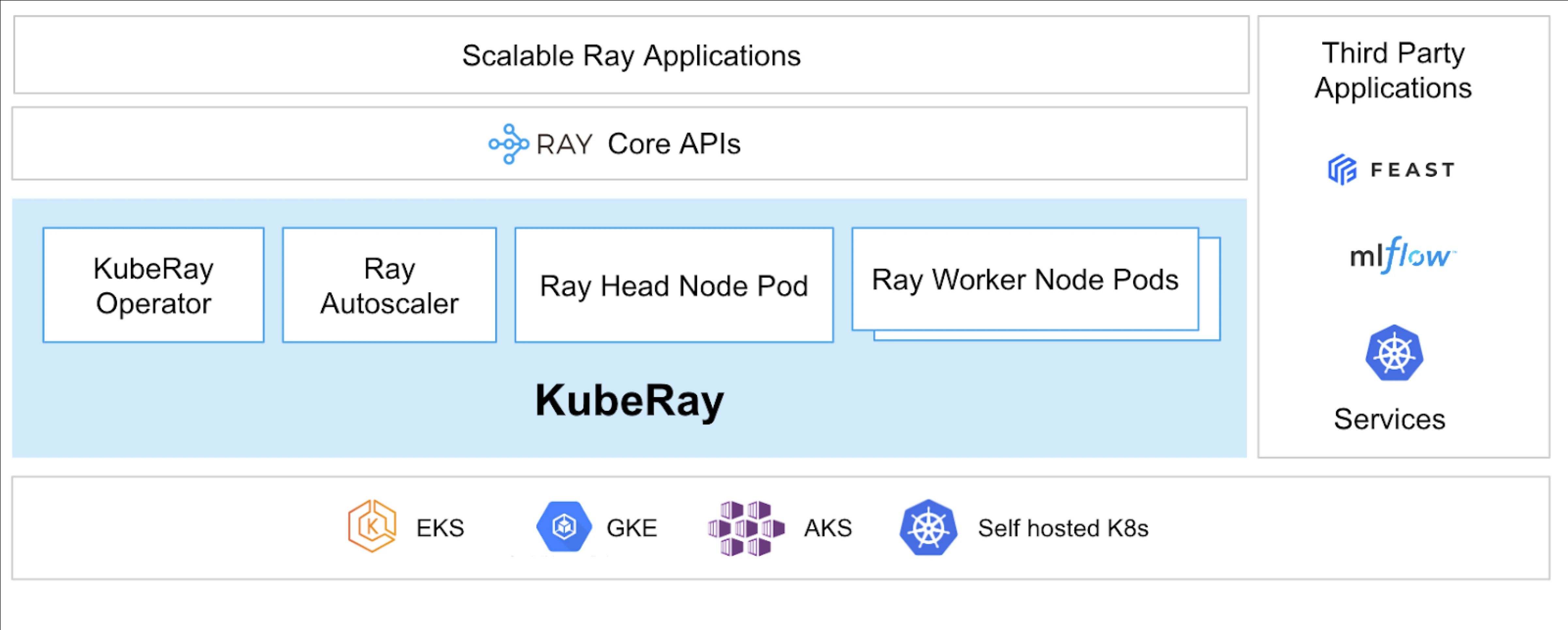
- RayCluster: Этот CRD помогает управлять жизненным циклом RayCluster и заботится об автоматическом масштабировании на основе заданной конфигурации.
- RayJob: Он полезен, когда есть одноразовая задача, которую вы хотите выполнить, вместо того чтобы постоянно поддерживать RayCluster в ожидании. Он создает RayCluster и отправляет задачу, когда она готова. После завершения задачи он удаляет RayCluster. Это помогает автоматически перерабатывать RayCluster.
- RayService: Он также создает RayCluster, но развертывает на нем приложение RayServe. Этот CRD позволяет выполнять обновления приложения на месте, обеспечивая безостановочные обновления и улучшения для обеспечения высокой доступности приложения.
Сценарии использования KubeRay
Развертывание модели по запросу с использованием RayService
RayService позволяет вам развертывать модели по запросу в среде Kubernetes. Это может быть особенно полезно для приложений, таких как генерация изображений или извлечение текста, где модели развертываются только по мере необходимости.
Вот пример стабильной диффузии. Как только он применяется в Kubernetes, он создаст RayCluster и также запустит RayService, который будет обслуживать модель, пока вы не удалите этот ресурс. Это позволяет пользователям контролировать ресурсы.
Обучение модели на кластере с использованием GPU с помощью RayJob
RayService предоставляет пользователю различные возможности, где модель или приложение развертываются до их ручного удаления. В отличие от этого, RayJob позволяет выполнять одноразовые задачи для таких случаев, как обучение модели, предварительная обработка данных или вывод для заданного числа заданий.
Запуск сервера вывода на Kubernetes с использованием RayService или RayJob
Обычно мы запускаем наше приложение в развертываниях, которые обеспечивают безотказное обновление с прокруткой. Аналогично в KubeRay это можно достичь с помощью RayService, который развертывает модель или приложение и обрабатывает безотказное обновление.
Однако могут быть случаи, когда вы просто хотите выполнить пакетный вывод вместо запуска серверов вывода или приложений на длительное время. В этом случае вы можете использовать RayJob, который аналогичен ресурсу задания Kubernetes.
Пакетный вывод классификации изображений с использованием Huggingface Vision Transformer является примером RayJob, который выполняет пакетный вывод.
Это примеры использования KubeRay, позволяющие вам сделать больше с кластером Kubernetes. С помощью KubeRay вы можете запускать смешанные нагрузки на одном и том же кластере Kubernetes и передавать планирование рабочей нагрузки, требующей использования графического процессора, Ray.
Заключение
Распределенная параллельная обработка предлагает масштабируемое решение для выполнения задач большого объема, требующих значительных ресурсов. Ray упрощает сложности создания распределенных приложений, в то время как KubeRay интегрирует Ray с Kubernetes для бесперебойного развертывания и масштабирования. Эта комбинация улучшает производительность, масштабируемость и отказоустойчивость, что делает её идеальной для веб-сканирования, анализа данных и задач машинного обучения. Используя Ray и KubeRay, вы можете эффективно управлять распределенными вычислениями, удовлетворяя потребности современного мира, основанного на данных, с легкостью.
Не только это, но и поскольку наши типы вычислительных ресурсов переходят от CPU к GPU, становится важным иметь эффективную и масштабируемую облачную инфраструктуру для всех видов приложений, будь то ИИ или обработка больших данных.
Если вам показалась эта статья информативной и увлекательной, мне было бы интересно услышать ваше мнение, поэтому начните обсуждение на LinkedIn.
Source:
https://dzone.com/articles/primer-on-distributed-parallel-processing-with-ray