













בימיו הראשונים של המחשוב, יישומים טיפלו במשימות באופן סדרתי. כאשר הסקאלה גדלה עם מיליוני משתמשים, גישה זו הפכה לבלתי מעשית. עיבוד אסינכרוני אפשר טיפול במגוון משימות במקביל, אך ניהול חוטים/תהליכים במכונה אחת הביא להגבלות במשאבים ולמורכבות.
כאן נכנס לתמונה עיבוד מקביל מבוזר. על ידי פיזור העומס על פני מכונות רבות, שכל אחת מהן מוקדשת לחלק מהמשימה, הוא מציע פתרון נרחב ויעיל. אם יש לך פונקציה לעבד אוסף גדול של קבצים, תוכל לחלק את העומס על פני מכונות רבות כדי לעבד קבצים במקביל במקום לטפל בהם בסדר. בנוסף, זה משפר את הביצועים על ידי ניצול משאבים משולבים ומספק גמישות ועמידות בפני תקלות. ככל שהדרישות גדלות, תוכל להוסיף מכונות נוספות כדי להגדיל את המשאבים הזמינים.
לבנות ולהפעיל יישומים מבוזרים בסקאלה זה אתגר, אך יש מספר מסגרות וכלים שיכולים לעזור לך. בפוסט בלוג זה, נבחן אחת כזו – מסגרת מחשוב מבוזרת בקוד פתוח: ריי. נבחן גם את קובראיי, מפעיל קוברנטיס שמאפשר אינטגרציה חלקה של ריי עם אשכולות קוברנטיס עבור מחשוב מבוזר בסביבות ענן-מקורי. אך קודם, נבין היכן עיבוד מקביל מבוזר מסייע.
איפה עיבוד מקביל מבוזר עוזר?
כל משימה שמקבלת תועלת מהפרדת העומס שלה בין מספר מכונות יכולה לנצל עיבוד מקביל מבוזר. גישה זו שימושית במיוחד בתרחישים כגון זחילת רשת, ניתוח נתונים בקנה מידה רחב, אימון מודלים של למידת מכונה, עיבוד זרמים בזמן אמת, ניתוח נתוני גנומיקה ו-rendering של וידאו. על ידי חלוקת המשימות בין מספר צמתים, עיבוד מקביל מבוזר משפר משמעותית את הביצועים, מפחית את זמן העיבוד ומאופטם את ניצול המשאבים, מה שהופך אותו חיוני ליישומים שדורשים קצב העברה גבוה וטיפול מהיר בנתונים.
מתי עיבוד מקביל מבוזר אינו נדרש
- יישומים בקנה מידה קטן: עבור קבוצות נתונים קטנות או יישומים עם דרישות עיבוד מינימליות, העומס של ניהול מערכת מבוזרת עשוי שלא להיות מוצדק.
- תלותיות נתונים חזקה: אם המשימות תלויות זו בזו מאוד ואינן יכולות להיות מקביליות בקלות, עיבוד מבוזר עשוי להציע תועלת מועטה.
- מגבלות בזמן אמת: כמה יישומים בזמן אמת (למשל, אתרי פיננסים והזמנת כרטיסים) דורשים השהיה נמוכה מאוד, שעשויה שלא להיות ניתנת להשגה עם המורכבות הנוספת של מערכת מבוזרת.
- משאבים מוגבלים: אם התשתית הזמינה אינה יכולה לתמוך בעומס של מערכת מבוזרת (למשל, רוחב פס רשת לא מספיק, מספר מוגבל של צמתים), עשוי להיות עדיף לאופטם את הביצועים של מכונה אחת.
איך ריי עוזר עם עיבוד מקביל מבוזר
Ray הוא פריימוורק לעיבוד מקביל מבוזר שמכסה את כל היתרונות של חישוב מבוזר ופתרונות לאתגרים שדנו בהם, כגון עמידות בפני תקלות, קידמה, ניהול הקשר, תקשורת, וכו'. זהו פריימוורק פיתוני, שמאפשר את השימוש בספריות והמערכות הקיימות לעבוד איתו. בעזרת Ray, מתכנת אינו צריך לטפל בחלקי שכבת החישוב המקביל. Ray יטפל בקידום ובהתאמה אוטומטית בהתאם לדרישות המשאבים המצוינות.
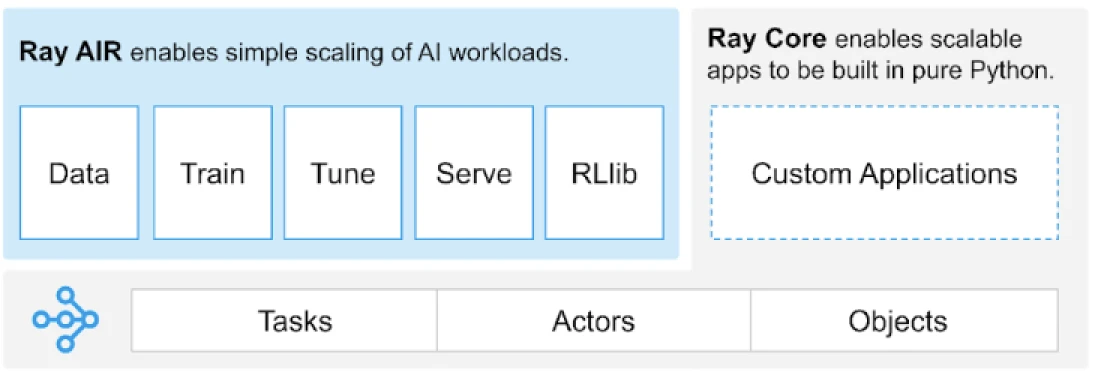
Ray מספק API אוניברסלי של משימות, שחקנים ואובייקטים לבניית יישומים מבוזרים.
(מקור התמונה)
Ray מספק סט של ספריות שנבנו על היסודות העיקריים, כלומר, משימות, שחקנים, אובייקטים, נהגים ועבודות. אלה מספקים API רב תכליתי לעזור בבניית יישומים מבוזרים. בואו נציץ ביסודות העיקריים, אחרת מוכני Ray.
יסודות Ray העיקריים
- משימות: משימות של Ray הן פונקציות פייתון שרצות באופן אסינכרוני על עובדים נפרדים של פייתון על צומת של קבוצת Ray. המשתמשים יכולים לציין את דרישות המשאבים שלהם במונחים של מעבדים, כרטיסי גרפיקה ומשאבים מותאמים אישית, אשר משמשים על ידי מתזמן הקבוצה כדי להפיץ משימות לביצוע במקביל.
- שחקנים: מה שמשימות הן לפונקציות, שחקנים הם למחלקות. שחקן הוא עובד עם מצב, והשיטות של שחקן מתוזמנות על אותו עובד ספציפי ויכולות לגשת ולשנות את מצב העובד. כמו משימות, שחקנים תומכים בדרישות משאבים של מעבדים, כרטיסי גרפיקה ומשאבים מותאמים אישית.
- אובייקטים: ב-Ray, משימות ושחקנים יוצרים ומחשבים אובייקטים. אובייקטים מרוחקים אלו יכולים להיות מאוחסנים בכל מקום בקבוצת Ray. הפניות לאובייקטים משמשות להתייחס אליהם, והן מאוחסנות בזיכרון המשותף המפוזר של Ray.
- דרייברים: שורש התוכנית, או התוכנית “הראשית”: זהו הקוד שרץ
ray.init() - עבודות: האוסף של משימות, אובייקטים ושחקנים שמקורם (באופן רקורסיבי) מאותו דרייבר וסביבת הריצה שלהם
למידע על פרימיטיבים, אתה יכול לעבור על התיעוד של Ray Core.
שיטות מפתח של Ray Core
להלן כמה מהשיטות המרכזיות בתוך Ray Core שמשתמשים בהן בדרך כלל:
-
ray.init()– התחל את זמן הריצה של Ray וחבר לקבוצת Ray.import ray ray.init()
-
@ray.remote– דקורטור שמציין פונקציה או מחלקה ב-Python שתבוצע כמשימה (פונקציה מרוחקת) או שחקן (מחלקה מרוחקת) בתהליך שונה@ray.remote def remote_function(x): return x * 2
-
.remote– סיומת לפונקציות ולמחלקות מרוחקות; פעולות מרוחקות הן אסינכרוניותresult_ref = remote_function.remote(10)
-
ray.put()– שמור אובייקט בחנות האובייקטים בזיכרון; מחזיר הפניה לאובייקט שמשמשת להעברת האובייקט לכל פונקציה או שיחת מתודה מרוחקת.data = [1, 2, 3, 4, 5] data_ref = ray.put(data)
-
ray.get()– קבל אובייקט(ים) מרוחק(ים) מחנות האובייקטים על ידי ציון הפניה(ות) לאובייקט.result = ray.get(result_ref) original_data = ray.get(data_ref)
הנה דוגמה לשימוש ברוב המתודות הבסיסיות:
import ray
ray.init()
@ray.remote
def calculate_square(x):
return x * x
# בשימוש ב-.remote כדי ליצור משימה
future = calculate_square.remote(5)
# קבל את התוצאה
result = ray.get(future)
print(f"The square of 5 is: {result}")כיצד Ray עובד?
אשכול Ray הוא כמו צוות של מחשבים שמשתפים את העבודה של הרצת תוכנית. הוא מורכב מצומת ראש ומספר רב של צמתי עובד. הצומת הראש מנהלת את מצב האשכול ואת הזמנת המשימות, בעוד שצמתי העובד בוצעים משימות ומנהלים את השחקן
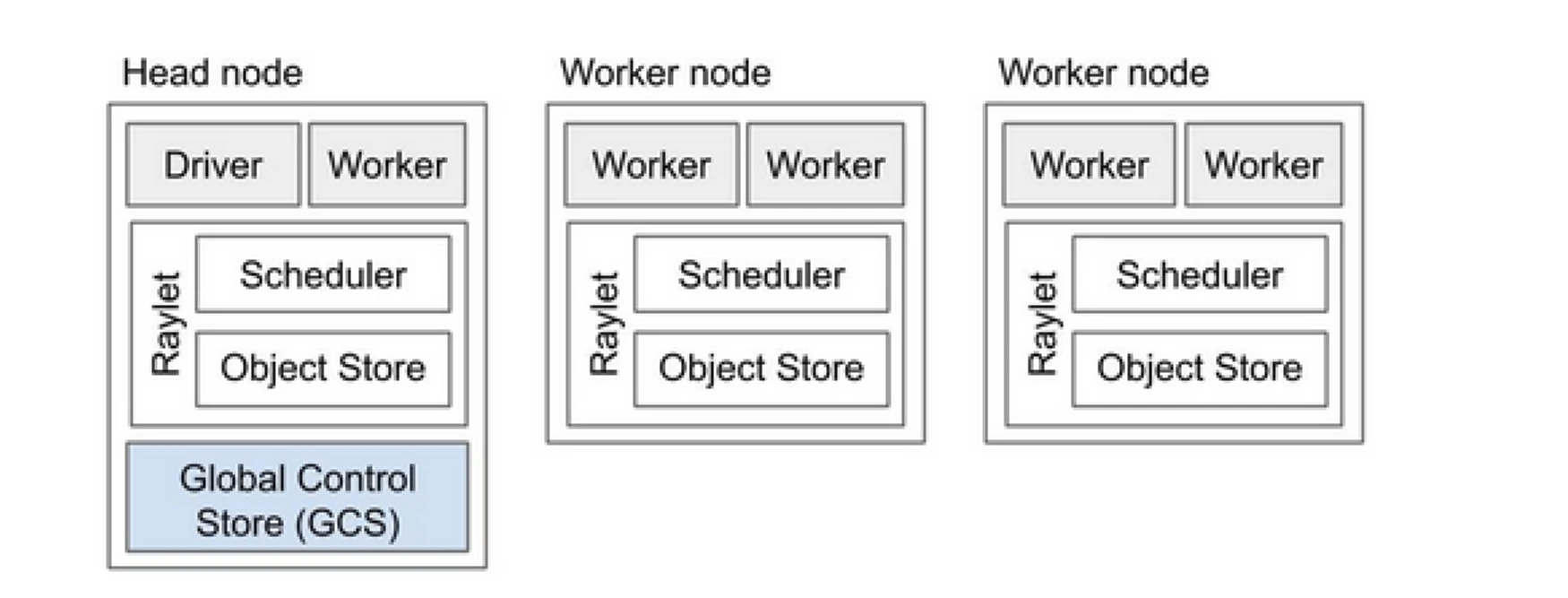
רכיבי אשכול Ray
- חנות שליטה גלובלית (GCS): ה-GCS נוהל את המטא-נתונים והמצב הגלובלי של אשכול Ray. הוא מעקב אחר המשימות, השחקנים וזמינות המשאבים, ומבטיח שכל הצמתים יש להם תצוגה עקבית של המערכת.
- מתזמן: המתזמן מפיץ משימות ושחקנים בין הצמתים הזמינים. הוא מבטיח שימוש יעיל במשאבים ואיזון עומס על ידי קידום דרישות המשאבים והתלות במשימה.
- צומת ראש: הצמת הראש מופעל את כל האשכול Ray. הוא מפעיל את ה-GCS, טופל בקידום המשימות ומנטר את מצבם של צמתי העובד.
- צמתי עובד: צמתי עובד בוצעים משימות ושחקנים. הם מבצעים את החישובים הממשיים ושומרים אובייקטים בזיכרון המקומי שלהם.
- ריילט: הוא מנהל משאבים משותפים בכל צומת ושיתף בכל המשימות שרצות בו במקביל.
ניתן לבדוק את מסמך ארכיטקטורת Ray v2 למידע מפורט יותר.
לעבודה עם יישומי פייתון קיימים לא נדרשות הרבה שינויים. השינויים הנדרשים יהיו בעיקר סביב הפונקציה או המחלקה שצריכה להיות מופצת באופן טבעי. אפשר להוסיף דקורטור ולהמיר אותה למשימות או שחקנים. בואו נסתכל על דוגמה לכך.
המרת פונקציית פייתון למשימת ריי
# (Normal Python function)
def square(x):
return x * x
# Usage
results = []
for i in range(4):
result = square(i)
results.append(result)
print(results)
# Output: [0, 1, 4, 9]
# (Ray Implementation)
# Define the square task.
.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]
המרת מחלקת פייתון לשחקן ריי
# (Regular Python class)
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create an instance of the Counter class
c = Counter()
# Call the incr method on the instance
for _ in range(10):
c.incr(1)
# Get the final state of the counter
print(c.get()) # Output: 10
# (Ray implementation in actor)
# Define the Counter actor.
.remote
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create a Counter actor.
c = Counter.remote()
# Submit calls to the actor. These
# calls run asynchronously but in
# submission order on the remote actor
# process.
for _ in range(10):
c.incr.remote(1)
# Retrieve final actor state.
print(ray.get(c.get.remote()))
# -> 10
אחסון מידע באובייקטי ריי
import numpy as np
# (Regular Python function)
# Define a function that sums the values in a matrix
def sum_matrix(matrix):
return np.sum(matrix)
# Call the function with a literal argument value
print(sum_matrix(np.ones((100, 100)))) # Output: 10000.0
# Create a large array
matrix = np.ones((1000, 1000))
# Call the function with the large array
print(sum_matrix(matrix)) # Output: 1000000.0
# (Ray implementation of function)
import numpy as np
# Define a task that sums the values in a matrix.
.remote
def sum_matrix(matrix):
return np.sum(matrix)
# Call the task with a literal argument value.
print(ray.get(sum_matrix.remote(np.ones((100, 100)))))
# -> 10000.0
# Put a large array into the object store.
matrix_ref = ray.put(np.ones((1000, 1000)))
# Call the task with the object reference as argument.
print(ray.get(sum_matrix.remote(matrix_ref)))
# -> 1000000.0
כדי ללמוד יותר על המושג הזה, פנו ל-עקרון מפתח של ריי במסמכים.
ריי מול גישה מסורתית של עיבוד מקביל מבוזר
להלן ניתוח השוואתי בין הגישה המסורתית (ללא ריי) לבין ריי על קוברנטיס כדי לאפשר עיבוד מקביל מבוזר.
| Aspect | Traditional Approach | Ray on Kubernetes |
|---|---|---|
| פריסה | התקנה והגדרה ידנית | אוטומטית עם KubeRay Operator |
| הגדלה | הגדלה ידנית | הגדלה אוטומטית עם RayAutoScaler וקוברנטיס |
| עמידות בפני תקלות | מנגנוני עמידות בפני תקלות מותאמים אישית | עמידות מובנית בפני תקלות עם קוברנטיס וריי |
| ניהול משאבים | הקצאת משאבים ידנית | הקצאת משאבים וניהול אוטומטיים |
| איזון עומסים | פתרונות איזון עומסים מותאמים אישית | טעינה מובנית עם Kubernetes |
| ניהול תלות | התקנת תלות ידנית | סביבה עקבית עם תופעלי Docker |
| תיאום אשכול | מורכב וידני | נפשר עם גילוי שירות ותיאום של Kubernetes |
| עלות פיתוח | גבוהה, עם צורך בפתרונות מותאמים | מופחתת, עם Ray ו-Kubernetes טופלים רבות מזרזי ההיבטים |
| גמישות | סימוכון מוגבל לשינויים בעומס עבודה | גמישות גבוהה עם התאמה דינמית והקצאת משאבים |
Kubernetes מספק פלטפורמה אידיאלית להפעלת אפליקציות מבוזרות כמו Ray בגלל יכולות האורכסטרציה הגבוהות שלה. להלן הנקודות העיקריות שמאיצות את הערך בהפעלת Ray על Kubernetes:
- ניהול משאבים
- קידמה
- אורכסטרציה
- אינטגרציה עם האקוסיסטמה
- הפעלה וניהול קל
המפעיל KubeRay מאפשר להפעיל את Ray על Kubernetes.
מהו KubeRay?
ה־KubeRay Operator פשוט מנהל אשכולות Ray על Kubernetes על ידי אוטומציה של משימות כגון הפצה, קידום ותחזוקה. הוא משתמש בהגדרות משאבים מותאמות ב-Kubernetes (CRDs) לניהול משאבים ספציפיים של Ray.
CRDs של KubeRay
יש לו שלושה CRDs ייחודיים:
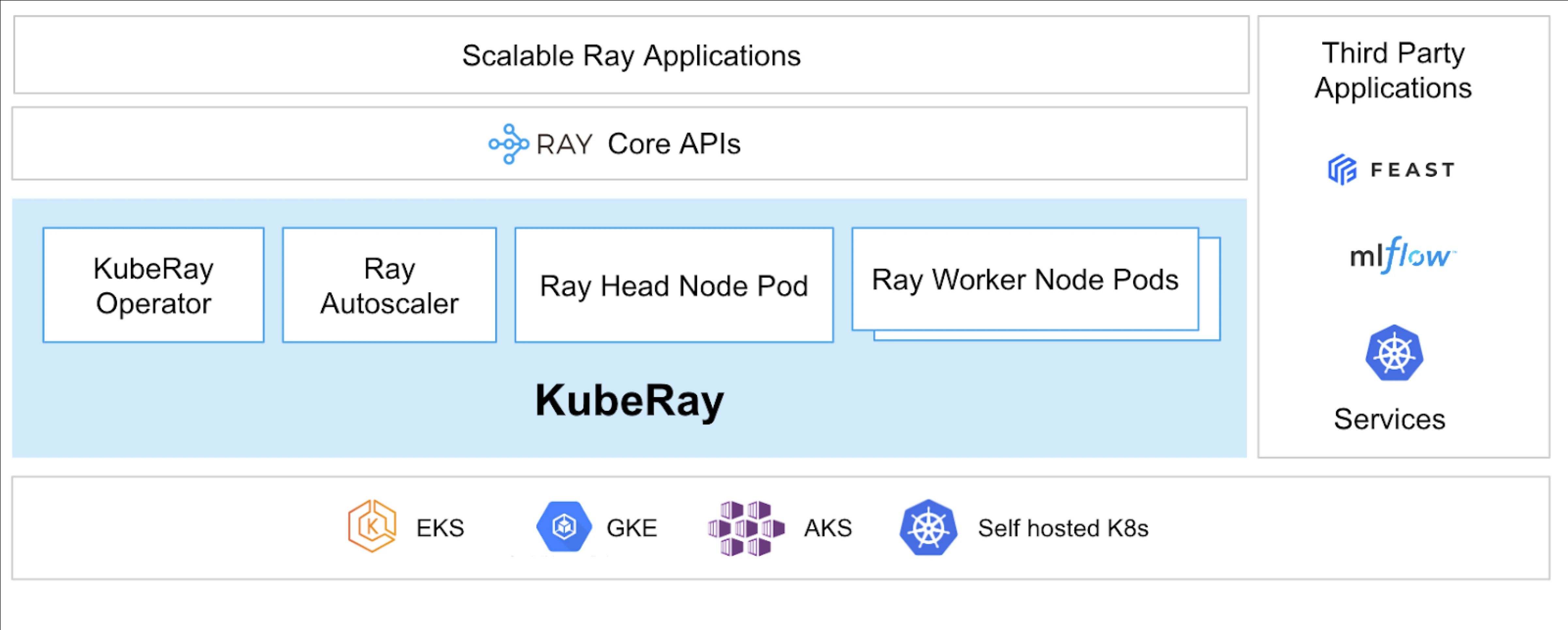
- RayCluster: CRD זה עוזר לנהל את מחזור חיי ה-RayCluster ודואג לאוטו-סקיילינג בהתבסס על ההגדרה המוגדרת.
- RayJob: זה שימושי כאשר יש עבודה חד-פעמית שאתה רוצה להריץ במקום להשאיר RayCluster במצב המתנה כל הזמן. זה יוצר RayCluster ומגיש את העבודה כאשר הוא מוכן. ברגע שהעבודה הסתיימה, הוא מוחק את ה-RayCluster. זה עוזר למחזור אוטומטי של ה-RayCluster.
- RayService: זה גם יוצר RayCluster אבל מפעיל אפליקציית RayServe עליו. CRD זה מאפשר לבצע עדכונים במקום לאפליקציה, מה שמספק שדרוגים ועדכונים ללא השבתה כדי להבטיח זמינות גבוהה של האפליקציה.
מקרי שימוש של KubeRay
פריסת מודל לפי דרישה באמצעות RayService
RayService מאפשר לך לפרוס מודלים לפי דרישה בסביבת Kubernetes. זה יכול להיות במיוחד מועיל לאפליקציות כמו יצירת תמונות או חילוץ טקסט, שבהן מודלים מוחזקים רק כאשר נדרשים.
הנה דוגמה לדיפוזיה יציבה. ברגע שזה מוחל ב-Kubernetes, זה ייצור RayCluster וגם יריץ RayService, שיגיש את המודל עד שתמחק את המשאב הזה. זה מאפשר למשתמשים לשלוט במשאבים.
הכשרת מודל על אשכול GPU באמצעות RayJob
RayService מתאימה לדרישות שונות של משתמשים, שבהן היא שומרת על המודל או היישום המוצג עד שהם נמחקים ידנית. לעומת זאת, RayJob מאפשר עבודות חד פעמיות למקרים שימוש כמו הכשרת מודל, עיבוד נתונים מראש או הסקה עבור מספר קבוע של מצוות נתונים מסוימים.
הפעלת שרת ההסקה על Kubernetes באמצעות RayService או RayJob
בדרך כלל, אנו מריצים את היישום שלנו באמצעות פרסומים, ששומרים על עדכונים מתמידים ללא הפסקה. באותה דרך, ב-KubeRay אפשר להשיג זאת באמצעות RayService, שמפרסם את המודל או היישום ומתייחס לעדכונים מתמידים.
אם כי ייתכן ותהיה למקרים בהם תרצה פשוט לבצע הסקה צפופה במקום הפעלת שרתי ההסקה או היישומים לזמן רב. זהו המקום בו באפשרותך להשתמש ב-RayJob, שדומה למשאב העבודה של Kubernetes.
הסקת דפוסי תמונה באצווה ראייתית של Huggingface הוא דוגמה ל-RayJob, שמבצע הסקת צפופות.
אלו הם מקרי השימוש של KubeRay, המאפשרים לך לבצע יותר עם אשכול Kubernetes. בעזרת KubeRay תוכל להריץ עומסי עבודה מעורבים על אותו אשכול Kubernetes ולהעביר לתזמון עומסי עבודה המבוססים על GPU אל Ray.
מסקנה
עיבוד מבוזר מקביל מציע פתרון המתאים לטיפול במשימות בגודל גדול וממוקדות במשאבים. Ray פשוט את הקומפלקסיות שבבניית אפליקציות מבוזרות, בעוד ש-KubeRay משלב את Ray עם Kubernetes לפיתוח והרצה מתמידה והרצת לכל מקום. השילוב הזה משפר ביצועים, סקאלביליות ועמידות בפני תקלות, ועשוי להיות אידיאלי לטיפול באינטרנט, בנתונים ובמשימות למידת מכונה. על ידי השקעת משאבים ב-Ray וב-KubeRay, ניתן לנהל ביצועי חישוב מבוזרים ביעילות, ולעמוד בדרישות העולם המבוסס על נתונים של היום בקלות.
לא רק זאת, אלא גם עם שינוי סוגי המשאבים שלנו ממעבד CPU למבוסס GPU, חשוב לקיים תשתית ענן יעילה וסקאלבילית למגוון רחב של אפליקציות, בין אם זה בתחום המודלים המופשטים או בעיבוד נתונים גדול.
אם נתקלת בפוסט זה ונהנית ממנו, אשמח לשמוע את דעתך עליו, ולפתוח שיחה ב-LinkedIn.
Source:
https://dzone.com/articles/primer-on-distributed-parallel-processing-with-ray