













在计算机的早期阶段,应用程序按顺序处理任务。随着用户规模的增长,这种方法变得不切实际。异步处理允许同时处理多个任务,但在单台机器上管理线程/进程会导致资源限制和复杂性。
这就是分布式并行处理的作用。通过将工作负载分散到多台机器上,每台机器专门处理任务的一部分,它提供了可扩展和高效的解决方案。如果您有一个处理大批量文件的函数,您可以将工作负载分配给多台机器,以并发处理文件,而不是在一台机器上按顺序处理它们。此外,它通过利用合并资源来提高性能,并提供可扩展性和容错性。随着需求的增加,您可以添加更多机器以增加可用资源。
在大规模上构建和运行分布式应用程序是具有挑战性的,但有几个框架和工具可以帮助您。在这篇博文中,我们将介绍一个开源的分布式计算框架:Ray。我们还将介绍KubeRay,这是一个Kubernetes运算符,它可以在云原生环境中实现Ray与Kubernetes集群的无缝集成,用于分布式计算。但首先,让我们了解一下分布式并行处理在哪些方面有帮助。
分布式并行处理在哪些方面有帮助?
任何从跨多台机器分配工作负载中受益的任务都可以利用分布式并行处理。这种方法在诸如网络爬虫、大规模数据分析、机器学习模型训练、实时流处理、基因组数据分析和视频渲染等场景中特别有用。通过在多个节点之间分配任务,分布式并行处理显著提升了性能,缩短了处理时间,并优化了资源利用,使其成为需要高吞吐量和快速数据处理的应用程序必不可少的部分。
当分布式并行处理不需要时
- 小规模应用:对于小数据集或处理要求较低的应用程序来说,管理分布式系统的开销可能无法证明其必要性。
- 数据依赖性强:如果任务高度相互依赖且不易并行化,分布式处理可能带来的好处有限。
- 实时约束:一些实时应用(例如金融和订票网站)需要极低的延迟,而加入分布式系统的复杂性可能无法实现这一要求。
- 资源有限:如果可用基础设施无法支持分布式系统的开销(例如网络带宽不足、节点数量有限),优化单机性能可能更加明智。
Ray 如何帮助分布式并行处理
Ray 是一个分布式并行处理框架,封装了分布式计算的所有优点和我们讨论过的挑战的解决方案,如容错、可扩展性、上下文管理、通信等。它是一个 Pythonic框架,允许使用现有的库和系统与之协作。在 Ray 的帮助下,程序员无需处理并行处理计算层的各个部分。Ray 将根据指定的资源需求负责调度和自动扩展。
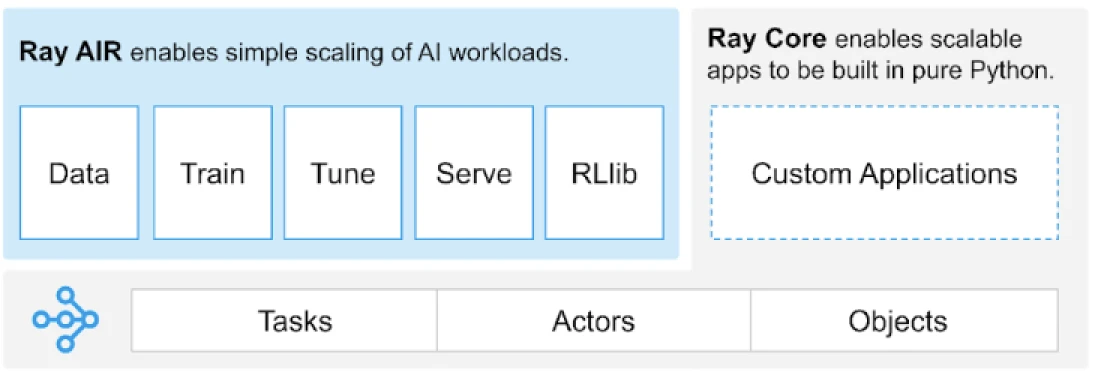
Ray 提供了一个通用的任务、演员和对象 API,用于构建分布式应用程序。
(图片来源)
Ray 提供了一套建立在核心原语上的库,即任务、演员、对象、驱动程序和作业。这些提供了一个多功能的 API,帮助构建分布式应用程序。让我们来看看核心原语,也就是 Ray Core。
Ray Core 原语
- 任务:Ray 任务是在 Ray 集群节点上异步执行的任意 Python 函数。用户可以根据需要指定它们的 CPU、GPU 和自定义资源需求,集群调度程序将使用这些需求来分发任务以实现并行执行。
- 演员:就像任务对应函数一样,演员对应类。演员是有状态的工作者,演员的方法被调度到特定的工作者上,并且可以访问和修改该工作者的状态。与任务类似,演员也支持 CPU、GPU 和自定义资源需求。
- 对象:在 Ray 中,任务和演员创建和计算对象。这些远程对象可以存储在 Ray 集群中的任何位置。对象引用用于引用它们,并且它们被缓存在 Ray 的分布式共享内存对象存储中。
- 驱动程序:程序的根部,或者称为“主”程序:这是运行
ray.init()的代码。 - 作业:源自同一驱动程序及其运行时环境的任务、对象和演员的集合(递归)。
有关基本原语的信息,您可以查看 Ray 核心文档。
Ray 核心关键方法
以下是 Ray 核心中常用的一些关键方法:
-
ray.init()– 启动 Ray 运行时并连接到 Ray 集群。import ray
ray.init()
-
@ray.remote– 装饰器,用于指定 Python 函数或类在不同进程中作为任务(远程函数)或演员(远程类)执行@ray.remote def remote_function(x): return x * 2
-
.remote– 远程函数和类的后缀;远程操作是异步的result_ref = remote_function.remote(10)
-
ray.put()– 将对象放入内存对象存储中;返回一个对象引用,用于将对象传递给任何远程函数或方法调用。data = [1, 2, 3, 4, 5] data_ref = ray.put(data)
-
ray.get()– 通过指定对象引用从对象存储中获取远程对象。result = ray.get(result_ref) original_data = ray.get(data_ref)
以下是使用大多数基本关键方法的示例:
import ray
ray.init()
@ray.remote
def calculate_square(x):
return x * x
# 使用 .remote 创建一个任务
future = calculate_square.remote(5)
# 获取结果
result = ray.get(future)
print(f"The square of 5 is: {result}")Ray 是如何工作的?
Ray 集群就像是一个共同运行程序任务的计算机团队。它包括一个主节点和多个工作节点。主节点负责管理集群状态和调度,而工作节点执行任务并管理 actor。
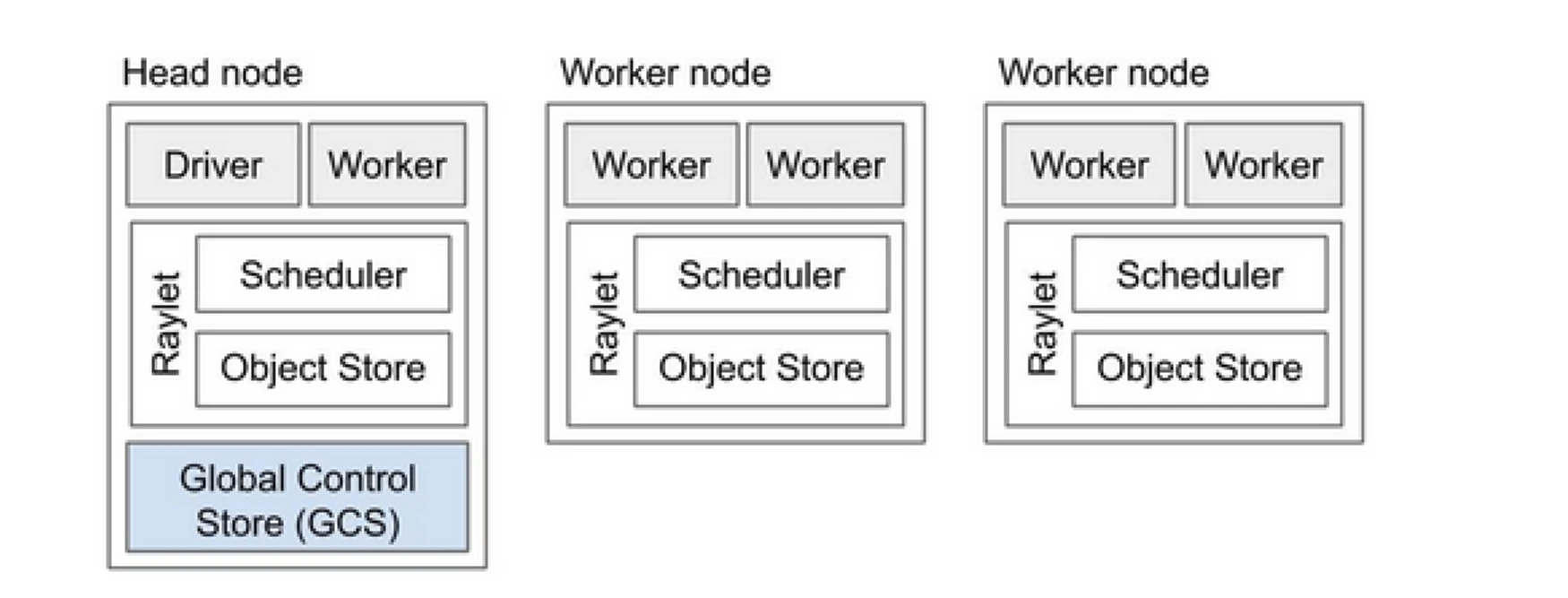
Ray 集群组件
- 全局控制存储(GCS):GCS 管理 Ray 集群的元数据和全局状态。它跟踪任务、actor 和资源可用性,确保所有节点对系统有一致的视图。
- 调度器:调度器将任务和 actor 分发到可用节点。它通过考虑资源需求和任务依赖关系来确保资源利用效率和负载平衡。
- 主节点:主节点协调整个 Ray 集群。它运行 GCS,处理任务调度,并监控工作节点的健康状态。
- 工作节点:工作节点执行任务和 actor。它们执行实际的计算并将对象存储在本地内存中。
- Raylet:Raylet 在每个节点上管理共享资源,并在所有并发运行的作业之间共享。
您可以查看 Ray v2 架构文档获取更详细的信息。
与现有的Python应用程序合作并不需要太多更改。所需的更改主要集中在需要自然分发的函数或类上。您可以添加一个装饰器,将其转换为任务或演员。让我们看一个例子。
将Python函数转换为Ray任务
# (Normal Python function)
def square(x):
return x * x
# Usage
results = []
for i in range(4):
result = square(i)
results.append(result)
print(results)
# Output: [0, 1, 4, 9]
# (Ray Implementation)
# Define the square task.
.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]
将Python类转换为Ray演员
# (Regular Python class)
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create an instance of the Counter class
c = Counter()
# Call the incr method on the instance
for _ in range(10):
c.incr(1)
# Get the final state of the counter
print(c.get()) # Output: 10
# (Ray implementation in actor)
# Define the Counter actor.
.remote
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create a Counter actor.
c = Counter.remote()
# Submit calls to the actor. These
# calls run asynchronously but in
# submission order on the remote actor
# process.
for _ in range(10):
c.incr.remote(1)
# Retrieve final actor state.
print(ray.get(c.get.remote()))
# -> 10
在Ray对象中存储信息
import numpy as np
# (Regular Python function)
# Define a function that sums the values in a matrix
def sum_matrix(matrix):
return np.sum(matrix)
# Call the function with a literal argument value
print(sum_matrix(np.ones((100, 100)))) # Output: 10000.0
# Create a large array
matrix = np.ones((1000, 1000))
# Call the function with the large array
print(sum_matrix(matrix)) # Output: 1000000.0
# (Ray implementation of function)
import numpy as np
# Define a task that sums the values in a matrix.
.remote
def sum_matrix(matrix):
return np.sum(matrix)
# Call the task with a literal argument value.
print(ray.get(sum_matrix.remote(np.ones((100, 100)))))
# -> 10000.0
# Put a large array into the object store.
matrix_ref = ray.put(np.ones((1000, 1000)))
# Call the task with the object reference as argument.
print(ray.get(sum_matrix.remote(matrix_ref)))
# -> 1000000.0
要了解更多关于其概念的信息,请访问 Ray Core Key Concept 文档。
Ray与传统分布式并行处理方法的比较
以下是传统(不使用Ray)方法与在Kubernetes上使用Ray进行分布式并行处理的比较分析。
| Aspect | Traditional Approach | Ray on Kubernetes |
|---|---|---|
| 部署 | 手动设置和配置 | 使用KubeRay Operator自动化 |
| 扩展 | 手动扩展 | 使用RayAutoScaler和Kubernetes自动扩展 |
| 容错 | 自定义容错机制 | 与Kubernetes和Ray内置的容错机制 |
| 资源管理 | 手动资源分配 | 自动化资源分配和管理 |
| 负载均衡 | 自定义负载均衡解决方案 | 内置负载均衡与Kubernetes |
| 依赖管理 | 手动依赖安装 | 与Docker容器一致的环境 |
| 集群协调 | 复杂且手动 | 通过Kubernetes服务发现和协调简化 |
| 开发开销 | 高,需要定制解决方案 | 减少,Ray和Kubernetes处理许多方面 |
| 灵活性 | 对变化工作负载的适应性有限 | 具高灵活性,支持动态扩展和资源分配 |
Kubernetes为运行像Ray这样的分布式应用程序提供了理想平台,因其强大的编排能力。以下是运行Ray在Kubernetes上的关键要点:
- 资源管理
- 可扩展性
- 编排
- 与生态系统的集成
- 简化的部署和管理
KubeRay Operator使在Kubernetes上运行Ray成为可能。
什么是KubeRay?
KubeRay Operator通过自动化部署、扩展和维护等任务,简化了在Kubernetes上管理Ray集群的过程。它使用Kubernetes自定义资源定义(CRDs)来管理Ray特定资源。
KubeRay CRDs
它有三个不同的CRD:
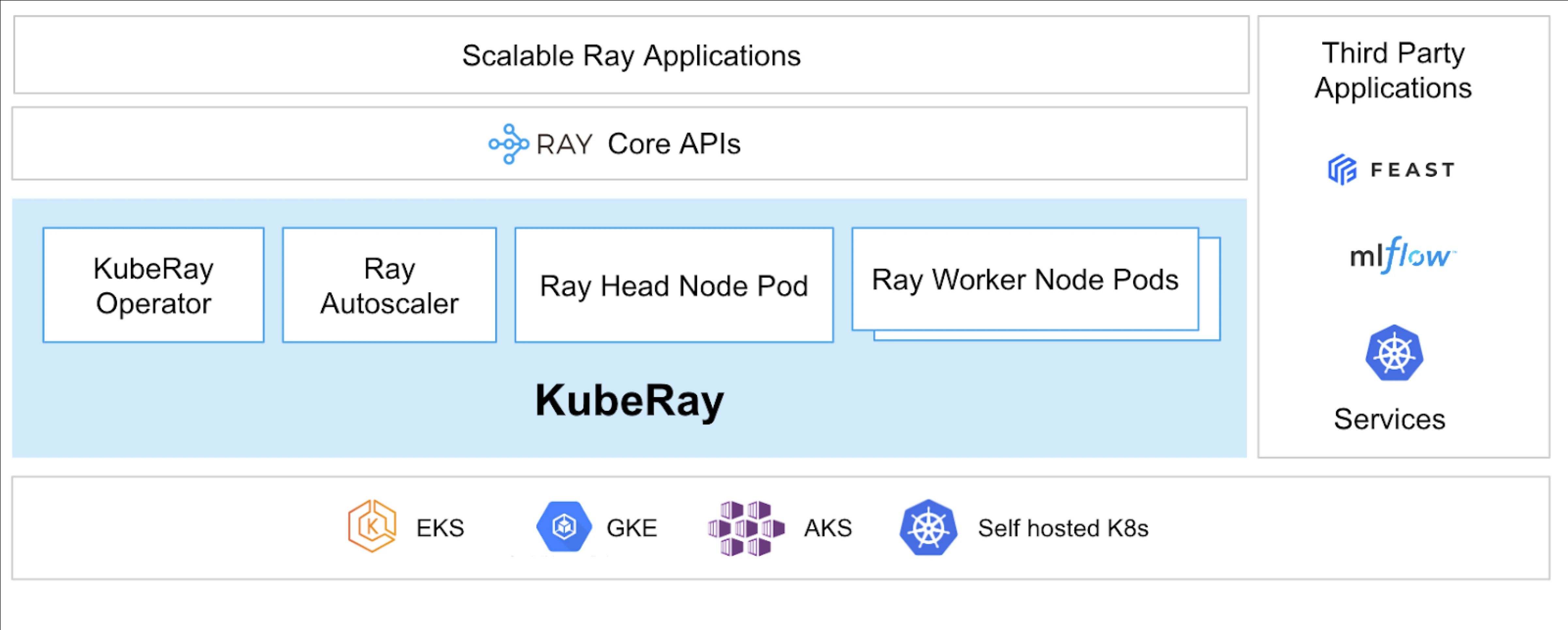
- RayCluster:该CRD有助于管理RayCluster的生命周期,并根据定义的配置负责自动扩展。
- RayJob:当您想要运行一次性作业而不是始终保持待命的RayCluster时,这很有用。它创建一个RayCluster,并在准备就绪时提交作业。作业完成后,它会删除RayCluster。这有助于自动回收RayCluster。
- RayService:它也创建一个RayCluster,但在其上部署一个RayServe应用程序。这个CRD使得可以对应用程序进行就地更新,提供零停机升级和更新,确保应用程序的高可用性。
KubeRay的用例
使用RayService部署按需模型
RayService允许您在Kubernetes环境中按需部署模型。这对于诸如图像生成或文本提取等应用特别有用,其中模型仅在需要时部署。
这里是一个稳定扩散的例子。一旦在Kubernetes中应用它,它将创建RayCluster并运行RayService,直到您删除此资源为止,RayService将为模型提供服务。它允许用户掌控资源。
在GPU集群上使用RayJob训练模型
RayService满足用户的不同需求,它会在模型或应用程序被手动删除之前持续保持部署状态。相比之下,RayJob允许用于一次性作业的场景,例如训练模型、预处理数据或对固定数量的给定提示进行推理。
在Kubernetes上使用RayService或RayJob运行推理服务器
通常,我们在部署中运行应用程序,这样可以在不停机的情况下进行滚动更新。同样,在KubeRay中,可以使用RayService实现这一点,它部署模型或应用程序并处理滚动更新。
然而,可能会有一些情况,你只是想进行批量推理,而不是长时间运行推理服务器或应用程序。这时,你可以利用RayJob,它类似于Kubernetes的Job资源。
使用Huggingface Vision Transformer进行图像分类批量推理是一个RayJob的例子,它执行批量推理。
这些是KubeRay的使用案例,使你能够在Kubernetes集群上做更多事情。借助KubeRay,你可以在同一个Kubernetes集群上运行混合工作负载,并将基于GPU的工作负载调度卸载到Ray。
结论
分布式并行处理为处理大规模、资源密集型任务提供了可扩展的解决方案。Ray 简化了构建分布式应用程序的复杂性,而 KubeRay 将 Ray 与 Kubernetes 集成,实现无缝的部署和扩展。这种组合增强了性能、可扩展性和容错能力,使其非常适合网络爬虫、数据分析和机器学习任务。通过利用 Ray 和 KubeRay,您可以高效管理分布式计算,轻松满足当今数据驱动世界的需求。
不仅如此,随着我们的计算资源类型从 CPU 转变为基于 GPU 的,拥有高效且可扩展的云基础设施变得至关重要,无论是用于人工智能还是大数据处理。
如果您觉得这篇文章信息丰富且引人入胜,我很想听听您对这篇文章的看法,请在 LinkedIn 上开始讨论。
Source:
https://dzone.com/articles/primer-on-distributed-parallel-processing-with-ray