













Организации начинают внедрение потоковых данных с одного кластера Apache Kafka для развертывания первых использований. Потребность в общегрупповом управлении данными и безопасности, но с различными SLA, задержкой и потребностями в инфраструктуре, приводит к созданию новых кластеров Kafka. Несколько кластеров Kafka – это норма, а не исключение. Сценарии использования включают гибридную интеграцию, агрегацию, миграцию и аварийное восстановление. В этом блоге рассматриваются реальные истории успеха и стратегии кластеров для различных развертываний Kafka в различных отраслях.

Apache Kafka: Фактический стандарт для архитектур событийного управления и потоков данных
Apache Kafka – это платформа распределенного потокового событийного потокового потокового потокового потокового потокового потокового потокового потокового потокового потокового потокового потокового потокового потокового потокового потокового потокового потокового потокового потокового потокового потока…
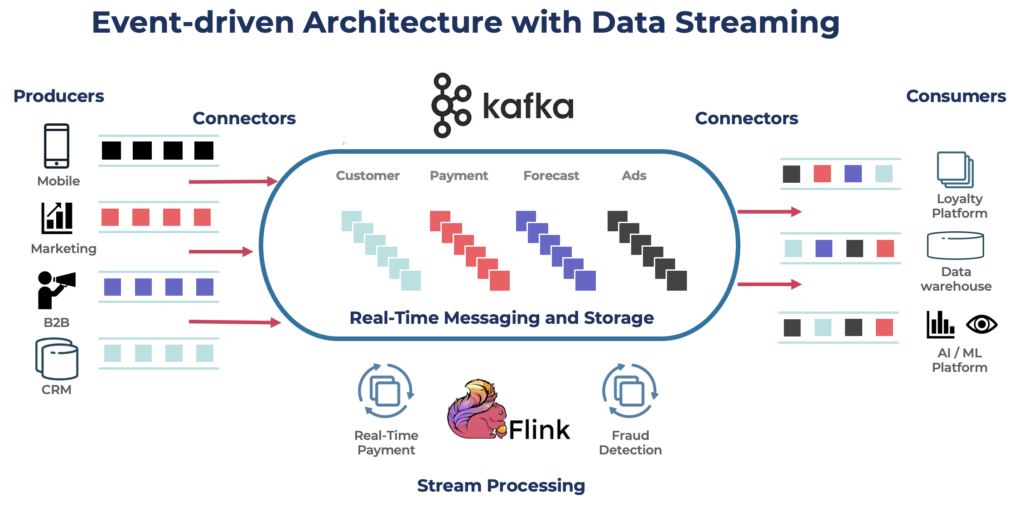
Kafka является популярным выбором для построения потоков данных в реальном времени и потоковых приложений. Протокол Kafka стал де-факто стандартом для потоковой передачи событий в различных фреймворках, решениях и облачных сервисах. Он поддерживает операционные и аналитические нагрузки с такими функциями, как постоянное хранилище, масштабируемость и отказоустойчивость. Kafka включает компоненты, такие как Kafka Connect для интеграции и Kafka Streams для обработки потоков, что делает его универсальным инструментом для различных сценариев использования, основанных на данных.
Хотя Kafka известен своими сценариями использования в реальном времени, многие проекты используют платформу потоковой передачи данных для обеспечения согласованности данных по всей архитектуре предприятия, включая базы данных, озера данных, устаревшие системы, открытые API и облачные приложения.
Различные типы кластеров Apache Kafka
Kafka является распределенной системой. Производственная настройка обычно требует как минимум четырех брокеров. Поэтому большинство людей автоматически предполагают, что все, что вам нужно, это один распределенный кластер, который вы масштабируете, когда добавляете пропускную способность и сценарии использования. Это не неправильно в начале. Но…
Один кластер Kafka не является правильным ответом для каждого сценария использования. На архитектуру кластера Kafka влияют различные характеристики:
- Доступность: Нулевое время простоя? SLA 99,99% времени безотказной работы? Некритическая аналитика?
- Задержка: Обработка от начала до конца в <100 мс (включая обработку)? 10-минутный конвейер хранилища данных от начала до конца? Путешествие во времени для повторной обработки исторических событий?
- Стоимость: Соотношение цены и стоимости? Общая стоимость владения имеет значение. Например, в общедоступном облаке сетевые расходы могут составлять до 80% общей стоимости Kafka!
- Безопасность и Конфиденциальность Данных: Конфиденциальность данных (данные PCI, GDPR и т. д.)? Управление данными и соответствие? Конечное шифрование на уровне атрибутов? Использование собственного ключа? Общий доступ к данным и обмен данными? Отсоединенная от сети среда края?
- Производительность и Размер Данных: Критические транзакции (обычно низкий объем)? Потоки больших данных (щелчки, датчики Интернета вещей, журналы безопасности и т. д.)?
Связанные темы, такие как локальное облако по сравнению с общедоступным, региональное по сравнению с глобальным, и многие другие требования также влияют на архитектуру Kafka.
Стратегии и Архитектуры Кластера Apache Kafka
Один кластер Kafka часто является правильной отправной точкой для вашего потока данных. Он может принимать на борт несколько случаев использования из разных бизнес-доменов и обрабатывать гигабайты данных в секунду (если работает и масштабируется правильным образом).
Однако, в зависимости от требований вашего проекта, вам понадобится предприятий архитектура с несколькими кластерами Kafka. Вот несколько распространенных примеров:
- Гибридная архитектура: Интеграция данных и одно- или двусторонняя синхронизация данных между несколькими центрами обработки данных. Часто это соединение между локальным центром обработки данных и облачным поставщиком услуг. Один из наиболее распространенных сценариев – перенос данных с устаревших систем в облачную аналитику. Однако также возможно управление и контроль, например, передача решений/рекомендаций/транзакций в региональное окружение (например, сохранение платежа или заказа из мобильного приложения в главной системе).
- Мультирегиональность/Мультиоблачность: Репликация данных по соображениям соответствия, экономии или конфиденциальности данных. Обычно обмен данных включает лишь часть событий, а не все темы Kafka. Здравоохранение – лишь одна из многих отраслей, идущих по этому пути.
- Восстановление после катастрофы: Репликация критических данных в активном-активном или активном-пассивном режиме между различными центрами обработки данных или облачными регионами. Включает стратегии и инструменты для переключения и обратного восстановления в случае катастрофы для обеспечения бизнес-непрерывности и соответствия требованиям.
- Агрегация: Региональные кластеры для локальной обработки (например, предварительная обработка, потоковое ETL, бизнес-приложения для обработки потоков) и репликация отобранных данных в крупный центр обработки данных или облако. Розничные магазины – отличный пример.
- Миграция: Модернизация ИТ с переходом с локальной инфраструктуры в облако или с самостоятельного управления открытым исходным кодом к полностью управляемому SaaS. Такие миграции могут быть выполнены без простоев или потерь данных при продолжении работы бизнеса во время перехода.
- Edge (Disconnected/Air-Gapped): Безопасность, стоимость или задержка требуют развертывания на краю, например, в заводе или розничном магазине. Некоторые отрасли размещают их в условиях повышенной безопасности с помощью одностороннего аппаратного шлюза и диода данных.
- Single Broker: Неустойчив, но достаточен для сценариев, таких как встраивание брокера Kafka в машину или на промышленный компьютер (IPC) и репликация агрегированных данных в кластер аналитики облака Kafka. Один из примеров — установка потоков данных (включая интеграцию и обработку) на компьютере солдата на поле боя.
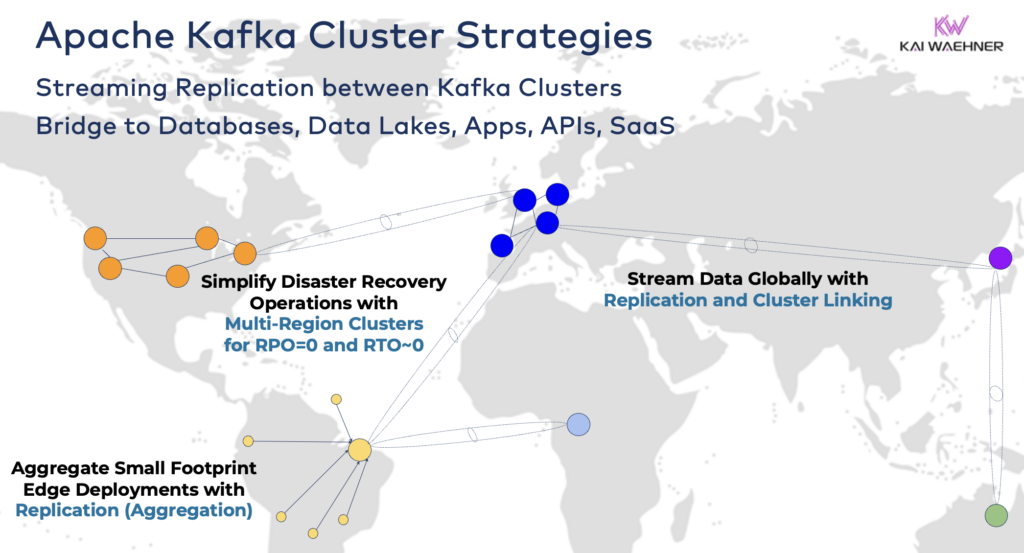
Соединение гибридных кластеров Kafka
Эти варианты могут быть объединены. Например, один брокер на краю обычно реплицирует некоторые отобранные данные в удаленный дата-центр. Гибридные кластеры имеют различные архитектуры в зависимости от того, как они соединены: соединения через общедоступный Интернет, частный канал, сопряжение VPC, транзитный шлюз и т. д.
Видя развитие Confluent Cloud за годы, я недооценил, сколько инженерного времени нужно потратить на безопасность и подключение. Однако отсутствие защитных мостов является основным препятствием для принятия облачного сервиса Kafka. Таким образом, необходимо обеспечить различные защитные мосты между кластерами Kafka за пределами общедоступного Интернета.
Есть даже случаи использования, когда организациям необходимо реплицировать данные из центра обработки данных в облако, но облачному сервису нельзя инициировать соединение. Confluent создал специальную функцию “инициированная источником связь” для таких требований безопасности, где источник (т.е. кластер Kafka на месте) всегда инициирует соединение – даже если облачные кластеры Kafka потребляют данные:
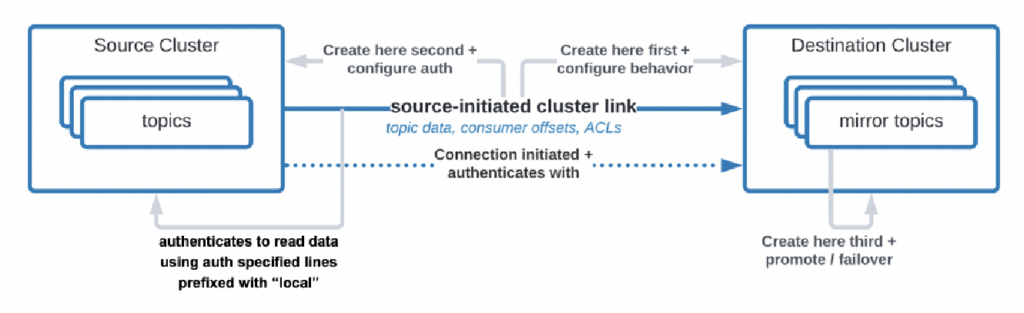 Источник: Confluent
Источник: Confluent
Как видите, это быстро усложняется. Найдите правильных экспертов, чтобы помочь вам с самого начала, не после того, как вы уже развернули первые кластеры и приложения.
Давным-давно я уже описывал в подробной презентации архитектурные шаблоны для распределенных, гибридных, ребрендовых и глобальных развертываний Apache Kafka. Посмотрите этот слайд и видеозапись для получения более подробной информации о вариантах развертывания и компромиссах.
RPO против RTO = Потери данных против Время простоя
RPO и RTO – два критических КПЭ, о которых необходимо обсудить перед принятием решения о стратегии кластера Kafka:
- RPO (Recovery Point Objective) – это максимально допустимая потеря данных, измеряемая во времени, указывающая на то, как часто необходимо выполнять резервное копирование для минимизации потерь данных.
- Время восстановления (RTO) – это максимально приемлемая длительность времени, необходимая для восстановления бизнес-операций после нарушения. Вместе они помогают организациям планировать свои стратегии резервного копирования данных и восстановления после катастрофы для балансировки затрат и операционного воздействия.
Часто люди начинают с цели RPO = 0 и RTO = 0, но быстро понимают, насколько это сложно (но не невозможно). Вам нужно решить, сколько данных вы можете потерять в случае катастрофы. Вам нужен план восстановления после катастрофы, если случится беда. Юридические и команды по соблюдению стандартов должны сказать вам, можно ли потерять несколько наборов данных в случае катастрофы или нет. Эти и многие другие проблемы должны быть обсуждены при оценке вашей стратегии кластера Kafka.
Репликация между кластерами Kafka с использованием инструментов типа MIrrorMaker или Cluster Linking является асинхронной, и RPO > 0. Только растянутый кластер Kafka обеспечивает RPO = 0.
Растянутый кластер Kafka: Нулевая потеря данных с синхронной репликацией между центрами обработки данных
Большинство развертываний с несколькими кластерами Kafka используют асинхронную репликацию между центрами обработки данных или облаками с помощью инструментов типа MirrorMaker или Confluent Cluster Linking. Этого достаточно для большинства сценариев использования. Но в случае катастрофы вы теряете несколько сообщений. RPO > 0.
Растянутый кластер Kafka разворачивает брокеры Kafka одного кластера в трех центрах обработки данных. Репликация синхронная (поскольку именно так Kafka реплицирует данные в рамках одного кластера) и гарантирует нулевую потерю данных (RPO = 0) – даже в случае катастрофы!
Почему не стоит всегда использовать растянутые кластеры?
- Требуется низкая задержка (<~50мс) и стабильное соединение между центрами обработки данных.
- Необходимы три (!) центра обработки данных; двух недостаточно, так как большинство (кворум) должно подтверждать записи и чтения для обеспечения надежности системы.
- Их сложно настраивать, обслуживать и контролировать, гораздо сложнее, чем кластер, работающий в одном центре обработки данных.
- Соотношение стоимости и ценности во многих случаях не оправдывает затрат; в случае реального катастрофического события у большинства организаций и вариантов использования возникают более серьезные проблемы, чем потеря нескольких сообщений (даже если это критические данные, такие как платеж или заказ).
Чтобы быть ясным, в общедоступном облаке обычно есть три центра обработки данных (= зоны доступности). Следовательно, в облаке это зависит от ваших SLA, считается ли один облачный регион растянутым кластером или нет. Большинство предложений SaaS Kafka развертываются в растянутом кластере здесь.
Однако многие сценарии соответствия не считают кластер Kafka в одном облачном регионе достаточно хорошим для обеспечения SLA и бизнес-непрерывности в случае катастрофы.
Confluent создал специальный продукт для решения (некоторых) этих проблем: Многорегиональные кластеры (MRC). Он предоставляет возможности для синхронной и асинхронной репликации в рамках растянутого кластера Kafka.
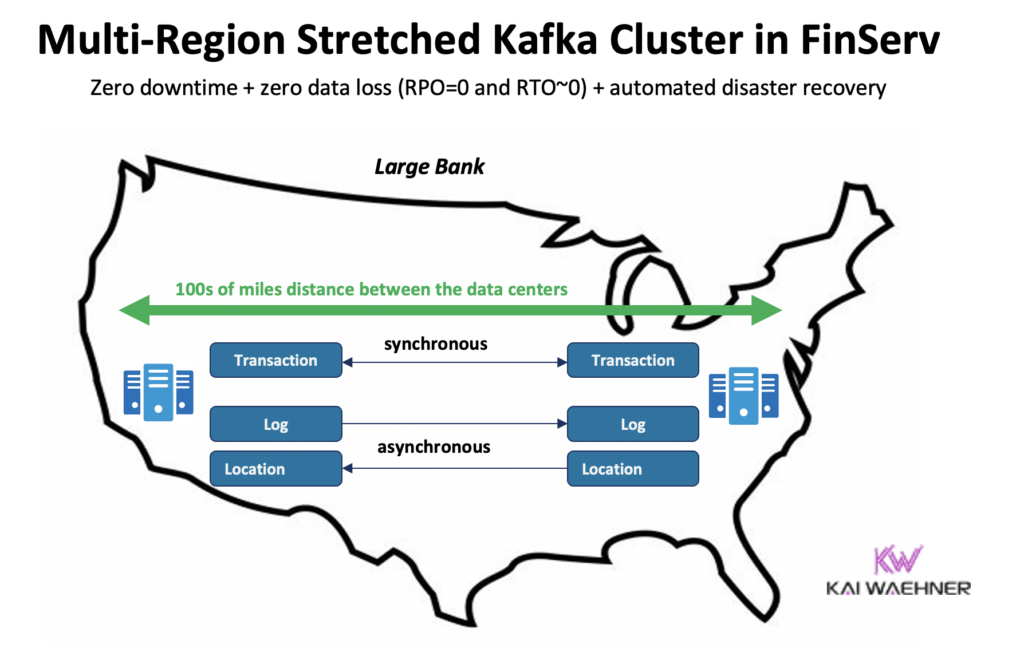
Например, в сценарии финансовых услуг MRC реплицирует низкочастотные критические транзакции синхронно, но журналы высокой частоты асинхронно:
- Обрабатывает транзакции “Платеж” поступающие из США Восток и США Запад с полностью синхронной репликацией
- Информация о “Журнале” и “Местоположении” в одном кластере использует асинхронный режим – оптимизирован для задержек
- Автоматизированный бизнес-план аварийного восстановления (нулевое время простоя, нулевая потеря данных)
Более подробную информацию о растянутых кластерах Kafka по сравнению с активным-активным / активным-пассивным воспроизведением между двумя кластерами Kafka можно найти в моей презентации о глобальной Kafka.
Ценообразование облачных предложений Kafka (по сравнению с самостоятельным управлением)
Вышеуказанные разделы поясняют, почему вам следует учитывать различные архитектуры Kafka в зависимости от требований вашего проекта. Самостоятельно управляемые кластеры Kafka могут быть настроены так, как вам необходимо. В общественном облаке полностью управляемые предложения выглядят иначе (так же, как любое другое полностью управляемое ПО как услуга). Ценообразование отличается, потому что поставщики ПО как услуга должны настроить разумные ограничения. Поставщик должен предоставить конкретные SLA.
Ландшафт потоковой передачи данных включает различные облачные предложения Kafka. Вот пример текущих облачных предложений Confluent, включая многопользовательские и выделенные среды с различными SLA, функциями безопасности и моделями стоимости.
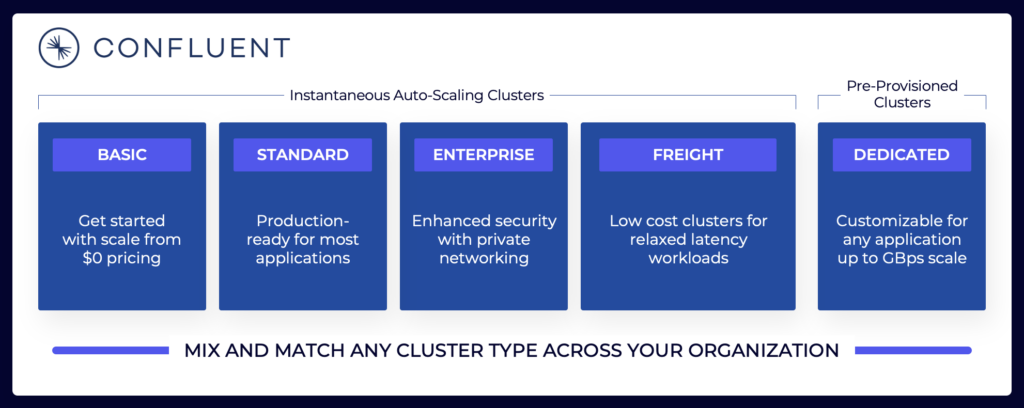 Источник: Confluent
Источник: Confluent
Убедитесь в том, что вы оценили и понимаете различные типы кластеров от разных поставщиков, доступные в общедоступном облаке, включая общую стоимость владения, гарантии времени работы, стоимость репликации между регионами или облачными поставщиками и так далее. Пробелы и ограничения часто намеренно скрываются в деталях.
Например, если вы используете Amazon Managed Streaming для Apache Kafka (MSK), вы должны знать, что в условиях указано, что “Обязательства по обслуживанию не распространяются на недоступность, приостановку или прекращение … вызванные базовым программным обеспечением движка Apache Kafka или Apache Zookeeper, приводящие к сбоям запросов.”
Однако ценообразование и гарантии поддержки – это только один критический аспект сравнения. Существует множество“решений по вопросу “создать или купить”, которые вам нужно принять в рамках оценки платформы потоковых данных.
Хранение Kafka: Ленточное хранение и формат таблицы Iceberg для однократного хранения данных
Apache Kafka добавил Уровневое хранение для разделения вычислений и хранения. Эта возможность обеспечивает более масштабируемые, надежные и экономичные корпоративные архитектуры. Уровневое хранение для Kafka позволяет создавать новый тип кластера Kafka: хранение петабайтов данных в журнале фиксации Kafka способом, экономичным с точки зрения затрат (как в вашем хранилище данных), с метками времени и гарантированным порядком для возврата во времени для повторной обработки исторических данных. KOR Financial – хороший пример использования Apache Kafka в качестве базы данных для долгосрочного хранения.
Kafka позволяет создавать архитектуру Shift Left для хранения данных только один раз для операционных и аналитических наборов данных:

Имея это в виду, еще раз подумайте о сценариях использования, описанных мной выше, для нескольких кластеров Kafka. Следует ли вам все еще реплицировать данные пакетно в базе данных, хранилище данных или lakehouse из одного центра обработки данных или облака в другой? Нет. Вам следует синхронизировать данные в реальном времени, хранить данные один раз (обычно в объектном хранилище, например, Amazon S3), а затем подключать все аналитические движки, такие как Snowflake, Databricks, Amazon Athena, Google Cloud BigQuery и т. д., к этому стандартному формату таблицы.
Успешные кейсы использования нескольких кластеров Kafka в реальном мире
У большинства организаций есть несколько кластеров Kafka. В этом разделе рассматриваются четыре успешных кейса в различных отраслях:
- Paypal (Финансовые услуги) – США: Мгновенные платежи, предотвращение мошенничества.
- JioCinema (Telco/Media) – APAC: Интеграция данных, аналитика кликов, реклама, персонализация.
- Audi (Автомобильное/Производственное производство) – EMEA: Связанные автомобили с критическими и аналитическими требованиями.
- New Relic (Программное обеспечение/Облачные технологии) – США: Наблюдаемость и управление производительностью приложений (APM) во всем мире.
Paypal: Разделение по зонам безопасности
PayPal – это цифровая платежная платформа, которая позволяет пользователям отправлять и получать деньги онлайн безопасно и удобно по всему миру в реальном времени. Для этого необходима масштабируемая, безопасная и соответствующая требованиям Кафка инфраструктура.
Во время черной пятницы 2022 года объем трафика в Кафке достигал около 1,3 триллиона сообщений в день. В настоящее время у PayPal более 85 кластеров Kafka, и каждый праздничный сезон они увеличивают свою инфраструктуру Kafka для обработки всплеска трафика. Платформа Kafka продолжает масштабироваться без какого-либо влияния на бизнес, чтобы поддержать этот рост трафика.
Сегодня флот Kafka PayPal состоит из более чем 1 500 брокеров, которые хранят более 20 000 тем. События реплицируются между кластерами, обеспечивая доступность 99,99%.
Развертывание кластеров Kafka разделено на различные зоны безопасности внутри дата-центра:
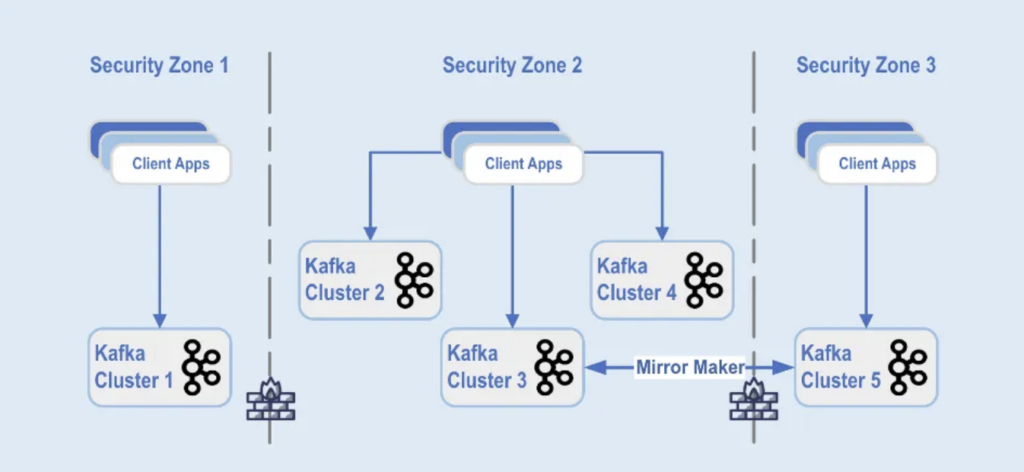 Источник: Paypal
Источник: Paypal
Кластеры Kafka развернуты в пределах этих зон безопасности в зависимости от классификации данных и бизнес-требований. Для зеркалирования данных между центрами обработки данных используется средство реального времени, такое как MirrorMaker (в данном примере, запущенный на инфраструктуре Kafka Connect) или Confluent Cluster Linking (используя более простой и менее подверженный ошибкам подход, напрямую используя протокол Kafka для зеркалирования), что помогает при восстановлении после катастрофы и обеспечивает коммуникацию между зонами безопасности.
JioCinema: Разделение по сценариям использования и SLA
JioCinema – быстрорастущая платформа видеостриминга в Индии. Телекоммуникационный сервис OTT известен своим обширным контентом, включая прямые трансляции спортивных событий, таких как Индийская Премьер-лига (IPL) по крикету, недавно запущенный Anime Hub и комплексные планы по охвату крупных событий, таких как Олимпийские игры в Париже 2024 года.
Архитектура данных использует Apache Kafka, Flink и Spark для обработки данных, как было представлено на Саммите Kafka в Индии 2024 года в Бангалоре:
 Источник: JioCinema
Источник: JioCinema
Потоковая передача данных играет ключевую роль в различных сценариях использования для трансформации пользовательских впечатлений и доставки контента. Более десяти миллионов сообщений в секунду улучшают аналитику, понимание пользователей и механизмы доставки контента.
Сценарии использования JioCinema включают:
- Межсервисное взаимодействие
- Кликстрим/аналитика
- Трекер рекламы
- Машинное обучение и персонализация
Кушал Кхандельвал, руководитель платформы данных, аналитики и потребления в JioCinema, пояснил, что не все данные равнозначны, и приоритеты и SLA различаются в зависимости от сценария использования:
 Источник: JioCinema
Источник: JioCinema
Потоковая передача данных – это путь. Как и многие другие организации по всему миру, JioCinema начала с одного крупного кластера Kafka с использованием 1000+ тем Kafka и 100 000+ разделов Kafka для различных сценариев использования. Со временем разделение ответственности по сценариям использования и SLA привело к появлению нескольких кластеров Kafka:
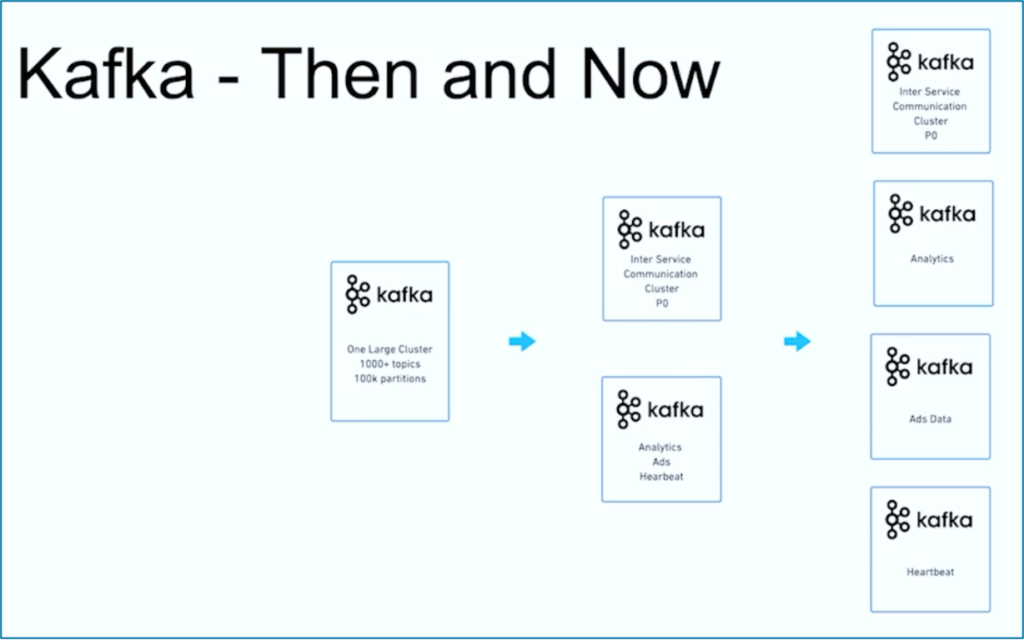 Источник: JioCinema
Источник: JioCinema
История успеха JioCinema показывает общее развитие организации по потоковой передаче данных. Давайте теперь рассмотрим другой пример, когда с самого начала было развернуто два очень разных кластера Kafka для одного использования.
Ауди: Операции против аналитики для подключенных автомобилей
Производитель автомобилей Audi предоставляет подключенные автомобили с передовой технологией, интегрирующей интернет-подключение и интеллектуальные системы. Автомобили Audi обеспечивают навигацию в реальном времени, удаленную диагностику и улучшенное развлечение в автомобиле. Эти автомобили оснащены сервисами Audi Connect. Функции включают аварийные вызовы, онлайн-информацию о дорожном движении и интеграцию с умными домашними устройствами для повышения удобства и безопасности водителей.
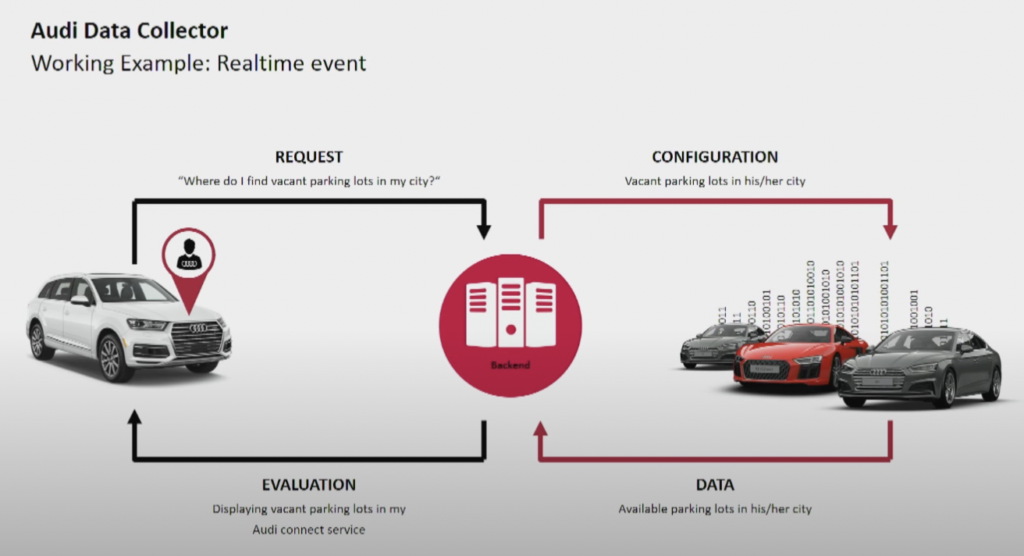 Источник: Audi
Источник: Audi
Ауди представила свою архитектуру подключенного автомобиля в основном докладе саммита Kafka 2018 года. Архитектура предприятия Audi полагается на два кластера Kafka с очень разными SLA и использованием.
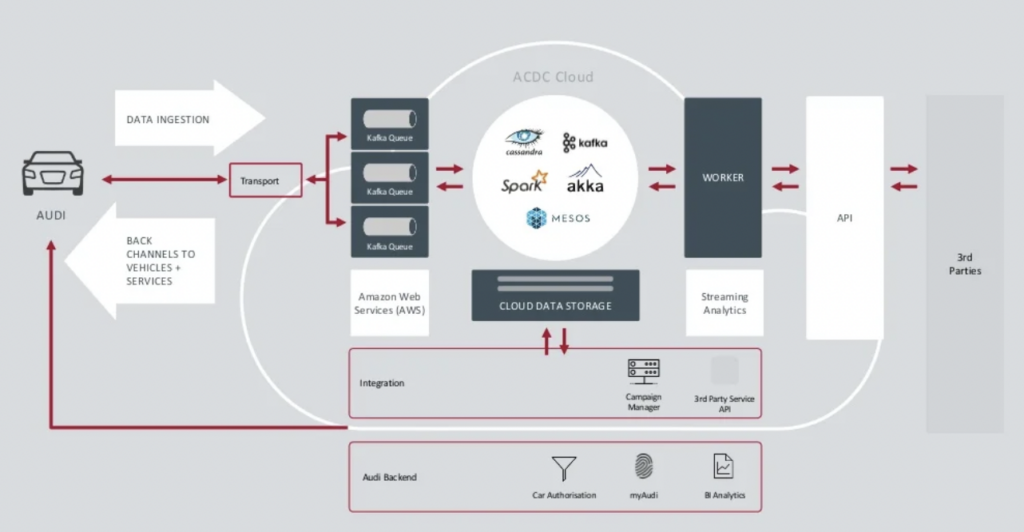 Источник: Audi
Источник: Audi
Кластер Data Ingestion Kafka очень важен.Он должен работать круглосуточно в масштабе. Он обеспечивает подключение последней мили к миллионам автомобилей с использованием Kafka и MQTT. Обратные каналы связи от стороны ИТ к автомобилю помогают в обслуживании связи и обновлениях по воздуху (OTA).
Кластер ACDC Cloud является аналитическим кластером Kafka архитектуры подключенного автомобиля Audi. Кластер является основой многих аналитических рабочих нагрузок, которые обрабатывают огромные объемы данных IoT и логов в масштабе с использованием фреймворков пакетной обработки, таких как Apache Spark.
Эта архитектура была представлена еще в 2018 году. Девиз Audi, “Прогресс через технологии”, показывает, как компания применила новые технологии для инноваций задолго до того, как большинство производителей автомобилей внедрили подобные сценарии. Все данные сенсоров из подключенных автомобилей обрабатываются в реальном времени и хранятся для исторического анализа и отчетности.
Новый Релик: Обзор мультиоблака по всему миру
Новый Релик – облачная платформа для наблюдаемости, которая предоставляет мониторинг производительности в реальном времени и аналитику для приложений и инфраструктуры для клиентов по всему миру.
Эндрю Хартнетт, вице-президент по программной инженерии в New Relic, объясняет, насколько важна потоковая передача данных для всей бизнес-модели New Relic:
“Кафка – это наша центральная нервная система. Это часть всего, что мы делаем. Большинство сервисов из 110 различных инженерных команд с сотнями сервисов каким-либо образом касаются Кафки в нашей компании, так что это действительно критически важно. Мы искали возможность роста, и Confluent Cloud предоставил нам это.
New Relic обрабатывает до 7 миллиардов точек данных в минуту и планирует обработать 2,5 экзабайт данных в 2023 году. По мере расширения стратегий мультиоблачности New Relic, команды будут использовать Confluent Cloud для общего представления по всем средам.
“New Relic работает в мультиоблаке. Мы хотим быть там, где наши клиенты. Мы хотим находиться в тех же средах, в тех же регионах, и хотели бы иметь нашу Кафку рядом с нами,” – говорит Артнетт в кейс-стади Confluent.
Несколько кластеров Kafka – это норма, а не исключение
Архитектуры, ориентированные на события и обработка потоков существуют десятилетиями. Их принятие растет благодаря открытым фреймворкам, таким как Apache Kafka и Flink, в сочетании с полностью управляемыми облачными сервисами. Все больше организаций сталкиваются с проблемами масштабирования своей Kafka. Корпоративное управление данными на уровне предприятия, центр компетенций, автоматизация развертывания и операций, а также лучшие практики корпоративной архитектуры помогают успешно предоставлять потоковые данные с использованием нескольких кластеров Kafka для независимых или сотрудничающих бизнес-доменов.”
Несколько кластеров Kafka – это норма, а не исключение. Сценарии использования, такие как гибридная интеграция, резервное копирование, миграция или агрегация, обеспечивают поток данных в реальном времени повсюду с необходимыми SLA.
Source:
https://dzone.com/articles/apache-kafka-cluster-type-deployment-strategies