













Organisaties beginnen hun adoptie van gegevensstreaming met een enkel Apache Kafka-cluster om de eerste use cases te implementeren. De behoefte aan groepsbrede gegevensbeheer en beveiliging, maar met verschillende SLA’s, latentie en infrastructuureisen, leidt tot het ontstaan van nieuwe Kafka-clusters. Meerdere Kafka-clusters zijn de norm, geen uitzondering. Gebruiksscenario’s omvatten hybride integratie, aggregatie, migratie en rampenherstel. In deze blogpost worden succesverhalen uit de praktijk en clusterstrategieën onderzocht voor verschillende Kafka-implementaties in verschillende sectoren.

Apache Kafka: De facto standaard voor op gebeurtenissen gebaseerde architectuur en gegevensstreaming
Apache Kafka is een open-source, gedistribueerd gebeurtenisstreamingplatform dat is ontworpen voor verwerking van gegevens met een hoge doorvoer en lage latentie. Het stelt u in staat om stromen van records in realtime te publiceren, te abonneren op, op te slaan en te verwerken.
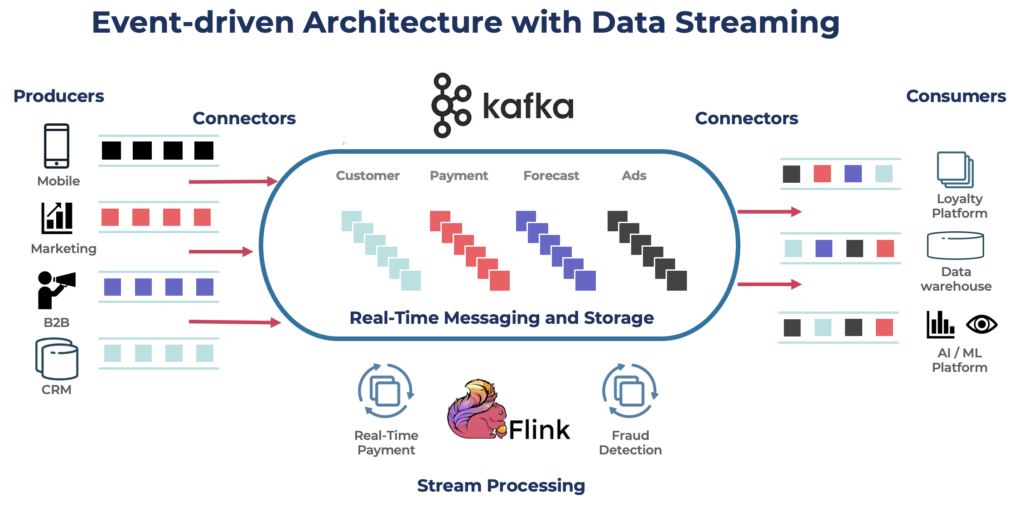
Kafka is een populaire keuze voor het bouwen van real-time datapijpleidingen en streamingtoepassingen. Het Kafka-protocol werd de de facto standaard voor event streaming binnen verschillende frameworks, oplossingen en cloudservices. Het ondersteunt operationele en analytische werkbelastingen met functies zoals persistente opslag, schaalbaarheid en fouttolerantie. Kafka bevat componenten zoals Kafka Connect voor integratie en Kafka Streams voor streamverwerking, waardoor het een veelzijdige tool is voor verschillende datagestuurde use cases.
Hoewel Kafka beroemd is om real-time use cases, maken veel projecten gebruik van het datastreamingplatform voor dataconsistentie binnen de hele enterprise-architectuur, inclusief databases, datameren, legacy-systemen, Open API’s en cloud-native toepassingen.
Verschillende Apache Kafka Cluster Types
Kafka is een gedistribueerd systeem. Een productieopstelling vereist meestal minstens vier brokers. Daarom gaan de meeste mensen er automatisch vanuit dat je alleen een enkele gedistribueerde cluster nodig hebt die je opschaalt wanneer je de doorvoer en use cases toevoegt. Dit is in het begin niet verkeerd. Maar…
Één Kafka-cluster is niet het juiste antwoord voor elke use case. Diverse kenmerken beïnvloeden de architectuur van een Kafka-cluster:
- Beschikbaarheid: Geen downtime? 99,99% uptime SLA? Niet-kritische analyses?
- Latentie: End-to-end verwerking in <100ms (inclusief verwerking)? Datawarehouse-pijplijn van 10 minuten? Tijdreizen voor het opnieuw verwerken van historische gebeurtenissen?
- Kosten: Waarde versus kosten? Totale eigendomskosten (TCO) zijn belangrijk. Bijvoorbeeld, in de publieke cloud kan networking tot wel 80% van de totale Kafka-kosten bedragen!
- Beveiliging en Gegevensprivacy: Gegevensprivacy (PCI-gegevens, GDPR, enz.)? Gegevensbeheer en naleving? End-to-end versleuteling op attribuutniveau? Breng je eigen sleutel mee? Openbare toegang en gegevensdeling? Afgeschermd edge-omgeving?
- Doorvoer en Gegevensgrootte: Kritieke transacties (meestal lage volumes)? Grote gegevensfeeds (klikstromen, IoT-sensoren, beveiligingslogs, enz.)?
Gerelateerde onderwerpen zoals on-premise vs. publieke cloud, regionaal vs. mondiaal, en vele andere vereisten hebben ook invloed op de Kafka-architectuur.
Apache Kafka Cluster Strategieën en Architecturen
Een enkel Kafka-cluster is vaak het juiste startpunt voor je gegevensstroomreis. Het kan meerdere use-cases van verschillende bedrijfsdomeinen aan boord nemen en gigabytes per seconde verwerken (indien goed bediend en geschaald).
Afhankelijk van je projectvereisten heb je echter een enterprise-architectuur nodig met meerdere Kafka-clusters. Hier zijn een paar veelvoorkomende voorbeelden:
- Hybride Architectuur: Gegevensintegratie en uni- of bidirectionele gegevenssynchronisatie tussen meerdere gegevenscentra. Vaak betreft het connectiviteit tussen een on-premise gegevenscentrum en een openbare cloudserviceprovider. Het verplaatsen van gegevens van legacy naar cloud-analyse is een van de meest voorkomende scenario’s. Maar commando- en controlecommunicatie is ook mogelijk, bijvoorbeeld het verzenden van beslissingen/aanbevelingen/transacties naar een regionale omgeving (bijv. het opslaan van een betaling of bestelling vanuit een mobiele app in het mainframe).
- Multi-Regio/Multi-Cloud: Gegevensreplicatie om redenen van naleving, kosten of gegevensprivacy. Gegevens delen omvat meestal slechts een deel van de gebeurtenissen, niet alle Kafka-onderwerpen. Gezondheidszorg is een van de vele sectoren die deze richting opgaan.
- Rampenherstel: Replicatie van kritieke gegevens in actief-actief of actief-passief modus tussen verschillende gegevenscentra of cloudregio’s. Omvat strategieën en tools voor fail-over en fallback-mechanismen in geval van een ramp om bedrijfscontinuïteit en naleving te garanderen.
- Aggregatie: Regionale clusters voor lokale verwerking (bijv. voorbewerking, streaming ETL, streaming verwerking van bedrijfstoepassingen) en replicatie van samengestelde gegevens naar het grote gegevenscentrum of de cloud. Winkels zijn een uitstekend voorbeeld.
- Migratie: IT-modernisering met een migratie van on-premise naar de cloud of van zelfbeheerde open source naar een volledig beheerde SaaS. Dergelijke migraties kunnen worden uitgevoerd zonder downtime of gegevensverlies, terwijl het bedrijf doorgaat tijdens de overgang.
- Rand (Losgekoppeld/Luchtgat): Beveiliging, kosten of latentie vereisen randimplementaties, bijvoorbeeld in een fabriek of winkel. Sommige industrieën implementeren in veiligheidskritieke omgevingen met eenrichtings-hardwaregateway en datadiode.
- Enkele Makelaar: Niet veerkrachtig, maar voldoende voor scenario’s zoals het inbedden van een Kafka-makelaar in een machine of op een Industriële PC (IPC) en het repliceren van geaggregeerde gegevens naar een grote cloudanalyse Kafka-cluster. Een goed voorbeeld is de installatie van gegevensstreaming (inclusief integratie en verwerking) op de computer van een soldaat op het slagveld.
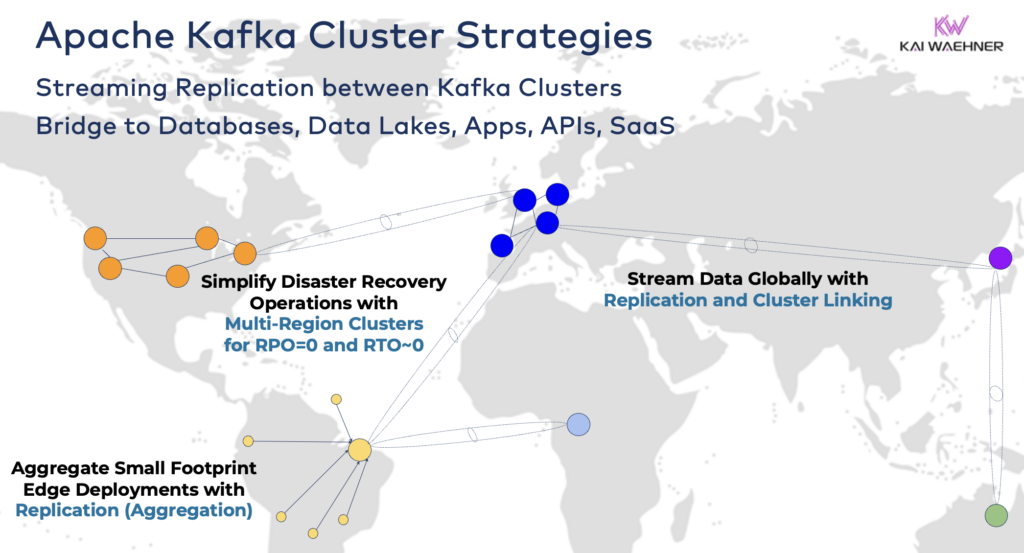
Bruggen slaan tussen hybride Kafka-clusters
Deze opties kunnen worden gecombineerd. Zo zal een enkele makelaar aan de rand meestal enkele samengestelde gegevens repliceren naar een extern datacenter. Hybride clusters hebben verschillende architecturen, afhankelijk van hoe ze worden overbrugd: verbindingen via het openbare internet, privéverbinding, VPC-peering, transit-gateway, enz.
Na de ontwikkeling van Confluent Cloud door de jaren heen te hebben gezien, heb ik onderschat hoeveel engineeringtijd moet worden besteed aan beveiliging en connectiviteit. Echter, ontbrekende beveiligingsbruggen zijn de belangrijkste obstakels voor de adoptie van een Kafka cloudservice. Dus, er is geen ontkomen aan het bieden van diverse beveiligingsbruggen tussen Kafka-clusters, verder dan alleen het openbare internet.
Er zijn zelfs gebruikscases waarbij organisaties gegevens van het datacenter naar de cloud moeten repliceren, maar de cloudservice is niet toegestaan om de verbinding te initiëren. Confluent heeft een specifieke functie ontwikkeld, “source-initiated link,” voor dergelijke beveiligingseisen waarbij de bron (d.w.z. de on-premise Kafka-cluster) altijd de verbinding initieert – hoewel de cloud Kafka-clusters de gegevens consumeren:
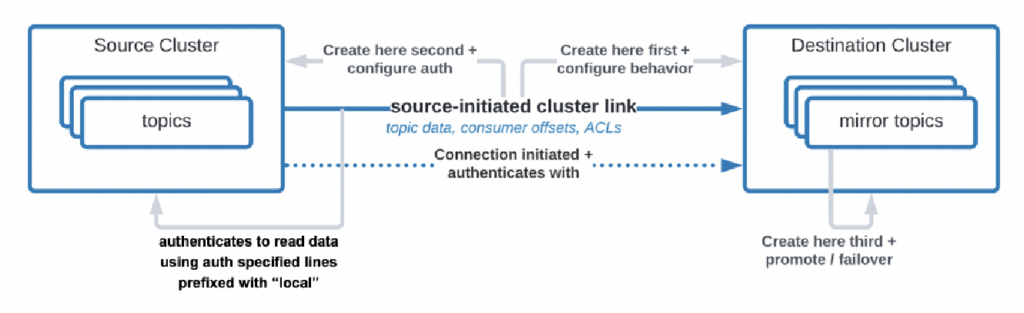 Bron: Confluent
Bron: Confluent
Zoals je kunt zien, wordt het snel complex. Zoek de juiste experts om je vanaf het begin te helpen, niet nadat je al de eerste clusters en applicaties hebt geïmplementeerd.
Lang geleden heb ik al in een gedetailleerde presentatie de architectuurpatronen voor gedistribueerde, hybride, edge en wereldwijde Apache Kafka-implementaties beschreven. Kijk naar die slides en video-opname voor meer details over de implementatieopties en afwegingen.
RPO versus RTO = Gegevensverlies versus Downtime
RPO en RTO zijn twee kritieke KPI’s die je moet bespreken voordat je een strategie voor een Kafka-cluster beslist:
- RPO (Recovery Point Objective) is de maximaal acceptabele hoeveelheid gegevensverlies gemeten in tijd, die aangeeft hoe vaak back-ups moeten plaatsvinden om gegevensverlies te minimaliseren.
- RTO (Recovery Time Objective) is de maximale acceptabele duur van tijd die nodig is om bedrijfsactiviteiten te herstellen na een verstoring. Samen helpen ze organisaties bij het plannen van hun gegevensback-up en rampenherstelstrategieën om kosten en operationele impact in evenwicht te brengen.
Hoewel mensen vaak beginnen met het doel RPO = 0 en RTO = 0, realiseren ze zich al snel hoe moeilijk (maar niet onmogelijk) dit is. Je moet beslissen hoeveel gegevens je kunt verliezen bij een ramp. Je hebt een rampenherstelplan nodig als er een ramp toeslaat. De juridische en nalevingsafdelingen moeten je vertellen of het acceptabel is om een paar gegevenssets te verliezen in geval van een ramp of niet. Deze en vele andere uitdagingen moeten worden besproken bij het evalueren van je Kafka-clusterstrategie.
De replicatie tussen Kafka-clusters met tools zoals MIrrorMaker of Cluster Linking is asynchroon en RPO > 0. Alleen een uitgerekt Kafka-cluster biedt RPO = 0.
Uitgerekt Kafka-cluster: Geen Gegevensverlies Met Synchrone Replicatie Over Datacenters
De meeste implementaties met meerdere Kafka-clusters gebruiken asynchrone replicatie over datacenters of clouds via tools zoals MirrorMaker of Confluent Cluster Linking. Dit is meestal voldoende voor de meeste gebruiksscenario’s. Maar in geval van een ramp verlies je een paar berichten. De RPO is > 0.
Een uitgerekt Kafka-cluster implementeert Kafka-brokers vanéén enkele cluster over drie datacenters. De replicatie is synchroon (omdat dit is hoe Kafka gegevens binnen één cluster dupliceert) en garandeert geen gegevensverlies (RPO = 0) – zelfs in geval van een ramp!
Waarom zou je niet altijd uitgerekte clusters gebruiken?
- Lage latentie (<~50 ms) en stabiele verbinding zijn vereist tussen datacenters.
- Er zijn drie (!) datacenters nodig; twee is niet genoeg omdat een meerderheid (quorum) schrijf- en leesbewerkingen moet bevestigen om de betrouwbaarheid van het systeem te waarborgen.
- Ze zijn moeilijk op te zetten, te bedienen en te monitoren en veel moeilijker dan een cluster dat draait in één datacenter.
- De kosten versus de waarde zijn in veel gevallen niet de moeite waard; tijdens een echte ramp hebben de meeste organisaties en toepassingen grotere problemen dan het verliezen van een paar berichten (zelfs als het kritieke gegevens betreft zoals een betaling of bestelling).
Om duidelijk te zijn, in de publieke cloud heeft een regio meestal drie datacenters (= beschikbaarheidszones). Daarom hangt het in de cloud af van uw SLA’s of één cloudregio telt als een uitgerekt cluster of niet. De meeste SaaS Kafka-aanbiedingen implementeren hier een uitgerekt cluster.
Veel nalevingsscenario’s beschouwen een Kafka-cluster in één cloudregio echter als niet voldoende om SLA’s en bedrijfscontinuïteit te garanderen als er een ramp plaatsvindt.
Confluent heeft een speciaal product gebouwd om (een aantal van) deze uitdagingen op te lossen: Multi-Region Clusters (MRC). Het biedt mogelijkheden voor synchrone en asynchrone replicatie binnen een uitgerekt Kafka-cluster.
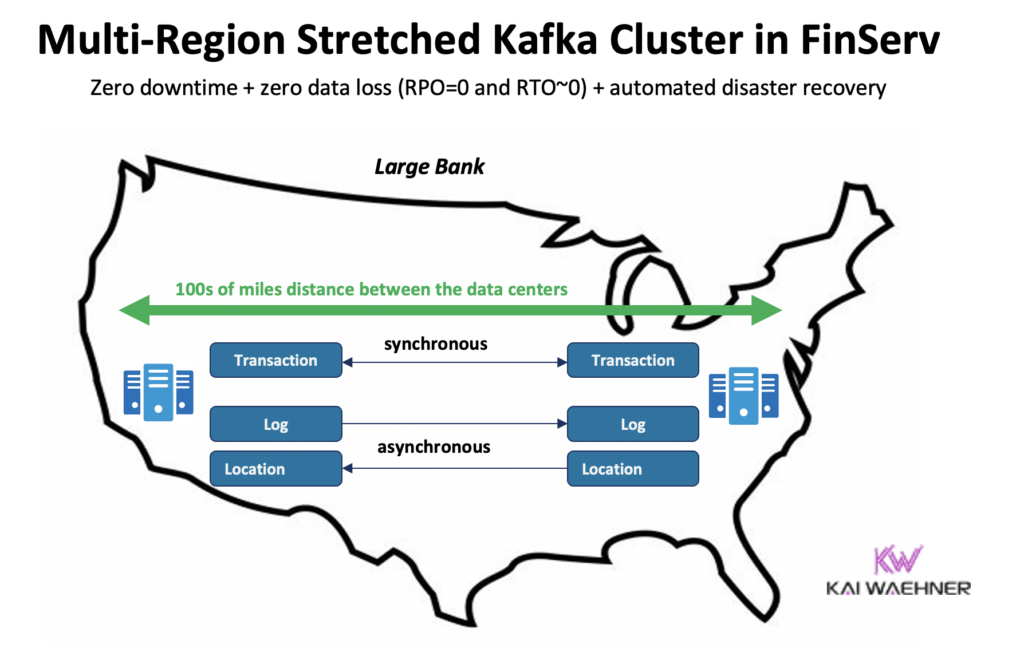
Bijvoorbeeld, in een financiële dienstverleningssituatie, repliceert MRC synchroon lage-volume kritieke transacties, maar logt hoog-volume asynchroon:
- Handelt ‘Betaling’ transacties afkomstig uit de VS Oost en VS West met volledig synchrone replicatie
- ‘Log’ en ‘Locatie’ informatie in hetzelfde cluster gebruiken asynchroon – geoptimaliseerd voor latentie
- Geautomatiseerde rampenherstel (nul downtime, nul gegevensverlies)
Meer details over gerekt Kafka clusters versus actief-actief / actief-passieve replicatie tussen twee Kafka clusters in mijn wereldwijde Kafka presentatie.
Prijzen van Kafka Cloud Aanbiedingen (vs. Self-Managed)
Bovenstaande secties leggen uit waarom u verschillende Kafka-architecturen moet overwegen, afhankelijk van uw projectvereisten. Self-managed Kafka-clusters kunnen geconfigureerd worden zoals u dat wilt. In de publieke cloud zien volledig beheerde aanbiedingen er anders uit (net als elk ander volledig beheerd SaaS). Prijzen zijn anders omdat SaaS-leveranciers redelijke limieten moeten instellen. De leverancier moet specifieke SLA’s verstrekken.
Het datatreaming-landschap omvat verschillende Kafka-cloudaanbiedingen. Hier is een voorbeeld van de huidige cloudaanbiedingen van Confluent, inclusief multi-tenant en toegewijde omgevingen met verschillende SLA’s, beveiligingsfuncties en kostenmodellen.
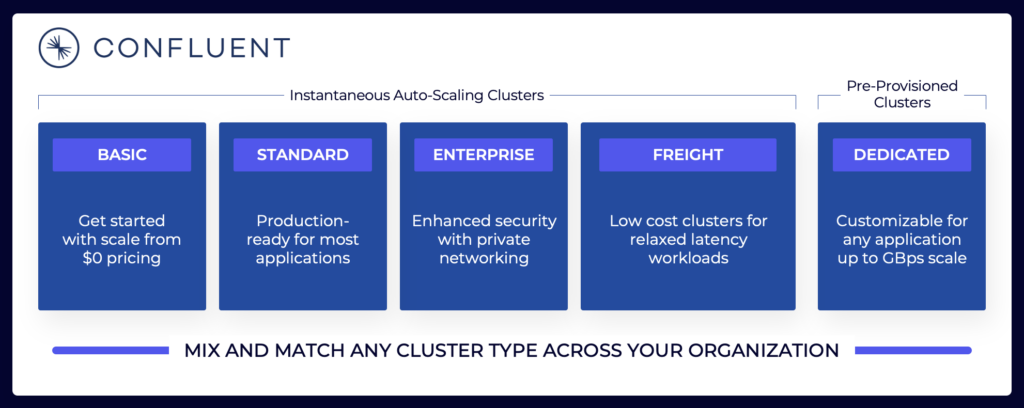 Bron: Confluent
Bron: Confluent
Zorg ervoor dat je de verschillende clustertypen van verschillende leveranciers die beschikbaar zijn in de publieke cloud evalueert en begrijpt, inclusief TCO, geboden uptime SLA’s, replicatiekosten tussen regio’s of cloudproviders, enzovoorts. De hiaten en beperkingen zijn vaak opzettelijk verborgen in de details.
Als je bijvoorbeeld gebruikmaakt van Amazon Managed Streaming voor Apache Kafka (MSK), moet je je ervan bewust zijn dat de algemene voorwaarden stellen dat “de serviceverbintenis niet van toepassing is op enige onbeschikbaarheid, opschorting of beëindiging … veroorzaakt door de onderliggende Apache Kafka of Apache Zookeeper engine software die leidt tot aanvraagfouten.”
De prijsstelling en ondersteuning SLA’s zijn echter slechts één kritisch onderdeel van de vergelijking. Er zijn veel “bouw versus kopen” beslissingen die je moet nemen als onderdeel van het evalueren van een datastreamingplatform.
Kafka-opslag: Gelaagde opslag en Iceberg-tabelindeling om gegevens slechts één keer op te slaan.
Apache Kafka heeft Tiered Storage toegevoegd om rekenkracht en opslag te scheiden. De mogelijkheid maakt meer schaalbare, betrouwbare en kostenefficiënte enterprise-architecturen mogelijk. Tiered Storage voor Kafka maakt een nieuw Kafka cluster type mogelijk: het opslaan van petabytes aan gegevens in het Kafka commit log op een kostenefficiënte manier (zoals in uw data lake) met tijdstempels en gegarandeerde ordening om terug in de tijd te kunnen reizen voor het opnieuw verwerken van historische gegevens. KOR Financial is een mooi voorbeeld van het gebruik van Apache Kafka als database voor langdurige persistentie.
Kafka maakt een Shift Left Architecture mogelijk om gegevens slechts één keer op te slaan voor operationele en analytische datasets:

Met dit in gedachten, denk opnieuw na over de gebruiksscenario’s die ik hierboven heb beschreven voor meerdere Kafka-clusters. Moet u nog steeds gegevens in batch repliceren in rust in de database, data lake of lakehouse van het ene datacenter of cloudregio naar de andere? Nee. U moet gegevens in realtime synchroniseren, de gegevens slechts één keer opslaan (meestal in een objectopslag zoals Amazon S3), en vervolgens alle analytische engines zoals Snowflake, Databricks, Amazon Athena, Google Cloud BigQuery, enzovoort verbinden met dit standaard tabel formaat.
Succesverhalen uit de praktijk voor meerdere Kafka-clusters
De meeste organisaties hebben meerdere Kafka-clusters. In dit gedeelte worden vier succesverhalen uit verschillende sectoren onderzocht:
- Paypal (Financiële diensten) – VS: Directe betalingen, fraudepreventie.
- JioCinema (Telco/Media) – APAC: Gegevensintegratie, clickstream-analyse, advertenties, personalisatie.
- Audi (Automotive/Manufacturing) – EMEA: Verbonden auto’s met kritische en analytische vereisten.
- New Relic (Software/Cloud) – US: Observability en applicatieprestatiemanagement (APM) over de hele wereld.
Paypal: Scheiding per beveiligingszone
PayPal is een digitaal betaalplatform waarmee gebruikers veilig en gemakkelijk geld online kunnen verzenden en ontvangen over de hele wereld in realtime. Dit vereist een schaalbare, veilige en conforme Kafka-infrastructuur.
Tijdens Black Friday 2022 piekte het Kafka-verkeersvolume op ongeveer 1,3 biljoen berichten per dag. Op dit moment heeft PayPal 85+ Kafka-clusters en tijdens elk feestseizoen schalen ze hun Kafka-infrastructuur op om de verkeerspiek aan te kunnen. Het Kafka-platform blijft naadloos schalen om deze verkeersgroei te ondersteunen zonder enige invloed op hun bedrijf.
Vandaag de dag bestaat de Kafka-vloot van PayPal uit meer dan 1.500 brokers die meer dan 20.000 onderwerpen hosten. De gebeurtenissen worden gerepliceerd tussen de clusters, met een beschikbaarheid van 99,99%.
Kafka-clusterimplementaties zijn gescheiden in verschillende beveiligingszones binnen een datacenter:
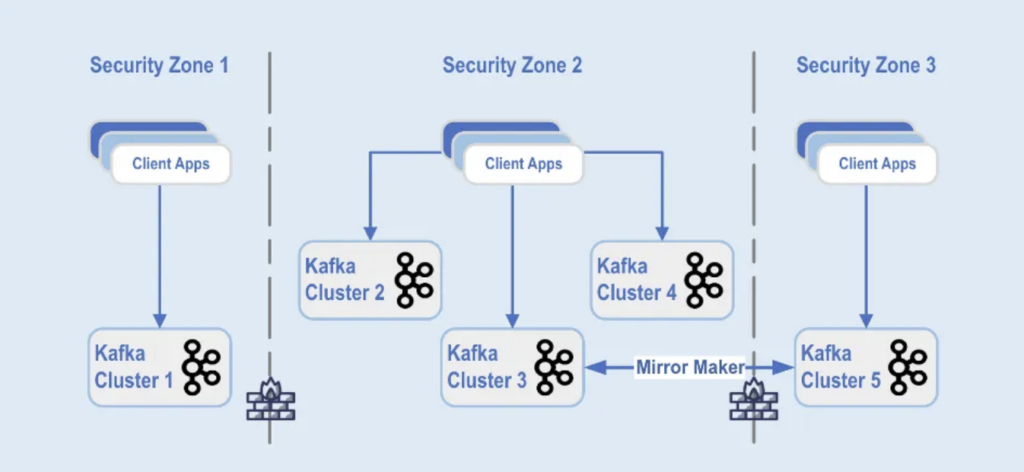 Bron: Paypal
Bron: Paypal
De Kafka-clusters zijn ingezet over deze beveiligingszones, op basis van gegevensclassificatie en zakelijke vereisten. Realtime replicatie met tools zoals MirrorMaker (in dit voorbeeld, draaiend op Kafka Connect-infrastructuur) of Confluent Cluster Linking (met een eenvoudigere en minder foutgevoelige aanpak door rechtstreeks gebruik te maken van het Kafka-protocol voor replicatie) wordt gebruikt om de gegevens over de datacenters te spiegelen, wat helpt bij rampenherstel en om inter-beveiligingszone communicatie te bereiken.
JioCinema: Scheiding op basis van Gebruiksscenario en SLA
JioCinema is een snelgroeiend videostreamingplatform in India. De telecommunicatie OTT-service staat bekend om zijn uitgebreide contentaanbod, waaronder live sportevenementen zoals de Indian Premier League (IPL) voor cricket, een nieuw gelanceerd Anime Hub, en uitgebreide plannen voor de dekking van grote evenementen zoals de Olympische Spelen van Parijs 2024.
De data-architectuur maakt gebruik van Apache Kafka, Flink en Spark voor gegevensverwerking, zoals gepresenteerd op de Kafka Summit India 2024 in Bangalore:
 Bron: JioCinema
Bron: JioCinema
Gegevensstreaming speelt een cruciale rol in verschillende gebruiksscenario’s om gebruikerservaringen en contentlevering te transformeren. Meer dan tien miljoen berichten per seconde verbeteren analyses, gebruikersinzichten en mechanismen voor contentlevering.
De gebruiksscenario’s van JioCinema omvatten:
- Interne dienstcommunicatie
- Klikstroom/Analyse
- Ad Tracker
- Machine learning en personalisatie
Kushal Khandelwal, Hoofd van het Data Platform, Analyse en Gebruik bij JioCinema, legde uit dat niet alle gegevens gelijk zijn en dat de prioriteiten en SLA’s verschillen per gebruiksscenario:
 Bron: JioCinema
Bron: JioCinema
Gegevensstreaming is een reis. Net als veel andere organisaties wereldwijd begon JioCinema met één groot Kafka-cluster met meer dan 1000 Kafka-onderwerpen en meer dan 100.000 Kafka-partities voor verschillende gebruiksscenario’s. Na verloop van tijd ontwikkelde zich een scheiding van zorgen met betrekking tot gebruiksscenario’s en SLA’s tot meerdere Kafka-clusters:
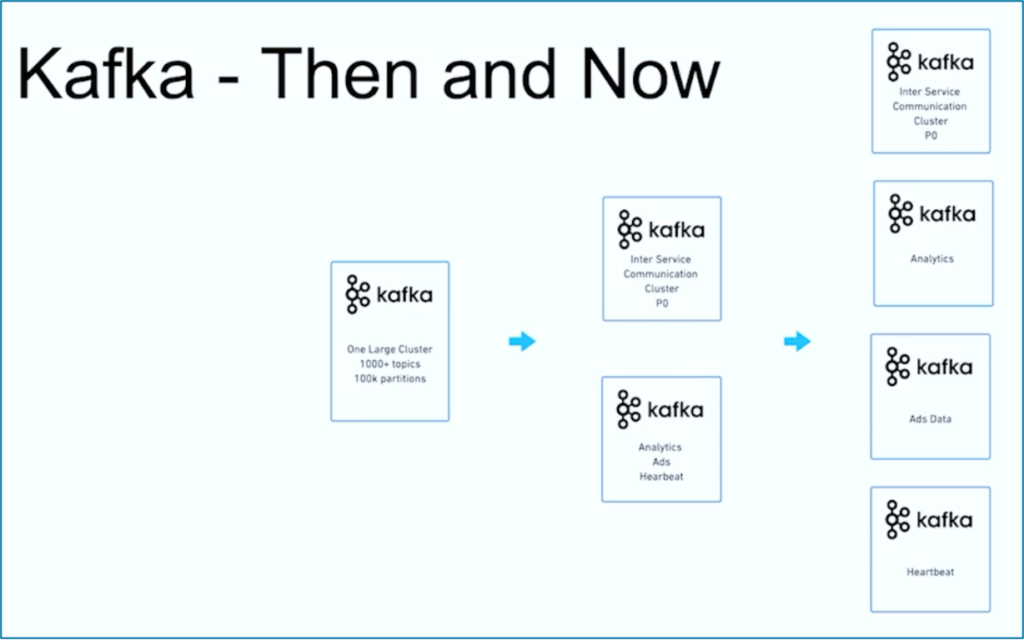 Bron: JioCinema
Bron: JioCinema
Het succesverhaal van JioCinema toont de gebruikelijke evolutie van een gegevensstreamingorganisatie. Laten we nu een ander voorbeeld verkennen waarbij vanaf het begin twee zeer verschillende Kafka-clusters werden ingezet voor één gebruikssituatie.
Audi: Operaties versus Analyse voor Connected Cars
Autofabrikant Audi biedt connected cars met geavanceerde technologie die internetconnectiviteit en intelligente systemen integreert. De auto’s van Audi bieden realtime navigatie, externe diagnose en verbeterd entertainment in de auto. Deze voertuigen zijn uitgerust met Audi Connect-services. Functies zijn onder andere noodoproepen, online verkeersinformatie en integratie met slimme thuisapparaten, om het gemak en de veiligheid voor bestuurders te verbeteren.
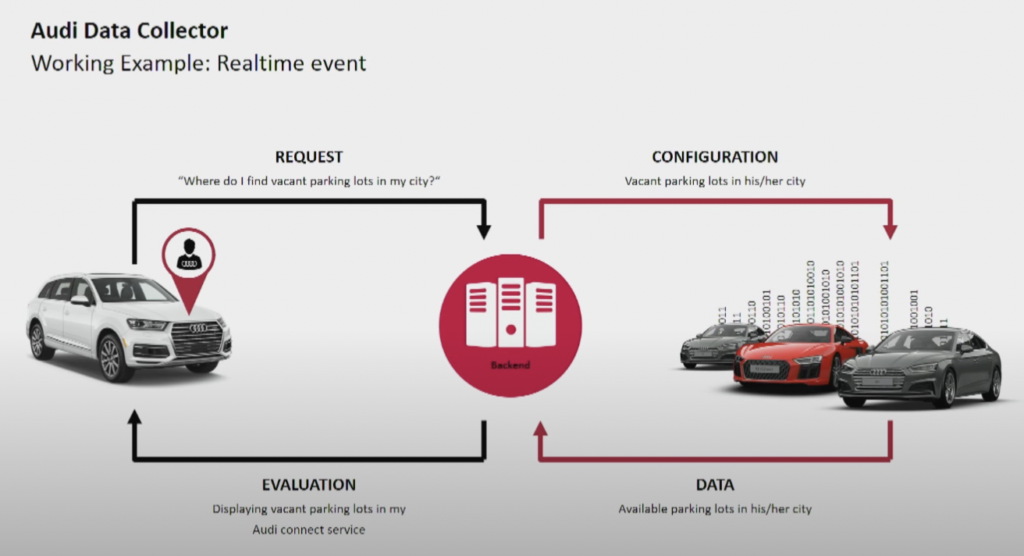 Bron: Audi
Bron: Audi
Audi presenteerde zijn connected car-architectuur tijdens de keynote van de Kafka Summit 2018. De enterprise-architectuur van Audi vertrouwt op twee Kafka-clusters met zeer verschillende SLA’s en gebruikssituaties.
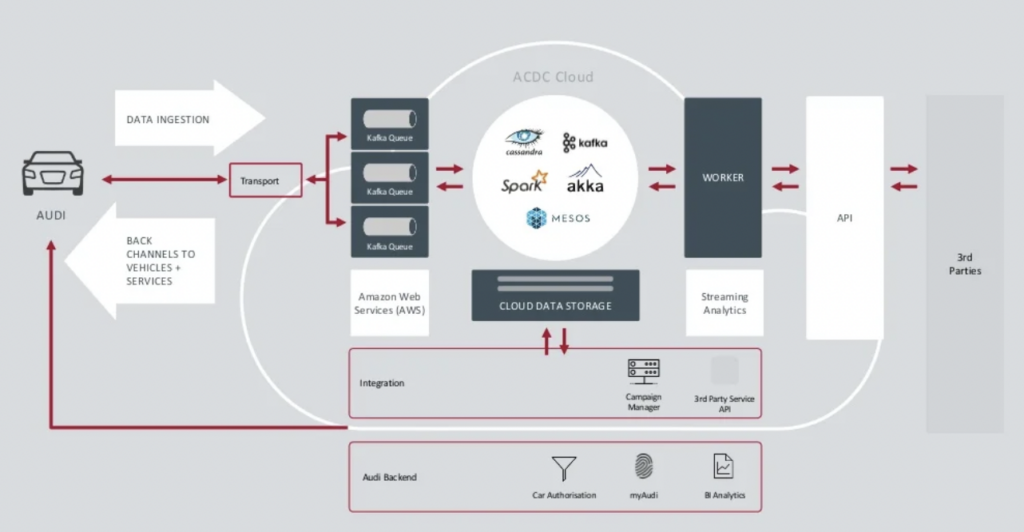 Bron: Audi
Bron: Audi
Het Data Ingestion Kafka-cluster is zeer kritiek.Het moet 24/7 op schaal draaien. Het biedt connectiviteit tot op de laatste kilometer voor miljoenen auto’s met behulp van Kafka en MQTT. Backchannels van de IT-kant naar het voertuig helpen bij servicecommunicatie en over-the-air-updates (OTA).
ACDC Cloud is het analytics Kafka-cluster van de connected car-architectuur van Audi. Het cluster vormt de basis van veel analytische workloads, die enorme hoeveelheden IoT- en loggegevens verwerken op schaal met batchverwerkingsframeworks zoals Apache Spark.
Deze architectuur werd al in 2018 gepresenteerd. Het motto van Audi, “Vooruitgang door technologie”, toont hoe het bedrijf nieuwe technologie heeft toegepast voor innovatie lang voordat de meeste autofabrikanten vergelijkbare scenario’s implementeerden. Alle sensordata van verbonden auto’s wordt in realtime verwerkt en opgeslagen voor historische analyse en rapportage.
New Relic: Wereldwijde Multi-Cloud Observability
New Relic is een cloudgebaseerd observatieplatform dat real-time prestatiebewaking en analyses biedt voor applicaties en infrastructuur aan klanten over de hele wereld.
Andrew Hartnett, VP van Software Engineering bij New Relic, legt uit hoe datastreaming cruciaal is voor het gehele bedrijfsmodel van New Relic:
“Kafka is ons centrale zenuwstelsel. Het maakt deel uit van alles wat we doen. De meeste diensten over 110 verschillende engineeringteams met honderden diensten raken op de een of andere manier Kafka in ons bedrijf, dus het is echt van cruciaal belang. Wat we zochten, was de mogelijkheid om te groeien, en Confluent Cloud bood dat.”
New Relic heeft tot wel 7 miljard gegevenspunten per minuut ingeslikt en staat op schema om in 2023 2,5 exabytes aan gegevens te verwerken. Terwijl New Relic zijn multi-cloudstrategieën uitbreidt, zullen teams Confluent Cloud gebruiken voor een allesomvattend overzicht over alle omgevingen.
“New Relic is multi-cloud. We willen zijn waar onze klanten zijn. We willen in dezelfde omgevingen zijn, in dezelfde regio’s, en we wilden onze Kafka daar bij ons hebben,” zegt Artnett in een Confluent casestudie.
Meerdere Kafka-clusters zijn de norm, geen uitzondering
Gebeurtenisgestuurde architecturen en streamverwerking bestaan al tientallen jaren. De adoptie groeit met open-source frameworks zoals Apache Kafka en Flink in combinatie met volledig beheerde cloudservices. Steeds meer organisaties worstelen met de schaalbaarheid van hun Kafka. Data governance op ondernemingsniveau, center of excellence, automatisering van implementatie en operaties, en best practices voor enterprise-architectuur helpen bij het succesvol leveren van gegevensstreaming met meerdere Kafka-clusters voor onafhankelijke of samenwerkende bedrijfsdomeinen.
Meerdere Kafka-clusters zijn de norm, geen uitzondering. Gebruiksscenario’s zoals hybride integratie, noodherstel, migratie of aggregatie maken real-time gegevensstreaming overal mogelijk met de benodigde SLA’s.
Source:
https://dzone.com/articles/apache-kafka-cluster-type-deployment-strategies