













تبدأ المؤسسات اعتماد تيار البيانات الخاصة بها بعيدا عن البيانات مع عملية استخدام أولية لمجموعة واحدة من أجهزة Apache Kafka لنشر حالات الاستخدام الأولى. الحاجة إلى حكم البيانات والأمان على مستوى المجموعة ولكن مع اختلاف متطلبات SLAs والتأخير وبنية البنية التحتية تقدم مجموعات Kafka جديدة. تعتبر مجموعات Kafka المتعددة القاعدة، ليست استثناء. تتضمن حالات الاستخدام التكامل الهجين، والتجميع، والهجرة، واستعادة الكوارث. يستكشف هذا المنشور في المدونة قصص النجاح الواقعية واستراتيجيات المجموعات لنشر Kafka المختلفة عبر الصناعات.

Apache Kafka: المعيار الواقعي للهندسات الموجهة بالأحداث وتيار البيانات
Apache Kafka هو منصة تدفق حدث موزعة مفتوحة المصدر مصممة ل معالجة البيانات عالية النطاق ومنخفضة التأخير. يتيح لك نشر والاشتراك في، وتخزين، ومعالجة تيارات السجلات في الوقت الحقيقي.
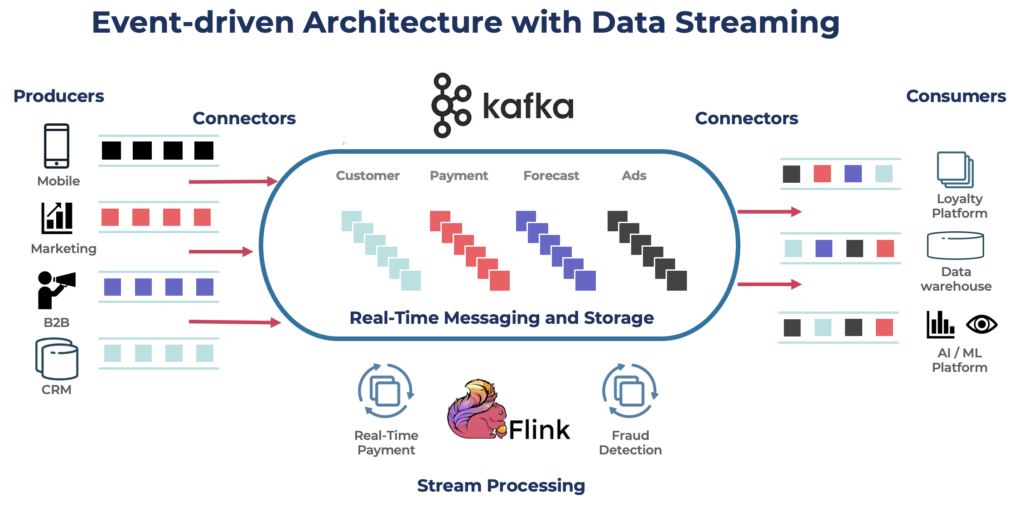
كافكا هو اختيار شائع لـ بناء خطوط بيانات في الوقت الحقيقي وتطبيقات البث. أصبح بروتوكول كافكا المعيار الفعلي لبث الأحداث عبر أطر العمل المختلفة، والحلول، وخدمات السحابة. يدعم الأحمال التشغيلية والتحليلية مع ميزات مثل التخزين الدائم، وقابلية التوسع، وتحمل الأخطاء. يتضمن كافكا مكونات مثل كافكا كونكت للتكامل وكافكا ستريمز لمعالجة البث، مما يجعله أداة متعددة الاستخدامات لمجموعة متنوعة من حالات الاستخدام المعتمدة على البيانات.
بينما يشتهر كافكا بحالات الاستخدام في الوقت الحقيقي، تستفيد العديد من المشاريع من منصة بث البيانات لتحقيق اتساق البيانات عبر الهيكلية المؤسسية بالكامل، بما في ذلك قواعد البيانات، بحيرات البيانات، الأنظمة القديمة، واجهات برمجة التطبيقات المفتوحة، والتطبيقات السحابية الأصلية.
أنواع مجموعات كافكا المختلفة
كافكا هو نظام موزع. عادةً ما يتطلب إعداد الإنتاج ما لا يقل عن أربعة وسطاء. ومن ثم، يفترض معظم الناس تلقائيًا أن كل ما تحتاجه هو مجموعة موزعة واحدة تقوم بتوسيعها عند إضافة السعة وحالات الاستخدام. هذا ليس خاطئًا في البداية. لكن…
مجموعة كافكا واحدة ليست الإجابة الصحيحة لكل حالة استخدام. تؤثر خصائص مختلفة على هيكل مجموعة كافكا:
- التوافر: عدم وجود وقت تعطل؟ 99.99% وقت تشغيل SLA؟ تحليلات غير حرجة؟
- التأخير: معالجة من النهاية إلى النهاية في أقل من 100 مللي ثانية (بما في ذلك المعالجة)؟ أنبوب بيانات مستودع البيانات من النهاية إلى النهاية في 10 دقائق؟ السفر عبر الزمن لإعادة معالجة الأحداث التاريخية؟
- التكلفة: القيمة مقابل التكلفة؟ إجمالي تكلفة الملكية يهم. على سبيل المثال، في السحابة العامة، قد تكون الشبكات تصل إلى 80٪ من إجمالي تكلفة Kafka!
- الأمان وخصوصية البيانات: خصوصية البيانات (بيانات PCI، GDPR، إلخ)؟ حوكمة البيانات والامتثال؟ تشفير من النهاية إلى النهاية على مستوى السمات؟ جلب مفتاحك الخاص؟ الوصول العام ومشاركة البيانات؟ بيئة حواف منعزلة عن الشبكة؟
- الإنتاجية وحجم البيانات: المعاملات الحرجة (عادة حجم منخفض)? تغذيات البيانات الكبيرة (تتبع النقرات، أجهزة استشعار IoT، سجلات الأمان، إلخ)؟
المواضيع ذات الصلة مثل السحابة الخاصة مقابل السحابة العامة، المحلية مقابل العالمية، والعديد من المتطلبات الأخرى تؤثر أيضًا على بنية Kafka.
استراتيجيات وهندسة مجموعات Kafka لأباتشي
عادة، تكون مجموعة Kafka الواحدة هي نقطة البداية المناسبة لرحلتك في تدفق البيانات. يمكنها استيعاب العديد من حالات الاستخدام من مجالات الأعمال المختلفة ومعالجة غيغابايتات في الثانية (إذا تم تشغيلها وتوسيعها بالطريقة الصحيحة).
ومع ذلك، اعتمادًا على متطلبات مشروعك، تحتاج إلى هندسة مؤسسية تضم مجموعات Kafka متعددة. إليك بعض الأمثلة الشائعة:
- الهندسة المعمارية الهجينة: تكامل البيانات ومزامنة البيانات ذات الاتجاه الواحد أو ذات الاتجاهين بين مراكز البيانات المتعددة. غالبًا ما تكون الاتصالات بين مركز بيانات على الأرض ومزود خدمة سحابي عام. إفراغ البيانات من النظام التقليدي إلى تحليلات السحابة هو واحد من أكثر السيناريوهات شيوعًا. ولكن التواصل للتحكم والتوجيه أيضًا ممكن، أي إرسال القرارات/التوصيات/المعاملات إلى بيئة إقليمية (على سبيل المثال، تخزين دفعة أو طلب من تطبيق جوال في الحاسوب الرئيسي).
- متعدد المناطق/متعدد السحب: تكرار البيانات لأسباب الامتثال أو التكلفة أو الخصوصية. تقتصر مشاركة البيانات عادةً على جزء صغير من الأحداث، ليس كل مواضيع كافكا. الرعاية الصحية هي واحدة من العديد من الصناعات التي تتجه بهذا الاتجاه.
- استعادة الكوارث: تكرار البيانات الحرجة بين مراكز بيانات مختلفة أو مناطق سحابية بنشاط نشط أو نشط غير نشط. يتضمن استراتيجيات وأدوات للتبديل وآليات الاسترجاع في حالة وقوع كارثة لضمان استمرارية الأعمال والامتثال.
- التجميع: تجميع العناقيد الإقليمية للمعالجة المحلية (على سبيل المثال، المعالجة المسبقة، تحويل البيانات المتدفقة، تطبيقات الأعمال لمعالجة التدفقات) وتكرار البيانات المنقاة إلى مركز البيانات الكبير أو السحابة. تعتبر متاجر التجزئة مثالًا ممتازًا.
- الهجرة: تحديث تكنولوجيا المعلومات من النظام الأساسي إلى السحابة أو من البرمجيات مفتوحة المصدر التي تُدار ذاتيًا إلى خدمة البرمجيات كخدمة مُدارة بالكامل. يمكن تنفيذ مثل هذه الهجرات دون توقف أو فقدان للبيانات بينما تستمر الأعمال خلال التحول.
- الحافة (غير متصلة بالإنترنت/معزولة): الأمان أو التكلفة أو التأخير يتطلبان نشر الحواف، على سبيل المثال، في مصنع أو متجر تجزئة. تقوم بعض الصناعات بنشرها في بيئات حساسة من الناحية الأمنية مع بوابة أجهزة غير ثنائية الاتجاه ومحول بيانات.
- سمسار واحد: غير مقاوم، ولكن كافٍ لسيناريوهات مثل تضمين سمسار Kafka في جهاز أو على جهاز كمبيوتر صناعي (IPC) وتكرار البيانات المجمعة في مجموعة كبيرة من تحليلات سحابة Kafka. مثال جيد هو تثبيت تدفق البيانات (بما في ذلك التكامل والمعالجة) على كمبيوتر الجندي في ساحة المعركة.
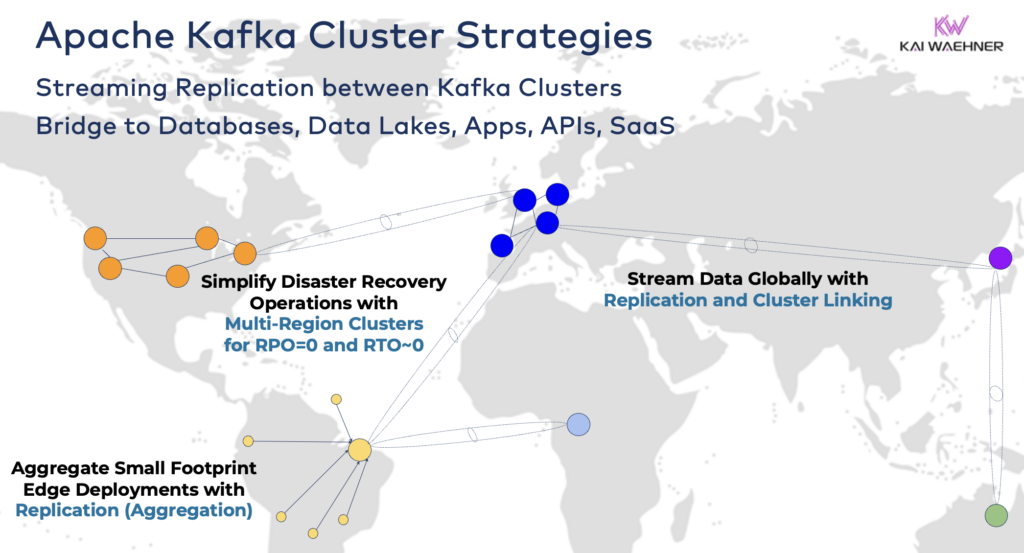
ربط مجموعات Kafka الهجينة
يمكن دمج هذه الخيارات. على سبيل المثال، يكرر وسيط واحد على الحافة بعض البيانات المراقبة إلى مركز بيانات عن بعد. تحتوي المجموعات الهجينة على تصاميم مختلفة تعتمد على كيفية ربطها: اتصالات عبر الإنترنت العام، وصلة خاصة، ربط VPC، بوابة عبور، إلخ.
بعد رؤية تطور Confluent Cloud على مر السنين، كنت أقل تقديرًا لكمية وقت الهندسة المطلوبة للعمل على الأمان والاتصالات. ومع ذلك، الجسور الأمنية المفقودة هي العوائق الرئيسية أمام اعتماد خدمة سحابة Kafka. لذا، لا يوجد سبيل لتقديم جسور أمنية متنوعة بين مجموعات Kafka بالإضافة إلى الإنترنت العام.
هناك حالات استخدام حتى حيث تحتاج المؤسسات إلى استنساخ البيانات من مركز البيانات إلى السحابة، لكن خدمة السحابة غير مسموح لها ببدء الاتصال. قامت Confluent ببناء ميزة معينة، “رابط يبدأ من المصدر”، لمتطلبات الأمان من هذا القبيل حيث المصدر (أي، عقدة Kafka الموجودة على الأرض) يبدأ الاتصال دائمًا – حتى وإن كانت عقدات Kafka في السحابة تستهلك البيانات:
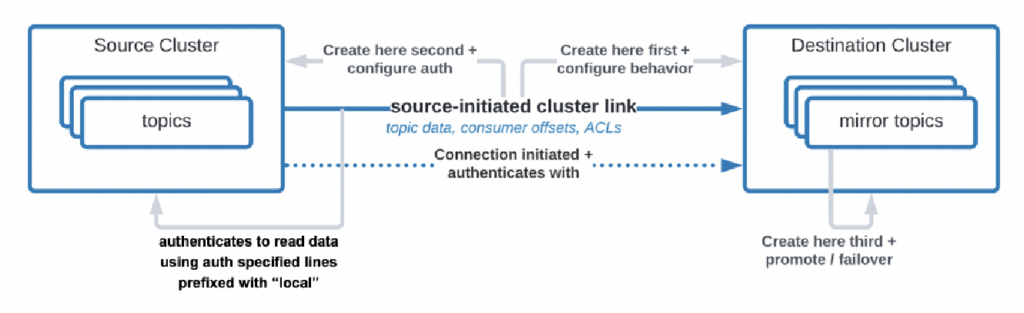 المصدر: Confluent
المصدر: Confluent
كما ترون، تصبح الأمور معقدة بسرعة. ابحث عن الخبراء المناسبين لمساعدتك من البداية، وليس بعد نشر العقدات الأولى والتطبيقات بالفعل.
منذ وقت طويل، وصفت بالفعل في عرض تقديمي مفصل أنماط الهندسة المعمارية لنشر Apache Kafka الموزع والهجين والحافة والعالمي. انظر إلى ذلك العرض التقديمي وتسجيل الفيديو لمزيد من التفاصيل حول خيارات النشر والتنازلات.
مدى فقدان البيانات مقابل وقت التشغيل = RPO مقابل RTO
RPO و RTO هما مؤشران أساسيان يجب مناقشتهما قبل اتخاذ استراتيجية عقدة Kafka:
- RPO (هدف نقطة الاسترداد) هو أقصى كمية مقبولة من فقدان البيانات يتم قياسها بالزمن، مشيرة إلى مدى تكرار النسخ الاحتياطية التي ينبغي أن تحدث لتقليل فقدان البيانات.
- مدة الاستعادة المستهدفة (RTO) هي المدة القصوى المقبولة لاستعادة عمليات الأعمال بعد حدوث انقطاع. معًا، تساعد هذه المفاهيم المؤسسات على تخطيط استراتيجيات نسخ البيانات واستعادة الكوارث لتحقيق التوازن بين التكلفة والتأثير التشغيلي.
على الرغم من أن الناس غالبًا ما يبدؤون بالهدف من RPO = 0 و RTO = 0، إلا أنهم يدركون بسرعة مدى صعوبة الأمر (ولكن ليس المستحيل). عليك أن تقرر كمية البيانات التي يمكن أن تفقدها في حالة وقوع كارثة. ستحتاج إلى خطة لاستعادة الكوارث إذا حدثت كارثة. سيضطر فرق القانونية والامتثال لإخبارك ما إذا كان من المقبول أن تفقد بعض مجموعات البيانات في حالة وقوع كارثة أم لا. يجب مناقشة هذه التحديات والعديد من التحديات الأخرى عند تقييم استراتيجية مجموعة Kafka الخاصة بك.
التكرار بين مجموعات Kafka باستخدام أدوات مثل MIrrorMaker أو Cluster Linking هو غير متزامن و RPO > 0. إن توفير مجموعة Kafka الممتدة يوفر RPO = 0.
مجموعة Kafka الممتدة: عدم فقد البيانات باستخدام التكرار المتزامن عبر مراكز البيانات
معظم التنفيذات التي تحتوي على عدة مجموعات Kafka تستخدم تكرارًا غير متزامن عبر مراكز البيانات أو السحب عبر السحب عبر السحب مثل MirrorMaker أو Confluent Cluster Linking. هذا يكفي بما فيه الكفاية لمعظم حالات الاستخدام. ولكن في حالة وقوع كارثة، ستفقد بعض الرسائل. RPO هو > 0.
تنفذ مجموعة Kafka الممتدة وسطاء Kafka من مجموعة واحدة فقط عبر ثلاث مراكز بيانات. التكرار متزامن (لأن هذه هي الطريقة التي تقوم بها Kafka بتكرار البيانات ضمن مجموعة واحدة) ويضمن عدم فقد البيانات (RPO = 0) – حتى في حالة وقوع كارثة!
لماذا لا يجب عليك دائمًا تنفيذ مجموعات ممتدة؟
- يتطلب وجود اتصال منخفض الكمون (<~50ms) ومستقر بين مراكز البيانات.
- هناك حاجة إلى ثلاثة (!) مراكز بيانات؛ فاثنان غير كافيين حيث يجب أن تعترف الغالبية (نصاب) بالكتابات والقراءات لضمان موثوقية النظام.
- من الصعب إعدادها وتشغيلها ومراقبتها وهي أصعب بكثير من عنقود يعمل في مركز بيانات واحد.
- التكلفة مقابل القيمة لا تستحق ذلك في العديد من حالات الاستخدام؛ خلال كارثة حقيقية، تواجه معظم المنظمات وحالات الاستخدام مشاكل أكبر من فقدان بضع رسائل (حتى لو كانت بيانات حاسمة مثل الدفع أو الطلب).
للتوضيح، في السحابة العامة، عادةً ما تحتوي المنطقة على ثلاثة مراكز بيانات (= مناطق التوفر). وبالتالي، في السحابة، يعتمد الأمر على اتفاقيات مستوى الخدمة الخاصة بك إذا كانت منطقة سحابية واحدة تُعتبر عنقودًا ممتدًا أم لا. تقوم معظم عروض SaaS Kafka بنشرها في عنقود ممتد هنا.
ومع ذلك، لا ترى العديد من سيناريوهات الامتثال أن عنقود Kafka في منطقة سحابية واحدة كافٍ لضمان اتفاقيات مستوى الخدمة واستمرارية الأعمال إذا حدثت كارثة.
قامت Confluent ببناء منتج مخصص لحل (بعض من) هذه التحديات: العناقيد متعددة المناطق (MRC). يوفر إمكانيات للقيام بالتكرار المتزامن وغير المتزامن داخل عنقود Kafka ممتد.
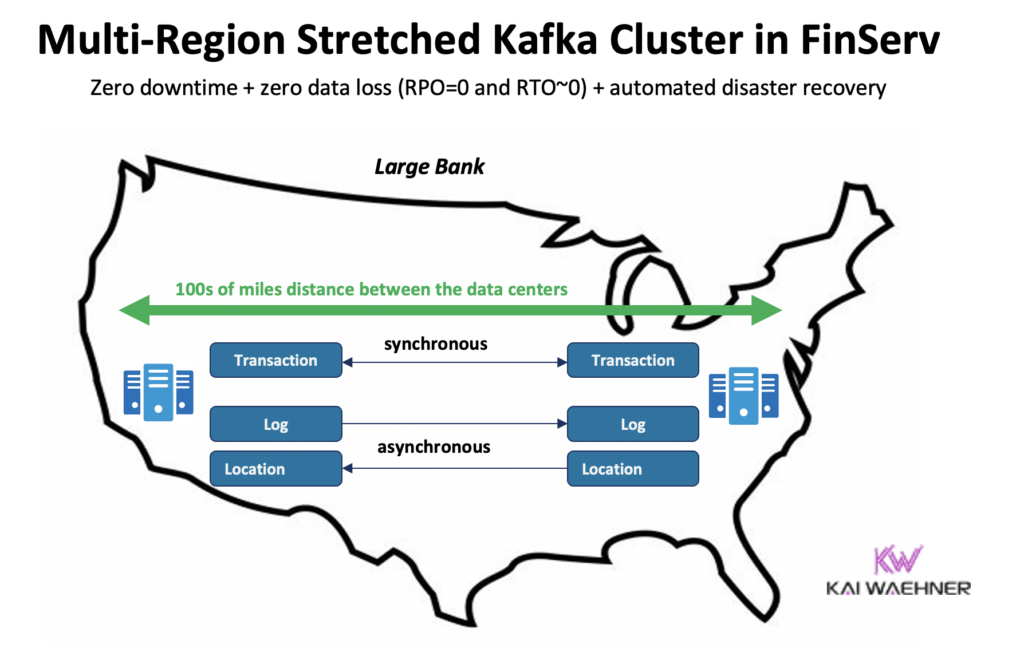
على سبيل المثال، في سيناريو الخدمات المالية، يقوم MRC بتكرار المعاملات الحرجة ذات الحجم المنخفض متزامنة ولكن سجلات الحجم الكبير غير متزامنة:
- يتعامل مع معاملات “الدفع” التي تدخل من الولايات المتحدة الشرقية والولايات المتحدة الغربية بتكرار متزامن بالكامل
- المعلومات المتعلقة بـ “السجل” و “الموقع” في نفس المجموعة تستخدم النقل بشكل غير متزامن – محسن للتأخير
- استعادة الكوارث التلقائية (صفر توقف، صفر فقد بيانات)
مزيد من التفاصيل حول مجموعات Kafka الممتدة مقابل التكرار النشط/النشط أو النشط/السلبي بين مجموعتين من Kafka في عرضي كافكا العالمي.
التسعير لعروض خدمات السحابة لـ Kafka (مقابل الإدارة الذاتية)
تشرح الأقسام أعلاه لماذا يجب عليك أن تنظر في الهندسات المعمارية المختلفة لـ Kafka تبعًا لمتطلبات مشروعك. يمكن تكوين مجموعات Kafka التي تديرها بنفسك بالطريقة التي تحتاج إليها. في السحابة العامة، تبدو العروض التي تديرها بالكامل مختلفة (بنفس الطريقة التي يتم فيها إدارة أي برنامج تطبيقي بالكامل). التسعير مختلف لأن مزودي SaaS يحتاجون إلى تكوين حدود معقولة. يتعين على البائع تقديم SLAs محددة.
يشمل منظر البث المتدفق مجموعة متنوعة من عروض خدمات السحابة لـ Kafka. إليك مثال على العروض السحابية الحالية لـ Confluent، بما في ذلك البيئات المشتركة والمخصصة مع SLAs مختلفة، وميزات الأمان، ونماذج التكلفة.
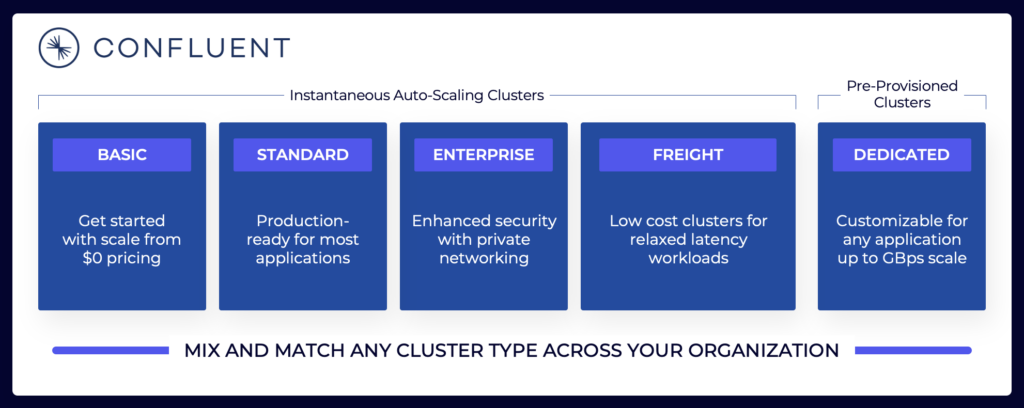 المصدر: كونفلونت
المصدر: كونفلونت
تأكد من تقييم وفهم أنواع العنقود المختلفة من مختلف البائعين المتاحة في السحابة العامة، بما في ذلك تكلفة التملك الكلية، الضمانات للتوفر، تكاليف النسخ الاحتياطي عبر المناطق أو مقدمي الخدمة السحابية، وما إلى ذلك. الفجوات والقيود غالبًا ما تكون مخفية بشكل مقصود في التفاصيل.
على سبيل المثال، إذا كنت تستخدم خدمة Amazon Managed Streaming for Apache Kafka (MSK)، يجب عليك أن تكون على علم بأن شروط الاستخدام تنص على أن “التزام الخدمة لا ينطبق على أي عدم توفر، أو تعليق، أو إنهاء … الذي يُسببه برنامج المحرك الأساسي Apache Kafka أو Apache Zookeeper والذي يؤدي إلى فشل الطلبات.”
ومع ذلك، فإن التسعير وضمانات الدعم ليست سوى قطعة واحدة حرجة من عملية المقارنة. هناك العديد من “قرارات البناء مقابل الشراء” التي يجب عليك اتخاذها كجزء من تقييم منصة تدفق البيانات.
تخزين Kafka: تخزين طبقاتي وتنسيق جداول Iceberg لتخزين البيانات مرة واحدة فقط
أضاف Apache Kafka تخزين متدرج لفصل الحوسبة عن التخزين. تمكن هذه القدرة من تحقيق بنية مؤسسية أكثر قابلية للتوسع والموثوقية وكفاءة تكلفة. يتيح تخزين متدرج لـ Kafka نوعًا جديدًا من عنقود Kafka: تخزين بيتابايتات من البيانات في سجل الالتزام في Kafka بطريقة كفؤة من حيث التكلفة (مثلما يحدث في بحيرة البيانات الخاصة بك) مع الطوابع الزمنية والترتيب المضمون للعودة في الزمن لإعادة معالجة البيانات التاريخية. KOR Financial هو مثال جيد على استخدام Apache Kafka كقاعدة بيانات للاحتفاظ بالبيانات لفترات طويلة.
تمكن Kafka من معمارية نقل اليسار لتخزين البيانات مرة واحدة فقط لمجموعات البيانات التشغيلية والتحليلية:

بهذا في الاعتبار، تفكر مرة أخرى في الحالات الاستخدام التي وصفتها أعلاه لعدة عناقيد Kafka. هل يجب عليك لا تزال تكرار البيانات على دفعات في الراحة في قاعدة البيانات، بحيرة البيانات، أو منزل البحيرة من مركز بيانات واحد أو منطقة سحابية إلى أخرى؟ لا. يجب عليك مزامنة البيانات في الوقت الحقيقي، وتخزين البيانات مرة واحدة (عادة في متجر كائني مثل Amazon S3)، ثم ربط جميع محركات التحليل مثل Snowflake، Databricks، Amazon Athena، Google Cloud BigQuery، وغيرها بتنسيق الجدول القياسي هذا.
قصص نجاح في العالم الحقيقي لعدة عناقيد Kafka
معظم المؤسسات لديها عدة عناقيد Kafka. تستكشف هذه القسم أربع قصص نجاح في قطاعات مختلفة:
- Paypal (خدمات مالية) – الولايات المتحدة: الدفع الفوري، منع الاحتيال.
- جيوسينما (شركة الاتصالات / الإعلام) – آسيا والمحيط الهادئ: تكامل البيانات، تحليلات النقرات، الإعلانات، التخصيص.
- أودي (السيارات / التصنيع) – أوروبا والشرق الأوسط وإفريقيا: السيارات المتصلة مع متطلبات حرجة وتحليلية.
- نيو ريليك (البرمجيات / السحابة) – الولايات المتحدة: المراقبة وإدارة أداء التطبيقات (APM) عبر العالم.
بايبال: الفصل حسب منطقة الأمان
بايبال هي منصة دفع رقمية تتيح للمستخدمين إرسال الأموال واستقبالها عبر الإنترنت بشكل آمن ومريح في جميع أنحاء العالم في الوقت الحقيقي. وهذا يتطلب بنية تحتية لـ Kafka قابلة للتوسيع وآمنة ومتوافقة.
خلال يوم الجمعة السوداء لعام 2022، بلغت حجم حركة مرور Kafka حوالي 1.3 تريليون رسالة يوميًا. حاليًا، لدى بايبال أكثر من 85 مجموعة Kafka، وفي كل موسم عطلات، يوسعون بنيتهم التحتية لـ Kafka للتعامل مع زيادة حركة المرور. تستمر منصة Kafka في التوسع بسلاسة لدعم نمو هذه الحركة دون أي تأثير على عملهم.
اليوم، تتكون أسطول Kafka لدى بايبال من أكثر من 1,500 وسيط يضمون أكثر من 20,000 موضوع. يتم استنساخ الأحداث بين المجموعات، مما يوفر توافرًا بنسبة 99.99٪.
يتم فصل نشر مجموعات Kafka في مناطق أمان مختلفة داخل مركز بيانات واحد:
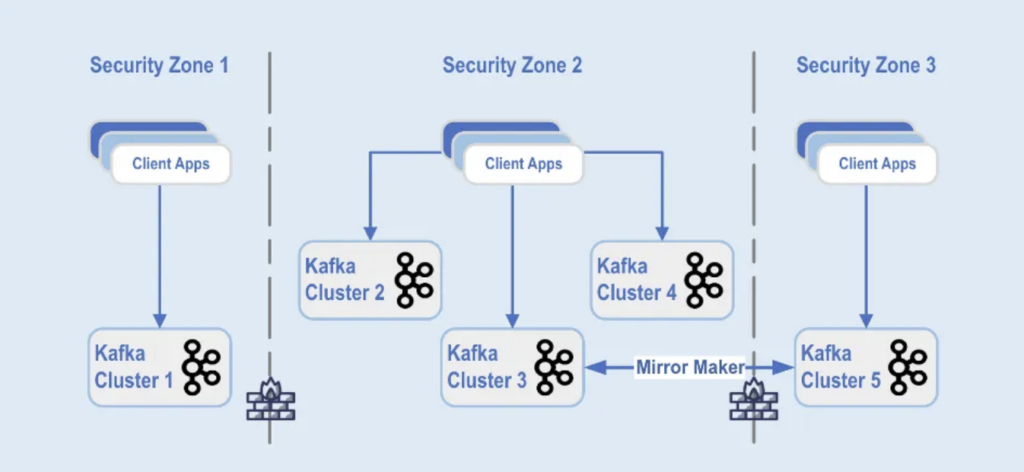 المصدر: باي بال
المصدر: باي بال
يتم نشر مجموعات Kafka عبر هذه المناطق الأمنية، استنادًا إلى تصنيف البيانات ومتطلبات العمل.يتم استخدام التكرار الفوري باستخدام أدوات مثل MirrorMaker (في هذا المثال، يعمل على بنية Kafka Connect) أو Confluent Cluster Linking (باستخدام نهج أبسط وأقل عرضة للأخطاء مباشرة باستخدام بروتوكول Kafka للتكرار) لعكس البيانات عبر مراكز البيانات، مما يساعد في الاستعادة من الكوارث وتحقيق التواصل بين مناطق الأمان.
JioCinema: فصل حسب حالة الاستخدام وSLA
JioCinema هي منصة بث فيديو متنامية بسرعة في الهند. يُعرف خدمة OTT للهاتف النقال بتقديمها لعروض محتوى واسعة، بما في ذلك الرياضات الحية مثل الدوري الهندي الممتاز (IPL) للكريكيت، ومركز أنمي الذي تم إطلاقه حديثًا، وخطط شاملة لتغطية الأحداث الكبرى مثل ألعاب أولمبياد باريس 2024.
تستفيد الهندسة المعمارية للبيانات من Apache Kafka وFlink وSpark لمعالجة البيانات، كما تم تقديمها في قمة Kafka Summit India 2024 في بنغالور:
 المصدر: JioCinema
المصدر: JioCinema
تلعب تدفق البيانات دورًا حيويًا في مختلف حالات الاستخدام لتحويل تجارب المستخدم وتوصيل المحتوى. أكثر من عشرة ملايين رسالة في الثانية تعزز التحليلات والبصمات الاستخدامية وآليات توصيل المحتوى.
تشمل حالات الاستخدام لـ JioCinema:
- الاتصال بين الخدمات
- سجل النقر/التحليلات
- متتبع الإعلانات
- التعلم الآلي والتخصيص
أوضح كوشال خاندلوال، رئيس منصة البيانات والتحليلات واستهلاكها في JioCinema، أنه ليس كل البيانات متساوية وتختلف الأولويات ومعايير الخدمة لكل حالة استخدام:
 المصدر: JioCinema
المصدر: JioCinema
تدفق البيانات هو رحلة. مثل العديد من المنظمات الأخرى في جميع أنحاء العالم، بدأت JioCinema بعقد كبير واحد لـ Kafka يستخدم 1000+ موضوع Kafka و 100,000+ قسمًا لـ Kafka لمختلف حالات الاستخدام. مع الوقت، تطوّر انفصال الاهتمامات بشأن حالات الاستخدام ومعايير الخدمة إلى عدة عقد Kafka متعددة:
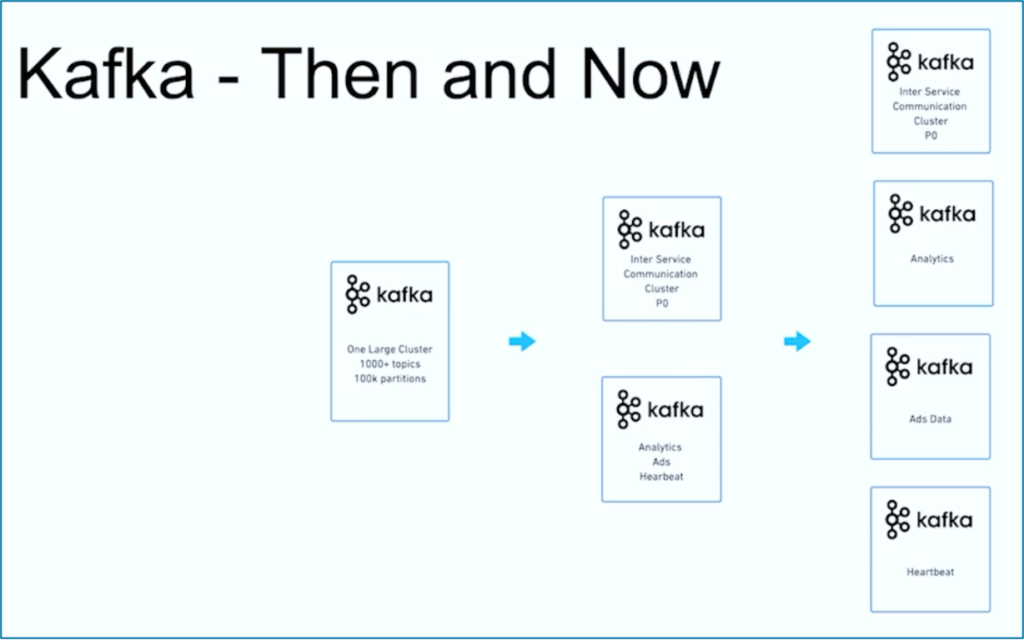 المصدر: JioCinema
المصدر: JioCinema
تُظهر قصة نجاح JioCinema تطورًا شائعًا لمنظمة بث بيانات. دعونا نكتشف الآن مثالًا آخر حيث تم نشر مجموعتين مختلفتين تمامًا من عنقودات Kafka من البداية لحالة استخدام واحدة.
Audi: العمليات مقابل التحليل للسيارات المتصلة
توفر شركة تصنيع السيارات أودي سيارات متصلة تضم تكنولوجيا متقدمة تدمج الاتصال بالإنترنت وأنظمة ذكية. تُمكن سيارات أودي الملاحة في الوقت الفعلي، والتشخيص عن بعد، وتحسين الترفيه داخل السيارة. تتميز هذه السيارات بخدمات Audi Connect. تشمل الميزات مكالمات الطوارئ، ومعلومات حركة المرور عبر الإنترنت، والتكامل مع أجهزة المنزل الذكي لتعزيز الراحة والسلامة للسائقين.
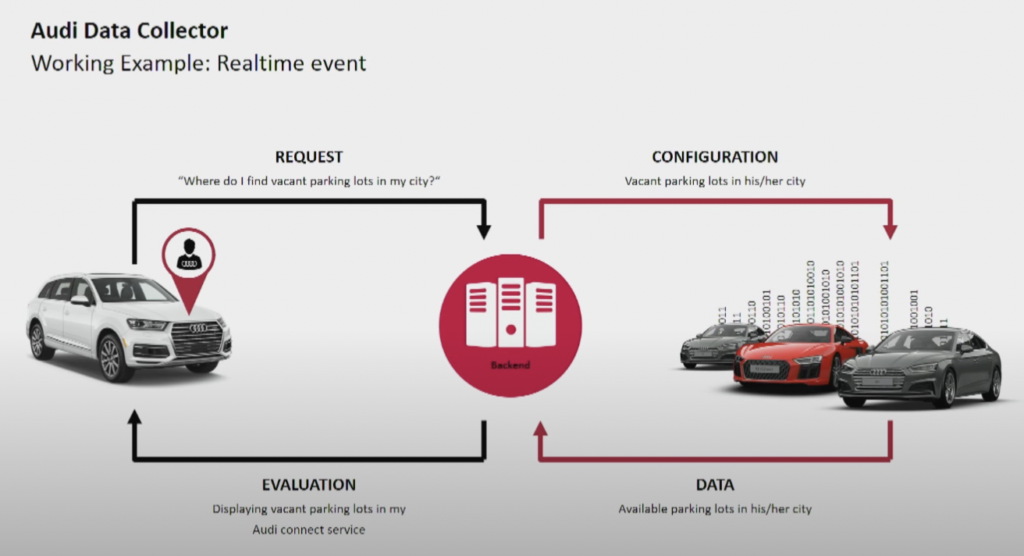 المصدر: أودي
المصدر: أودي
قدَّمت أودي بنية سيارتها المتصلة في الجلسة الرئيسية لقمة Kafka لعام 2018. تعتمد بنية أودي التنظيمية على عنقودي Kafka مع SLAs وحالات استخدام مختلفة تمامًا.
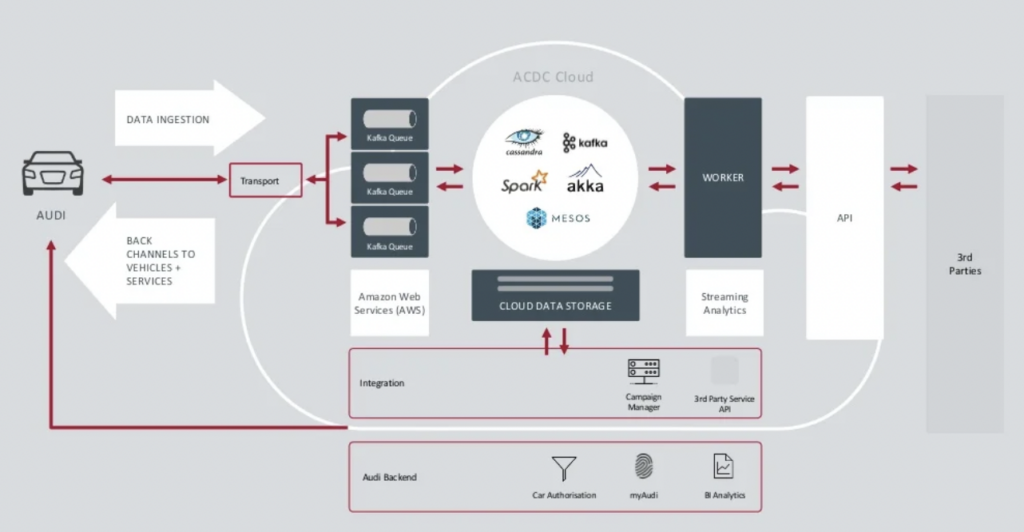 المصدر: أودي
المصدر: أودي
مجموعة بيانات Kafka Ingestion حيوية للغاية.يجب أن تعمل على مدار الساعة على نطاق واسع. إنها توفر الاتصال الأخير إلى الملايين من السيارات باستخدام Kafka و MQTT. القنوات العكسية من الجانب التكنولوجي إلى السيارة تساعد في التواصل مع الخدمات والتحديثات عبر الهواء (OTA).
مجموعة ACDC Cloud هي مجموعة Kafka لتحليلات هندسة السيارات المتصلة بشركة Audi. تعتبر المجموعة أساسًا للعديد من أعباء العمل التحليلية، التي تعالج حجومًا هائلة من بيانات الإنترنت من الأشياء والسجلات على نطاق واسع باستخدام إطر الدفعة مثل Apache Spark.
تم تقديم هذه البنية المعمارية بالفعل في عام 2018. شعار Audi “التقدم من خلال التكنولوجيا” يظهر كيف قامت الشركة بتطبيق تكنولوجيا جديدة للابتكار قبل أن يطبق معظم مصنعي السيارات سيناريوهات مماثلة. يتم معالجة جميع بيانات الاستشعار من السيارات المتصلة في الوقت الحقيقي وتخزينها للتحليل التاريخي والإبلاغ.
New Relic: مراقبة متعددة السحابة على مستوى العالم
نيو ريليك هي منصة مراقبة مستندة إلى السحابة توفر مراقبة أداء في الوقت الحقيقي وتحليلات للتطبيقات والبنية التحتية للعملاء في جميع أنحاء العالم.
أندرو هارتنت، نائب رئيس هندسة البرمجيات في New Relic، يشرح كيف أن تدفق البيانات أمر حاسم لنموذج الأعمال بأكمله في New Relic:
“كافكا هو جهاز الجهاز العصبي المركزي لدينا. إنه جزء من كل ما نقوم به. معظم الخدمات عبر 110 فريقًا هندسيًا مختلفًا بمئات الخدمات تلمس كافكا بطريقة ما في شركتنا، لذلك فإنه حقًا أمر حيوي. ما كنا نبحث عنه هو القدرة على النمو، وقدمت Confluent Cloud ذلك.”
قامت New Relic بامتصاص ما يصل إلى 7 مليار نقطة بيانات في الدقيقة وتتجه نحو استيعاب 2.5 إكسابايت من البيانات في عام 2023. ومع توسيع New Relic لاستراتيجياتها متعددة السحاب، ستستخدم الفرق Confluent Cloud للحصول على عرض شامل عبر جميع البيئات.
“نيو ريليك متعدد السحب. نريد أن نكون حيث يكون عملاؤنا. نريد أن نكون في تلك البيئات نفسها، في تلك الإقليم، وأردنا أن يكون كافكا معنا هناك.” يقول آرتنيت في دراسة حالة لشركة Confluent.
تعتبر تجمعات كافكا المتعددة النموذج، وليست استثناء
الهندسة المعمارية المدفوعة بالأحداث ومعالجة التيارات موجودة منذ عقود. يزداد اعتمادها باستخدام أطر عمل مفتوحة المصدر مثل Apache Kafka و Flink بالاقتران مع خدمات السحابة المدارة بالكامل. تزداد المزيد من المؤسسات صعوبة التعامل مع توسع كافكا. تقوم حوكمة البيانات على مستوى المؤسسة، ومركز التميز، والتشغيل والنشر الآلي، وأفضل الممارسات في الهندسة المعمارية بالمؤسسة بمساعدة توفير بيانات التدفق بنجاح مع تجمعات كافكا المتعددة لنطاقات الأعمال المستقلة أو المتعاونة.
العديد من مجموعات Kafka هو القاعدة، وليس الاستثناء. حالات الاستخدام مثل التكامل الهجين، واستعادة الكوارث، والهجرة، أو التجميع تمكّن من تشغيل تدفق البيانات في الوقت الحقيقي في كل مكان مع متطلبات خدمة المستوى.
Source:
https://dzone.com/articles/apache-kafka-cluster-type-deployment-strategies