













Преобразование ваших исходных данных в организованную и действенную информацию может показаться сложным. Но не когда у вас есть быстрое и эффективное решение. Не волнуйтесь! Этот учебник по AWS Glue для начинающих поможет вам.
В этом учебнике вы узнаете ключевые шаги конфигурации и выполнения преобразований данных с помощью AWS Glue.
Исследуйте и оптимизируйте подготовку данных для облачного анализа!
Предварительные требования
Перед началом работы с AWS Glue убедитесь, что у вас есть аккаунт в Amazon Web Services (AWS) с активированным биллингом. Для этого урока подойдет бесплатный аккаунт.
Создание IAM-роли для AWS Glue
Перед выполнением задания по преобразованию вам необходимо создать роль Identity and Access Management (IAM), которая предоставит разрешения на доступ к сервису AWS Glue. Эта роль определяет, к каким ресурсам AWS Glue разрешен доступ в вашем аккаунте AWS.
Чтобы создать IAM-роль, выполните следующие шаги:
1. Откройте предпочтительный веб-браузер и войдите в Консоль управления AWS.
2. Поиск и выбор IAM в списке результатов для доступа к консоли IAM.
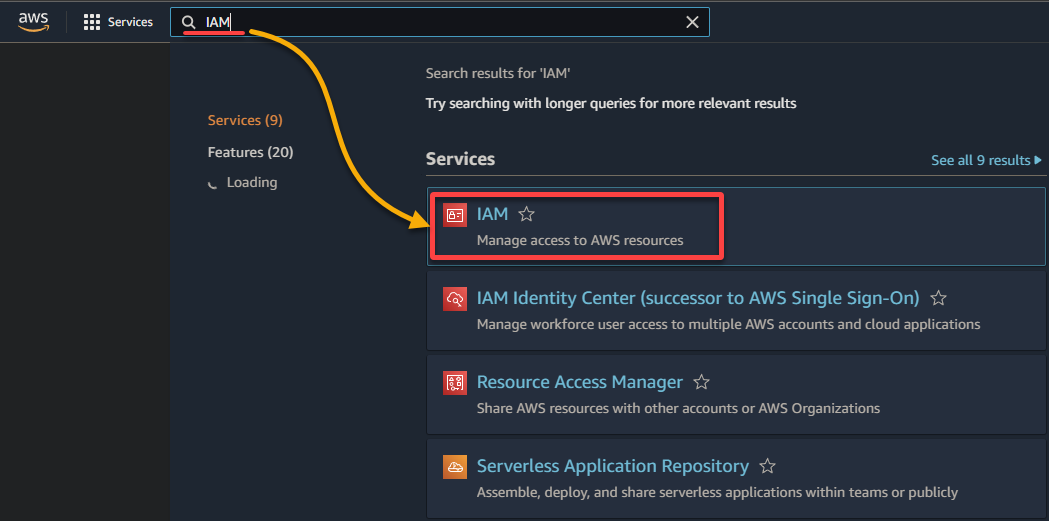
3. В консоли IAM перейдите к Ролям (левая панель) и нажмите Создать роль (вверху справа), перенаправив ваш браузер на новую страницу, посвященную настройке роли.

4. Теперь настройте следующие параметры для роли:
- Тип доверенной сущности – Выберите службу AWS, чтобы служба AWS доверяла роли. Это позволяет этой службе принимать роль и действовать от вашего имени.
- Вариант использования – Выберите Glue в разделе Варианты использования для других служб AWS, поскольку вы создадите роль IAM специально для AWS Glue, и нажмите Далее.
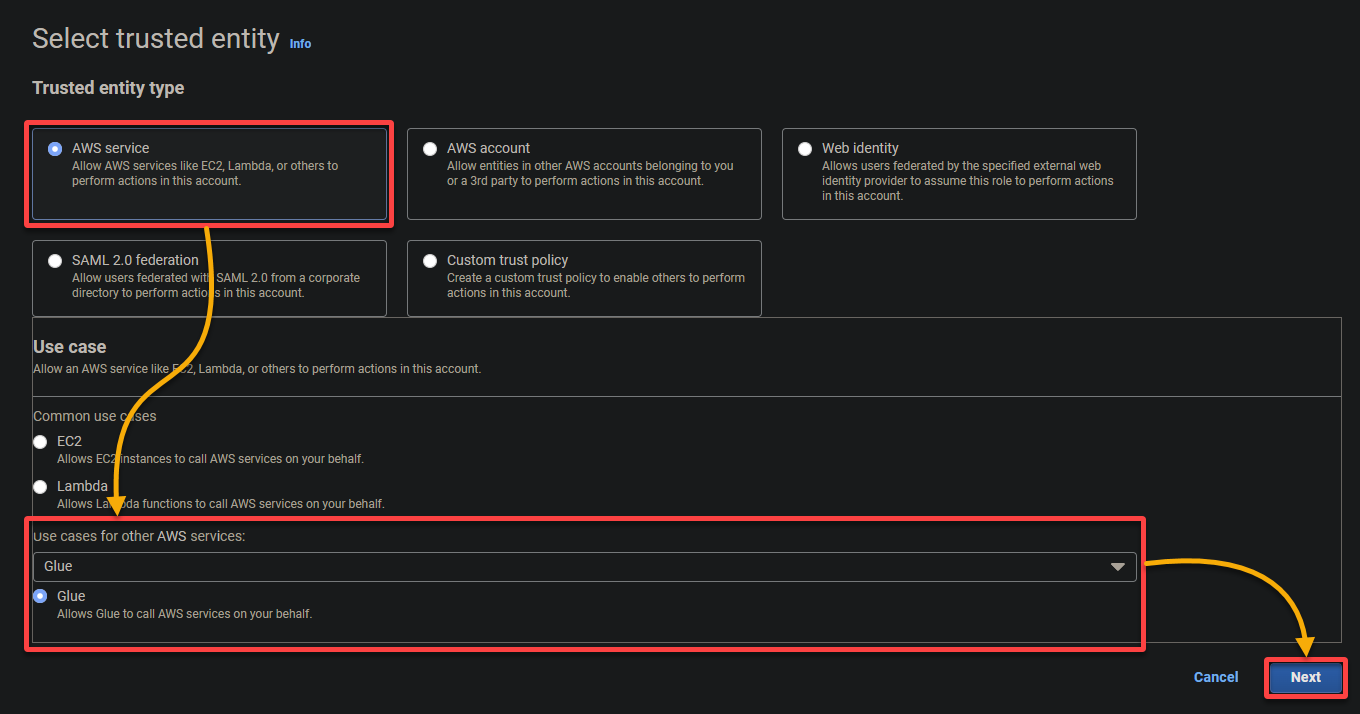
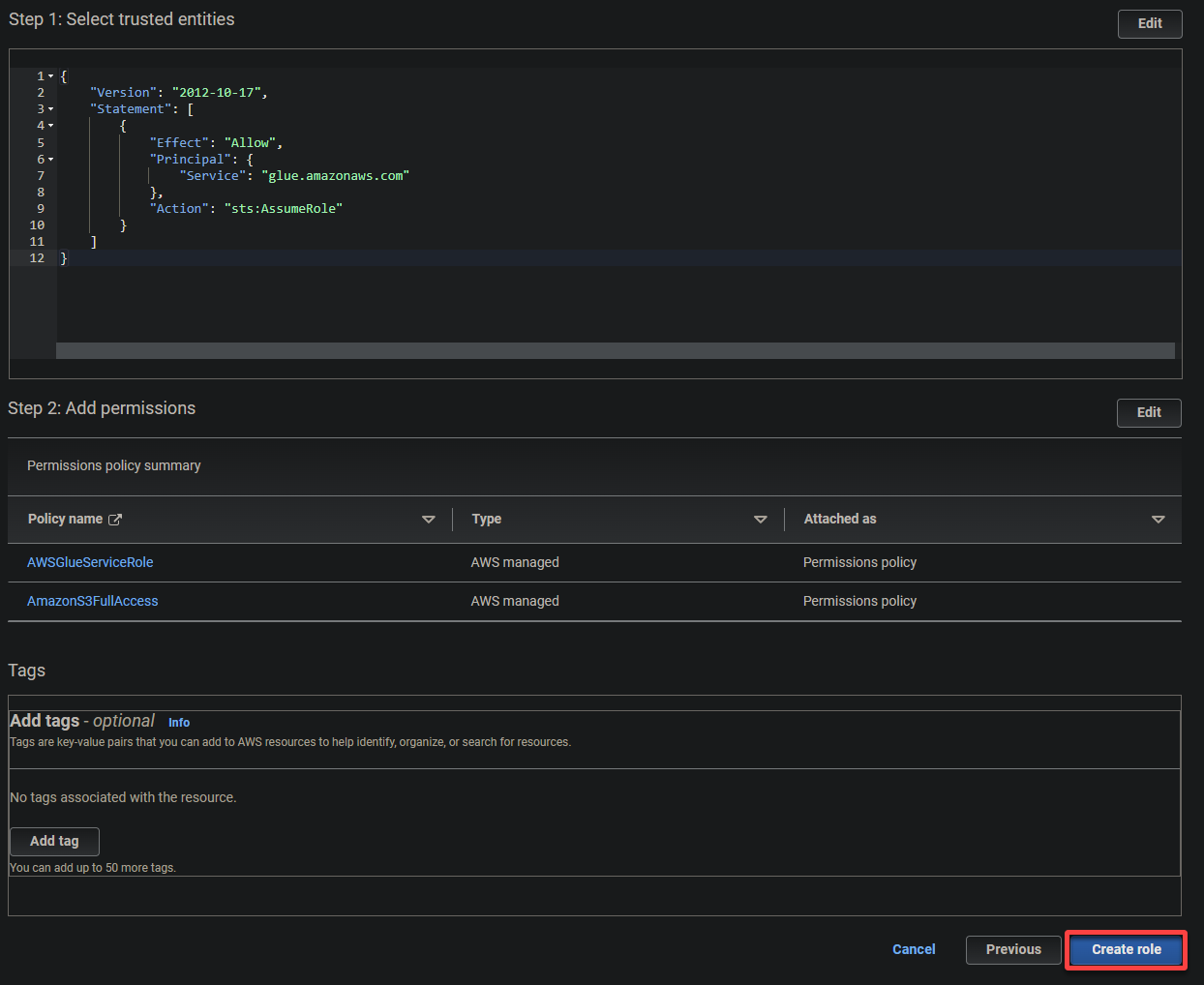
5. Поиск и выбор следующих политик, и нажмите Далее.
- AWSGlueServiceRole – Предоставляет службе AWS Glue необходимые разрешения для выполнения ее операций.
- S3FullAccess – Предоставляет полный доступ к ресурсам S3, позволяя AWS Glue читать и записывать в бакеты S3.
AWS Glue требуется обширные разрешения для чтения и записи в бакеты S3 для эффективного выполнения своих задач по извлечению, трансформации и загрузке (ETL) данных.
? Избегайте предоставления ненужных избыточных разрешений, так как они могут представлять угрозу безопасности.
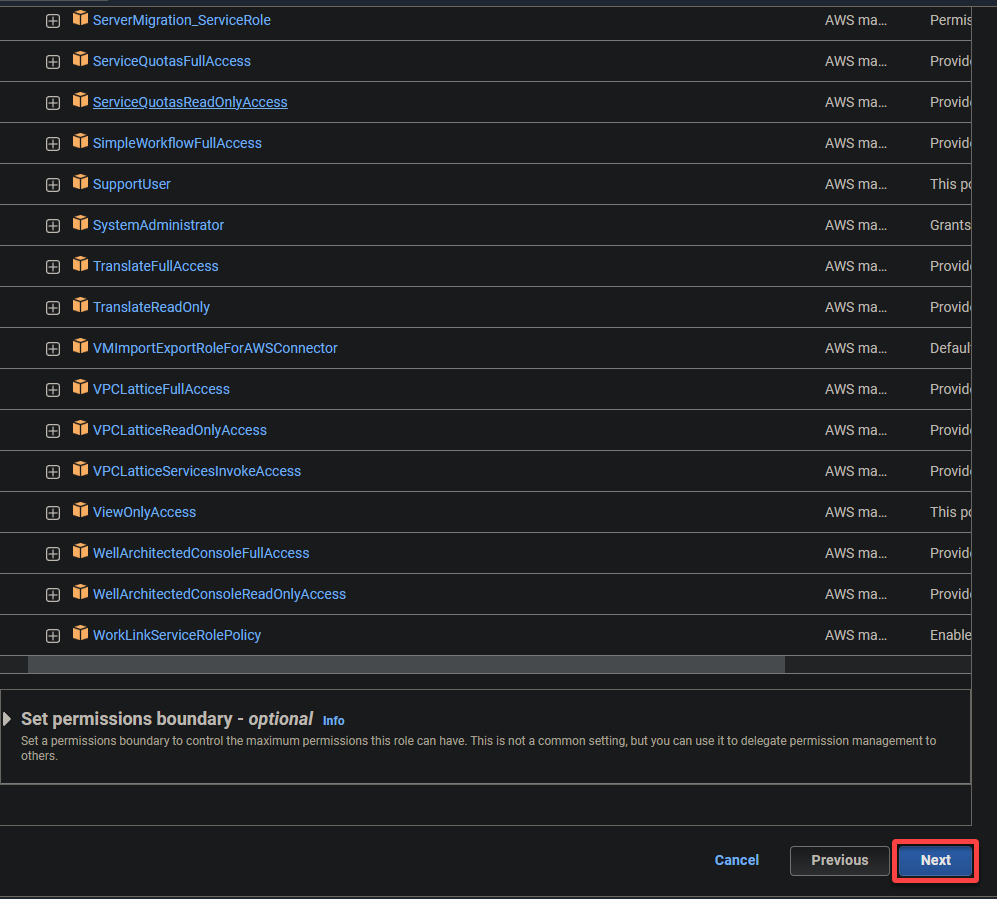
6. Укажите описательное имя для роли (например, glue_role) и описание.
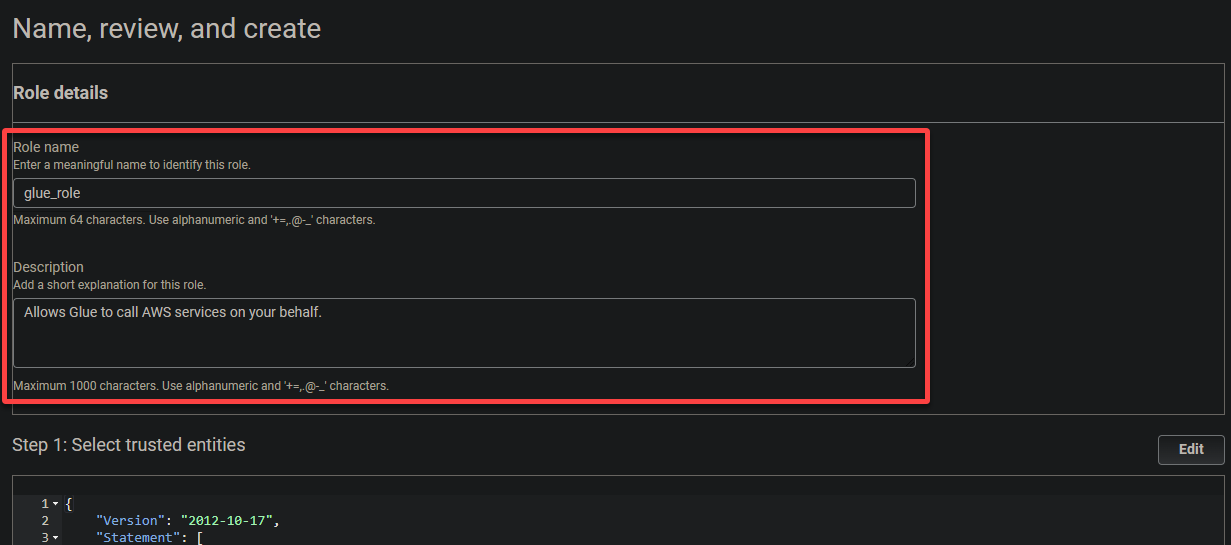
7. Наконец, прокрутите вниз, проверьте ваши настройки и нажмите Создать роль (в правом нижнем углу), чтобы завершить создание роли.
Создание бакета S3 и загрузка образца файла
Теперь, когда у вас есть роль IAM для AWS Glue, вам нужно место для хранения ваших данных, а именно, бакет S3. Бакет S3 предоставляет централизованное место для хранения данных, которые будет обрабатывать AWS Glue.
В этом примере AWS Glue будет использовать AWS S3 в качестве хранилища данных для различных операций, таких как извлечение данных, преобразование и загрузка (ETL).
Чтобы создать бакет S3 и загрузить образец файла, выполните следующие шаги:
1. Скачайте образец файла данных (например, набор данных Every Politician) на ваш компьютер. Этот файл содержит неструктурированную коллекцию записей, которая будет служить входными данными для работы преобразования AWS Glue.
2. Найдите и выберите службу S3, чтобы получить доступ к консоли S3.
3. Нажмите Создать бакет, чтобы начать создание нового бакета S3.

4. Теперь укажите уникальное имя для вашего бакета (например, sampledata54675) и выберите регион, где должен находиться бакет.
A unique name lets you avoid conflicts with existing bucket names is crucial, while the region selection determines the physical location of your bucket’s data.
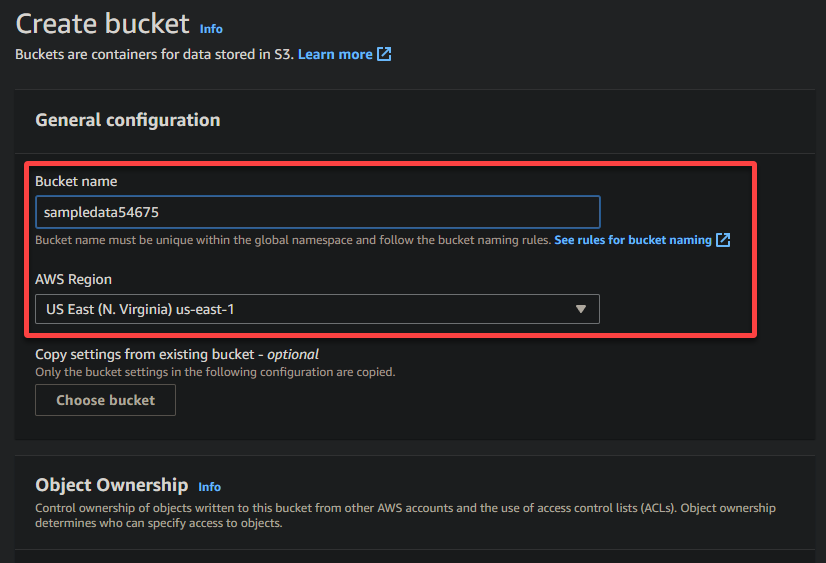
5. Прокрутите вниз, оставьте другие параметры как есть, и нажмите Создать бакет, чтобы создать бакет.

6. После создания нажмите на гиперссылку для нового бакета S3, чтобы перейти к нему.

7. Нажмите Загрузить и найдите образец файла, который вы хотите загрузить.
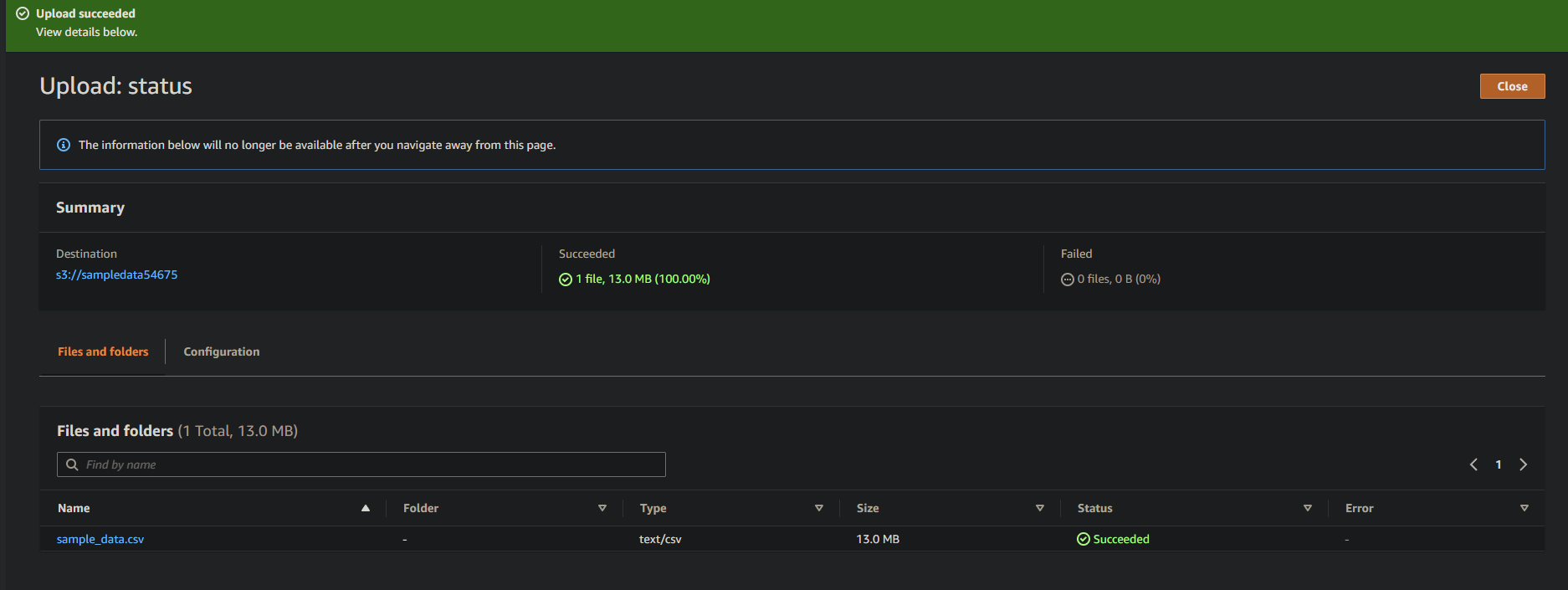
8. Наконец, оставьте остальные настройки без изменений и нажмите Загрузить, чтобы загрузить образец файла в только что созданный бакет.
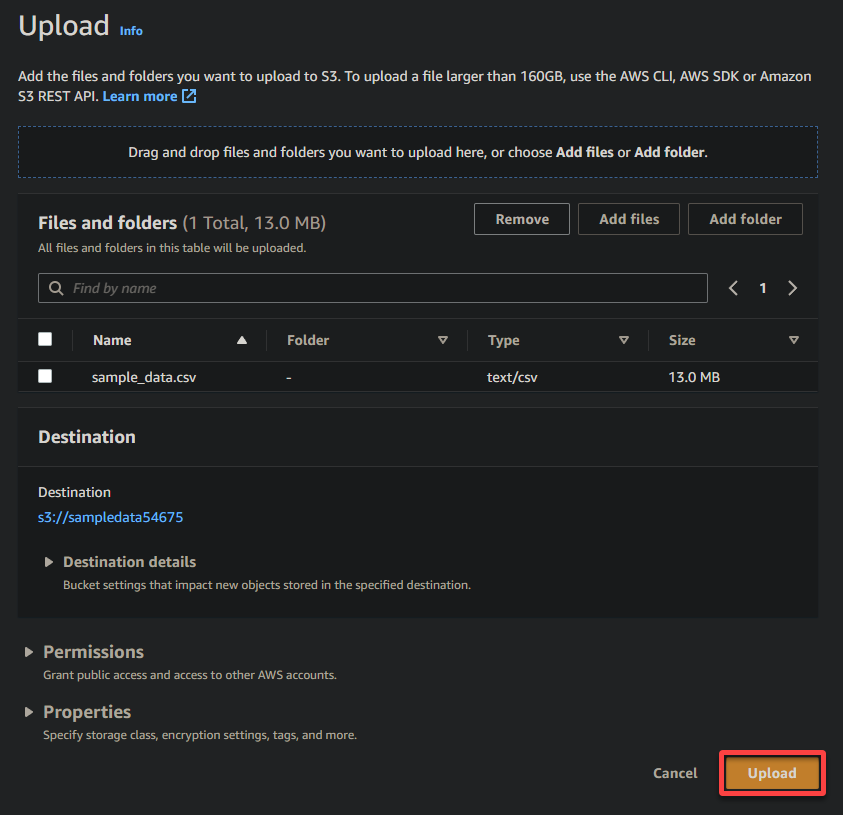
При успешной загрузке вы увидите свой только что загруженный файл в вашем бакете, как показано ниже.
Создание сканера Glue для сканирования и каталогизации данных
Вы только что загрузили образец данных в свой бакет S3, но так как они в настоящее время неструктурированные, вам нужен способ прочитать данные и построить каталог метаданных. Как? Создав сканер клея, который автоматически сканирует и каталогизирует данные.
Чтобы создать сканер клея, выполните следующие шаги:
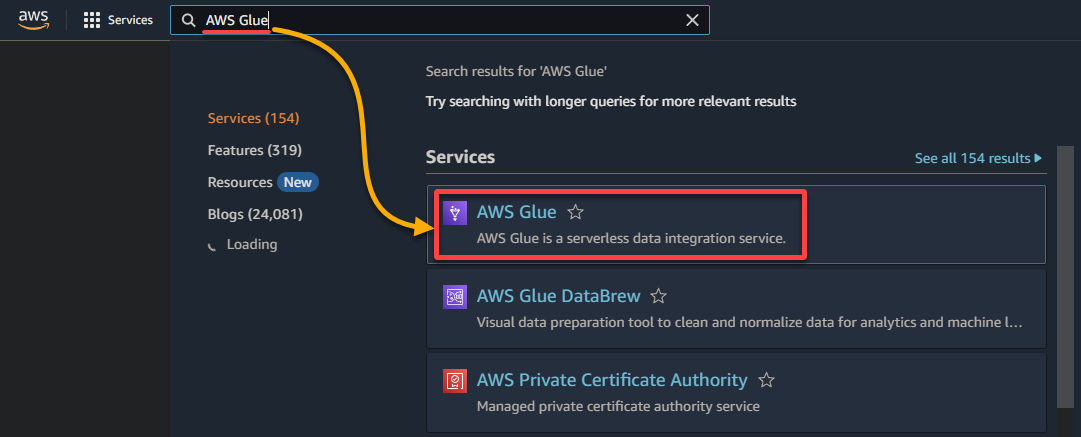
1. Перейдите в консоль AWS Glue через консоль управления AWS, как показано ниже.
2. Затем перейдите к Сканеру (левая панель) и нажмите Добавить сканер (в верхнем правом углу) , чтобы начать создание нового сканера клея.
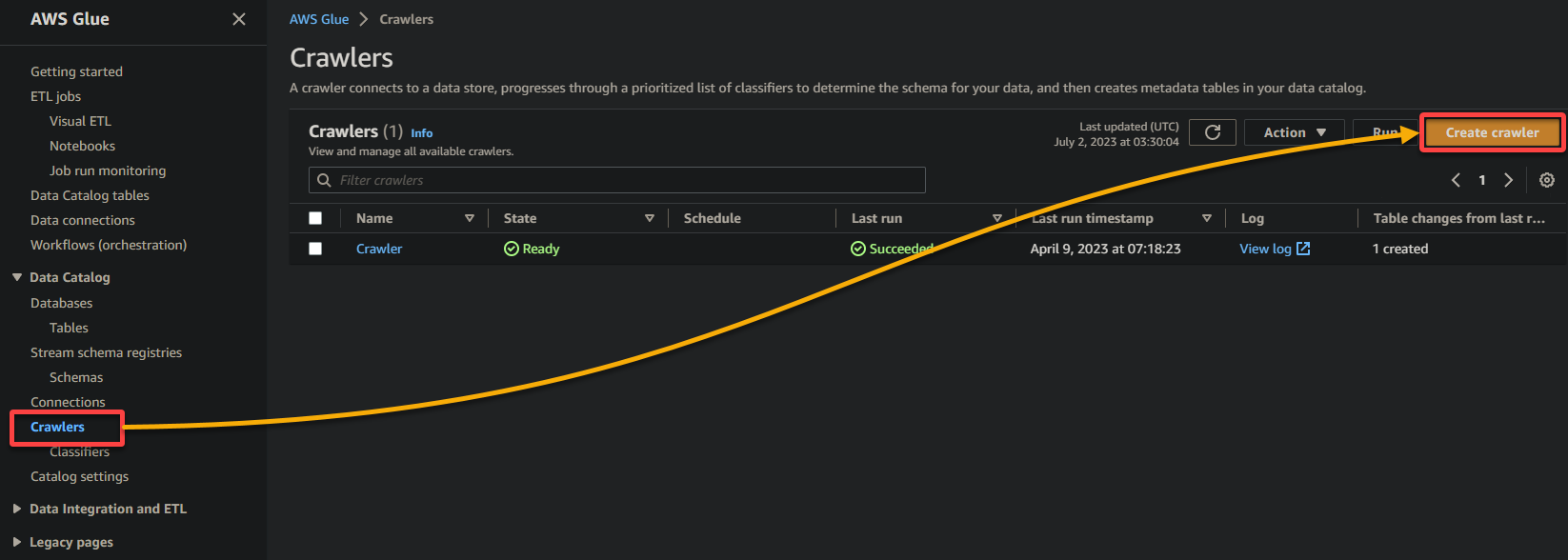
3. Укажите описательное имя (например, glue_crawler) и описание для сканера, оставьте остальные настройки без изменений и нажмите Далее.
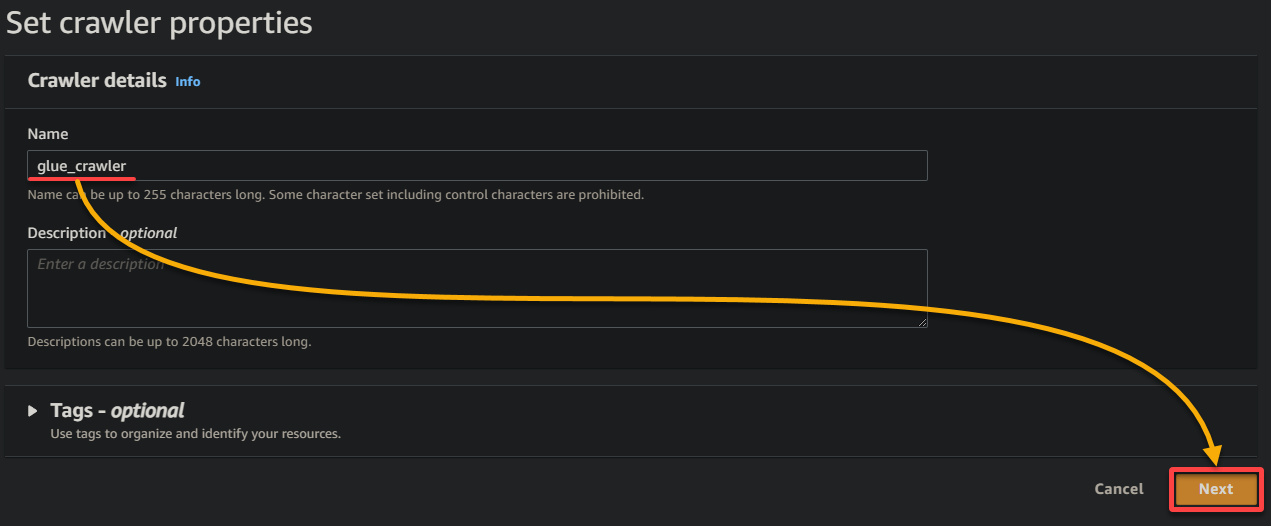
4. Теперь нажмите Добавить источник данных в разделе Источники данных, чтобы начать добавление нового источника данных в сканер.
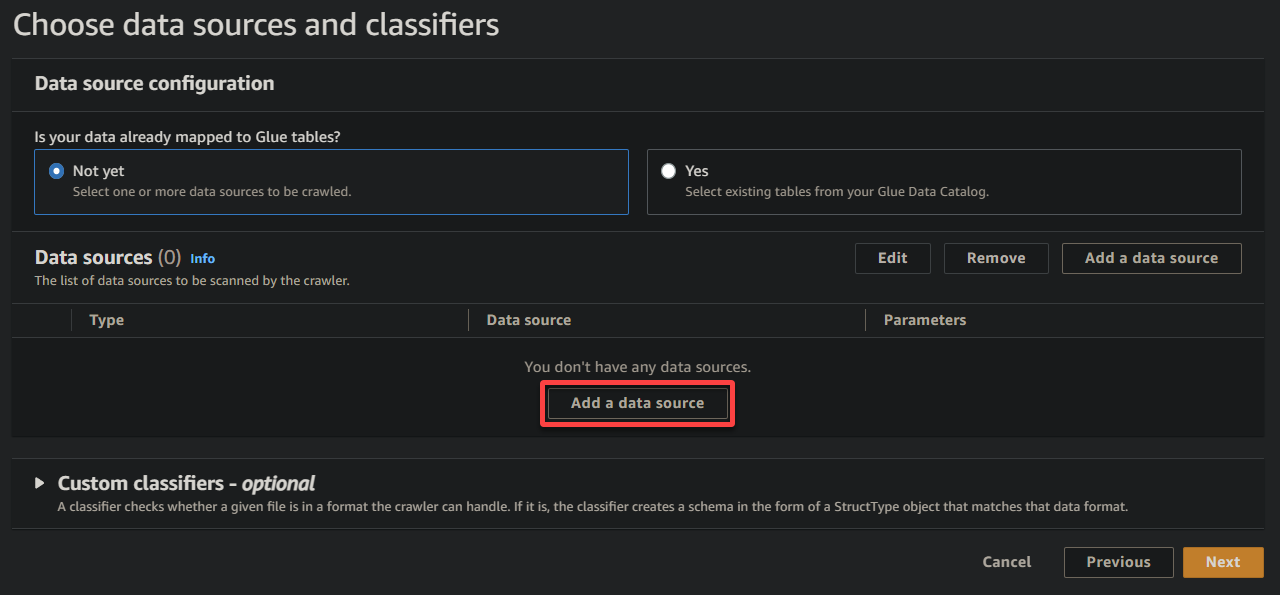
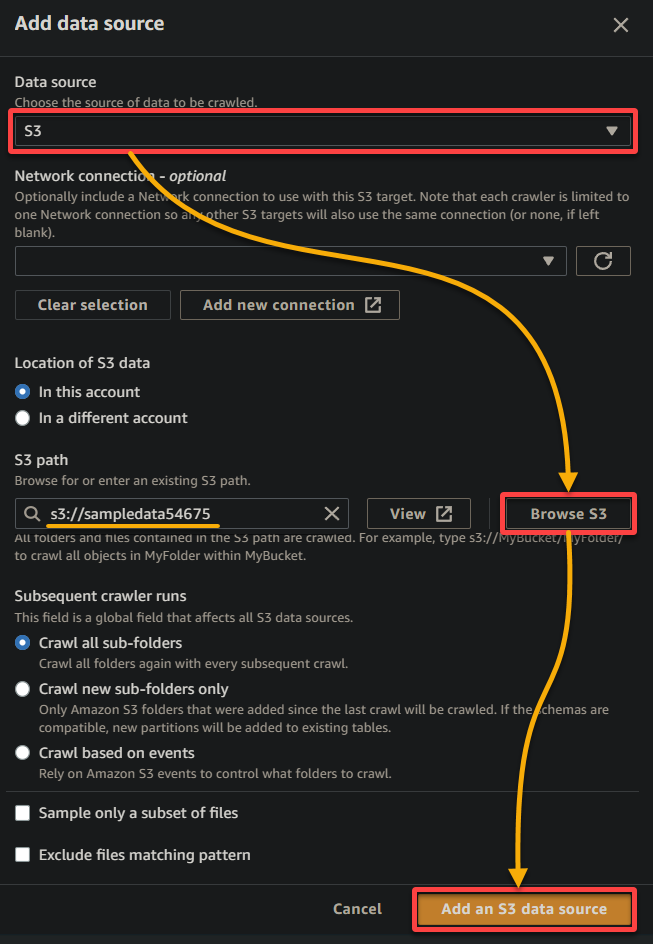
5. Во всплывающем окне настройте источник данных следующим образом:
- Источник данных – Выберите S3, так как ваши данные находятся в вашем бакете S3.
- Путь S3 – Нажмите Обзор S3 и выберите бакет, содержащий ваши загруженные образцовые данные (sampledata54675).
- Оставьте остальные настройки без изменений и нажмите Добавить источник данных S3, чтобы добавить образцовые данные в краулер.
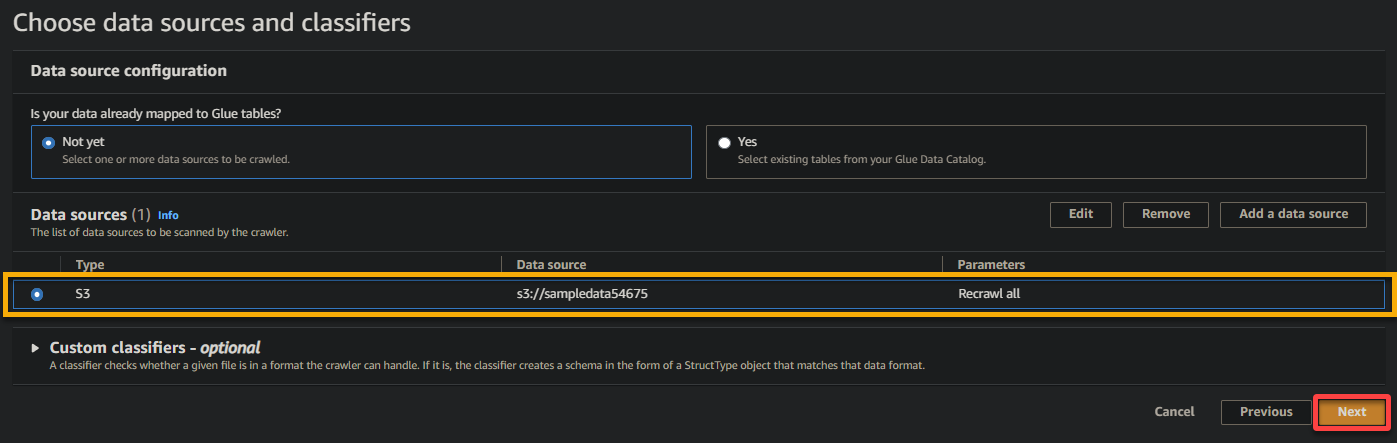
6. После настройки проверьте источник данных, как показано ниже, и нажмите Далее, чтобы продолжить.
7. На следующем экране выберите ранее созданную роль IAM (glue_role), оставьте остальные настройки без изменений, и нажмите Далее.
8. В разделе вывода и планирования нажмите Добавить базу данных, чтобы начать добавление новой базы данных для хранения обработанных данных и метаданных, созданных вашим краулером. Это действие откроет новую вкладку браузера, где вы настроите детали вашей базы данных (шаг восемь).
Эта база данных обеспечивает структурированное представление данных для запросов и анализа.
9. На новой вкладке браузера укажите описательное имя базы данных (например, glue_database) и нажмите Создать базу данных, чтобы создать базу данных.
10. Вернитесь на предыдущую вкладку браузера, выберите вновь созданную базу данных (glue_database) из выпадающего списка, оставьте остальные настройки без изменений и нажмите Далее.
11. В конечном итоге пересмотрите ваши настройки на последнем экране, чтобы убедиться, что они верны, и нажмите Создать краулер (внизу справа), чтобы создать нового краулера.
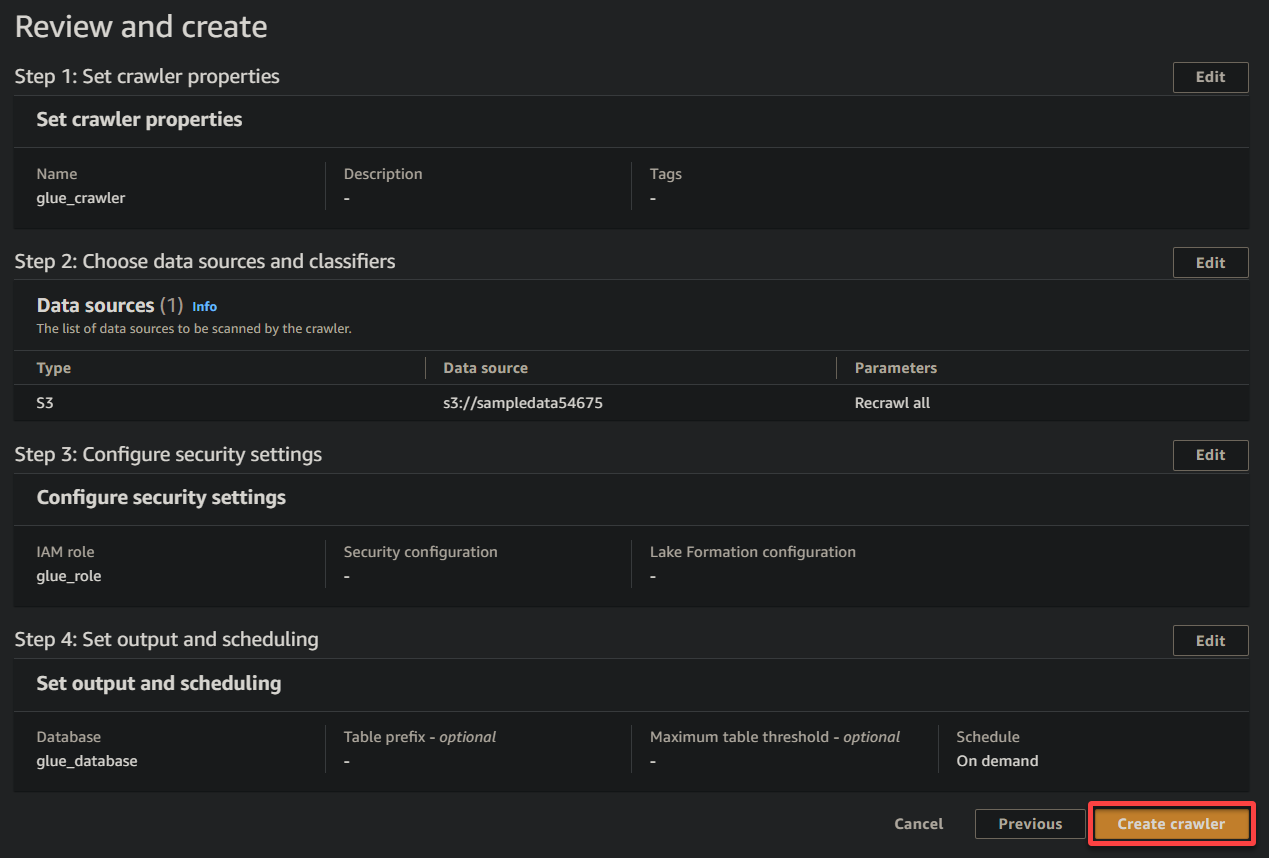
Если все прошло успешно, вы увидите экран, подтверждающий успешное создание краулера. Не закрывайте этот экран; вы запустите этот краулер в следующем разделе.
Запуск веб-паука Glue для создания каталога метаданных
С новым веб-пауком, который у вас теперь есть, запуск веб-паука является неотъемлемым этапом для начала процесса сканирования и каталогизации. Ваш веб-паук Glue создаст каталог метаданных, предоставляющий структурированное представление ваших данных для запросов и анализа.
Чтобы запустить созданный вами веб-паук Glue:
1. На странице с подробностями веб-паука щелкните Запустить веб-паук в разделе Запуски веб-паука, чтобы начать выполнение веб-паука.
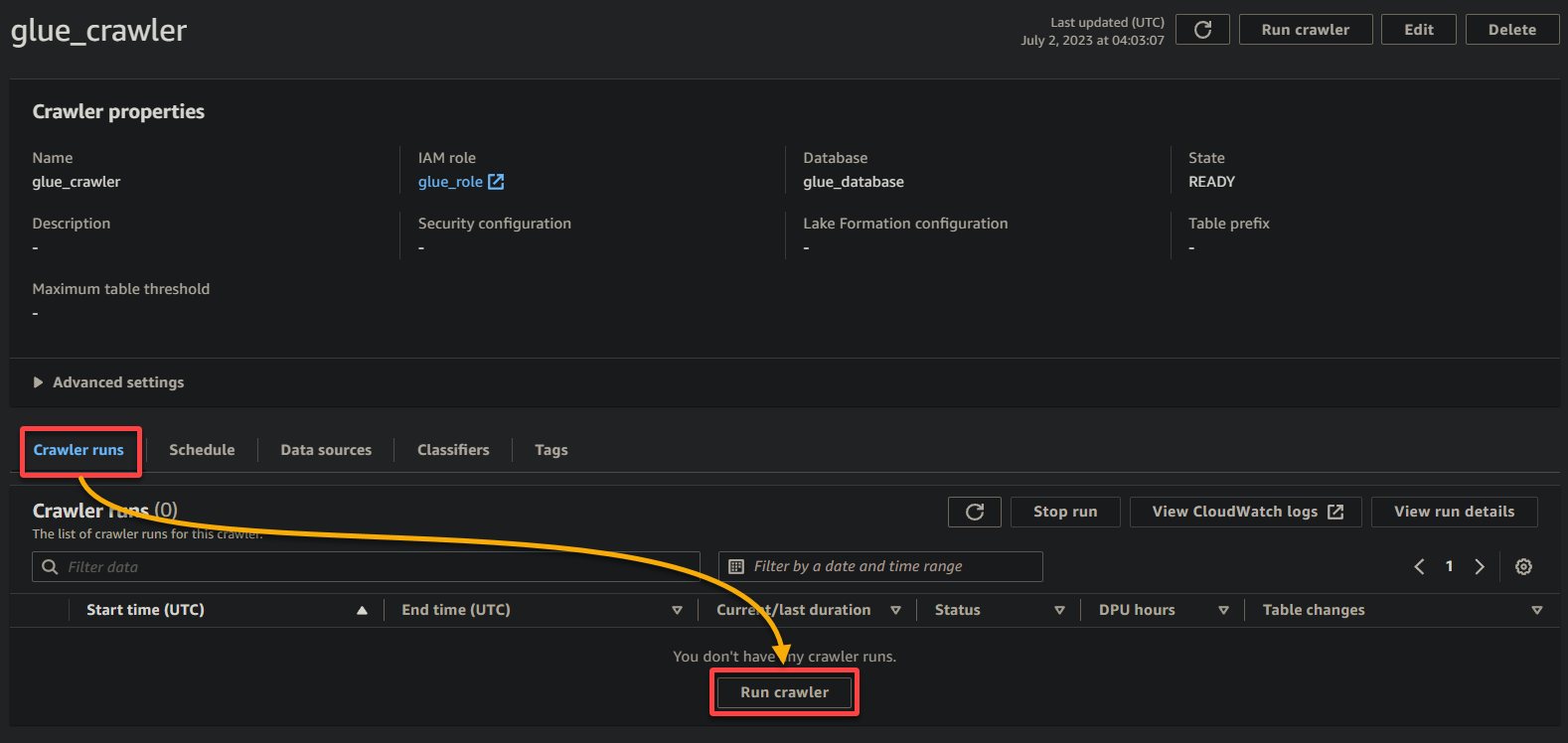
Как только веб-паук начнет выполнение, вы увидите его статус и прогресс на странице с подробностями веб-паука.
В зависимости от размера и сложности ваших данных выполнение веб-паука может занять некоторое время. Вы можете периодически обновлять страницу, чтобы видеть обновленный статус веб-паука.
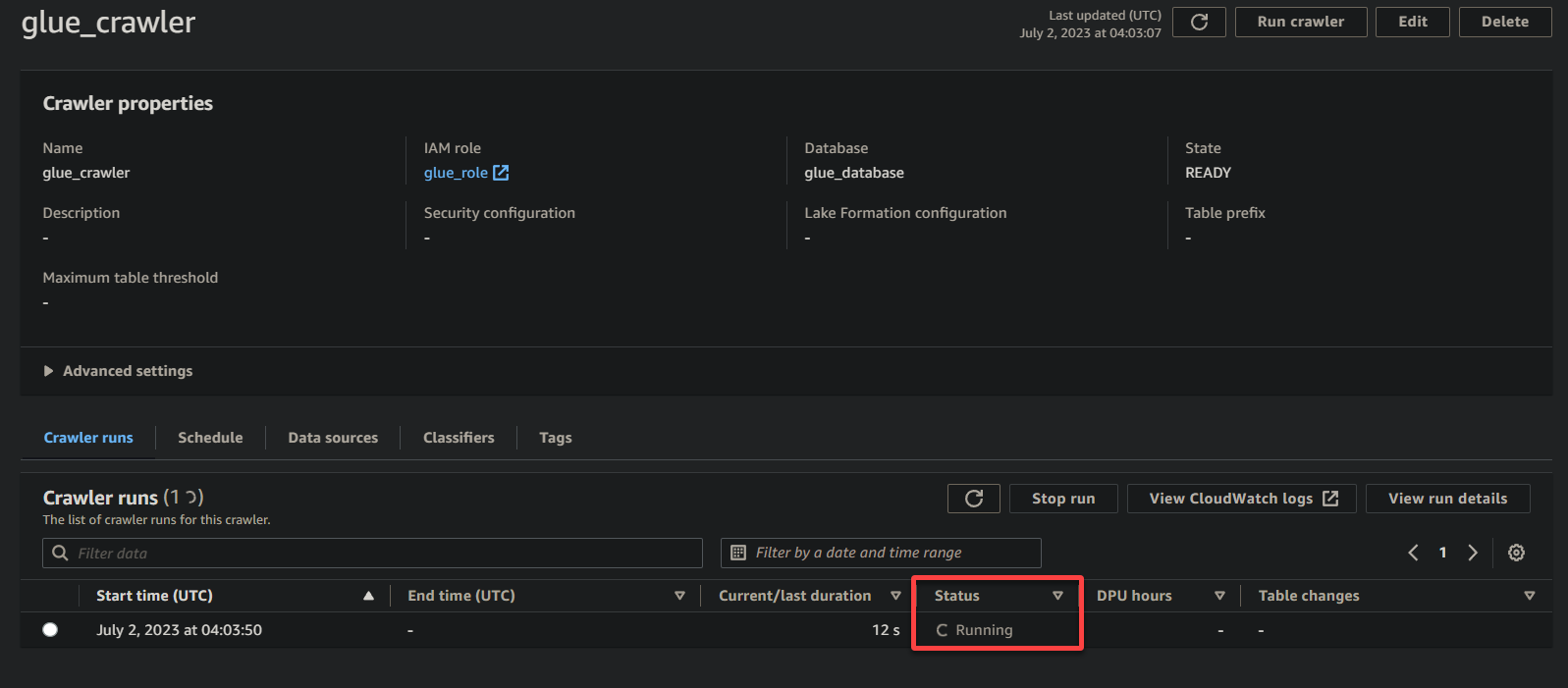
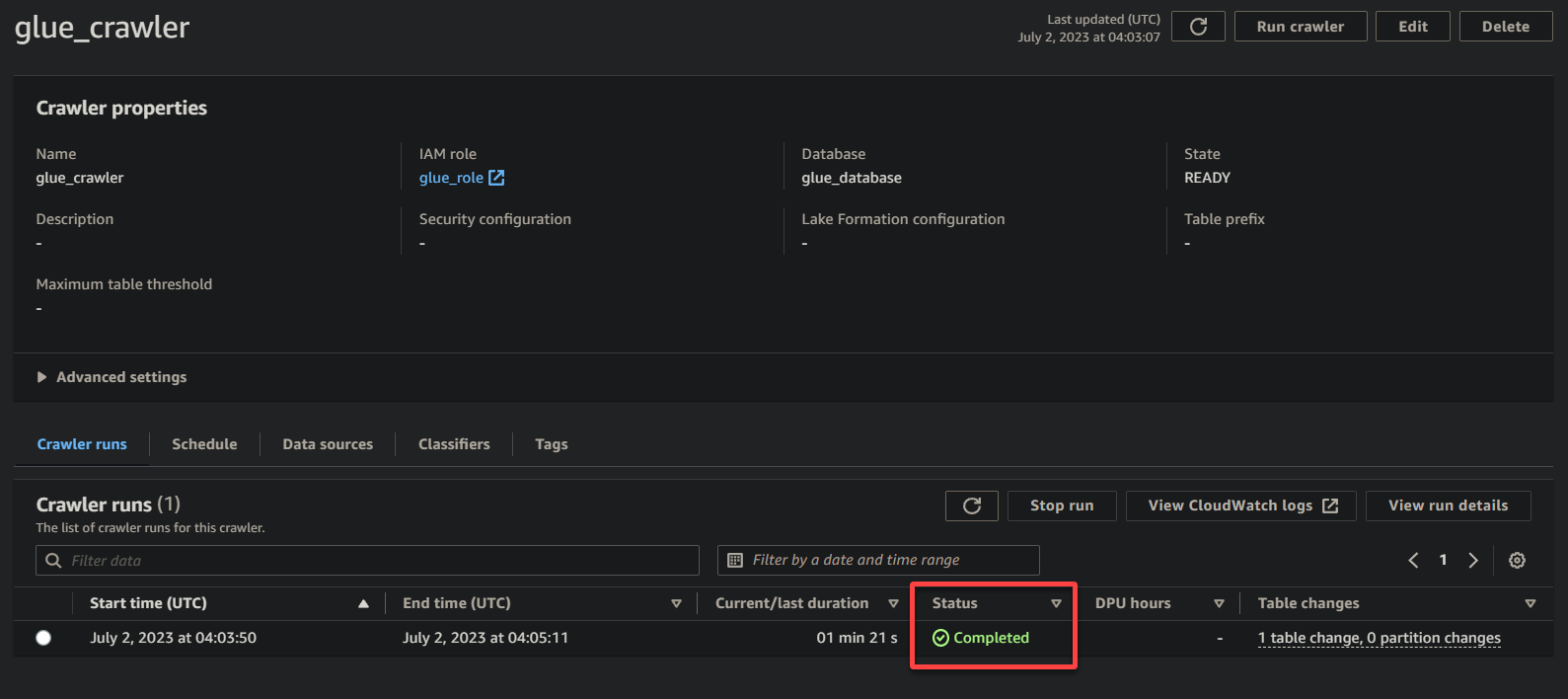
После завершения выполнения веб-паука его статус изменится на Завершено, как показано ниже. На этом этапе вы можете продолжить с выполнением запросов к вашим данным.
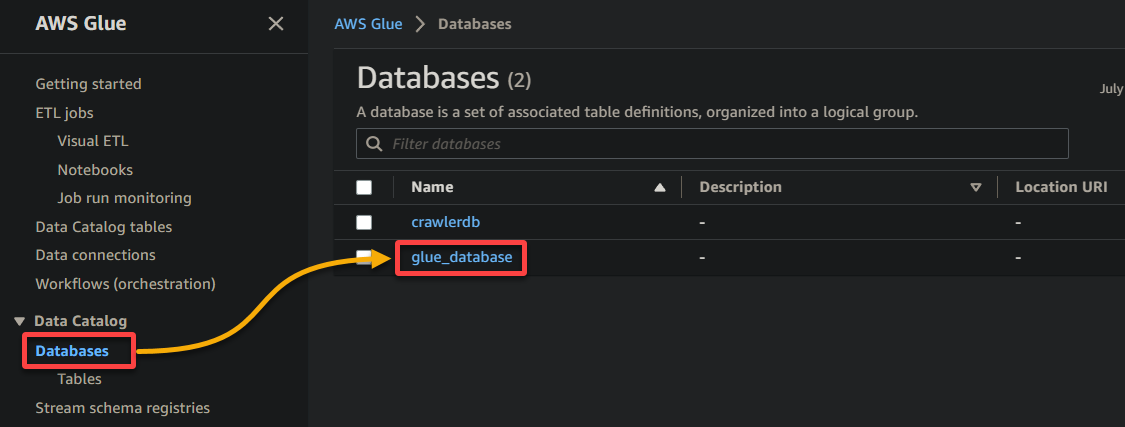
2. Затем перейдите в раздел База данных (левая панель) и щелкните по вашей базе данных, чтобы получить доступ к ее свойствам и таблицам.
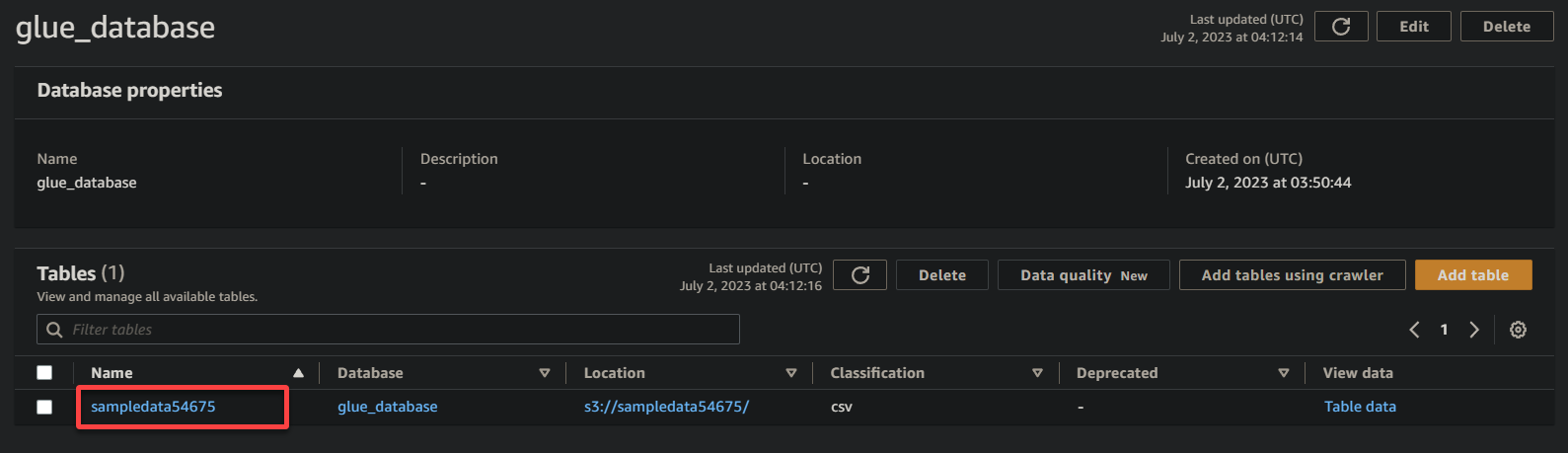
3. Наконец, щелкните по имени вашего ведра (sampledata54675), теперь таблицы, чтобы просмотреть хранящиеся в ней данные.
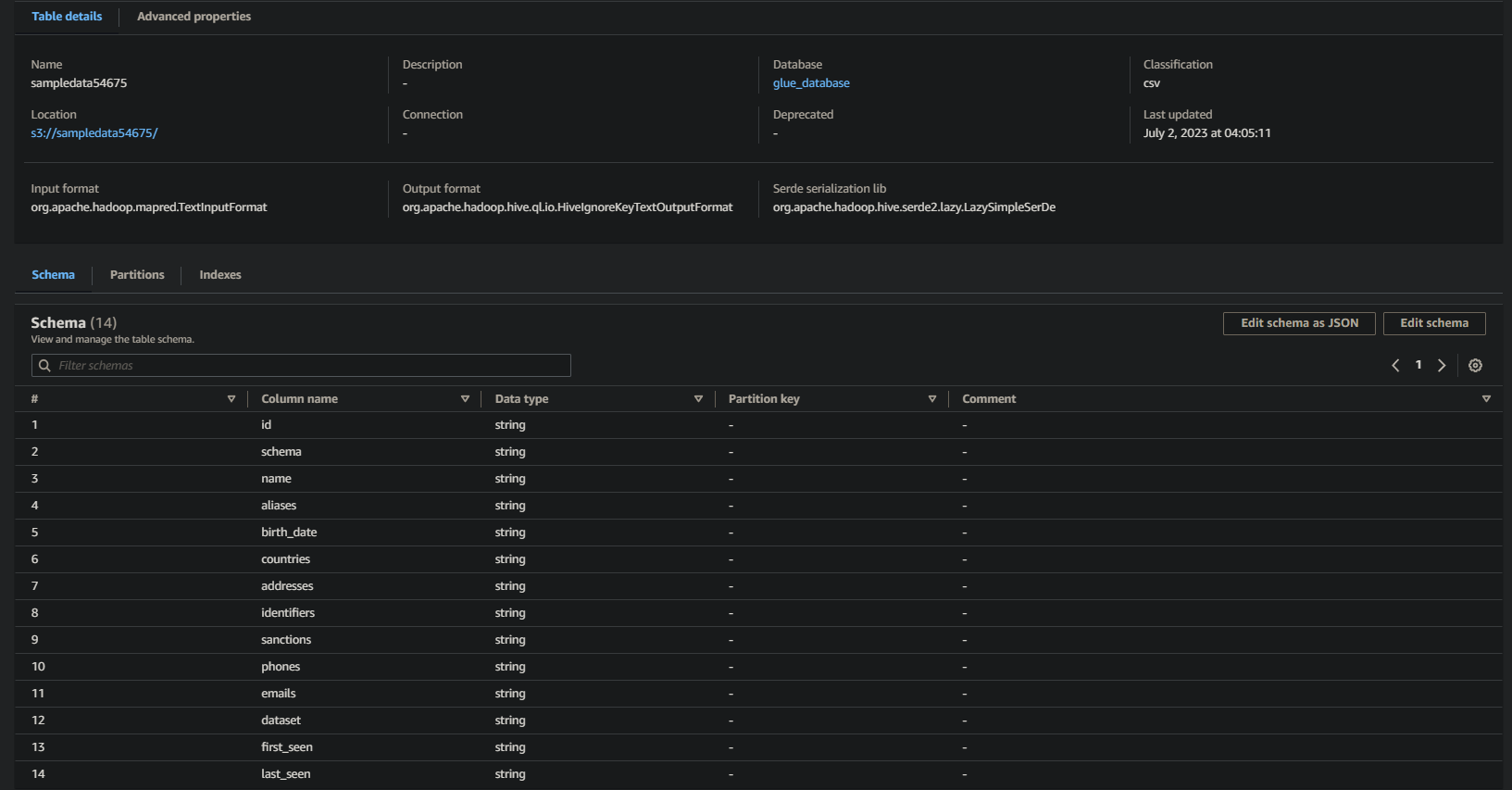
Если успешно, вы увидите информацию, подобную приведенной ниже. Эта информация подтверждает, что данные успешно преобразованы в таблицу базы данных, предоставляя ценные детали.
Запрос данных из каталога с использованием AWS Athena
Теперь, когда ваши данные доступны в каталоге данных AWS Glue, вы можете использовать различные инструменты для запросов и анализа данных. Одним из таких инструментов является AWS Athena – интерактивный сервис запросов, который позволяет анализировать данные в облаке с использованием стандартного SQL.
Для запроса данных с использованием AWS Athena выполните следующие шаги:
1. Найдите и откройте консоль Athena.
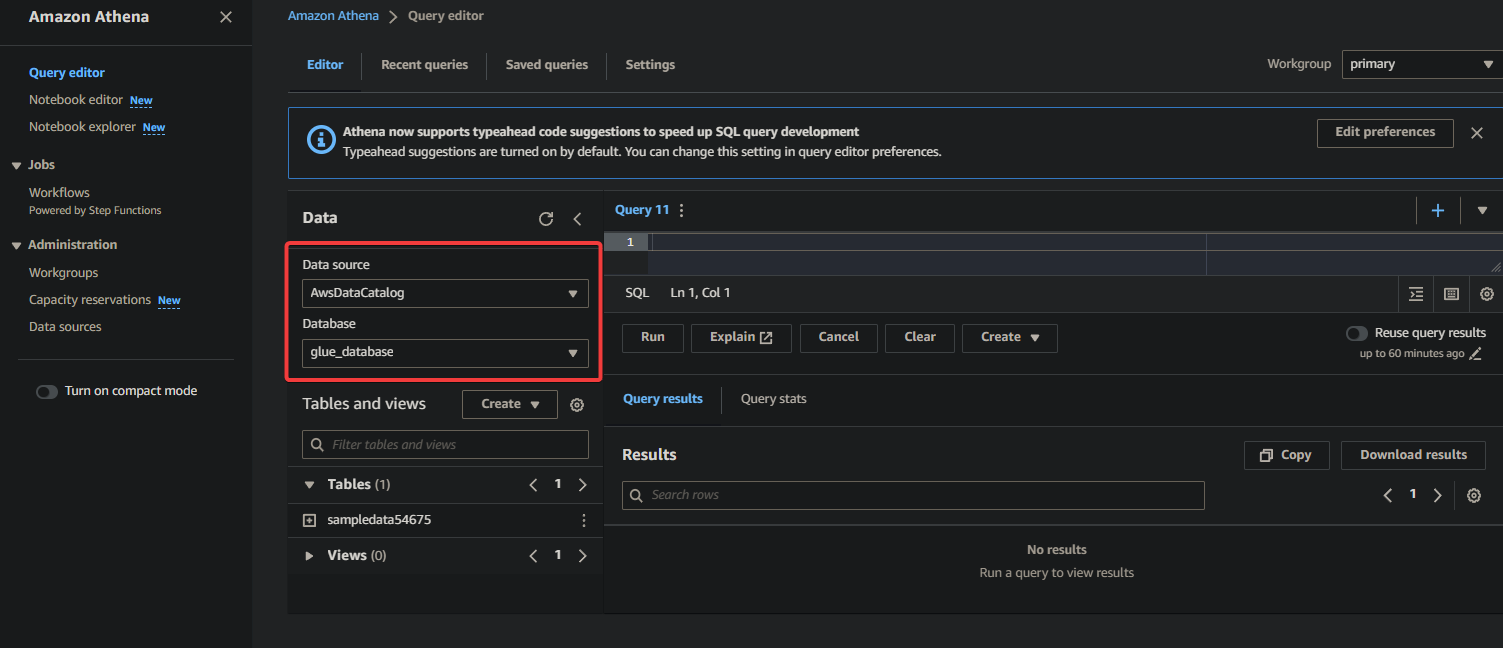
2. Выберите базу данных, в которой ваша информация каталогизирована в разделе Data следующим образом:
- Data source – Выберите AwsDataCatalog, чтобы указать, что вы хотите запросить данные, каталогизированные в AWS Glue.
- Database – Выберите соответствующую базу данных из выпадающего списка (например, glue_database).
? Если вы не видите нужную базу данных в списке, убедитесь, что веб-сканер завершил выполнение и каталогизировал данные.
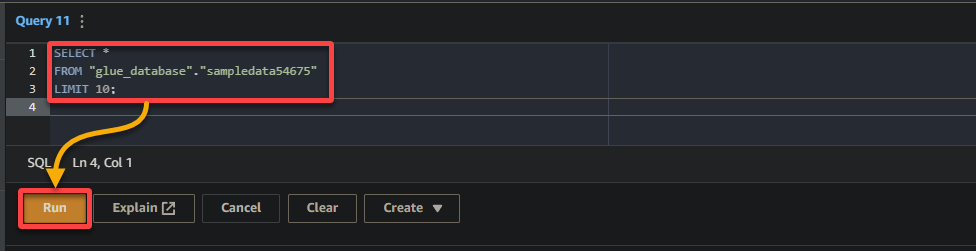
3. Наконец, заполните и выполните следующий запрос в редакторе запросов справа.
Этот запрос возвращает первые 10 строк из таблицы sampledata54675 в базе данных glue_database. Смело изменяйте запрос в соответствии с вашими конкретными требованиями.
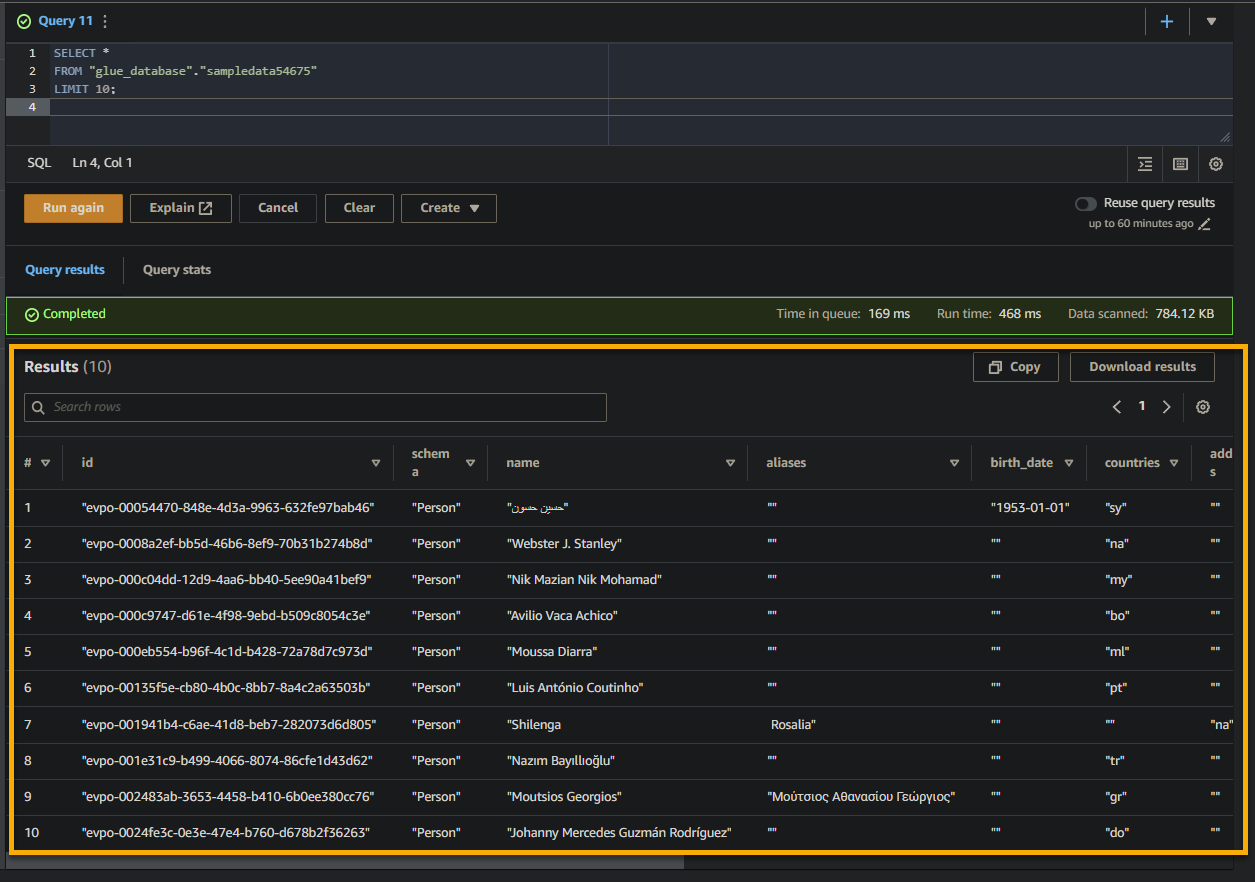
Если запрос успешен, результаты будут отображены в разделе Result, как показано ниже. Результаты содержат информацию о записях, хранящихся в таблице на основе вашего SQL-запроса.
Примите к сведению названия столбцов, типы данных и значения, возвращаемые в наборе результатов. Эта информация поможет вам понять структуру и содержание запрашиваемых данных.
Заключение
В этом руководстве вы узнали основы использования AWS Glue для создания краулера Glue, каталогизации ваших данных и запроса данных с использованием AWS Athena. Подготовка и анализ данных необходимы для любого приложения, основанного на данных. И инструменты, такие как AWS Glue, предоставляют быстрый способ извлечения, преобразования и загрузки (ETL) данных из различных источников в таблицу базы данных.
С AWS Glue вы теперь можете быстро управлять и организовывать данные, что позволяет вам сосредоточиться больше на анализе и выводе инсайтов из ваших данных. Но то, что вы увидели, всего лишь вершина айсберга. Исследуйте широкий спектр возможностей и функциональности, которые может предложить AWS Glue!
Почему бы не воспользоваться соединениями AWS Glue, чтобы без проблем интегрироваться с другими сервисами AWS, такими как Amazon RDS или Amazon Redshift? Эта интеграция позволяет создавать сложные конвейеры ETL и добиваться еще больших возможностей анализа данных.