













Convirtiendo sus datos sin procesar en información organizada y accionable puede sonar complejo. Bueno, no cuando tiene una solución rápida y eficiente. ¡No se preocupe! Este tutorial de AWS Glue, amigable para principiantes, lo respalda.
En este tutorial, aprenderá los pasos cruciales para configurar y ejecutar transformaciones de datos con AWS Glue.
¡Explore y simplifique la preparación de datos para análisis basado en la nube!
Prerrequisitos
Antes de trabajar con AWS Glue, asegúrese de tener una cuenta activa de Amazon Web Services (AWS) con facturación habilitada. Una cuenta gratuitar será suficiente para este tutorial.
Creación de un Rol IAM para AWS Glue
Antes de ejecutar un trabajo de transformación, debe crear un rol de Identidad y Acceso (IAM) que otorgue permisos al servicio AWS Glue. Este rol define qué tipo de recursos AWS Glue tiene permitido acceder en su cuenta de AWS.
Para crear el rol IAM, siga los pasos a continuación:
1. Abra su navegador web preferido e inicie sesión en la Consola de administración de AWS.
2. Busca y selecciona IAM en la lista de resultados para acceder a la consola de IAM.
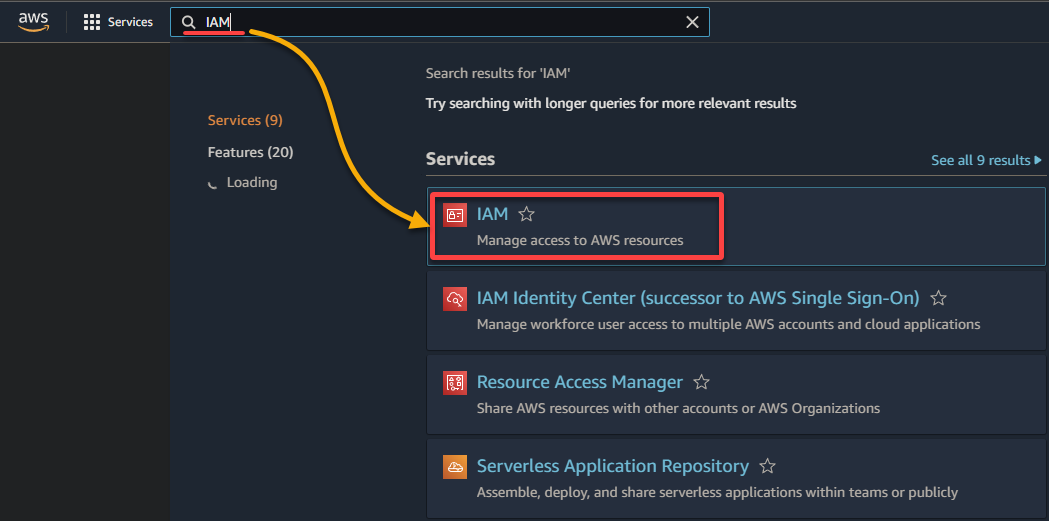
3. En la consola de IAM, navega hasta Roles (panel izquierdo) y haz clic en Crear rol (arriba a la derecha), lo que redirigirá tu navegador a una nueva página dedicada a configurar el rol.

4. Ahora, configura los siguientes ajustes para el rol:
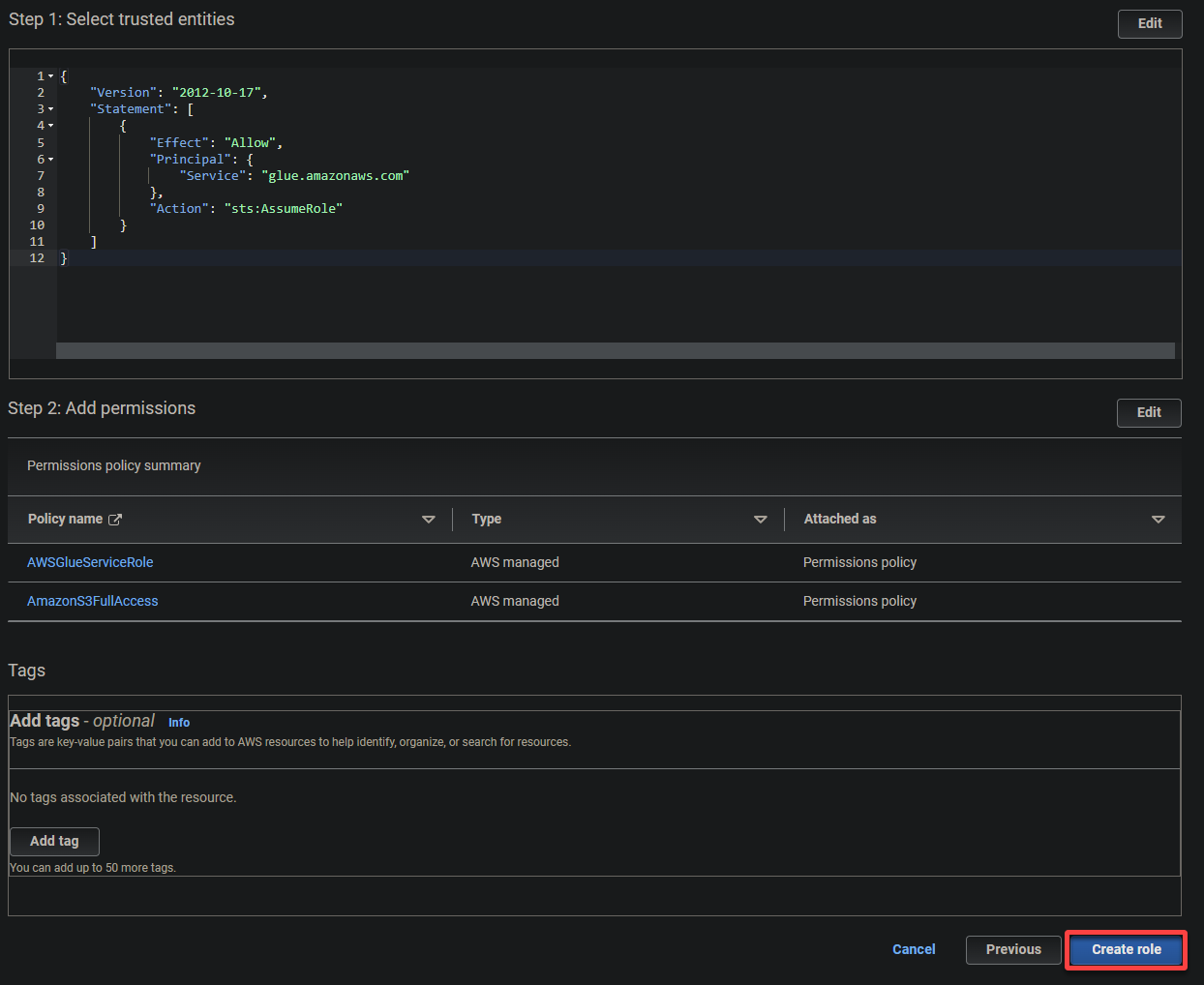
- Tipo de entidad de confianza: selecciona Servicio de AWS para que un servicio de AWS confíe en el rol. Haciendo esto, permite que ese servicio asuma el rol y actúe en tu nombre.
- Caso de uso: elige Glue bajo la sección Casos de uso para otros servicios de AWS, ya que crearás el rol de IAM específicamente para AWS Glue, y haz clic en Siguiente.
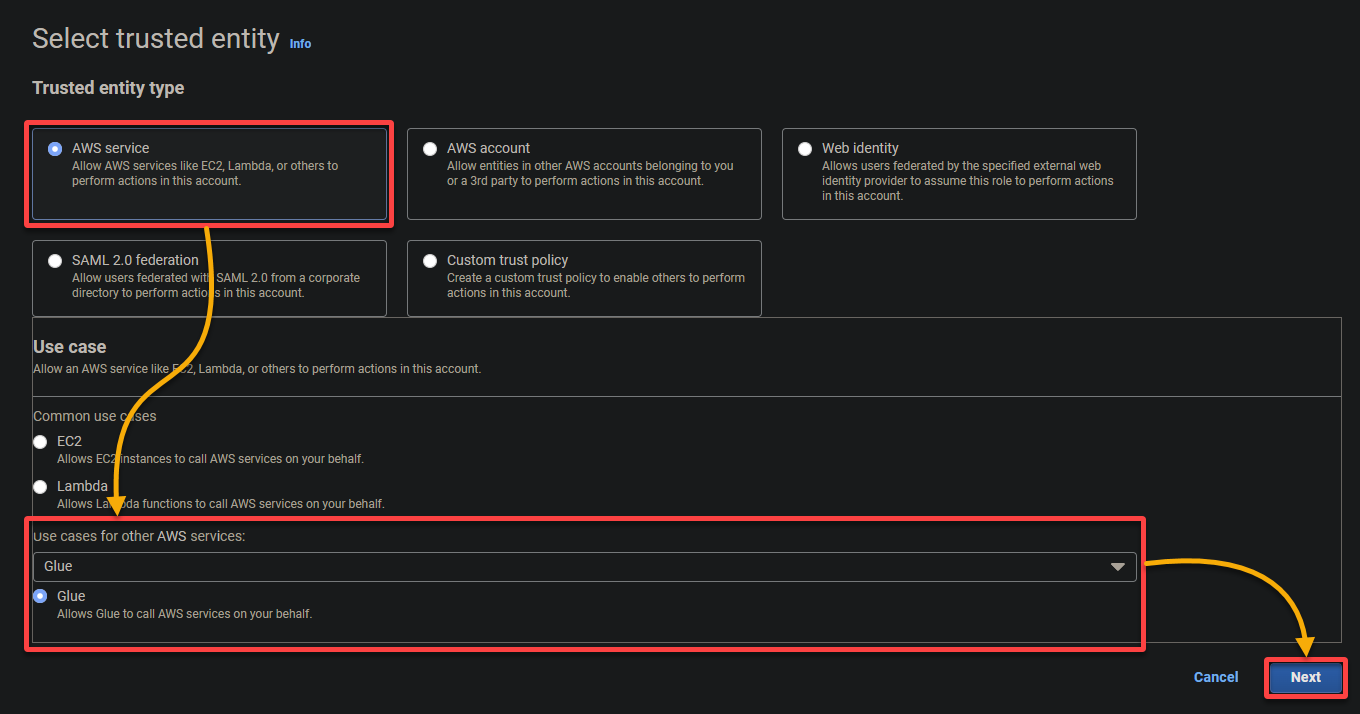
5. Busca y selecciona las siguientes políticas, y haz clic en Siguiente.
- AWSGlueServiceRole – Concede al servicio AWS Glue los permisos necesarios para realizar sus operaciones.
- S3FullAccess – Concede acceso completo a los recursos de S3, lo que permite a AWS Glue leer desde y escribir en los buckets de S3.
AWS Glue necesita permisos extensos para leer desde y escribir en los buckets de S3 para realizar eficazmente sus tareas de extracción, transformación y carga (ETL) de datos.
? Avoid granting unnecessary excessive permissions, as they can pose security risks.
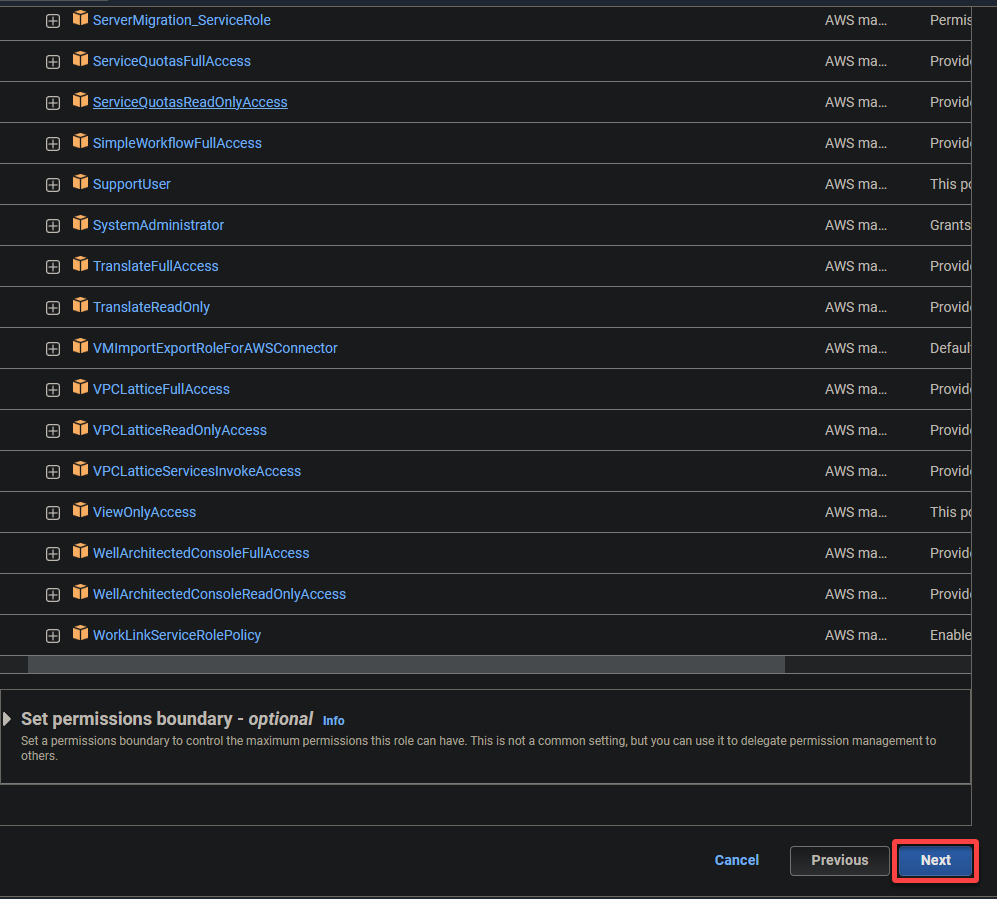
6. Proporciona un nombre descriptivo para el rol (por ejemplo, glue_role) y una descripción.
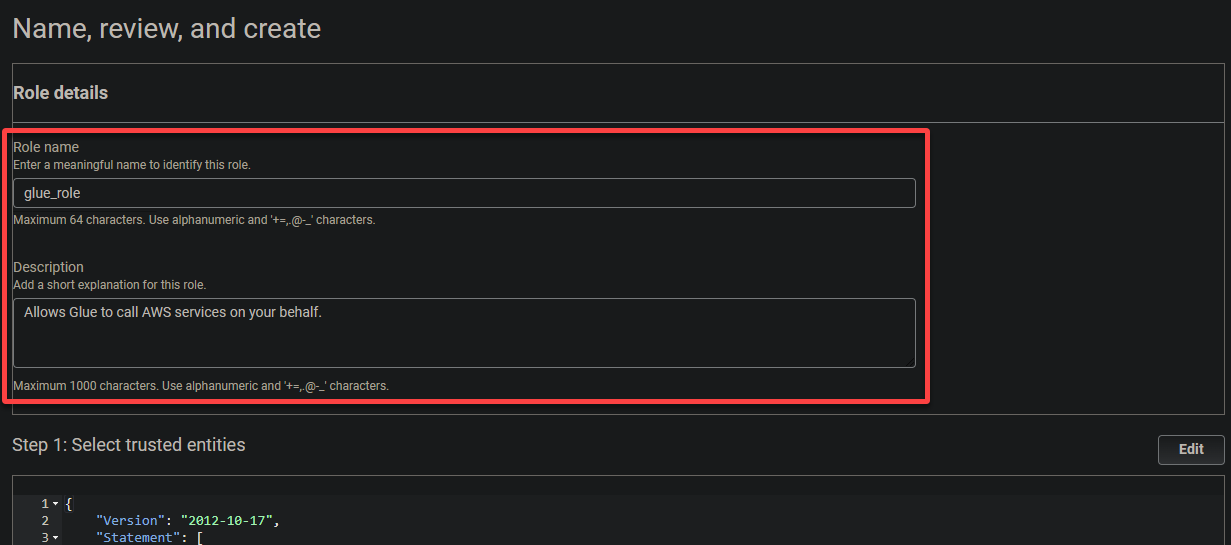
7. Finalmente, desplázate hacia abajo, revisa tus ajustes y haz clic en Crear rol (parte inferior derecha) para finalizar la creación del rol.
Creando un Bucket de S3 y Subiendo un Archivo de Muestra
Ahora que tienes un rol IAM para AWS Glue, necesitas un lugar para almacenar tus datos, específicamente, un bucket de S3. Un bucket de S3 proporciona un lugar centralizado para almacenar los datos que AWS Glue procesará.
En este ejemplo, AWS Glue utilizará AWS S3 como almacenamiento de datos para varias operaciones, como extracción de datos, transformación y tareas de carga (ETL).
Para crear un bucket de S3 y subir un archivo de muestra, sigue estos pasos:
1. Descarga un archivo de datos de muestra (por ejemplo, conjunto de datos Every Politician) a tu máquina local. Este archivo contiene una colección no estructurada de registros para servir como entrada para el trabajo de transformación de AWS Glue.
2. Busca y selecciona el servicio S3 para acceder a la consola de S3.
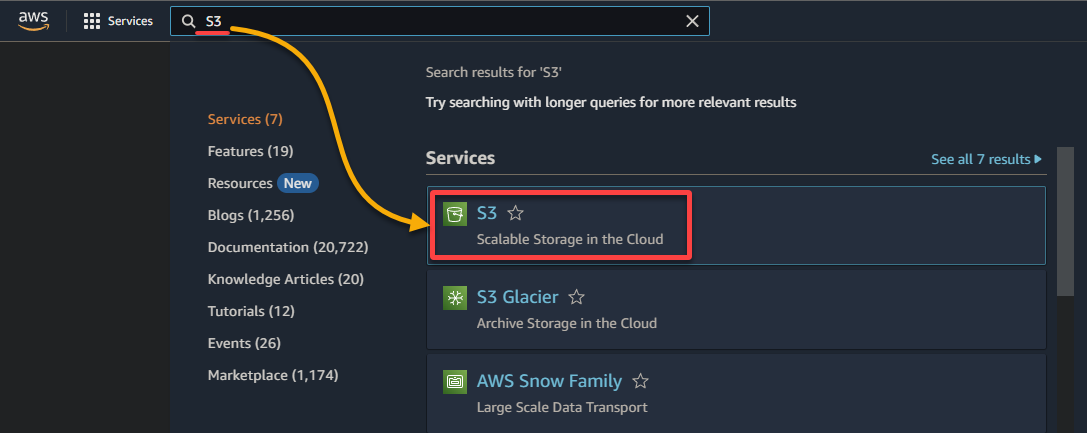
3. Haz clic en Crear un bucket para iniciar la creación de un nuevo bucket de S3.

4. Ahora, proporciona un nombre único para tu bucket (por ejemplo, datosdemuestra54675) y selecciona la región donde debería estar ubicado el bucket.
A unique name lets you avoid conflicts with existing bucket names is crucial, while the region selection determines the physical location of your bucket’s data.
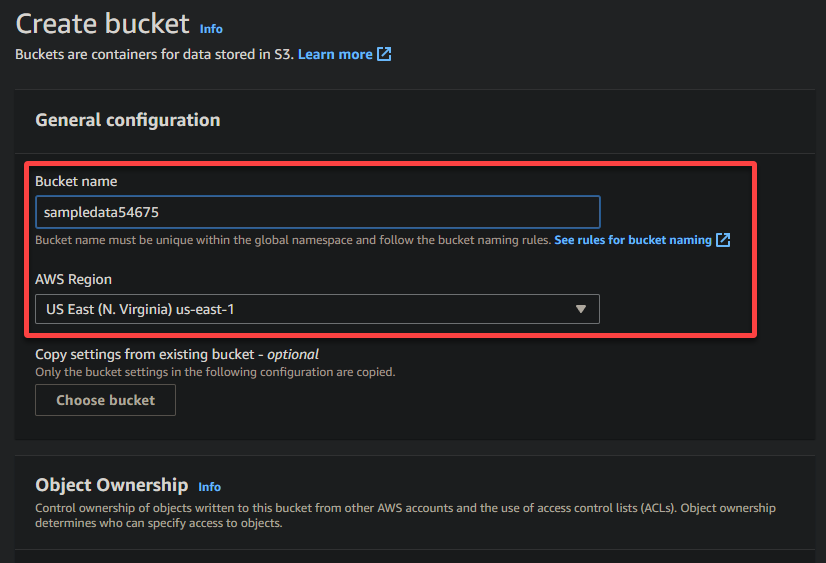
5. Desplázate hacia abajo, deja las demás opciones como están y haz clic en Crear bucket para crear el bucket.

6. Una vez creado, haz clic en el hipervínculo del bucket de S3 recién creado para navegar hasta el bucket.

7. Haz clic en Subir y localiza el archivo de muestra que deseas cargar.
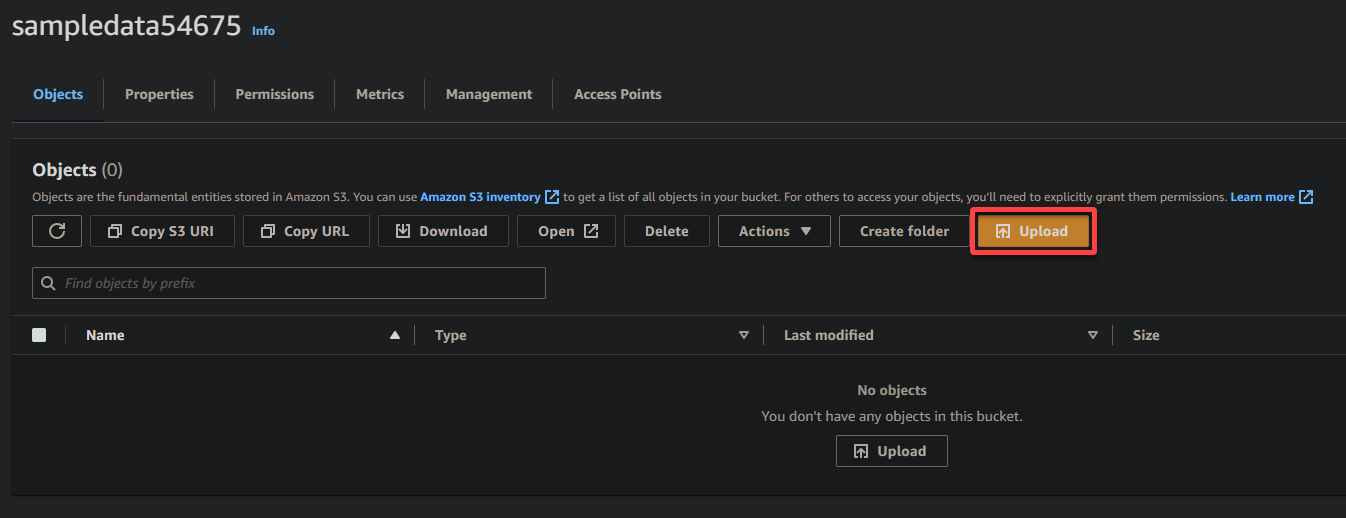
Por último, mantén los demás ajustes como están y haz clic en Subir para cargar el archivo de muestra en el bucket recién creado.
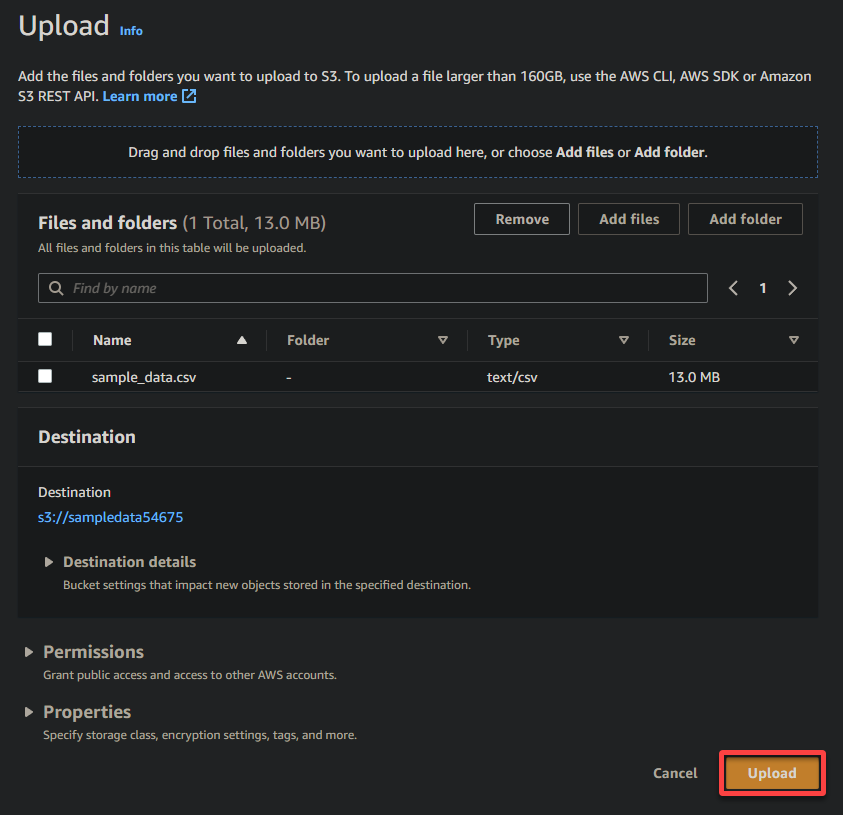
Si tienes éxito, verás tu archivo recién cargado en tu bucket, como se muestra a continuación.
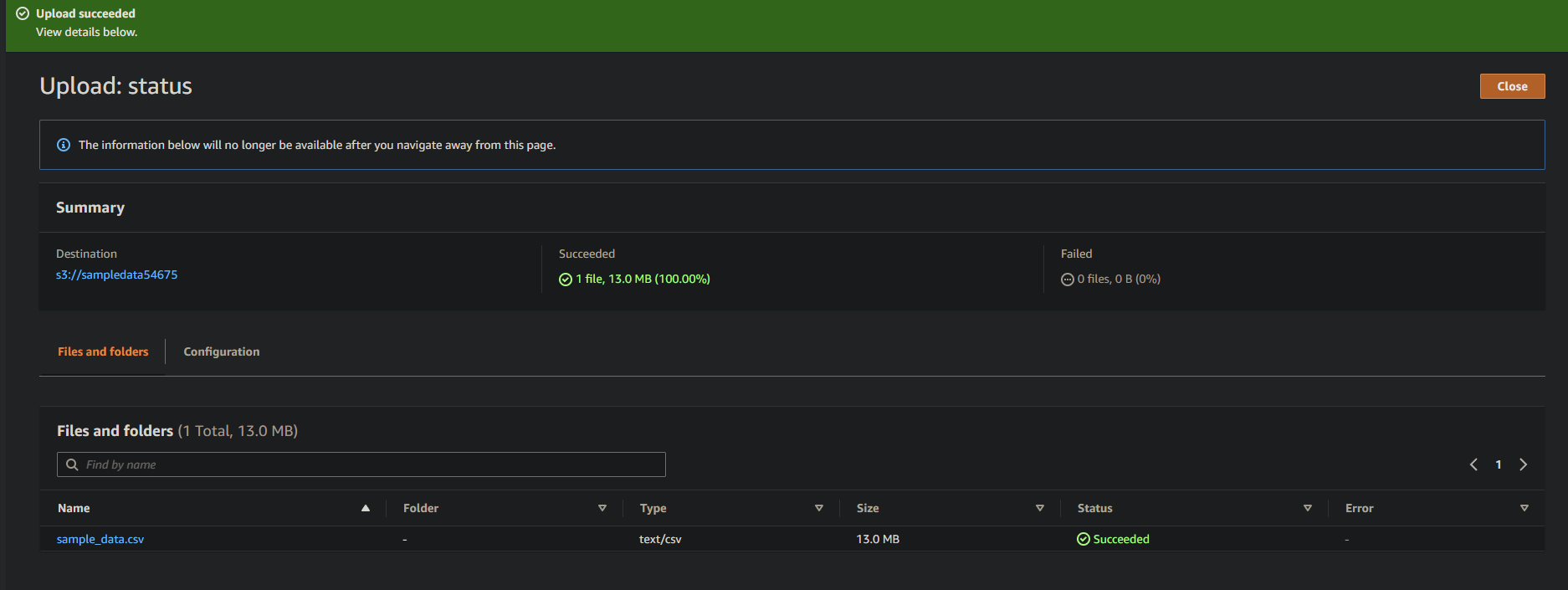
Creando un Rastreador de Glue para Escanear y Catalogar Datos
Acabas de cargar datos de muestra en tu bucket de S3, pero como actualmente no están estructurados, necesitas una forma de leer los datos y construir un catálogo de metadatos. ¿Cómo? Creando un rastreador de glue que escanee y catalogue automáticamente los datos.
Para crear un rastreador de glue, sigue los pasos a continuación:
1. Ve a la consola de AWS Glue a través de la Consola de Administración de AWS, como se muestra a continuación.
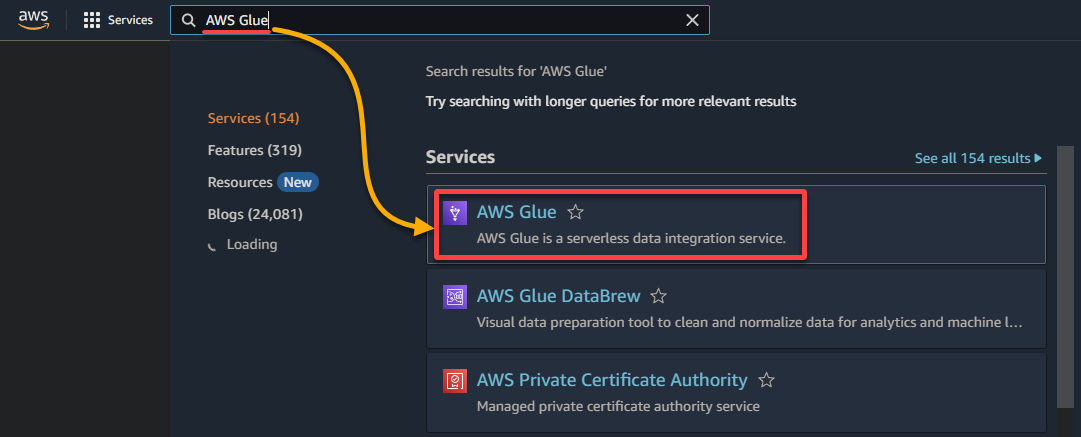
2. A continuación, ve a Rastreador (panel izquierdo) y haz clic en Agregar rastreador (arriba a la derecha) para iniciar la creación de un nuevo rastreador de glue.
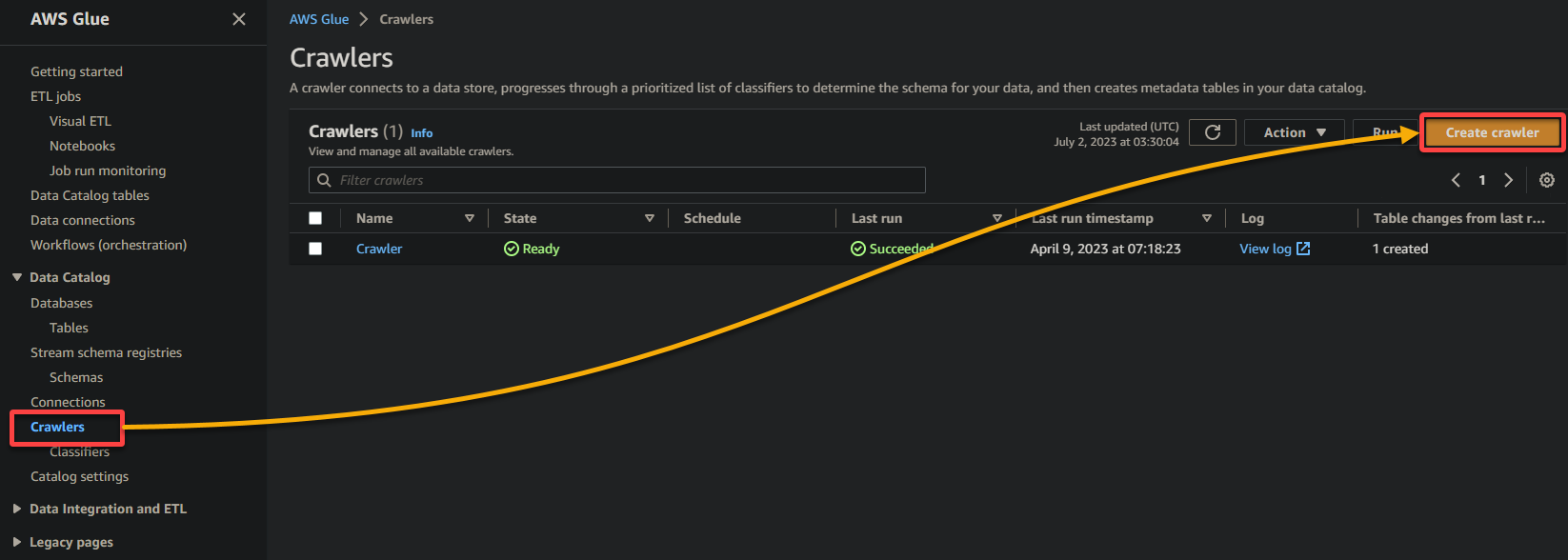
3. Proporciona un nombre descriptivo (por ejemplo, rastreador_glue) y una descripción para el rastreador, mantén los demás ajustes como están y haz clic en Siguiente.
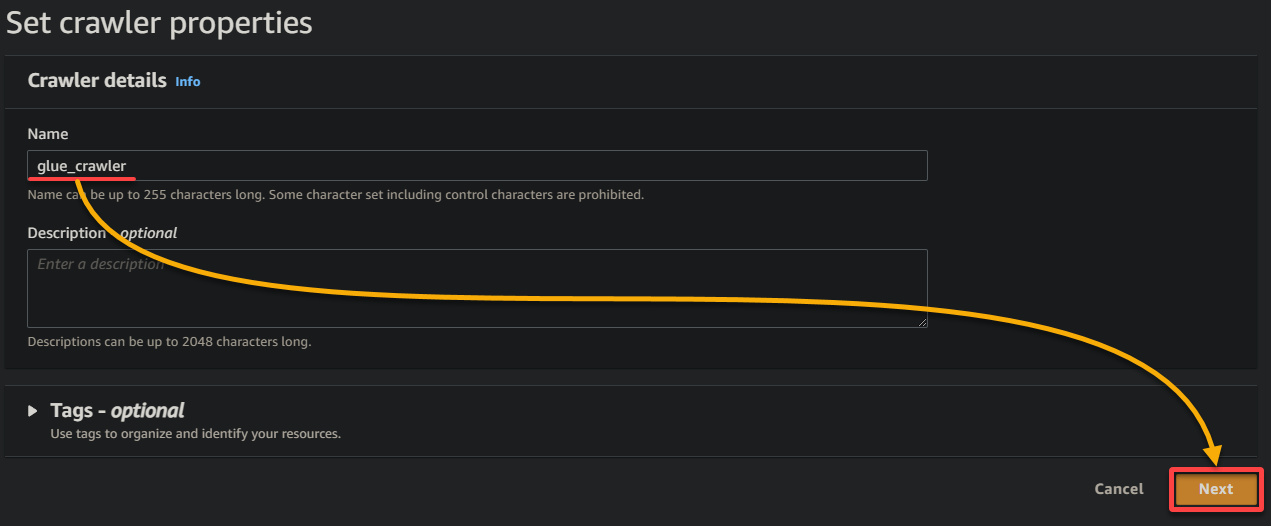
4. Ahora, haz clic en Agregar una fuente de datos bajo Fuentes de datos para iniciar la adición de una nueva fuente de datos al rastreador.
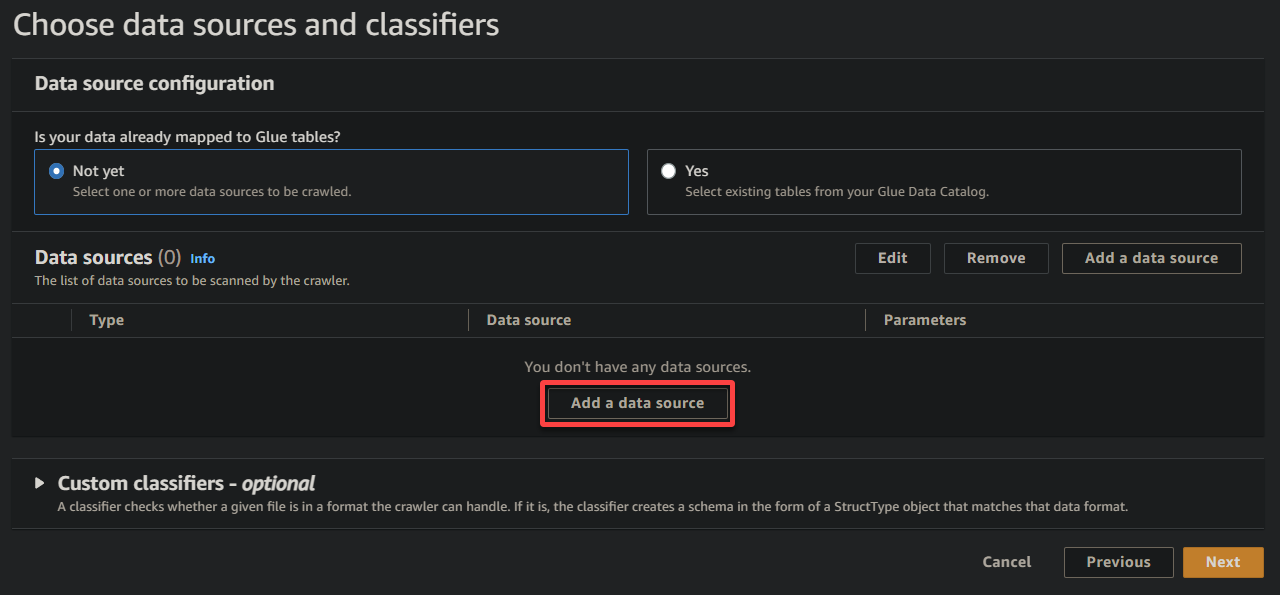
5. En la ventana emergente, configura la fuente de datos de la siguiente manera:
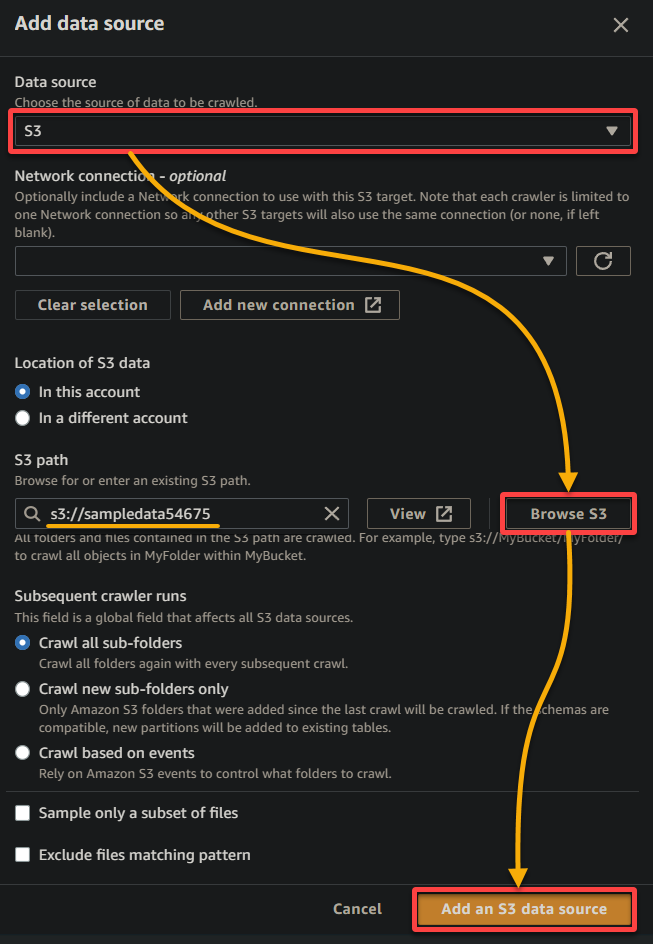
- Fuente de datos – Selecciona S3 ya que tus datos están en tu bucket de S3.
- Ruta S3 – Haz clic en Examinar en S3 y elige el bucket que contiene tus datos de muestra cargados (sampledata54675).
- Mantén los demás ajustes como están y haz clic en Agregar una fuente de datos de S3 para añadir los datos de muestra al rastreador.
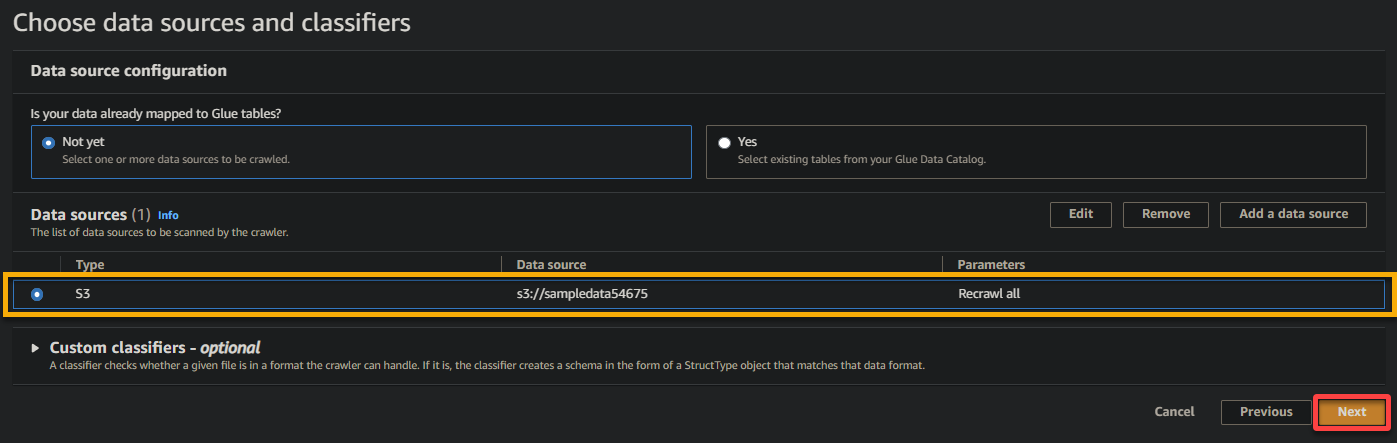
6. Una vez configurado, verifica la fuente de datos, como se muestra a continuación, y haz clic en Siguiente para continuar.
7. En la siguiente pantalla, selecciona el rol IAM que creaste anteriormente (glue_role), mantén los demás ajustes como están y haz clic en Siguiente.
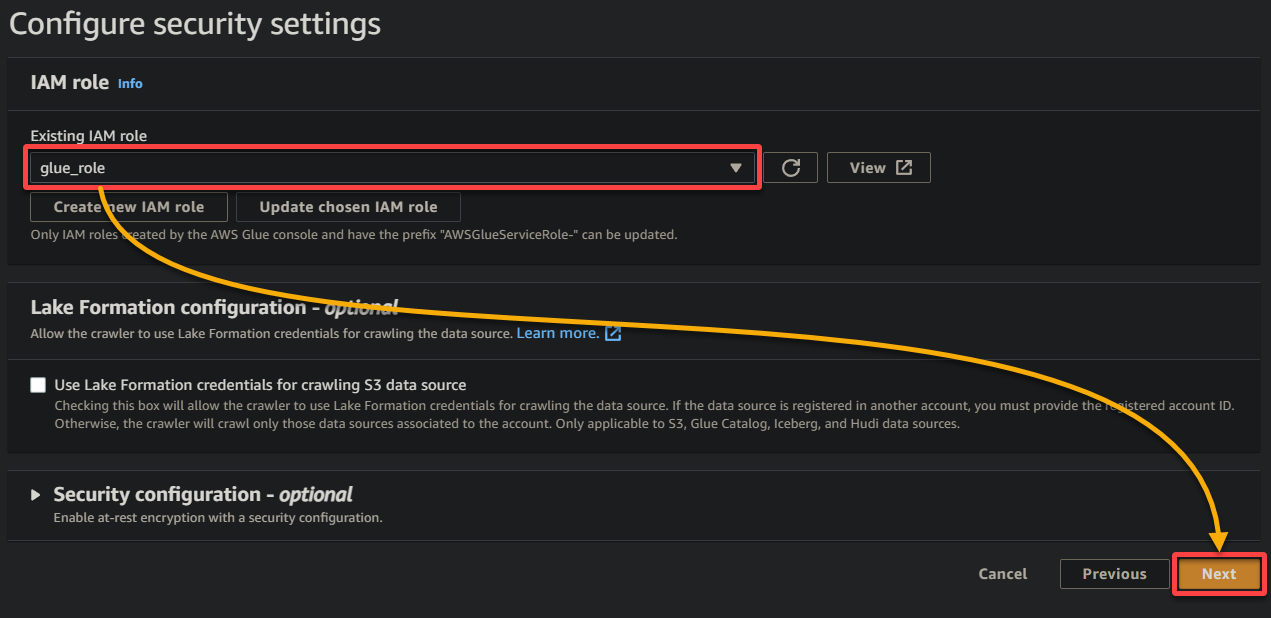
8. En salida y programación, haz clic en Agregar base de datos para iniciar la adición de una nueva base de datos para almacenar los datos procesados y metadatos generados por tu rastreador Glue. Esta acción abre una nueva pestaña del navegador, donde configurarás los detalles de tu base de datos (paso ocho).
Esta base de datos proporciona una representación estructurada de los datos para consultas y análisis.
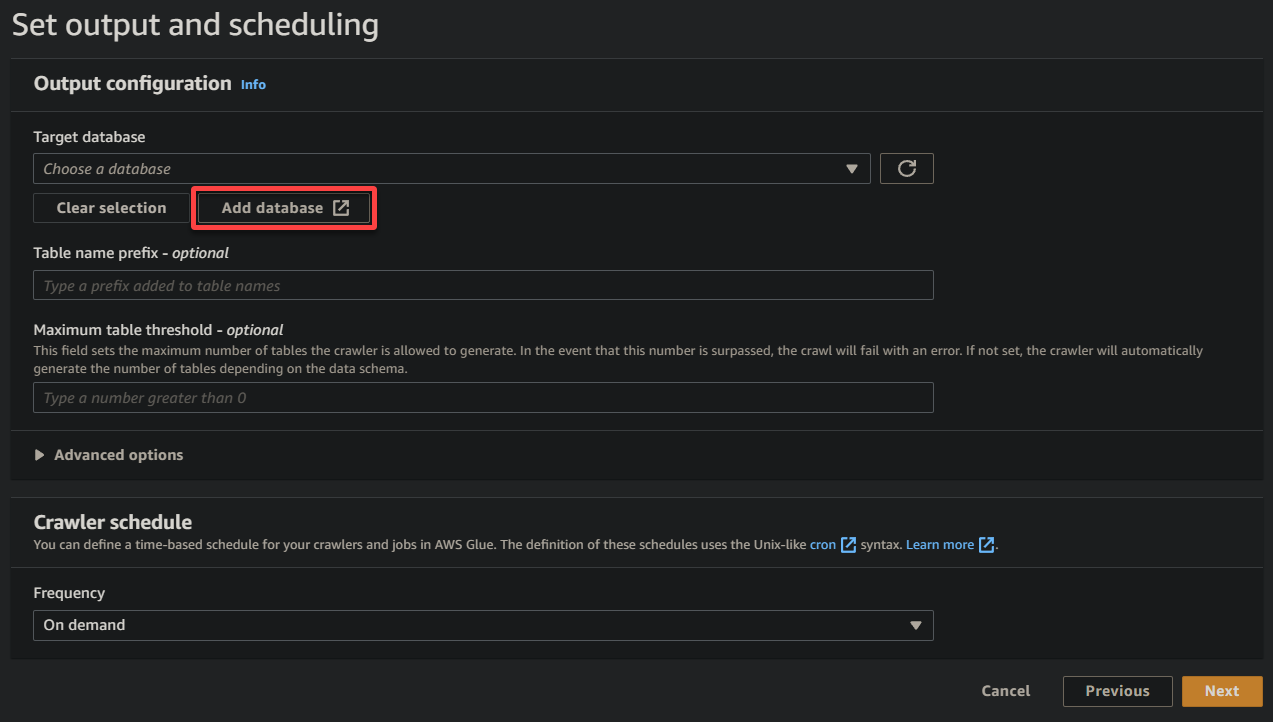
9. En la nueva pestaña del navegador, proporciona un nombre descriptivo para la base de datos (es decir, glue_database) y haz clic en Crear base de datos para crear la base de datos.
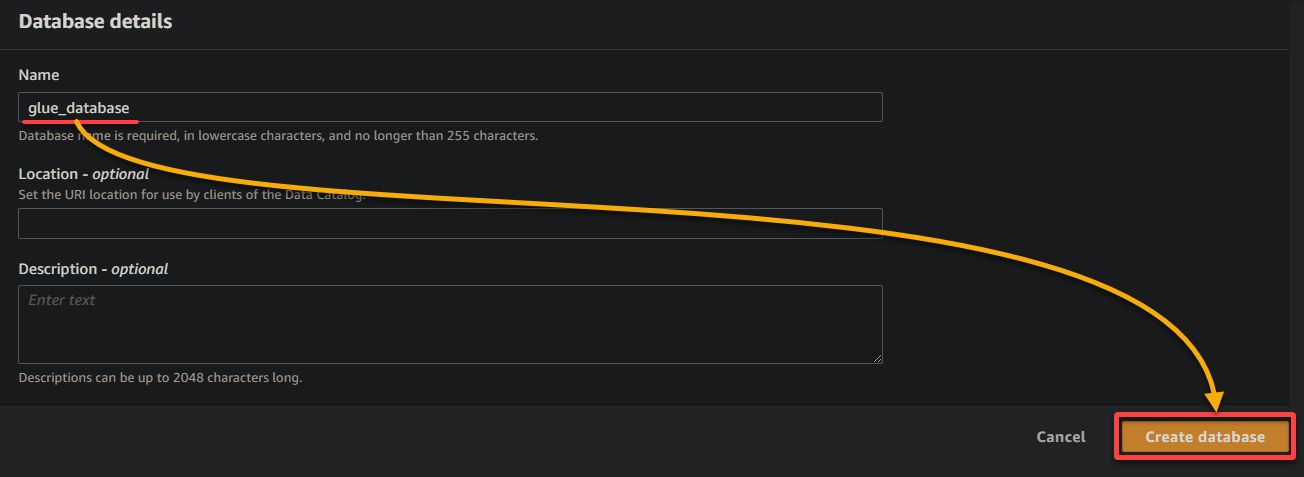
10. Cambia a la pestaña anterior del navegador, selecciona la base de datos recién creada (glue_database) del menú desplegable, mantén los demás ajustes como están y haz clic en Siguiente.
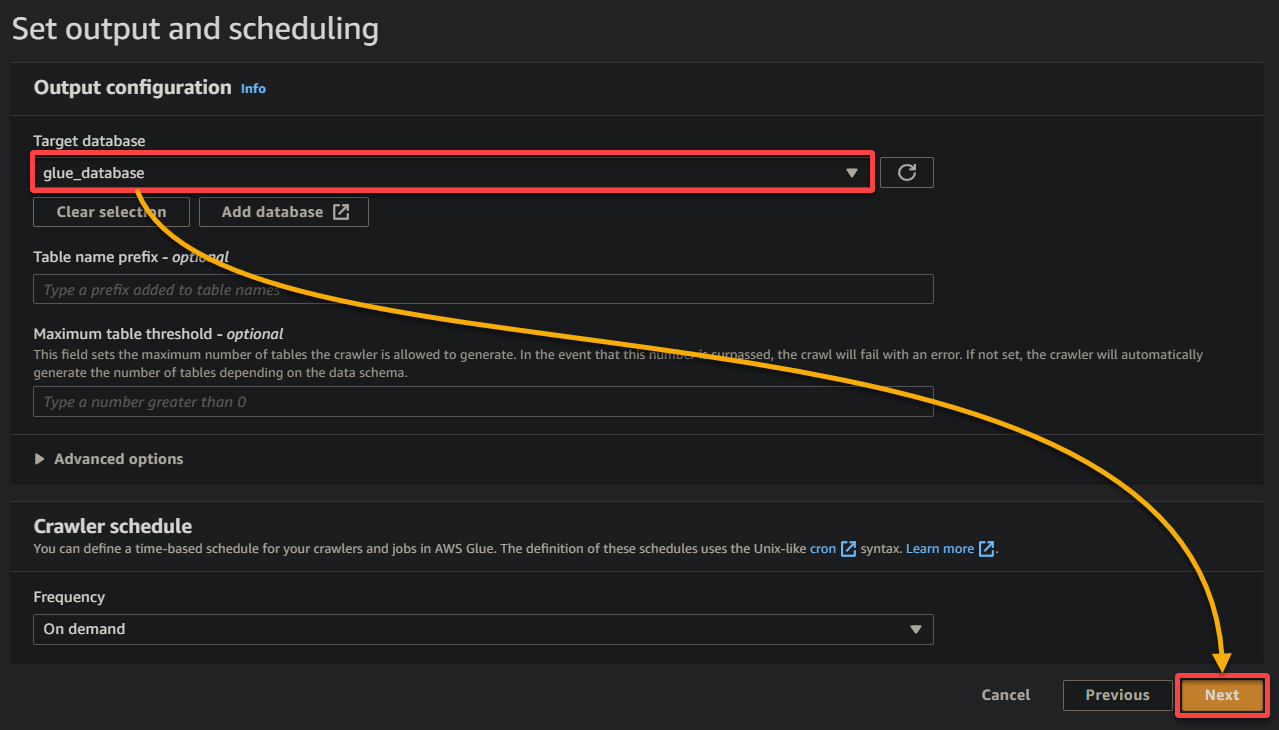
11. Finalmente, revisa tus ajustes en la pantalla final para asegurarte de que sean precisos y haz clic en Crear rastreador (abajo a la derecha) para crear el nuevo rastreador.
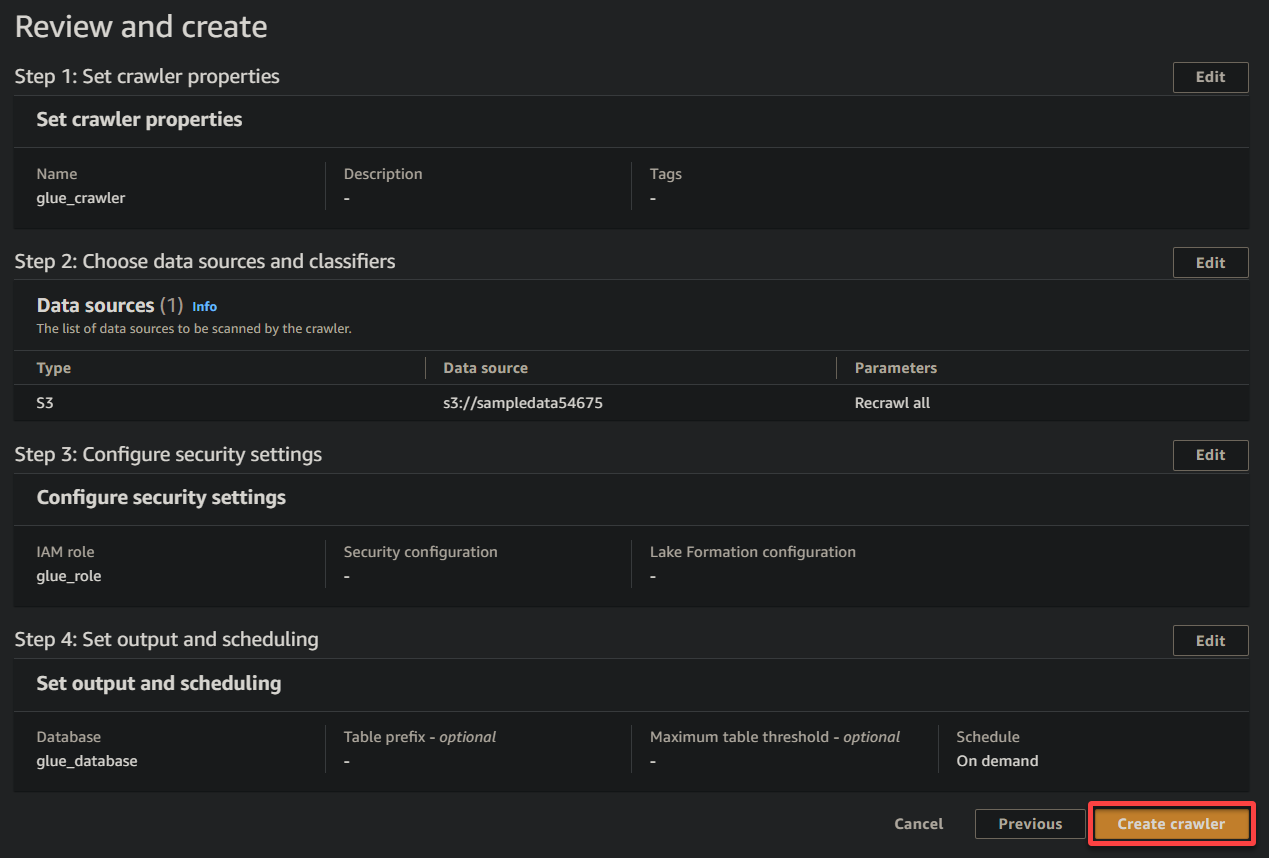
Si todo va bien, verás una pantalla confirmando la exitosa creación del rastreador. No cierres esta pantalla aún; ejecutarás este rastreador en la siguiente sección.
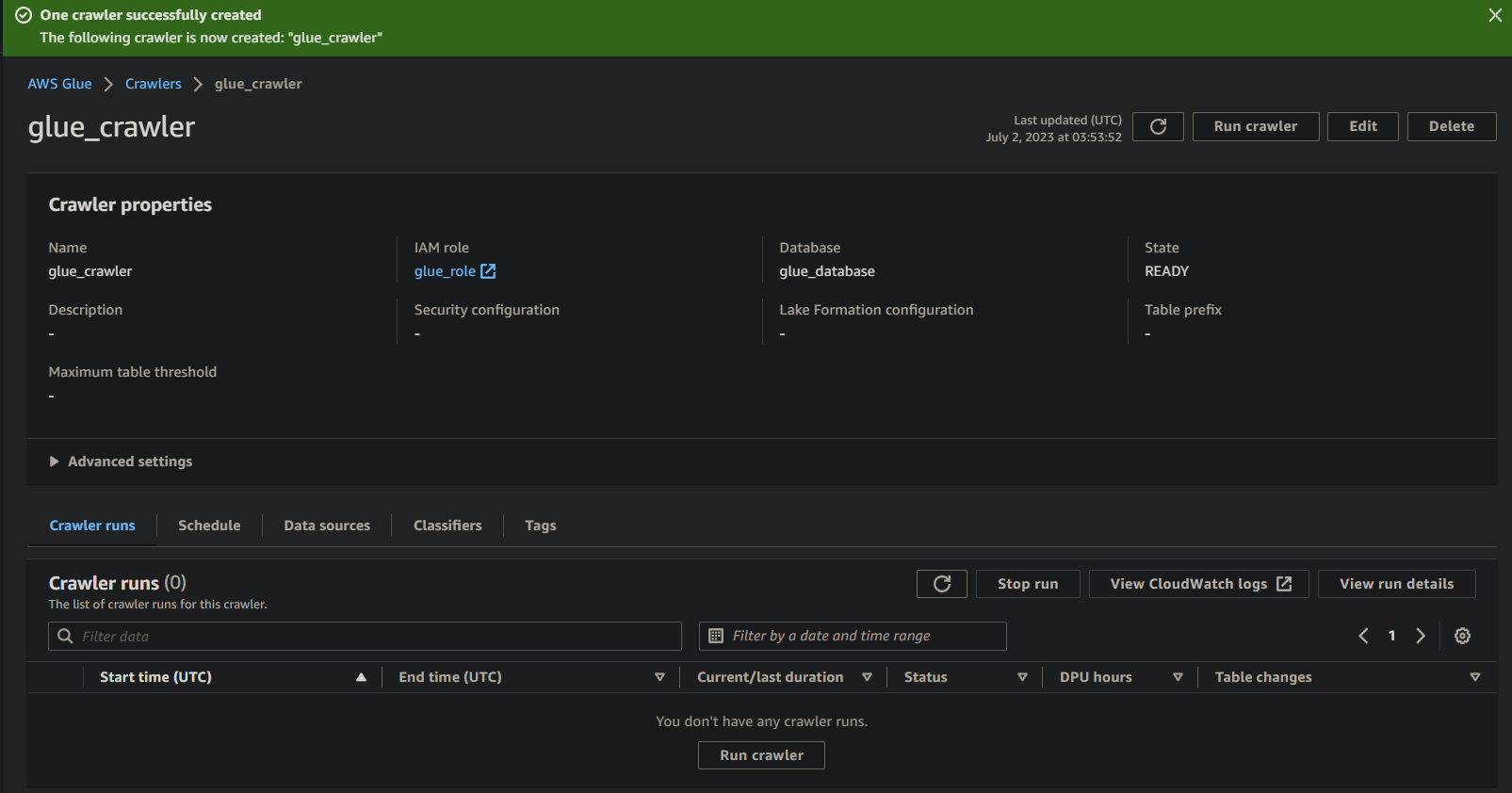
Ejecutando el Rastreador de Glue para Construir un Catálogo de Metadatos
Con un nuevo rastreador a su disposición, ejecutar el rastreador es esencial para iniciar el proceso de escaneo y catalogación. Su rastreador de Glue construirá un catálogo de metadatos que proporciona una representación estructurada de sus datos para fines de consulta y análisis.
Para ejecutar su rastreador de Glue recién creado:
1. En la página de detalles del rastreador, haga clic en Ejecutar rastreador bajo la pestaña Ejecuciones de rastreador para iniciar la ejecución del rastreador.
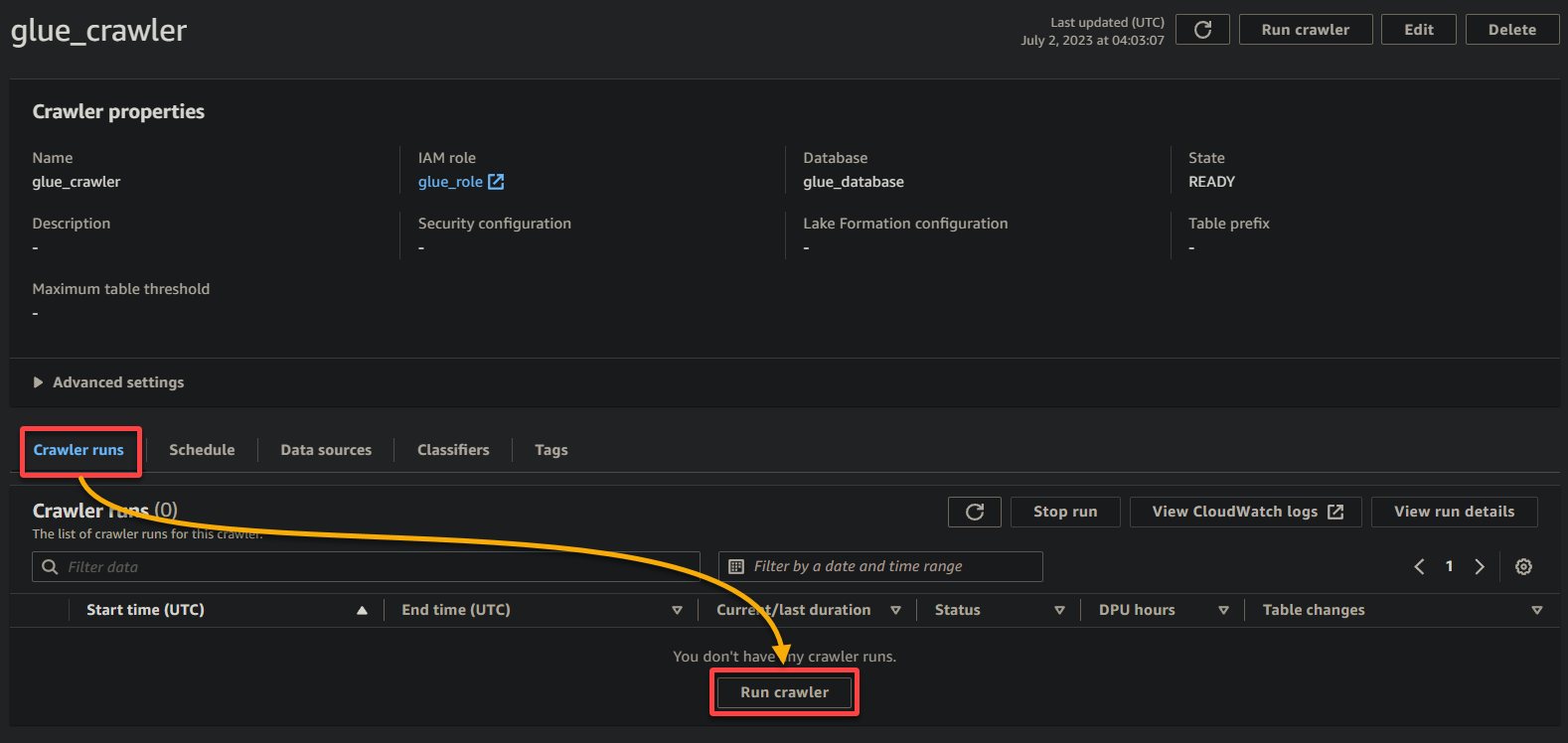
Una vez que el rastreador comienza a ejecutarse, verá su estado y progreso en la página de detalles del rastreador.
Dependiendo del tamaño y complejidad de sus datos, el rastreador puede tardar algún tiempo en completar su ejecución. Puede actualizar periódicamente la página para ver el estado actualizado del rastreador.
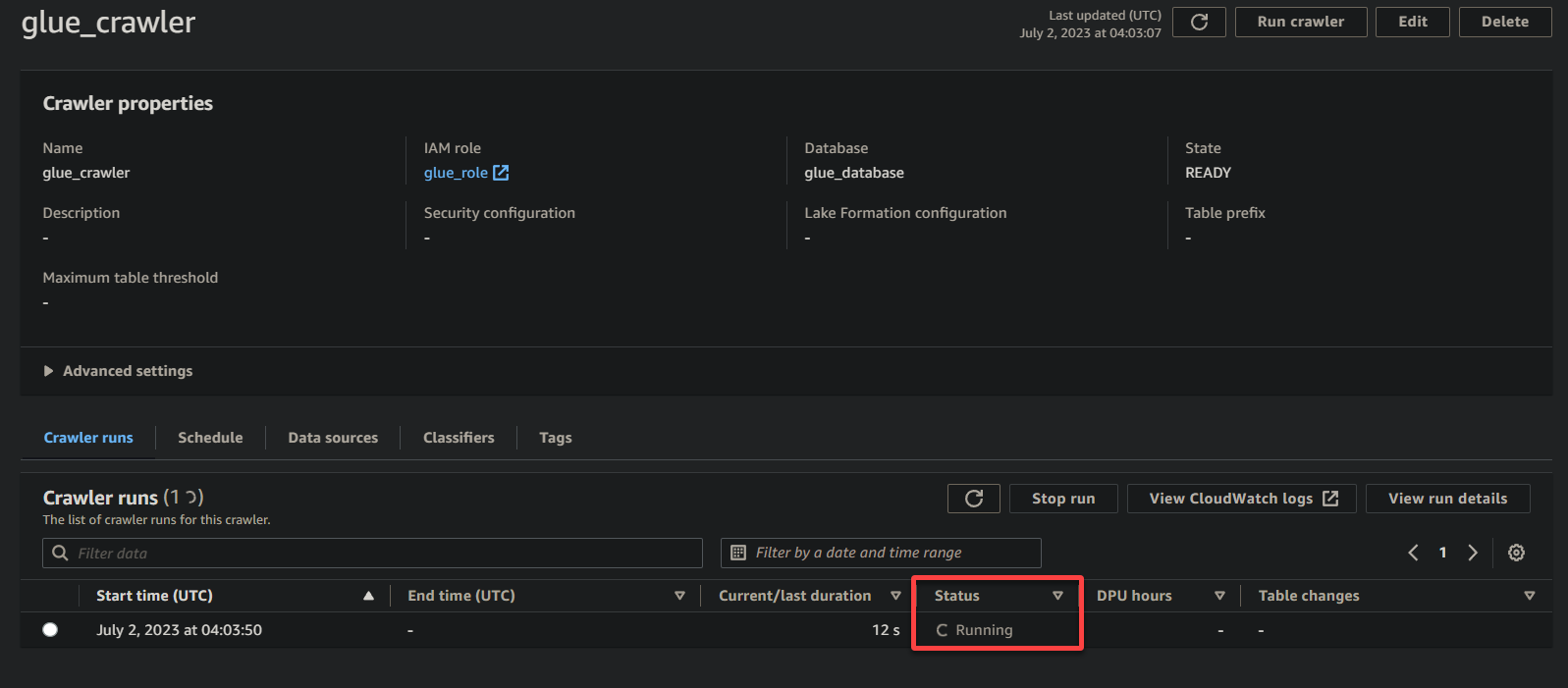
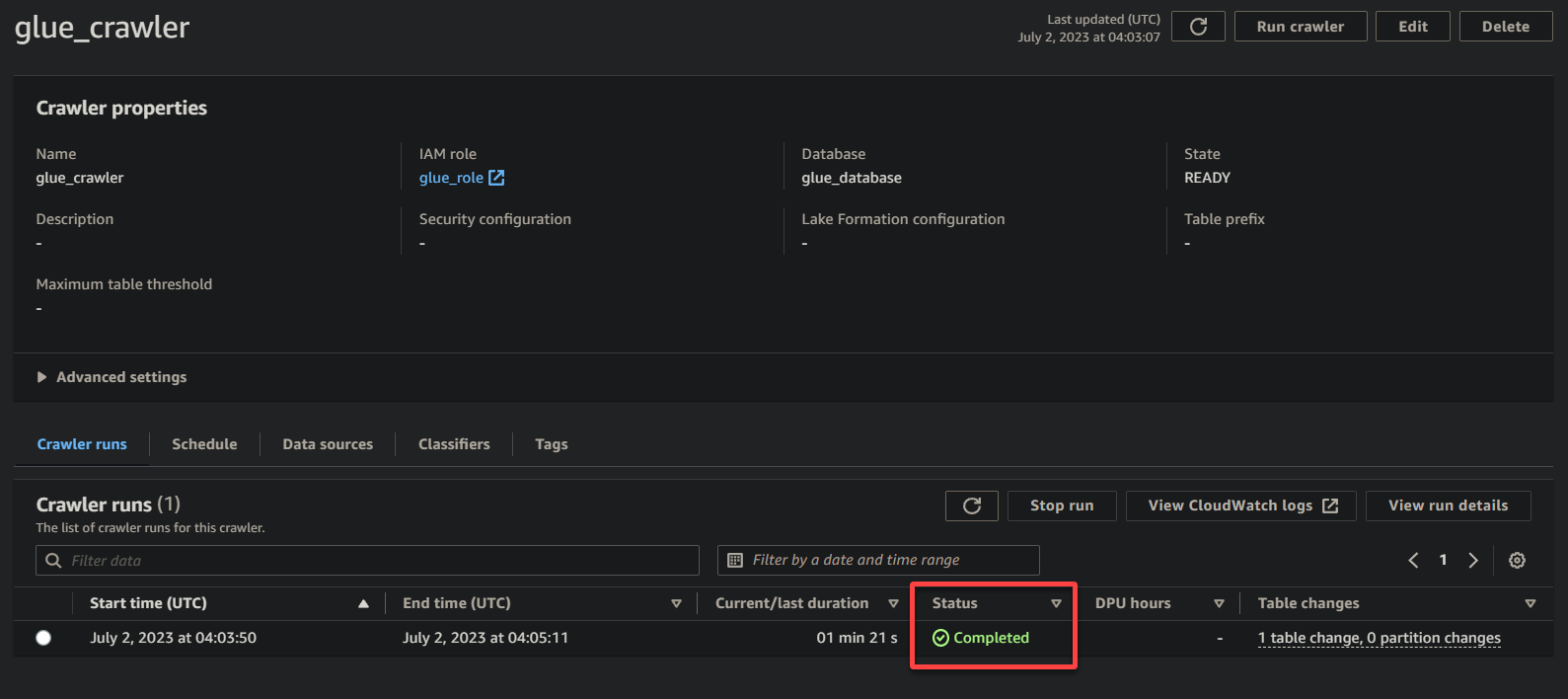
Una vez que el rastreador ha completado su ejecución, el estado cambia a Completado, como se muestra a continuación. En este punto, puede proceder a consultar sus datos.
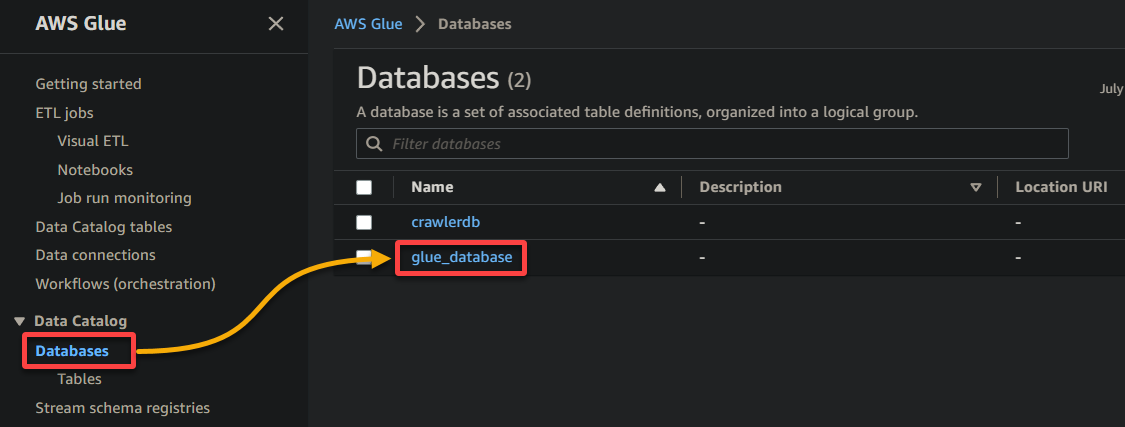
2. A continuación, vaya a Base de datos (panel izquierdo) y haga clic en su base de datos para acceder a sus propiedades y tablas.
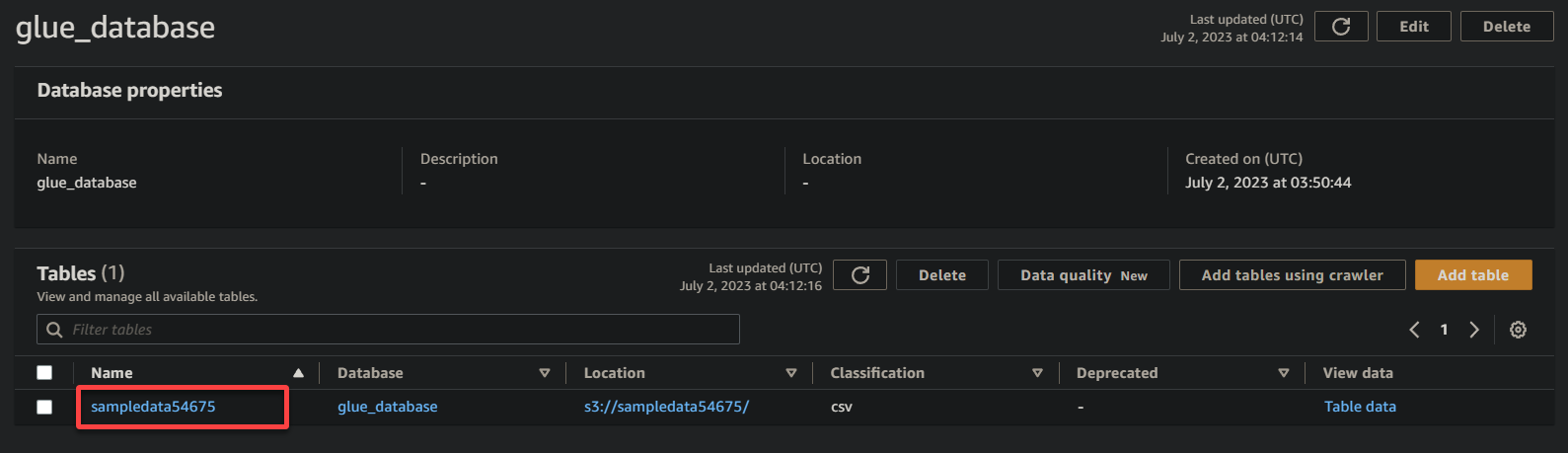
3. Por último, haga clic en el nombre de su cubo (sampledata54675), ahora una tabla, para ver sus datos almacenados.
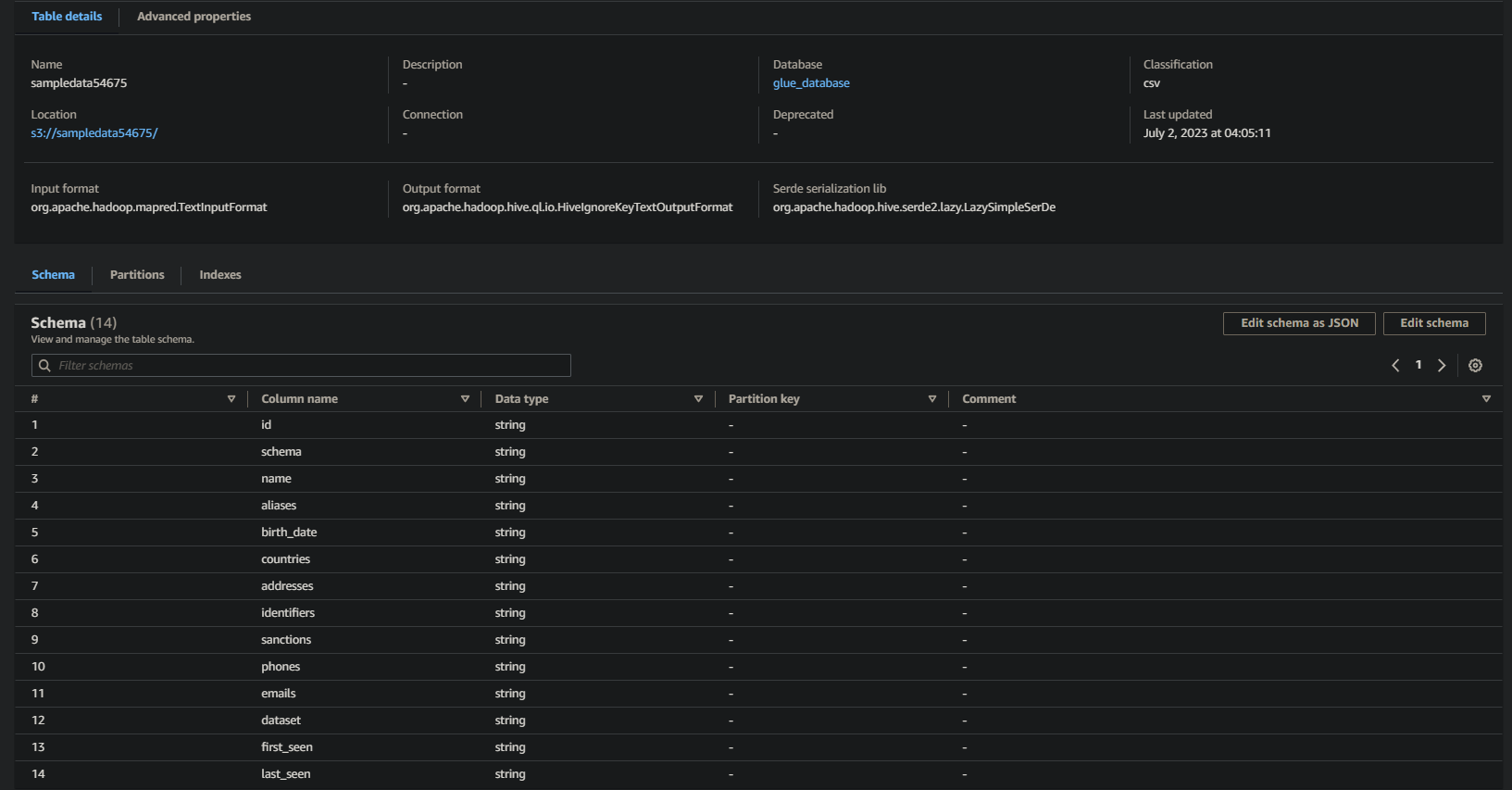
Si tiene éxito, verá información similar a continuación. Esta información confirma que los datos se transformaron con éxito en la tabla de la base de datos, proporcionando detalles valiosos.
Consulta de Datos Catalogados a través de AWS Athena
Ahora que sus datos están disponibles en el Catálogo de Datos de AWS Glue, puede utilizar varias herramientas para consultar y analizar sus datos. Una de esas herramientas es AWS Athena, un servicio de consulta interactivo que le permite analizar datos en la nube utilizando SQL estándar.
Para consultar los datos utilizando AWS Athena, siga los pasos a continuación:
1. Busque y acceda a la consola de Athena.
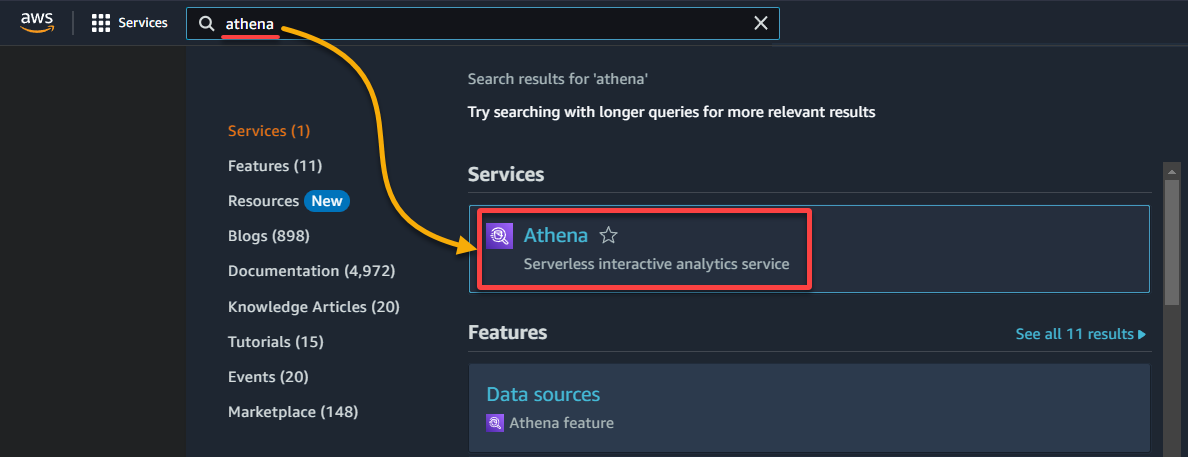
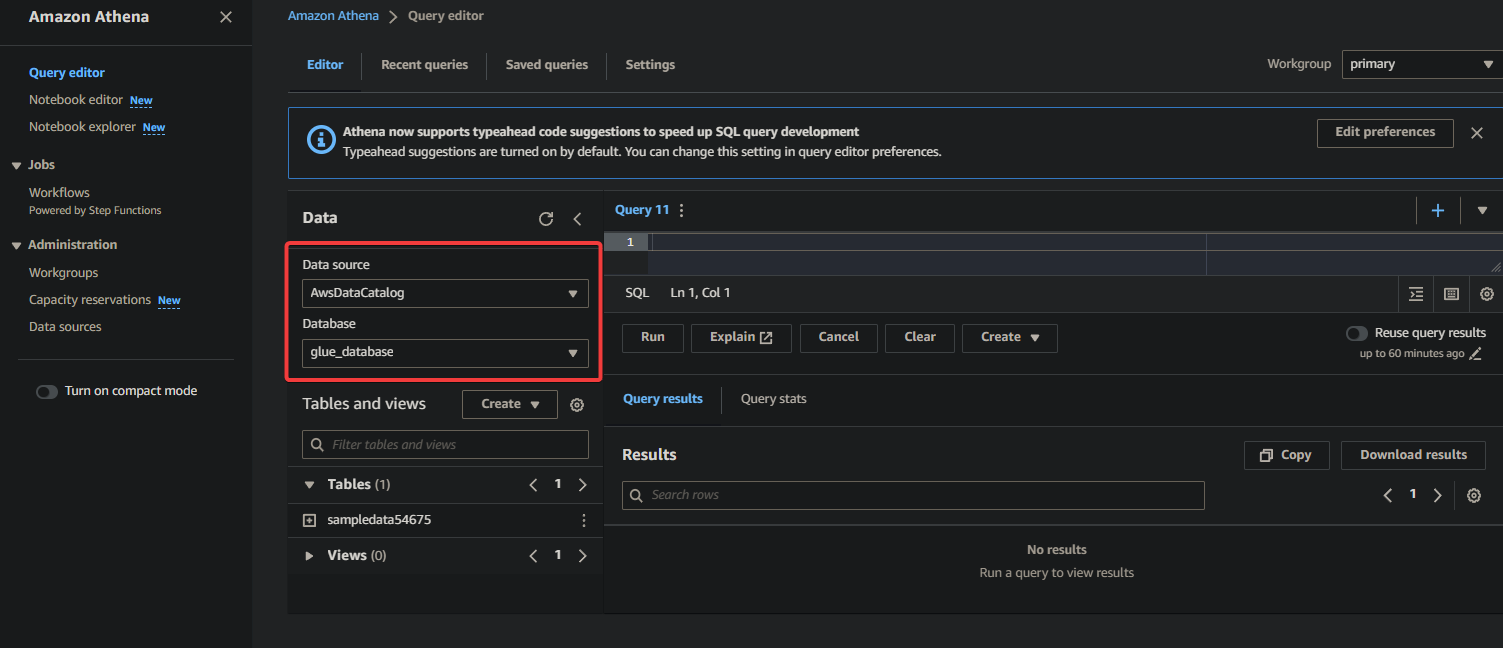
2. Seleccione la base de datos donde se encuentra su datos catalogados en la sección Datos de la siguiente manera:
- Fuente de datos – Seleccione AwsDataCatalog para indicar que desea consultar los datos catalogados en AWS Glue.
- Base de datos – Seleccione la base de datos adecuada del campo desplegable (es decir, glue_database).
? Si no ve la base de datos deseada en el menú desplegable, asegúrese de que el rastreador haya completado su ejecución y haya catalogado los datos.
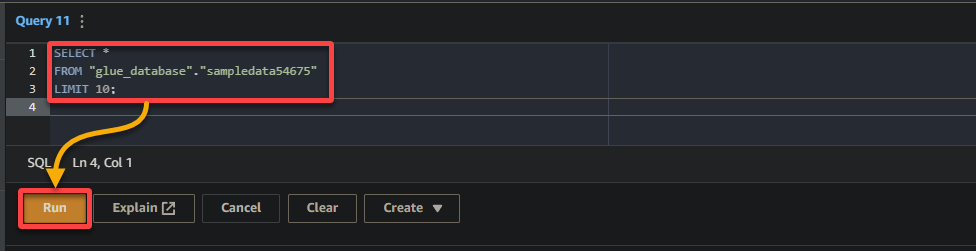
3. Por último, rellene y ejecute la siguiente consulta en el editor de consultas a la derecha.
Esta consulta devuelve las primeras 10 filas de la tabla sampledata54675 en la base de datos glue_database. Siéntase libre de modificar la consulta para satisfacer sus requisitos específicos.
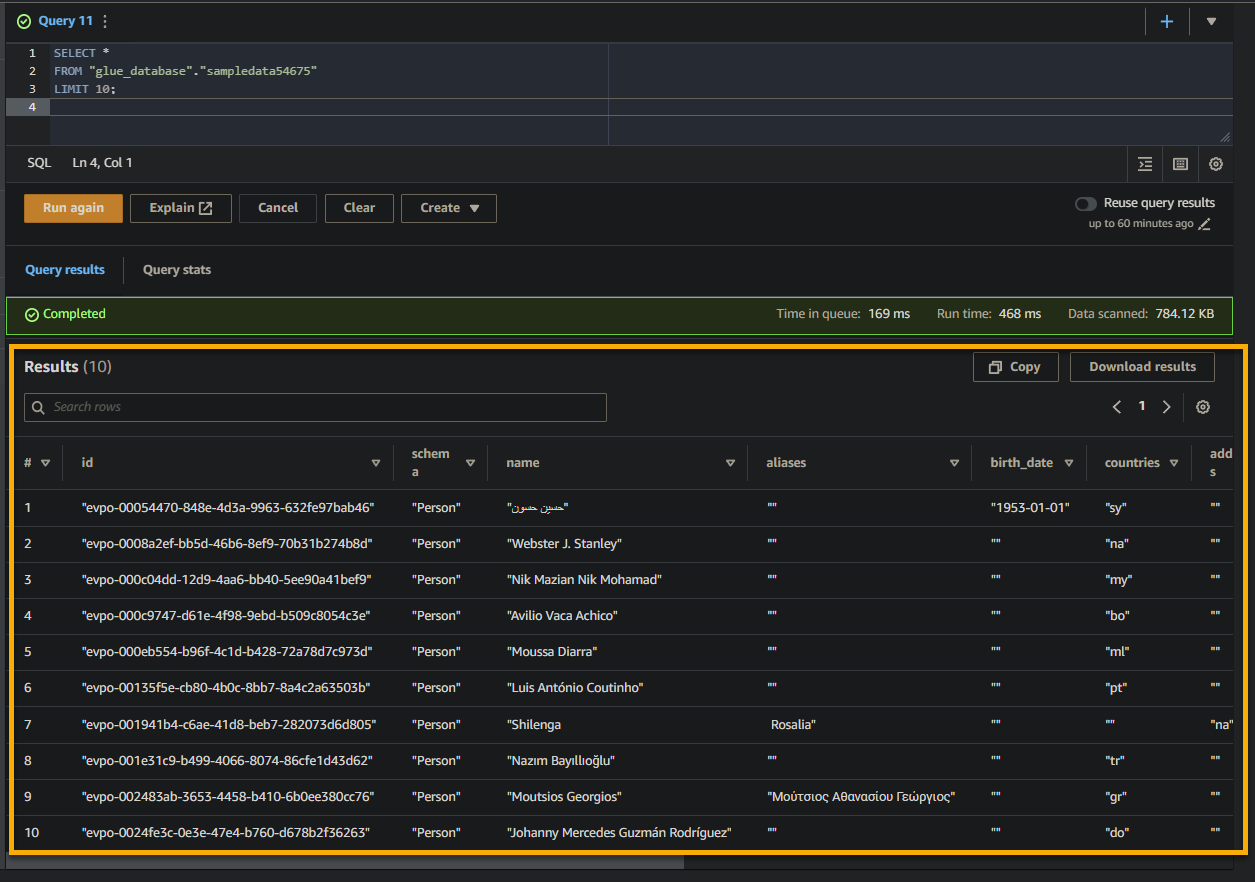
Si la consulta tiene éxito, verá los resultados en el panel Resultado, como se muestra a continuación. Los resultados contienen información sobre los registros almacenados en la tabla según su consulta SQL.
Toma nota de los nombres de las columnas, tipos de datos y valores devueltos en el conjunto de resultados. Esta información te ayuda a comprender la estructura y el contenido de los datos consultados.
Conclusión
En este tutorial, has aprendido lo básico sobre cómo utilizar AWS Glue para crear un Crawler, catalogar tus datos y consultar datos utilizando AWS Athena. La preparación y análisis de datos son esenciales para cualquier aplicación basada en datos. Y herramientas como AWS Glue ofrecen una manera rápida de extraer, transformar y cargar (ETL) datos desde diversas fuentes a una tabla de base de datos.
Con AWS Glue, ahora puedes gestionar y organizar datos rápidamente, lo que te permite centrarte más en analizar y obtener información de tus datos. Pero lo que has visto es solo la punta del iceberg. ¡Explora la amplia gama de capacidades y funcionalidades que AWS Glue puede ofrecer!
¿Por qué no aprovechar las conexiones de AWS Glue para integrarte sin problemas con otros servicios de AWS, como Amazon RDS o Amazon Redshift? Esta integración te permite construir tuberías ETL complejas y lograr incluso mayores capacidades de análisis de datos.