













Conversion de vos données brutes en informations organisées et exploitables peut sembler complexe. Eh bien, pas quand vous avez une solution rapide et efficace. Ne vous inquiétez pas ! Ce tutoriel AWS Glue convivial pour les débutants est là pour vous aider.
Dans ce tutoriel, vous apprendrez les étapes cruciales de configuration et d’exécution des transformations de données avec AWS Glue.
Explorez et simplifiez la préparation des données pour l’analyse basée sur le cloud !
Prérequis
Avant de travailler avec AWS Glue, assurez-vous d’avoir un compte Amazon Web Services (AWS) actif avec la facturation activée. Un compte gratuit sera suffisant pour ce tutoriel.
Créer un rôle IAM pour AWS Glue
Avant d’exécuter un travail de transformation, vous devez créer un rôle Identity and Access Management (IAM) qui accorde l’autorisation au service AWS Glue. Ce rôle définit le type de ressources auxquelles AWS Glue est autorisé à accéder dans votre compte AWS.
Pour créer le rôle IAM, suivez les étapes ci-dessous :
1. Ouvrez votre navigateur web préféré et connectez-vous à la Console de gestion AWS.
2. Recherchez et sélectionnez IAM dans la liste des résultats pour accéder à la console IAM.
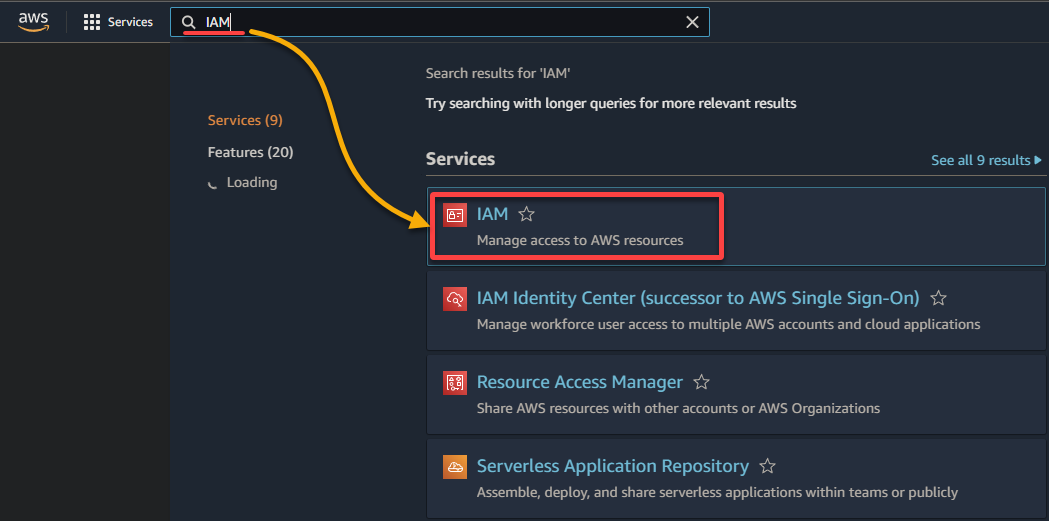
3. Dans la console IAM, accédez à Rôles (volet de gauche) et cliquez sur Créer un rôle (en haut à droite), redirigeant votre navigateur vers une nouvelle page dédiée à la configuration du rôle.

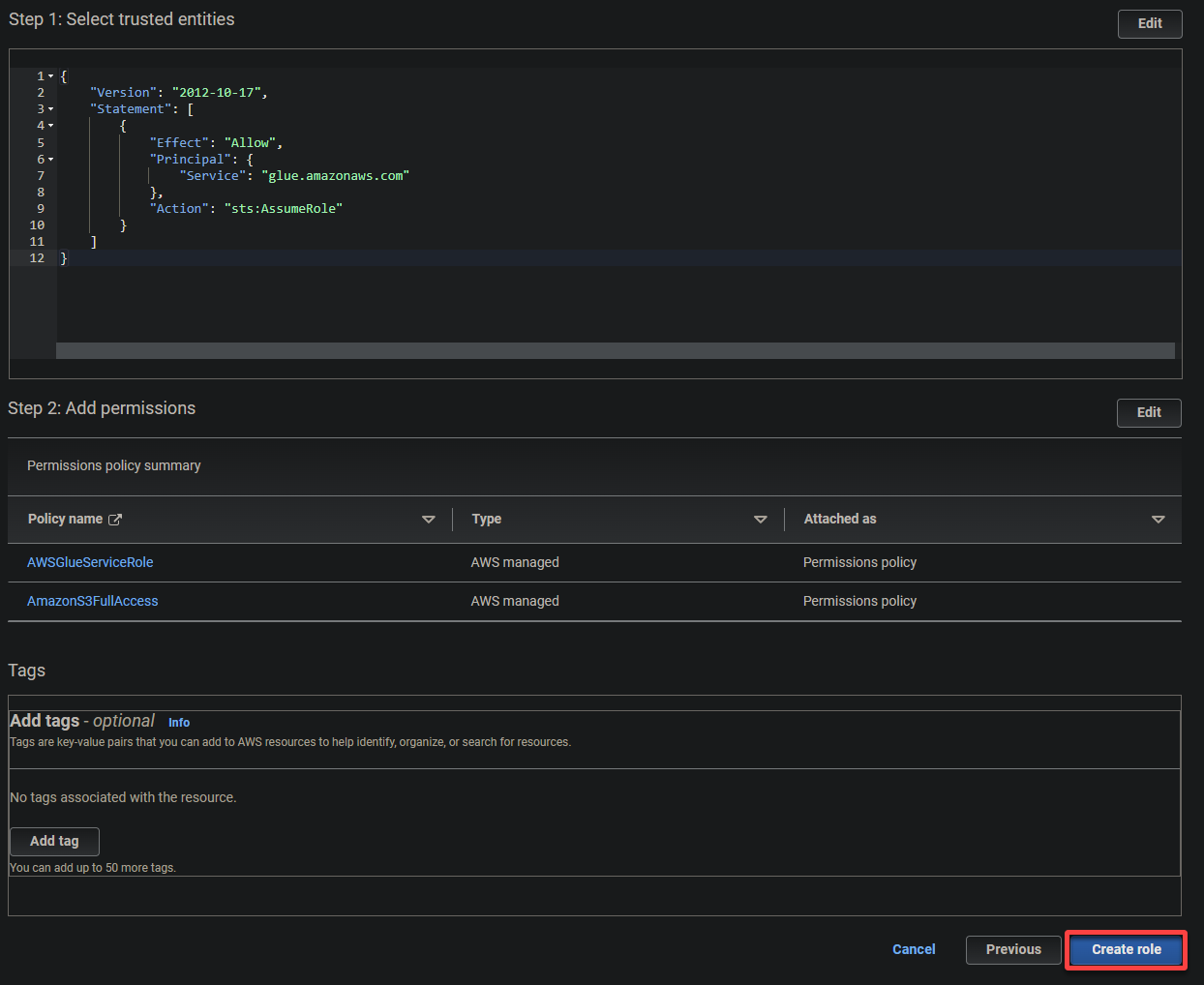
4. Configurez maintenant les paramètres suivants pour le rôle:
- Type d’entité de confiance – Sélectionnez Service AWS afin qu’un service AWS fasse confiance au rôle. Cela permet à ce service d’assumer le rôle et d’agir en votre nom.
- Cas d’utilisation – Choisissez Glue dans la section Cas d’utilisation pour d’autres services AWS puisque vous créerez le rôle IAM spécifiquement pour AWS Glue, et cliquez sur Suivant.
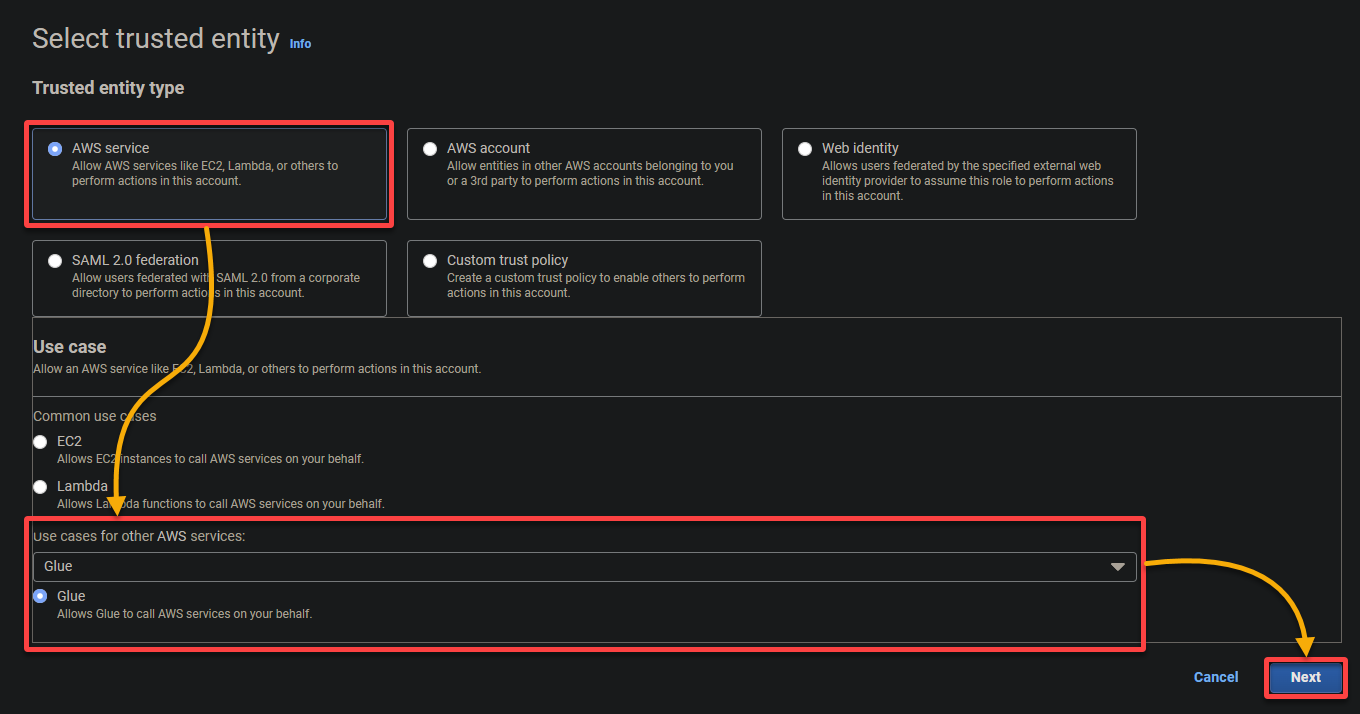
5. Recherchez et sélectionnez les politiques suivantes, et cliquez sur Suivant.
- AWSGlueServiceRole – Accorde au service AWS Glue les autorisations nécessaires pour effectuer ses opérations.
- S3FullAccess – Accorde un accès complet aux ressources S3, permettant à AWS Glue de lire depuis et d’écrire dans des compartiments S3.
AWS Glue a besoin de permissions étendues pour lire depuis et écrire dans des compartiments S3 afin d’effectuer efficacement ses tâches d’extraction, de transformation et de chargement (ETL).
? Évitez d’accorder des autorisations excessives inutiles, car elles peuvent présenter des risques de sécurité.
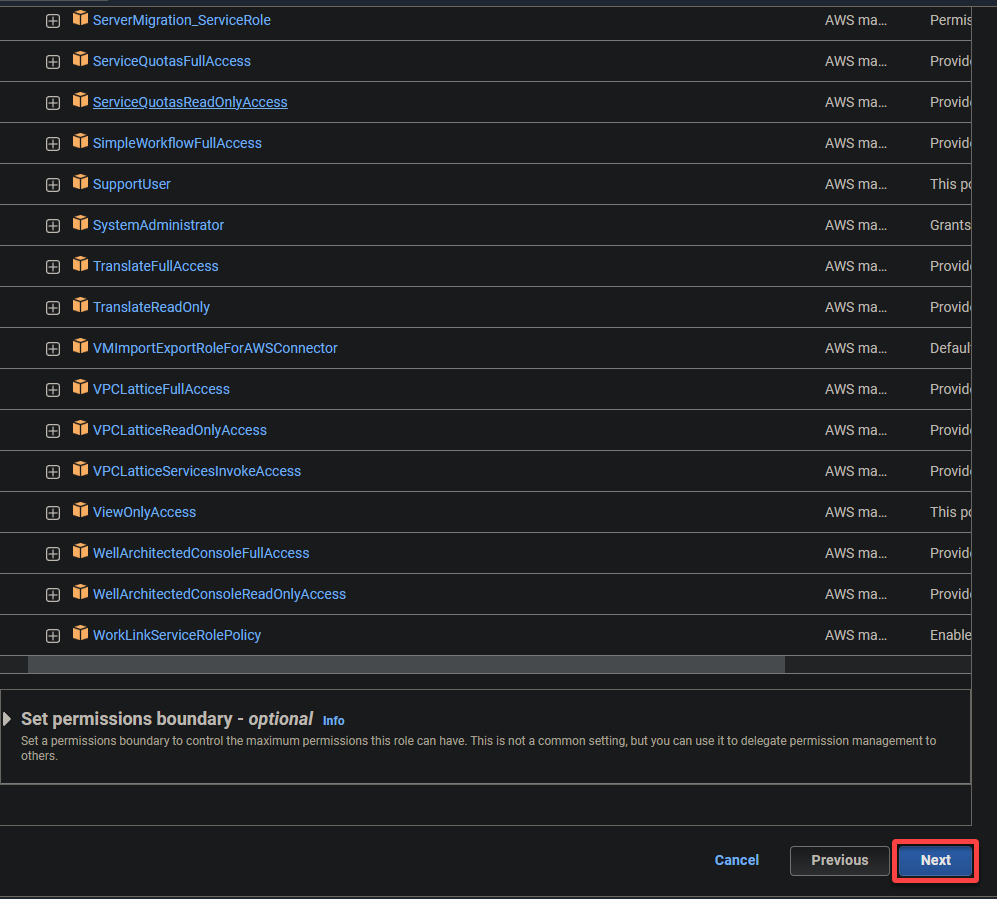
6. Fournissez un nom descriptif pour le rôle (c’est-à-dire, glue_role) et une description.
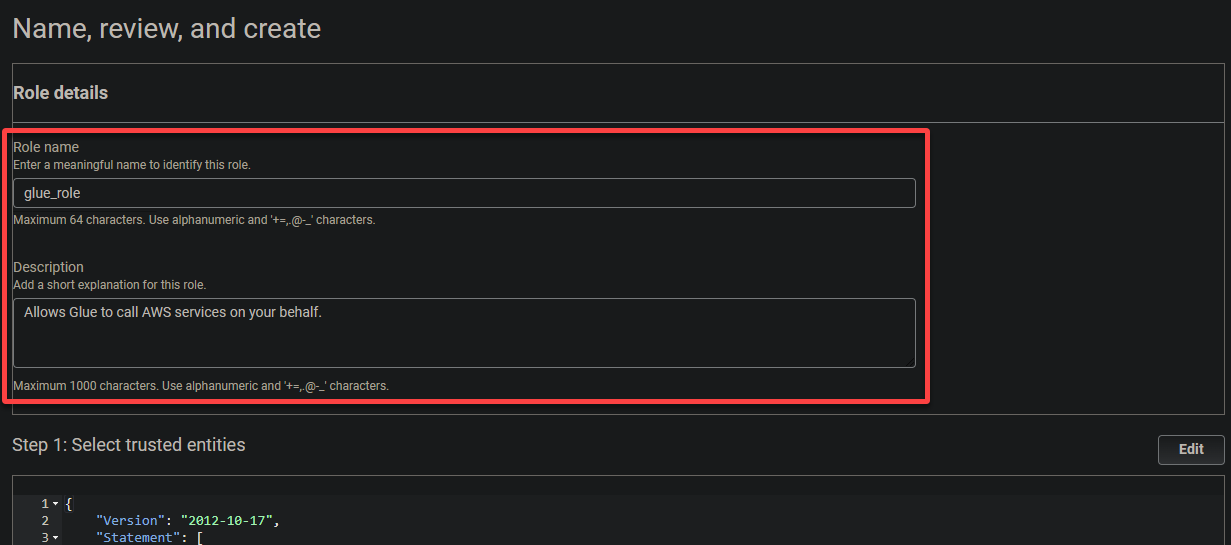
7. Enfin, faites défiler vers le bas, vérifiez vos paramètres, et cliquez sur Créer un rôle (en bas à droite) pour finaliser la création du rôle.
Création d’un compartiment S3 et téléchargement d’un fichier exemple
Maintenant que vous avez un rôle IAM pour AWS Glue, vous avez besoin d’un endroit pour stocker vos données, plus précisément, un compartiment S3. Un compartiment S3 fournit un emplacement centralisé pour stocker les données que AWS Glue traitera.
Dans cet exemple, AWS Glue utilisera AWS S3 comme magasin de données pour diverses opérations, telles que l’extraction, la transformation et le chargement (ETL) des tâches de données.
Pour créer un compartiment S3 et télécharger un fichier exemple, suivez ces étapes:
1. Téléchargez un fichier de données exemple (exemple de jeu de données Every Politician) sur votre machine locale. Ce fichier contient une collection non structurée d’enregistrements pour servir d’entrée à la tâche de transformation AWS Glue.
2. Recherchez et sélectionnez le service S3 pour accéder à la console S3.
3. Cliquez sur Créer un compartiment pour lancer la création d’un nouveau compartiment S3.

4. Maintenant, fournissez un nom unique pour votre compartiment (par exemple, sampledata54675) et sélectionnez la région où le compartiment doit être situé.
A unique name lets you avoid conflicts with existing bucket names is crucial, while the region selection determines the physical location of your bucket’s data.
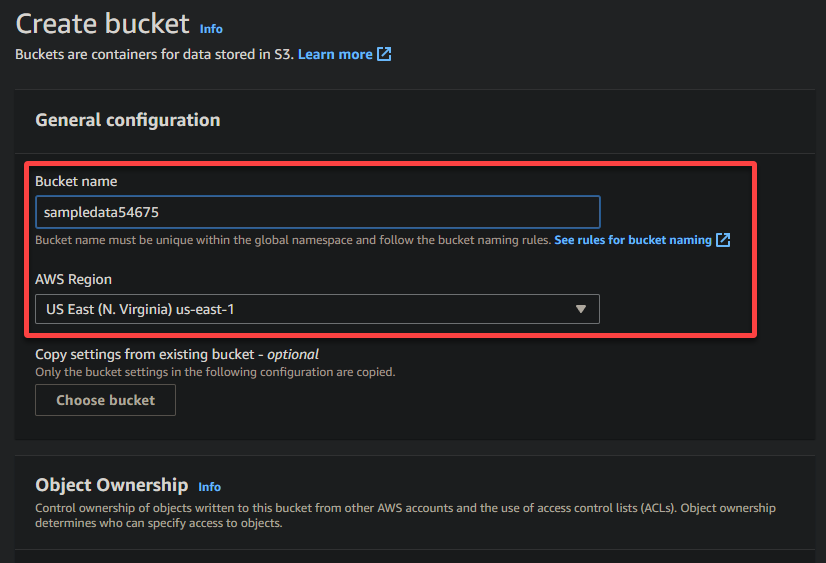
5. Faites défiler vers le bas, laissez les autres options telles quelles, et cliquez sur Créer le compartiment pour créer le compartiment.

6. Une fois créé, cliquez sur le lien hypertexte du compartiment S3 nouvellement créé pour accéder au compartiment.

7. Cliquez sur Charger et localisez le fichier exemple que vous souhaitez télécharger.
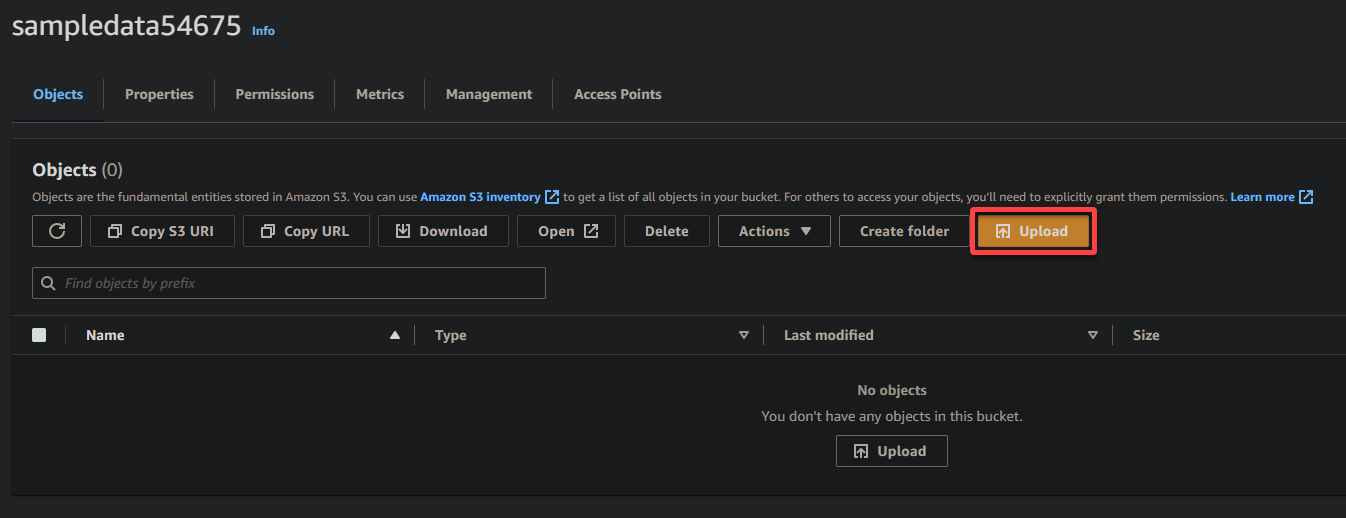
8. Enfin, laissez les autres paramètres tels qu’ils sont, et cliquez sur Upload pour télécharger le fichier d’exemple dans le bucket nouvellement créé.
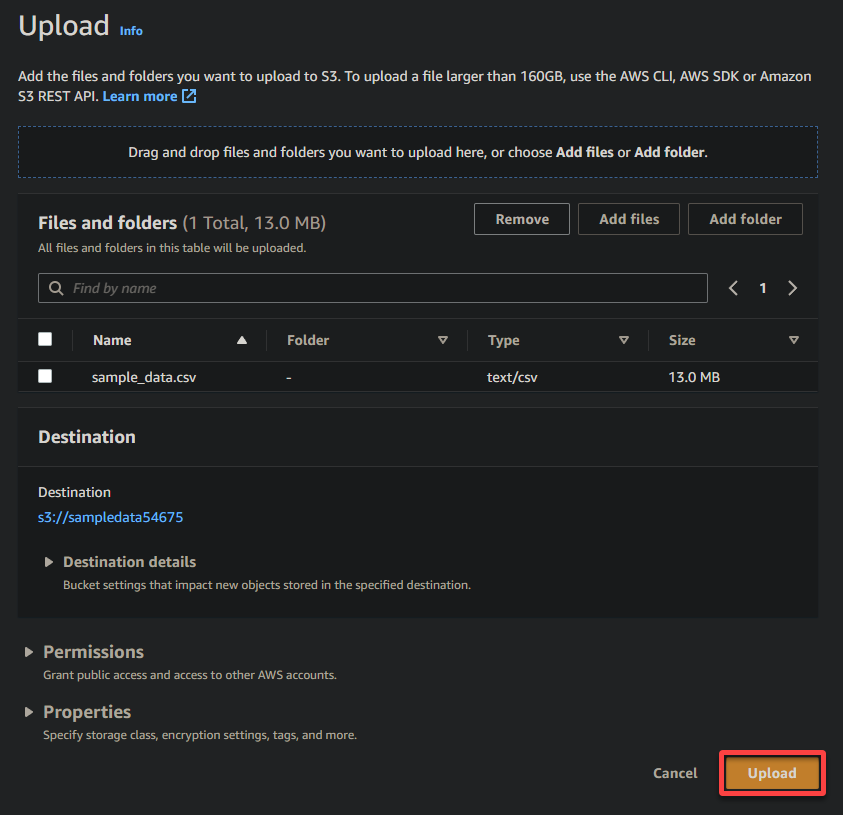
Si réussi, vous verrez votre fichier nouvellement téléchargé dans votre bucket, comme illustré ci-dessous.
Création d’un Crawler Glue pour Analyser et Cataloguer les Données
Vous venez de télécharger des données d’exemple dans votre bucket S3, mais comme elles sont actuellement non structurées, vous avez besoin d’un moyen de lire les données et de construire un catalogue de métadonnées. Comment ? En créant un crawler Glue qui scanne et catalogue automatiquement les données.
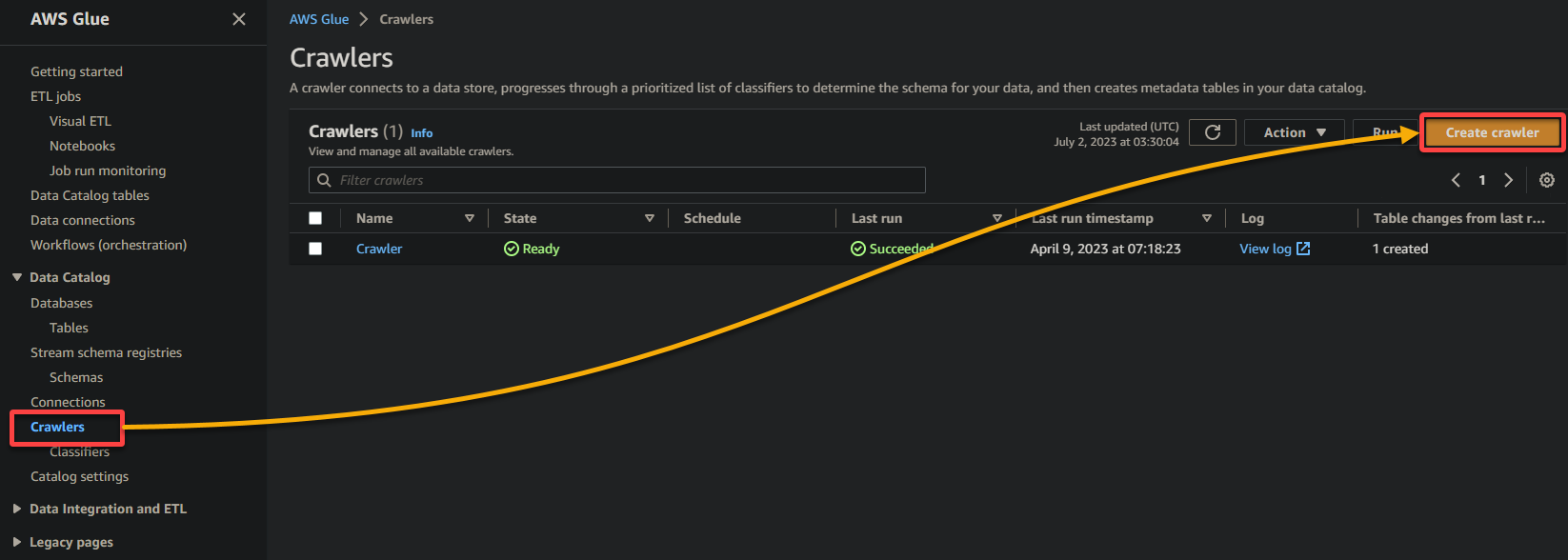
Pour créer un crawler Glue, suivez les étapes ci-dessous :
1. Accédez à la console AWS Glue via la Console de gestion AWS, comme illustré ci-dessous.
2. Ensuite, accédez à Crawler (volet gauche) et cliquez sur Ajouter un crawler (en haut à droite) pour initier la création d’un nouveau crawler Glue.
3. Fournissez un nom descriptif (par exemple, glue_crawler) et une description pour le crawler, laissez les autres paramètres tels qu’ils sont, et cliquez sur Suivant.
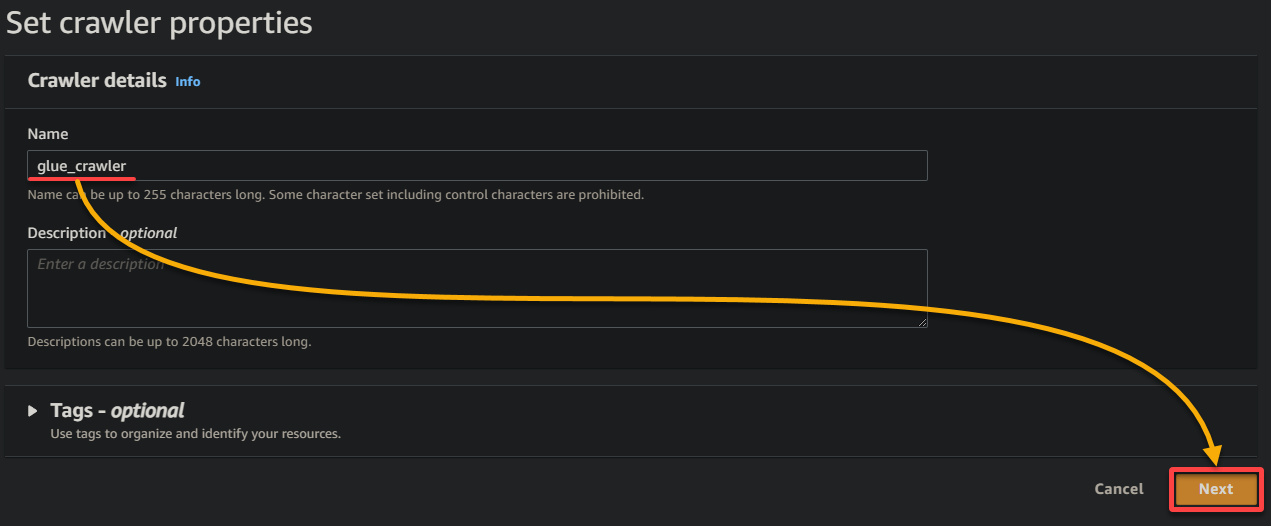
4. Maintenant, cliquez sur Ajouter une source de données sous Sources de données pour initier l’ajout d’une nouvelle source de données au crawler.
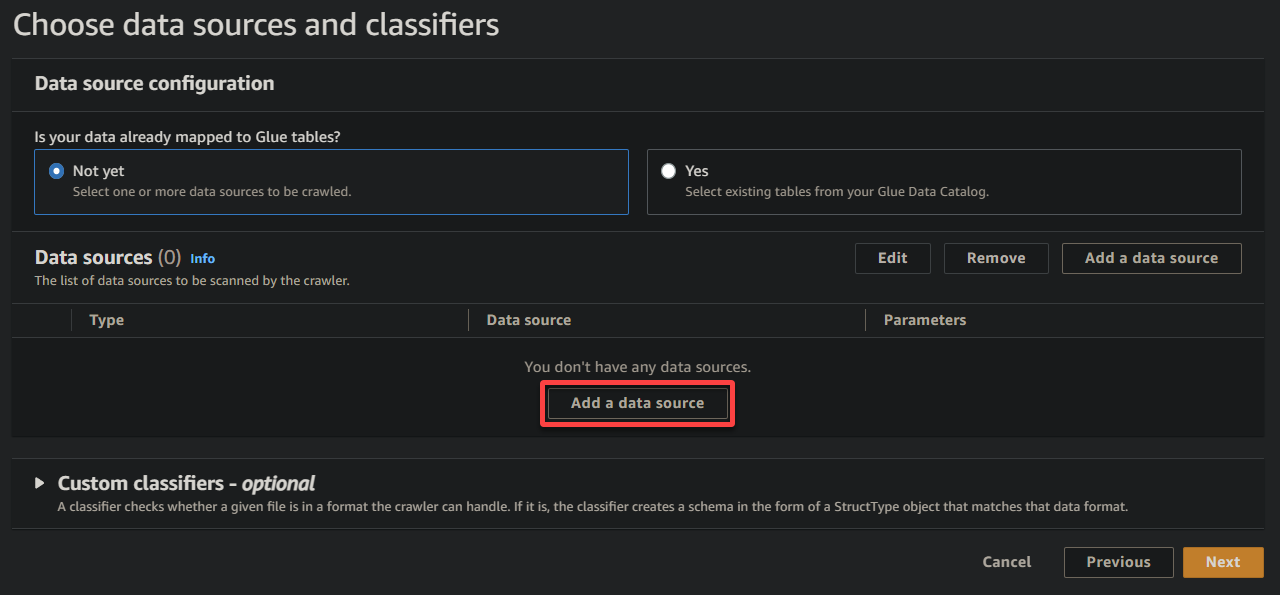
5. Dans la fenêtre contextuelle, configurez la source de données comme suit :
- Source de données – Sélectionnez S3 puisque vos données se trouvent dans votre bucket S3.
- Chemin S3 – Cliquez sur Parcourir S3, et choisissez le bucket qui contient vos données d’échantillon téléchargées (sampledata54675).
- Gardez les autres paramètres tels quels, et cliquez sur Ajouter une source de données S3 pour ajouter les données d’échantillon au crawler.
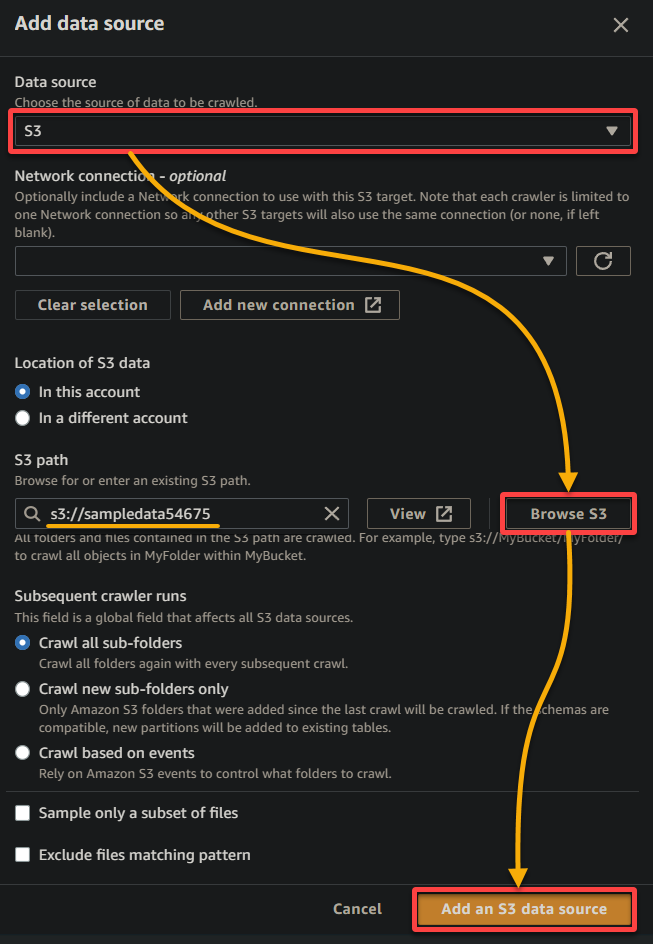
6. Une fois configuré, vérifiez la source de données, comme indiqué ci-dessous, et cliquez sur Suivant pour continuer.
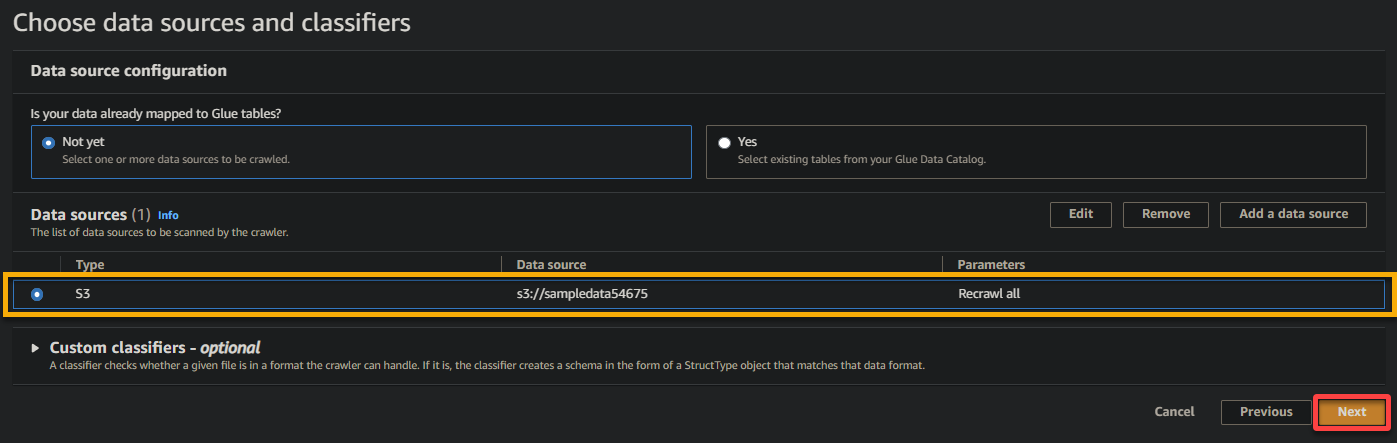
7. À l’écran suivant, sélectionnez le rôle IAM que vous avez créé précédemment (glue_role), gardez les autres paramètres tels quels, et cliquez sur Suivant.
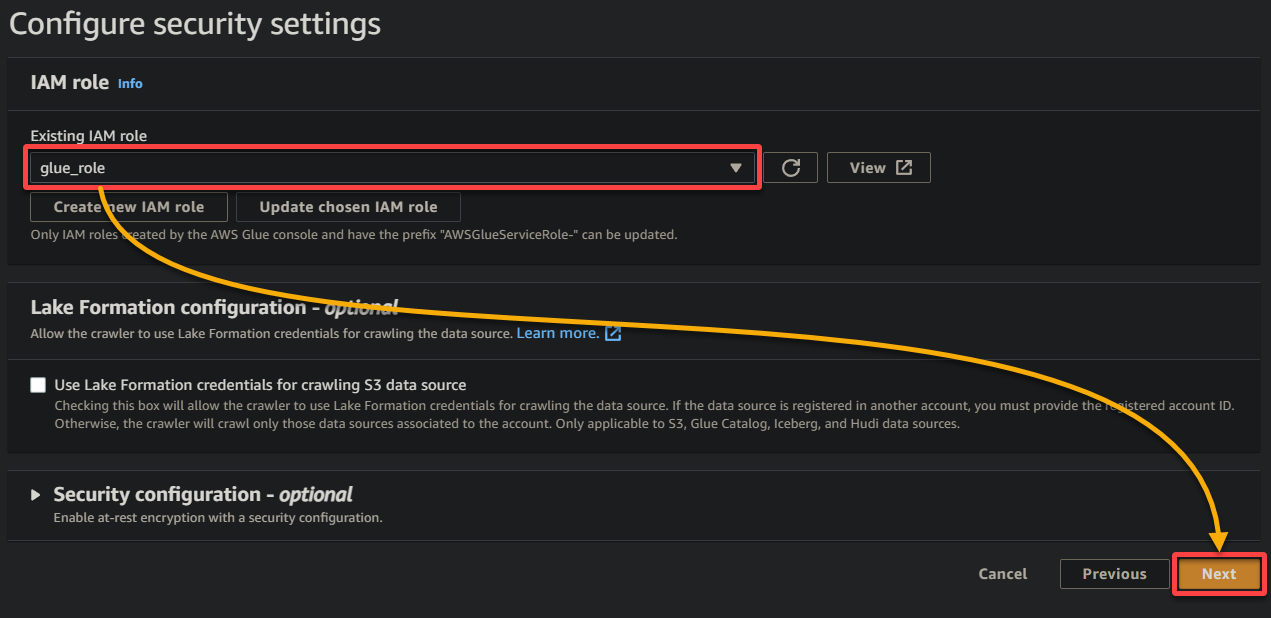
8. Sous la sortie et la planification, cliquez sur Ajouter une base de données pour initier l’ajout d’une nouvelle base de données pour stocker les données traitées et les métadonnées générées par votre crawler Glue. Cette action ouvre un nouvel onglet de navigateur, où vous configurerez les détails de votre base de données (étape huit).
Cette base de données fournit une représentation structurée des données pour les requêtes et l’analyse.
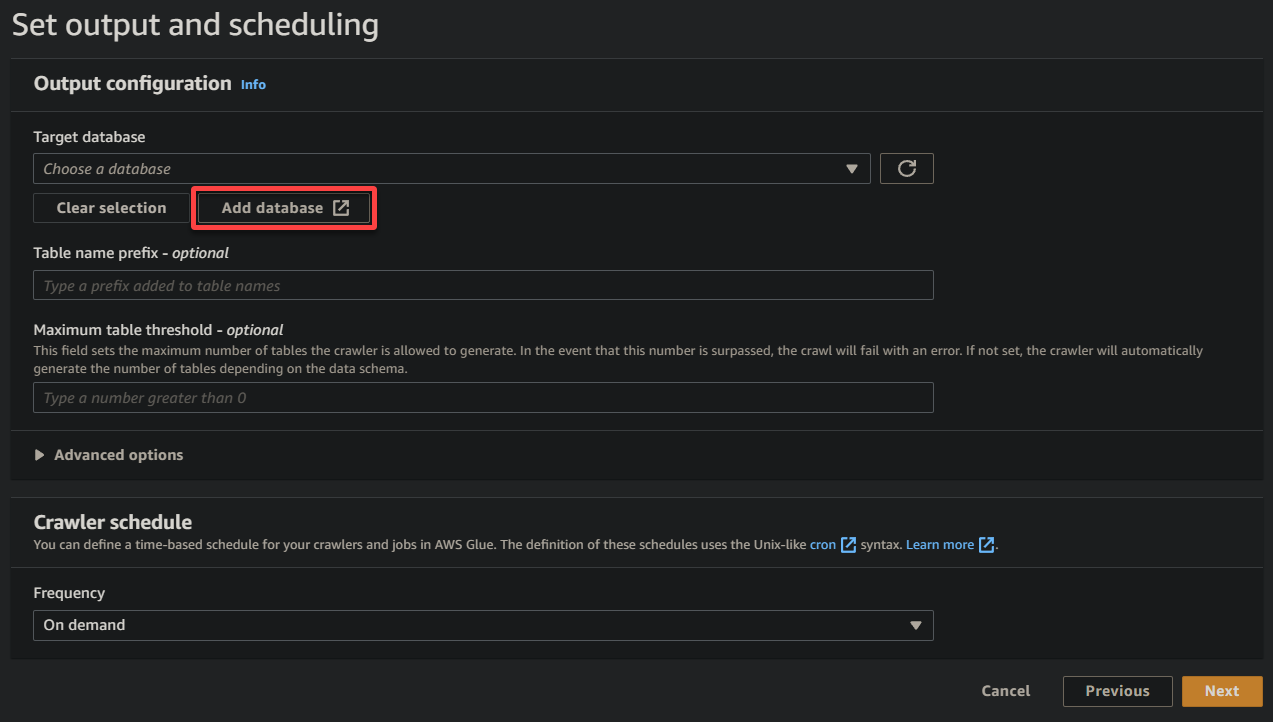
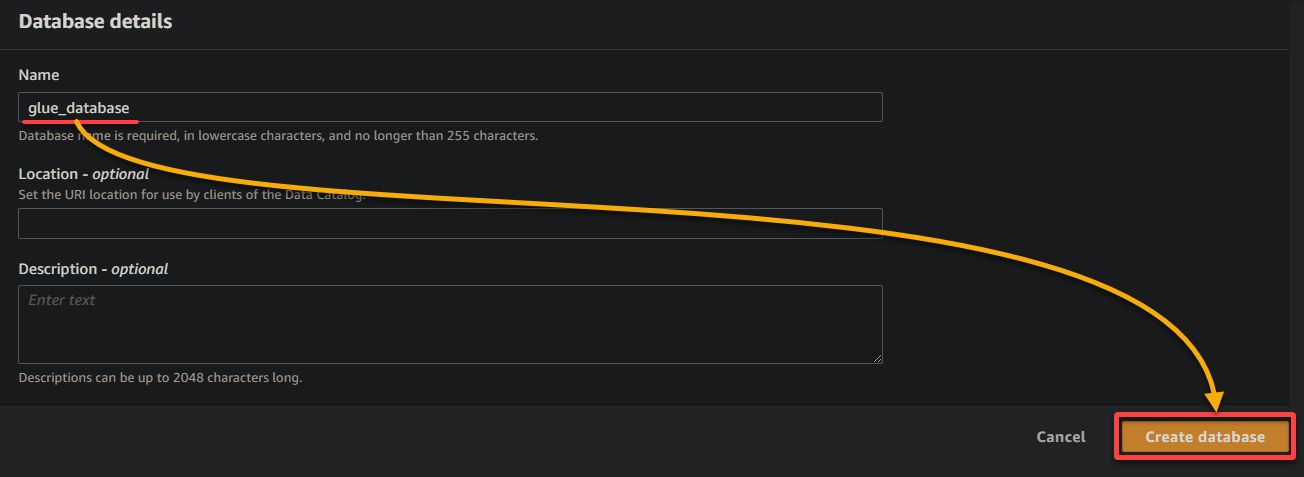
9. Sur le nouvel onglet du navigateur, fournissez un nom de base de données descriptif (c’est-à-dire, glue_database), et cliquez sur Créer une base de données pour créer la base de données.
10. Revenez à l’onglet précédent du navigateur, sélectionnez la base de données nouvellement créée (glue_database) dans le menu déroulant, gardez les autres paramètres tels quels, et cliquez sur Suivant.
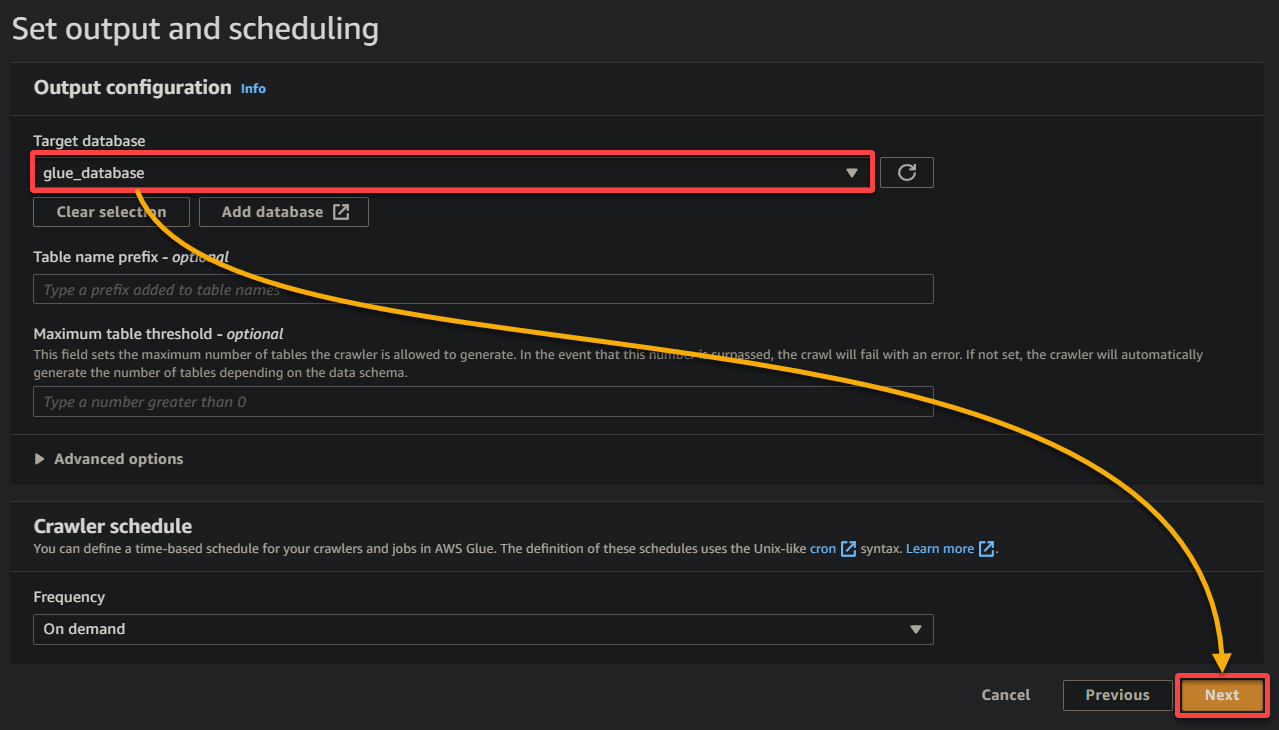
11. Enfin, passez en revue vos paramètres sur l’écran final pour vous assurer qu’ils sont exacts, et cliquez sur Créer le crawler (en bas à droite) pour créer le nouveau crawler.
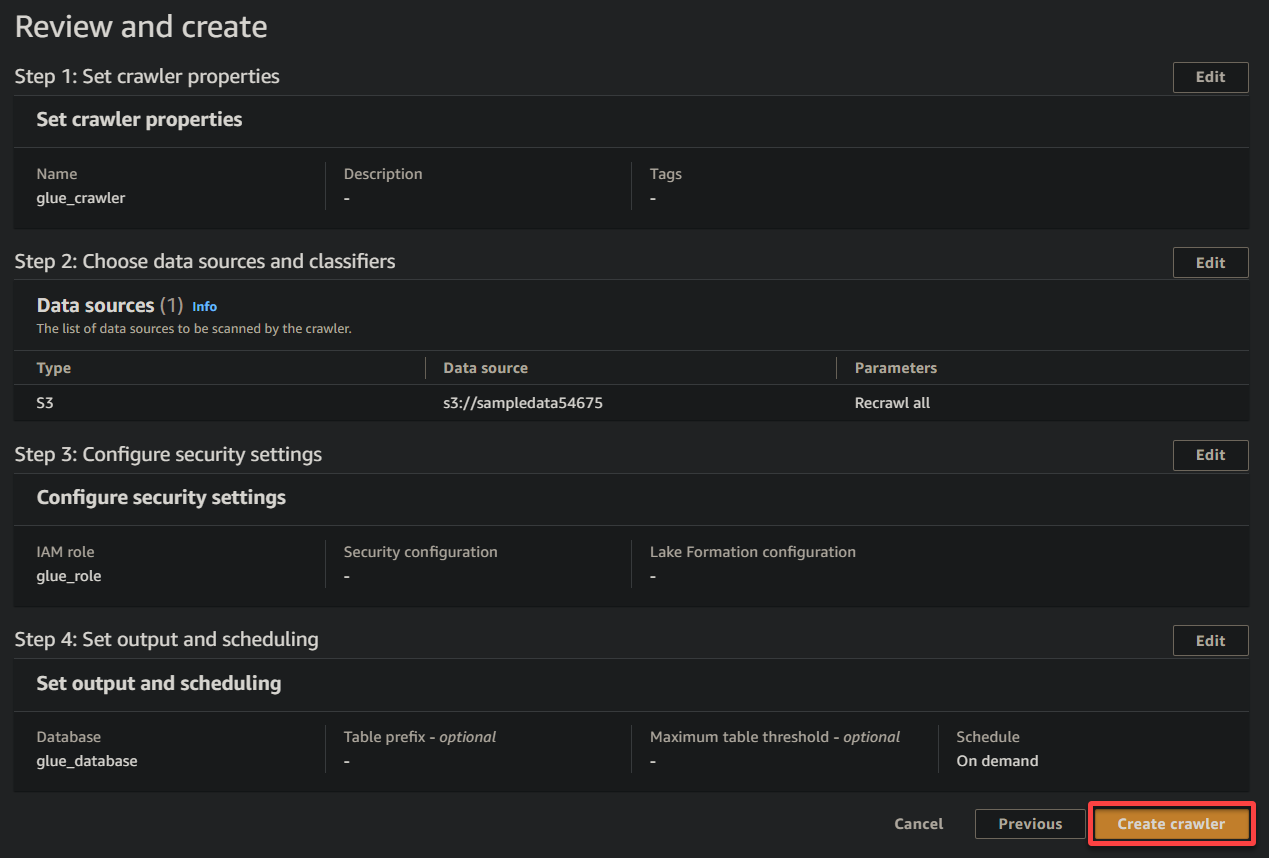
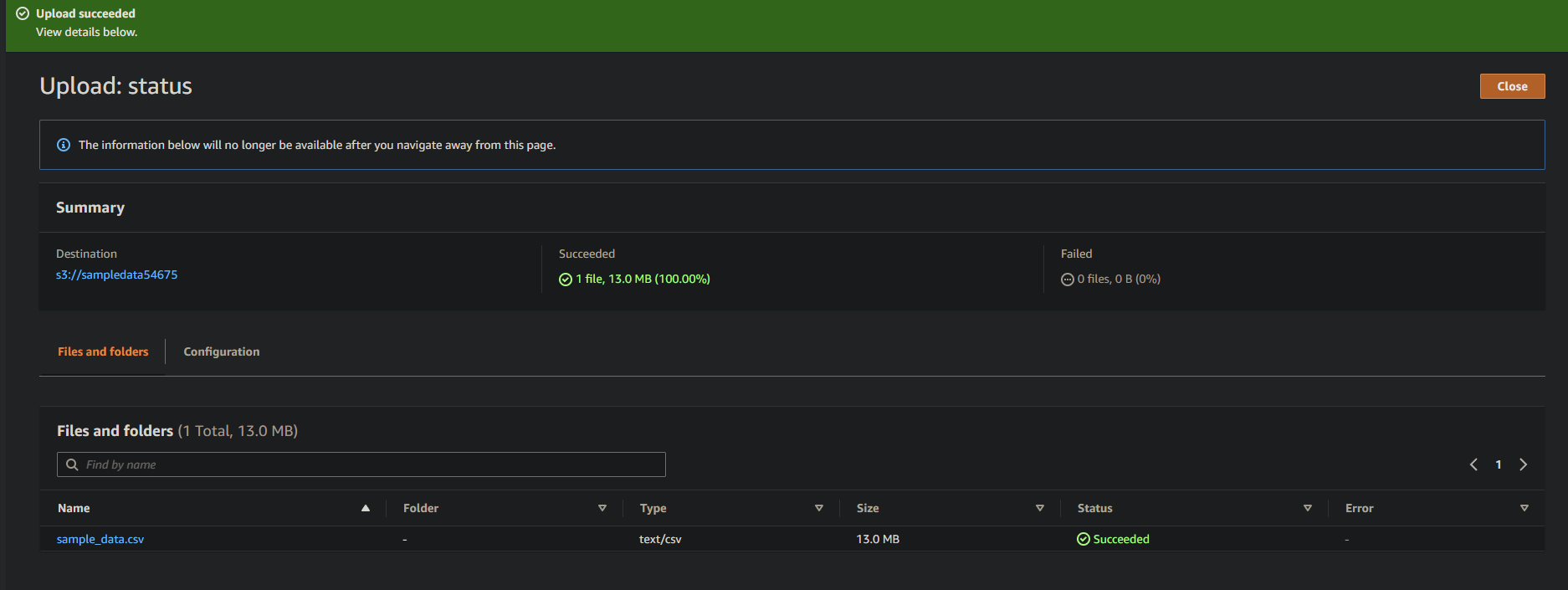
Si tout se passe bien, vous verrez un écran confirmant la création réussie du crawler. Ne fermez pas encore cet écran ; vous exécuterez ce crawler dans la section suivante.
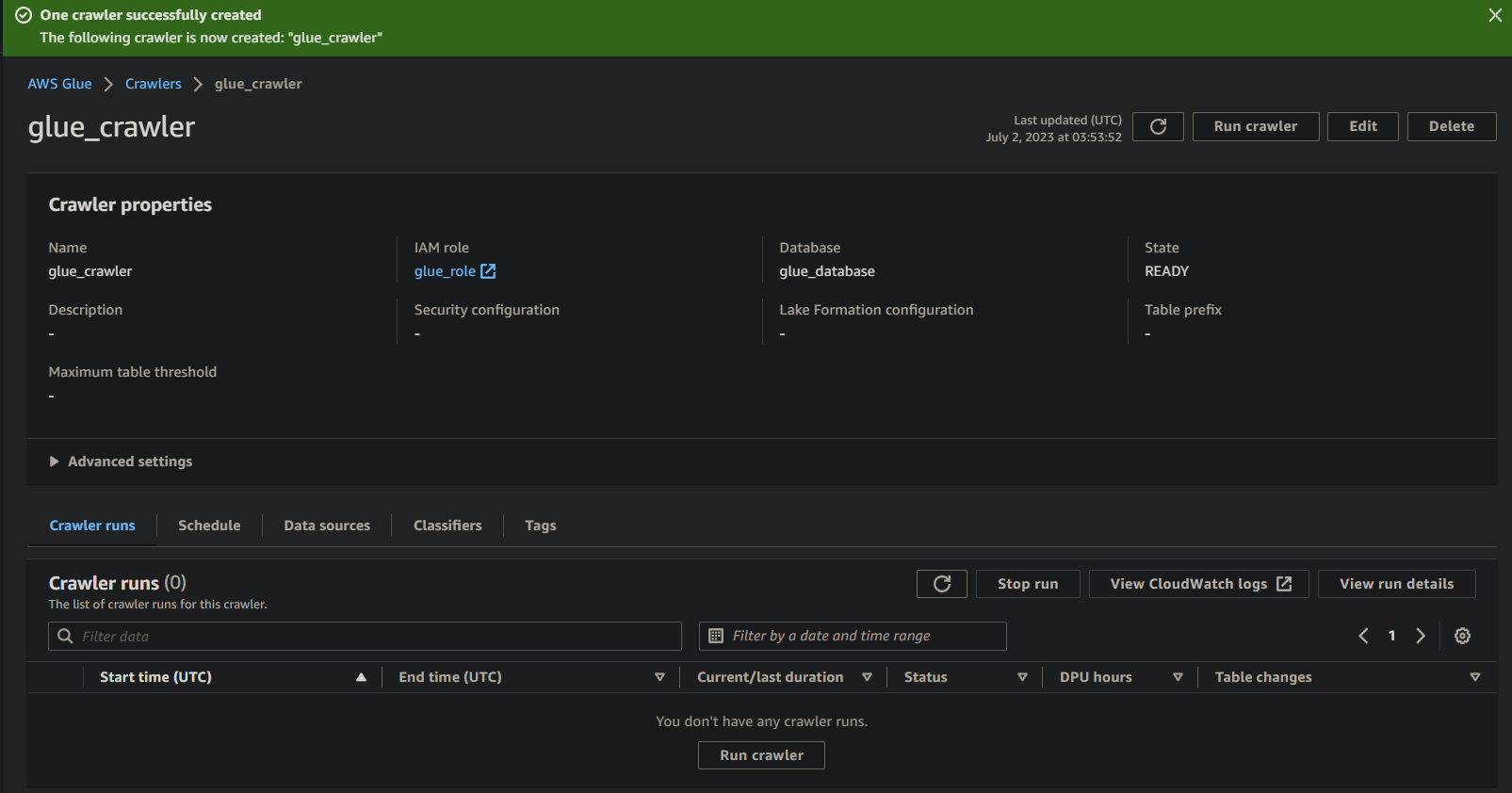
Exécution du Glue Crawler pour construire un catalogue de métadonnées
Avec un nouveau crawler à votre disposition, lancer le crawler est essentiel pour démarrer le processus de numérisation et de catalogage. Votre glue crawler construira un catalogue de métadonnées qui fournit une représentation structurée de vos données à des fins de requêtage et d’analyse.
Pour exécuter votre glue crawler nouvellement créé :
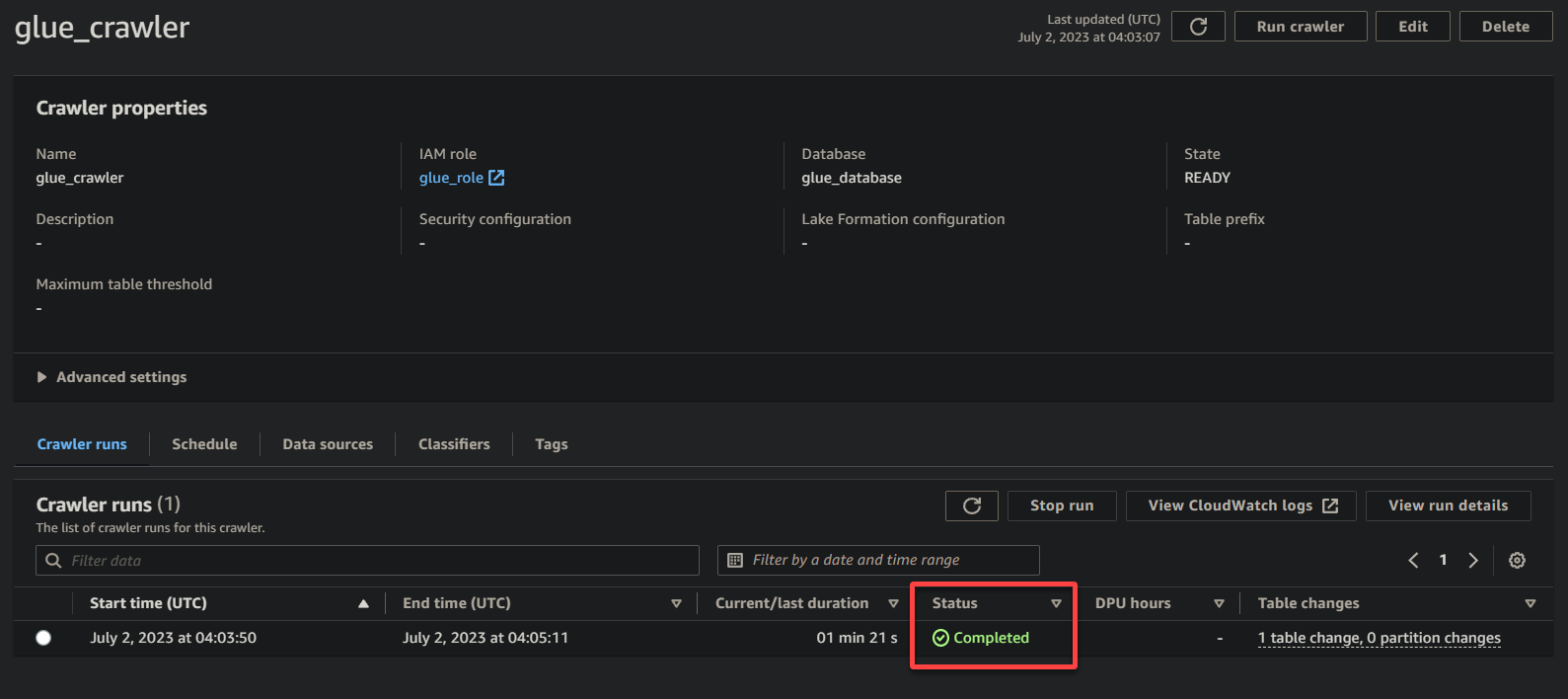
1. Sur la page des détails du crawler, cliquez sur Exécuter le crawler sous l’onglet Exécutions du crawler pour lancer l’exécution du crawler.
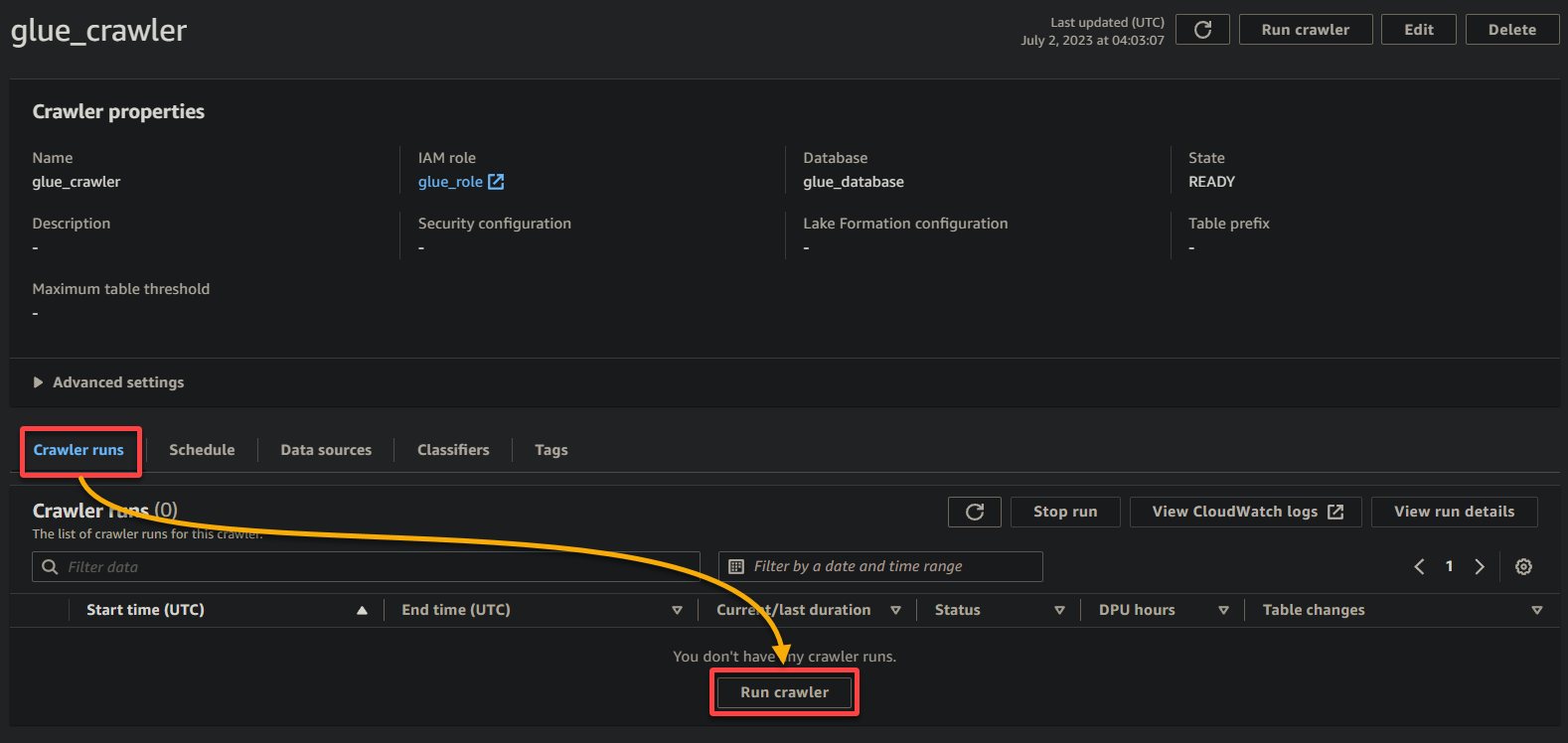
Une fois que le crawler commence à s’exécuter, vous verrez son état et sa progression sur la page des détails du crawler.
En fonction de la taille et de la complexité de vos données, le crawler peut prendre un certain temps pour terminer son exécution. Vous pouvez rafraîchir périodiquement la page pour voir l’état mis à jour du crawler.
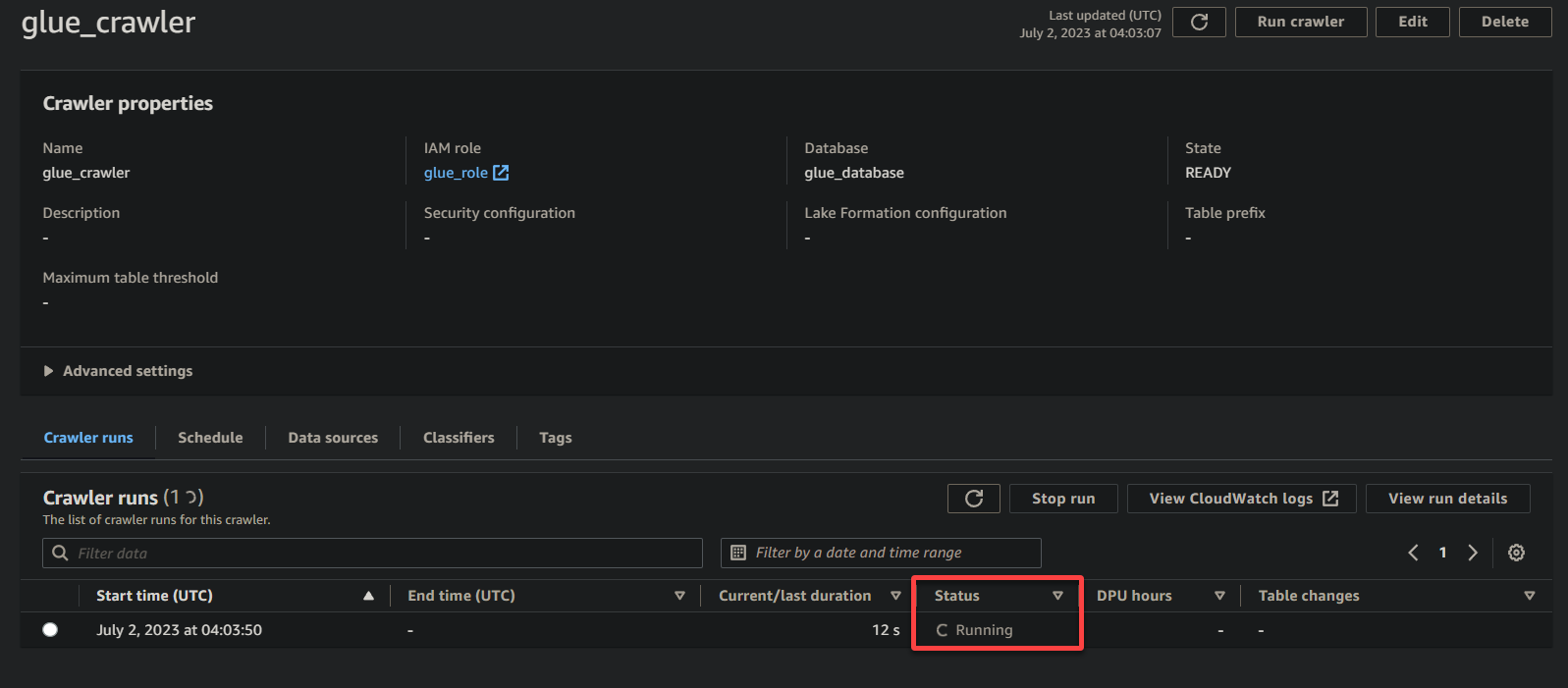
Une fois que le crawler a terminé son exécution, le statut passe à Terminé, comme indiqué ci-dessous. À ce stade, vous pouvez procéder à l’interrogation de vos données.
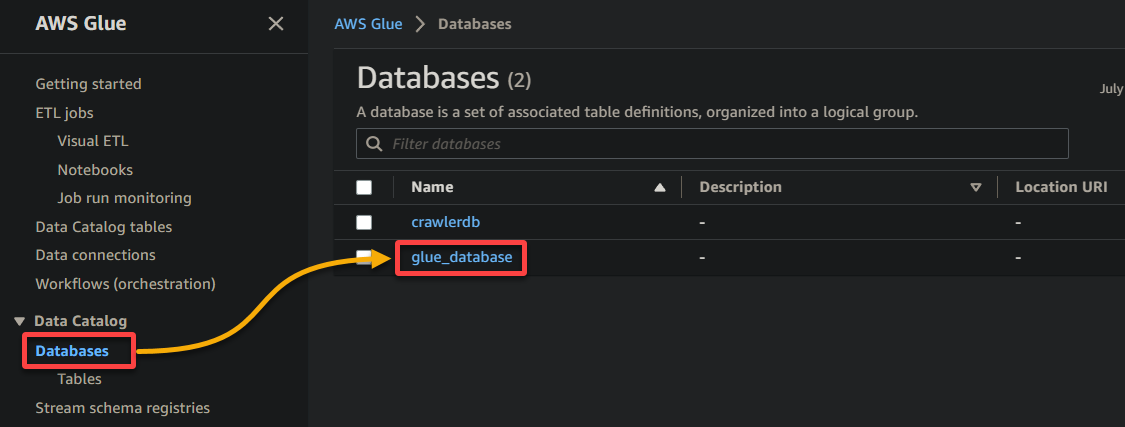
2. Ensuite, accédez à Base de données (volet gauche) et cliquez sur votre base de données pour accéder à ses propriétés et tables.
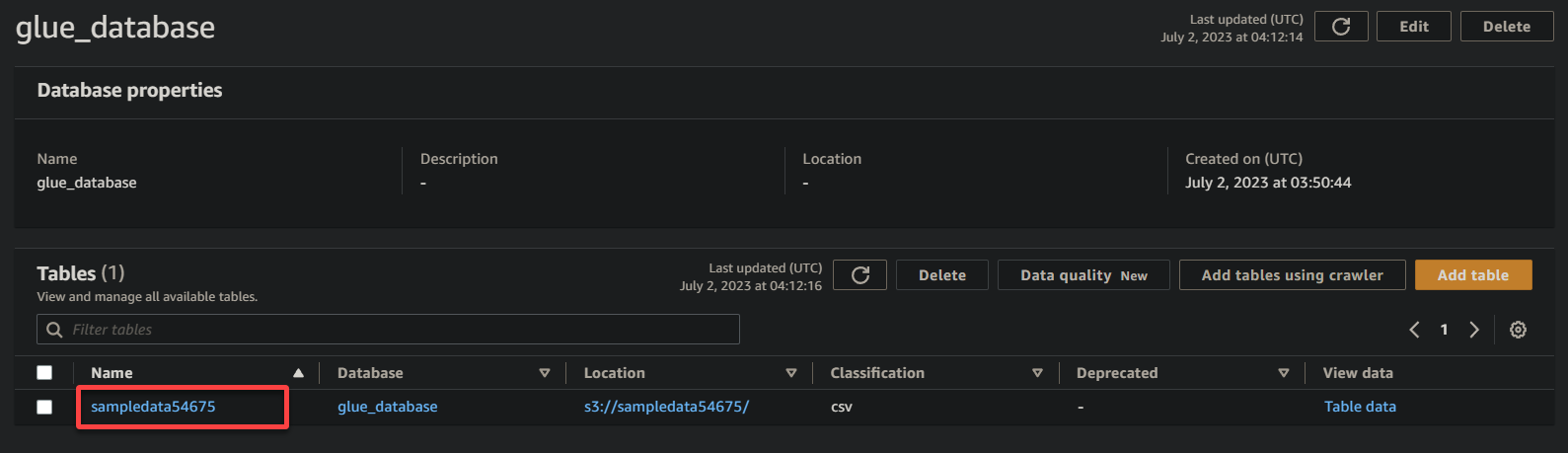
3. Enfin, cliquez sur le nom de votre compartiment (sampledata54675), maintenant une table, pour voir les données stockées.
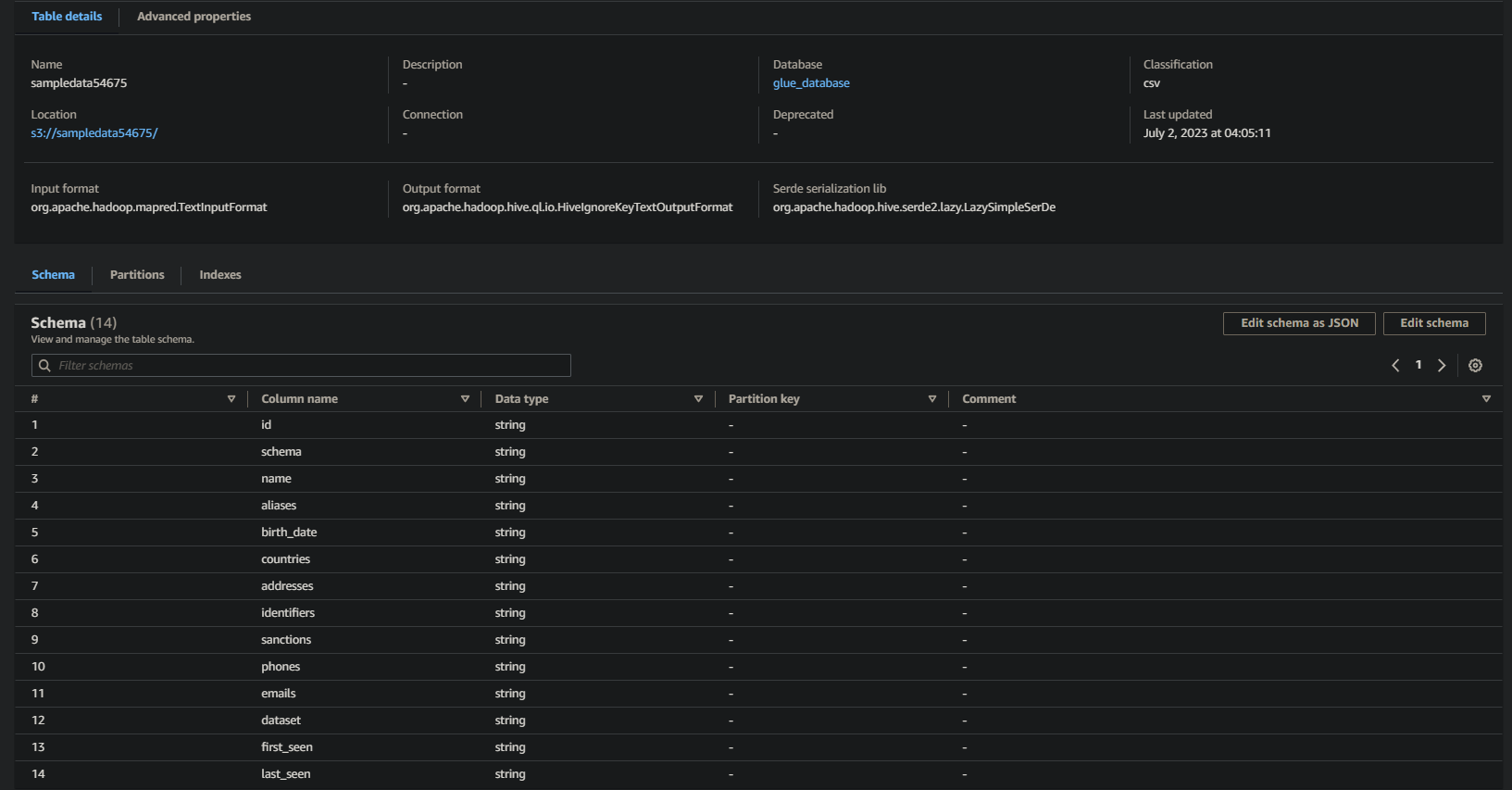
En cas de succès, vous verrez des informations similaires ci-dessous. Ces informations confirment que les données ont été transformées avec succès en table de base de données, fournissant des détails précieux.
Interrogation des données cataloguées via AWS Athena
Maintenant que vos données sont disponibles dans le catalogue de données AWS Glue, vous pouvez utiliser différents outils pour interroger et analyser vos données. Un tel outil est AWS Athena, un service de requête interactif qui vous permet d’analyser des données dans le cloud en utilisant SQL standard.
Pour interroger les données en utilisant AWS Athena, suivez les étapes ci-dessous :
1. Recherchez et accédez à la console Athena.
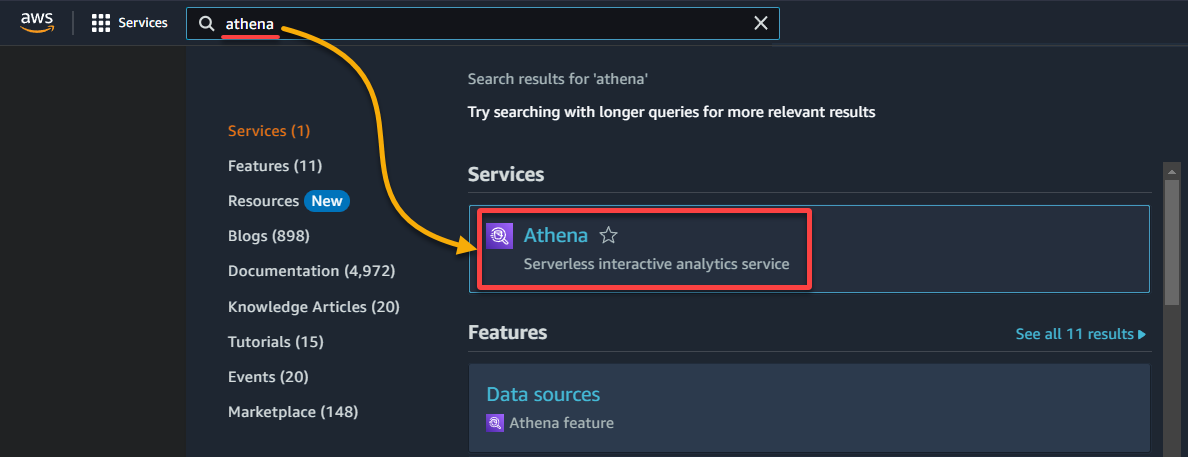
2. Sélectionnez la base de données où vos données sont cataloguées sous la section Données comme suit :
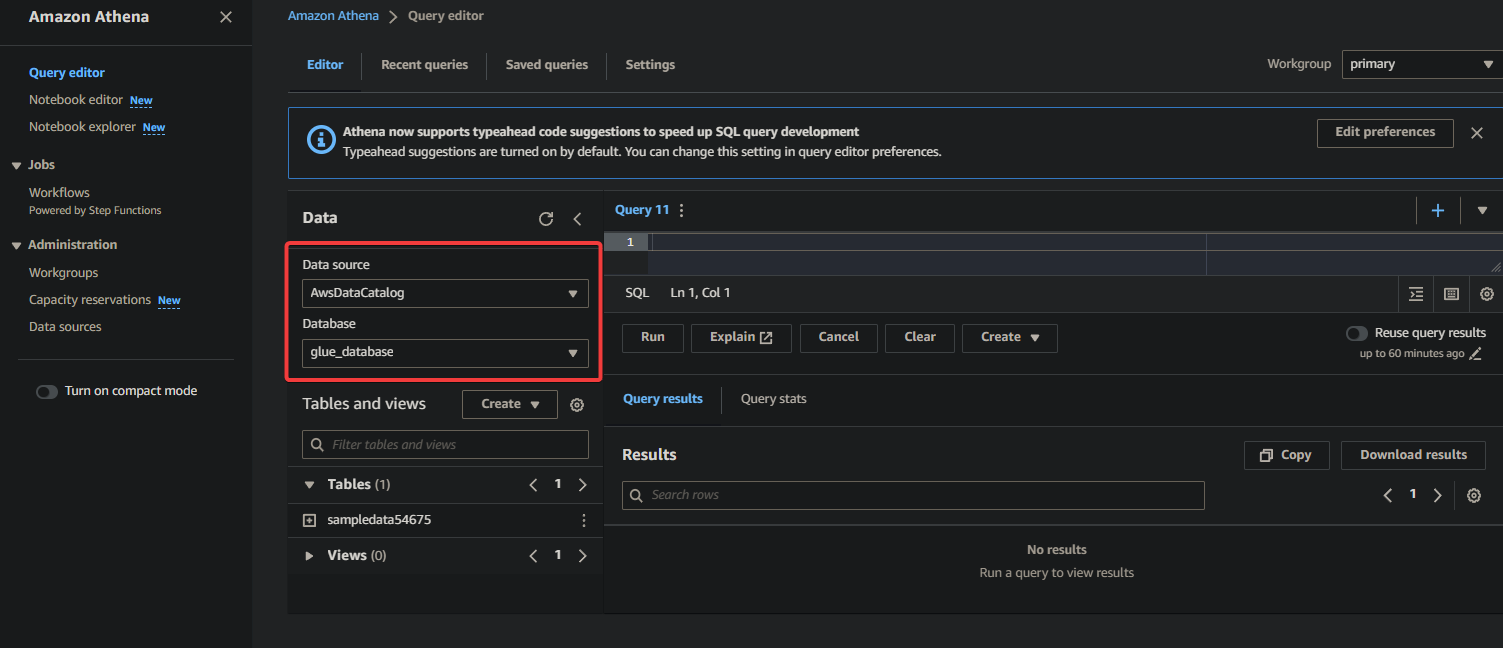
- Source de données – Sélectionnez AwsDataCatalog pour indiquer que vous souhaitez interroger les données cataloguées dans AWS Glue.
- Base de données – Sélectionnez la base de données appropriée dans le champ déroulant (c’est-à-dire glue_database).
? Si vous ne voyez pas votre base de données souhaitée dans le menu déroulant, assurez-vous que le crawler a terminé son exécution et catalogué les données.
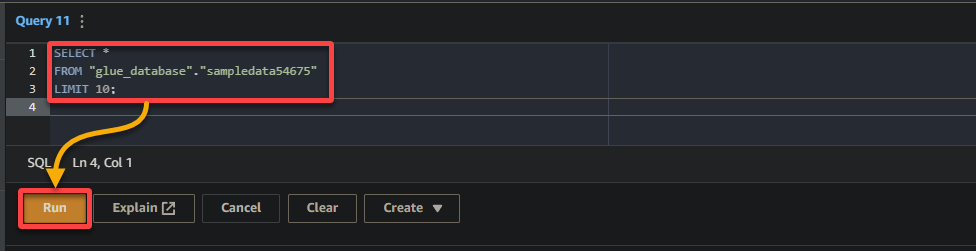
3. Enfin, remplissez et exécutez la requête suivante dans l’éditeur de requêtes sur la droite.
Cette requête renvoie les 10 premières lignes de la table sampledata54675 dans la base de données glue_database. N’hésitez pas à modifier la requête pour répondre à vos besoins spécifiques.
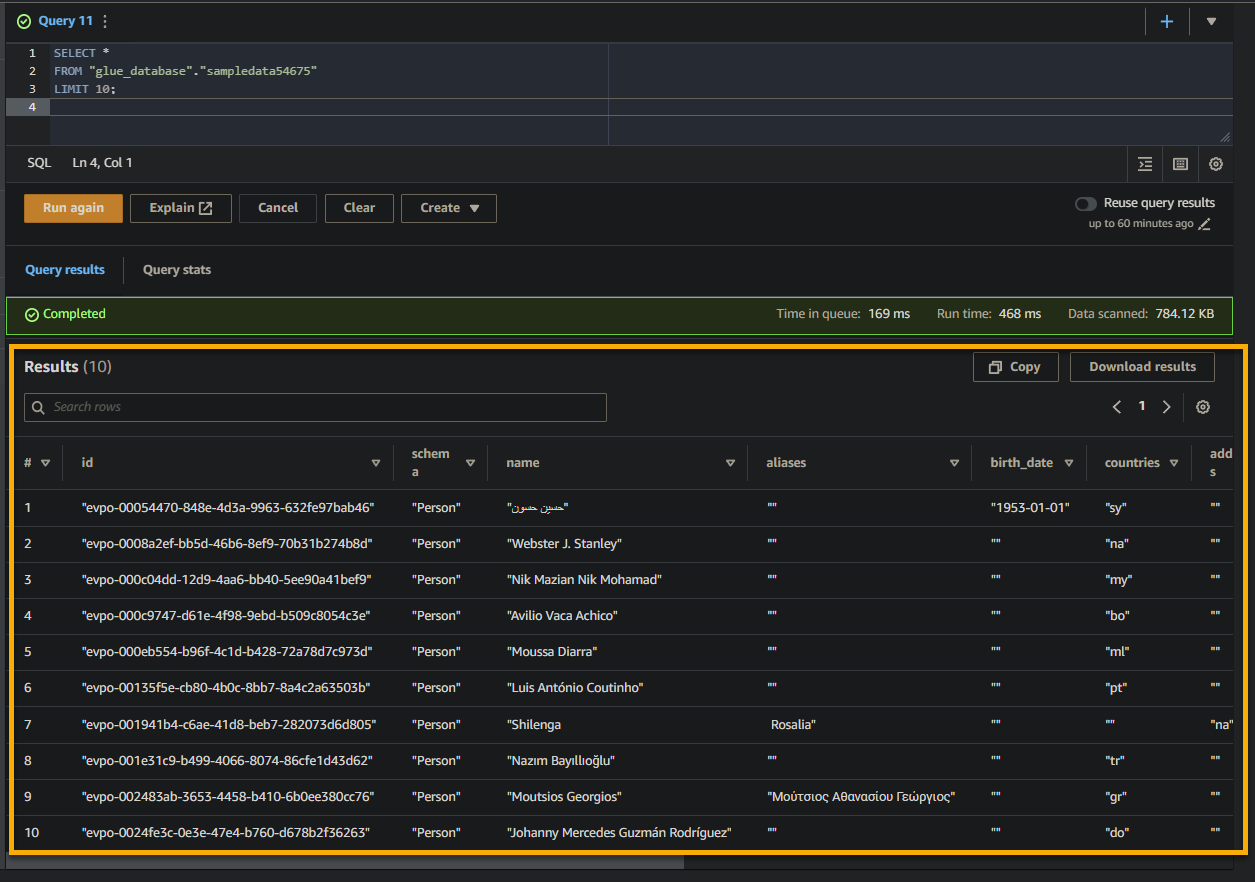
Si la requête aboutit, vous verrez les résultats dans le volet Résultat, comme indiqué ci-dessous. Les résultats contiennent des informations sur les enregistrements stockés dans la table en fonction de votre requête SQL.
Prenez note des noms de colonnes, des types de données et des valeurs renvoyées dans l’ensemble de résultats. Cette information vous aide à comprendre la structure et le contenu des données interrogées.
Conclusion
Dans ce tutoriel, vous avez appris les bases de l’utilisation d’AWS Glue pour créer un Glue Crawler, cataloguer vos données et interroger les données à l’aide d’AWS Athena. La préparation et l’analyse des données sont essentielles pour toute application axée sur les données. Et des outils comme AWS Glue offrent un moyen rapide d’extraire, de transformer et de charger (ETL) des données à partir de différentes sources dans une table de base de données.
Avec AWS Glue, vous pouvez maintenant gérer et organiser rapidement les données, vous permettant de vous concentrer davantage sur l’analyse et la dérivation d’informations à partir de vos données. Mais ce que vous avez vu n’est que la pointe de l’iceberg. Explorez la vaste gamme de capacités et de fonctionnalités qu’AWS Glue peut offrir!
Pourquoi ne pas tirer parti des connexions AWS Glue pour intégrer de manière transparente avec d’autres services AWS, tels que Amazon RDS ou Amazon Redshift? Cette intégration vous permet de construire des pipelines ETL complexes et d’atteindre des capacités d’analyse de données encore plus grandes.