













Системы RAG объединяют силу механизмов извлечения и языковых моделей, что позволяет им генерировать контекстуально релевантные и обоснованные ответы. Однако оценить производительность и выявить потенциальные режимы сбоя систем RAG может быть очень сложно.
Поэтому разработан RAG Триада – набор из трех метрик, которые охватывают три основных этапа выполнения системы RAG: Контекстная Релевантность, Обоснованность и Релевантность Ответа. В этом блоге я расскажу о тонкостях RAG Триада и проведу вас через процесс настройки, выполнения и анализа оценки системы RAG.
Введение в RAG Триада:
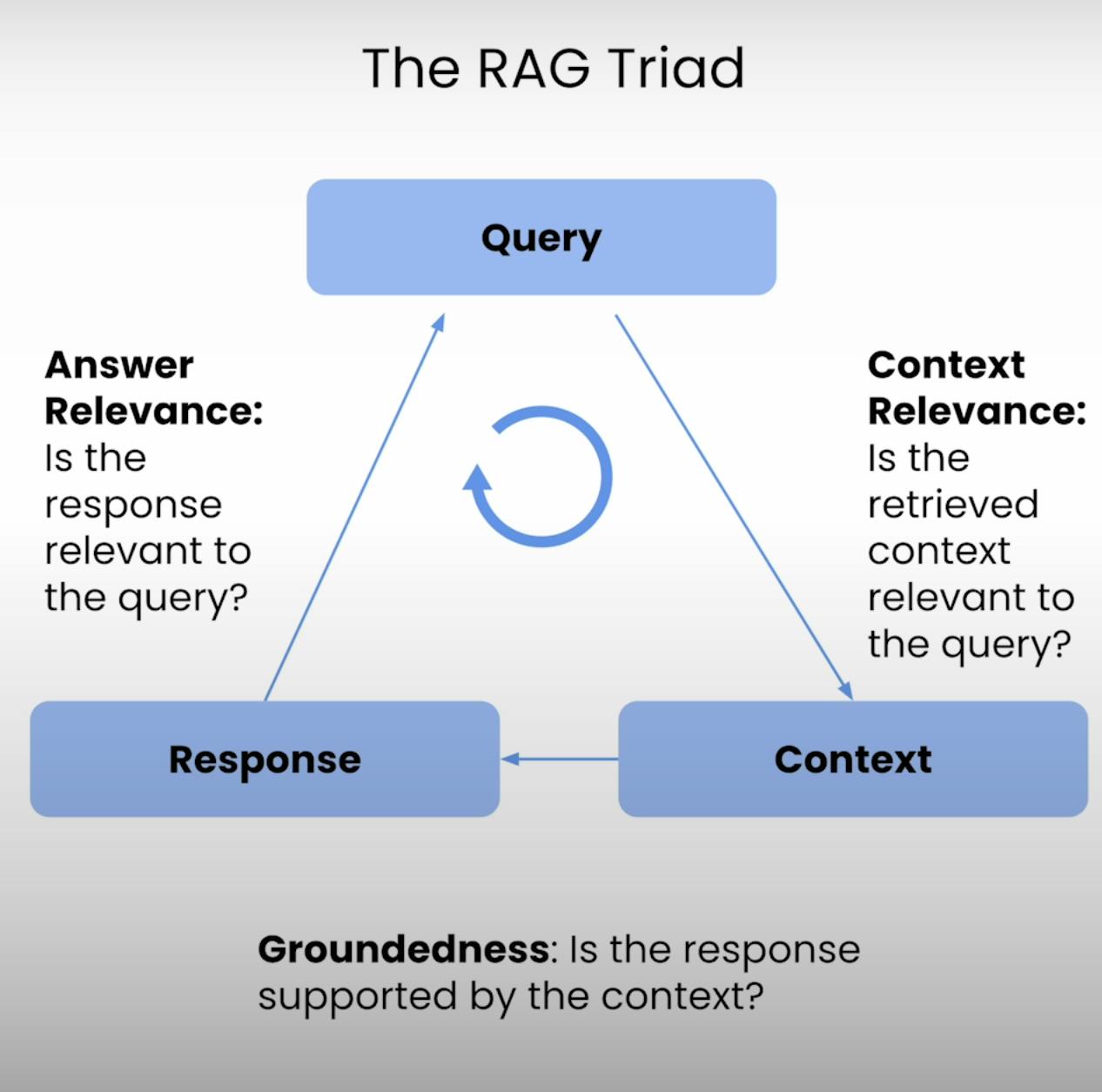
В основе каждой системы RAG лежит тонкий баланс между извлечением и генерацией. RAG Триада предоставляет комплексную структуру для оценки качества и потенциальных режимов сбоя этого тонкого баланса. Давайте разберем три компонента.
A. Context Relevance:
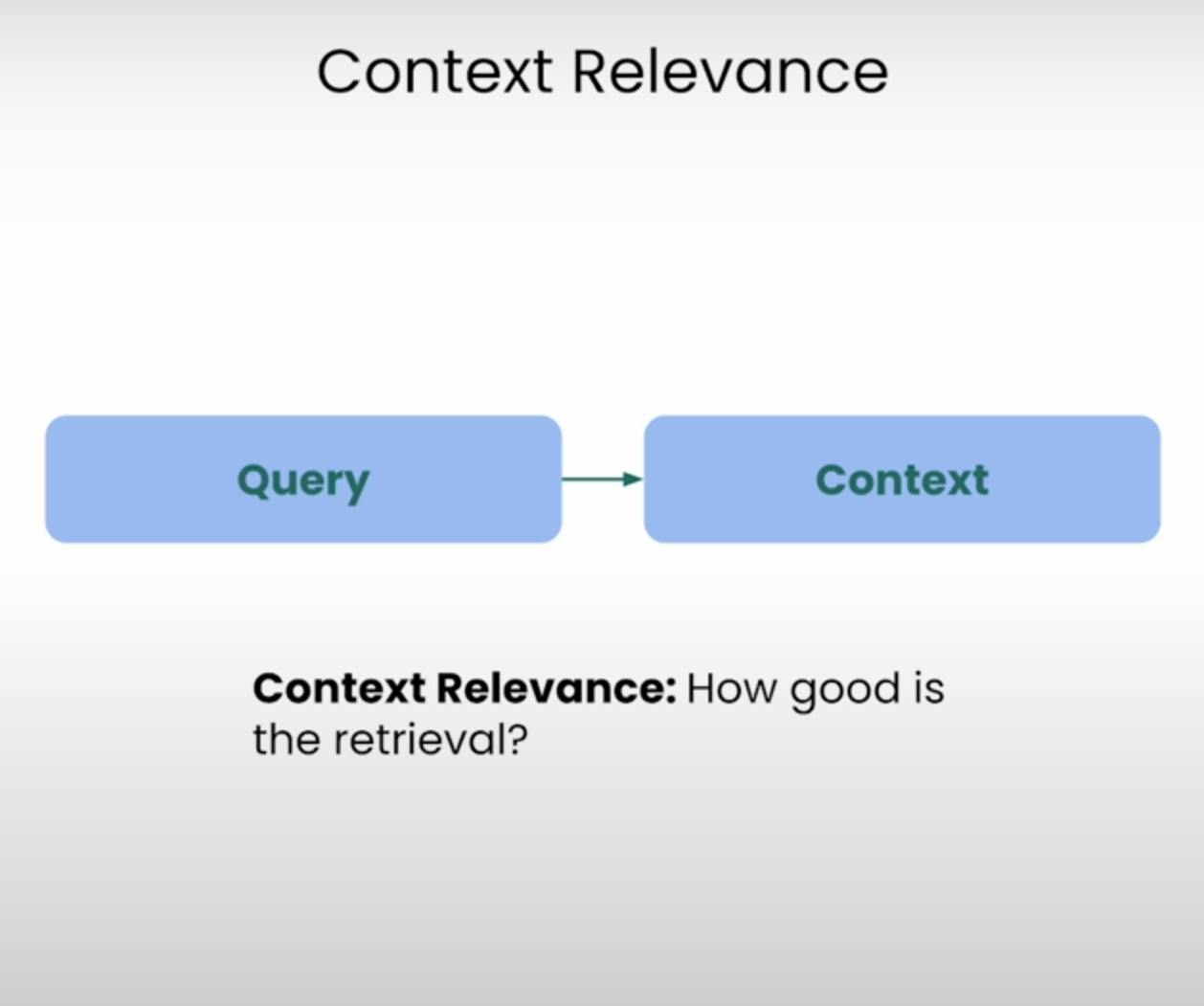
Представьте, что вам нужно ответить на вопрос, но информация, которую вы получили, полностью не связана с ним. Именно это система RAG стремится предотвратить. Контекстная Релевантность оценивает качество процесса извлечения, определяя, насколько релевантны каждый фрагмент извлеченного контекста исходному запросу. Оценивая релевантность извлеченного контекста, мы можем выявить потенциальные проблемы в механизме извлечения и внести необходимые корректировки.

B. Groundedness:
Вы когда-нибудь были в разговоре, где кто-то казался создающим факты или предоставляющим информацию без твердой основы? Это эквивалентно системе RAG, лишенной обоснованности. Обоснованность оценивает, насколько конечный ответ, сгенерированный системой, хорошо обоснован в извлеченном контексте. Если ответ содержит утверждения или заявления, которые не поддерживаются извлеченной информацией, система может быть подвержена галлюцинациям или чрезмерно полагаться на свою предварительно обученную информацию, что может привести к возможным неточностям или предвзятости.
C. Answer Relevance:
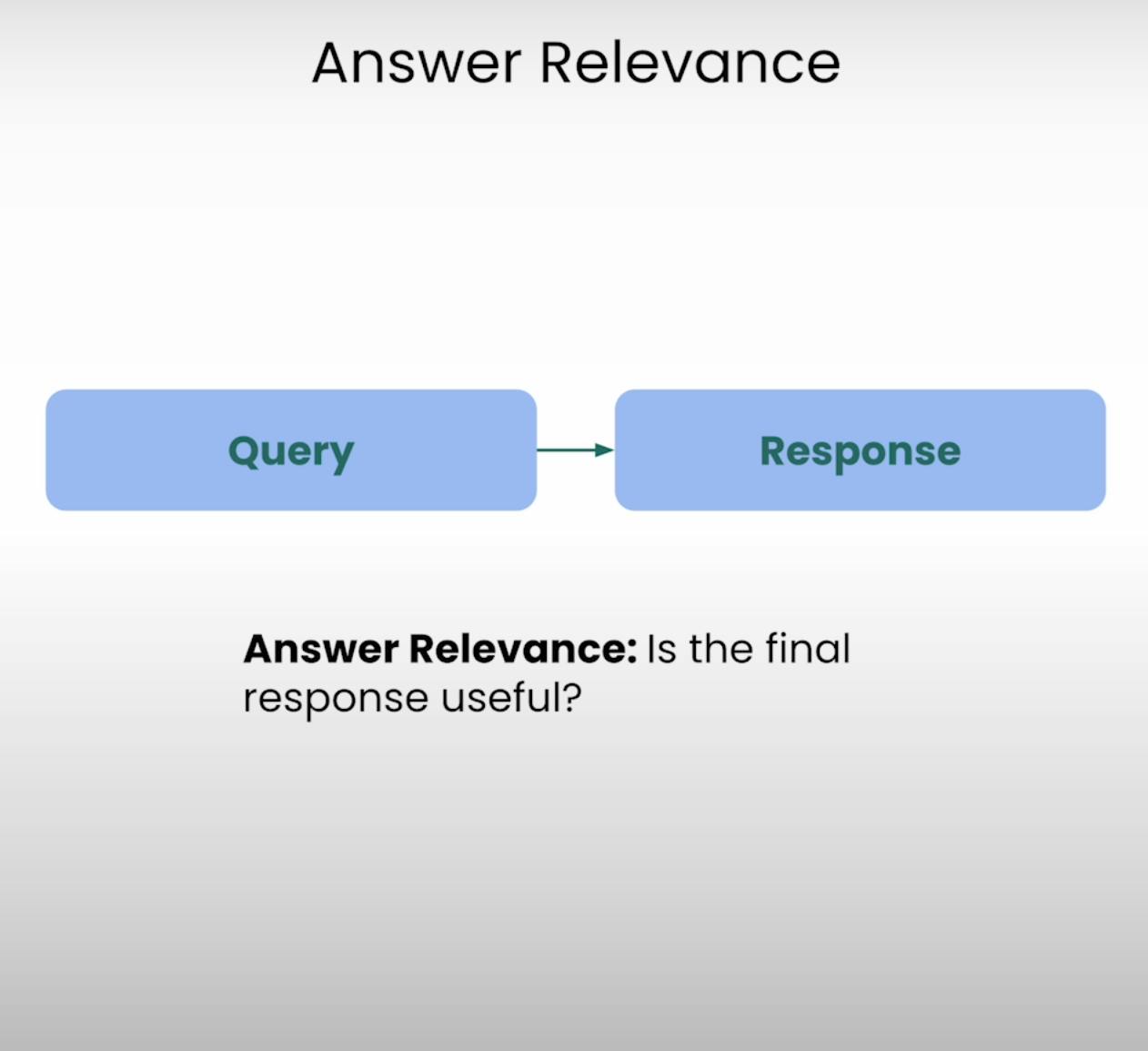
Представьте, что вы просите указать направление к ближайшей кофейне и получаете подробный рецепт выпечки торта. Такие ситуации система Answer Relevance стремится предотвратить. Эта составляющая триады RAG оценивает, насколько конечный ответ, сгенерированный системой, действительно релевантен исходному запросу. Оценивая релевантность ответа, мы можем выявить случаи, когда система могла неправильно понять вопрос или отклониться от предназначенной темы.

Настройка оценки триады RAG
Прежде чем мы сможем погрузиться в процесс оценки, нам нужно подготовить основу. Давайте пройдем через необходимые шаги для настройки оценки триады RAG.
A. Importing Libraries and Establishing API Keys:
Во-первых, нам нужно импортировать необходимые библиотеки и модули, включая API-ключ OpenAI и поставщика LLM.
import warnings
warnings.filterwarnings('ignore')
import utils
import os
import openai
openai.api_key = utils.get_openai_api_key()
from trulens_eval import Tru
B. Loading and Indexing the Document Corpus:
Далее мы загрузим и проиндексируем документный корпус, с которым будет работать наша система RAG. В нашем случае мы будем использовать PDF-документ на тему “Как построить карьеру в AI” от Andrew NG.
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
C. Defining the Feedback Functions:

В основе оценки RAG Триады лежат функции обратной связи – специализированные функции, оценивающие каждую компоненту триады. Давайте определим эти функции с помощью библиотеки TrueLens.


from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
# Answer Relevance
from trulens_eval import Feedback
f_qa_relevance = Feedback(
provider.relevance_with_cot_reasons,
name="Answer Relevance"
).on_input_output()
# Context Relevance
import numpy as np
f_qs_relevance = (
Feedback(provider.qs_relevance_with_cot_reasons,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)
# Groundedness
from trulens_eval.feedback import Groundedness
grounded = Groundedness(groundedness_provider=provider)
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(context_selection)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
Выполнение приложения и оценки RAG
С настройкой завершенной, пришло время запустить нашу систему RAG и структуру оценки в действии. Давайте пройдемся по шагам, связанным с выполнением приложения и регистрацией результатов оценки.
A. Preparing the Evaluation Questions:
Во-первых, мы загрузим набор вопросов для оценки, на которые наша система RAG должна ответить. Эти вопросы послужат основой для нашего процесса оценки.
eval_questions = []
with open('eval_questions.txt', 'r') as file:
for line in file:
item = line.strip()
eval_questions.append(item)
B. Running the RAG Application and Recording Results:
Далее, мы настроим записыватель TruLens, который поможет нам записывать подсказки, ответы и результаты оценки в локальной базе данных.
from trulens_eval import TruLlama
tru_recorder = TruLlama(
sentence_window_engine,
app_id="App_1",
feedbacks=[
f_qa_relevance,
f_qs_relevance,
f_groundedness
]
)
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
По мере работы приложения RAG над каждым вопросом для оценки, записыватель TruLens тщательно захватывает подсказки, ответы, промежуточные результаты и оценки, храня их в локальной базе данных для дальнейшего анализа.
Анализ результатов оценки
Имея данные оценки под рукой, пришло время заняться анализом и получить понимание. Давайте рассмотрим различные способы анализа результатов и выявления потенциальных областей для улучшения.
A. Examining Individual Record-Level Results:
Иногда все дело в деталях. Анализируя результаты на уровне отдельных записей, мы можем глубже понять сильные и слабые стороны нашей системы RAG.
records, feedback = tru.get_records_and_feedback(app_ids=[])
records.head()
Этот фрагмент кода предоставляет нам доступ к подсказкам, ответам и оценкам для каждой отдельной записи, что позволяет нам выявить конкретные случаи, где система могла столкнуться с трудностями или преуспеть.
B. Viewing Aggregate Performance Metrics:
Давайте сделаем шаг назад и посмотрим на более крупномасштабную картину. Библиотека TrueLens предоставляет нам таблицу лидеров, которая объединяет показатели производительности по всем записям, давая высокоуровневый обзор общей производительности нашей системы RAG.
tru.get_leaderboard(app_ids=[])
В этой таблице лидеров отображаются средние баллы для каждого компонента RAG Триады, а также такие метрики, как задержка и стоимость. Анализируя эти агрегированные метрики, мы можем выявить тенденции и закономерности, которые могут быть не видны на уровне отдельных записей.
C. Exploring the TrueLens Streamlit Dashboard:
Помимо CLI, TrueLens также предлагает панель управления Streamlit, которая предоставляет GUI для изучения и анализа результатов оценки. Несколькими простыми командами мы можем запустить панель.
tru.run_dashboard()
Как только панель запущена, мы видим всеобъемлющий обзор производительности системы RAG. С первого взгляда мы видим агрегированные метрики для каждого компонента RAG Триады, а также информацию о задержке и стоимости.
Выбрав наше приложение из выпадающего меню, мы можем получить детальное представление на уровне записей результатов оценки. Каждая запись аккуратно отображается, включая ввод пользовательского запроса, ответ системы RAG и соответствующие баллы по критериям Соответствия Ответу, Соответствия Контексту и Основанности.
Нажав на отдельную запись, мы получаем больше информации. Мы можем исследовать цепочку рассуждений, стоящую за каждым баллом оценки, объясняя мыслительный процесс языковой модели, выполняющей оценку. Такой уровень прозрачности полезен для выявления потенциальных сбоев и областей для улучшения.
Предположим, мы наткнулись на запись, где показатель Засыпанности низкий. Оглядываясь на детали, мы можем обнаружить, что ответ системы RAG содержит утверждения, которые недостаточно обоснованы в извлеченном контексте. Панель мониторинга покажет нам именно те утверждения, которые не имеют достаточных доказательств, что позволит нам точно определить причину проблемы.
Панель TrueLens Streamlit – это не просто инструмент визуализации. Используя его интерактивные возможности и данные-инсайты, мы можем принимать обоснованные решения и предпринимать целенаправленные действия для улучшения работы наших приложений.
Продвинутые техники RAG и итерационное улучшение
A. Introducing the Sentence Window RAG Technique:
Одна из продвинутых техник – Sentence Window RAG, которая решает распространенный провал систем RAG: ограниченный размер контекста. Увеличивая размер окна контекста, Sentence Window RAG стремится предоставить языковой модели больше релевантной и всеобъемлющей информации, что потенциально может улучшить показатели релевантности контекста и засыпанности системы.
B. Re-evaluating with the RAG Triad:
После внедрения техники Sentence Window RAG мы можем протестировать ее, повторно оценив с использованием того же фреймворка RAG Triad. На этот раз мы сосредоточим свое внимание на оценках релевантности контекста и засыпанности, ищем улучшения в этих областях благодаря увеличенному размеру контекста.
# Set up the Sentence Window RAG
sentence_index = build_sentence_window_index(
document,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="sentence_index"
)
sentence_window_engine = get_sentence_window_query_engine(sentence_index)
# Re-evaluate with the RAG Triad
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
C. Experimenting with Different Window Sizes:
Хотя техника Sentence Window RAG потенциально может улучшить производительность, оптимальный размер окна может варьироваться в зависимости от конкретного случая использования и набора данных. Слишком маленькое окно может не обеспечить достаточный релевантный контекст, в то время как слишком большое окно может ввести нерелевантную информацию, влияя на засыпанность системы и релевантность ответа.
Экспериментируя с различными размерами окон и переоценивая с использованием RAG Triad, мы можем найти идеальный баланс между релевантностью контекста, укорененностью и релевантностью ответа, что в конечном итоге приведет к более надежной и надежной системе RAG.
Заключение:
RAG Triad, состоящий из Контекстной Релевантности, Укорененности и Релевантности Ответа, доказал свою эффективность в качестве полезной структуры для оценки производительности и выявления потенциальных режимов отказа систем Генерации, Укрепленных Извлечением.
Source:
https://rutam.hashnode.dev/the-rag-triad-guide-to-evaluating-and-optimizing-rag-systems