













RAG系統融合了檢索機制與語言模型的力量,使其能夠產生情境相關且基於事實的回應。然而,評估RAG系統的效能並識別其潛在的失效模式卻是極具挑戰性。
因此,RAG三元組應運而生——一套包含三個主要步驟的指標:情境相關性、事實基礎性與答案相關性。在本文中,我將深入探討RAG三元組的細節,並引導您完成設置、執行及分析RAG系統評估的過程。
RAG三元組簡介:
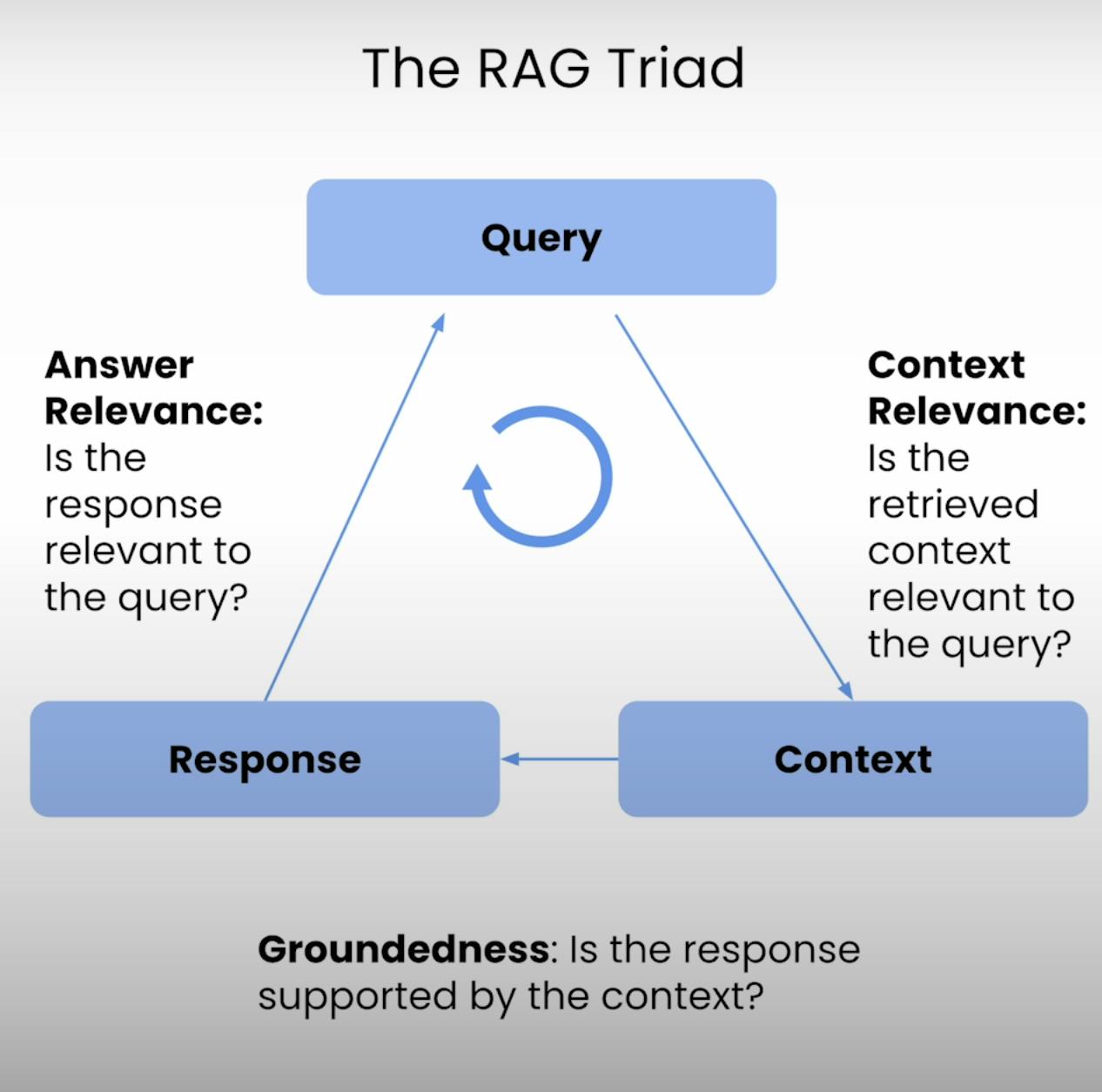
每個RAG系統的核心都在於檢索與生成之間的微妙平衡。RAG三元組提供了一個全面的框架,用以評估這種平衡的品質及其潛在的失效模式。讓我們逐一解析這三個組成部分。
A. Context Relevance:
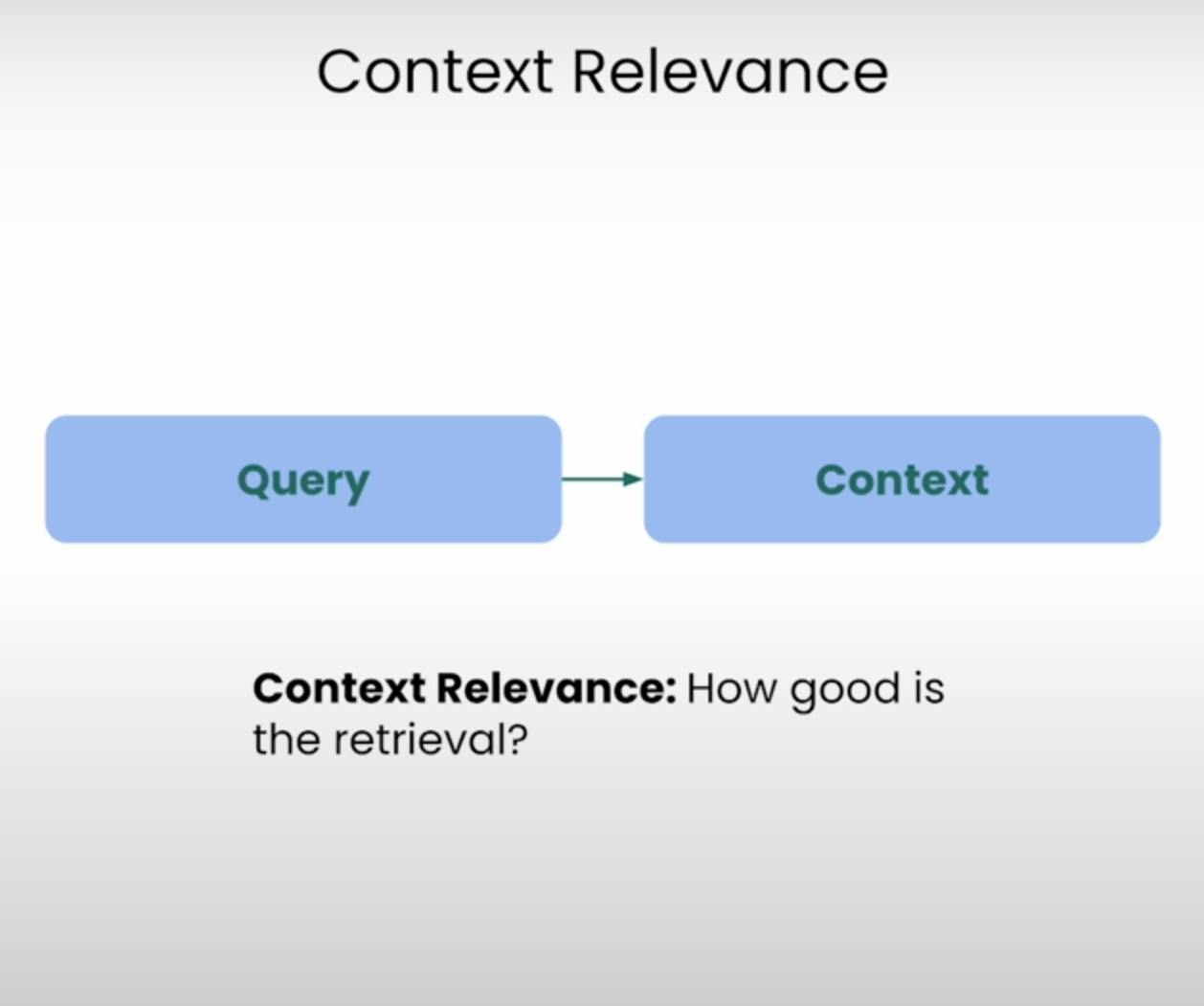
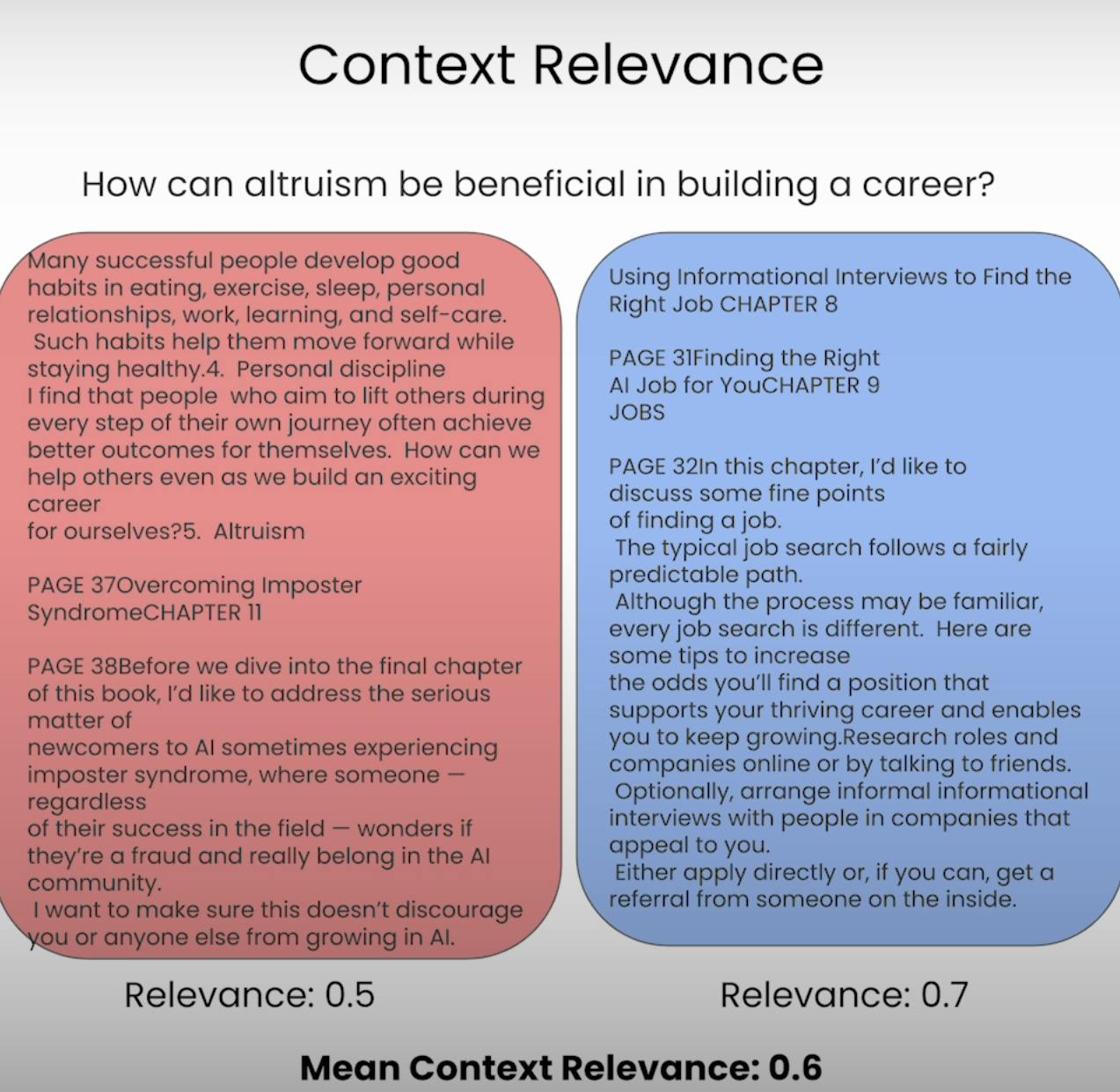
想像一下,如果被要求回答一個問題,但所提供的信息完全不相關,這正是RAG系統致力於避免的情況。情境相關性評估了檢索過程的品質,通過評價每個檢索到的情境片段與原始查詢的相關程度。透過對檢索到的情境相關性進行打分,我們能夠識別檢索機制中的潛在問題,並進行必要的調整。

B. Groundedness:
你是否曾經經歷過這樣的對話,對方似乎在捏造事實或提供毫無根據的資訊?這就像是一個缺乏紮實基礎的RAG系統。紮實基礎(Groundedness)評估系統最終生成的回應是否基於檢索到的上下文有充分的依據。如果回應中包含的陳述或主張並未得到檢索資訊的支持,系統可能正在產生幻覺或過度依賴其預訓練數據,這可能導致不準確或偏見的結果。
C. Answer Relevance:
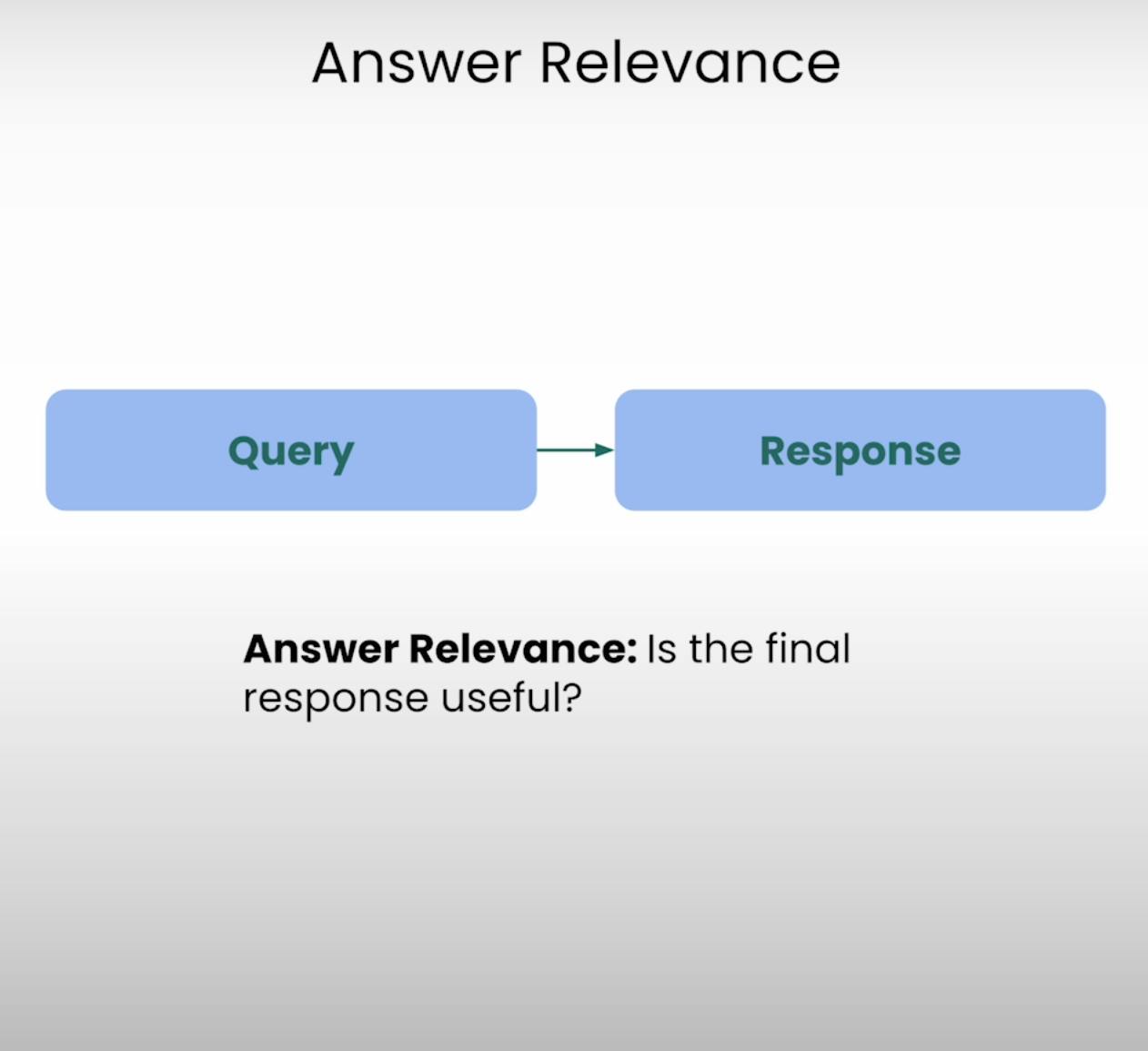
想像一下,如果你詢問最近的咖啡店怎麼走,卻收到一份詳細的蛋糕烘焙食譜,這就是Answer Relevance旨在防止的情況。RAG三元組的這一部分評估系統生成的最終回應是否真正與原始查詢相關。通過評估答案的相關性,我們可以識別系統可能誤解問題或偏離主題的情況。

建立RAG三元組評估
在深入評估過程之前,我們需要奠定基礎。讓我們逐步了解設置RAG三元組評估的必要步驟。
A. Importing Libraries and Establishing API Keys:
首先,我們需要導入必要的庫和模塊,包括OpenAI的API密鑰和LLM提供商。
import warnings
warnings.filterwarnings('ignore')
import utils
import os
import openai
openai.api_key = utils.get_openai_api_key()
from trulens_eval import Tru
B. Loading and Indexing the Document Corpus:
接下來,我們將加載並索引RAG系統將使用的文檔語料庫。在我們的案例中,將使用Andrew NG的”如何在AI領域建立職業生涯”的PDF文檔。
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
C. Defining the Feedback Functions:

在RAG三元組評估的核心是反饋函數——專門用於評估三元組各個組件的函數。讓我們使用TrueLens庫來定義這些函數。


from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
# Answer Relevance
from trulens_eval import Feedback
f_qa_relevance = Feedback(
provider.relevance_with_cot_reasons,
name="Answer Relevance"
).on_input_output()
# Context Relevance
import numpy as np
f_qs_relevance = (
Feedback(provider.qs_relevance_with_cot_reasons,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)
# Groundedness
from trulens_eval.feedback import Groundedness
grounded = Groundedness(groundedness_provider=provider)
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(context_selection)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
執行RAG應用程序與評估
設置完成後,是時候將我們的RAG系統及評估框架付諸實踐了。讓我們逐步了解執行應用程序並記錄評估結果的步驟。
A. Preparing the Evaluation Questions:
首先,我們將加載一組評估問題,這些問題將作為我們評估過程的基礎。
eval_questions = []
with open('eval_questions.txt', 'r') as file:
for line in file:
item = line.strip()
eval_questions.append(item)
B. Running the RAG Application and Recording Results:
接下來,我們將設置TruLens記錄器,它將幫助我們在本地數據庫中記錄提示、響應和評估結果。
from trulens_eval import TruLlama
tru_recorder = TruLlama(
sentence_window_engine,
app_id="App_1",
feedbacks=[
f_qa_relevance,
f_qs_relevance,
f_groundedness
]
)
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
當RAG應用程序針對每個評估問題運行時,TruLens記錄器將勤奮地捕捉提示、響應、中間結果和評估分數,並將它們存儲在本地數據庫中以供進一步分析。
分析評估結果
有了評估數據在手,是時候進行分析並獲取洞察了。讓我們看看可以採用多種方式來分析結果並識別潛在的改進領域。
A. Examining Individual Record-Level Results:
有時候,魔鬼就在細節中。通過檢查個別記錄級別的結果,我們可以更深入地了解我們RAG系統的強項和弱點。
records, feedback = tru.get_records_and_feedback(app_ids=[])
records.head()
這段代碼片段使我們能夠訪問每個個別記錄的提示、響應和評估分數,這使我們能夠識別系統可能在哪些特定情況下遇到困難或表現出色。
B. Viewing Aggregate Performance Metrics:
讓我們退一步,從更廣闊的視角來看。TrueLens 圖書館提供了一個排行榜,匯總了所有記錄的性能指標,為我們的RAG系統的整體表現提供了高層次的視圖。
tru.get_leaderboard(app_ids=[])
此排行榜展示了RAG三元組每個組件的平均分數,以及延遲和成本等指標。通過分析這些匯總指標,我們可以識別出在記錄級別可能不明顯的趨勢和模式。
C. Exploring the TrueLens Streamlit Dashboard:
除了命令行界面(CLI),TrueLens還提供了一個Streamlit儀表板,該儀表板提供了一個圖形用戶界面(GUI)來探索和分析評估結果。通過幾個簡單的命令,我們就可以啟動這個儀表板。
tru.run_dashboard()
一旦儀表板啟動並運行,我們就能看到我們RAG系統性能的全面概覽。一眼望去,我們可以看到RAG三元組每個組件的匯總指標,以及延遲和成本信息。
通過從下拉菜單中選擇我們的應用程序,我們可以訪問評估結果的詳細記錄級視圖。每條記錄都整齊地展示,包括用戶的輸入提示、RAG系統的回應以及答案相關性、上下文相關性和基於事實性的相應分數。
點擊單個記錄可以揭示更多見解。我們可以探索每個評估分數背後的思考過程,解釋執行評估的語言模型的思考過程。這種透明度對於識別潛在的失敗模式和改進領域非常有用。
假設我們遇到一個記錄,其Groundedness分數偏低。通過查看詳細信息,我們可能會發現RAG系統的回應包含了一些未能充分基於檢索到上下文的陳述。儀表板將明確展示哪些陳述缺乏支持證據,使我們能夠精確定位問題的根本原因。
TrueLens Streamlit儀表板不僅僅是一個視覺化工具。通過利用其互動功能和數據驅動的洞察,我們可以做出明智的決策並採取針對性的行動,以提升我們應用程式的性能。
先進的RAG技術與迭代改進
A. Introducing the Sentence Window RAG Technique:
一種先進技術是Sentence Window RAG,它解決了RAG系統常見的一種失效模式:上下文尺寸有限。通過增大上下文窗口大小,Sentence Window RAG旨在為語言模型提供更多相關和全面的資訊,可能會提高系統的上下文相關性和Groundedness。
B. Re-evaluating with the RAG Triad:
在實施了Sentence Window RAG技術後,我們可以通過重新使用RAG Triad框架進行評估來測試它。這次,我們將重點關注上下文相關性和Groundedness分數,尋找由於增大上下文大小而帶來的改進。
# Set up the Sentence Window RAG
sentence_index = build_sentence_window_index(
document,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="sentence_index"
)
sentence_window_engine = get_sentence_window_query_engine(sentence_index)
# Re-evaluate with the RAG Triad
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
C. Experimenting with Different Window Sizes:
雖然Sentence Window RAG技術可能會提升性能,但最佳窗口大小可能會根據具體用例和數據集而變化。窗口太小可能無法提供足夠的相關上下文,而窗口太大可能會引入不相關的信息,影響系統的Groundedness和答案相關性。
透過嘗試不同視窗大小並重新評估使用RAG三元組,我們能找到平衡上下文相關性、基礎性和答案相關性的最佳點,最終導向一個更強健可靠的RAG系統。
結論:
RAG三元組,包含上下文相關性、基礎性及答案相關性,已被證實為評估檢索增強生成系統性能及識別潛在失效模式的實用框架。
Source:
https://rutam.hashnode.dev/the-rag-triad-guide-to-evaluating-and-optimizing-rag-systems