













RAG-Systeme kombinieren die Kraft von Abrufmechanismen und Sprachmodellen und ermöglichen es ihnen, kontextbezogene und gut begründete Antworten zu generieren. Die Bewertung der Leistung und die Identifizierung potenzieller Fehlermodi von RAG-Systemen kann jedoch sehr schwierig sein.
Deshalb gibt es das RAG-Triade – ein Triade von Metriken, die die drei Hauptstufen der Ausführung eines RAG-Systems abdecken: Kontextrelevanz, Begründetheit und Antwortrelevanz. In diesem Blogbeitrag werde ich die Feinheiten der RAG-Triade durchgehen und Sie durch den Prozess des Aufsetzens, Durchführens und Analysierens der Bewertung eines RAG-Systems führen.
Einführung in die RAG-Triade:
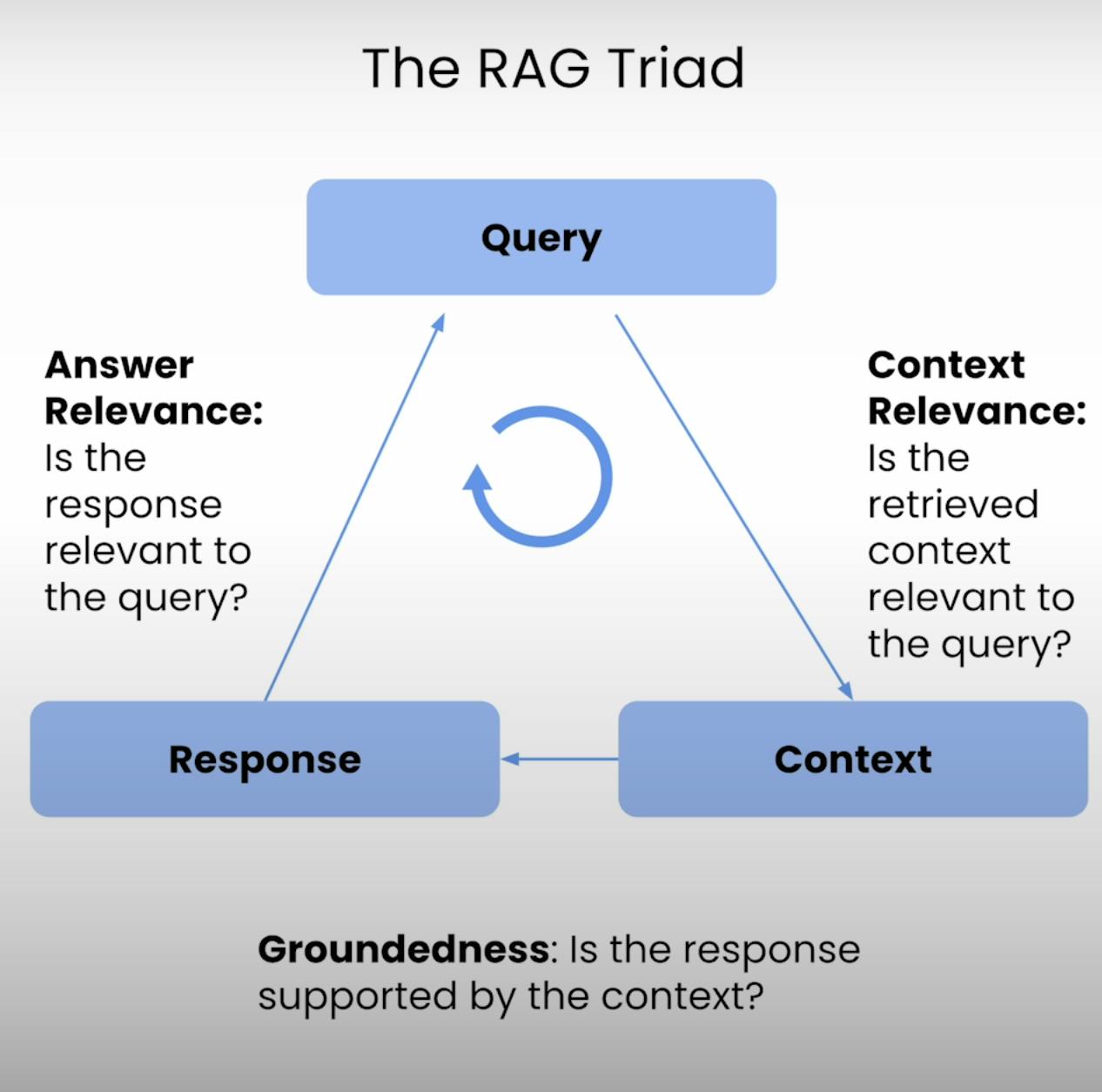
Im Kern jedes RAG-Systems liegt ein feines Gleichgewicht zwischen Abruf und Generierung. Die RAG-Triade bietet einen umfassenden Rahmen, um die Qualität und potenzielle Fehlermodi dieses feinen Gleichgewichts zu bewerten. Lassen Sie uns die drei Komponenten aufteilen.
A. Context Relevance:
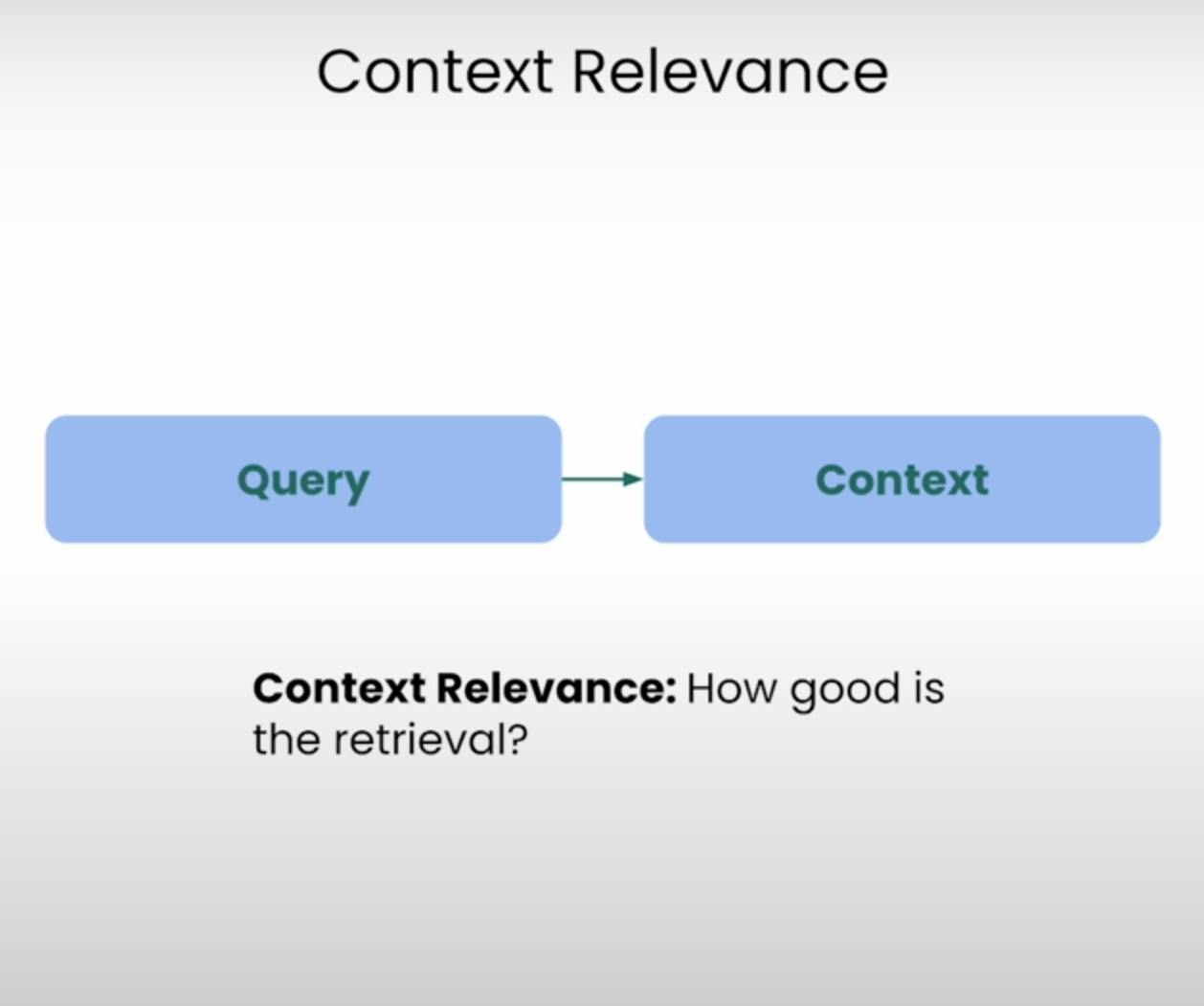
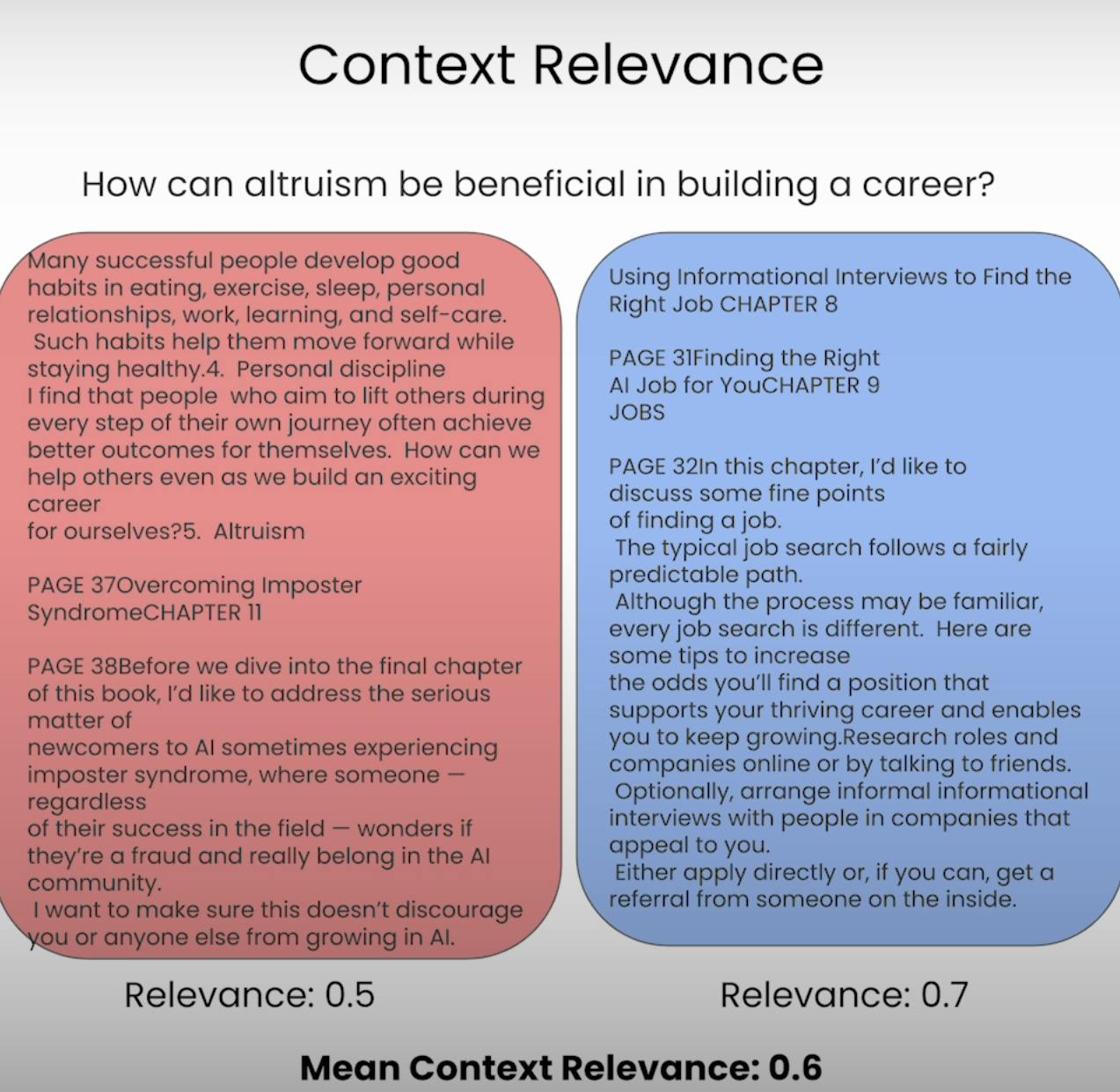
Stellen Sie sich vor, Sie sollen eine Frage beantworten, aber die ihnen zur Verfügung gestellten Informationen sind völlig unzutreffend. Genau das ist das Ziel eines RAG-Systems. Die Kontextrelevanz bewertet die Qualität des Abrufprozesses, indem sie die Relevanz jedes abgerufenen Kontextes im Hinblick auf die ursprüngliche Abfrage überprüft. Durch die Bewertung der Relevanz des abgerufenen Kontexts können wir potenzielle Probleme im Abrufmechanismus identifizieren und die notwendigen Anpassungen vornehmen.

B. Groundedness:
Hast du jemals eine Unterhaltung gehabt, in der jemand scheinbar Fakten erfand oder Informationen ohne solide Grundlage lieferte? Das ist das Äquivalent eines RAG-Systems, das an Bodenhaftung fehlt. Bodenhaftung bewertet, ob die vom System generierte finale Antwort gut im abgerufenen Kontext verankert ist. Wenn die Antwort Aussagen oder Behauptungen enthält, die nicht durch die abgerufenen Informationen gestützt werden, kann das System halluzinieren oder zu stark auf seine vorab trainierten Daten angewiesen sein, was zu möglichen Ungenauigkeiten oder Verzerrungen führen kann.
C. Answer Relevance:
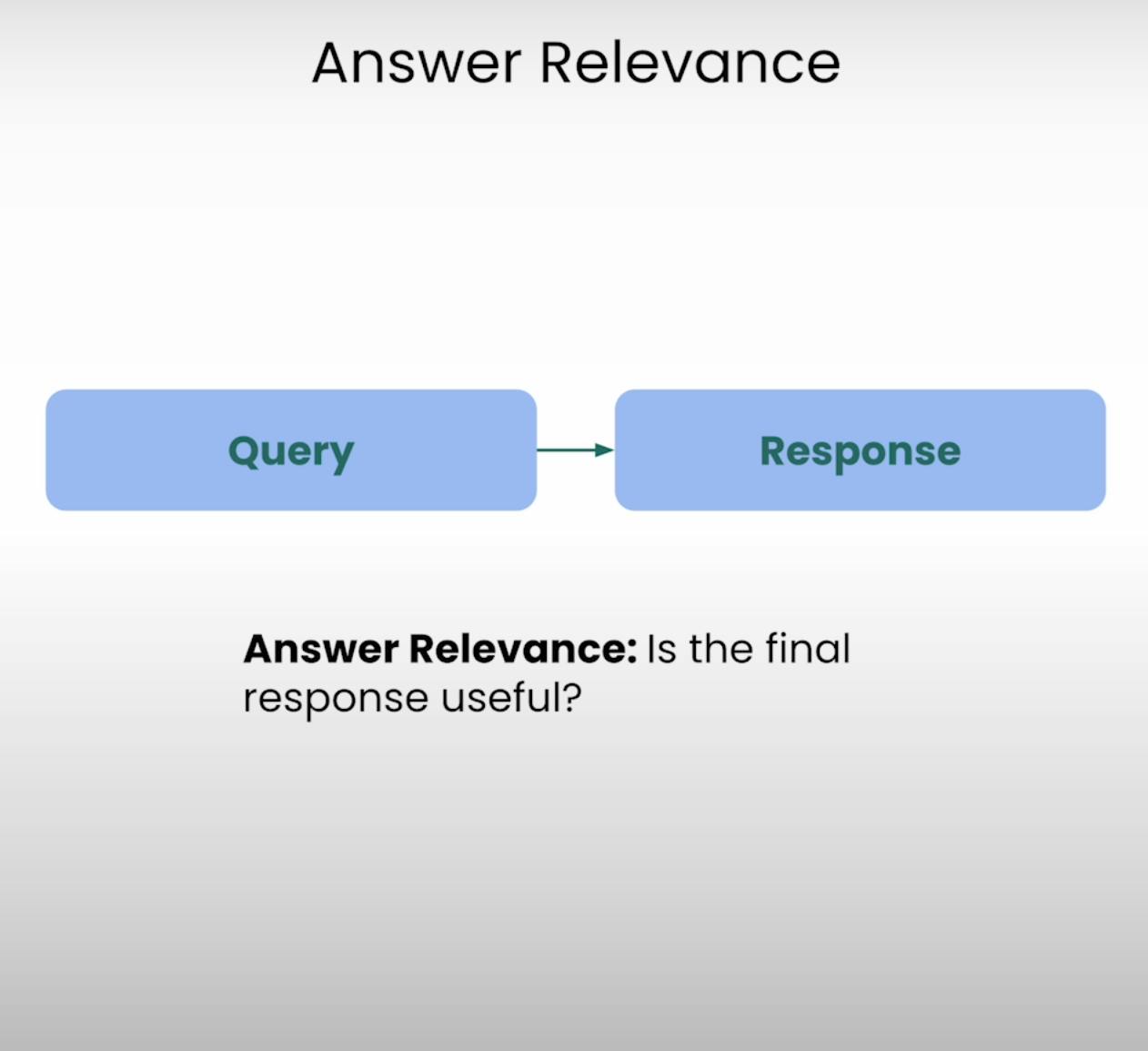
Stell dir vor, du fragst nach den Wegbeschreibungen zum nächsten Kaffeehaus und erhältst stattdessen ein detailliertes Rezept zum Backen eines Kuchens. Das ist die Art von Situation, die die Antwortrelevanz verhindern möchte. Dieser Bestandteil des RAG-Triaden-Evaluierung bewertet, ob die vom System generierte finale Antwort wirklich relevant für die ursprüngliche Anfrage ist. Durch die Bewertung der Relevanz der Antwort können wir Fälle identifizieren, in denen das System die Frage möglicherweise missverstanden oder vom eigentlichen Thema abgewichen ist.

Einrichten der RAG-Triaden-Evaluierung
Bevor wir uns mit dem Evaluierungsprozess befassen können, müssen wir die Grundlagen legen. Gehen wir die notwendigen Schritte zur Einrichtung der RAG-Triaden-Evaluierung durch.
A. Importing Libraries and Establishing API Keys:
Zuerst müssen wir die erforderlichen Bibliotheken und Module importieren, einschließlich des OpenAI-API-Schlüssels und des LLM-Anbieters.
import warnings
warnings.filterwarnings('ignore')
import utils
import os
import openai
openai.api_key = utils.get_openai_api_key()
from trulens_eval import Tru
B. Loading and Indexing the Document Corpus:
Als nächstes werden wir das Dokumentenkorpus laden und indizieren, mit dem unser RAG-System arbeiten wird. In unserem Fall verwenden wir ein PDF-Dokument mit dem Titel „Wie man eine Karriere in AI aufbaut“ von Andrew NG.
from llama_index import SimpleDirectoryReader
documents = SimpleDirectoryReader(
input_files=["./eBook-How-to-Build-a-Career-in-AI.pdf"]
).load_data()
C. Defining the Feedback Functions:

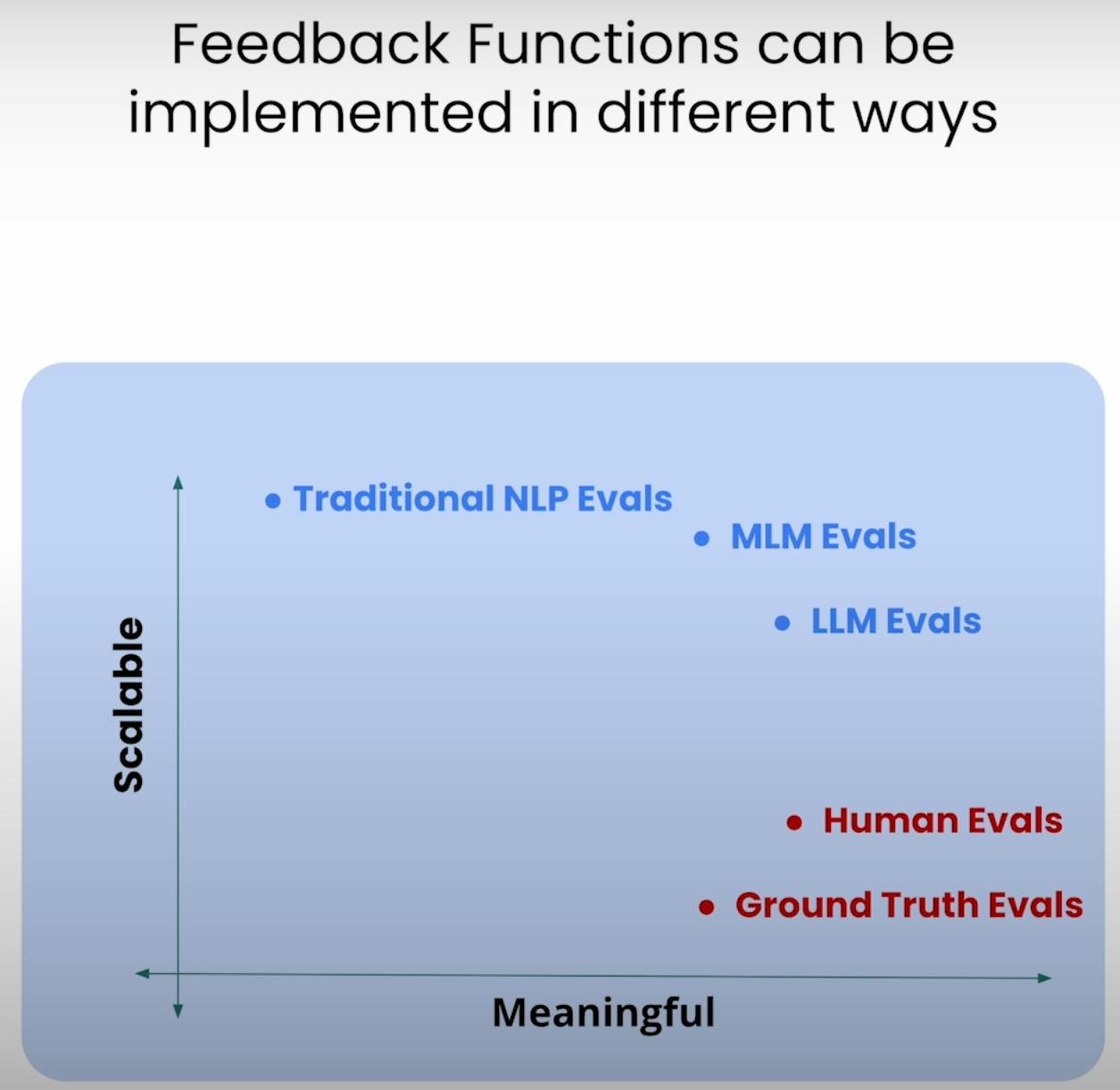
Im Kern der RAG-Triade-Bewertung stehen die Feedbackfunktionen – spezialisierte Funktionen, die jedes Element der Triade bewerten. Lassen Sie uns diese Funktionen mit der TrueLens-Bibliothek definieren.


from llama_index.llms import OpenAI
llm = OpenAI(model="gpt-3.5-turbo", temperature=0.1)
# Answer Relevance
from trulens_eval import Feedback
f_qa_relevance = Feedback(
provider.relevance_with_cot_reasons,
name="Answer Relevance"
).on_input_output()
# Context Relevance
import numpy as np
f_qs_relevance = (
Feedback(provider.qs_relevance_with_cot_reasons,
name="Context Relevance")
.on_input()
.on(context_selection)
.aggregate(np.mean)
)
# Groundedness
from trulens_eval.feedback import Groundedness
grounded = Groundedness(groundedness_provider=provider)
f_groundedness = (
Feedback(grounded.groundedness_measure_with_cot_reasons,
name="Groundedness"
)
.on(context_selection)
.on_output()
.aggregate(grounded.grounded_statements_aggregator)
)
Ausführen der RAG-Anwendung und -Bewertung
Nachdem die Einrichtung abgeschlossen ist, ist es an der Zeit, unser RAG-System und das Bewertungsframework in Aktion zu sehen. Gehen wir die Schritte durch, die bei der Ausführung der Anwendung und der Aufzeichnung der Bewertungsergebnisse beteiligt sind.
A. Preparing the Evaluation Questions:
Zuerst laden wir eine Reihe von Bewertungsfragen, die wir von unserem RAG-System beantwortet haben möchten. Diese Fragen werden die Grundlage unseres Bewertungsprozesses bilden.
eval_questions = []
with open('eval_questions.txt', 'r') as file:
for line in file:
item = line.strip()
eval_questions.append(item)
B. Running the RAG Application and Recording Results:
Als nächstes richten wir den TruLens-Recorder ein, der uns dabei hilft, die Prompts, Antworten und Bewertungsergebnisse in einer lokalen Datenbank aufzuzeichnen.
from trulens_eval import TruLlama
tru_recorder = TruLlama(
sentence_window_engine,
app_id="App_1",
feedbacks=[
f_qa_relevance,
f_qs_relevance,
f_groundedness
]
)
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
Während die RAG-Anwendung auf jede Bewertungsfrage läuft, wird der TruLens-Recorder gewissenhaft die Prompts, Antworten, Zwischenergebnisse und Bewertungsscores erfassen und in einer lokalen Datenbank für weitere Analyse speichern.
Analysieren der Bewertungsergebnisse
Mit den Bewertungsdaten griffbereit ist es an der Zeit, sich mit der Analyse zu befassen und die Erkenntnisse zu gewinnen. Schauen wir uns verschiedene Möglichkeiten an, wie wir die Ergebnisse analysieren und potentielle Bereiche für Verbesserungen identifizieren können.
A. Examining Individual Record-Level Results:
Manchmal liegt der Teufel in den Details. Durch die Untersuchung einzelner Datensatz-Ergebnisse können wir ein profundes Verständnis der Stärken und Schwächen unseres RAG-Systems gewinnen.
records, feedback = tru.get_records_and_feedback(app_ids=[])
records.head()
Dieser Codeausschnitt gibt uns Zugriff auf die Prompts, Antworten und Bewertungsscores für jeden einzelnen Datensatz, was uns ermöglicht, spezifische Fälle zu identifizieren, in denen das System möglicherweise Schwierigkeiten hatte oder herausragte.
B. Viewing Aggregate Performance Metrics:
Schauen wir uns das große Ganze an. Die TrueLens-Bibliothek bietet uns eine Rangliste, die die Leistungsindikatoren über alle Aufzeichnungen hinweg aggregiert und uns einen Überblick über die Gesamtleistung unseres RAG-Systems gibt.
tru.get_leaderboard(app_ids=[])
Diese Rangliste zeigt die durchschnittlichen Punktzahlen für jeden Teil des RAG-Triaden, zusammen mit Metriken wie Latenz und Kosten. Durch die Analyse dieser aggregierten Metriken können wir Trends und Muster identifizieren, die auf der Aufzeichnungsebene möglicherweise nicht offensichtlich sind.
C. Exploring the TrueLens Streamlit Dashboard:
Neben der CLI bietet TrueLens auch eine Streamlit-Dashboards, die eine GUI zum Erkunden und Analysieren der Evaluierungsergebnisse bereitstellt. Mit wenigen einfachen Befehlen können wir das Dashboard starten.
tru.run_dashboard()
Sobald das Dashboard betriebsbereit ist, erhalten wir einen umfassenden Überblick über die Leistung unseres RAG-Systems. Im Blickfeld sind die aggregierten Metriken für jeden Teil des RAG-Triaden sowie Informationen zur Latenz und Kosten.
Durch Auswahl unserer Anwendung aus dem Dropdown-Menü können wir einen detaillierten Aufzeichnungsansicht der Evaluierungsergebnisse zugänglich machen. Jede Aufzeichnung wird ordentlich angezeigt, komplett mit dem Benutzer-Eingabeprompt, der RAG-Systemantwort und den entsprechenden Punktzahlen für Antwortrelevanz, Kontextrelevanz und Fundiertheit.
Durch Klicken auf eine einzelne Aufzeichnung erhalten wir weitere Einblicke. Wir können die Gedankengang der Begründung hinter jeder Evaluierungspunktzahl erkunden, die den Denkprozess des Sprachmodells bei der Evaluierung erklärt. Diese Transparenz ist hilfreich, um mögliche Versagensmodi und Verbesserungsbereiche zu identifizieren.
Angenommen, wir stoßen auf eine Aufzeichnung, bei der der Groundedness-Score niedrig ist. Durch die Betrachtung der Details können wir feststellen, dass die Antwort des RAG-Systems Aussagen enthält, die nicht gut im abgerufenen Kontext verankert sind. Der Dashboard zeigt uns genau, welche Aussagen keine unterstützenden Beweise haben, was uns ermöglicht, die Ursache des Problems genau zu lokalisieren.
Das TrueLens Streamlit Dashboard ist mehr als nur ein Visualisierungswerkzeug. Durch die Nutzung seiner interaktiven Fähigkeiten und datengetriebenen Einsichten können wir fundierte Entscheidungen treffen und gezielte Maßnahmen ergreifen, um die Leistungsfähigkeit unserer Anwendungen zu verbessern.
Fortgeschrittene RAG-Techniken und iterative Verbesserung
A. Introducing the Sentence Window RAG Technique:
Eine fortgeschrittene Technik ist das Sentence Window RAG, welches ein häufiges Versagen von RAG-Systemen anspricht: begrenzte Kontextgröße. Durch die Erhöhung der Kontextfenstergröße zielt das Sentence Window RAG darauf ab, dem Sprachmodell relevantere und umfassendere Informationen zur Verfügung zu stellen, was möglicherweise die Kontextrelevanz und Groundedness des Systems verbessert.
B. Re-evaluating with the RAG Triad:
Nach der Implementierung der Sentence Window RAG-Technik können wir diese durch erneute Bewertung mit dem gleichen RAG-Triad-Rahmen testen. Diesmal konzentrieren wir unsere Aufmerksamkeit auf die Kontextrelevanz- und Groundedness-Scores und suchen nach Verbesserungen in diesen Bereichen als Folge der erhöhten Kontextgröße.
# Set up the Sentence Window RAG
sentence_index = build_sentence_window_index(
document,
llm,
embed_model="local:BAAI/bge-small-en-v1.5",
save_dir="sentence_index"
)
sentence_window_engine = get_sentence_window_query_engine(sentence_index)
# Re-evaluate with the RAG Triad
for question in eval_questions:
with tru_recorder as recording:
sentence_window_engine.query(question)
C. Experimenting with Different Window Sizes:
Während die Sentence Window RAG-Technik die Leistung möglicherweise verbessern kann, kann die optimale Fenstergröße je nach spezifischem Anwendungsfall und Datensatz variieren. Ein zu kleines Fenster kann nicht genügend relevanten Kontext liefern, während ein zu großes Fenster irrelevante Informationen einführen könnte, was die Groundedness und Antwortrelevanz des Systems beeinträchtigen könnte.
Durch das Experimentieren mit unterschiedlichen Fenstergrößen und die Neubewertung mithilfe des RAG-Triadenmodells können wir den optimalen Punkt finden, der die Kontextrelevanz mit Bodenheit und Antwortrelevanz ausgleicht und letztendlich zu einem robuster und zuverlässiger RAG-System führt.
Schlussfolgerung:
Die RAG-Triade, bestehend aus Kontextrelevanz, Bodenheit und Antwortrelevanz, hat sich als nützliches Rahmenwerk zur Bewertung der Leistung und Identifizierung möglicher Versagensmodi von Retrieval-Augmented Generation-Systemen erwiesen.
Source:
https://rutam.hashnode.dev/the-rag-triad-guide-to-evaluating-and-optimizing-rag-systems