













Любой специалист, работающий в области DevOps сегодня, скорее всего согласится с тем, что кодирование ресурсов упрощает наблюдение, управление и автоматизацию. Однако большинство инженеров также признают, что эта трансформация сопровождается новым набором вызовов.
Возможно, самой большой проблемой операций IaC являются дрейфы — ситуация, когда рабочие среды отклоняются от определенных в IaC состояний, создавая зловонную проблему, которая может иметь серьезные долгосрочные последствия. Эти расхождения подрывают согласованность облачных сред, ведут к потенциальным проблемам с надежностью и поддерживаемостью инфраструктуры, а также к серьезным рискам в области безопасности и соответствия.
В попытке минимизировать эти риски те, кто отвечает за управление этими средами, классифицируют дрейф как задачу высокого приоритета (и крупное потребление времени) для команд по инфраструктурным операциям.
Это привело к растущей популярности инструментов обнаружения дрейфа, которые выявляют расхождения между желаемой конфигурацией и фактическим состоянием инфраструктуры. Несмотря на эффективность в обнаружении дрейфа, эти решения ограничиваются выдачей предупреждений и выделением различий в коде, не предлагая более глубоких исследований причин.
Почему обнаружение дрейфа оказывается недостаточным
Текущее состояние обнаружения дрейфа связано с тем, что дрейф происходит вне установленного CI/CD pipeline и часто прослеживается до ручных настроек, обновлений, инициируемых API, или экстренных исправлений. В результате эти изменения обычно не оставляют следов аудита в слое IaC, создавая темную зону, которая ограничивает инструменты только выявлением несоответствий в коде. Это оставляет инженерные команды платформы в состоянии предполагать о происхождении дрейфа и о том, как его лучше всего решить.
Отсутствие ясности делает разрешение дрейфа рискованной задачей. В конце концов, автоматическое откатывание изменений без понимания их цели — распространенный подход по умолчанию — может привести к серьезным последствиям и вызвать каскад проблем.
Один из рисков заключается в том, что это может отменить законные настройки или оптимизации, потенциально повторно вводя проблемы, которые уже были решены, или нарушая работу ценного стороннего инструмента.
Возьмем, к примеру, ручное исправление, примененное вне обычного процесса IaC для устранения внезапной проблемы в производстве. Перед откатом таких изменений важно зафиксировать их, чтобы сохранить их намерение и влияние, иначе существует риск назначить лечение, которое может оказаться хуже самой болезни.
Обнаружение встречается с контекстом
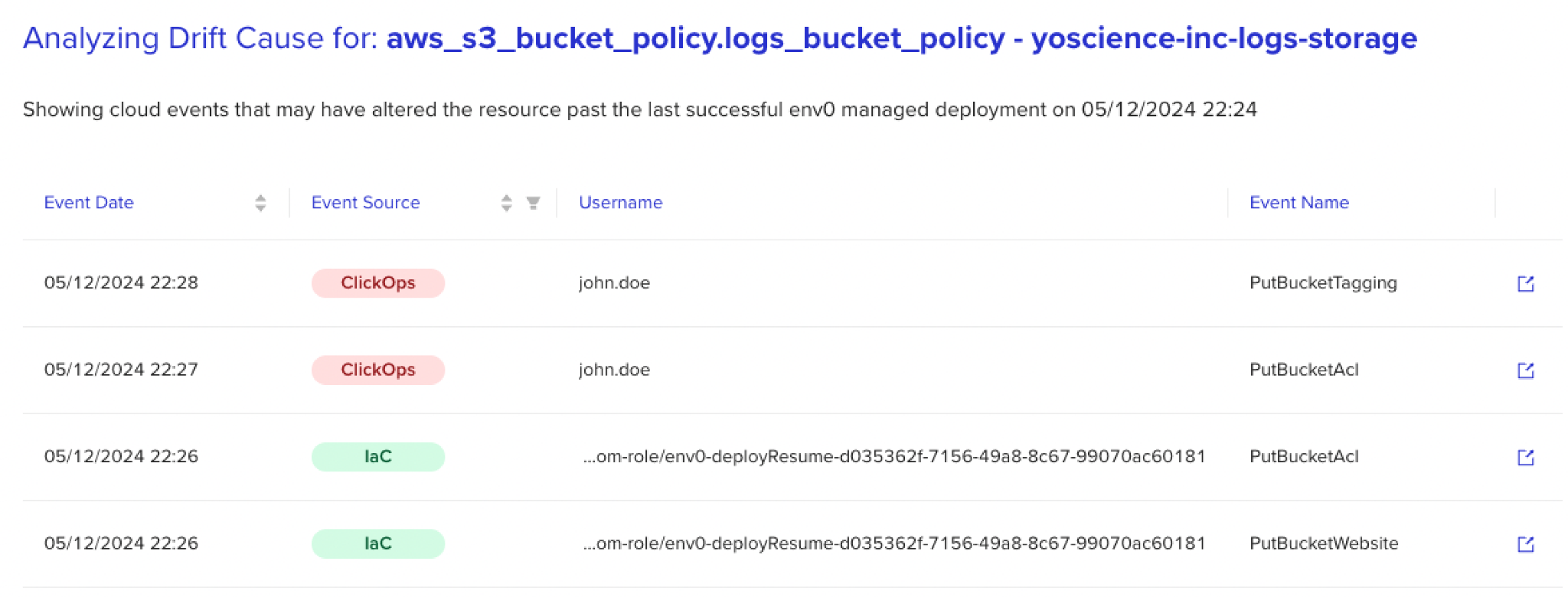
Наблюдение за тем, как организации борются с этими дилеммами, вдохновило концепцию «Причина дрейфа». Эта концепция использует логику с поддержкой искусственного интеллекта для анализа больших журналов событий и предоставления дополнительного контекста для каждого дрейфа, отслеживая изменения до их источника — раскрывая не только «что», но и «кто», «когда» и «почему».
Эта способность обрабатывать неоднородные журналы оптом и собирать данные, связанные с дрейфом, меняет ход процесса согласования. Чтобы проиллюстрировать, позвольте мне вернуть вас к сценарию, о котором я упоминал ранее, и нарисовать картину получения предупреждения о дрейфе от вашего средства обнаружения — на этот раз с добавленным контекстом.
Теперь, имея информацию, предоставленную Причиной дрейфа, вы не только можете быть в курсе дрейфа, но и приблизиться, чтобы узнать, что изменение было сделано Джоном в 2 часа ночи, прямо во время пика нагрузки на приложение.
Без этой информации вы могли бы предположить, что дрейф проблематичен и отменить изменение, что потенциально привело бы к нарушению критических операций и вызову последующих сбоев.
С добавленным контекстом, однако, вы сможете связать все факты, связаться с Джоном, подтвердить, что исправление устранило немедленную проблему, и решить, что его не следует слепо согласовывать. Более того, используя этот контекст, вы также можете начать думать вперед и внести корректировки в конфигурацию для добавления масштабируемости и предотвращения повторения проблемы.
Это простой пример, конечно, но я надеюсь, что он хорошо демонстрирует преимущества наличия дополнительного контекста коренных причин — элемента, который долго отсутствовал в обнаружении смещения, несмотря на то что является стандартом в других областях отладки и устранения неполадок. Цель, конечно, состоит в том, чтобы помочь командам понять не только то, что изменилось, но и почему это изменилось, что дает им возможность уверенно принимать наилучшие решения.
За пределами управления IaC
Однако наличие дополнительного контекста для смещения, как бы важным оно ни было, является лишь одной частью гораздо более крупной головоломки. Управление крупными облачными флотами с закодированными ресурсами вносит больше, чем просто проблемы со смещением, особенно в больших масштабах. Современные инструменты управления IaC эффективны для решения задач управления ресурсами, но спрос на большую видимость и контроль в средах корпоративного масштаба вводит новые требования и приводит к их неизбежной эволюции.
Одно направление, в котором я вижу эту эволюцию, — это управление облачными активами (CAM), которое отслеживает и управляет всеми ресурсами в облачной среде — будь то предоставленные через IaC, API или ручные операции — обеспечивая единый взгляд на активы и помогая организациям понимать конфигурации, зависимости и риски, которые все являются необходимыми для соблюдения нормативных требований, оптимизации затрат и операционной эффективности.
Управление IaC сосредотачивается на операционных аспектах, в то время как управление облачными активами подчеркивает видимость и понимание облачного положения. Действуя как дополнительный уровень наблюдаемости, он заполняет пробел между закодированными рабочими процессами и импровизированными изменениями, обеспечивая всесторонний обзор инфраструктуры.
1+1 Будет Равно Трем
Сочетание управления IaC и УА обеспечивает команды возможностью управлять сложностью с ясностью и контролем. Поскольку наступает конец года, начинается “сезон прогнозирования” — вот мой прогноз. После того как я потратил большую часть последнего десятилетия на создание и совершенствование одной из более популярных (если мне позволить так сказать) платформ управления IaC, я вижу это как естественное развитие нашей отрасли: объединение управления IaC, автоматизации и управления с улучшенной видимостью не закодированных активов.
Эта синергия, на мой взгляд, станет основой для более качественной облачной структуры управления — более точной, адаптивной и приспособленной к будущему. По сей день уже почти принято, что IaC является основой управления облачной инфраструктурой. Однако мы также должны признать, что не все активы когда-либо будут закодированы. В таких случаях решение управления инфраструктурой от начала до конца не может ограничиваться только уровнем IaC.
Следующим этапом станет помощь командам расширить видимость не закодированных активов, обеспечивая бесперебойное функционирование инфраструктуры по мере ее развития — одно согласованное изменение за раз и далее.
Source:
https://dzone.com/articles/the-problem-of-drift-detection-and-drift-cause-analysis