













Qualquer pessoa que trabalhe em DevOps hoje provavelmente concordaria que codificar recursos torna mais fácil observar, governar e automatizar. No entanto, a maioria dos engenheiros também reconheceria que essa transformação traz um novo conjunto de desafios.
Talvez o maior desafio das operações IaC sejam as divergências — um cenário onde os ambientes de execução se desviam de seus estados definidos por IaC, criando um problema crescente que pode ter sérias implicações a longo prazo. Essas discrepâncias prejudicam a consistência dos ambientes em nuvem, levando a potenciais problemas com a confiabilidade e a manutenibilidade da infraestrutura, e até mesmo riscos significativos de segurança e conformidade.
Em um esforço para minimizar esses riscos, aqueles responsáveis por gerenciar esses ambientes estão classificando a divergência como uma tarefa de alta prioridade (e uma grande perda de tempo) para as equipes de operações de infraestrutura.
Isso tem impulsionado a crescente adoção de ferramentas de detecção de divergências que sinalizam discrepâncias entre a configuração desejada e o estado real da infraestrutura. Embora sejam eficazes na detecção de divergências, essas soluções estão limitadas a emitir alertas e destacar diferenças de código, sem oferecer insights mais profundos sobre a causa raiz.
Por que a Detecção de Divergências é Insuficiente
O estado atual da detecção de deriva decorre do fato de que as derivações ocorrem fora do pipeline CI/CD estabelecido e muitas vezes são rastreadas até ajustes manuais, atualizações acionadas por API ou correções de emergência. Como resultado, essas mudanças geralmente não deixam um rastro de auditoria na camada IaC, criando um ponto cego que limita as ferramentas a apenas sinalizar discrepâncias de código. Isso deixa as equipes de engenharia de plataforma especulando sobre as origens da derivação e sobre a melhor forma de abordá-la.
Essa falta de clareza torna a resolução de derivações uma tarefa arriscada. Afinal, reverter automaticamente alterações sem entender seu propósito — uma abordagem padrão comum — poderia abrir uma caixa de Pandora e desencadear uma cascata de problemas.
Um risco é que isso poderia desfazer ajustes ou otimizações legítimas, potencialmente reintroduzindo problemas que já foram resolvidos ou perturbando as operações de uma ferramenta de terceiros valiosa.
Por exemplo, considere um ajuste manual aplicado fora do processo IaC usual para lidar com um problema repentino de produção. Antes de reverter tais alterações, é essencial codificá-las para preservar sua intenção e impacto, ou correr o risco de prescrever um remédio que poderia se revelar pior que a doença.
Deteção Encontra Contexto
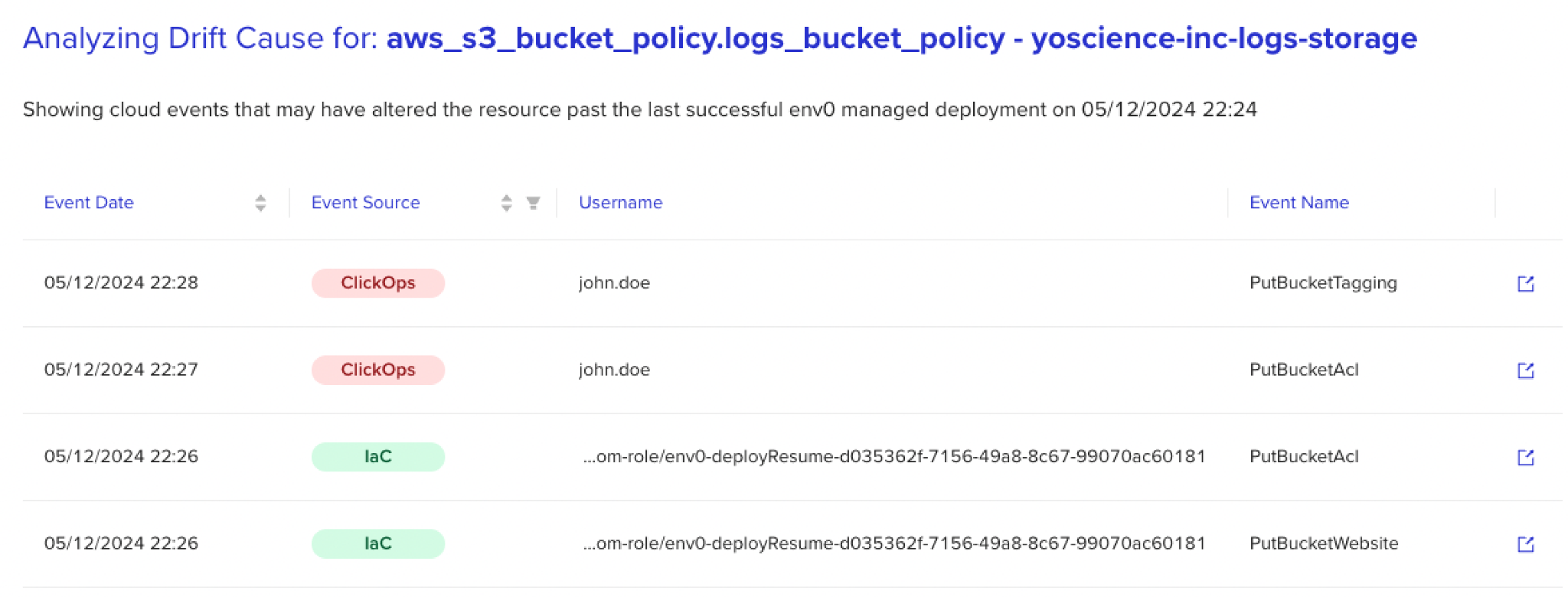
Ver organizações lidando com esses dilemas inspirou o conceito de ‘Causa de Deriva.’ Este conceito utiliza lógica assistida por IA para filtrar grandes logs de eventos e fornecer contexto adicional para cada deriva, rastreando as mudanças até sua origem — revelando não apenas ‘o que’, mas também ‘quem’, ‘quando’ e ‘por quê.’
Essa capacidade de processar logs não uniformes em massa e reunir dados relacionados à deriva muda o jogo no processo de reconciliação. Para ilustrar, deixe-me levá-lo de volta ao cenário que mencionei anteriormente e pintar um quadro de receber um alerta de deriva da sua solução de detecção — desta vez com contexto adicional.
Agora, com as informações fornecidas pela Causa de Deriva, você pode não apenas estar ciente da deriva, mas também se aprofundar para descobrir que a mudança foi feita por John às 2 da manhã, bem na hora em que a aplicação estava lidando com um pico de tráfego.
Sem essa informação, você poderia assumir que a deriva é problemática e reverter a mudança, potencialmente interrompendo operações críticas e causando falhas a montante.
Com o contexto adicional, no entanto, você consegue conectar os pontos, entrar em contato com John, confirmar que a correção resolveu um problema imediato e decidir que não deve ser reconciliada de forma cega. Além disso, usando esse contexto, você também pode começar a pensar à frente e introduzir ajustes na configuração para adicionar escalabilidade e evitar que o problema retorne.
Este é um exemplo simples, é claro, mas espero que sirva bem para mostrar o benefício de ter um contexto adicional sobre a causa raiz — um elemento há muito ausente na detecção de desvios, apesar de ser padrão em outras áreas de depuração e solução de problemas. O objetivo, é claro, é ajudar as equipes a entender não apenas o que mudou, mas por que mudou, capacitando-as a tomar a melhor decisão com confiança.
Além da Gestão de IaC
Mas ter um contexto adicional para desvios, por mais importante que seja, é apenas uma parte de um quebra-cabeça muito maior. Gerenciar grandes frotas em nuvem com recursos codificados introduz mais do que apenas desafios de desvios, especialmente em escala. As ferramentas de gestão de IaC de geração atual são eficazes em lidar com a gestão de recursos, mas a demanda por maior visibilidade e controle em ambientes de grande escala empresarial está introduzindo novos requisitos e impulsionando sua evolução inevitável.
Uma direção que vejo essa evolução se movendo é a Gestão de Ativos em Nuvem (CAM), que rastreia e gerencia todos os recursos em um ambiente de nuvem — seja provisionado via IaC, APIs ou operações manuais — fornecendo uma visão unificada dos ativos e ajudando as organizações a entender configurações, dependências e riscos, todos essenciais para conformidade, otimização de custos e eficiência operacional.
Enquanto a gestão do IaC foca nos aspectos operacionais, o Gerenciamento de Ativos na Nuvem enfatiza a visibilidade e compreensão da postura na nuvem. Atuando como uma camada adicional de observabilidade, ele preenche a lacuna entre fluxos de trabalho codificados e alterações ad hoc, fornecendo uma visão abrangente da infraestrutura.
1+1 Será Igual a Três
A combinação da gestão do IaC e do CAM capacita equipes a gerenciar a complexidade com clareza e controle. À medida que o final do ano se aproxima, é a ‘época de previsões’ – então aqui está a minha. Tendo passado a maior parte da última década construindo e refinando uma das plataformas de gestão do IaC mais populares (se posso dizer isso), vejo isso como a progressão natural de nossa indústria: combinando gestão do IaC, automação e governança com uma visibilidade aprimorada para ativos não codificados.
Essa sinergia, acredito, formará a base para um tipo melhor de estrutura de governança na nuvem – uma que seja mais precisa, adaptável e à prova do futuro. Nesse ponto, é quase certo que o IaC é o alicerce da gestão da infraestrutura na nuvem. No entanto, também devemos reconhecer que nem todos os ativos nunca serão codificados. Em tais casos, uma solução de gerenciamento de infraestrutura de ponta a ponta não pode se limitar apenas à camada do IaC.
A próxima fronteira, então, é ajudar equipes a expandir a visibilidade para ativos não codificados, garantindo que, à medida que a infraestrutura evolui, ela continue a funcionar perfeitamente – uma deriva reconciliada de cada vez e além.
Source:
https://dzone.com/articles/the-problem-of-drift-detection-and-drift-cause-analysis