













В Части 1 этой серии мы рассмотрели MongoDB, одну из самых надежных и устойчивых документально-ориентированных NoSQL баз данных. Здесь, в Части 2, мы рассмотрим другую quite unavoidably NoSQL базу данных: Elasticsearch.
Не только популярную и мощную open-source распределенную NoSQL базу данных, Elasticsearch в первую очередь является поисковой и аналитической системой. Он построен поверх Apache Lucene, самой известной поисковой Java библиотеки, и способен выполнять операции реального времени по поиску и анализу структурированных и неструктурированных данных. Он предназначен для эффективной обработки больших объемов данных.
Еще раз, мы должныDECLARE, что этот короткий пост никоим образом не является учебником по Elasticsearch. Соответственно, читателю настоятельно рекомендуется обширно использовать официальную документацию, а также отличную книгу, “Elasticsearch in Action” Madhusudhan Konda (Manning, 2023), чтобы узнать больше о архитектуре и операциях продукта. Здесь, мы просто реализуем тот же кейс использования, что и previously, но на этот раз, используя Elasticsearch вместо MongoDB.
Итак,前进!
Модель домена
Диаграмма ниже показывает нашу *customer-order-product* модель домена:
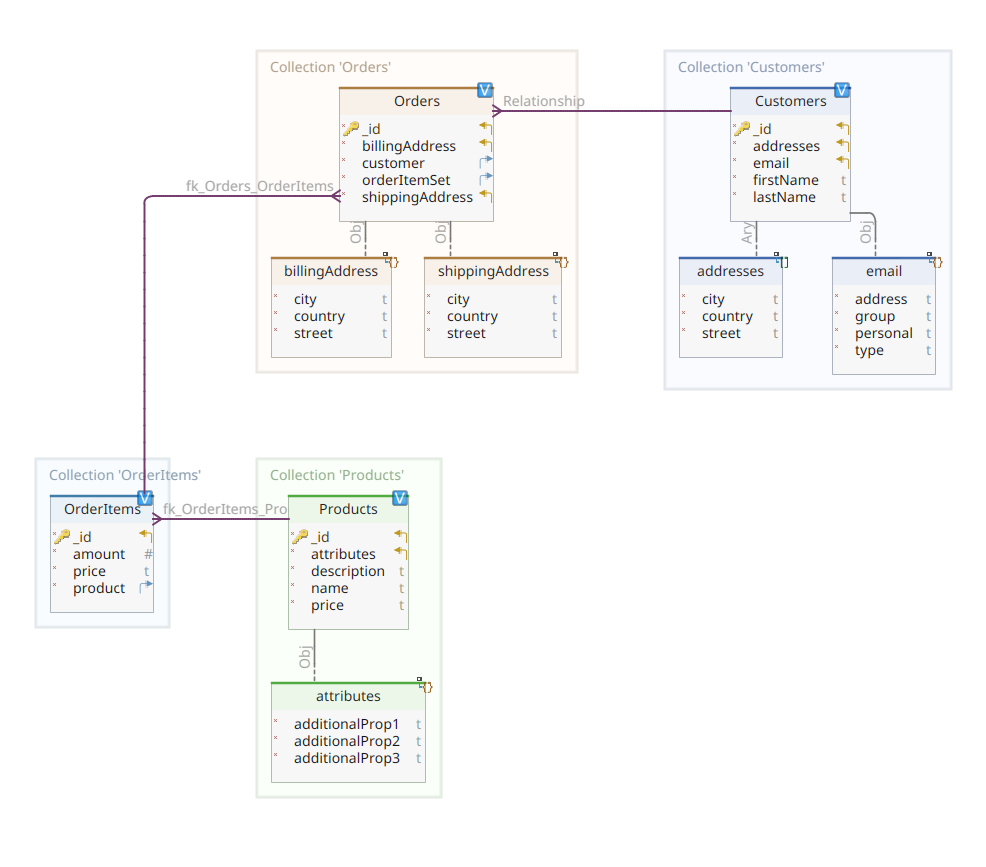
Эта диаграмма такая же, как та, что была представлена в Части 1. Как и MongoDB, Elasticsearch также является хранилищем документных данных и, как таковой, ожидает, чтобы документы были представлены вnotation JSON. Единственное различие заключается в том, что для обработки своих данных Elasticsearch необходимо их индексировать.
Существуют несколько способов индексации данных в хранилище Elasticsearch; например, передавать их из реляционной базы данных, извлекать из файловой системы, передавать их в реальном времени из источника и т.д. Но whichever метод ingestion может быть, в конечном итоге он состоит в вызове RESTful API Elasticsearch через dedicated клиент. Существует две категории таких dedicated клиентов:
- REST-клиенты, такие как
curl,Postman, HTTP-модули для Java, JavaScript, Node.js и т.д. - SDK для программирования (Software Development Kit): Elasticsearch предоставляет SDK для всех наиболее используемых programming languages, включая, но не ограничиваясь Java, Python и т.д.
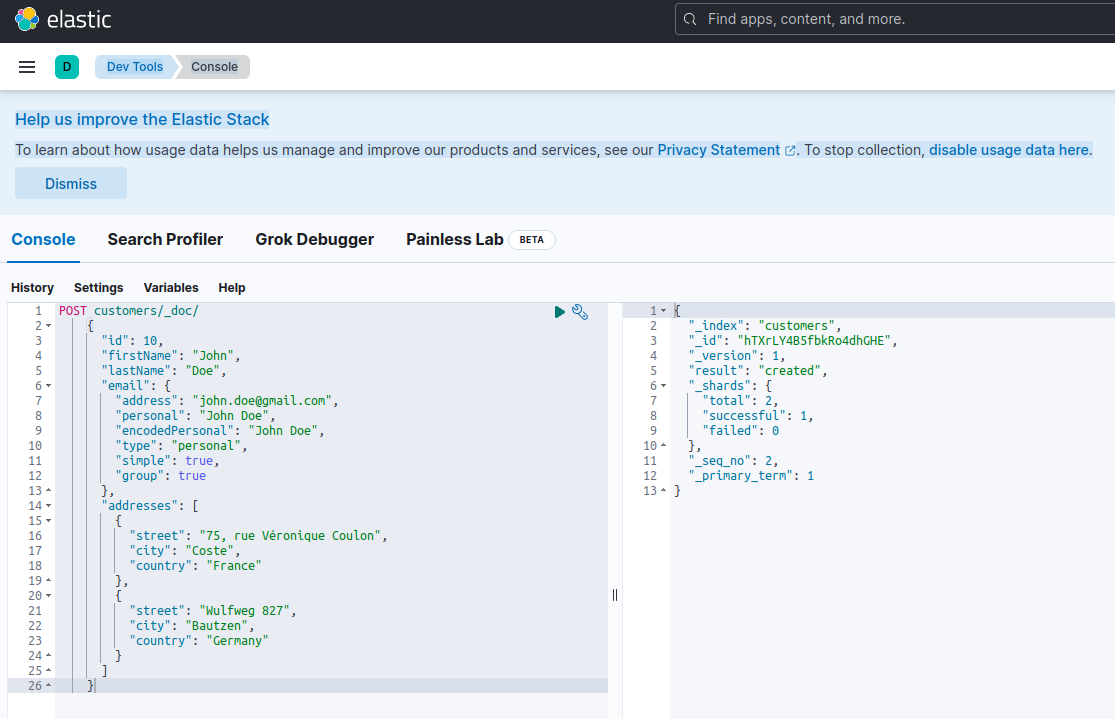
Индексирование нового документа с помощью Elasticsearch означает его создание с использованием POST запроса против special RESTful API endpoint с названием _doc. Например, следующий запрос создаст новый индекс Elasticsearch и сохранит новую запись клиента в нем.
POST customers/_doc/
{
"id": 10,
"firstName": "John",
"lastName": "Doe",
"email": {
"address": "[email protected]",
"personal": "John Doe",
"encodedPersonal": "John Doe",
"type": "personal",
"simple": true,
"group": true
},
"addresses": [
{
"street": "75, rue Véronique Coulon",
"city": "Coste",
"country": "France"
},
{
"street": "Wulfweg 827",
"city": "Bautzen",
"country": "Germany"
}
]
}Выполнение вышеуказанного запроса с помощью curl или консоли Kibana (как мы увидим позже) даст следующий результат:
{
"_index": "customers",
"_id": "ZEQsJI4BbwDzNcFB0ubC",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
Это стандартный ответ Elasticsearch на запрос POST. Он подтверждает создание индекса с именем customers, новый документ customer, identificato от автоматически сгенерированного ID (в данном случае, ZEQsJI4BbwDzNcFB0ubC).
Здесь также появляются другие интересные параметры, такие как _version и особенно _shards. Не углубляясь в太多 деталей, Elasticsearch создает индексы в виде логических коллекций документов. Как будто хранить бумажные документы в картотечном ящике, Elasticsearch хранит документы в индексе. Каждый индекс состоит из фрагментов, которые являются физическими экземплярами Apache Lucene, движка, работающего за кулисами и ответственного за передачу данных в хранилище или из него. Они могут быть основными, хранящими документы, или репликами, хранящими, как suggests их название, копии основных фрагментов. Подробнее об этом в документации Elasticsearch – на данный момент нам нужно отметить, что наш индекс с именем customers состоит из двух фрагментов: один из которых, конечно, основной.
A final notice: the POST request above doesn’t mention the ID value as it is automatically generated. While this is probably the most common use case, we could have provided our own ID value. In each case, the HTTP request to be used isn’t POST anymore, but PUT.
Вернемся к диаграмме доменного модели, как вы можете видеть, ее central документ – Order, хранящийся в deducated коллекции под названием Orders. Order – это агрегат документов OrderItem, каждый из которых указывает на связанный Product. Документ Order также ссылается на Customer, который его разместил. В Java это реализуется следующим образом:
public class Customer
{
private Long id;
private String firstName, lastName;
private InternetAddress email;
private Set<Address> addresses;
...
}
Приведенный выше код показывает фрагмент класса Customer. Это простой POJO (Plain Old Java Object), который имеет свойства, такие как ID клиента, имя и фамилия, адрес электронной почты и набор почтовых адресов.
Теперь давайте рассмотрим документ Order.
public class Order
{
private Long id;
private String customerId;
private Address shippingAddress;
private Address billingAddress;
private Set<String> orderItemSet = new HashSet<>()
...
}
Здесь можно заметить некоторые различия по сравнению с версией MongoDB. На самом деле, с MongoDB мы использовали ссылку на экземпляр клиента, связанный с этим заказом. Понятие ссылки не существует в Elasticsearch, и поэтому мы используем этот идентификатор документа для создания ассоциации между заказом и клиентом, который его сделал. То же самое применяется к свойству orderItemSet, которое создает ассоциацию между заказом и его позициями.
Остальная часть нашей доменной модели довольно相似на и основана на тех же идеях нормализации. Например, документ OrderItem:
public class OrderItem
{
private String id;
private String productId;
private BigDecimal price;
private int amount;
...
}
Здесь нам нужно связать продукт, который является объектом текущей позиции заказа. Наконец, у нас есть документ Product:
public class Product
{
private String id;
private String name, description;
private BigDecimal price;
private Map<String, String> attributes = new HashMap<>();
...
}хранилища данных
Quarkus Panache значительно упрощает процесс 数据处理持久化, поддерживая как активную запись, так и паттерн репозитория. В части 1 мы использовали расширение Quarkus Panache для MongoDB для реализации наших репозиториев данных, но до сих пор нет аналогичного расширения Quarkus Panache для Elasticsearch. Соответственно, ожидая возможного будущего расширения Quarkus для Elasticsearch, здесь мы должны вручную реализовать наши репозитории данных, используя dedicatied клиент для Elasticsearch.
Elasticsearch написан на Java и, следовательно, не удивительно, что он предлагает nativную поддержку вызова API Elasticsearch с использованием библиотеки Java-клиента. Эта библиотека основана на паттерне的设计а fluent API builder и предоставляет как синхроническую, так и асинхронную модели обработки. Она требует как минимум Java 8.
Итак, как выглядят наши репозитории данных на основе fluent API builder? Ниже приведен отрывок из класса CustomerServiceImpl, который действует как репозиторий данных для документа Customer.
@ApplicationScoped
public class CustomerServiceImpl implements CustomerService
{
private static final String INDEX = "customers";
@Inject
ElasticsearchClient client;
@Override
public String doIndex(Customer customer) throws IOException
{
return client.index(IndexRequest.of(ir -> ir.index(INDEX).document(customer))).id();
}
...
Как мы видим, реализация нашего репозитория данных должна быть бином CDI с приложением области применения. Клиент Java Elasticsearch просто инжектируется благодаря расширению quarkus-elasticsearch-java-client Quarkus. Таким образом, мы избегаем массы наворотов, которые мы были бы вынуждены использовать в противном случае. Единственное, что нам нужно для инъекции клиента, это объявить следующую_property:
quarkus.elasticsearch.hosts = elasticsearch:9200Здесь, elasticsearch – это DNS (сервер доменных имен), который мы ассоциируем с сервером базы данных Elastic search в файле docker-compose.yaml. 9200 – это номер порта TCP, который используется сервером для прослушивания подключений.
Метод doIndex() выше создает новый индекс с именем customers, если его не существует, и индексирует (хранит) в нем новый документ, представляющий экземпляр класса Customer. Процесс индексации выполняется на основе IndexRequest, принимающего в качестве входных аргументов имя индекса и тело документа. Что касается ID документа, он генерируется автоматически и возвращается звонящему для дальнейшего использования.
Следующий метод позволяет получить клиента, идентифицированного по ID, переданному в качестве входного аргумента:
...
@Override
public Customer getCustomer(String id) throws IOException
{
GetResponse<Customer> getResponse = client.get(GetRequest.of(gr -> gr.index(INDEX).id(id)), Customer.class);
return getResponse.found() ? getResponse.source() : null;
}
...
Принцип тот же: используя этот фluent API паттерн строительства, мы создаем экземпляр GetRequest аналогичным образом, как мы это делали с IndexRequest, и запускаем его против Java клиента Elasticsearch. Другие endpoints нашего хранилища данных, позволяющие выполнять полные поисковые операции или обновлять и удалять клиентов, спроектированы аналогичным образом.
Пожалуйста, уделите немного времени, чтобы изучить код и понять, как все работает.
REST API
Наш интерфейс REST API для MongoDB был прост в реализации благодаря расширению quarkus-mongodb-rest-data-panache, в котором процессор.annotation автоматически генерировал все необходимые endpoint’ы. С Elasticsearch мы пока не можем воспользоваться тем же удобством и, следовательно, должны реализовывать его вручную. Это не большая проблема, так как мы можем инжектить предыдущие репозитории данных, показанные ниже:
@Path("customers")
@Produces(APPLICATION_JSON)
@Consumes(APPLICATION_JSON)
public class CustomerResourceImpl implements CustomerResource
{
@Inject
CustomerService customerService;
@Override
public Response createCustomer(Customer customer, @Context UriInfo uriInfo) throws IOException
{
return Response.accepted(customerService.doIndex(customer)).build();
}
@Override
public Response findCustomerById(String id) throws IOException
{
return Response.ok().entity(customerService.getCustomer(id)).build();
}
@Override
public Response updateCustomer(Customer customer) throws IOException
{
customerService.modifyCustomer(customer);
return Response.noContent().build();
}
@Override
public Response deleteCustomerById(String id) throws IOException
{
customerService.removeCustomerById(id);
return Response.noContent().build();
}
}Это реализация REST API клиента. Другие, связанные с заказами, элементами заказа и продуктами, аналогичны.
Давайте теперь посмотрим, как запустить и протестировать все это.
Запуск и Тестирование наших Микросервисов
Теперь, когда мы рассмотрели детали нашей реализации, давайте посмотрим, как запустить и протестировать ее. Мы выбрали делать это от имени утилиты docker-compose. Вот соответствующий файл docker-compose.yml:
version: "3.7"
services:
elasticsearch:
image: elasticsearch:8.12.2
environment:
node.name: node1
cluster.name: elasticsearch
discovery.type: single-node
bootstrap.memory_lock: "true"
xpack.security.enabled: "false"
path.repo: /usr/share/elasticsearch/backups
ES_JAVA_OPTS: -Xms512m -Xmx512m
hostname: elasticsearch
container_name: elasticsearch
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- node1-data:/usr/share/elasticsearch/data
networks:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:8.6.2
hostname: kibana
container_name: kibana
environment:
- elasticsearch.url=http://elasticsearch:9200
- csp.strict=false
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 5601:5601
networks:
- elasticsearch
depends_on:
- elasticsearch
links:
- elasticsearch:elasticsearch
docstore:
image: quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT
depends_on:
- elasticsearch
- kibana
hostname: docstore
container_name: docstore
links:
- elasticsearch:elasticsearch
- kibana:kibana
ports:
- "8080:8080"
- "5005:5005"
networks:
- elasticsearch
environment:
JAVA_DEBUG: "true"
JAVA_APP_DIR: /home/jboss
JAVA_APP_JAR: quarkus-run.jar
volumes:
node1-data:
driver: local
networks:
elasticsearch:
Этот файл instructs утилиту docker-compose запустить три сервисы:
- A service named
elasticsearchrunning the Elasticsearch 8.6.2 database - A service named
kibanarunning the multipurpose web console providing different options such as executing queries, creating aggregations, and developing dashboards and graphs - A service named
docstorerunning our Quarkus microservice
Теперь вы можете проверить, что все необходимые процессы работают:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
005ab8ebf6c0 quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT "/opt/jboss/containe…" 3 days ago Up 3 days 0.0.0.0:5005->5005/tcp, :::5005->5005/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp docstore
9678c0a04307 docker.elastic.co/kibana/kibana:8.6.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana
805eba38ff6c elasticsearch:8.12.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp elasticsearch
$
Чтобы confirm, что сервер Elasticsearch доступен и может выполнять запросы, вы можете подключиться к Kibana по адресу http://localhost:601. После прокрутки страницы вниз и выбора Dev Tools в меню предпочтений, вы можете выполнять запросы, как показано ниже:
Чтобы протестировать микросервисы, proceed следующим образом:
1. Clone соответствующий репозиторий GitHub:
$ git clone https://github.com/nicolasduminil/docstore.git2. Перейдите в проект:
$ cd docstore3. Переключитесь на правильную ветку:
$ git checkout elastic-search4. Build:
$ mvn clean install5. Запустите интеграционные тесты:
$ mvn -DskipTests=false failsafe:integration-testЭтот последний命令 запустит 17 предоставленных тестов интеграции, которые должны все успешно завершиться. Вы также можете использовать интерфейс Swagger UI для тестирования, открыв ваш любимый браузер по адресу http://localhost:8080/q:swagger-ui. Затем, чтобы�试ировать endpoints, вы можете использовать данные из JSON-файлов, расположенных в директории src/resources/data проекта docstore-api.
Наслаждайтесь!
Source:
https://dzone.com/articles/cruding-nosql-data-with-quarkus-part-two-elasticse