













En la Primera Parte de esta serie, nos centramos en MongoDB, una de las bases de datos NoSQL orientadas a documentos más confiables y robustas. Aquí, en la
Más que solo una base de datos NoSQL distribuida popular y poderosa de código abierto, Elasticsearch es ante todo un motor de búsqueda y análisis. Se construye sobre Apache Lucene, la biblioteca de búsqueda Java más famosa, y es capaz de realizar operaciones de búsqueda y análisis en tiempo real en datos estructurados y no estructurados. Está diseñado para manejar eficientemente grandes cantidades de datos.
Otra vez, debemos aclarar que este breve artículo no es ni mucho menos un tutorial de Elasticsearch. En consecuencia, se recomienda encarecidamente al lector que utilice extensamente la documentación oficial, así como el excelente libro, “Elasticsearch in Action” de Madhusudhan Konda (Manning, 2023) para aprender más sobre la arquitectura y operaciones del producto. Aquí, simplemente estamos reimplementando el mismo caso de uso que antes, pero esta vez, utilizando Elasticsearch en lugar de MongoDB.
Así que, aquí vamos!
El Modelo de Dominio
El diagrama a continuación muestra nuestro modelo de dominio *customer-order-product*:
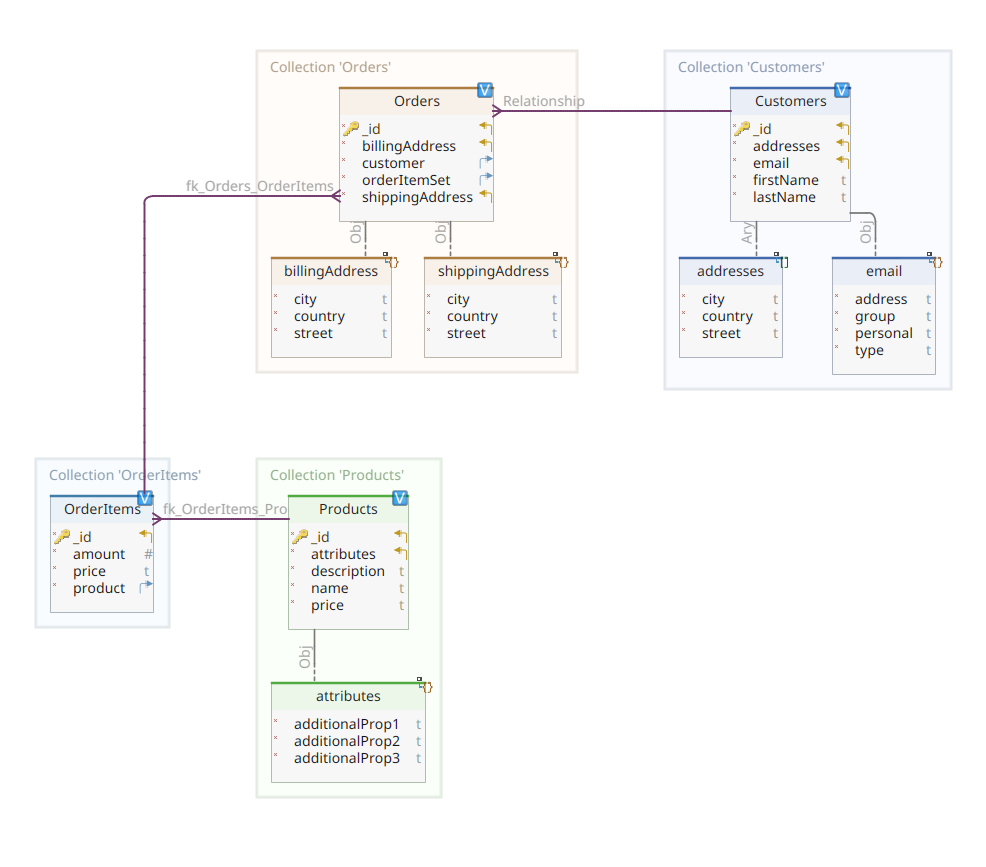
Este diagrama es el mismo que el presentado en la Parte 1. Al igual que MongoDB, Elasticsearch también es un almacén de datos de documentos y, como tal, espera que los documentos se presenten en notación JSON. La única diferencia es que para manejar sus datos, Elasticsearch necesita que estos sean indexados.
Existen varias maneras en que los datos pueden ser indexados en un almacén de datos de Elasticsearch; por ejemplo, transportándolos desde una base de datos relacional, extrayéndolos de un sistema de archivos, transmitiéndolos desde una fuente en tiempo real, etc. Pero independientemente del método de ingesta, finalmente consiste en invocar la API RESTful de Elasticsearch a través de un cliente dedicado. Hay dos categorías de tales clientes dedicados:
- clientes basados en REST como
curl,Postman, módulos HTTP para Java, JavaScript, Node.js, etc. - SDKs de lenguajes de programación (Software Development Kit): Elasticsearch proporciona SDKs para todos los lenguajes de programación más utilizados, incluyendo pero no limitado a Java, Python, etc.
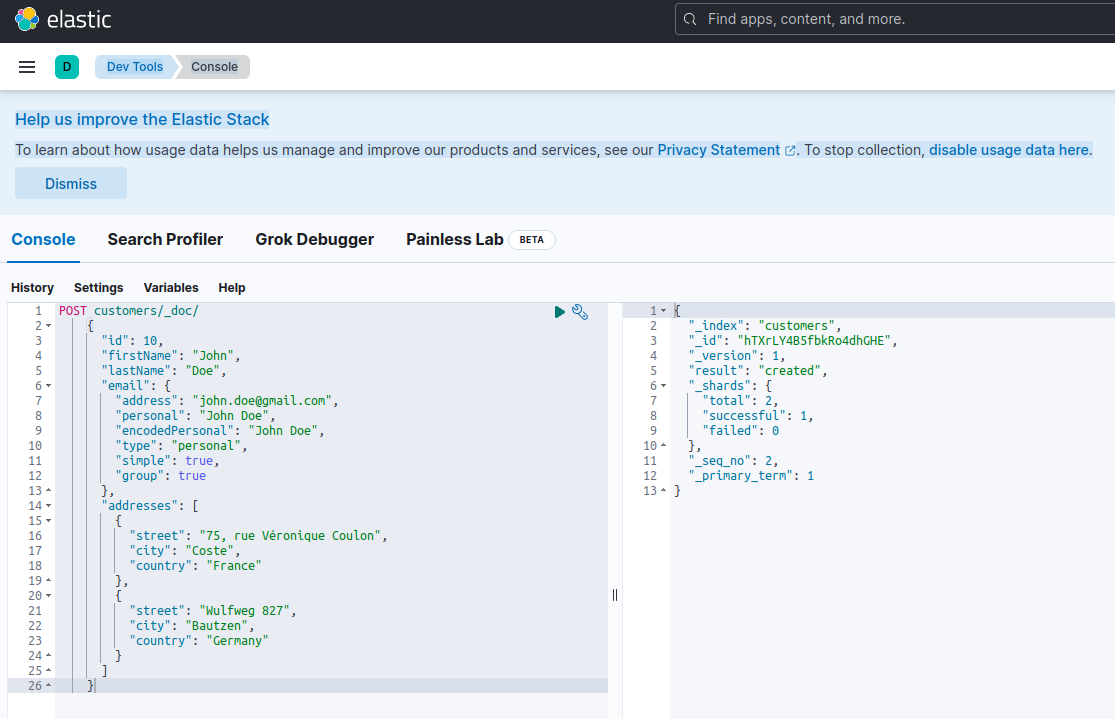
Indexar un nuevo documento con Elasticsearch significa crearlo utilizando una solicitud POST contra un endpoint RESTful especial llamado _doc. Por ejemplo, la siguiente solicitud creará un nuevo índice de Elasticsearch y almacenará una nueva instancia de cliente en él.
POST customers/_doc/
{
"id": 10,
"firstName": "John",
"lastName": "Doe",
"email": {
"address": "[email protected]",
"personal": "John Doe",
"encodedPersonal": "John Doe",
"type": "personal",
"simple": true,
"group": true
},
"addresses": [
{
"street": "75, rue Véronique Coulon",
"city": "Coste",
"country": "France"
},
{
"street": "Wulfweg 827",
"city": "Bautzen",
"country": "Germany"
}
]
}Ejecutar la solicitud anterior utilizando curl o la consola de Kibana (como veremos más adelante) producirá el siguiente resultado:
{
"_index": "customers",
"_id": "ZEQsJI4BbwDzNcFB0ubC",
"_version": 1,
"result": "created",
"_shards": {
"total": 2,
"successful": 1,
"failed": 0
},
"_seq_no": 1,
"_primary_term": 1
}
Esta es la respuesta estándar de Elasticsearch a una solicitud POST. Confirmar haber creado el índice llamado customers, tener un nuevo documento customer, identificado por un ID generado automáticamente (en este caso, ZEQsJI4BbwDzNcFB0ubC).
Otros parámetros interesantes aparecen aquí, como _version y especialmente _shards. Sin entrar en muchos detalles, Elasticsearch crea índices como colecciones lógicas de documentos. Al igual que mantener documentos en papel en un archivador, Elasticsearch mantiene documentos en un índice. Cada índice está compuesto por shards, que son instancias físicas de Apache Lucene, el motor detrás que se encarga de obtener los datos del almacenamiento o sacarlos de él. Pueden ser primarias, almacenando documentos, o replicas, almacenando, como su nombre sugiere, copias de los shards primarios. Más sobre esto en la documentación de Elasticsearch – por ahora, necesitamos notar que nuestro índice llamado customers está compuesto por dos shards: uno de los cuales, por supuesto, es primario.
A final notice: the POST request above doesn’t mention the ID value as it is automatically generated. While this is probably the most common use case, we could have provided our own ID value. In each case, the HTTP request to be used isn’t POST anymore, but PUT.
Para regresar a nuestro diagrama de modelo de dominio, como puedes ver, su documento central es Order, almacenado en una colección dedicada llamada Orders. Una Order es un agregado de documentos OrderItem, cada uno de los cuales apunta a su Product asociado. Un documento Order también hace referencia al Customer que lo placed. En Java, esto se implementa de la siguiente manera:
public class Customer
{
private Long id;
private String firstName, lastName;
private InternetAddress email;
private Set<Address> addresses;
...
}
El código anterior muestra un fragmento de la clase Customer. Esta es una simple POJO (Plain Old Java Object) que tiene propiedades como el ID del cliente, el nombre y apellido, dirección de correo electrónico y un conjunto de direcciones postales.
Veamos ahora el documento Order.
public class Order
{
private Long id;
private String customerId;
private Address shippingAddress;
private Address billingAddress;
private Set<String> orderItemSet = new HashSet<>()
...
}
Aquí puedes notar algunas diferencias en comparación con la versión de MongoDB. De hecho, con MongoDB estábamos utilizando una referencia a la instancia del cliente asociada con este pedido. Esta noción de referencia no existe con Elasticsearch, y por lo tanto, estamos utilizando este ID de documento para crear una asociación entre el pedido y el cliente que lo realizó. Lo mismo se aplica a la propiedad orderItemSet que crea una asociación entre el pedido y sus ítems.
El resto de nuestro modelo de dominio es bastante similar y se basa en las mismas ideas de normalización. Por ejemplo, el documento OrderItem:
public class OrderItem
{
private String id;
private String productId;
private BigDecimal price;
private int amount;
...
}
Aquí, necesitamos asociar el producto que es el objeto del ítem de pedido actual. Por último, pero no menos importante, tenemos el documento Product:
public class Product
{
private String id;
private String name, description;
private BigDecimal price;
private Map<String, String> attributes = new HashMap<>();
...
}Los Repositorios de Datos
Quarkus Panache greatly simplifies the proceso de persistencia de datos al apoyo tanto del patrón active record como del patrón repository. En la Parte 1, utilizamos la extensión Quarkus Panache para MongoDB para implementar nuestros repositorios de datos, pero aún no hay una extensión equivalente de Quarkus Panache para Elasticsearch. Por lo tanto, esperando una posible extensión futura de Quarkus para Elasticsearch, aquí debemos implementar manualmente nuestros repositorios de datos utilizando el cliente dedicado de Elasticsearch.
Elasticsearch está escrito en Java y, consecuentemente, no es una sorpresa que ofrezca soporte nativo para invocar la API de Elasticsearch utilizando la biblioteca de cliente de Java. Esta biblioteca se basa en el patrón de diseño de constructor de API fluente y proporciona tanto modelos de procesamiento síncrono como asíncrono. Requiere al menos Java 8.
Entonces, ¿qué aspecto tienen nuestros repositorios de datos basados en el constructor de API fluente? A continuación, se muestra un extracto de la clase CustomerServiceImpl que actúa como un repositorio de datos para el documento Customer.
@ApplicationScoped
public class CustomerServiceImpl implements CustomerService
{
private static final String INDEX = "customers";
@Inject
ElasticsearchClient client;
@Override
public String doIndex(Customer customer) throws IOException
{
return client.index(IndexRequest.of(ir -> ir.index(INDEX).document(customer))).id();
}
...
Como podemos ver, nuestra implementación de repositorio de datos debe ser un bean CDI con un alcance de aplicación. El cliente de Java de Elasticsearch se’inyecta simplemente’ gracias a la extensión quarkus-elasticsearch-java-client de Quarkus. De esta manera, evitamos muchos accesorios que de otro modo habríamos tenido que usar. Lo único que necesitamos para poder inyectar el cliente es declarar la siguiente propiedad:
quarkus.elasticsearch.hosts = elasticsearch:9200Aquí, elasticsearch es el nombre de DNS (Servidor de Nombres de Dominio) que asociamos con el servidor de base de datos Elastic search en el archivo docker-compose.yaml. 9200 es el número de puerto TCP utilizado por el servidor para escuchar conexiones.
El método doIndex() de arriba crea un nuevo índice llamado customers si no existe y indexa (almacena) en él un nuevo documento que representa una instancia de la clase Customer. El proceso de indexación se realiza basado en una IndexRequest que acepta como argumentos de entrada el nombre del índice y el cuerpo del documento. En cuanto al ID del documento, se genera automáticamente y se devuelve al llamador para futuras referencias.
El siguiente método permite recuperar el cliente identificado por el ID dado como argumento de entrada:
...
@Override
public Customer getCustomer(String id) throws IOException
{
GetResponse<Customer> getResponse = client.get(GetRequest.of(gr -> gr.index(INDEX).id(id)), Customer.class);
return getResponse.found() ? getResponse.source() : null;
}
...
El principio es el mismo: utilizando este patrón de constructor de API fluent, construimos una instancia de GetRequest de manera similar a como lo hicimos con la IndexRequest, y la ejecutamos contra el cliente de Elasticsearch en Java. Los otros puntos de extremo de nuestro repositorio de datos, que nos permiten realizar operaciones de búsqueda completas o actualizar y eliminar clientes, están diseñados de la misma manera.
Por favor, dedique un poco de tiempo a revisar el código para entender cómo funcionan las cosas.
La API REST
Nuestra interfaz de API REST de MongoDB fue sencilla de implementar, gracias a la extensión quarkus-mongodb-rest-data-panache, en la cual el procesador de anotaciones generó automáticamente todos los endpoints requeridos. Con Elasticsearch, aún no contamos con el mismo nivel de confort y, por lo tanto, necesitamos implementarlo manualmente. Esto no es un gran problema, ya que podemos inyectar los repositorios de datos anteriores, como se muestra a continuación:
@Path("customers")
@Produces(APPLICATION_JSON)
@Consumes(APPLICATION_JSON)
public class CustomerResourceImpl implements CustomerResource
{
@Inject
CustomerService customerService;
@Override
public Response createCustomer(Customer customer, @Context UriInfo uriInfo) throws IOException
{
return Response.accepted(customerService.doIndex(customer)).build();
}
@Override
public Response findCustomerById(String id) throws IOException
{
return Response.ok().entity(customerService.getCustomer(id)).build();
}
@Override
public Response updateCustomer(Customer customer) throws IOException
{
customerService.modifyCustomer(customer);
return Response.noContent().build();
}
@Override
public Response deleteCustomerById(String id) throws IOException
{
customerService.removeCustomerById(id);
return Response.noContent().build();
}
}Esta es la implementación de la API REST del cliente. Las otras asociadas a pedidos, artículos de pedido y productos son similares.
Vamos a ver ahora cómo ejecutar y probar todo el sistema.
Ejecución y Pruebas de Nuestros Microservicios
Ahora que hemos visto los detalles de nuestra implementación, veamos cómo ejecutar y probarla. Optamos por hacerlo a través de la utilidad docker-compose. Aquí está el archivo asociado docker-compose.yml:
version: "3.7"
services:
elasticsearch:
image: elasticsearch:8.12.2
environment:
node.name: node1
cluster.name: elasticsearch
discovery.type: single-node
bootstrap.memory_lock: "true"
xpack.security.enabled: "false"
path.repo: /usr/share/elasticsearch/backups
ES_JAVA_OPTS: -Xms512m -Xmx512m
hostname: elasticsearch
container_name: elasticsearch
ports:
- "9200:9200"
- "9300:9300"
ulimits:
memlock:
soft: -1
hard: -1
volumes:
- node1-data:/usr/share/elasticsearch/data
networks:
- elasticsearch
kibana:
image: docker.elastic.co/kibana/kibana:8.6.2
hostname: kibana
container_name: kibana
environment:
- elasticsearch.url=http://elasticsearch:9200
- csp.strict=false
ulimits:
memlock:
soft: -1
hard: -1
ports:
- 5601:5601
networks:
- elasticsearch
depends_on:
- elasticsearch
links:
- elasticsearch:elasticsearch
docstore:
image: quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT
depends_on:
- elasticsearch
- kibana
hostname: docstore
container_name: docstore
links:
- elasticsearch:elasticsearch
- kibana:kibana
ports:
- "8080:8080"
- "5005:5005"
networks:
- elasticsearch
environment:
JAVA_DEBUG: "true"
JAVA_APP_DIR: /home/jboss
JAVA_APP_JAR: quarkus-run.jar
volumes:
node1-data:
driver: local
networks:
elasticsearch:
Este archivo indica a la utilidad docker-compose que ejecute tres servicios:
- A service named
elasticsearchrunning the Elasticsearch 8.6.2 database - A service named
kibanarunning the multipurpose web console providing different options such as executing queries, creating aggregations, and developing dashboards and graphs - A service named
docstorerunning our Quarkus microservice
Ahora, puedes verificar que todos los procesos requeridos están en ejecución:
$ docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
005ab8ebf6c0 quarkus-nosql-tests/docstore-elasticsearch:1.0-SNAPSHOT "/opt/jboss/containe…" 3 days ago Up 3 days 0.0.0.0:5005->5005/tcp, :::5005->5005/tcp, 0.0.0.0:8080->8080/tcp, :::8080->8080/tcp, 8443/tcp docstore
9678c0a04307 docker.elastic.co/kibana/kibana:8.6.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:5601->5601/tcp, :::5601->5601/tcp kibana
805eba38ff6c elasticsearch:8.12.2 "/bin/tini -- /usr/l…" 3 days ago Up 3 days 0.0.0.0:9200->9200/tcp, :::9200->9200/tcp, 0.0.0.0:9300->9300/tcp, :::9300->9300/tcp elasticsearch
$
Para confirmar que el servidor de Elasticsearch está disponible y capaz de ejecutar consultas, puedes conectarte a Kibana en http://localhost:601. Después de desplazarte hacia abajo en la página y seleccionar Dev Tools en el menú de preferencias, puedes ejecutar consultas como se muestra a continuación:
Para probar los microservicios, procede de la siguiente manera:
1. Clona el repositorio de GitHub asociado:
$ git clone https://github.com/nicolasduminil/docstore.git2. Dirígete al proyecto:
$ cd docstore3. Cambia al分支 correcto:
$ git checkout elastic-search4. Construye:
$ mvn clean install5. Ejecuta las pruebas de integración:
$ mvn -DskipTests=false failsafe:integration-testEste último comando ejecutará las 17 pruebas de integración proporcionadas, las cuales todas deberían exitir. También puedes usar la interfaz de Swagger UI para fines de prueba abriendo tu navegador preferido en http://localhost:8080/q:swagger-ui. Luego, para probar los endpoints, puedes usar las cargas útiles en los archivos JSON ubicados en el directorio src/resources/data del proyecto docstore-api.
¡Disfruta!
Source:
https://dzone.com/articles/cruding-nosql-data-with-quarkus-part-two-elasticse