













Introdução
Na ciência de dados, e especialmente no Processamento de Linguagem Natural, a resumo é e tem sido sempre um assunto de interesse intenso. Embora os métodos de resumo de texto tenham existido por algum tempo, os últimos anos têm visto desenvolvimentos significativos no processamento de linguagem natural e aprendizagem profunda. Existem inúmeros artigos sendo publicados sobre o assunto por gigantes da internet, como o recente ChatGPT. Embora muito trabalho seja feito neste tópico de estudo, há muito pouco escrito sobre implementações práticas de resumo dirigido por AI. A dificuldade de análise de afirmações amplas e genéricas é um obstáculo para o resumo efetivo.
Resumir um artigo de notícias e um relatório de lucros financeiros são duas tarefas diferentes. Quando se trata de textos de características que variam em comprimento ou assunto (tecnologia, esportes, finanças, viagens, etc.), o resumo se torna um trabalho de ciência de dados desafiador. É essencial abordar alguns fundamentos de teoria de resumo antes de mergulhar em uma visão geral de aplicações.
Resumo Extraído
O processo de resumo extrativo envolve selecionar as frases mais relevantes de um artigo e organizá-las sistematicamente. As frases que compõem o resumo são tiradas de forma literal do material fonte.
Sistemas de resumo extrativo, como os conhecemos hoje, giram em torno de três operações fundamentais:
Construção de uma representação intermediária do texto de entrada
As representações baseadas em representação incluem exemplos como representação de tópicos e representação de indicadores. Para entender os assuntos mencionados no texto, a representação de tópicos converte o texto em uma representação intermediária.
Avaliando as frases com base na representação
Ao tempo da geração da representação intermediária, cada frase é atribuída uma pontuação de relevância. Quando se utiliza um método que depende da representação de tópicos, a pontuação da frase reflete como ela explica com eficácia os conceitos críticos no texto. Na representação de indicadores, a pontuação é calculada agregando a evidência de diferentes indicadores com pesos.
Seleção de um resumo composto por várias frases
Para gerar um resumo, o software de resumo seleciona as k frases mais importantes. Por exemplo, alguns métodos usam algoritmos avultados para escolher quais frases são as mais relevantes, enquanto outros podem transformar a seleção de frases em um problema de otimização no qual é selecionado um conjunto de frases sob a condição de que deve maximizar a importância e a coerência global e minimizar a quantidade de informação redundante.
Vamos mergulhar mais fundo nas metodologias que mencionámos:
Métodos de Representação de Tópicos
Palavras-tópico: Usando este método, você pode encontrar termos relacionados ao tópico em um documento de entrada. A importância de uma frase pode ser calculada de duas formas: primeiro, como uma função do número de assinaturas de tópico que ela inclui; segundo, como uma fração das assinaturas de tópico que contém.
Enquanto o primeiro método dá pontuações mais altas para frases longer com mais palavras, o segundo mede a densidade das palavras-tópico.
Aproximadas baseadas em frequência: Através deste método, as palavras são atribuídas importância relativa. Se o termo for adequado à questão, obtém 1 ponto; caso contrário, chega a zero. Dependendo de como são implementadas, as ponderações podem ser contínuas. Representações de tópicos podem ser alcançadas usando um de dois métodos:
Probabilidade de Palavra: Ela considera apenas a frequência de uma palavra para indicar sua importância. Para calcular a probabilidade de uma palavra w, dividimos a frequência com que ela ocorre, f(w), pela quantidade total de palavras, N.
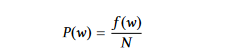
A importância média das palavras em uma sentença dá a importância da sentença quando usando probabilidades de palavra.
TFIDF (Termo de Frequência em Relação à Frequência Inversa do Documento): Este método é uma melhoria sobre o método de probabilidade de palavra. Aqui, as ponderações são determinadas usando o TF-IDF. A técnica de TFIDF dá menos importância a termos que frequentemente aparecem em a maioria dos documentos. A peso de cada palavra w no documento d é calculado da seguinte forma:
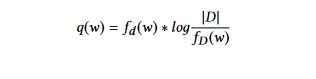
onde fd (w) é a frequência do termo w no documento d,
fD (w) é o número de documentos que contêm a palavra w, e |D| é o número de documentos na coleção D.
Análise Semântica Latente: Análise semântica latente (LSA) é um método não supervisado para extrair uma representação da semântica de texto com base em palavras observadas. O processo de LSA começa com a construção de uma matriz de termo-sentença (n por m), onde cada linha representa uma palavra de entrada (n-palavras) e cada coluna representa uma sentença (m sentenças). Na matriz, o peso da palavra i na sentença j é definido pela entrada aij. De acordo com a técnica TFIDF, cada palavra em uma sentença é dada uma certa peso, com zero sendo atribuído a termos que não estão incluídos na sentença.
Abordagens de Representação de Indicador
Métodos baseados em grafos
Métodos gráficos, influenciados pelo algoritmo PageRank, representam os documentos como um grafo conectado. As frases formam os vértices do grafo, e as arestas que conectam as frases mostram o grau de relação entre duas frases. Um método frequentemente usado para ligar dois vértices é avaliar a similaridade entre duas frases, e se o grau de similaridade for maior do que um certo limiar, os vértices são conectados. Ambos os resultados são possíveis com essa representação de grafo. Primeiro, as partições do grafo (sub-grafos) definem categorias individuais de informação abordadas pelos documentos. O segundo resultado é que as frases chave do documento são destacadas. Frases que estão conectadas a muitas outras frases na partição podem ser o centro do grafo e são mais prováveis de serem incluídas na resumo. Ambos o resumo de documentos únicos e de documentos múltiplos podem beneficiar do uso de técnicas baseadas em grafos.
Aprendizagem Automática
As técnicas de aprendizagem automática vêem o problema de resumo como um desafio de classificação. Os modelos tentam categorizar as frases em categorias de resumo e não-resumo baseado em suas características. Temos um conjunto de treinamento composto por documentos e resumos extraídos e avaliados por humanos, a partir do qual treinamos nossos algoritmos. Geralmente, isso é feito usando Naive Bayes, Árvore de Decisão ou Máquina de Apoio Vetorial.
Resumo Abstrato
Em contraste com o resumo extraído, a abstracção é um método ainda mais eficaz. A capacidade de criar frases únicas que convelem informações chave de fontes de texto contribui para esta ascensão de popularidade.
Um resumidor abstrato apresenta o material em uma forma lógica, bem organizada e gramaticalmente correta. A qualidade de um resumo pode ser substancialmente melhorada fazendo-o mais legível ou melhorando sua qualidade linguística. (inclua imagem).
Existem duas abordagens: A abordagem baseada em estrutura e a abordagem baseada em semântica.
ABORDAGEM BASEADA EM ESTRUTURA
Numa abordagem estrutural, a informação mais importante do documento é codificada usando schemas de características psicológicas como modelos, regras de extração e estruturas alternativas, incluindo árvore, ontologia, cabeçalho e corpo, regra e estrutura baseada em grafo. A seguir, vamos ler sobre algumas das muitas abordagens que são integradas nesta estratégia.
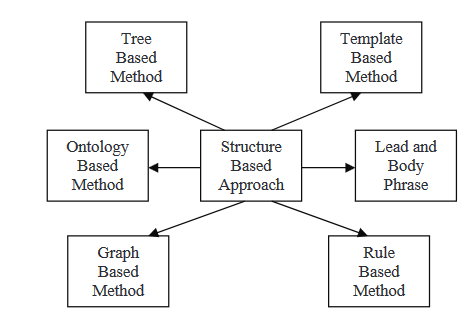
Métodos baseados em árvores
Neste método, o conteúdo de um documento é representado como uma árvore de dependências. A seleção de conteúdo para um sumário pode ser realizada através de várias outras técnicas, como um programa de algoritmo de intersecção de tópicos ou um que utilize alinhamento nativo tentativo entre frases análise. Esta abordagem emprega um gerador de linguagem ou um algoritmo associado para a geração de sumários. Neste artigo, os autores oferecem um método de fundição de sentença que usa alinhamento local múltiplo de sequências de baixo para cima para encontrar as frases de informação comum. Sistemas de resumo de multigene usam uma técnica chamada fundição de sentença.
Neste método, um conjunto de documentos é usado como entradas, processado usando um algoritmo de seleção de tópico para extrair o tópico central, e depois um algoritmo de aglomerativo é usado para classificar as frases em ordem de importância. Depois que as sentenças têm sido organizadas, elas são fundidas usando fundição de sentença, e um resumo estatístico é gerado. O método estruturado codifica as informações mais importantes do documento (s) usando esquemas de características psicológicas como modelos, regras de extração e estruturas alternativas como árvore, ontologia, cabeçalho e corpo, regra e estrutura baseada em gráfico.
Métodos baseados em modelos
Nesta abordagem, uma guia é usada para representar todo o documento. Padrões linguísticos ou critérios de extração são comparados para identificar trechos de texto que podem ser mapeados para as guias de slots. Estes trechos de texto são indicadores de unidades de área do conteúdo do esboço. Este artigo sugere dois métodos (resumo de documento único e resumo de documentos múltiplos) para o resumo de documentos. Para criar resumos e abstractos dos documentos, eles seguiram os métodos descritos em GISTEXTER.
Implementado para extração de informação, GISTEXTER é um sistema de resumo que identifica informação relacionada ao tópico no texto de entrada e a converte em entradas de banco de dados; as sentenças são então adicionadas ao resumo dependendo das solicitações do usuário.

Métodos baseados em ontologias
Muitos investigadores tentaram melhorar a eficácia das resumos usando ontologias (bases de conhecimento). A maioria dos documentos da Internet tem um domínio comum, o que significa que todos tratam do mesmo assunto geral. Uma ontologia é uma representação poderosa da estrutura de informação única de cada domínio.
Este artigo propõe o uso de uma ontologia fuzzy, que modela a incerteza e descreve com precisão o conhecimento do domínio, para resumir notícias chinesas. Neste método, os expertos do domínio primeiro definem a ontologia de domínio para eventos noticiosos, e em seguida, a fase de preparação de documentos extrai palavras semânticas do corpus noticioso e do dicionário de notícias chinesas.
Método de frase de cabeçalho e corpo
Este método envolve a reescrita da frase de cabeçalho realizando operações em frases com o mesmo pedaço de cabeça sintático no cabeçalho e corpo da frase. Usando a análise sintática de pedaços de frase, Tanaka sugeriu uma técnica para resumir notícias de rádio. Métodos de fusão de frases são usados para inferir o fundamento deste conceito.
Resumir transmissões noticiosas envolve localizar frases partilhadas pelos pedaços de capa e corpo, em seguida, inserir e substituir essas frases para produzir um resumo através da revisão de sentenças. Primeiro, um analisador sintático é aplicado aos pedaços de capa e corpo. Em seguida, são identificadas as pares de busca de gatilhos, e finalmente, as frases são alinhadas usando vários critérios de similaridade e alinhamento. A última etapa pode ser tanto uma inserção quanto uma substituição ou ambas.
O processo de inserção envolve escolher um ponto de inserção, verificar redundâncias e verificar o discurso para garantir coherencia interna, para garantir coherency e eliminar redundâncias. O passo de substituição fornece informação adicional substituindo a frase do corpo no pedaço de capa.
Método baseado em regras
Nessa técnica, os documentos a serem resumidos são representados em termos de classes e listagem de aspectos. O módulo de escolha de conteúdo seleciona o candidato mais eficaz entre aqueles gerados por regras de extração de dados para responder a um ou muitos aspectos de uma categoria. Finalmente, padrões de geração são usados para a geração de sentenças de esboço.
Para identificar substantivos e verbos relacionados semanticamente, Pierre-Etienne et al. propuseram um conjunto de critérios para extração de informação. Uma vez extraídos, os dados são enviados para a etapa de seleção de conteúdo, que tenta filtrar candidatos misturados. É usado para estrutura de frases e palavras em padrões de geração direta. Depois da geração, é executada a resumo guiado pelo conteúdo.
Métodos baseados em grafos
Muitos investigadores usam uma estrutura de dados de grafo para representar documentos de linguagem. Grafos são uma escolha popular para representar documentos na comunidade de estudos linguísticos. Cada nó no sistema representa uma unidade de palavra, que, juntamente com arestas direcionadas, define a estrutura de uma frase. Para melhorar o desempenho da Summarization, Dingding Wang et al. propuseram sistemas de resumo de vários documentos que usam uma ampla gama de estratégias, como o método baseado no centroide, o método baseado em grafo, etc., para avaliar vários métodos de base de combinação, como pontuação média, classificação média, contagem de Borda, agregação de média, etc.
Uma metodologia de consenso ponderada única é desenvolvida para coletar os resultados de diferentes estratégias de resumo. Numa abordagem baseada em semântica, uma ilustração linguística de um documento ou documentos é usada para alimentar um sistema de geração de linguagem natural (NLG). Esta técnica se destaca por identificar frases nominales e frases verbais através de dados linguísticos.
ABORDAGEM BASEADA EM SEMÂNTICA
Abordagens baseadas em semântica usam a ilustração linguística de um documento para alimentar um sistema de geração de linguagem natural (NLG). Este método processa dados linguísticos para identificar frases nominales e frases verbais.
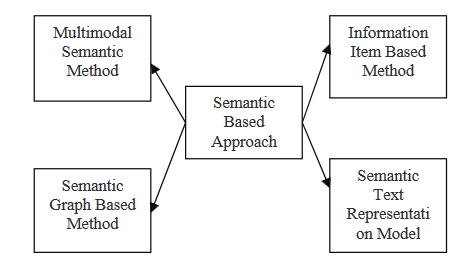
- Modelo semântico multimodal: Nesta abordagem, é criado um modelo lingüístico que captura conceitos e relações entre ideias para descrever o conteúdo de documentos multimodais, como texto e imagens. As ideias-chave são avaliadas usando vários critérios, e os conceitos selecionados são então expressos como frases para formar um resumo.
- Método baseado em itens de informação: Nesta abordagem, em vez de usar frases dos documentos de origem, é usada uma representação abstrata desses documentos para gerar o conteúdo do resumo. A representação abstrata é um item de informação, a parte mais pequena de informação coerente em um texto.
- Modelo de Grafo Semântico: Esta técnica visa resumir um documento construindo um grafo semântico rico (RSG) para o documento inicial, depois reduzindo o grafo linguístico criado e gerando o resumo abstrato final a partir do grafo linguístico reduzido.
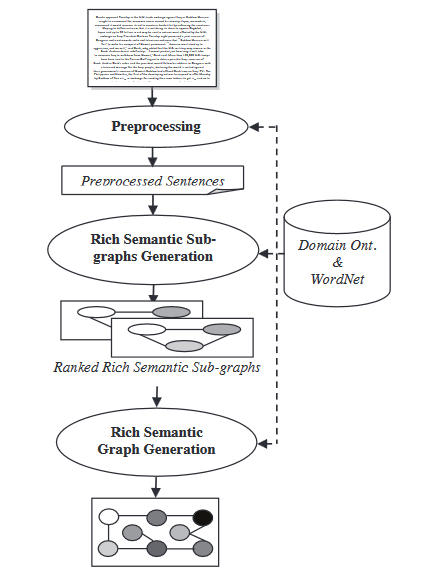
Durante o módulo de geração de Grafo Semântico Rico, uma série de regras heurísticas são aplicadas ao grafo semântico rico gerado para reduzi-lo, mesclando, excluindo ou consolidando os nós do grafo.
- Modelo de Representação Textual Semântica: Esta técnica analisa o texto de entrada usando a semântica das palavras, em vez da sintaxe/estrutura do texto.
Estudos de casos em negócios
- Programação de linguagem computacional: Foram realizados vários esforços para desenvolver tecnologia AI capaz de escrever código e desenvolver sites de forma independente. No futuro, programadores poderão ser capazes de contar com especializados “resumidores de código” para extrair os elementos essenciais de projetos inovadores.
- Ajudando as pessoas com deficiências físicas: As pessoas com dificuldades de fala podem descobrir que o resumo lhes ajuda a seguir melhor o conteúdo com o avanço da tecnologia de conversão de voz em texto.
- Conferências e outras reuniões em vídeo: Com a expansão do trabalho remoto, a capacidade de gravar ideias e conteúdo significativos de interações é cada vez mais necessária. Ficaria fantástico se as sessões de equipe pudessem ser resumidas usando um método de conversão de voz em texto.
- A Busca por Patentes: Encontrar informações de patentes relevantes pode ser tempo-consumindo. Um gerador de resumo de patentes poderia poupar tempo, quer você esteja fazendo pesquisa de inteligência de mercado ou preparando para registrar uma nova patente.
- Livros e literatura: Os resumos são úteis porque dão aos leitores uma visão geral concisa do conteúdo que podem esperar de um livro antes de decidir se comprá-lo.
- Publicidade através de mídias sociais: Organizações que criam relatórios brancos, e-books e blogs da empresa podem usar o resumo para tornar seu trabalho mais digerível e compartilhável em plataformas como Twitter e Facebook.
- Pesquisa econômica: A indústria de bancos de investimento investe grandes quantidades de dinheiro em aquisição de dados para uso em decisões, como negociação de ações por computador. qualquer analista financeiro que passa todo dia a analisar dados de mercado e notícias eventualmente atingirá o excesso de informação. documentos financeiros, como relatórios de resultados e notícias financeiras, poderiam beneficiar de sistemas de resumo que permitam aos analistas extrair sinais de mercado do conteúdo rapidamente.
- Divulgação de seu negócio usando Otimização para Pesquisa de Engines: Avaliações de Otimização para Pesquisa de Engines (SEO) precisam de um conhecimento aprofundado dos tópicos discutidos no conteúdo dos concorrentes. É de suma importância considerando as modificações recentes no algoritmo do Google e o subsequente foco na autoridade do assunto. A capacidade de resumir rapidamente vários documentos, identificar comuns e procurar informações chave pode ser uma ferramenta de pesquisa poderosa.
Conclusão
Embora o resumo abstrato seja menos confiável do que os métodos extraíveis, ele apresenta mais promessas para a produção de resumos que se ajustam à maneira como os seres humanos os escreveriam. Como resultado, é provável que surjam uma variedade de novas técnicas computacionais, cognitivas e linguísticas neste campo.
Referências
Source:
https://www.digitalocean.com/community/tutorials/extractive-and-abstractive-summarization-techniques