













A loja de recursos de Aprendizado de Máquina (ML) tem atraído atenção e uso para aplicações críticas de negócios desde que a Uber introduziu o conceito com Michelangelo em 2017. Neste post de blog, vamos nos aprofundar nos fundamentos das lojas de recursos ML e explorar por que e como o ScyllaDB pode ser uma parte crítica da sua arquitetura de loja de recursos.
Para entender o que são lojas de recursos, é importante primeiro entender o que recursos são.
O que é um Recurso?
No Aprendizado de Máquina, um recurso é um conjunto de pontos de dados que podem ser usados para treinar um modelo e fazer previsões sobre o futuro com base em dados históricos. Por exemplo, nosso aplicativo de exemplo de loja de recursos permite fazer previsões sobre atrasos de vôos com base em registros históricos de vôos.
Os recursos são o resultado de pipelines complexos de processamentos e transformações de dados. Quantidades enormes de dados de recursos permitem previsões precisas e projetos de aprendizado de máquina bem-sucedidos.
O que é uma Loja de Recursos?
A feature store is a central database in your machine-learning architecture that contains your real-time and historical features. Feature stores allow your data engineers and data scientists to use the same central repository to discover, monitor, and analyze features.
What does a feature store architecture look like?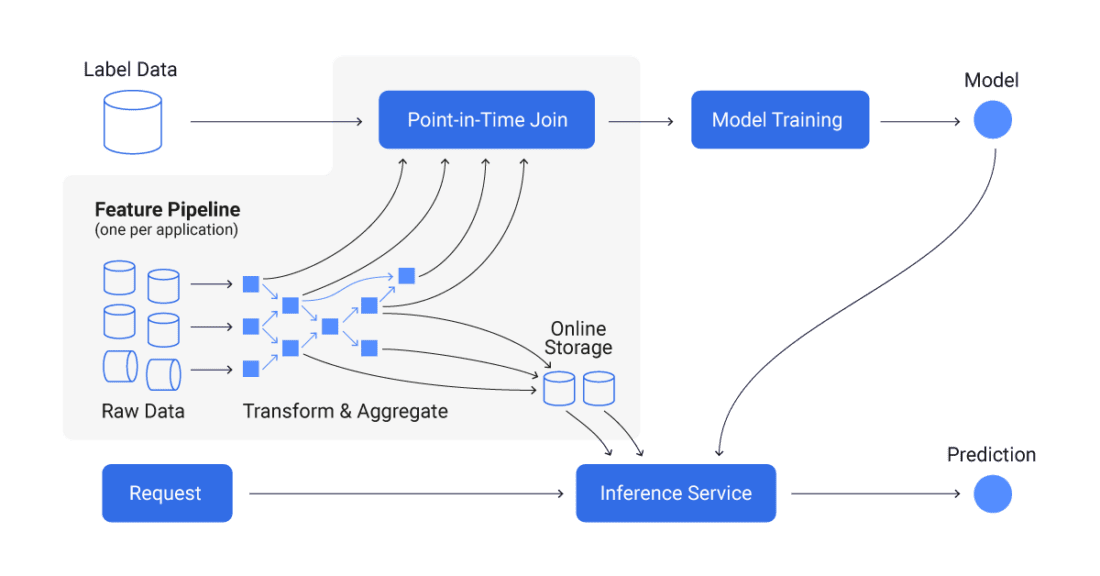
Bancos de Dados Online e Offline na Loja de Recursos
Ao falarmos de lojas de recursos, os usuários geralmente diferenciam entre dois tipos de bancos de dados em sua arquitetura. Por um lado, utilizam um banco de dados online, e por outro, também podem ter um banco de dados offline. Esses bancos de dados têm propósitos diferentes.
Banco de dados offline: Este tipo de banco de dados armazena características processadas historicamente, geralmente ingeridas em lotes. Os bancos de dados offline possuem dados de características que abrangem um grande período de tempo do passado; portanto, são úteis para trabalhar com um conjunto de características em um período específico da história.
Banco de dados online: Este banco de dados pode conter dados de fluxos de dados em tempo real e do banco de dados offline também. O armazenamento online é usado para servir ao modelo de produção e outras aplicações em tempo real com os dados de características mais atualizados. Performance e baixa latência são realmente importantes aqui. Se seu banco de dados não for capaz de entregar características em tempo real com rapidez suficiente, então seu modelo pode usar dados desatualizados ou imprecisos para fazer previsões.
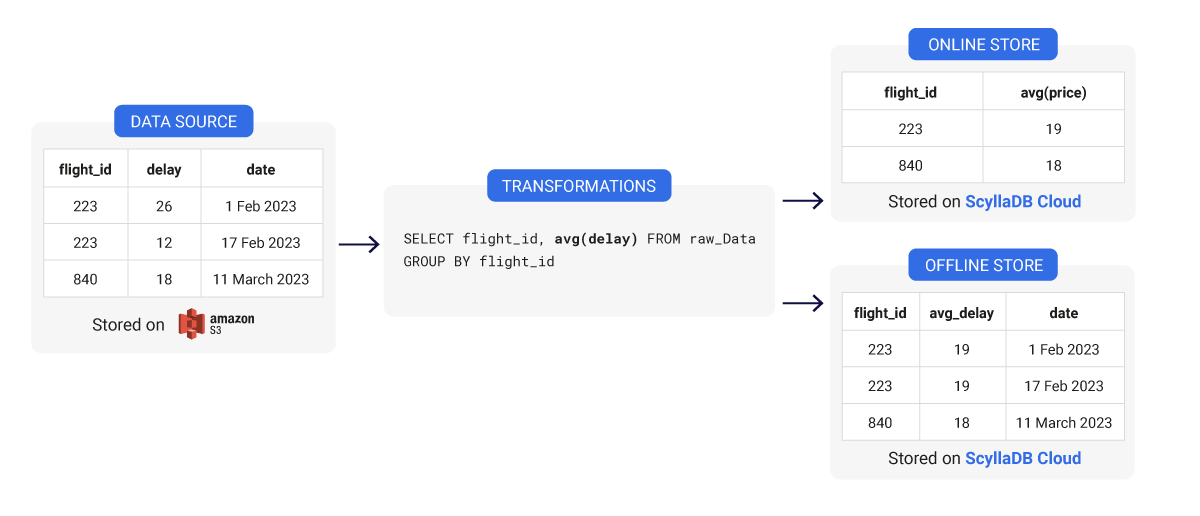
Modelagem de Dados da Feature Store: Design de Tabela Larga vs. Estreita
Ao projetar o modelo de dados dentro de sua feature store, seja ela offline ou online, você pode optar entre dois tipos de designs de tabela: largo e estreito. Cada um tem seus próprios benefícios e desvantagens. Vamos ver exemplos reais para ambos e por que eles podem ou não ser os melhores para o seu caso de uso:
Design de Tabela Larga
O design de tabela larga inclui colunas separadas para cada característica. Quanto mais tipos de características você deseja armazenar na tabela, mais colunas você terá que criar.
Exemplo de Layout de Tabela Larga
| create table feature_store.wide_example( | |
| date TIMESTAMP, | |
| feature_id INT, | |
| feature_col1 FLOAT, | |
| feature_col2 FLOAT, | |
| feature_col3 FLOAT, | |
| feature_col4 FLOAT, | |
| feature_col5 FLOAT, | |
| feature_col6 FLOAT, | |
| feature_col7 FLOAT | |
| ) |
Este tipo de layout pode ser fácil de começar, mas também se torna mais complicado de manter ao longo do tempo e difícil de fazer alterações. Sempre que você deseja introduzir uma nova característica (ou descartar uma existente), você precisa modificar o esquema, o que pode ser complicado.
Design de Tabela Estreita
Projetos de tabelas estreitas são simples e mais fáceis de manter. Isso ocorre porque o número de colunas não está destinado a aumentar ou diminuir no futuro, mesmo que você adicione ou remova recursos.
Exemplo de Layout de Tabela Estreita
| create table feature_store.narrow_example( | |
| feature_id INT, | |
| feature_name TEXT, | |
| feature_value FLOAT | |
| ) |
Usando este layout, você pode se dar ao luxo de usar apenas duas colunas fixas a longo prazo para armazenar recursos. Uma para o nome do recurso (por exemplo, LATE_AIRCRAFT_DELAY) e outra para o valor desse recurso.
Em geral, tabelas estreitas podem exigir a conversão dos tipos de dados ao recuperar dados, pois não estão na forma correta (por exemplo, o tipo de coluna é FLOAT, mas, na realidade, o valor dos dados é um INTEGER. Felizmente, quando falamos de lojas de recursos, lojas online e offline já têm os dados em formato limpo de número (FLOAT) adequado, e todos os valores têm o mesmo tipo de dados, o que significa que isso não é uma desvantagem no caso de lojas de recursos.
O que é o ScyllaDB e como pode ser usado na sua arquitetura de loja de recursos?
Para que as equipes de aprendizado de máquina construam aplicativos de inferência em tempo real, elas precisam de bancos de dados que possam retornar recursos em escala com baixa latência. O ScyllaDB é um banco de dados NoSQL de alto desempenho e baixa latência que pode lidar com altos volumes de operações de leitura e escrita. Além disso, o ScyllaDB é um banco de dados confiável para cargas de trabalho críticas de loja de recursos em empresas como GE Healthcare ou ShareChat. Devido à sua alta disponibilidade e tolerância a falhas, ele pode fazer o trabalho pesado em sua infraestrutura onde desempenho e confiabilidade são importantes.
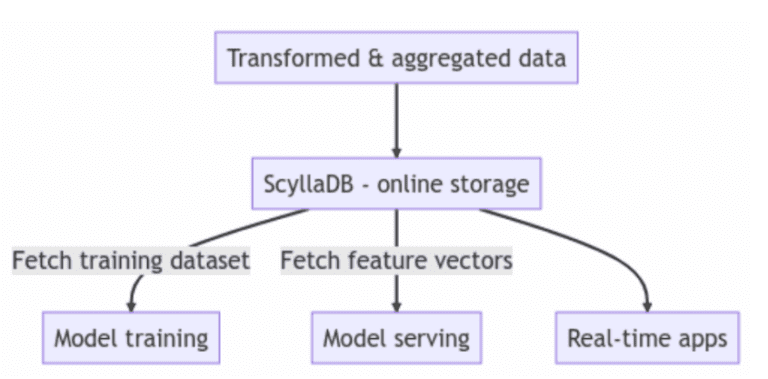
Além de utilizar o ScyllaDB como a loja online em sua arquitetura de feature store, o ScyllaDB também é usado como uma solução de armazenamento híbrido online/offline. Com essa abordagem, você pode reduzir a carga de manutenção em sua equipe, tendo um único banco de dados para atender a todas as cargas de trabalho de sua feature store.
Os usuários frequentemente colocam o ScyllaDB no centro de sua arquitetura para persistir e recuperar features e metadados da feature store. Neste caso, o ScyllaDB atua como uma loja online. Outros usuários também utilizam o ScyllaDB como seu armazenamento híbrido online/offline. O desempenho é um requisito chave para acelerar o desenvolvimento de modelos, e o desempenho de leitura e escrita do ScyllaDB consistentemente atende ou supera as expectativas dos usuários.
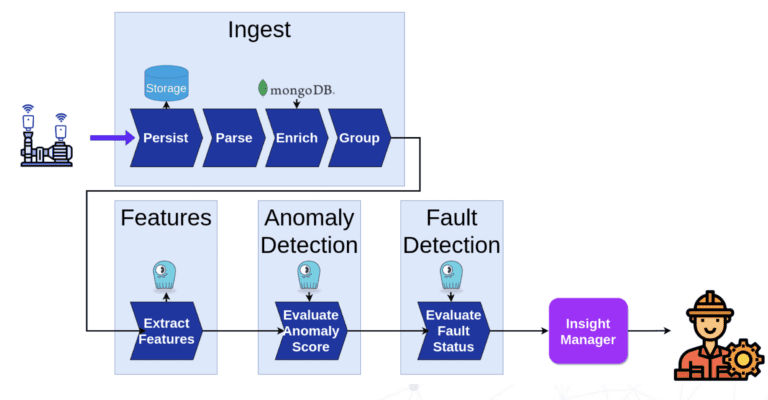
De fato, alguns usuários descobriram que o ScyllaDB poderia substituir vários bancos de dados e servir como uma única loja central para todas as suas necessidades de dados de machine learning. Por exemplo, o ScyllaDB pode substituir o Redis (loja online) e o PostgreSQL (loja offline) — tornando a manutenção de infraestrutura menos dispendiosa e mais simples.
O ScyllaDB brilha em casos de uso onde você requer baixa latência e alto desempenho. Além disso, o ScyllaDB é compatível com Cassandra e DynamoDB, o que significa que se você já utiliza um desses bancos de dados, pode migrar sem problemas sem precisar alterar suas consultas.
Tutorial: Loja Online ScyllaDB
Para ajudá-lo a começar com o ScyllaDB como sua loja online, criamos uma aplicação de exemplo (também disponível no GitHub).
- Clone o repositório
- Inscreva-se no ScyllaDB Cloud ou instale o ScyllaDB localmente
- Crie o esquema:
cqlsh “node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud” 9042 -u scylla -p “password” -f schema.cql - Conecte-se ao instância com cqlsh e importe um conjunto de dados de amostra
cqlsh “node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud” 9042 -u scylla -p “password” scylla@cqlsh> COPY feature_store.flight_features FROM ‘flight_features.csv’;
Este comando ingere um conjunto de dados de voo de amostra:
| op_carrier_fl_num|actual_elapsed_time|air_time|arr_delay|arr_time|cancellation_code|cancelled|carrier_delay|crs_arr_time|crs_dep_time|crs_elapsed_time|dep_delay|dep_time|dest|distance|diverted|fl_date |late_aircraft_delay|nas_delay|op_carrier|origin|security_delay|taxi_in|taxi_out|weather_delay|wheels_off|wheels_on| | |
| —————–+——————-+——–+———+——–+—————–+———+————-+————+————+—————-+———+——–+—-+——–+——–+——————-+——————-+———+———-+——+————–+——-+——–+————-+———-+———+ | |
| 4317| 96.0| 73.0| -19.0| 2113.0| | 0.0| | 2132| 2040| 112.0| -3.0| 2037.0|MLI | 373.0| 0.0|2018-12-31 02:00:00| | |OO |DTW | | 5.0| 18.0| | 2055.0| 2108.0| | |
| 3372| 94.0| 74.0| 81.0| 1500.0| | 0.0| 0.0| 1339| 1150| 109.0| 96.0| 1326.0|RNO | 564.0| 0.0|2018-12-31 02:00:00| 81.0| 0.0|OO |SEA | 0.0| 3.0| 17.0| 0.0| 1343.0| 1457.0| | |
| 1584| 385.0| 348.0| -21.0| 2023.0| | 0.0| | 2034| 1700| 394.0| -9.0| 1658.0|SFO | 2565.0| 0.0|2018-12-31 02:00:00| | |UA |EWR | | 13.0| 33.0| | 1731.0| 2019.0| | |
| 4830| 119.0| 85.0| -35.0| 1431.0| | 0.0| | 1437| 1245| 136.0| -13.0| 1232.0|MSP | 546.0| 0.0|2018-12-31 02:00:00| | |OO |MSP | | 16.0| 18.0| | 1250.0| 1415.0| | |
| 2731| 158.0| 146.0| -19.0| 1911.0| | 0.0| | 1930| 1800| 160.0| -8.0| 1800.0|MSP | 842.0| 0.0|2018-12-31 02:00:00| | |WN |PVD | | 7.0| 7.0| | 1807.0| 1904.0| |
view rawgistfile1.txt hosted with ❤ by GitHub.
ScyllaDB + Feast
O ScyllaDB também se integra a ferramentas de armazenamento de recursos como Feast. Feast é uma loja de recursos open-source popular para ML de produção. Você pode usar vários bancos de dados como sua loja de recursos online ao usar o Feast, incluindo o ScyllaDB.
Para configurar o ScyllaDB como uma loja online do Feast, você precisa editar o arquivo de configuração do Feast e adicionar suas credenciais do ScyllaDB. O ScyllaDB é compatível com Cassandra, portanto, você pode usar o conector Cassandra interno do Feast.
| # feature_store.yaml | |
| project: scylla_feature_repo | |
| registry: data/registry.db | |
| provider: local | |
| online_store: | |
| type: cassandra | |
| hosts: | |
| – node-0.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| – node-1.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| – node-2.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| keyspace: feast | |
| username: scylla | |
| password: password |
view rawgistfile1.txt hosted with ❤ by GitHub.
Conclusão
Lojas de recursos são necessárias para engenharia de recursos e construção de modelos de aprendizado de máquina. Se você está construindo uma infraestrutura de loja de recursos em tempo real, é preciso considerar cuidadosamente o desempenho. Requisitos de baixa latência, alto desempenho e alta taxa de transferência tornam os bancos de dados NoSQL um candidato perfeito como solução de armazenamento online em sua loja de recursos.
Source:
https://dzone.com/articles/tutorial-whats-an-aiml-feature-store-and-how-to-bu