













Introdução
Neste artigo, iremos construir uma das primeiras redes neurais convolucionais já apresentadas, a LeNet5. Estaremos construindo esta CNN do zero em PyTorch e verá como ela se comporta the um conjunto de dados do mundo real.
Vamos começar explorando a arquitetura da LeNet5. Em seguida, carregaremos e analisaremos o nosso conjunto de dados, o MNIST, usando a classe fornecida do torchvision. Usando o PyTorch, construiremos nossa LeNet5 do zero e a treinaremos com nossos dados. Finalmente, veremos o desempenho do modelo em dados de teste não vistos.
Pré-requisitos
O conhecimento de redes neurais será útil para entender este artigo. Isso significa estar familiarizado com as diferentes camadas de redes neurais (camada de entrada, camadas ocultas, camada de saída), funções de ativação, algoritmos de otimização (variações do descida de gradiente), funções de perda, etc. Adicionalmente, a familiaridade com a sintaxe do Python e com a biblioteca PyTorch é essencial para entender os exemplos de código apresentados neste artigo.
Um entendimento de RNNs é também recomendado. Isso inclui o conhecimento de camadas de convolução, camadas de pooling e seu papel na extração de recursos de dados de entrada. O entendimento de conceitos como stride, padding e o impacto do tamanho do kernel/filtro é benefício.
LeNet5
LeNet5 foi usado para a reconhecimento de caracteres entregues à mão e foi proposto por Yann LeCun e outros em 1998 com o artigo,Gradient-Based Learning Applied to Document Recognition.
Vamos entender a arquitetura de LeNet5 conforme mostrado na figura abaixo:
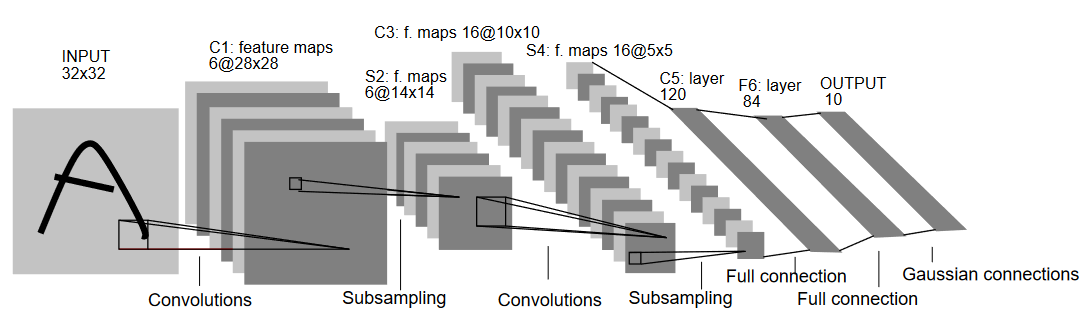
Como o nome indica, LeNet5 tem 5 camadas com duas camadas de convolução e três camadas totalmente conectadas. Vamos começar com a entrada. LeNet5 aceita como entrada uma imagem em escala de cinza de 32×32, o que indica que a arquitetura não é adequada para imagens RGB (múltiplos canais). Portanto, a imagem de entrada deve conter apenas um canal. Depois disto, começamos com nossas camadas de convolução
A primeira camada de convolução tem um tamanho de filtro de 5×5 com 6 filtros desse tamanho. Isso reduzirá a largura e a altura da imagem enquanto aumenta a profundidade (número de canais). A saída seria de 28x28x6. Depois disso, a pooling é aplicada para diminuir o mapa de recursos por metade, ou seja, 14x14x6. O mesmo tamanho de filtro (5×5) com 16 filtros é agora aplicado ao resultado seguido por uma camada de pooling. Isto reduz o mapa de recursos de saída para 5x5x16.
Depois disto, uma camada convolucional de tamanho 5×5 com 120 filtros é aplicada para tornar a feature map plana em 120 valores. Então vem a primeira camada totalmente conectada, com 84 neurônios. Finalmente, temos a camada de saída, que tem 10 neurônios de saída, pois os dados MNIST têm 10 classes para cada um dos 10 números digitais representados.
Carregando Dados
Vamos começar carregando e analisando os dados. Vamos usar o conjunto de dados MNIST. O conjunto de dados MNIST contém imagens de números digitais escritos à mão. As imagens são em escala de cinza, todas com o tamanho de 28×28, e é composto por 60.000 imagens de treinamento e 10.000 imagens de teste.
Você pode ver alguns exemplos das imagens abaixo:

Importando as Bibliotecas
Vamos começar importando as bibliotecas necessárias e definindo algumas variáveis (hipérparametros e device também são detalhados para ajudar o pacote a decidir se treinar com GPU ou CPU):
# Carregue as bibliotecas relevantes e use aliases apropriados quando necessário
import torch
import torch.nn as nn
import torchvision
import torchvision.transforms as transforms
# Defina variáveis relevantes para a tarefa de ML
batch_size = 64
num_classes = 10
learning_rate = 0.001
num_epochs = 10
# O dispositivo decidirá se a execução do treinamento deve ser feita com GPU ou CPU.
device = torch.device('cuda' if torch.cuda.is_available() else 'cpu')
Carregando e Transformando os Dados
Usando o torchvision, vamos carregar o conjunto de dados, pois isso nos permitirá realizar qualquer etapa de pré-processamento com facilidade.
#Carregando o conjunto de dados e pré-processamento
train_dataset = torchvision.datasets.MNIST(root = './data',
train = True,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1307,), std = (0.3081,))]),
download = True)
test_dataset = torchvision.datasets.MNIST(root = './data',
train = False,
transform = transforms.Compose([
transforms.Resize((32,32)),
transforms.ToTensor(),
transforms.Normalize(mean = (0.1325,), std = (0.3105,))]),
download=True)
train_loader = torch.utils.data.DataLoader(dataset = train_dataset,
batch_size = batch_size,
shuffle = True)
test_loader = torch.utils.data.DataLoader(dataset = test_dataset,
batch_size = batch_size,
shuffle = True)
Vamos entender o código:
- Primeiro, os dados MNIST não podem ser usados como são para a arquitetura LeNet5. A arquitetura LeNet5 aceita a entrada como 32×32 e as imagens MNIST são 28×28. Podemos corrigir isso redimensionando as imagens, normalizando-as usando a média e a desvio padrão pré-calculados (disponíveis online) e, finalmente, armazenando-as como tensores.
- Nós definimos
download=Truecaso os dados ainda não estejam baixados. - A seguir, nós fazemos uso de carregadores de dados. Isto pode não afetar o desempenho no caso de um conjunto de dados pequeno como o MNIST, mas pode realmente impedir o desempenho no caso de grandes conjuntos de dados e é considerado uma boa prática em geral. Os carregadores de dados nos permitem iterar pelos dados em lotes, e o dado é carregado enquanto iteramos e não de uma só vez no início.
- Nós especificamos o tamanho do lote e embaralhamos o conjunto de dados ao carregar para que cada lote tenha alguma variação nos tipos de rótulos que tem. Isso aumentará a eficácia de nossa modelo eventual.
LeNet5 de Raiz
Vamos primeiro olhar para o código:
# Definindo a rede neural convolucional
class LeNet5(nn.Module):
def __init__(self, num_classes):
super(ConvNeuralNet, self).__init__()
self.layer1 = nn.Sequential(
nn.Conv2d(1, 6, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(6),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.layer2 = nn.Sequential(
nn.Conv2d(6, 16, kernel_size=5, stride=1, padding=0),
nn.BatchNorm2d(16),
nn.ReLU(),
nn.MaxPool2d(kernel_size = 2, stride = 2))
self.fc = nn.Linear(400, 120)
self.relu = nn.ReLU()
self.fc1 = nn.Linear(120, 84)
self.relu1 = nn.ReLU()
self.fc2 = nn.Linear(84, num_classes)
def forward(self, x):
out = self.layer1(x)
out = self.layer2(out)
out = out.reshape(out.size(0), -1)
out = self.fc(out)
out = self.relu(out)
out = self.fc1(out)
out = self.relu1(out)
out = self.fc2(out)
return out
Definindo o Modelo LeNet5
Eu explicarei o código linearmente:
- Em PyTorch, definimos uma rede neural criando uma classe que herda de
nn.Modulepois contém muitos dos métodos que precisaremos de usar. - Existem duas etapas principais depois disso. A primeira é inicializar as camadas que vamos usar em nossa CNN dentro de
__init__, e a outra é definir a sequência na qual essas camadas processarão a imagem. Isto é definido dentro da funçãoforward. - Para a arquitetura em si, primeiro definimos as camadas convolucionais usando a função
nn.Conv2Dcom o tamanho de kernel apropriado e os canais de entrada/saída. Também aplicamos o max pooling usando a funçãonn.MaxPool2D. O que é legal em PyTorch é que podemos combinar a camada convolucional, função de ativação e max pooling em uma camada única (elas serão aplicadas separadamente, mas ajuda com a organização) usando a funçãonn.Sequential. - Definimos então as camadas totalmente conectadas. Observe que nós podemos usar
nn.Sequentialaqui também e combinar as funções de ativação e as camadas lineares, mas eu quis mostrar que qualquer uma é possível. - Finalmente, nossa última camada sai com 10 neuronios, que são nossas previsões finais para os dígitos.
Definindo Hiperparâmetros
Antes da treinamento, precisamos definir alguns hiperparâmetros, como a função de perda e o otimizador a ser usado.
model = LeNet5(num_classes).to(device)
#Definindo a função de perda
cost = nn.CrossEntropyLoss()
#Definindo o otimizador com os parâmetros do modelo e a taxa de aprendizagem
optimizer = torch.optim.Adam(model.parameters(), lr=learning_rate)
#isto está definido para imprimir quantos passos restam durante o treinamento
total_step = len(train_loader)
Nós começamos inicializando nosso modelo usando o número de classes como um argumento, o que neste caso é 10. Então definimos nossa função de custo como perda de entropia cruzada e o otimizador como Adam. Existem muitas escolhas para estes, mas essas tendem a dar bons resultados com o modelo e os dados dados. Finalmente, definimos total_step para manter melhor o rastreamento dos passos durante o treinamento.
Treinamento do Modelo
Agora, podemos treinar nosso modelo:
total_step = len(train_loader)
for epoch in range(num_epochs):
for i, (images, labels) in enumerate(train_loader):
images = images.to(device)
labels = labels.to(device)
#Passo de frente
outputs = model(images)
loss = cost(outputs, labels)
#Volta e otimiza
optimizer.zero_grad()
loss.backward()
optimizer.step()
if (i+1) % 400 == 0:
print ('Epoch [{}/{}], Step [{}/{}], Loss: {:.4f}'
.format(epoch+1, num_epochs, i+1, total_step, loss.item()))
Vamos ver o que o código faz:
- COMEÇAMOS por iterar através do número de épocas e, em seguida, as_batches em nossos dados de treinamento.
- Convertemos as imagens e as etiquetas de acordo com o dispositivo que estamos usando, ou seja, GPU ou CPU.
- Na passagem para frente, fazemos previsões usando nosso modelo e calculamos a perda com base nessas previsões e nossas etiquetas reais.
- Em seguida, fazemos a passagem para trás, onde realmente atualizamos nossos pesos para melhorar nosso modelo
- Antes de cada atualização, definimos os gradientes como zero usando a função
optimizer.zero_grad(). - Então, calculamos os novos gradientes usando a função
loss.backward(). - E finalmente, atualizamos os pesos com a função
optimizer.step().
Podemos ver a saída como segue:
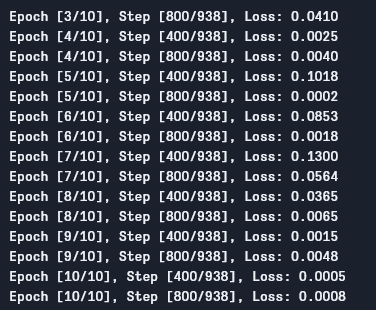
Como podemos ver, a perda está diminuindo a cada época, o que mostra que nosso modelo realmente está aprendendo. Note que essa perda é no conjunto de treinamento, e se a perda for muito pequena (como é no nosso caso), pode indicar sobreajuste. Existem várias maneiras de resolver esse problema, como regularização, aumento de dados, e assim por diante, mas não entraremos nisso neste artigo. Vamos agora testar nosso modelo para ver como ele se sai.
Teste do Modelo
Agora vamos testar nosso modelo:
# Testar o modelo
# Na fase de teste, não precisamos calcular gradientes (para eficiência de memória)
with torch.no_grad():
correct = 0
total = 0
for images, labels in test_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
print('Accuracy of the network on the 10000 test images: {} %'.format(100 * correct / total))
Como podem ver, o código não é muito diferente do usado para treinamento. A única diferença é que nós não estamos calculando gradientes (usando with torch.no_grad()), e também não estamos calculando a perda, pois não precisamos de backpropagation aqui. Para calcular a acurácia resultante do modelo, podemos simplesmente calcular o número total de predições corretas sobre o número total de imagens.
Usando este modelo, obtemos uma acurácia de cerca de 98,8%, o que é muito bom:

Acurácia de Teste
Observe que o conjunto de dados MNIST é bem básico e pequeno, comparado aos padrões de hoje, e é difícil obter resultados semelhantes em outros conjuntos de dados. Conforme é um bom ponto de partida para aprender deep learning e CNNs.
Conclusão
Vamos agora concluir o que fizemos neste artigo:
- Começamos aprendendo a arquitetura de LeNet5 e os diferentes tipos de camadas nele.
- Em seguida, exploramos o conjunto de dados MNIST e carregamos os dados usando
torchvision. - Depois, construímos LeNet5 do zero, juntamente com a definição de hipérparametros para o modelo.
- Finalmente, treinamos e testamos o nosso modelo no conjunto de dados MNIST, e o modelo pareceu funcionar bem no conjunto de testes.
Trabalho Futuro
Embora isso seja uma ótima introdução ao aprendizado profundo no PyTorch, você pode estender esse trabalho para aprender mais também:
- Você pode tentar usar diferentes conjuntos de dados, mas para esse modelo você precisará de conjuntos de dados em escala de cinza. Um desses conjuntos de dados é o FashionMNIST.
- Você pode experimentar com diferentes hiperparâmetros e ver a melhor combinação deles para o modelo.
- Finalmente, você pode tentar adicionar ou remover camadas do conjunto de dados para ver seu impacto na capacidade do modelo.
Source:
https://www.digitalocean.com/community/tutorials/writing-lenet5-from-scratch-in-python