













Módulo Python Pandas
- O Pandas é uma biblioteca de código aberto em Python. Ele fornece estruturas de dados de alto desempenho prontas para uso e ferramentas de análise de dados.
- O módulo Pandas é executado sobre o NumPy e é popularmente utilizado para ciência de dados e análise de dados.
- O NumPy é uma estrutura de dados de baixo nível que suporta matrizes multidimensionais e uma ampla gama de operações matemáticas em arrays. O Pandas possui uma interface de nível mais alto. Ele também fornece alinhamento simplificado de dados tabulares e funcionalidade poderosa de séries temporais.
- O DataFrame é a estrutura de dados chave no Pandas. Ele nos permite armazenar e manipular dados tabulares como uma estrutura de dados 2-D.
- O Pandas fornece um conjunto de recursos rico no DataFrame. Por exemplo, alinhamento de dados, estatísticas de dados, fatias, agrupamento, mesclagem, concatenação de dados, etc.
Instalando e Começando com Pandas
Você precisa ter o Python 2.7 ou superior para instalar o módulo Pandas. Se estiver usando o conda, então você pode instalá-lo usando o comando abaixo.
conda install pandas
Se você estiver usando o PIP, execute o comando abaixo para instalar o módulo pandas.
pip3.7 install pandas
Para importar Pandas e NumPy no seu script Python, adicione o trecho de código abaixo:
import pandas as pd
import numpy as np
Como o Pandas depende da biblioteca NumPy, precisamos importar essa dependência.
Estruturas de Dados no módulo Pandas
Há 3 estruturas de dados fornecidas pelo módulo Pandas, que são as seguintes:
- Série: É uma estrutura de array imutável de tamanho 1-D, semelhante a um array, com dados homogêneos.
- DataFrames: É uma estrutura tabular mutável de tamanho 2-D com colunas de tipos heterogêneos.
- Panel: É um array mutável de tamanho 3-D.
DataFrame Pandas
O DataFrame é a estrutura de dados mais importante e amplamente utilizada, sendo uma maneira padrão de armazenar dados. O DataFrame tem dados alinhados em linhas e colunas, como uma tabela SQL ou um banco de dados de planilha. Podemos tanto codificar dados diretamente em um DataFrame quanto importar um arquivo CSV, arquivo tsv, arquivo Excel, tabela SQL, etc. Podemos usar o construtor abaixo para criar um objeto DataFrame.
pandas.DataFrame(data, index, columns, dtype, copy)
Aqui está uma breve descrição dos parâmetros:
- dados – cria um objeto DataFrame a partir dos dados de entrada. Pode ser uma lista, dicionário, série, ndarrays do Numpy ou até mesmo outro DataFrame.
- índice – possui os rótulos das linhas
- colunas – usadas para criar rótulos de colunas
- dtype – usado para especificar o tipo de dados de cada coluna, parâmetro opcional
- cópia – usado para copiar dados, se houver
Há muitas maneiras de criar um DataFrame. Podemos criar um objeto DataFrame a partir de Dicionários ou lista de dicionários. Também podemos criá-lo a partir de uma lista de tuplas, CSV, arquivo Excel, etc. Vamos executar um código simples para criar um DataFrame a partir da lista de dicionários.
import pandas as pd
import numpy as np
df = pd.DataFrame({
"State": ['Andhra Pradesh', 'Maharashtra', 'Karnataka', 'Kerala', 'Tamil Nadu'],
"Capital": ['Hyderabad', 'Mumbai', 'Bengaluru', 'Trivandrum', 'Chennai'],
"Literacy %": [89, 77, 82, 97,85],
"Avg High Temp(c)": [33, 30, 29, 31, 32 ]
})
print(df)
Saída:  O primeiro passo é criar um dicionário. O segundo passo é passar o dicionário como argumento no método DataFrame(). O passo final é imprimir o DataFrame. Como você pode ver, o DataFrame pode ser comparado a uma tabela com valores heterogêneos. Além disso, o tamanho do DataFrame pode ser modificado. Nós fornecemos os dados na forma do mapa e as chaves do mapa são consideradas pelo Pandas como os rótulos das linhas. O índice é exibido na coluna mais à esquerda e possui os rótulos das linhas. O cabeçalho da coluna e os dados são exibidos de maneira tabular. Também é possível criar DataFrames indexados. Isso pode ser feito configurando o parâmetro de índice no método
O primeiro passo é criar um dicionário. O segundo passo é passar o dicionário como argumento no método DataFrame(). O passo final é imprimir o DataFrame. Como você pode ver, o DataFrame pode ser comparado a uma tabela com valores heterogêneos. Além disso, o tamanho do DataFrame pode ser modificado. Nós fornecemos os dados na forma do mapa e as chaves do mapa são consideradas pelo Pandas como os rótulos das linhas. O índice é exibido na coluna mais à esquerda e possui os rótulos das linhas. O cabeçalho da coluna e os dados são exibidos de maneira tabular. Também é possível criar DataFrames indexados. Isso pode ser feito configurando o parâmetro de índice no método DataFrame().
Importando dados de CSV para DataFrame
Também podemos criar um DataFrame importando um arquivo CSV. Um arquivo CSV é um arquivo de texto com um registro de dados por linha. Os valores dentro do registro são separados usando o caractere “vírgula”. O Pandas fornece um método útil, chamado read_csv(), para ler o conteúdo do arquivo CSV em um DataFrame. Por exemplo, podemos criar um arquivo chamado ‘cidades.csv’ contendo detalhes das cidades indianas. O arquivo CSV é armazenado no mesmo diretório que contém os scripts Python. Este arquivo pode ser importado usando:
import pandas as pd
data = pd.read_csv('cities.csv')
print(data)
. Nosso objetivo é carregar dados e analisá-los para tirar conclusões. Portanto, podemos usar qualquer método conveniente para carregar os dados. Neste tutorial, estamos codificando os dados do DataFrame.
Inspeção de dados no DataFrame
Executando o DataFrame usando seu nome exibe a tabela inteira. Em tempo real, os conjuntos de dados para análise terão milhares de linhas. Para analisar dados, precisamos inspecionar dados de volumes enormes de conjuntos de dados. O Pandas fornece muitas funções úteis para inspecionar apenas os dados de que precisamos. Podemos usar df.head(n) para obter as primeiras n linhas ou df.tail(n) para imprimir as últimas n linhas. Por exemplo, o código abaixo imprime as primeiras 2 linhas e a última 1 linha do DataFrame.
print(df.head(2))
Output: 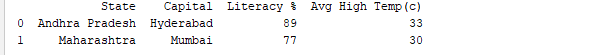
print(df.tail(1))
Output: 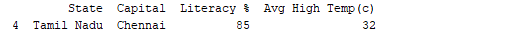 Da mesma forma,
Da mesma forma, print(df.dtypes) imprime os tipos de dados. Output: 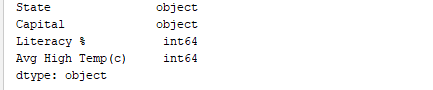
print(df.index) imprime o índice. Output: 
print(df.columns) imprime as colunas do DataFrame. Output: 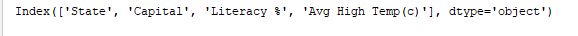
print(df.values) exibe os valores da tabela. Output: 
1. Obtendo resumo estatístico dos registros
Podemos obter um resumo estatístico (contagem, média, desvio padrão, mínimo, máximo etc.) dos dados usando a função df.describe(). Agora, vamos usar essa função para exibir o resumo estatístico da coluna “Literacy %”. Para fazer isso, podemos adicionar o seguinte trecho de código:
print(df['Literacy %'].describe())
Resultado: 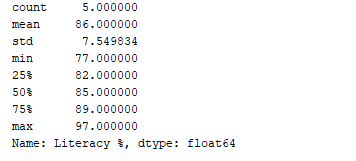 A função
A função df.describe() exibe o resumo estatístico, juntamente com o tipo de dados.
2. Ordenando registros
Podemos ordenar registros por qualquer coluna usando a função df.sort_values(). Por exemplo, vamos ordenar a coluna “Literacy %” em ordem decrescente.
print(df.sort_values('Literacy %', ascending=False))
Resultado: 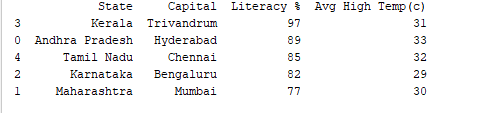
3. Fatiação de registros
É possível extrair dados de uma coluna específica, usando o nome da coluna. Por exemplo, para extrair a coluna ‘Capital’, usamos:
df['Capital']
ou
(df.Capital)
Saída:  Também é possível fatiar várias colunas. Isso é feito ao incluir múltiplos nomes de colunas entre 2 colchetes, com os nomes das colunas separados por vírgulas. O código a seguir fatia as colunas ‘Estado’ e ‘Capital’ do DataFrame.
Também é possível fatiar várias colunas. Isso é feito ao incluir múltiplos nomes de colunas entre 2 colchetes, com os nomes das colunas separados por vírgulas. O código a seguir fatia as colunas ‘Estado’ e ‘Capital’ do DataFrame.
print(df[['State', 'Capital']])
Saída:  Também é possível fatiar linhas. Múltiplas linhas podem ser selecionadas usando o operador “:”. O código abaixo retorna as primeiras 3 linhas.
Também é possível fatiar linhas. Múltiplas linhas podem ser selecionadas usando o operador “:”. O código abaixo retorna as primeiras 3 linhas.
df[0:3]
Saída:  Uma característica interessante da biblioteca Pandas é selecionar dados com base em seus rótulos de linha e coluna usando a função
Uma característica interessante da biblioteca Pandas é selecionar dados com base em seus rótulos de linha e coluna usando a função iloc[0]. Muitas vezes, podemos precisar apenas de algumas colunas para analisar. Também podemos selecionar por índice usando loc['index_one']). Por exemplo, para selecionar a segunda linha, podemos usar df.iloc[1,:]. Digamos que precisamos selecionar o segundo elemento da segunda coluna. Isso pode ser feito usando a função df.iloc[1,1]. Neste exemplo, a função df.iloc[1,1] exibe “Mumbai” como saída.
4. Filtragem de dados
Também é possível filtrar os valores das colunas. Por exemplo, o código abaixo filtra as colunas que têm uma taxa de alfabetização acima de 90%.
print(df[df['Literacy %']>90])
Qualquer operador de comparação pode ser usado para filtrar com base em uma condição. Resultado:  Outra maneira de filtrar dados é usando o
Outra maneira de filtrar dados é usando o isin. A seguir está o código para filtrar apenas 2 estados, ‘Karnataka’ e ‘Tamil Nadu’.
print(df[df['State'].isin(['Karnataka', 'Tamil Nadu'])])
Resultado: 
5. Renomear coluna
É possível usar a função df.rename() para renomear uma coluna. A função recebe o nome antigo da coluna e o novo nome como argumentos. Por exemplo, vamos renomear a coluna ‘Literacy %’ para ‘Literacy percentage’.
df.rename(columns = {'Literacy %':'Literacy percentage'}, inplace=True)
print(df.head())
O argumento `inplace=True` faz as alterações no DataFrame. Resultado: 
6. Manipulação de dados
Ciência de Dados envolve o processamento de dados para que os dados possam funcionar bem com os algoritmos de dados. Data Wrangling é o processo de processamento de dados, como mesclagem, agrupamento e concatenação. A biblioteca Pandas fornece funções úteis como merge(), groupby() e concat() para apoiar as tarefas de Data Wrangling. Vamos criar 2 DataFrames e mostrar as funções de Data Wrangling para entender melhor.
import pandas as pd
d = {
'Employee_id': ['1', '2', '3', '4', '5'],
'Employee_name': ['Akshar', 'Jones', 'Kate', 'Mike', 'Tina']
}
df1 = pd.DataFrame(d, columns=['Employee_id', 'Employee_name'])
print(df1)
Resultado:  Vamos criar o segundo DataFrame usando o código abaixo:
Vamos criar o segundo DataFrame usando o código abaixo:
import pandas as pd
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Tia', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data, columns=['Employee_id', 'Employee_name'])
print(df2)
Resultado: 
a. Merging
Agora, vamos mesclar os 2 DataFrames que criamos, ao longo dos valores de ‘Employee_id’ usando a função merge():
print(pd.merge(df1, df2, on='Employee_id'))
Resultado:  Podemos ver que a função merge() retorna as linhas de ambos os DataFrames que têm o mesmo valor de coluna, que foi usado durante a mesclagem.
Podemos ver que a função merge() retorna as linhas de ambos os DataFrames que têm o mesmo valor de coluna, que foi usado durante a mesclagem.
b. Grouping
Agrupamento é um processo de coletar dados em diferentes categorias. Por exemplo, no exemplo abaixo, o campo “Employee_Name” tem o nome “Meera” duas vezes. Então, vamos agrupá-lo pela coluna “Employee_name”.
import pandas as pd
import numpy as np
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Meera', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data)
group = df2.groupby('Employee_name')
print(group.get_group('Meera'))
O campo ‘Employee_name’ com valor ‘Meera’ é agrupado pela coluna “Employee_name”. A saída de exemplo é a seguinte: Resultado: 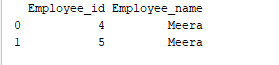
c. Concatenating
Concatenar dados envolve adicionar um conjunto de dados ao outro. O Pandas fornece uma função chamada concat() para concatenar DataFrames. Por exemplo, vamos concatenar os DataFrames df1 e df2, usando:
print(pd.concat([df1, df2]))
Saída: 
Criar um DataFrame passando um Dicionário de Séries
Para criar uma Série, podemos usar o método pd.Series() e passar uma matriz para ele. Vamos criar uma Série simples da seguinte forma:
series_sample = pd.Series([100, 200, 300, 400])
print(series_sample)
Saída:  Nós criamos uma Série. Você pode ver que 2 colunas são exibidas. A primeira coluna contém os valores do índice começando do 0. A segunda coluna contém os elementos passados como séries. É possível criar um DataFrame passando um dicionário de `Series`. Vamos criar um DataFrame que é formado unindo e passando os índices das séries. Exemplo
Nós criamos uma Série. Você pode ver que 2 colunas são exibidas. A primeira coluna contém os valores do índice começando do 0. A segunda coluna contém os elementos passados como séries. É possível criar um DataFrame passando um dicionário de `Series`. Vamos criar um DataFrame que é formado unindo e passando os índices das séries. Exemplo
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df)
Saída de exemplo 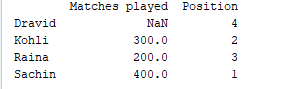 Para a série um, como não especificamos o rótulo ‘d’, NaN é retornado.
Para a série um, como não especificamos o rótulo ‘d’, NaN é retornado.
Seleção, Adição, Exclusão de Colunas
É possível selecionar uma coluna específica do DataFrame. Por exemplo, para exibir apenas a primeira coluna, podemos reescrever o código acima como:
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df['Matches played'])
O código acima imprime apenas a coluna “Partidas jogadas” do DataFrame. Saída 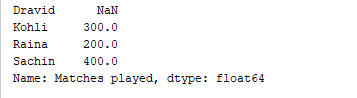 Também é possível adicionar colunas a um DataFrame existente. Por exemplo, o código abaixo adiciona uma nova coluna chamada “Runrate” ao DataFrame acima.
Também é possível adicionar colunas a um DataFrame existente. Por exemplo, o código abaixo adiciona uma nova coluna chamada “Runrate” ao DataFrame acima.
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
df['Runrate']=pd.Series([80, 70, 60, 50], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])
print(df)
Saída:  Podemos excluir colunas usando as funções `delete` e `pop`. Por exemplo, para excluir a coluna ‘Partidas jogadas’ no exemplo acima, podemos fazer isso de qualquer uma das seguintes duas maneiras:
Podemos excluir colunas usando as funções `delete` e `pop`. Por exemplo, para excluir a coluna ‘Partidas jogadas’ no exemplo acima, podemos fazer isso de qualquer uma das seguintes duas maneiras:
del df['Matches played']
ou
df.pop('Matches played')
Saída: 
Conclusão
Neste tutorial, tivemos uma breve introdução à biblioteca Python Pandas. Também realizamos exemplos práticos para liberar o poder da biblioteca Pandas usada no campo da ciência de dados. Também passamos pelas diferentes Estruturas de Dados na biblioteca Python. Referência: Site Oficial do Pandas
Source:
https://www.digitalocean.com/community/tutorials/python-pandas-module-tutorial