













As organizações estão cada vez mais dependendo de backups para proteger seus dados e garantir a continuidade dos negócios em caso de desastre. No entanto, estima-se que mais de 72% das empresas não conseguem atender às suas expectativas de recuperação de TI relacionadas aos seus objetivos de ponto de recuperação (RPO) e objetivos de tempo de recuperação (RTO).
Para ajudá-lo a criar um plano de recuperação eficiente, é essencial que você desenvolva um entendimento completo sobre RTO e RPO e aprenda sobre as diferenças. Este post explica tudo o que você precisa saber sobre esses dois parâmetros para uma estratégia de recuperação de desastres confiável. Continue lendo para descobrir como você pode alcançar RPO e RTO mais apertados para minimizar a perda de dados e retomar as operações normais de negócios o mais rápido possível após um desastre.
O que é RTO?
O objetivo de tempo de recuperação (RTO) refere-se ao máximo de tempo de inatividade que uma organização pode tolerar após um evento disruptivo. Em outras palavras, o RTO é a duração entre a ocorrência de um desastre e a recuperação das cargas de trabalho críticas afetadas.
O cálculo do RTO geralmente depende do seu plano de recuperação de desastres, dos recursos disponíveis e do orçamento. Enquanto sua infraestrutura de TI estiver indisponível, você precisa de algum tempo para identificar a(s) razão(ões) da falha e tomar as medidas necessárias para corrigir o problema. No entanto, etapas de recuperação de desastres devem estar em vigor para garantir que sistemas críticos e cargas de trabalho sejam acessíveis e disponíveis enquanto o problema de produção é resolvido. Seu RTO é o tempo entre a falha e a disponibilidade dos sistemas por meio de backups ou cargas de trabalho de réplica.
O que é RPO?
O objetivo de ponto de recuperação (RPO) representa a quantidade máxima de dados que uma organização pode suportar perder em um desastre sem consequências críticas. Essa métrica é medida em horas/minutos desde o último processo de backups/replicação. Use-a para determinar com que frequência você precisa criar backups de dados e réplicas para reduzir a perda de dados após um evento disruptivo.
Em uma situação ideal, um trabalho de backup ou replicação é concluído logo antes que a máquina original falhe. No entanto, isso é raro na vida real, então existe uma lacuna entre o momento em que o último backup bem-sucedido foi criado e o momento em que a máquina original falha. Durante esse tempo, a VM estava realizando operações e armazenando dados, e é provável que esses dados sejam perdidos.
O que é RTO e RPO na recuperação de desastres
O objetivo final da proteção de dados é claro: você quer garantir que os dados críticos não sejam perdidos se algo der errado e que você possa atender aos SLAs da sua organização em termos de tempo de atividade e disponibilidade. No entanto, é bastante caro espelhar todas as mudanças em seu ambiente virtual para um site de recuperação de desastres (DR) em tempo real. É por isso que você precisa aceitar a ideia de que perderá alguns dados e que seus serviços de TI serão interrompidos em caso de falha. Assim, sua tarefa é minimizar essas perdas e interrupções.
Vamos ilustrar os conceitos de RPO e RTO em um diagrama simples:
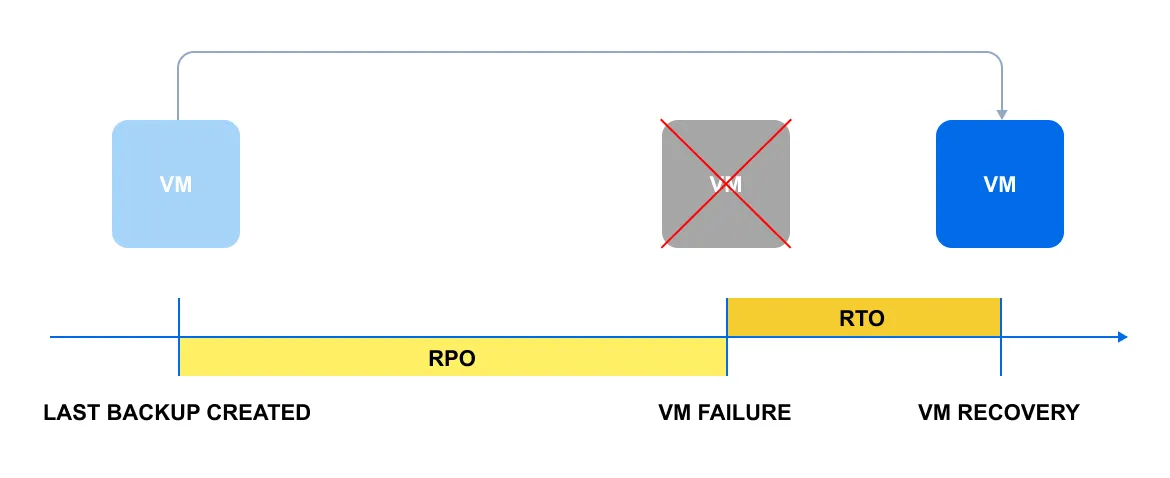
O diagrama mostra um cenário comum: uma máquina virtual falha por algum motivo. A linha amarela representa o RPO, que é o tempo entre o último backup e a interrupção. A linha laranja é o RTO e reflete o tempo necessário para restaurar a VM.
Diferenças entre RTO e RPO
Para entender como determinar RTO e RPO, você deve observar suas diferenças e seu papel no processo de DR.
Avaliação
- RTO está principalmente preocupado com o período de tempo dentro do qual as operações comerciais são esperadas para serem retomadas durante um desastre. Os pontos a considerar são:
- Avalie as necessidades e prioridades da sua organização, pois são únicas para cada organização.
- Considere quais aplicativos são os mais críticos para os serviços e aplicativos essenciais para a sobrevivência da organização, bem como quais podem ser as repercussões se esses aplicativos falharem.
- Determine a ordem em que cada sistema/aplicativo deve ser restaurado para garantir uma recuperação de desastres bem-sucedida com perdas de tempo de inatividade mínimas.
- RPO está mais focado na quantidade de dados que podem ser perdidos durante o tempo de inatividade sem causar danos graves ao resultado final de uma organização. Os pontos a considerar são:
- Identifique a frequência do backup/replicação e quanto dados podem ser perdidos entre o backup VM mais recente e um desastre real.
- Considere a quantidade de dados que sua organização pode se dar ao luxo de perder para cada tipo de carga de trabalho.
Custos
A principal diferença entre RTO e RPO é que o primeiro considera todos os aspectos da estrutura de negócios e do processo de DR como um todo, enquanto o segundo apenas considera a criticidade de dados e aplicativos para a continuidade do negócio. Portanto, atingir valores de RTO pode ser uma tarefa demandante e cara para garantir uma recuperação rápida. Similarmente, ter RPOs menores significa que você precisa executar mais backups e criar pontos de recuperação adicionais, o que pode aumentar seus custos de armazenamento.
Automação
- Como o RPO se concentra em dados e a resiliência do seu sistema à perda, é recomendável que você execute backups de dados frequentes. Muitas soluções de backup modernas permitem que você execute backups VM automaticamente, o que significa que suas estratégias de backup podem ser personalizadas de uma maneira que atinja seus objetivos de RPO de forma eficiente, com o mínimo de entrada de sua parte.
- Atingir RTO é um processo mais complexo de gerenciar, pois considera todos os processos de negócios e componentes de sistema que precisam ser recuperados durante um evento de DR. Dito isso, é recomendável automatizar e orquestrar todo o processo de DR de start a finish para garantir que seus objetivos de RTO possam ser atingidos.
Facilidade de cálculo
- O RPO é fácil de calcular, pois abrange apenas um aspecto do processo de recuperação – os dados.
- RTO considera todos os aspectos da sua organização, incluindo a importância dos seus dados e serviços, o custo de tempo de inatividade, o investimento em atividades de DR, etc. Ao calcular o RTO, deve levar em conta os diferentes tipos de cargas de trabalho e aplicações, pois eles podem ter processos de recuperação diferentes. É recomendável calcular o RTO com base em um plano de continuidade de negócios, que descreve os riscos e ameaças possíveis e descreve as etapas a serem tomadas para retomar as operações do negócio.
Para definir o RTO adequado aos diferentes tipos de cargas de trabalho na sua organização, responda à seguinte questão:
Quanto tempo uma aplicação/sistema/máquina pode ficar offline sem ter um impacto significativo nas operações centrais da sua organização?
Após responder a esta questão para diferentes máquinas, considerar se os resultados esperados podem atender aos seus atuais需求. Se não, pensar em como poderia melhorar suas estratégias de backup e DR para manter os dados backados o mais atuais possíveis.
Como Atingir um RPO e RTO mais Rígidos com NAKIVO
O NAKIVO Backup & Replication permite que você crie backups de máquinas virtuais e físicas com mais frequência, melhorando o RPO. Basta agendar backups regulares com um intervalo que não ultrapasse sua meta.
A solução também ajuda a reduzir o RTO com recuperação instantânea de VM e funcionalidade de replicação para VMware vSphere, Microsoft Hyper-V e Amazon EC2. Integre seus serviços de monitoramento de rede e disparar um processo de recuperação imediatamente após uma VM ficar indisponível. Você também pode criar réplicas offsite (cópias exatas) de VMs críticos. Se a VM original falhar, as réplicas seriam acionadas automaticamente. Se a manutenção de réplicas exigir mais recursos do que você puder afford, você pode escolher a funcionalidade de arrasto instantâneo de VM de backup.
Para alcançar os menores RTOs, o NAKIVO Backup & Replication apresentou a funcionalidade de orquestração de Recuperação de Site. Automatize totalmente o failover e o failback de VM para diferentes cenários de DR e execute testes não disruptivos para garantir recuperação dentro do tempo esperado.