













Le organizzazioni stanno sempre più affidandosi ai backup per proteggere i loro dati e garantire la continuità aziendale in caso di disastro. Tuttavia, si stima che oltre il 72% delle imprese non sia in grado di soddisfare le loro aspettative di recupero IT relative agli obiettivi di punto di recupero (RPO) e agli obiettivi di tempo di recupero (RTO).
Per aiutarti a creare un piano di recupero efficiente, è essenziale sviluppare una comprensione completa di RTO e RPO e imparare le differenze. Questo post spiega tutto ciò che devi sapere su questi due parametri per una strategia di disaster recovery affidabile. Continua a leggere per scoprire come puoi ottenere RPO e RTO più stretti per minimizzare la perdita di dati e riprendere le normali operazioni aziendali il più rapidamente possibile dopo un disastro.
Che cos’è RTO?
L’obiettivo di tempo di recupero (RTO) si riferisce alla quantità massima di tempo di inattività che un’organizzazione può tollerare a seguito di un evento di interruzione. In altre parole, RTO è la durata tra l’accadimento di un disastro e il recupero delle attività critiche interessate.
Il calcolo del RTO dipende generalmente dal tuo piano di ripristino dei disastri, dalle risorse disponibili e dal budget. Mentre la tua infrastruttura IT non è disponibile, hai bisogno di tempo per identificare le ragioni del guasto e prendere le azioni necessarie per risolvere il problema. Tuttavia, dovrebbero essere in atto passaggi di ripristino dei disastri per garantire che i sistemi critici e i carichi di lavoro siano accessibili e disponibili mentre il problema di produzione viene risolto. Il tuo RTO è il tempo tra il guasto e la disponibilità dei sistemi tramite backup o carichi di lavoro replica.
Cos’è l’RPO?
L’obiettivo di punto di recupero (RPO) rappresenta la massima quantità di dati che un’organizzazione può sopportare di perdere in un disastro senza conseguenze critiche. Questa metrica è misurata in ore/minuti dall’ultimo processo di backup/replica. Usalo per determinare ogni quanto devi creare backup dei dati e repliche per ridurre la perdita di dati a seguito di un evento dirompente.
In una situazione ideale, un lavoro di backup o replica viene completato proprio prima che la macchina originale fallisca. Tuttavia, questo è raro nella vita reale, quindi hai un intervallo tra il momento in cui è stato creato l’ultimo backup di successo e il momento in cui la macchina originale fallisce. Durante questo tempo, la VM stava eseguendo operazioni e memorizzando dati, e molto probabilmente questi dati andranno persi.
Cos’è RTO e RPO nel ripristino dei disastri
L’obiettivo finale della protezione dei dati è chiaro: si desidera essere sicuri che i dati critici non vengano persi se qualcosa va storto e che si possano rispettare gli SLA dell’organizzazione in termini di tempo di attività e disponibilità. Tuttavia, è piuttosto costoso replicare tutti i cambiamenti nel proprio ambiente virtuale su un sito di ripristino di emergenza (DR) in tempo reale. Ecco perché è necessario accettare l’idea che si perderanno alcuni dati e che i servizi IT verranno interrotti in caso di emergenza. Pertanto, il compito è quello di ridurre al minimo tali perdite e interruzioni.
Illustreremo i concetti di RPO e RTO in un semplice diagramma:
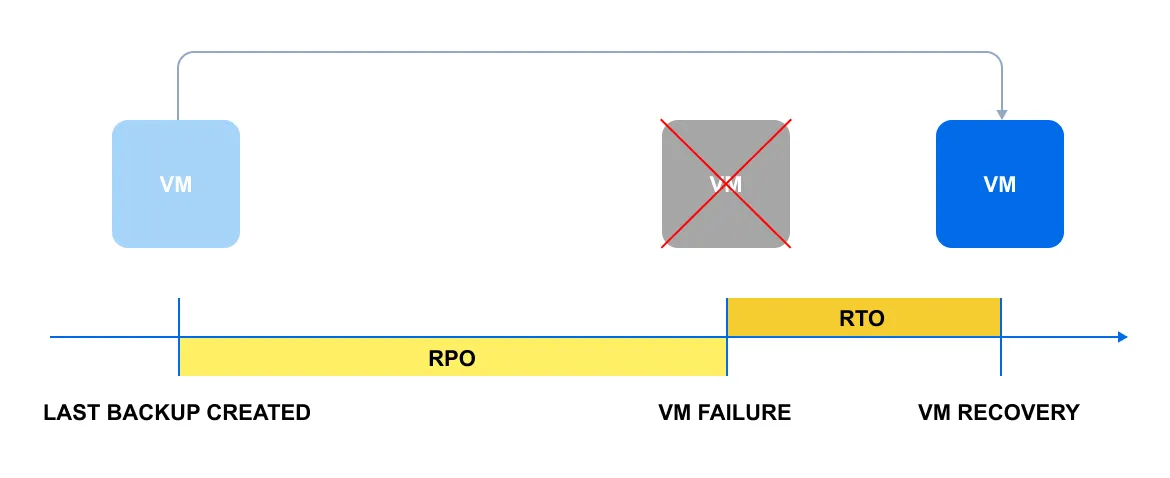
Il diagramma mostra uno scenario comune: una macchina virtuale si blocca per qualche motivo. La linea gialla rappresenta l’RPO, che è il tempo trascorso dall’ultimo backup e dal momento della disconnessione. La linea arancione è l’RTO e riflette il tempo necessario per ripristinare la VM.
Differenze tra RTO e RPO
Per capire come determinare RTO e RPO, è necessario guardare alle loro differenze e al loro ruolo nel processo DR.
Valutazione
- RTO si occupa principalmente del periodo di tempo entro il quale ci si aspetta che le operazioni aziendali vengano riprese durante un disastro. I punti da considerare sono:
- Valutare le esigenze e le priorità della propria organizzazione, poiché sono uniche per ciascuna organizzazione.
- Considerare quali applicazioni sono le più critiche per i servizi e le applicazioni vitali per la sopravvivenza dell’organizzazione, nonché quali potrebbero essere le ripercussioni se queste applicazioni dovessero fallire.
- Determinare l’ordine in cui ogni sistema/applicazione dovrebbe essere ripristinato per garantire un recupero da disastro di successo con perdite di tempo di inattività minime.
- RPO è più concentrato sulla quantità di dati che possono essere persi durante il tempo di inattività senza causare seri danni al bilancio di un’organizzazione. I punti da considerare sono:
- Identificare la frequenza di backup/replicazione e quanto dati potrebbero essere persi tra l’ultimo backup VM e un effettivo disastro.
- Considerare la quantità di dati che la propria organizzazione può permettersi di perdere per ogni tipo di carico di lavoro.
Costi
La differenza principale tra RTO e RPO è che il primo tiene conto di tutti gli aspetti della struttura aziendale e del processo di ripristino dei disastri nel loro complesso, mentre il secondo considera solo la criticità dei dati e delle applicazioni per la continuità aziendale. Pertanto, rispettare i valori di RTO potrebbe essere un compito impegnativo e costoso per garantire un ripristino veloce. Allo stesso modo, avere RPO più piccoli significa che è necessario effettuare più backup e creare punti di ripristino aggiuntivi che possono aumentare i costi di archiviazione.
Automazione
- Poiché RPO è focalizzato sui dati e sulla resilienza del vostro sistema alla perdita, si consiglia di eseguire frequenti backup dei dati. Molte moderne soluzioni di backup consentono di eseguire backup automatici di VM, il che significa che le vostre strategie di backup possono essere personalizzate in modo da soddisfare efficientemente i vostri obiettivi di RPO, con un input minimo da parte vostra.
- Raggiungere RTO è un processo più complesso da gestire, poiché tiene conto di tutti i processi aziendali e dei componenti di sistema che devono essere ripristinati durante un evento di ripristino dei disastri. Detto ciò, si consiglia di automatizzare e orchestrare l’intero processo di ripristino dei disastri dall’inizio alla fine per garantire che i vostri obiettivi di RTO possano essere raggiunti.
Semplicità di calcolo
- Il metrica RPO è facile da calcolare, poiché copre solo un aspetto del processo di ripristino: i dati.
- RTO considera tutti gli aspetti della tua organizzazione, compresa l’importanza dei tuoi dati e servizi, il costo dell’inattività, gli investimenti nelle attività di ripristino, ecc. Quando calcoli l’RTO, dovresti tenere conto dei diversi tipi di carichi di lavoro e applicazioni in quanto possono avere processi di ripristino variabili. È consigliabile calcolare l’RTO sulla base di un piano di continuità aziendale, che descrive i possibili rischi e minacce aziendali e descrive le misure da adottare per riprendere le operazioni aziendali.
Per definire l’RTO applicabile ai diversi carichi di lavoro della tua organizzazione, rispondi alla seguente domanda:
Per quanto tempo una specifica applicazione/sistema/macchina può restare inattiva senza avere un impatto significativo sulle operazioni principali della tua organizzazione?
Dopo aver risposto a questa domanda per diverse macchine, valuta se i risultati attesi possono soddisfare le attuali esigenze aziendali. In caso contrario, pensa a come potresti migliorare le tue strategie di backup e DR per mantenere i dati di backup il più attuali possibile.
Come raggiungere RPO e RTO più stretti con NAKIVO
NAKIVO Backup & Replication ti consente di creare backup di macchine virtuali e fisiche più frequentemente, migliorando il RPO. Programma semplicemente backup regolari con un intervallo non superiore al tuo obiettivo.
La soluzione aiuta anche a ridurre il RTO con il recupero istantaneo delle VM e la funzionalità di replicazione per VMware vSphere, Microsoft Hyper-V e Amazon EC2. Integra i tuoi servizi di monitoraggio della rete e attiva un processo di recupero immediatamente dopo che una VM diventa non disponibile. Puoi anche creare repliche offsite (copie esatte) di VM critiche. Se la VM originale non funziona, le repliche verrebbero attivate automaticamente. Se il mantenimento delle repliche richiede più risorse di quante tu possa permetterti, puoi scegliere la funzionalità di avvio istantaneo delle VM dalle backup.
Per ottenere i RTO più stretti, NAKIVO Backup & Replication ha introdotto la funzionalità di orchestrazione di Site Recovery. Automatizza completamente il failover e il failback delle VM per diversi scenari di DR e esegui test non distruttivi per garantire il recupero entro il tempo previsto.