













Más del 72 % de las empresas no pueden cumplir con sus expectativas de recuperación de TI relacionadas con sus objetivos de punto de recuperación (RPO) y objetivos de tiempo de recuperación (RTO).
Para ayudarle a crear un plan de recuperación eficaz, es fundamental que comprenda completamente los conceptos de RTO y RPO y conozca sus diferencias. En esta publicación se explican todos los aspectos que necesita saber sobre estos dos parámetros para contar con una estrategia de recuperación ante desastres confiable. Siga leyendo para descubrir cómo puede lograr un RPO y un RTO más estrictos para minimizar la pérdida de datos y reanudar las operaciones comerciales normales lo antes posible después de un desastre.
¿Qué es RTO?
El objetivo de tiempo de recuperación (RTO) se refiere al tiempo máximo de inactividad que una organización puede tolerar después de un evento disruptivo. En otras palabras, el RTO es el período que transcurre entre la ocurrencia de un desastre y la recuperación de las cargas de trabajo críticas afectadas.
El cálculo de RTO generalmente depende de su plan de recuperación ante desastres, recursos disponibles y presupuesto. Mientras su infraestructura de TI no esté disponible, necesita tiempo para identificar la(s) razón(es) del fallo y tomar las medidas necesarias para solucionar el problema. Sin embargo, deben existir pasos de recuperación ante desastres para asegurar que los sistemas críticos y las cargas de trabajo estén accesibles y disponibles mientras se resuelve el problema de producción. Su RTO es el tiempo entre el fallo y la disponibilidad de los sistemas a través de copias de seguridad o cargas de trabajo replicadas.
¿Qué es RPO?
El objetivo de punto de recuperación (RPO) representa la cantidad máxima de datos que una organización puede soportar perder en un desastre sin consecuencias críticas. Esta métrica se mide en horas/minutos desde el último proceso de copias de seguridad/replicación. Úsela para determinar con qué frecuencia necesita crear copias de seguridad de datos y réplicas para reducir la pérdida de datos después de un evento disruptivo.
En una situación ideal, un trabajo de copia de seguridad o replicación se completa justo antes de que falle la máquina original. Sin embargo, esto es raro en la vida real, por lo que existe un espacio entre el momento en que se creó la última copia de seguridad exitosa y el momento en que falla la máquina original. Durante este tiempo, la MV estaba realizando operaciones y almacenando datos, y es muy probable que estos datos se pierdan.
¿Qué es RTO y RPO en la recuperación ante desastres
El objetivo final de la protección de datos es claro: quieres asegurarte de que los datos críticos no se pierdan si algo sale mal y de que puedas cumplir con los SLA de tu organización en cuanto a tiempo de actividad y disponibilidad. Sin embargo, es bastante costoso replicar todos los cambios en tu entorno virtual a un sitio de recuperación ante desastres (DR) en tiempo real. Por eso necesitas aceptar la idea de que perderás algunos datos y que tus servicios de TI se interrumpirán en caso de una falla. Por lo tanto, tu tarea es minimizar esas pérdidas e interrupciones.
Ilustremos los conceptos de RPO y RTO en un diagrama simple:
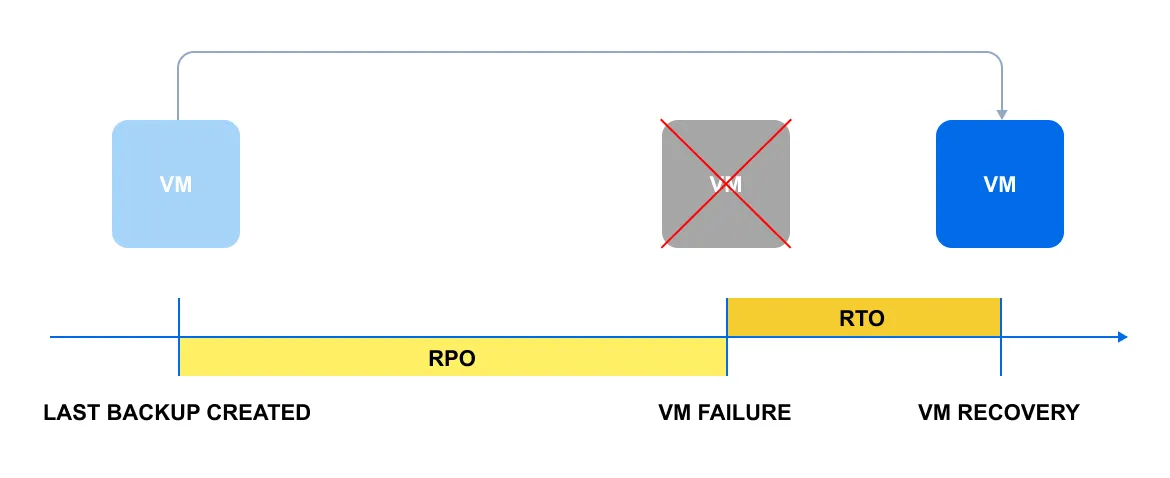
El diagrama muestra un escenario común: una máquina virtual se estrella por alguna razón. La línea amarilla representa el RPO, que es el tiempo entre el último respaldo y la interrupción. La línea naranja es el RTO y refleja el tiempo requerido para restaurar la VM.
Diferencias entre RTO y RPO
Para entender cómo determinar RTO y RPO, debes observar sus diferencias y su papel en el proceso de DR.
Evaluación
- RTO se preocupa principalmente por el período de tiempo dentro del cual se espera que se reanuden las operaciones comerciales durante un desastre. Los puntos a considerar son:
- Evaluar las necesidades y prioridades de su organización, ya que son únicas para cada organización.
- Considerar qué aplicaciones son las más críticas para los servicios y aplicaciones críticas para la supervivencia de la organización, así como cuáles podrían ser las repercusiones si estas aplicaciones fallaran.
- Determinar el orden en el que cada sistema/aplicación debe ser restaurado para garantizar una recuperación de desastres exitosa con pérdidas mínimas de tiempo de inactividad.
- RPO se centra más en la cantidad de datos que pueden perderse durante el tiempo de inactividad sin causar daños graves a la línea de fondo de una organización. Los puntos a considerar son:
- Identificar la frecuencia de la copia de seguridad/replicación y cuántos datos podrían perderse entre la última copia de seguridad de la máquina virtual y un desastre real.
- Considerar la cantidad de datos que su organización puede permitirse perder para cada tipo de carga de trabajo.
Costos
La principal diferencia entre RTO y RPO es que el primero tiene en cuenta todos los aspectos de la estructura empresarial y el proceso de recuperación ante desastres en su totalidad, mientras que el segundo solo considera la criticidad de los datos y aplicaciones para la continuidad del negocio. Por lo tanto, cumplir con los valores de RTO puede ser una tarea exigente y costosa para garantizar una recuperación rápida. Del mismo modo, tener RPO más pequeños significa que necesita realizar más copias de seguridad y crear puntos de recuperación adicionales, lo que puede aumentar sus costos de almacenamiento.
Automatización
- Dado que RPO se centra en los datos y en la capacidad de resiliencia de su sistema ante pérdidas, se recomienda ejecutar copias de seguridad de datos con frecuencia. Muchas soluciones modernas de copia de seguridad le permiten realizar copias de seguridad de máquinas virtuales de forma automatizada, lo que significa que sus estrategias de copia de seguridad pueden adaptarse de manera que cumplan eficientemente con sus objetivos de RPO, y con una entrada mínima por su parte.
- Lograr el RTO es un proceso más complejo de gestionar, ya que tiene en cuenta todos los procesos empresariales y componentes del sistema que deben recuperarse durante un evento de recuperación ante desastres. Dicho esto, se recomienda automatizar y orquestar todo el proceso de recuperación ante desastres de principio a fin para garantizar que se puedan cumplir sus objetivos de RTO.
Facilidad de cálculo
- El métrico RPO es fácil de calcular, ya que solo cubre un aspecto del proceso de recuperación: los datos.
- RTO considera todos los aspectos de su organización, incluida la importancia de sus datos y servicios, el costo del tiempo de inactividad, la inversión en actividades de recuperación ante desastres, etc. Al calcular el RTO, debe tener en cuenta los diferentes tipos de cargas de trabajo y aplicaciones, ya que pueden tener procesos de recuperación variables. Es recomendable calcular el RTO en base a un plan de continuidad empresarial, que describe los posibles riesgos y amenazas comerciales, y describe los pasos a seguir para reanudar las operaciones comerciales.
Para definir el RTO que es aplicable a las diferentes cargas de trabajo en sus organizaciones, responda la siguiente pregunta:
¿Cuánto tiempo puede estar inactiva una aplicación/sistema/máquina específica sin tener un impacto significativo en las operaciones principales de su organización?
Después de responder a esta pregunta para diferentes máquinas, considere si los resultados esperados pueden satisfacer sus necesidades comerciales actuales. Si no es así, piense en cómo podría mejorar sus estrategias de copia de seguridad y DR para mantener los datos respaldados lo más actualizados posible.
Cómo lograr un RPO y RTO más estrictos con NAKIVO
NAKIVO Backup & Replicación le permite crear copias de seguridad de máquinas virtuales y físicas con más frecuencia, mejorando el RPO. Simplemente programe copias de seguridad regulares con un intervalo que no sea mayor que su objetivo.
La solución también ayuda a reducir el RTO con recuperación instantánea de VM y funcionalidad de replicación para VMware vSphere, Microsoft Hyper-V y Amazon EC2. Integre sus servicios de monitoreo de red y desencadene un proceso de recuperación inmediatamente después de que una VM se vuelva inaccesible. También puede crear réplicas fuera del sitio (copias exactas) de VMs críticas. Si la VM original fallara, las réplicas se encenderían automáticamente. Si mantener réplicas requiere más recursos de los que puede permitirse, puede optar por la función de arranque instantáneo de VM desde la copia de seguridad.
Para lograr los RTO más estrictos, NAKIVO Backup & Replication ha introducido la funcionalidad de orquestación de recuperación de sitio. Automatice completamente la conmutación por error y la conmutación por recuperación de VM para diferentes escenarios de DR y realice pruebas no disruptivas para garantizar la recuperación dentro del tiempo esperado.