













A Recuperação Aumentada da Geração (RAG) representa uma evolução transformadora em modelos de linguagem de grande escala (LLM). Ele combina a habilidade gerativa das arquiteturas de transformer com a recuperação de informações dinâmicas.
Essa integração permite que os LLMs acessem e incorporem conhecimento externo relevante durante a geração de texto, resultando em saídas mais precisas, contextuais e consistentes factualmente.
A evolução dos primeiros sistemas baseados em regras para modelos neurais sofisticados como BERT e GPT-3 abriu caminho para a RAG, endereçando as limitações da memória paramétrica estática. Além disso, o advento da Multimodal RAG estende essas capacidades ao incorporar tipos de dados diversos, como imagens, áudio e vídeo, melhorando a riqueza e a relevância do conteúdo gerado.
Essa mudança de paradigma não só melhora a precisão e a interpretabilidade das saídas de LLMs, mas também apoia aplicações inovadoras em vários domínios.
Veja o que vamos cobrir:
- Capítulo 1. Introdução à RAG
– 1.1 O que é a RAG? Uma Visão Geral
– 1.2 Como a RAG Resolve Problemas Complexos - Capítulo 2. Fundamentos Técnicos
– 2.1 Transição de LM Neurais para RAG
– 2.2 Compreendendo a Memória do RAG: Paramétrico vs. Não-Paramétrico
– 2.3 RAG Multimodal: Integrando Múltiplos Tipos de Dados - Capítulo 3. Mecanismos Centrais
– 3.1 O Poder de Combinar Recuperação e Geração de Informações no RAG
– 3.2 Estratégias de Integração para Recuperadores e Geradores - Capítulo 4. Aplicações e Casos de Uso
– 4.1 RAG em Ação: De QA a Escrita Criativa
– 4.2 RAG para Línguas de Baixo Recurso: Expandindo Alcance e Capacidades - Capítulo 5. Técnicas de Otimização
– 5.1 Técnicas Avançadas de Recuperação para Otimização de Sistemas RAG - Capítulo 6. Desafios e Inovações
– 6.1 Desafios Atuais e Direções Futuras para RAG
– 6.2 Aceleração de Hardware e Implantação Eficiente de Sistemas RAG - Capítulo 7. Considerações Finais
– 7.1 O Futuro do RAG: Conclusões e Reflexões
Pré-requisitos
Para se envolver com conteúdo focado em modelos de linguagem de grande porte (LLMs) como Geração Aumentada por Recuperação (RAG), dois pré-requisitos essenciais são:
- Fundamentos de Aprendizado de Máquina: Entender conceitos e algoritmos básicos de aprendizado de máquina é crucial, especialmente no que se aplica às arquiteturas de redes neurais.
- Processamento de Linguagem Natural (NLP): O conhecimento das técnicas de NLP, incluindo a pré-processamento de texto, a tokenização e o uso de embeddings, é fundamental para trabalhar com modelos de linguagem.
Capítulo 1: Introdução ao RAG
A Retrieval-Augmented Generation (RAG) revoluciona o processamento de linguagem natural pela combinação de informação de recuperação e modelos geradores. Os sistemas RAG acessam dinamicamente conhecimentos externos, melhorando a precisão e a relevância do texto gerado.
Este capítulo explora os mecanismos, vantagens e desafios do RAG. Nós mergulhamos nas técnicas de recuperação, na integração com modelos geradores e no impacto em várias aplicações.
O RAG reduz as alucinações, incorpora informações atualizadas e aborda problemas complexos. Também discutimos desafios como a eficiência na recuperação e considerações éticas. Este capítulo fornece uma compreensão abrangente do potencial transformador do RAG no processamento de linguagem natural.
1.1 O que é o RAG? Uma Visão Geral
A Retrieval-Augmented Generation (RAG) representa uma mudança de paradigma no processamento de linguagem natural, integrando de forma natural as vantagens dos modelos de recuperação de informação e dos modelos geradores de linguagem. Os sistemas RAG aproveitam fontes de conhecimento externos para melhorar a precisão, relevância e coesão do texto gerado, abordando as limitações da memória paramétrica pura dos modelos de linguagem tradicionais. (Lewis et al., 2020)
Por meio de recuperação e integração dinâmicas de informações relevantes durante o processo de geração, o RAG permite saídas mais contextuais e consistentes em fatos em uma ampla variedade de aplicações,从问题解答和对话系统到摘录和创意写作。(Petroni et al., 2021)
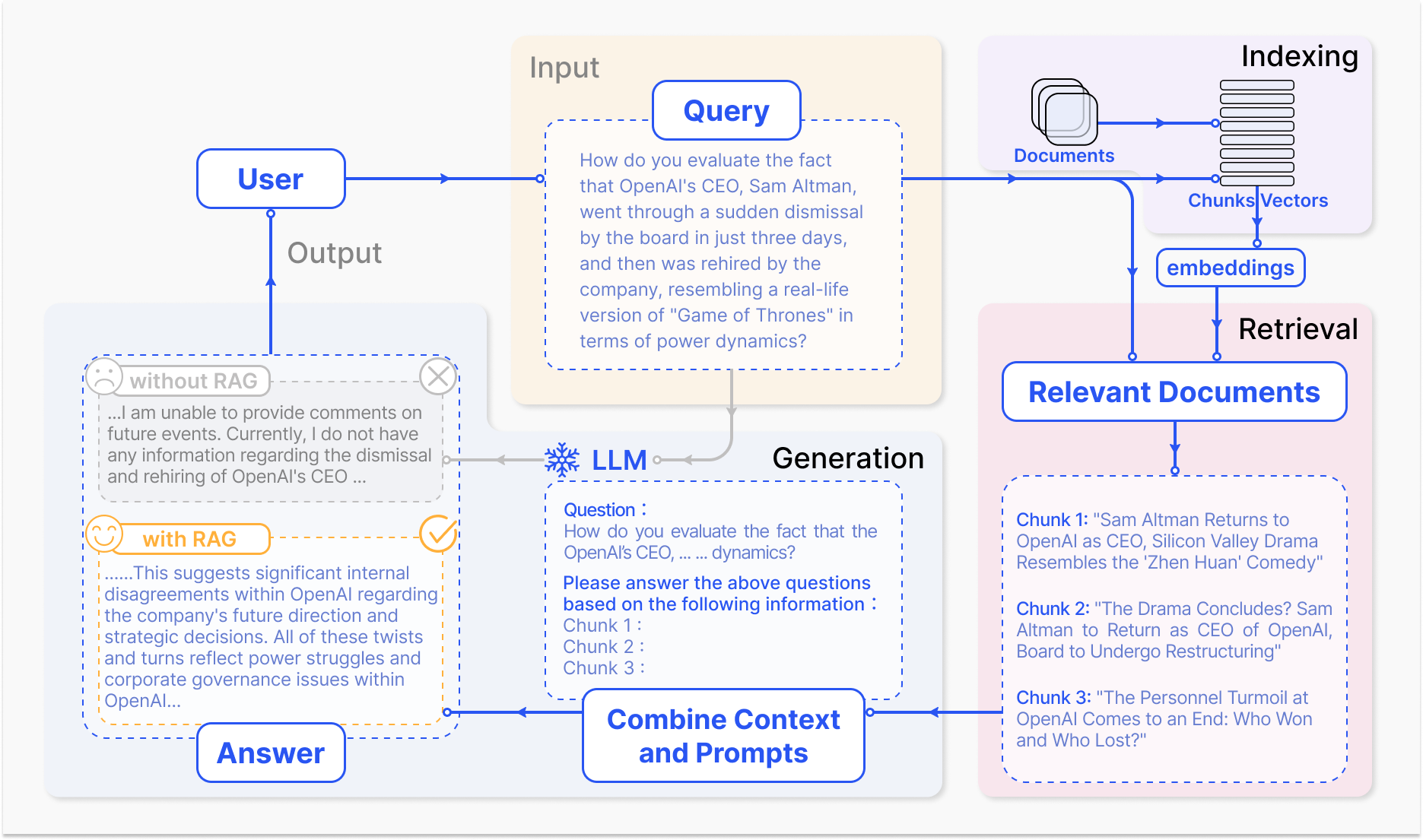
Como um Sistema RAG Opera – arxiv.org
O mecanismo principal do RAG envolve dois componentes primários: recuperação e geração.
O componente de recuperação procurar eficientemente através de bases de conhecimento extensas para identificar a informação mais pertinente com base na consulta de entrada ou contexto. As técnicas como recuperação dispersa, que utiliza índices invertidos e correspondência baseada em termos, e recuperação densa, que emprega representações de vetores densos e semelhança semântica, são usadas para otimizar o processo de recuperação.(Karpukhin et al., 2020)
A informação recuperada é então integrada ao modelo gerativo, normalmente um grande modelo de linguagem como GPT ou T5, que sintetiza o conteúdo relevante em uma resposta coesa e fluida.(Izacard & Grave, 2021)
A integração de recuperação e geração em RAG oferece várias vantagens sobre os modelos de linguagem tradicionais. Ao ancorar o texto gerado em conhecimento externo, o RAG reduz significamente a incidência de alucinações ou resultados factuais incorretos. (Shuster et al., 2021)
O RAG também permite a incorporação de informações atualizadas, garantindo que as respostas geradas refletem o conhecimento e os desenvolvimentos mais recentes em um determinado domínio. (Lewis et al., 2020) Essa adaptabilidade é particularmente crítica em campos como saúde, finanças e pesquisa científica, onde a precisão e a atualidade das informações são de extrema importância. (Petroni et al., 2021)
Mas o desenvolvimento e o deploy de sistemas RAG também apresentam desafios significativos. A recuperação eficiente de bases de conhecimento em larga escala, a mitigação de alucinações e a integração de modalidades de dados diversificados são alguns dos obstáculos técnicos que precisam ser addressados. (Izacard & Grave, 2021)
Considerações éticas, como garantir uma recuperação e geração de informações justas e sem viés, são cruciais para o Deployamento responsável de sistemas RAG. (Bender et al., 2021) Desenvolver métricas e frameworks de avaliação abrangentes que capturam a interação entre a precisão de recuperação e a qualidade gerativa é essencial para avaliar a eficácia dos sistemas RAG. (Lewis et al., 2020)
À medida que o campo de RAG continua a evoluir, direções futuras de pesquisa se concentram em otimizar processos de recuperação, expandir capacidades multimodais, desenvolver arquiteturas modulares e estabelecer frameworks de avaliação robustos. (Izacard & Grave, 2021) Estas melhorias irão aumentar a eficiência, precisão e adaptabilidade dos sistemas RAG, pavimentando o caminho para aplicações mais inteligentes e versáteis em processamento de linguagem natural.
Aqui está um exemplo básico de código em Python demonstrando uma configuração de Geração Augmentada de Recuperação (RAG) usando as bibliotecas populares LangChain e FAISS:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 1. Carregar e Incorporar Documentos
loader = TextLoader('your_documents.txt') # Substitua pela fonte do seu documento
documents = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. Recuperar Documentos Relevantes
def retrieve_docs(query):
return vectorstore.similarity_search(query)
# 3. Configurar a Corrente RAG
llm = OpenAI(temperature=0.1) # Ajuste a temperatura para a criatividade das respostas
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# 4. Usar o Modelo RAG
def get_answer(query):
return chain.run(query)
# Exemplo de uso
query = "What are the key features of Company X's latest product?"
answer = get_answer(query)
print(answer)
#Exemplo de Uso História da Empresa
query = "When was Company X founded and who were the founders?"
answer = get_answer(query)
print(answer)
#Exemplo de Uso Desempenho Financeiro
query = "What were Company X's revenue and profit figures for the last quarter?"
answer = get_answer(query)
print(answer)
#Exemplo de Uso Perspectiva Futura
query = "What are Company X's plans for expansion or new product development?"
answer = get_answer(query)
print(answer)
Ao aproveitar o poder da recuperação e geração, RAG detém um enorme potencial para transformar a forma como interagimos e geramos informações, revolucionando vários domínios e moldando o futuro da interação humano-máquina.
1.2 Como RAG Resolve Problemas Complexos
A Geração Aumentada por Recuperação (RAG) oferece uma solução poderosa para problemas complexos com os quais modelos de linguagem de grande escala (LLMs) tradicionais se esforçam, especialmente em cenários que envolvem vastas quantidades de dados não estruturados.
Um desses problemas é a habilidade de se envolver em conversas significativas sobre documentos específicos ou conteúdos multimídias, como vídeos do YouTube, sem fine-tuning prévio ou treinamento explícito no material de destino.
LMMs tradicionais, apesar de sua capacidade impressionante de geração, são limitadas por sua memória paramétrica, que é fixa no momento da treinamento. (Lewis et al., 2020) Isso significa que elas não podem acessar ou incorporar informações novas além dos dados de treinamento, fazendo com que seja difícil participar de discussões informadas sobre documentos ou vídeos não vistos.
Como resultado, LMMs podem gerar respostas que são inconsistentes, irrelevantes ou factualmente incorretas quando solicitadas com consultas relacionadas a conteúdo específico. (Petroni et al., 2021)
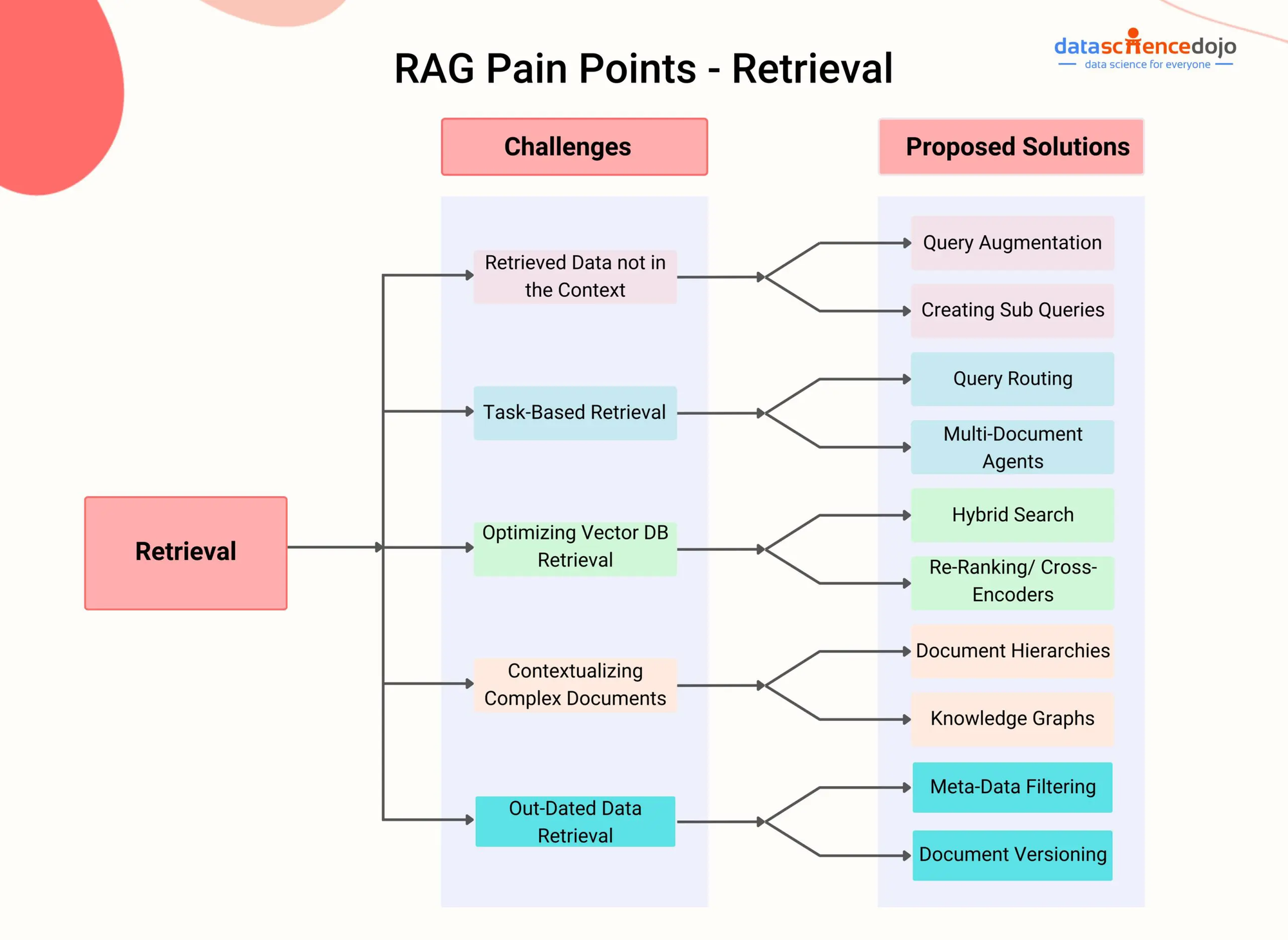
Pontos problemáticos do RAG – DataScienceDojo
O RAG resolve essa limitação integrando um componente de recuperação que permite que o modelo acesse e incorporate informações relevantes de fontes de conhecimento externos durante o processo de geração.
Ao aproveitar técnicas de recuperação avançadas, como a recuperação de passagens densas (Karpukhin et al., 2020) ou busca híbrida (Izacard & Grave, 2021), os sistemas RAG podem identificar com eficiência as passagens ou segmentos mais pertinentes the um dado documento ou vídeo com base no contexto conversacional.
Seja um cenário em que o usuário queira se envolver em uma conversa sobre um vídeo específico do YouTube sobre um tópico científico. Um sistema RAG pode primeiro transcrever o conteúdo áudio do vídeo e depois indexar o texto resultante usando representações de vetores densos.
Então, quando o usuário faz uma pergunta relacionada ao vídeo, o componente de recuperação do sistema RAG pode rapidamente identificar as passagens mais relevantes da transcrição com base na semelhança semântica entre a consulta e o conteúdo indexado.
As passagens recuperadas são então alimentadas ao modelo gerativo, que sintetiza uma resposta coerente e informativa que aborda diretamente a pergunta do usuário enquanto fundamenta a resposta no conteúdo do vídeo. (Shuster et al., 2021)
Essa abordagem permite que sistemas RAG se envolvam em conversas informadas sobre uma ampla gama de documentos e conteúdos multimídias sem a necessidade de ajuste fino explícito. Ao recuperar e incorporar dinamicamente informações relevantes, RAG pode gerar respostas que são mais precisas, relevantes contextualmente e consistentes factualmente em comparação com LLMs tradicionais. (Lewis et al., 2020)
Além disso, a capacidade do RAG de lidar com dados não estruturados de várias modalidades, como texto, imagens e áudio, torna-o uma solução versátil para problemas complexos que envolvem fontes de informação heterogêneas. (Izacard & Grave, 2021) À medida que os sistemas RAG continuam a evoluir, seu potencial para enfrentar problemas complexos em domínios diversos cresce.
Aproveitando técnicas avançadas de recuperação e integração multimodal, o RAG pode possibilitar agentes conversacionais mais inteligentes e conscientes do contexto, sistemas de recomendação personalizados e aplicações intensivas em conhecimento.
À medida que a pesquisa avança em áreas como indexação eficiente, alinhamento cross-modal e integração recuperação-geração, o RAG sem dúvida desempenhará um papel crucial em expandir os limites do que é possível com modelos de linguagem e inteligência artificial.
Capítulo 2: Fundamentos Técnicos
Este capítulo mergulha no fascinante mundo da Geração Aumentada por Recuperação Multimodal (RAG), uma abordagem de ponta que transcende as limitações dos modelos tradicionais baseados em texto.
Integrando perfeitamente diversas modalidades de dados como imagens, áudio e vídeo com Modelos de Linguagem de Grande Escala (LLMs), o RAG Multimodal capacita sistemas de IA a raciocinar em um panorama informacional mais rico.
Exploraremos os mecanismos por trás dessa integração, como aprendizado contrastivo e atenção cross-modal, e como eles permitem que os LLMs gerem respostas mais nuançadas e contextualmente relevantes.
Enquanto a RAG Multimodal oferece benefícios promissores como melhor precisão e a capacidade de suportar casos de uso novos como resposta a questões visuais, ela também apresenta desafios únicos. Esses desafios incluem a necessidade de conjuntos de dados multimodais em grande escala, complexidade computacional aumentada e o potencial de viés na informação recuperada.
À medida que iniciamos essa jornada, não só descobriremos o potencial transformador da RAG Multimodal, mas também examinaremos críticamente os obstáculos que separamos, pavimentando o caminho para uma compreensão mais profunda desse campo em rápida evolução.
2.1 Modelos neurais de LM para RAG
A evolução dos modelos de linguagem tem sido marcada por uma progressão constante de sistemas baseados em regras iniciais para modelos estatísticos e baseados em redes neurais cada vez mais sofisticados.
No início, os modelos de linguagem dependiam de regras artesanais e conhecimento linguístico para gerar texto, resultando em saídas rígidas e limitadas. A chegada de modelos estatísticos, como modelos de n-gramas, introduziu uma abordagem baseada em dados que aprendeu padrões de grandes corpos de texto, permitindo uma geração de linguagem mais natural e coerente. (Redis)
Como a RAG funciona – promptingguide.ai
No entanto, foi a emergência de modelos baseados em redes neurais, particularmente arquiteturas de transformador como BERT e GPT-3, que revolucionou o campo do Processamento de Linguagem Natural (NLP).
desses modelos, conhecidos como modelos de linguagem de grande escala (LLMs), aproveitam o poder do aprendizado profundo para capturar padrões linguísticos complexos e gerar texto semelhante a humano com fluidez e coerência sem precedentes. (Yarnit) A complexidade e escala crescentes dos LLMs, com modelos como o GPT-3 contando com mais de 175 bilhões de parâmetros, resultou em habilidades notáveis em tarefas como tradução de linguagem, respostas a perguntas e criação de conteúdo.
Apesar de seu desempenho impressionante, os LLMs tradicionais sofrem de limitações devido à sua dependência na memória puramente paramétrica. (StackOverflow) O conhecimento codificado nestes modelos é estático, limitado pela data de corte de seus dados de treinamento.
Como resultado, os LLMs podem gerar saídas que são factualmente incorretas ou inconsistentes com as informações mais recentes. Além disso, a falta de acesso explícito a fontes de conhecimento externas limita sua capacidade de proporcionar respostas precisas e relevantes contextualmente a consultas intensivas em conhecimento.
A Geração Aumentada com Recuperação (RAG) surge como uma solução que revoluciona o paradigma para endereçar essas limitações. Ao integrar de forma transparente as capacidades de recuperação de informação com o poder gerativo dos LLMs, a RAG permite que os modelos acessem e incorporem dinamicamente conhecimento relevante de fontes externas durante o processo de geração.
Esta fusão de memória paramétrica e não-paramétrica permite que LLMs equipadas com RAG produzam saídas que não só são fluentes e coerentes, mas também factualmente precisas e informadas contextualmente.
RAG representa um avanço significativo na geração de linguagem, misturando as forças das LLMs com o vasto conhecimento disponível em repositórios externos. Aproveitando o melhor de ambos os mundos, RAG dá poder aos modelos para gerar texto que é mais confiável, informativo e alinhado com o conhecimento do mundo real.
Esta mudança de paradigma abre novas possibilidades para aplicações de PLN, desde resposta a perguntas e criação de conteúdo a tarefas intensivas em conhecimento em domínios como saúde, finanças e pesquisa científica.
2.2 Memória Paramétrica vs Não-Paramétrica
Memória paramétrica refere-se ao conhecimento armazenado dentro dos parâmetros de modelos de linguagem pré-treinados, como BERT e GPT-4. Esses modelos aprendem a capturar padrões linguísticos e relações de vastas quantidades de dados de texto durante o processo de treinamento, codificando esse conhecimento em seus milhões ou biliões de parâmetros.
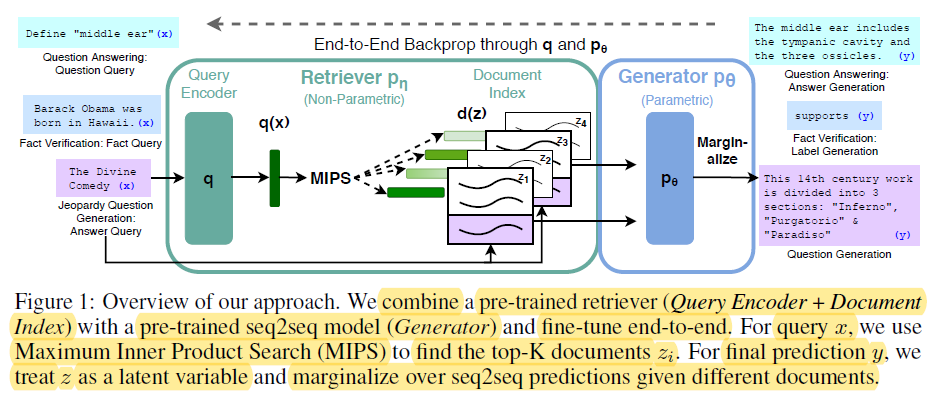
Backprop end-to-end através de q e p0 – miro.medium.com
As forças da memória paramétrica incluem:
- Fluência: Modelos de linguagem pré-treinados geram texto com fluência e coerência semelhantes a humanos, capturando as nuances e o estilo da linguagem natural. (Redis e Lewis et al.)
- Generalização: O conhecimento codificado nos parâmetros do modelo permite generalizar para novas tarefas e domínios, possibilitando a transferência de aprendizado e habilidades de aprendizado com poucas amostras. (Redis e Lewis et al.)
No entanto, a memória paramétrica também tem limitações significativas:
- Erros factuais: Modelos de linguagem podem gerar saídas inconsistentes com fatos do mundo real, pois seu conhecimento é limitado aos dados em que foram treinados.
- Conhecimento desatualizado: O conhecimento codificado nos parâmetros do modelo se torna obsoleto ao longo do tempo, pois é fixado no momento do treinamento e não reflete atualizações ou mudanças no mundo real.
- Alto custo computacional: Treinar grandes modelos de linguagem requer massivas quantidades de recursos computacionais e energia, tornando caro e demorado atualizar seu conhecimento.
- Conhecimento geral: O conhecimento capturado pelos modelos de linguagem é amplo e geral, carecendo da profundidade e especificidade necessária para muitas aplicações de domínio específico.
Em contraste, a memória não-paramétrica se refere ao uso de fontes de conhecimento explícitas, como bancos de dados, documentos e grafos de conhecimento, para proporcionar informações atualizadas e precisas aos modelos de linguagem. Essas fontes externas servem como uma forma complementar de memória, permitindo que os modelos acessem e recuperem informações relevantes sob demanda durante o processo de geração.
As vantagens da memória não-paramétrica incluem:
- Informação atualizada: Fontes de conhecimento externas podem ser facilmente atualizadas e mantidas, garantindo que o modelo tenha acesso às informações mais recentes e mais precisas.
- Redução de halucinações: “Ao recuperar informações relevantes a partir de fontes externas, o RAG reduz significamente a incidência de halucinações ou saídas gerativas facticamente incorretas.” (Lewis et al. e Guu et al.)
- Conhecimento específico de domínio: A memória não-paramétrica permite que os modelos aproveitem conhecimentos especializados de fontes específicas de domínio, permitindo saídas mais precisas e relevantes contextualmente para aplicações específicas. (Lewis et al. e Guu et al.)
As limitações da memória paramétrica realçam a necessidade de uma mudança de paradigma na geração de linguagem.
O RAG representa um avanço significativo no processamento de linguagem natural ao melhorar o desempenho dos modelos gerativos através da integração de técnicas de recuperação de informação. (Redis)
Aqui está o código em Python para demonstrar a distinção entre memória paramétrica e não-paramétrica no contexto do RAG, junto com uma destaque clara na saída:
from sentence_transformers import SentenceTransformer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAI
# Coleção de Documentos de Exemplo (suponha documentos mais substanciais em um cenário real)
documents = [
"The Large Hadron Collider (LHC) is the world's largest and most powerful particle accelerator.",
"The LHC is located at CERN, near Geneva, Switzerland.",
"The LHC is used to study the fundamental particles of matter.",
"In 2012, the LHC discovered the Higgs boson, a particle that gives mass to other particles.",
]
# 1. Memória Não-Paramétrica (Retrieval com Embeddings)
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings(model_name=model_name)
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. Memória Paramétrica (Modelo de Linguagem com Retrieval)
llm = OpenAI(temperature=0.1) # Ajuste a temperatura para a criatividade da resposta
chain = RetrievalQAWithSourcesChain.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# --- Consultas e Respostas ---
query = "What was discovered at the LHC in 2012?"
answer = chain.run(query)
print("Parametric (w/ Retrieval): ", answer["answer"])
query = "Where is the LHC located?"
docs = vectorstore.similarity_search(query)
print("Non-Parametric: ", docs[0].page_content)
Saída:
Parametric (w/ Retrieval): The Higgs boson, a particle that gives mass to other particles, was discovered at the LHC in 2012.
Non-Parametric: The LHC is located at CERN, near Geneva, Switzerland.
E aqui está o que está acontecendo neste código:
Memória Paramétrica:
- Aproveita o vasto conhecimento da LLM para gerar uma resposta abrangente, incluindo o fato crucial de que o bosão de Higgs dá massa a outras partículas. A LLM é “parametrizada” por seus extensos dados de treinamento.
Memória Não-Paramétrica:
- Realiza uma busca de similaridade no espaço vetorial, encontrando o documento mais relevante que responde diretamente à pergunta sobre a localização do GCH. Não sintetiza novas informações, simplesmente recupera o fato relevante.
Diferenças Chave:
| Feature | Parametric Memory | Non-Parametric Memory |
|---|---|---|
| Armazenamento de Conhecimento | codificado nos parâmetros do modelo (pesos) como representações aprendidas. | Armazenado diretamente como texto bruto ou outros formatos (por exemplo, embeddings). |
| Recuperação | Usa as capacidades gerativas do modelo para produzir texto relevante à consulta com base no conhecimento aprendido. | Envolve buscar documentos que sejam próximos à consulta (por exemplo, por similaridade ou correspondência de palavras-chave). |
| Flexibilidade | Altamente flexível e pode gerar respostas inovadoras, mas também pode criar ilusões (gerar informações incorretas). | Menos flexível, mas menos propenso a criar ilusões, pois depende de dados existentes. |
| Estilo de Resposta | Pode produzir respostas mais elaboradas e nuances, mas potencialmente com mais informações irrelevantes. | Fornece respostas diretas e concisas, mas pode carecer de contexto ou elaboração. |
| Custo Computacional | Gerar respostas pode ser intensivo em termos computacionais, especialmente para modelos de grande porte. | A recuperação pode ser mais rápida, especialmente com索引eficientes e algoritmos de busca. |
Combinando as forças da memória paramétrica e não-paramétrica, o RAG aborda as limitações dos modelos de linguagem tradicionais e permite a geração de saídas mais precisas, atualizadas e relevantes contextualmente. (Redis, Lewis et al., e Guu et al.)
2.3 Multimodal RAG: Integrando Texto
O Multimodal RAG estende o paradigma tradicional baseado em texto do RAG, incorporando múltiplas modalidades de dados, como imagens, áudio e vídeo, para melhorar as capacidades de recuperação e geração de modelos de linguagem de grande porte (LLMs).
Utilizando técnicas de aprendizado contrastivo, os sistemas multimodais RAG aprendem a incorporar tipos de dados heterogêneos em um espaço vetorial compartilhado, permitindo uma recuperação cross-modal sem problemas. Isso permite que os LLMs reasonem sobre um contexto mais rico, combinando informações textuais com pistas visuais e auditivas para gerar saídas mais sutilmente nuances e relevantes contextualmente. (Shen et al.)
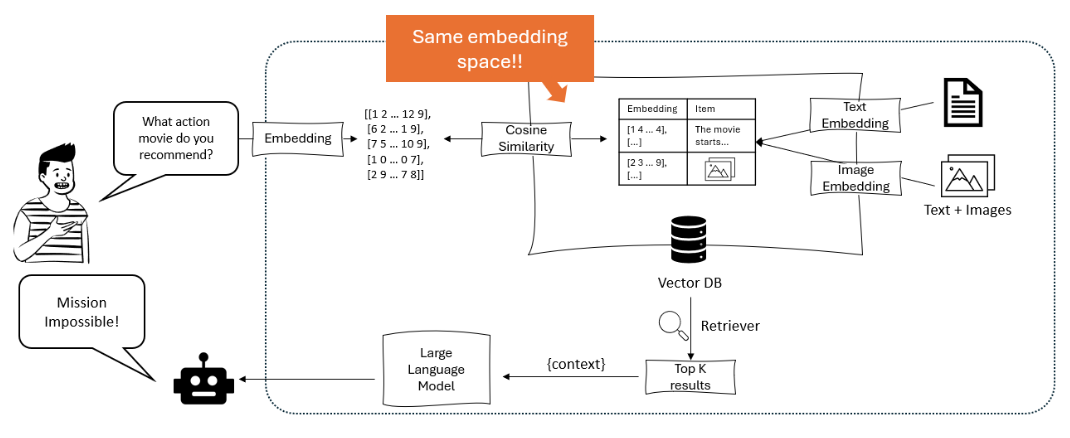
O diagrama ilustra um sistema de recomendação onde um grande modelo de linguagem processa a consulta de um usuário em embeddings, que são então comparados usando similaridade cosseno em um banco de dados vetorial contendo embeddings de texto e imagem, para recuperar e recomendar os itens mais relevantes. – opendatascience.com
Uma abordagem chave no RAG multimodal é o uso de modelos baseados em transformadores como ViLBERT e LXMERT que empregam mecanismos de atenção cruzada entre modalidades. Esses modelos podem focar em regiões relevantes em imagens ou segmentos específicos em áudio/vídeo enquanto geram texto, capturando interações detalhadas entre modalidades. Isso possibilita respostas mais visualmente e contextualmente fundamentadas. (Protecto.ai)
A integração de texto com outras modalidades em pipelines RAG envolve desafios como alinhar representações semânticas entre diferentes tipos de dados e lidar com as características únicas de cada modalidade durante o processo de embedding. Técnicas como codificação específica de modalidade e atenção cruzada são usadas para enfrentar esses desafios. (Zhu et al.)
Mas os benefícios potenciais do RAG multimodal são significativos, incluindo melhor precisão, controlabilidade e interpretabilidade do conteúdo gerado, além da capacidade de suportar novos casos de uso, como resposta a perguntas visuais e criação de conteúdo multimodal.
Por exemplo, Li et al. (2020) propuseram um framework multimodal RAG para responder questões visuais, que busca imagens relevantes e informações textuais para gerar respostas precisas, superando as melhores abordagens anteriores em benchmark como VQA v2.0 e CLEVR. (MyScale)
Apesar dos resultados promissores, o multimodal RAG também introduce novos desafios, como a complexidade computacional aumentada, a necessidade de grandes conjuntos de dados multimodais e o potencial para bias e ruído na informação retornada.
Pesquisadores estão ativamente explorando técnicas para mitigar esses problemas, como estruturas de índice eficientes, estratégias de aumento de dados e métodos de treinamento adversário. (Sohoni et al.)
Capítulo 3: Mecanismos Centrais de RAG
Este capítulo explora a complexa interação entre os recuperadores e modelos geradores em sistemas de Retrieval-Augmented Generation (RAG), destacando seus papéis cruciais em indexação, recuperação e síntese de informação para produzir respostas precisas e relevantes contextualmente.
Nós mergulhamos nas nuances das técnicas de recuperação dispersa e densa, comparando suas forças e fraquezas em diferentes cenários. Adicionalmente, examinamos diversas estratégias para integrar informação recuperada em modelos geradores, como concatenação e cross-attention, e discutimos seu impacto no efeito global de sistemas RAG.
Ao entender estas estratégias de integração, você terá insights valiosos sobre como otimizar sistemas RAG para tarefas e domínios específicos, pavimentando o caminho para um uso mais informado e efetivo deste poderoso paradigma.
3.1 O Poder de Combinar Recuperação e Geração de Informação em RAG
Retrieval-Augmented Generation (RAG) representa um paradigma poderoso que integra perfeitamente a recuperação de informação com modelos de linguagem gerativos. RAG é composto por dois componentes principais, como pode ser inferido de seu nome: Recuperação e Geração.
O componente de recuperação é responsável por indexar e buscar em um vasto repositório de conhecimento, enquanto o componente de geração utiliza a informação recuperada para produzir respostas contextualmente relevantes e factualmente precisas. (Redis e Lewis et al.)
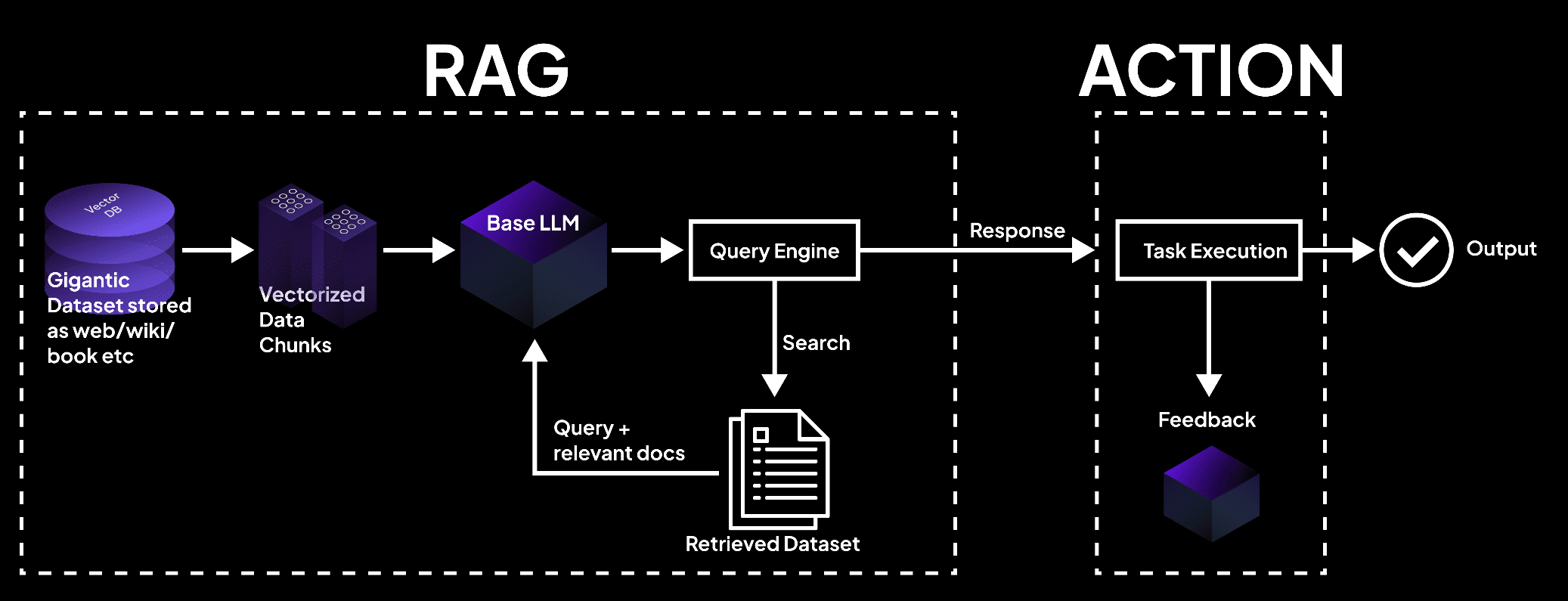
A imagem mostra um sistema RAG onde um banco de dados de vetores processa dados em pedaços, consultado por um modelo de linguagem para recuperar documentos para a execução de tarefas e saídas precisas. – superagi.com
O processo de recuperação começa com a indexação de fontes de conhecimento externos, como bases de dados, documentos e páginas da Web. (Redis e Lewis et al.) Recuperadores e indexadores desempenham um papel crucial neste processo, organizando e armazenando a informação de forma eficiente que facilite a busca rápida e a recuperação.
Quando uma questão é colocada ao sistema RAG, o recuperador busca pela base de conhecimento indexada para identificar as peças de informação mais relevantes com base na similaridade semântica e outras métricas de relevância.
Uma vez que a informação relevante for recuperada, a componente de geração assume o controle. O conteúdo recuperado é usado para prompt e guiar o modelo de linguagem gerativa, fornecendo-lhe com o contexto e o apoio fáctico necessários para gerar respostas precisas e informativas.
O modelo de linguagem emprega técnicas avançadas de inferência, como mecanismos de atenção e arquiteturas de transformador, para sintetizar a informação recuperada com o seu conhecimento pré-existente e gerar texto coeso e fluente.
O fluxo de informação dentro de um sistema RAG pode ser ilustrado da seguinte forma:
graph LR
A[Query] --> B[Retriever]
B --> C[Indexed Knowledge Base]
C --> D[Relevant Information]
D --> E[Generator]
E --> F[Response]
As vantagens do RAG são múltiplas:
Essa fusão de capacidades de recuperação e geração permite a criação de respostas que são não só apropriadas no contexto, mas também informadas pela informação mais atual e precisa disponível. (Guu et al.)
Ao aproveitar fontes de conhecimento externas, o RAG reduz significativamente a incidência de alucinações ou saídas factualmente incorretas, pitfalls comuns em modelos puramente gerativos.
Além disso, o RAG permite a integração de informações atualizadas, garantindo que as respostas geradas refletem o último conhecimento e os desenvolvimentos em um determinado domínio. Isso é particularmente crucial em campos como saúde, finanças e pesquisa científica, onde a precisão e a timidez da informação são de suma importância. (Guu et al. e NVIDIA)
O RAG também apresenta adaptação remarcável, permitindo que modelos de linguagem lidam com uma ampla variedade de tarefas com melhor desempenho. Ao retornar informações relevantes dinamicamente com base na consulta específica ou no contexto, o RAG capacita os modelos a gerar respostas personalizadas para as exigências únicas de cada tarefa, seja para respostas a questões, geração de conteúdo ou aplicações específicas de domínio.
Muitos estudos têm demonstrado a eficácia do RAG na melhoria da precisão factual, relevância e adaptabilidade de modelos de linguagem gerativa.
Lembra-se de Lews et al. (2020), que demonstrou que o RAG superou modelos gerativos puramente em uma variedade de tarefas de resposta a perguntas, alcançando resultados de estado-da-arte em benchmarks como Natural Questions e TriviaQA. (Lews et al.)
Da mesma forma, Izacard e Grave (2021) mostraram a superioridade do RAG sobre modelos de linguagem tradicionais na geração de texto de longa forma coerente e consistente factualmente.
A Geração Augmentada por Recuperação representa uma abordagem transformadora para a geração de linguagem, aproveitando o poder da recuperação de informação para melhorar a precisão, relevância e adaptabilidade de modelos gerativos.
Através da integração perfeita de conhecimento externo com capacidades linguísticas pré-existentes, o RAG abre novas possibilidades para o processamento de linguagem natural e pavimenta o caminho para sistemas de geração de linguagem mais inteligentes e confiáveis.
3.2 Estratégias de Integração do Recuperador-Gerador
Sistemas de Geração Augmentada por Recuperação (RAG) dependem de dois componentes chave: recuperadores e modelos gerativos. Recuperadores são responsáveis por buscar e recuperar eficientemente informações relevantes de bases de conhecimento em grande escala.
“Envolve duas fases principais, indexação e busca. A indexação organiza documentos para facilitar a recuperação eficiente, usando indexação invertida para recuperação esparsa ou codificação de vetor denso para recuperação densa.” (Redis)
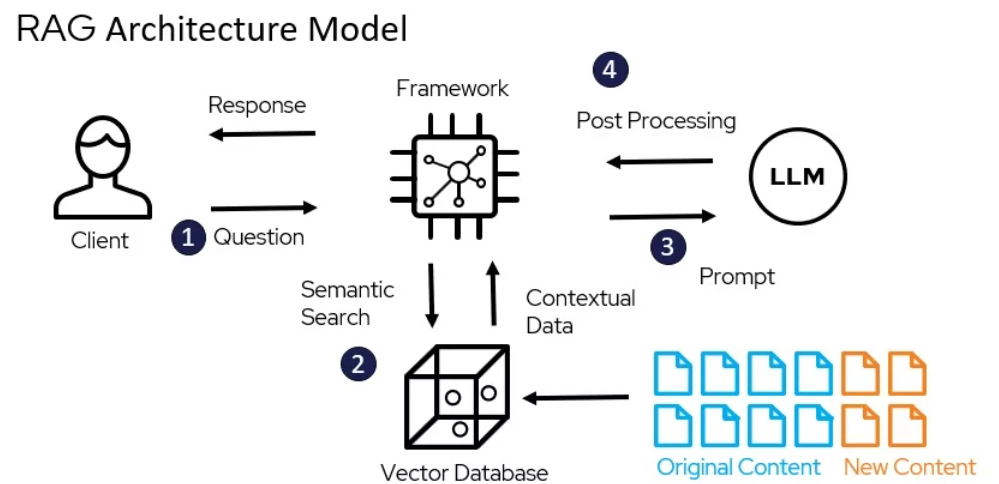
O Modelo de Arquitetura do RAG – miro.medium.com
Técnicas de recuperação esparsa, como TF-IDF e BM25, representam documentos como vetores esparsos de alta dimensão, onde cada dimensão corresponde a um termo único no vocabulário. A relevância de um documento para uma consulta é determinada pela sobreposição de termos, ponderada por sua importância.
Por exemplo, usando a popular biblioteca Elasticsearch, um recuperador baseado em TF-IDF pode ser implementado da seguinte forma:
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.index(index="documents", doc_type="_doc", body={"text": "This is a sample document."})
query = "sample"
results = es.search(index="documents", body={"query": {"match": {"text": query}}})
Técnicas de recuperação densa, como a recuperação de passagem densa (DPR) e modelos baseados em BERT, representam documentos e consultas como vetores densos em um espaço de incorporação contínua. A relevância é determinada pela similaridade cosseno entre os vetores de consulta e documento.
O DPR pode ser implementado usando a biblioteca Hugging Face Transformers:
from transformers import DPRContextEncoder, DPRQuestionEncoder
context_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
question_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
context_embeddings = context_encoder(documents)
query_embedding = question_encoder(query)
scores = torch.matmul(query_embedding, context_embeddings.transpose(0, 1))
Modelos generativos, como GPT e T5, são usados no RAG para gerar respostas coerentes e contextualmente relevantes com base nas informações recuperadas. Ajustar esses modelos em dados específicos do domínio e empregar técnicas de engenharia de prompts pode melhorar significativamente seu desempenho em sistemas RAG. (DEV Community)
Estratégias de integração determinam como o conteúdo recuperado é incorporado nos modelos generativos.
Componente de geração que utiliza o conteúdo recuperado para formular respostas coerentes e relevantes contextualmente nas fases de orientação e inferência. (Redis)
Duas abordagens comuns são a concatenação e a atenção cruzada.
A concatenação envolve anexar as passagens recuperadas à consulta de entrada, permitindo que o modelo gerativo atenda à informação relevante durante o processo de decodificação.
Embora simples de implementar, essa abordagem pode ter dificuldades com sequências longas e informação irrelevante. (DEV Community) Mecanismos de atenção cruzada, como RAG-Token e RAG-Sequence, permitem que o modelo gerativo atenda seletivamente às passagens recuperadas a cada etapa de decodificação.
Isso permite um controle mais fino sobre o processo de integração, mas vem com uma complexidade computacional maior.
Por exemplo, RAG-Token pode ser implementado usando a biblioteca Hugging Face Transformers:
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq")
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids)
generated_output = model.generate(input_ids, retrieved_docs=retrieved_docs)
A escolha do recuperador, modelo gerativo e estratégia de integração depende das exigências específicas do sistema RAG, como o tamanho e a natureza da base de conhecimento, o equilíbrio desejado entre eficiência e eficácia, e o domínio de aplicação alvo.
Capítulo 4: Aplicações e Casos de Uso
Este capítulo explora o potencial transformativo de Retrieval-Augmented Generation (RAG) na revolução de aplicações de linguagens de baixo recurso e multilíngue. Mergulhamos em estratégias como traduzir documentos fontes em línguas abastadas em recursos, utilizar embeddings multilíngues e aplicar aprendizado federado para superar limitações de dados e diferenças linguísticas.
Adicionalmente, abordamos o desafio crítico de mitigar as alucinações em sistemas RAG multilíngues para garantir a geração de conteúdo preciso e confiável. Explorando essas abordagens inovadoras, este capítulo oferece um guia abrangente para aproveitar o poder de RAG para inclusão e diversidade em processamento de linguagem.
4.1 Aplicações de RAG: QA para Redação Criativa
O Retrieval-Augmented Generation (RAG) encontrou numerosas aplicações práticas em vários domínios, mostrando seu potencial para revolucionar a forma como interagimos com e geramos informações. Ao aproveitar o poder da recuperação e da geração, os sistemas RAG mostraram melhorias significativas em precisão, relevância e engajamento do usuário.
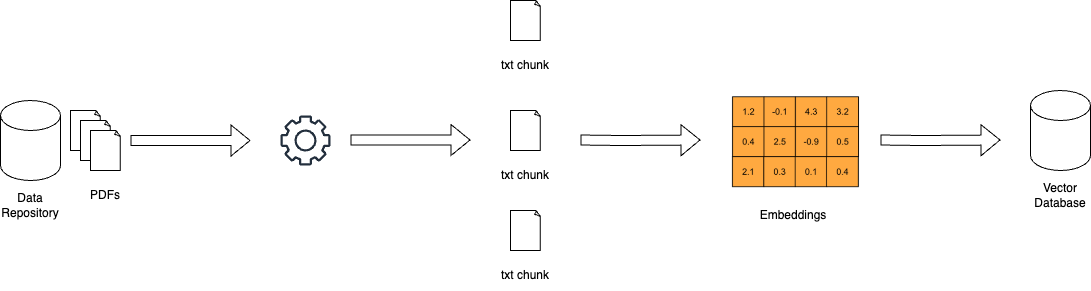
Como funciona o RAG – miro.medium.com
Pergunta e Resposta
O RAG já provou ser um game-changer no campo da resposta a perguntas. Retirando informações relevantes de fontes de conhecimento externas e integrando-as ao processo de geração, os sistemas RAG podem fornecer respostas mais precisas e relevantes no contexto às perguntas dos usuários. (LangChain e Django Stars)
Por exemplo, Izacard e Grave (2021) propuseram um modelo baseado em RAG chamado Fusion-in-Decoder (FiD), que alcançou o melhor desempenho até à data em várias bancadas de resposta a perguntas, incluindo Natural Questions e TriviaQA. (Izacard e Grave)
FiD aproveita um retriever denso para buscar passagens relevantes e um modelo gerativo para sintetizar a informação retirada em uma resposta coerente, superando os modelos gerativos puros com uma margem significativa. (Izacard e Grave)
Sistemas de Diálogo
RAG também encontrou aplicações na criação de agentes conversacionais mais engajantes e informativos. Incorporando conhecimento externo através de recuperação, sistemas de diálogo baseados em RAG podem gerar respostas que são não só apropriadas no contexto, mas também baseadas em fatos. (LlamaIndex e MyScale)
Shuster et al. (2021) apresentaram um sistema de diálogo baseado em RAG chamado BlenderBot 2.0, que demonstrou melhores habilidades conversacionais em comparação com seu predecessor. (Shuster et al.)
BlenderBot 2.0 recupera informações relevantes de um conjunto diversificado de fontes de conhecimento, incluindo a Wikipédia, artigos de notícias e mídias sociais, permitindo-lhe se engajar em conversas mais informadas e coerentes em uma ampla gama de tópicos. (Shuster et al.)
Resumo
O RAG mostrou promessas em melhorar a qualidade dos resumos gerados, incorporando informações relevantes de várias fontes. (Hyperight) Pasunuru et al. (2021) propuseram um modelo de resumo baseado em RAG chamado PEGASUS-X, que recupera e integra passagens relevantes de documentos externos para gerar resumos mais informativos e coerentes.
PEGASUS-X superou modelos puramente gerativos em vários benchmarks de resumo, demonstrando a eficácia da recuperação na melhoria da precisão factual e da relevância dos resumos gerados.
Escrita Criativa
O potencial do RAG vai além de domínios factuais e se estende ao reino da escrita criativa. Ao recuperar passagens relevantes de um corpus diversificado de obras literárias, sistemas RAG podem gerar histórias ou artigos novos e cativantes.
Rashkin et al. (2020) introduziram um modelo de escrita criativa baseado em RAG chamado CTRL-RAG, que recupera passagens relevantes de um dataset de ficção em grande escala e as integra ao processo de geração. O CTRL-RAG demonstrou a capacidade de gerar histórias coerentes e estilisticamente consistentes, mostrando o potencial do RAG em aplicações criativas.
Estudos de Caso
Vários artigos de pesquisa e projetos demonstraram a eficácia do RAG em vários domínios.
Por exemplo, Lewis et al. (2020) introduziram o framework RAG e o aplicaram à resposta a perguntas em domínio aberto, alcançando desempenho de estado-da-arte no benchmark Natural Questions. (Lewis et al.) Eles destacaram os desafios da recuperação eficiente e a importância da ajuste fino do modelo gerativo em passagens recuperadas.
Noutro caso de estudo, Petroni et al. (2021) aplicaram o RAG à tarefa de verificação de fatos, demonstrando sua capacidade de recuperar provas relevantes e gerar veredictos precisos. Eles mostraram o potencial do RAG na luta contra as informações erróneas e na melhoria da confiabilidade dos sistemas de informação.
O impacto do RAG na experiência do usuário e nas métricas de negócio tem sido significativo. Fornecendo respostas mais precisas e informativas, os sistemas baseados em RAG melhoraram a satisfação do usuário e a engajamento. (LlamaIndex e MyScale)
No caso de agentes conversacionais, o RAG permitiu interações mais naturais e coerentes, resultando em maior retenção de usuários e lealdade. (LlamaIndex e MyScale) No domínio da escrita criativa, o RAG tem o potencial para streamline o processo de criação de conteúdo e gerar ideias inovadoras, economizando tempo e recursos para as empresas.
Então, como podem ver, as aplicações práticas do RAG abrangem uma ampla gama de domínios, de respostas a perguntas e sistemas de diálogo a resumo e escrita criativa. Ao aproveitar o poder da recuperação e da geração, o RAG demonstrou melhorias significativas em precisão, relevância e engajamento do usuário.
Continuaremos a ver mais aplicações inovadoras de RAG à medida que o campo evolui, transformando a forma como interagimos e geramos informações em vários contextos.
4.2 RAG para Línguas de Baixo Recurso e Ambientes Multilingues
Aproveitando o poder da Geração Augmentada por Recuperação (RAG) para línguas de baixo recurso e ambientes multilingues não é apenas uma oportunidade — é uma necessidade. Com mais de 7.000 línguas faladas no mundo, muitas das quais carecem de recursos digitais substanciais, o desafio é claro: como garantimos que estas línguas não sejam deixadas para trás na era digital?
Tradução como uma Ponte
Uma estratégia efetiva é traduzir os documentos de origem para uma língua com mais recursos antes do indexação. Essa abordagem aproveita os extensos corpora disponíveis em línguas como o inglês, melhorando significamente a precisão e a relevância da recuperação.
Ao traduzir documentos para o inglês, você pode acessar os vastos recursos e técnicas avançadas de recuperação já desenvolvidas para línguas de alto recurso, melhorando assim o desempenho dos sistemas RAG em contextos de baixo recurso.
Embutidos Multilingues
Recentes avanços em embeddings de palavras multilingues oferecem outra solução promissora. Criando espaços de embedding compartilhados para várias línguas, você pode melhorar o desempenho cross-lingual mesmo para línguas muito de baixo recurso.
Pesquisas mostram que a incorporação de línguas intermediárias com embeddings de alta qualidade pode preencher a lacuna entre pares de línguas distantes, melhorando a qualidade geral dos embeddings multilingues.
Este método não apenas melhora a precisão de recuperação mas também garante que o conteúdo gerado seja contextualmente relevante e linguísticamente coerente.
Aprendizado Federado
O aprendizado federado apresenta uma abordagem inovadora para superar as limitações de divulgação de dados e as diferenças linguísticas. Ao refinando modelos theorizando fontes de dados descentralizadas, você pode preservar a privacidade do usuário enquanto melhora o desempenho do modelo em várias línguas.
Este método demonstrou uma acurácia 6,9% superior e uma redução de 99% nos parâmetros de treinamento em relação aos métodos tradicionais, tornando-se uma solução altamente eficiente e efetiva para os sistemas RAG multilíngue.
Mitigação de Ilusões
Um dos desafios críticos na implantação de sistemas RAG em ambientes multilíngues é a mitigação de ilusões – instâncias em que o modelo gera informação factualmente incorreta ou irrelevante.
Técnicas avançadas de RAG, como o RAG Modular, introduzem novos módulos e estratégias de refinamento para address this issue. By continuously updating the knowledge base and employing rigorous evaluation metrics, you can significantly reduce the incidence of hallucinations and ensure the generated content is both accurate and reliable.
Implementação Prática
Para implementar estas estratégias efetivamente, considere os seguintes passos práticos:
- Aproveite a Tradução: Traduzir documentos de línguas com recursos baixos em uma língua com recursos altos, como o inglês, antes de indexar.
- Usar Embedimentos Multilíngue: Incorporar idiomas intermediários com embedimentos de alta qualidade para melhorar o desempenho cross-lingual.
- Adotar Aprendizado Federal: Ajustar modelos em fontes de dados descentralizadas para melhorar o desempenho enquanto preservam a privacidade.
- Mitigar Ilusões: Empregar técnicas avançadas RAG e atualizações contínuas de base de conhecimento para garantir a precisão factual.
Ao adotar estas estratégicas, você pode melhorar significativamente o desempenho dos sistemas RAG em ambientes de recurso baixo e multilíngue, garantindo que nenhuma língua esteja de fora da revolução digital.
Capítulo 5: Técnicas de Otimização
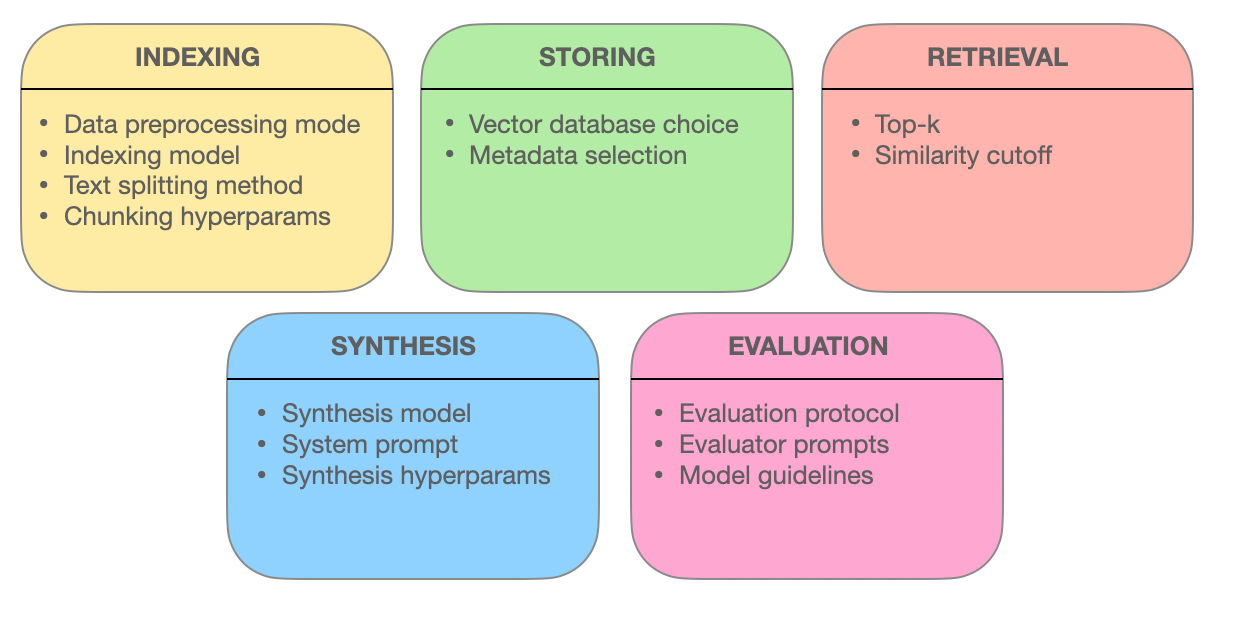
Este capítulo explora as técnicas avançadas de recuperação que subestão a eficácia dos sistemas RAG (Retrieval-Augmented Generation). Nós exploramos como a otimização de blocos, integração de metadados, indexação baseada em grafos, técnicas de alinhamento, busca híbrida e reordenação melhoram a precisão, relevância e abrangência da recuperação de informação.
Ao entender essas metodologias de ponta, você ganhará insights sobre como os sistemas RAG estão evoluindo de simples motores de busca para fornecedores inteligentes de informação capazes de entender consultas complexas e entregar respostas precisas e relevantes no contexto.
5.1 Técnicas Avançadas de Recuperação para Otimizar Sistemas RAG
Sistemas RAG (Retrieval Augmented Generation) estão revolucionando a maneira como acessamos e utilizamos informação. O cerne destes sistemas está em sua habilidade de recuperar informação relevante efetivamente.
Vamos mergulhar mais fundo nas técnicas avançadas de recuperação que empoderam os sistemas RAG a entregar respostas precisas, relevantes contextualmente e abrangentes.
Optimização de Chunk: Maximizando a Relevância Através da Recuperação Granular
No mundo dos sistemas RAG, documentos extensos podem ser intimidadores. A optimização de chunk resolve esse desafio ao quebrar textos extensos em unidades menores e mais gerenciáveis chamadas chunks. Esta granularidade permite que os sistemas de recuperação apontem seções específicas de texto que se alinham com os termos da consulta, melhorando a precisão e a eficiência.
A arte da optimização de chunk reside em determinar o tamanho ideal de chunk e a sobreposição. Um chunk muito pequeno pode lack de contexto, enquanto um chunk muito grande pode diluir a relevância. A chunking dinâmico, uma técnica que adapta o tamanho do chunk com base na estrutura e semântica do conteúdo, garante que cada chunk seja coeso e significativo contextualmente.
Integração de Metadados: Aproveitando o Poder das Tags de Informação
Metadados, a informação frequentemente negligenciada que acompanha documentos, pode ser uma mina de ouro para sistemas de recuperação. Ao integrar metadados como tipo de documento, autor, data de publicação e tags de tópico, os sistemas RAG podem realizar buscas mais direcionadas.
A recuperação de autoconsulta, uma técnica habilitada pela integração de metadados, permite que o sistema gere consultas adicionais com base nos resultados iniciais. Esse processo iterativo refina a busca, garantindo que os documentos recuperados não apenas correspondam à consulta, mas também atendam às necessidades específicas do usuário e às necessidades contextuais.
Estruturas de Indexação Avançadas: Redes Baseadas em Gráfico para Consultas Complexas
Métodos de indexação tradicionais, como índices invertidos e codificações de vetores densos, têm limitações quando lidam com consultas complexas que envolvem várias entidades e suas relações. Índices baseados em grafos oferecem uma solução organizando documentos e suas conexões em uma estrutura de grafo.
Essa organização de grafo permite uma busca e recuperação eficientes de documentos relacionados, mesmo em situações complexas. A indexação hierárquica e a busca de vizinhos mais próximos aproximados melhoram a escalabilidade e a velocidade dos sistemas de recuperação baseados em grafos.
Técnicas de Alinhamento: Garantindo Exatidão e Reduzindo Ilusões
A credibilidade dos sistemas RAG depende de sua capacidade de fornecer informações precisas. Técnicas de alinhamento, como treinamento contrafáctico, abordam essa preocupação. Exposto ao modelo a situações hipotéticas, o treinamento contrafáctico o ensina a distinguir entre fatos do mundo real e informações geradas, reduzindo assim as ilusões.
Em sistemas RAG multimodais, que integram informações de várias fontes, como texto e imagens, o aprendizado contrastivo desempenha um papel crucial. Esta técnica alinha as representações semânticas de diferentes modalidades de dados, garantindo que a informação recuperada seja coesa e integrada contextualmente.
Pesquisa Híbrida: Fundindo Precisão em Palavras-Chave com Compreensão Semântica
A pesquisa híbrida combina o melhor de ambos mundos: a velocidade e a precisão da pesquisa por palavras-chave com o entendimento semântico da pesquisa por vetores. Inicialmente, uma pesquisa por palavras-chave rapidamente encolhe o conjunto de documentos potenciais.
plaintext
Subsequentemente, uma busca baseada em vetores refinada os resultados com base na similaridade semântica. Esta abordagem é particularmente efetiva quando as correspondências exatas de palavras-chave são essenciais, mas também é necessário um entendimento mais profundo da intenção da consulta para a recuperação precisa.
Reclassificação: Aperfeiçoando a Relevância para a Resposta Ótima
Na fase final da recuperação, a reclassificação entra para ajustar os resultados. Modelos de aprendizado de máquina, como cross-encoders, reavaliam as pontuações de relevância dos documentos recuperados. Processando a consulta e os documentos juntos, esses modelos adquirem um entendimento mais profundo de sua relação.
Essa comparação sutil garante que os documentos melhor ranqueados estejam verdadeiramente alinhados com a consulta e o contexto do usuário, proporcionando uma experiência de busca mais satisfatória e informativa.
O poder dos sistemas RAG reside em sua capacidade de recuperar e apresentar informações sem problemas. Ao utilizar essas técnicas avançadas de recuperação – otimização de trechos, integração de metadados, indexação baseada em grafos, técnicas de alinhamento, busca híbrida e reclassificação – os sistemas RAG tornam-se mais do que meros motores de busca. Eles se tornam provedores inteligentes de informação, capazes de compreender consultas complexas, discernir nuances e entregar respostas precisas, relevantes e confiáveis.
Capítulo 6: Desafios e Inovações
Este capítulo explora os desafios críticos e as direções futuras no desenvolvimento e implantação de sistemas de Geração Aumentada com Recuperação (RAG).
Exploramos as complexidades da avaliação de sistemas RAG, incluindo a necessidade de métricas abrangentes e frameworks adaptativos para avaliar sua performance de forma precisa. Também abordamos considerações éticas, como a mitigação de viés e a justiça na recuperação e geração de informações.
Além disso, examinamos a importância da aceleração de hardware e das estratégias de implantação eficientes, destacando o uso de hardware especializado e ferramentas de otimização, como o Optimum, para melhorar o desempenho e a escabilidade.
Ao compreender esses desafios e explorar soluções potenciais, este capítulo fornece um roteiro abrangente para o avanço contínuo e a implementação responsável da tecnologia RAG.
6.1 Desafios e Direções Futuras
Os sistemas de Geração Aumentada com Recuperação (RAG) têm demonstrado um potencial notável em melhorar a precisão, relevância e coerência do texto gerado. No entanto, o desenvolvimento e a implantação de sistemas RAG também apresentam desafios significativos que precisam ser endereçados para fully aproveitar seu potencial.
“A avaliação de sistemas RAG envolve considerar vários componentes específicos e a complexidade da avaliação geral do sistema.” (Salemi et al.)
Desafios na Avaliação de Sistemas RAG
Um dos principais desafios técnicos em RAG é garantir a recuperação eficiente de informações relevantes a partir de bases de conhecimento em larga escala. (Salemi et al. e Yu et al.)
À medida que o tamanho e a diversidade das fontes de conhecimento continuam a crescer, desenvolver mecanismos de recuperação escaláveis e robustos se torna cada vez mais crítico. Técnicas como indexação hierárquica, pesquisa de vizinho aproximado e estratégias de recuperação adaptativa precisam ser exploradas para otimizar o processo de recuperação.
Alguns dos elementos envolvidos em um Sistema RAG – miro.medium.com
Outro desafio significativo é mitigar o problema da halucinação, em que o modelo gerador produz informações factualmente incorretas ou inconsistentes.
Por exemplo, um sistema RAG pode gerar um evento histórico que nunca ocorreu ou atribuir incorretamente um descobrimento científico. Embora a recuperação ajude a fundamentar o texto gerado em conhecimento factual, garantir a fidelidade e a coerência da saída gerada permanece um problema complexo.
Por exemplo, um sistema RAG pode recuperar informações precisas sobre um descobrimento científico de uma fonte confiável como a Wikipedia, mas o modelo gerador ainda pode halucinar ao combinar essa informação incorretamente ou adicionar detalhes inexistentes.
Desenvolvendo mecanismos eficazes para detectar e prevenir alucinações é um campo de pesquisa ativo. Técnicas como a verificação de fatos usando bases de dados externas e a verificação de consistência através de referências cruzadas de várias fontes estão sendo exploradas. Esses métodos visam garantir que o conteúdo gerado permaneça preciso e confiável, apesar dos desafios inerentes ao alinhamento dos processos de recuperação e geração.
A integração de fontes de conhecimento diversas, como bases de dados estruturadas, texto não estruturado e dados multimodais, apresenta desafios adicionais em sistemas RAG. (Yu et al. e Zilliz) Alinhar as representações e semânticas entre diferentes modalidades de dados e formatos de conhecimento exige técnicas sofisticadas, como atenção cruzada e embedding de grafos de conhecimento. Garantir a compatibilidade e interoperabilidade de várias fontes de conhecimento é crucial para o funcionamento eficaz de sistemas RAG. (Zilliz)
Além das challenges técnicas, os sistemas RAG também levantam considerações éticas importantes. Garantir a recuperação e geração de informações justas e sem viés é uma preocupação crítica. Os sistemas RAG podem inadvertidamente amplificar os viéses presentes nos dados de treinamento ou nas fontes de conhecimento, levando a saídas discriminatórias ou enganadoras. (Além das challenges técnicas, os sistemas RAG também levantam considerações éticas importantes. Garantir a recuperação e geração de informações justas e sem viés é uma preocupação crítica. Os sistemas RAG podem inadvertidamente amplificar os viéses presentes nos dados de treinamento ou nas fontes de conhecimento, levando a saídas discriminatórias ou enganadoras. (Salemi et al. e Banafa)
Desenvolver técnicas para detectar e mitigar viéses, como treinamento adversário e recuperação ciente da equidade, é uma importante direção de pesquisa. (Banafa)
Direções de Pesquisa Futuras
Para abordar os desafios na avaliação de sistemas RAG, várias soluções potenciais e direções de pesquisa podem ser exploradas.
Desenvolver métricas de avaliação abrangentes que capturam a interação entre a precisão na recuperação e a qualidade gerativa é crucial. (Salemi et al.)
Métricas que avaliam a relevância, coerência e corretude factual do texto gerado, considerando ao mesmo tempo a eficácia do componente de recuperação, precisam ser estabelecidas. (Salemi et al.) Isso requer uma abordagem holística que transcende as métricas tradicionais como BLEU e ROUGE e incorpora avaliação humana e medidas específicas de tarefa.
Explorar frameworks de avaliação adaptativa e em tempo real é outra direção promissora.
Sistemas RAG operam em ambientes dinâmicos onde as fontes de conhecimento e os requisitos do usuário podem evoluir ao longo do tempo. (Yu et al.) Desenvolver frameworks de avaliação que possam se adaptar a essas mudanças e fornecer feedback em tempo real sobre o desempenho do sistema é essencial para melhoria contínua e monitoramento.
Isso pode envolver técnicas como aprendizado online, aprendizado ativo e aprendizado por reforço para atualizar as métricas de avaliação e modelos com base na feedback do usuário e no comportamento do sistema. (Yu et al.)
Esforços colaborativos entre pesquisadores, profissionais da indústria e especialistas do domínio são necessários para avançar no campo de avaliação de RAG. A estabelecimento de benchmarks padronizados, conjuntos de dados e protocolos de avaliação pode facilitar a comparação e a reprodutibilidade de sistemas RAG em diferentes domínios e aplicações. (Salemi et al. e Banafa)
Interagir com stakeholders, incluindo usuários finais e legisladores, é crucial para garantir que o desenvolvimento e o deploy de sistemas RAG estejam alinhados com valores sociais e princípios éticos. (Banafa)
Embora os sistemas RAG tenham mostrado um imenso potencial, abordar os desafios em sua avaliação é crucial para sua adoção generalizada e confiança. Desenvolvendo métricas de avaliação abrangentes, explorando frameworks de avaliação adaptativos e em tempo real, e fomentando esforços colaborativos, podemos pavimentar o caminho para sistemas RAG mais confiáveis, imparciais e eficazes.
À medida que o campo continua a evoluir, é essencial priorizar esforços de pesquisa que avancem não só as capacidades técnicas de RAG, mas também assegurem seu deploy responsável e ético em aplicações do mundo real.
6.2 Aceleração de Hardware e Deploy eficiente de sistemas RAG
Aproveitamento de aceleração de hardware é fundamental para a implantação eficiente de sistemas de Geração Aumentada por Recuperação (RAG). Transferindo tarefas computacionalmente intensivas para hardware especializado, você pode melhorar significativamente o desempenho e a escalabilidade dos modelos RAG.
Aproveitar o Hardware Especializado
As ferramentas de otimização específica para hardware da Optimum oferecem benefícios substanciais. Por exemplo, a implantação de sistemas RAG em processadores Habana Gaudi pode resultar em uma redução notável na latência de inferência, enquanto as otimizações do Intel Neural Compressor podem melhorar ainda mais os indicadores de latência. O hardware AWS Inferentia, optimizado através do Optimum Neuron, pode melhorar as capacidades de throughput, tornando seu sistema RAG mais responsivo e eficiente.
Otimizar o Uso de Recursos
O uso eficiente de recursos é crucial. As otimizações do Optimum ONNX Runtime podem resultar em uso de memória mais eficiente, enquanto a API BetterTransformer pode melhorar a utilização de CPU e GPU. Essas otimizações garantem que seu sistema RAG operará com máxima eficiência, reduzindo custos operacionais e melhorando o desempenho.
Escalabilidade e Flexibilidade
A Optimum oferece uma transição fácil entre diferentes aceleradores de hardware, permitindo escalabilidade dinâmica. Essa suporte a vários hardware permite que você adapte-se a demandas computacionais variantes sem reconfiguração significativa. Além disso, as funcionalidades de quantização e redução de modelos em Optimum podem facilitarem tamanhos de modelo mais eficientes, tornando a implantação mais fácil e econômica.
Estudos de Casos e Aplicações do Mundo Real
Considere a aplicação de Optimum em busca de informação de saúde. Ao aproveitar otimizações específicas para hardware, os sistemas RAG podem lidar com grandes conjuntos de dados de forma eficiente, fornecendo busca de informação precisa e oportuna. Isso não só melhora a qualidade do atendimento médico quanto melhora a experiência do usuário globalmente.
Passos Práticos para Implementação
- Selecione Hardware Apropriado: Escolha aceleradores de hardware como o Habana Gaudi ou AWS Inferentia com base nas suas necessidades de desempenho específicas.
- Utilize Ferramentas de Otimização: Implemente as ferramentas de otimização do Optimum para melhorar a latência, a throughput e a utilização de recursos.
- Garantir Escalabilidade: Aproveite o suporte a vários hardware para dimensionar dinamicamente o seu sistema RAG de forma necessária.
- Otimizar o Tamanho do Modelo: Use a quantização e o recorte de modelos para reduzir o sobrecarga computacional e facilitar o deploy.
Ao integrar essas estratégias, você pode melhorar significativamente o desempenho, a escalabilidade e a eficiência de seus sistemas RAG, garantindo que eles estejam bem equipados para lidar com aplicações complexas e reais.
Conclusão: O Potencial Transformativo do RAG
A Retrieval-Augmented Generation (RAG) representa um paradigma transformativo em processamento de linguagem natural, integrando de forma natural o poder de busca de informação com as capacidades geradoras de grandes modelos de linguagem.
pt-br
Através da utilização de fontes externas de conhecimento, os sistemas RAG têm demonstrado melhorias notáveis em termos de precisão, relevância e coerência do texto gerado em uma ampla gama de aplicações, desde respostas a perguntas e sistemas de diálogo a resumos e escrita criativa.
A evolução dos modelos de linguagem, dos primeiros sistemas baseados em regras aos arquiteturas neurais de estado-da-arte como BERT e GPT-3, abriu caminho para a emergência de RAG. As limitações da memória puramente paramétrica em modelos de linguagem tradicionais, tais como datas de corte de conhecimento e inconsistências factuais, foram efetivamente endereçadas pela incorporação de memória não-paramétrica por meio de mecanismos de recuperação.
Os componentes centrais dos sistemas RAG, nomeadamente os recuperadores e modelos gerativos, funcionam em sinergia para produzir saídas contextualmente relevantes e baseadas em fatos.
Os recuperadores, empregando técnicas como recuperação esparsa e densa, buscam eficientemente através de vastas bases de conhecimento para identificar a informação mais pertinente. Modelos gerativos, aproveitando arquiteturas como GPT e T5, sintetizam o conteúdo recuperado em texto coerente e fluente.
As estratégias de integração, como concatenação e atenção cruzada, determinam como a informação recuperada é incorporada no processo de geração.
As aplicações práticas de RAG se estendem a diversos domínios, demonstrando seu potencial para revolucionar várias indústrias.
No question answering, o RAG melhorou significativamente a precisão e relevância das respostas, permitindo mais informação e informação confiável de busca. Sistemas de diálogo têm se beneficiado com o RAG, resultando em conversas mais interessantes e coerentes. Tarefas de resumo têm visto qualidade e coerência melhoradas através da integração de informações relevantes de várias fontes. Até mesmo a escrita criativa foi explorada, com sistemas RAG gerando históriasnovas e estilisticamente consistentes.
Mas o desenvolvimento e avaliação de sistemas RAG também apresentam desafios significativos. A recuperação eficiente de bases de conhecimento em larga escala, a mitigação de ilusões e a integração de diferentes modalidades de dados são entre os problemas técnicos que precisam ser resolvidos. Considerações éticas, como garantir que a recuperação e geração de informações sejam imparciales e justas, são cruciais para o uso responsável de sistemas RAG.
Para realizar plenamente o potencial do RAG, as direções de pesquisa futuras devem se concentrar no desenvolvimento de metricas de avaliação abrangentes que capturam a interação entre a precisão de recuperação e a qualidade de geração.
Frameworks de avaliação adaptativa e em tempo real que conseguem lidar com a natureza dinâmica de sistemas RAG são essenciais para melhoria contínua e monitoramento. Esforços colaborativos entre pesquisadores, profissionais da indústria e expertos em domínio são necessários para estabelecer padrões, bases de dados e protocolos de avaliação.
Enquanto o campo da RAG continua a evoluir, ele guarda um imenso potencial para transformar a forma como interagimos com e geramos informação. Ao aproveitar o poder da recuperação e da geração, os sistemas RAG têm a potência de revolucionar vários domínios, desde a recuperação de informação e os agentes conversacionais até a criação de conteúdo e a descoberta de conhecimento.
A representação Retrieval-Augmented Generation é um marco significativo no caminho para uma linguagem gerada mais inteligente, exata e relevante contextualmente.
Ao atingir a ligação entre a memória paramétrica e não-paramétrica, os sistemas RAG abriram novas possibilidades para o processamento de linguagem natural e suas aplicações.
Com o progresso da pesquisa e a resolução dos desafios, podemos esperar que a RAG desempenhe um papel cada vez mais central na formação do futuro da interação humano-máquina e da geração de conhecimento.
Sobre o Autor
Vahe Aslanyan aqui, no núcleo da computação, ciências de dados e AI. Visite vaheaslanyan.com para ver um portfólio que é uma testemunha da precisão e do progresso. Minha experiência atua como ponte entre o desenvolvimento full-stack e a otimização de produtos AI, movido pelo problema de resolução de novas maneiras.
Com um histórico que inclui a criação de um principal bootcamp de ciências de dados e trabalhando com especialistas de topo na indústria, o meu foco permanece em elevar a educação tecnológica a padrões universais.
Como você pode mergulhar mais fundo?
Após estudar este guia, se você estiver interessado em mergulhar ainda mais fundo e o estilo de aprendizagem estruturado for sua preferência, considere se juntar a nós no LunarTech, onde oferecemos cursos individuais e Bootcamp em Ciências de Dados, Aprendizagem Automática e Inteligência Artificial.
Nós fornecemos um programa abrangente que oferece um entendimento profundo da teoria, implementação prática de mão na massa, material de prática extensivo e preparação de entrevista personalizada para colocar você no caminho para o sucesso em sua própria fase.
Confira nosso Bootcamp de Ciência de Dados Ultimate e participe de uma avaliação gratuita para experimentar o conteúdo de primeira mão. Esse curso tem a distinção de ser um dos Melhores Bootcamps de Ciência de Dados de 2023 e foi destaque em publicações renomadas como a Forbes, Yahoo, Empreendedor e mais. Esta é sua chance de fazer parte de uma comunidade que se baseia na inovação e no conhecimento. Aqui está a mensagem de boas-vindas!
Conecte-se comigo.

LunarTech Newsletr
- Siga comigo no LinkedIn para acessar muitos Recursos Grátis em CS, ML e AI
- Visite o Meu Site Pessoal
- Inscreva-se em minha Newsletter de Ciência de Dados e AI
Se você quiser saber mais sobre uma carreira em Ciência de Dados, Aprendizagem Automática e AI, e aprender a conseguir um emprego de Data Science, você pode baixar este Guia de Carreira de Ciência de Dados e AI grátis.
Source:
https://www.freecodecamp.org/news/retrieval-augmented-generation-rag-handbook/