













تعني إيجاد التطوير التحولي في نماذج اللغات الكبيرة (النماذج اللغوية الكبيرة). يتمدّد هذا الإدماج من القدرة الإبداعية للتخطيطات المحورية بالإشباع التفاعلي للبحث في المعلومات.
هذا التركيب يسمح للنماذج اللغوية الكبيرة بالوصول إلى وإشمال معلومات خارجية مناسبة خلال توليد النصوص، مما ينتج عندها منتجات أكثر دقة وتناسبا واتماما في الحقائق.
تطور من الأنظمة القائمة على القوانين البدئية إلى النماذج العصبية المتقدمة مثل BERT و GPT-3 قدم الطريق لـ RAG، معالجاً تعالي للحدود التي يمثلها الذاكرة الثابتة المتغيرة. أيضًا ظهور متعدد الوسائط المتكاملة من RAG يقوم بتوسيع هذه القدرات بتضمين أنواع متنوعة من البيانات مثل الصور والصوت والفيديو. هذا يحسن الغاية والتناسب في المحتويات المنتجة.
هذه التحولة في المفهوم تحسين دقة وقابلية تفسير الناتجين للنماذج اللغوية الكبيرة وتدعم تطوير تطبيقات مبتكرة في مجالات مختلفة.
هذا ما سنتمكن من تغطيته:
- الفصل 1. معرفة RAG
– 1.1 ما هو RAG؟ تعرف عنه
– 1.2 كيف يحل RAG المشاكل المعقدة - الفصل 2. الأسس التقنية
– 2.1 تحويل من نظم الكتابة العصبية الى RAG
– 2.2 فهم ذاكرة RAG: المتغيرات versus الغير المتغيرات
– 2.3 RAG المتعدد الأنماط: دمج الأنواع المختلفة من البيانات - الفصل 3. الآليات الأساسية
– 3.1 قوة تركيب البحث عن المعلومات والتوليد في RAG
– 3.2 استراتيجيات التكامل للبحثين والمنتجين - الفصل 4. التطبيقات والحالات المستخدمة
– 4.1 RAG في العمل: من التساؤل الإجابي إلى الكتابة الإبداعية
– 4.2 RAG لللغات النادرة: توسيع المجال والقدرات - الفصل 5. تقنيات التحسين
– 5.1 تقنيات استخراج متقدمة لتحسين نظم RAG - الفصل 6. التحديات والإبتكارات
– 6.1 التحديات الحالية والاتجاهات المستقبلية لنظم RAG
– 6.2 تسريع ال hardware وتنصيب فعال لنظم RAG - الفصل 7. خاطرات الانتهاء
– 7.1 مستقبل RAG: خاطرات واعتبارات
المقاربات السابقة
للتفاعل مع المحتوى المركزي على النماذج الكبيرة للنظم (النماذج الذاتية التعاملية) مثل RAG، يوجد بحاجة إلى مقاربتين أساسيتين:
- أساسات التعلم الماكيني: وفر فهم المبادئ الأساسية للتعلم الماكيني والخوارزميات من الأهمية، وخاصة كما يتمتع بها الأنظمة العصبية التي تتطلب.
- المعالجة العالمية لللغة (NLP): معرفة تقنيات NLP ، بما فيها معالجة تحريك النصوص ، توزيع الكلمات واستخدام التركيبات ، مهم للعمل مع نماذج اللغة.
الفصل 1: مقابلة بالRAG
تغيير التصدير المساعد على البحث (RAG) يحدث تحولًا في المعالجة العالمية لللغة من خلال تحالف البحث الخارجي والنماذج الإلهامية. يتوفر RAG على وصول ديناميكي إلى المعرفة الخارجية ، مما يزيد من دقة وتناسب النصوص المنتجة.
يتم في هذا الفصل استكشاف آليات RAG والمزايا والتحديات. نتعمق في تقنيات البحث الخارجي ، دمجها مع النماذج الإلهامية والتأثير في التطبيقات المختلفة.
RAG يخفيف الهلوسات ، يدمج المعلومات الحديثة ويوصل إلى حلول معقدة. نتحدث أيضًا عن التحديات مثل البحث الفعال والأحداث الأخلاقية. هذا الفصل يوفر فهم شامل للقدرة التحولية لRAG في المعالجة العالمية لللغة.
1.1 ما هو RAG؟ تعريف
Retrieval-Augmented Generation (RAG) تمثل تحولًا في المعالجة العالمية لللغة بتوافد القوانين الخاصة بتكامل قوانين البحث الخارجي ونماذج اللغة الإلهامية. تستخدم نظم RAG المعرفة الخارجية لتحسين دقة وتناسب النصوص المنتجة والتوافق ، تعالجًا قصورًا الذي يحدث في نماذج اللغة التقليدية بسيطة بسبب ذاكرة المحددات الإلهامية فقط. (Lewis et al., 2020)
بواسطة التوافر الديناميكي ودمج المعلومات المتعلقة أثناء عملية توليد المخرجات، يمكن لراغ (RAG) توفير منهجيات وصف وطبيعة تتماشى بالسياق الكلامي والدقيق والمتوافقة مع الحقائق في مجموعة واسعة من التطبيقات، من الإجابة عن الأسئلة والأنظمة التحدثية إلى التوصيف والكتابة الإبداعية. (Petroni et al., 2021)
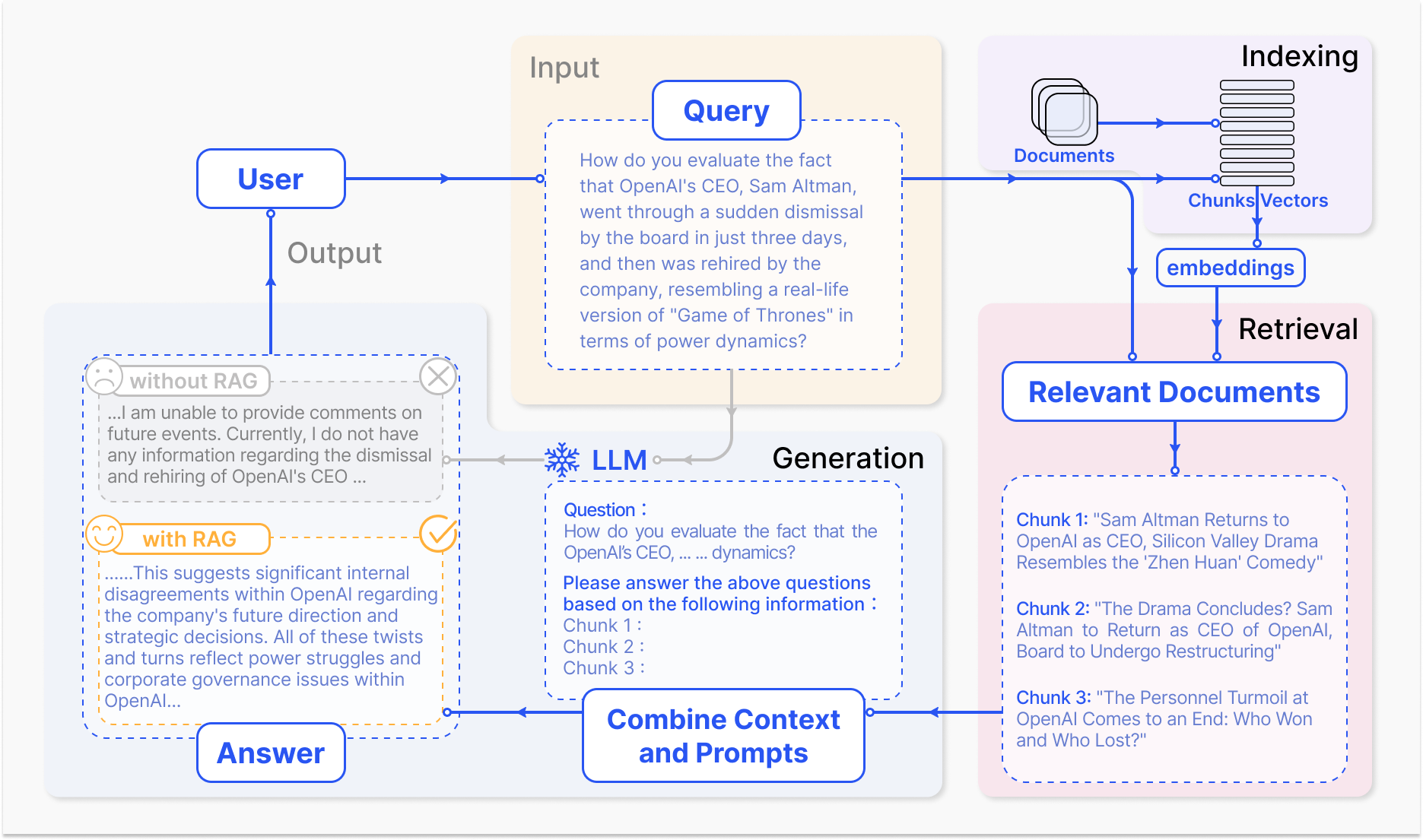
كيف تعمل نظام RAG – arxiv.org
الآلية الأساسية لراغ (RAG) تشمل عناصران رئيسيتان: البحث والتوليد.
المكون الأول يبحث بفعالية في البases المدروسة للتعرف على المعلومات الأكثر pertinence وفقاً للتعاون الإدخالي أو السياق. تستخدم تقنيات مثل البحث القليل المستخدمة، التي تستخدم في الفهرسات المعكوسة وما يتم بموجبه موافقة المعاني، والبحث الكثيف، الذي يستخدم تمثيلات فيديو كمية كبيرة وتشمل تشابه المعاني. تم تطبيق هذه التقنيات لتحسين عملية البحث. (Karpukhin et al., 2020)
يتم بعدها دمج المعلومات المتوفرة في نموذج التوليد العام بالكلام، مثل (GPT) أو (T5), الذي يتم تركيب المحتوى المتعلق في رد المتوافق والمنظم. (Izacard & Grave, 2021)
تكامل توفير وتوليد في RAG يقدم من المزيد من الممارسات عن نماذج النماذج اللغوية التقليدية. بتوليد النص الموجود بالمعرفة الخارجية، يقلل RAG بشكل كبير عدد الحالات التي ينتج منها الهلوسات أو الناساء الخاطئة من المعلومات. (Shuster et al., 2021)
يسمح أيضًا لRAG بتدمير المعلومات الحديثة، ويضمن أن الردود التي تنتج تتماشى مع أحدث المعلومات والتطورات في مجال معين. (Lewis et al., 2020) هذا التكيف مهم للمجالات التي تشمل الرعاية الصحية والمالية والبحث العلمي، حيث يحمل المعلومات الدقة والوقت المناسب الأولوية. (Petroni et al., 2021)
لكن تطوير وتنفيذ أنظمة RAG يعكس أيضًا تحديات كبيرة. البحث الفعال في قواعد المعرفة الكبيرة النموذجية، وتخفيض الهلوسات، وتدمير المواد المختلفة هي من هذه العقبات التقنية التي يتوجب على الموظفين إلتقاءها. (Izacard & Grave, 2021)
أيضًا، تتضمن المراعاة إلى أحساسات الأخلاق ، مثل ضمان الحصول على المعلومات بدون تحيز والتوافر العادل للمعلومات وهي أهم لتوفير التطبيقات التي تتم توفيرها للأنظمة التي تحمل أسماء RAG. (Bender et al., 2021) تتطلب تطوير معايير وإطارات تقييم شاملة تتسم بالتفاعل بين دقة الاستعمال الإنتقالي وجودة التوليد التي من المهم لتقييم فعالية الأنظمة التي تحمل أسماء RAG. (Lewis et al., 2020)
وفي حالة تطور مجال RAG مستمرًا فإن اتجاهات البحث المستقبلية تركز على تنسيق العمليات الإنتقالية وتوسيع قدرات المواد المتعددة الأبعاد وتطوير هياكل متشابكة وإنشاء إطارات تقييم قوية. (Izacard & Grave, 2021) ستحسن فعالية ودقة وقدرة التأقلم بالأنظمة التي تحمل أسماء RAG وستوسع مجال تطبيقات التحليل اللغوي التي تمت تطويرها في المجال الطبيعي لللغة.
هذا مثال برمجي بلغة بيتشوني بسيط يظهر إعداد توليد مع التوجيه (RAG) باستخدام المكتبات المفضلة LangChain و FAISS:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 1. تحميل وتضمين المستندات
loader = TextLoader('your_documents.txt') # استبدال المصدر بمصدرك للمستند
documents = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. استرجاع المستندات ذات الصلة
def retrieve_docs(query):
return vectorstore.similarity_search(query)
# 3. إعداد سلسلة RAG
llm = OpenAI(temperature=0.1) # ضبط درجة الحرارة لإثارة الإبداع في الاستجابة
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# 4. استخدام نموذج RAG
def get_answer(query):
return chain.run(query)
# مثال على الاستخدام
query = "What are the key features of Company X's latest product?"
answer = get_answer(query)
print(answer)
# استخدام مثال تاريخ الشركة
query = "When was Company X founded and who were the founders?"
answer = get_answer(query)
print(answer)
# استخدام مثال الأداء المالي
query = "What were Company X's revenue and profit figures for the last quarter?"
answer = get_answer(query)
print(answer)
# استخدام مثال التوجه المستقبلي
query = "What are Company X's plans for expansion or new product development?"
answer = get_answer(query)
print(answer)
من خلال استغلال قوة الاسترجاع والتكوين، تحمل RAG وعوداً هائلة في تحويل كيفية تفاعلنا مع المعلومات وتوليدها، محدثة ثورة في مختلف المجالات وتشكيل مستقبل التفاعل بين الإنسان والآلة.
1.2 كيفية حل RAG للمشاكل المعقدة
يقدم التكوين المعزز بالاسترجاع (RAG) حلاً قويًا للمشاكل المعقدة التي يعاني منها النماذج اللغوية الكبيرة التقليدية (LLMs)، خاصة في scenarios تتضمن كميات هائلة من البيانات غير المهيكلة.
إحدى تلك المشاكل هي القدرة على المشاركة في محادثات معنوية حول مستندات محددة أو محتوى وسائط متعددة، مثل مقاطع الفيديو على YouTube، من دون ضبط دقيق مسبق أو تدريب صريح على المواد المستهدفة.
تقليديات المؤلفات العامة، على الرغم من قدراتها الإنتاجية المذهلة، محدودة بذاكرتها المادية التي تعتمد عليها في الوقت الذي يتم بناءه. (Lewis et al., 2020) هذا يعني أنها لا تستطيع الوصول مباشرة إلى أو تحويل المعلومات الجديدة خارج معلوماتها التدريبية، مما يجعل من الصعب المشاركة في نقاشات معلومة حول المستندات الغير مرئية أو الفيديوهات. (
وبناءً على هذا، قد تنتج مؤلفات العامة التي تختلف عن التوافق، أو غير متعلقة، أو خاطئة في الحقائق عندما يتم ترتيبها مع الأسئلة المتعلقة بالمحتوى المحدد. (Petroni et al., 2021)
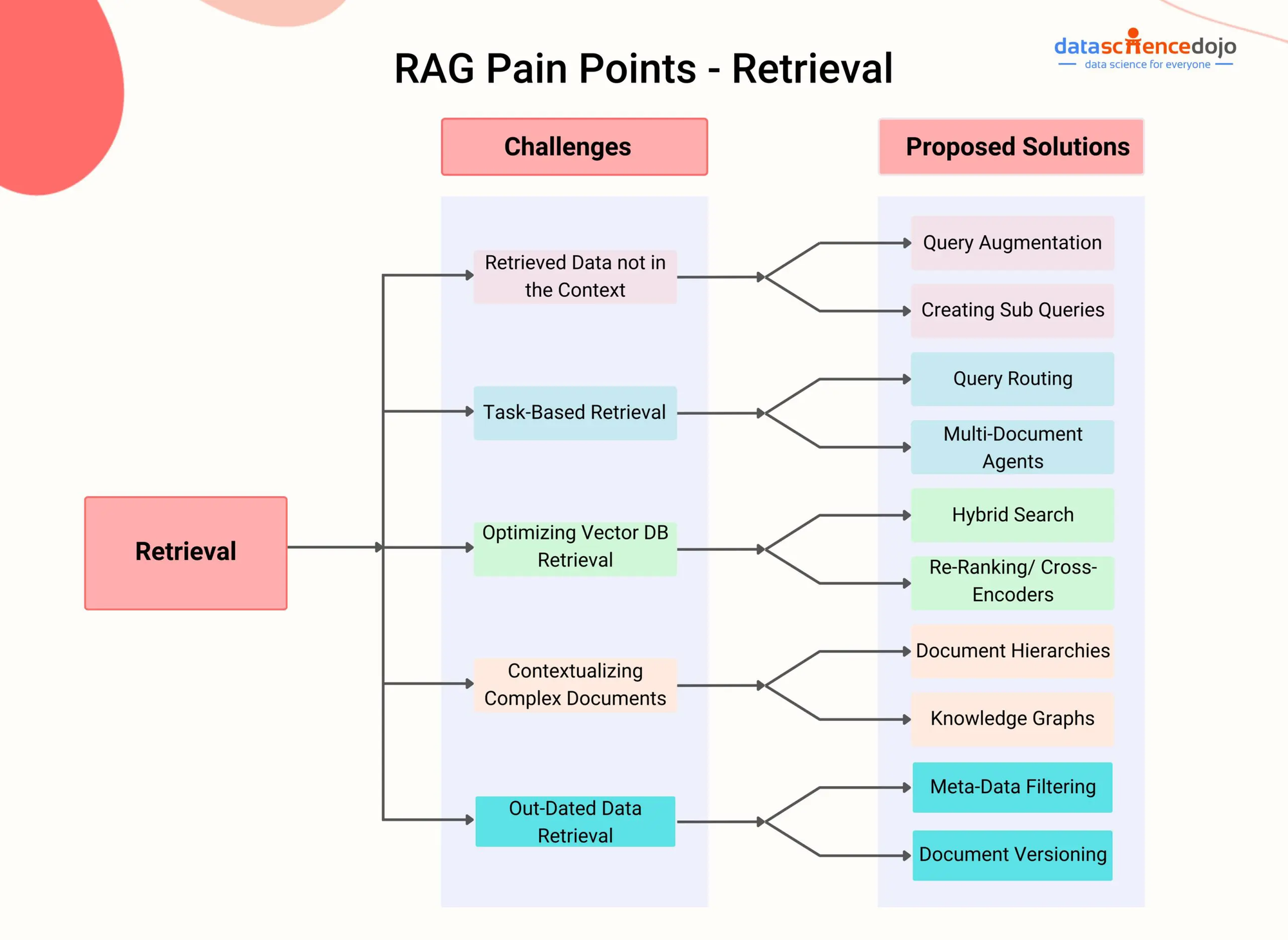
أعاقات RAG – DataScienceDojo
توفر RAG هذا القيود بتركيب عنصر الاستخراج التي تسمح للنموذج بالوصول ديناميكيًا وتدمير المعلومات المتعلقة المناسبة من مصادر من خلال الإنتاج التعاملي.
من خلال استخدام تقنيات البحث المتقدمة، مثل بحث المقالات الكثيفة (Karpukhin et al., 2020) أو البحث المزدوج (Izacard & Grave, 2021),يمكن للأنظمة RAG تحديد بسيط للمقالات الأكثر صلابة أو الأجزاء المناسبة من المستند أو الفيديو وفقاً للسياق المتعاملي.
فعلى سبيل المثال، اعتبر مشاركة مستخدم في محادثة عن مقطع يوتيوب معلومات علمية معينة. يمكن لنظام RAG التنسيق مع الصوت الموجود في المقطع ومن ثم التسلسل لنصوص المقطع التي تنتج من التنسيق باستخدام تمثيلات نمطية كثيفة.
بعد ذلك، عندما يطرح المستخدم سؤال يتصل بالمقطع، يمكن لمكون الاستعمال في نظام RAG التحديد من المقطعات المناسبة أو المرادفة من التسلسل وفقاً للتشابه المعنوي بين السؤال والمحتويات المسجلة.
يتم من ثم إرشاد مقالات التي تم إحضارها إلى النموذج الإنتاجي لتوليد رد منطقي ومعلوماتي يتناسب مع السؤال الذي يتم طرحه من قبل المستخدم ويتم توضيح الإجابة بما يتمتع به من محتويات المقطع. (Shuster et al., 2021)
هذه الطريقة تمكن نظم RAG من انخراط في محادثات معلوماتية حول مجموعة واسعة من المستندات والمحتويات المتعددة الوسائط بدون حاجة إلى تعديل فصيل واضح. من خلال البحث الحيوي وإدماج المعلومات المتعلقة، يمكن لRAG إنتاج ردود أكثر دقة وتوافقًا بالcontext واساسية وثابتة مقارنة بالنماذج السائدة للمعارف اللغوية المتقدمة. (Lewis et al., 2020)
أيضًا، قدرة راجليري (RAG) على التعامل مع البيانات الغير منظمة من متنوع مصادر، مثل النصوص، الصور والمعلومات الصوتية، تجعلها حل متعدد الاستعمال لمشاكل معقدة التي تتضمن مصادر متنوعة للمعلومات. (Izacard & Grave, 2021) وفي حالة تطور أنظمة راجليري (RAG) بشكل مستمر، تكبر قدرتها على التعامل مع المشاكل المعقدة عبر مجالات متنوعة.
من خلال استخدام تقنيات استخراج متقدمة والتكامل المتعدد الأبعاد، يمكن لراجليري (RAG) تمكين عوامل الحديث الذكية والواعية للسياق، وأنظمة التوصية الشخصية، وتطبيقات تعتمدة على المعرفة.
وعندما يتم تقدم البحث في مجالات مثل البحث الفعال، الانتقال العربي-متعدد الأبعاد، والتكامل بين الاستعمال والتوليد، سيلعب راجليري (RAG) دور أساسي بتعزيز الحدود التي يمكن أن تتجاوزها معالم النماذج اللغوية والتكنولوجيا الصناعية.
الفصل 2: الأساسات التقنية
يتعمق هذا الفصل في عالم تعزيز البحث المتعدد الأبعاد (RAG) المتقدم والذي يتجاوز حدود النماذج النصية التقليدية.
من خلال دمج بيانات متعددة من الأوساط المختلف، مثل الصور، المعلومات الصوتية والفيديو، مع النماذج الكبيرة اللغوية (LLMs),يمكن للنماذج المتعددة الرؤيا التقنية تمكين الأنظمة التي تعمل بالآلة الذكية الإنسانية (AI) عن تنطق عبر مناظر معقدة من المعلومات.
سنبحث عن الآلي
بينما يقدم الراجل المتعدد الأولويات من الفائدة المبهرة مثل تحسين الدقة وقدرته على دعم حالات استخدام جديدة مثل إجابة الأسئلة البصرية، فهو يوحد أيضًا تحديات فريدة. تتضمن هذه التحديات حاجة لأحجام كبيرة لقواعد البيانات المتعددة الأولويات، والتعقيد المحمول الأكثر في الحوسبة، والخطر الممكن للتوافق في المعلومات التي يتم استعمالها.
حينما نبدأ في هذه الرحلة، سنكشف ليس فقط عن قدرات الراجل المتعدد التحولية ولكن أيضًا سنبدأ باستعمال هذه العقبات التي تقبع في المستقبل، وستود هذه المسيرة على فهم عميق لهذا المجال القادم بسرعة.
2.1 النظم العصبية الحرفية إلى الراجل المتعدد.
وتطور النماذج اللغوية كان ماموراً بتقدم مستمر من الأنظمة القائمة على القوانين الصناعية إلى النماذج المتطورة بالشبكات العصبية والأنظمة التحكمية الأكثر تعقيدًا.
في الأيام القديمة، تعتمدت النماذج اللغوية على القوانين الصناعية المصنوعة يدويًا وعلم اللغة اللغوي لتوليد النص، وقد أثمرت نتائج قائمة على القواعد ومحدودة. بدأ ظهور النماذج الإحصائية، مثل النماذج العددية المتعددة، بتقدم طريقة قائمة على البيانات التي تتعلم من الكورpora الكبيرة، مما يمكن إنشاء اللغة الأكثر طبيعةً وترابطًا. (Redis)
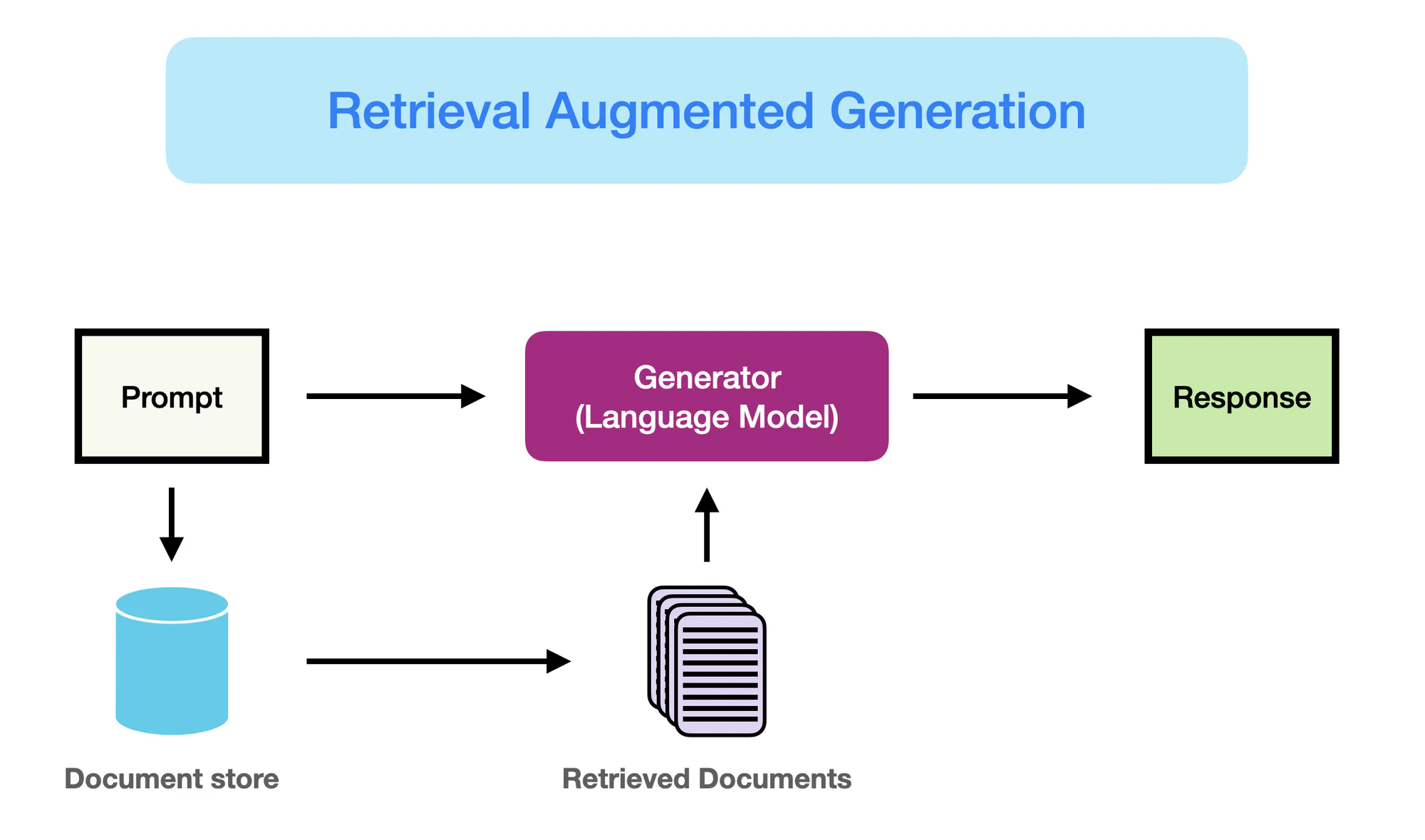
كيف يعمل RAG – promptingguide.ai
ومع ذلك، كان ظهور النماذج
تلك النماذج التي تعرف بأسم النماذج الكبيرة اللغوية (النماذج الكبيرة اللغوية), تستخدم قوة تعلم العم深度 للتقطيع في أنماط اللغة المعقدة وتوليد نصوص تشبه البشرية بلمسة غير مسبوقة والتي تتماشى مع بعضها. (Yarnit) والتعقيد والحجم المتزايد للنماذج الكبيرة اللغوية مع نماذج مثل GPT-3 تحدد أكثر من 175 بليون ماثل، قاد الى تواريخ قوية في المهام التي يمكن إنجازها مثل ترجمة اللغة، إجابة الأسئلة، وإنشاء المحتويات.
على الرغم من أداءها الرائع، يعاني النماذج الكبيرة اللغوية التقليدية من قيود بسبب تعتمدها على الذاكرة الطبقية وحده. (StackOverflow) يمكن تسجيل المعرفة التي تتم تعبئتها في تلك النماذج بشكل ثابت، مقيدة بتاريخ التجنيد الأخير لبيانات تدريبها.
ومن ثم، قد تنتج نوات النماذج الكبيرة اللغوية ما يكون خطأ في الحقائق أو غير توافقية مع المعلومات الأخيرة. أيضًا، عدم وجود دخول واضح لمصادر معرفية خارجية يعاني منها قدرتهم على تقديم ردود فعالة ومتناغمة بالمعنى البارز لأسئلة تعتمد على المعرفة.
يبرز حل تعزيز الاستخراج مع التوليد (RAG) كحل يجعل نماذجه قادرة بشكل ديناميكي على الوصول إلى وافعال توفير المعرفة المتعلقة من مصادر خارجية خلال عملية توليد النصوص.
هذا الدمج بين الذاكرة البارامترية والغير بارامترية يسمح للمعدات بـ RAG من نموذجات LLMs لإنتاج الخرجات التي ليست فقط سلسة ومترابطة ولكن أيضًا دقيقة وفي إطار المعلومات الخارجية.
RAG يمثل قفزة كبيرة في توليد اللغة، مزيج القوة من LLMs مع العلم الواسع المتوفر في مخازن خارجية. من خلال إستفادة من الأفضل في العالمين، يمكن RAG أن يعطي النماذج القدرة على توليد نصوص أكثر قابلية للثقة، معلومية، ومتماسكة مع المعرفة العالمية.
هذا التحول النموذجي يفتح فرص جديدة لتطبيقات NLP، من إجابة الأسئلة وإنشاء المحتوى إلى المهام الحاسمة في المعرفة في قطاعات مثل الرعاية الصحية، والمالية والبحث العلمي.
2.2 الذاكرة البارامترية مقابل الغير بارامترية
الذاكرة البارامترية تشير إلى المعرفة المخزَّنة داخل متغيرات نموذجات اللغة المُتَدربة مسبقًا، مثل BERT و GPT-4. تتعلم هذه النماذج التقاط الأنماط اللغوية والعلاقات من الكميات الضخمة من بيانات النص خلال عملية التدريب، وتقوم بترميز هذه المعرفة في الملايين أو المليارات من المتغيرات.
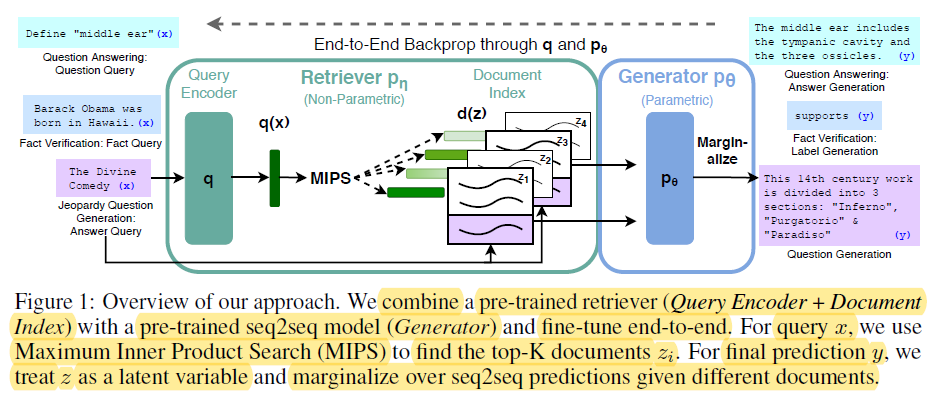
End-t-End Backprop through q and p0 – miro.medium.com
قوات الذاكرة البارامترية تشمل:
- التواناء: توليد النماذج اللغوية المتدربة من قبل توليد نصوص تشبه البشرية بتألق و توافق مذهل وتتسبب في التأشير والطريقة الخاصة باللغة الطبيعية. (Redis و Lewis و الآخرون.)
- التعميم: تخزين المعرفة في ما يليق بما يحتاج للتعميم للمهام الجديدة والمجالات الأخرى، مما يمكن توانماً وتعلم التنقل. (Redis و Lewis و الآخرون.)
مع ذلك، فإن ذاكرة المادة المتغيرة لديها حدود كبيرة:
- أخطأ واقعية: قد تنتج النماذج اللغوية ما يخالف بالفعل الواقعي، لأن معرفتها محدودة إلى البيانات التي تم تدريبها عليها.
- المعرفة المتقدمة في الزمن: تأخذ معرفة تخزينها في ما يليق بما يحتاج للمادة تتجاوز وقت التدريب ولا تمثل تحديثات أو تغيرات الواقع العام.
- تكاليف كمية كبيرة: تعلم النماذج اللغوية الكبيرة يتطلب مقدار كبير من الموارد المعقدة والطاقة، مما يجعله مكلف ومستغرب ومكلف لتحديث معرفته.
- المعرفة العامة: يتم تجميع المعرفة التي يتم تخزينها في نماذج اللغة بشكل واسع وعام وتفتقر إلى العمق والتعريف المتفاعل لما يكفي للعديد من التطبيقات التي تتمحور حول مجالات معينة.
بالمقابل، يشير الذاكرة الغير تنظمية إلى استخدام المصادر المعلوماتية البيانية، مثل البases معلوماتية، المستندات، والخوارزميات المعلوماتية، لتوفير المعلومات الحديثة والدقيقة لنماذج اللغة. تلك المصادر الخارجية تشكل نوع من الذاكرة المكملة، تسمح للنماذج بالوصول إلى تلك المعلومات وتسجيلها في التوان التي تستمر أثناء عملية توليد النصوص.
يشمل منافع الذاكرة الغير تنظمية التالية:
- المعلومات الحديثة: يمكن تحديث وحفظ المصادر الخارجية بسهولة، متأكدًا من أن النموذج يحصل على المعلومات الأحدث والدقيقة.
- تقليل الهلوسات: من خلال إستبدال المعلومات المهمة من المصادر الخارجية، تقليل نموذج RAG بشكل كبير الحالات التي يكون فيها التخيلات أو الإنتاجات الخاطئة من المعلومات الفيزيائية. (Lewis et al. و Guu et al.)
- معرفة تخصصية المجال: الذاكرة الغير parametricة تسمح للنماذج باستخدام المعرفة التخصصية من مصادر تخصصية للمجالات، مما يسمح للنتائج الأكثر دقة والتي تتمتع بالحالة الواقعية للتطبيقات الخاصة. (لويس والبرادز) و (كوو والبرادز)
قصور الذاكرة الparametricة يبرز حاجة لتغيير نموذج في توليد اللغة.
RAG يمثل تقدم كبير في مجال معالجة اللغة الطبيعية عن طريق تحسين أداء النماذج الإنتاجية من خلال تكافؤ المعلومات بواسطة تقنيات البحث في المعلومات. (Redis)
هذا هو البرمجيات البيتسورية لإظهار الفروق بين الذاكرة الparametricة والغير الparametricة في سياق RAG مع إظهار بوضوح:
from sentence_transformers import SentenceTransformer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAI
# مجموعة من الوثائق الموجودة (تخيل وثائق أكثر كتلة في حالة واقعية)
documents = [
"The Large Hadron Collider (LHC) is the world's largest and most powerful particle accelerator.",
"The LHC is located at CERN, near Geneva, Switzerland.",
"The LHC is used to study the fundamental particles of matter.",
"In 2012, the LHC discovered the Higgs boson, a particle that gives mass to other particles.",
]
# 1. الذاكرة الغير parametricة (البحث مع التعبيرات)
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings(model_name=model_name)
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. الذاكرة الparametricة (النموذج اللغوي مع البحث)
llm = OpenAI(temperature=0.1) # تنظيم الحرارة للإبداع في الردود
chain = RetrievalQAWithSourcesChain.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# --- الأسئلة والإجابات ---
query = "What was discovered at the LHC in 2012?"
answer = chain.run(query)
print("Parametric (w/ Retrieval): ", answer["answer"])
query = "Where is the LHC located?"
docs = vectorstore.similarity_search(query)
print("Non-Parametric: ", docs[0].page_content)
الإخراج:
Parametric (w/ Retrieval): The Higgs boson, a particle that gives mass to other particles, was discovered at the LHC in 2012.
Non-Parametric: The LHC is located at CERN, near Geneva, Switzerland.
وهذا ما يحدث في هذه البرمجيات:
الذاكرة الپاراميتريكية:
- تستفيد من العلم الواسع للمعجم الشامل لإنشاء جواب شامل، بما فيها الحقيقة الحاسمة بأن البوزون هيجس يعطي الكتلة للجسيمات الأخرى. يتم “تخصيص” المعجم بالبيانات التدريبية الواسعة.
الذاكرة غير الپاراميتريكية:
- أجري بحثًا تشابهي في الفضاء البكتوري، يجد الوثيقة الأكثر صلة التي تجيب مباشرة على سؤال مكان مصادمة الجسيمات العملاقة (LHC). لا يجمع معلومات جديدة، يقوم فقط بإسترجاع الحقيقة المناسبة.
الاختلافات الرئيسية:
| Feature | Parametric Memory | Non-Parametric Memory |
|---|---|---|
| تخزين المعرفة | مشفر في معلمات النموذج (الوزن) كتمثيلات تعلمت. | يتم تخزينها مباشرة كنص خام أو تشكيلات أخرى (مثل التضمينات). |
| الاسترجاع | يستخدم قدرات النموذج الإنتاجية لإنتاج نص صلب بالإستناد إلى المعرفة التي تعلمتها. | يتضمن البحث عن الوثيقة التي تطابق جيداً مع الاستعلام (مثل التشابه أو تطابق الكلمات الرئيسية). |
| المرونة | مرونة عالية ويمكنها إنتاج ردود فعلية جديدة، ولكن قد تصدر معلومات خاطئة أيضًا. | أقل مرونة، ولكن أقل عرضة للتخيلات لأنها تعتمد على البيانات القائمة. |
| أسلوب الرد | يمكنها إنتاج ردود أكثر تعقيدًا وتنوعًا، ولكن قد تحتوي على معلومات غير ذي صلة أيضًا. | توفر ردود مباشرة وموجزة، لكن قد يفتقر السياق أو التوضيح. |
| تكلفة الحساب | تكاليف التشغيل الحاسوبي قد تكون كبيرة جداً ، خاصة للأنظمة الكبيرة. | قد يكون الاسترجاع أسرع بشكل كبير ، خاصة بواسطة الخوارزميات الباصرة والتصفية الفعالة. |
من خلال تحويل قواصد النماذج البنياتية وغير البنياتية يتم تناول راجل لللغة التقنية التقليدية وتمكينهم من إنتاج نتائج أكثر دقة وحدة وتوافر واعتمادة على السياق. (Redis, Lewis et al., وGuu et al.)
2.3 راجل اللغة المتعددة الأبعاد: تكامل النص
يمكن توسيع مبدأ راجل اللغة النصية التقليدية عن طريق دمج الأشكال الإضافية للبيانات مثل الصور والصوت والفيديو لتحسين قدرات الاسترجاع والإنتاج للنماذج الكبيرة لللغة (النماذج الكبيرة اللغوية).
من خلال استخدام تقنيات التعامل المقابلي يتم تعلم نظم الراجل المتعدد الأبعاد كيفية تعميم أشكال البيانات المتنوعة في مساحة توافر واحدة ، مما يسمح للنماذج الكبيرة بالتفكير في سياق أكثر غنى ، من ثم يتم إنشاء نتائج أكثر تفاصيلاً وواعية ومتناسقة بالسياق. (Shen et al.)
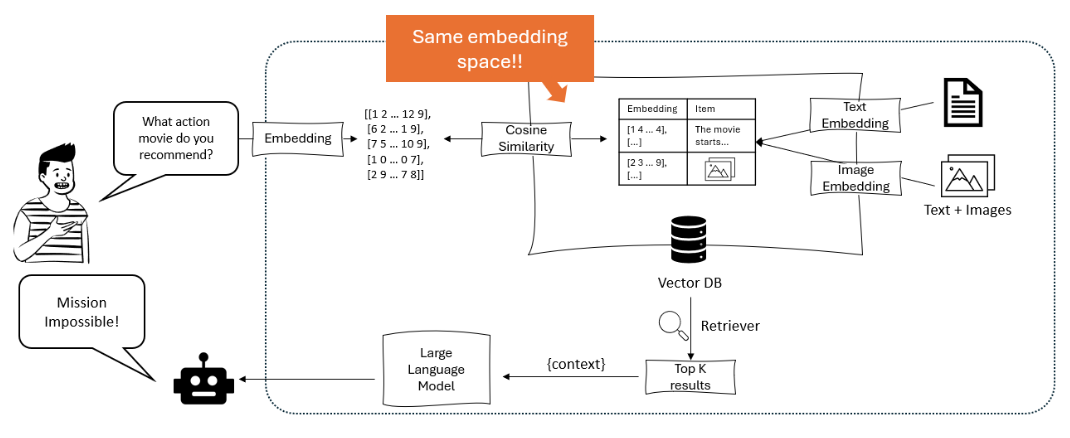
يوضح الرسم البياني نظام توصية حيث يقوم نموذج كبير من النظام اللغوي بمعالجة تساؤل المستخدم إلى تموضعات، ويتم موافقة هذه التموضعات بواسطة الشبهيون الجيني داخل قاعدة التوافذ الحاصلة على كلاً من التموضعات النصية والتموضعات الصورية للحصول على واحدًا من العناصر الأكثر توافقًا. – opendatascience.com
تعتمد أحد المقاربات الرئيسية في RAG المتعدد الأبعاد على نماذج قائمة على التحكم التعاوني مثل ViLBERT و LXMERT التي تستخدم تقنيات التوجه التعاوني. وهذه النماذج يمكنها التركيز على المناطق المهمة في الصور أو الجزء الخاص في المعلومات الصوتية/الفيديو أثناء توليد النص، متسلسلة بالتفاعلات الدقيقة بين الأوامر المختلفة. هذا يسمح لهم بإظهار أسلوبًا يشمل الصور والمحتوى السياسي بشكل أكبر. (Protecto.ai)
تتضمن الاندماج التامي للنص مع الأوامر الأخرى في أنابيب RAG تحديات مثل توافق التموضعات المعنية عبر الأنواع المختلفة من البيانات وإدارة خصائص الأوامر المنفصلة خلال عملية التموضعات. تستخدم تقنيات تعزيز التعاون التعاوني والتعزيز الخاص بالأوامر لتوليد تلك التحديات. (Zhu et al.)
ولكن من المتاع جميعًا من تحقيق RAG المتعدد الأبعاد المحتمل، بما في ذلك زيادة في الدقة والسيطرة وقابلية تفسير المحتوى المنتج وقدرته على دعم حالات استخدام جديدة مثل الإجابة عن الأسئلة
لي وآخرون (2020) اقترح إطار RAG متعدد الوسائط لإجابة الأسئلة التصويرية يستعيد الصور والمعلومات النصية ذات الصلة لتوليد إجابات دقيقة، يتمثل بمستوى أعلى للآتيثوت سابقة في معايير كالـ VQA v2.0 و CLEVR. (MyScale)
بغض النظر عن النتائج المؤكدة، يحدث RAG متعدد الوسائط أيضًا تحديات جديدة، مثل ال복잡ية التحليلية المعتززة، الحاجة إلى مجموعات بيانات متعددة الوسائط على نطاق واسع، والإحتمالية للتحيز والضجيج في المعلومات المستعيدة.
يتابع الباحثون تقنياتًا لتخفيف هذه القضايا، مثل البنية التحتية الفعالة للفهرسة، استراتيجيات تكثيف البيانات، وأساليب التدريب العدوانية. (Sohoni et al.)
الفصل 3: مؤشرات RAG الأساسية
يستكشف هذا الفصل التفاعل الجميل بين المستعيدين والنماذج التوليدية في أنظمة الإستعادة المعززة بالإنتاج، يبرز دورهم الحاسم في الفهرسة، وإستعادة المعلومات وتحليلها لإنتاج إجابات دقيقة ومتناسبة تنسيقيا.
سنغوص في تفاصيل تكنيق المستعيد الرقمي العارض والكثيف، ونقارن قواهم وضعفهم في مواقف مختلفة. بالإضافة إلى ذلك، سنتحقق في استراتيجيات مختلفة لإدماج المعلومات المستعيدة في النماذج التوليدية، مثل الإلحاق والاهتمام التركيزي القطري، ونتحدث عن تأثيرها على فعالية الأنظمة RAG العامة.
بفهم الاسترategيات التلائمية سوف تحصل على معاينات قيمة على كيفية تحسين أنظمة RAG للمهام والمجالات المعينة ، وهذا سيساهم في استخدام هذه المثالية القوية بطريقة معلومة وفعالة.
3.1 قوة توازي الاستخراج والتوليد في RAG
التوليد المساعد بالاستخراج (RAG) يمثل مثالية قوية التي تتماشى بالتكامل بين الاستخراج والنماذج الإلهامية للنظم اللغوية. RAG مكون من قطعتين رئيسيتين كما تلاحظ من تعريف اسمه: الاستخراج والتوليد.
الجزء المسؤول عن الاستخراج يكون مسئول من توازين وبحث في مخزون كبير من المعرفة بينما الجزء التوليدي يستخدم المعلومات المحولة لتوليد الردود المتناسقة والدقيقة من المعلومات. (Redis وLewis et al.)
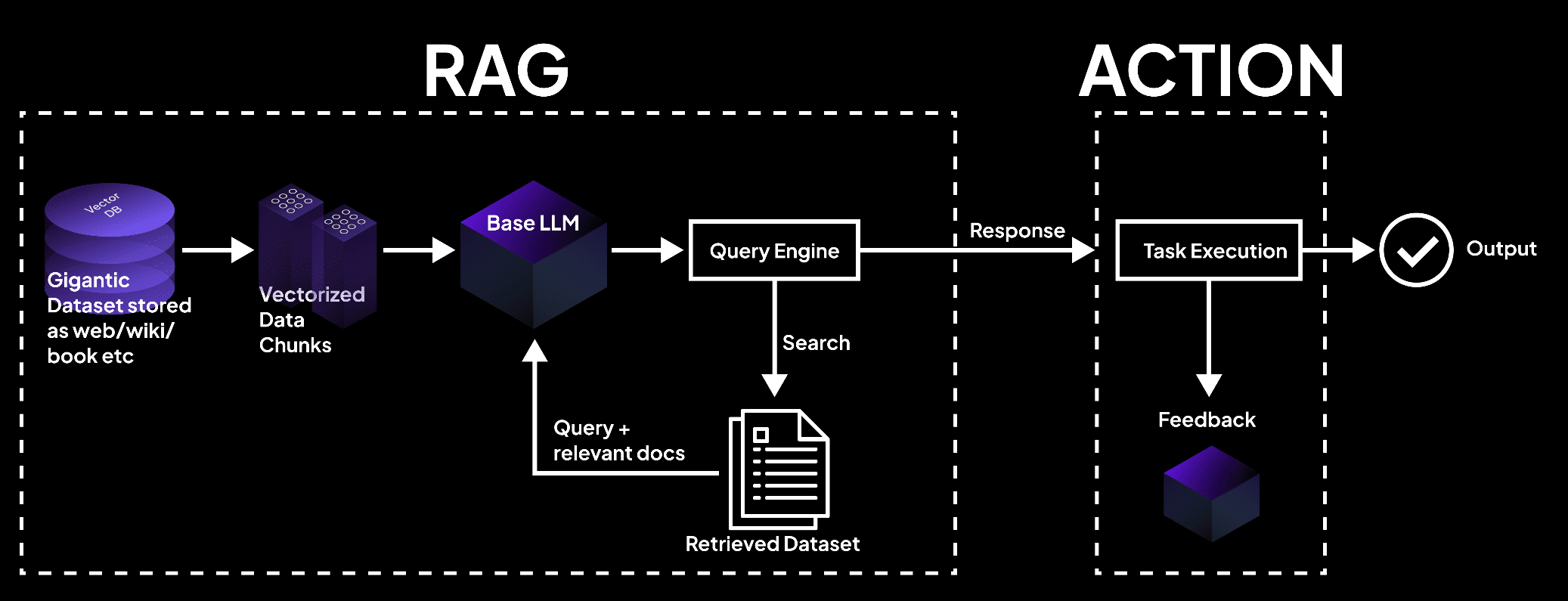
توضح الصورة نظام RAG الذي يعالج قاعدة البيانات إلى أجزاء من خلالها يتم بحثها من قبل نموذج اللغة للحصول على المستندات للقيام بالمهام والنتائج الدقيقة. – superagi.com
يبدأ عملية الاستعمال بتسجيل المصادر الخارجية المعرفية، مثل البases البياناتية، الوثائق والصفحات الويب. (Redis و Lewis والآخرون) ويلعب دور الاستعمالات والمُؤثرين دور حاسم في هذه العملية، تنظيم وتخزين المعلومات بشكل فعال بتنسيق يساعد في البحث والاستعمال بسرعة.
حين تم وضع سؤال في النظام RAG، يبحث المستعمل المتعلق بالمبادرة عن معلومات مُرتبطة بواسطة الشبكة المعرفية المُؤثرة وبمقياسات أخرى للتوافق والتناسق.
وبمجرد استعمال المعلومات المناسبة من مبادرة، يأخذ مكون الإنشاء على الإطلاق. يستخدم المحتوى المستقبلي لتحريك وتوجيه النموذج اللغوي التوليدي ويعطيه المادة الضرورية للسياق والتواريخ الحقيقي لإنتاج ردود فعالة ومفهومة.
يستخدم النموذج اللغوي تقنيات توزيع الإنتباه متقدمة، مثل أداة الإنتباه والهياكل المحورية، لترميم المعلومات التي تم استعمالها مع معرفته السابقة وإنتاج نصوص منظمة وسلسة.
يمكن رسم تدوير المعلومات داخل نظام RAG بالتالي:
graph LR
A[Query] --> B[Retriever]
B --> C[Indexed Knowledge Base]
C --> D[Relevant Information]
D --> E[Generator]
E --> F[Response]
تحمل منحنى RAG مزيد من المزايا:
تلك التركيبة بين قدرات الاسترجاع والإنتاج تمكن من إنشاء ردود الفعل ليست فقط مناسبة بالنسبة للسياق ولكن أيضًا مستنيرة بالمعلومات التي تتوفر عليها المعلومات الحديثة والدقيقة المعلومات المتوفرة. (Guu والأخرون)
من خلال تسخير المصادر الخارجية للمعرفة، يقلل RAG بشكل كبير من حصد الهلوسات أو الخروجات الخاطئة من المنهجيات الإنتاجية البسيطة، التي تكون أخطاء شائعة لهذه النماذج.
بالإضافة إلى ذلك، يسمح RAG للتكامل بالمعلومات الحديثة، مما يضمن أن تعكس الردود المنشورة أحدث المعلومات والتطورات في مجال معين. هذا مهم جدًا في المجالات التي تشمل الصحة المعنية بالمالية والبحث العلمي، حيث يحمل المعلومات الدقيقة والمتناولة أهمية كبيرة. (Guu والأخرون و NVIDIA)
ويظهر RAG أيضًا بالاستيعاب القابل للتغيير ، مما يسمح للنماذج اللغوية بالقيام بمجموعة واسعة من المهام ب desempeño مستحسب. من خلال الحصول على المعلومات المتعلقة بالسؤال الخاص أو السياق الخاص، يتمتع RAG بتوفير المعلومات المتعلقة بكل مهمة من الإجابة عن الأسئلة، التوليد المحتويات، أو التطبيقات التخصصية.
وقد أظهرت عدة دراسات بأثبات فاعلية RAG في تحسين الدقة الواقعية والتناسق والتكيف لنماذج اللغوية الإنتاجية.
على سبيل المثال، أظهر (Lewis والآخرون 2020) أن RAG أفضل من النماذج الإبداعية بشكل كامل في مجموعة من المهام الإجابية، وأنه يحقق نتائج متقدمة عالمياً في المؤشرات المثالية مثل Natural Questions و TriviaQA. (Lewis والآخرون)
بشكل مماثل، أظهر (Izacard و Grave 2021) قوة RAG أكثر من النماذج اللغوية التقليدية في توليد النصوص الطويلة التي تكون متماسكة ومتوافقة مع الحقائق.
تشكيل Retrieval-Augmented Generation يمثل طريقة تحويلية للتوليد اللغوي وهي تستغلل قوة الحصول على المعلومات لتحسين دقة وتوافق وتكيفية النماذج الإبداعية.
من خلال تداخل بطريقة سلسة مع القدرات اللغوية المسجلة مسبقاً، يفتح RAG أحتمالات جديدة للمعالجة اللغوية الطبيعية ويبني الطريقة لنظم التوليد الأكثر ذكاءً وموثوقًا بالتوليد اللغوي.
3.2 استراتيجيات تركيب RETRIEVER-GENERATOR
الأنظمة التي تستخدم RAG تعتمد على عناصرين رئيسيين: المحركات للبحث والنماذج الإبداعية. تقوم المحركات للبحث ببحث واسترجاع المعلومات المناسبة من قاعدات المعلومات الكبيرة بالكفاءة.
“هي تشمل عقدان معينين، تسريع والبحث. تسريع التنظيم للوثائق لتسهم بالتسريع في البحث المناسب، وتستخدم المعيار المعكوس للبحث النادر أو التكاليف الكيميائية الكثيفة للبحث الكثيف.” (Redis)
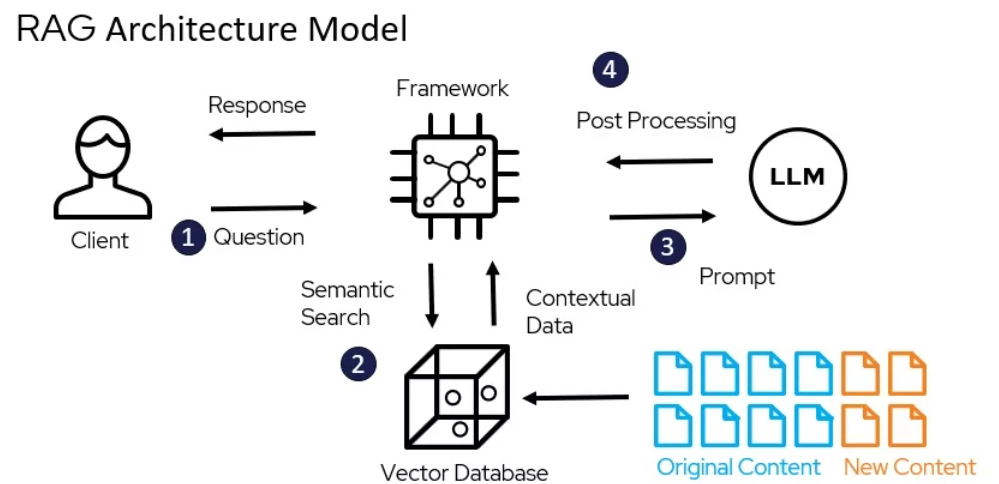
نموذج الهيكلية لـ RAG – miro.medium.com
تعاليم البحث النادر ، مثل TF-IDF و BM25 ، تمثل المستندات بال vectores النادرين بالأبعاد العالية ، حيث كل مستوى يمثل عبارة واحدة في القواميس. تحدد توافق المستند بالعبارة من خلال تكامل العبارات وتوزيع أهميتها.
على سبيل المثال ، يمكن تنفيذ مستندات TF-IDF مبتدئة بواسطة المكتبة المشهورة Elasticsearch بالتالي:
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.index(index="documents", doc_type="_doc", body={"text": "This is a sample document."})
query = "sample"
results = es.search(index="documents", body={"query": {"match": {"text": query}}})
تعاليم البحث الكثيفة ، مثل البحث الكثيف في المستندات (DPR) والنماذج المبتدئة على BERT ، تمثل المستندات والأسئلة بال vectores الكثيفين في فراغ التمثيل المتواصل. تحدد توافق المستند من خلال تشابه جيني التوازي بين العبارات المستند والأسئلة.
يمكن تنفيذ DPR بواسطة مكتبة Hugging Face Transformers:
from transformers import DPRContextEncoder, DPRQuestionEncoder
context_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
question_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
context_embeddings = context_encoder(documents)
query_embedding = question_encoder(query)
scores = torch.matmul(query_embedding, context_embeddings.transpose(0, 1))
تعاليم النماذج الإنتاجية ، مثل GPT و T5 ، يستخدم في RAG لإنشاء الردود المتوافقة والمتناسبة بالمعلومات المحولة. تحسين أداء هذه النماذج في نظم RAG يمكن تحسينه بالتنقيح على البيانات التخصصية وتطبيق التقنيات المعادية للتعيين. (مجموعة المطورين)
الاستراتيجيات التكاملية تحدد كيفية إدماج المحتويات المحولة في النماذج الإنتاجية.
“يستخدم المكون الجيلي ما يحصل عليه من محتوى البحث لتشكيل ردود منطقية ومتناسبة بالسياق مع المراجعة والمناظرة الدقيقة.” (Redis)
وتعتمد على نهجين شائعين يتم إدراجهما المعادل والتركيبي.
يتضمن التراكيبية وضع المقالات المتوفرة بجانب الأسئلة المدرجة، مما يسمح للنموذج التوليدي بالاهتمام بالمعلومات المتعلقة أثناء عملية الترجمة.
وبينما هذا النهج سهل التنفيذ، قد يتعاقب مع تلو السلسلات الطويلة والمعلومات الغير مرتبطة. (مجموعة التطوير التجاري) تسمح محركات التركيبية التي تشمل RAG-Token و RAG-Sequence للنموذج التوليدي بالاهتمام التحديدي بالمقالات المتوفرة في كل خطوة من عملية الترجمة.
وهذا يسمح للمجموعة بالتحكم الأوسع في عملية الادماج، ولكنه يأخذ بالمعاملة الكمية الأكثر تعقيدًا.
على سبيل المثال، يمكن تنفيذ RAG-Token بواسطة مكتبة التحويلات Hugging Face Transformers:
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq")
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids)
generated_output = model.generate(input_ids, retrieved_docs=retrieved_docs)
خيار ما يمكن إختياره من الإستجمام، والنموذج التوليدي، والاستراتيجيات التحكم يعتمد على تحتويات النظام RAG الخاص به، مثل حجم وطبيعة القاعدة المعلوماتية، والتوازن المطلوب بين الكفاءة والفعالية، والمجال التي تستهدف إليه تطبيقاته.
الفصل 4: التطبيقات والحالات الإستخدامية.
هذا الفصل يبحث في قدرات التحول التي يمتلكها نظام Retrieval-Augmented Generation (RAG) على تغيير مناظر اللغة القليلة الموارد وتطبيقات اللغة المتعددة اللغات. نتعمق في استراتيجيات مثل ترجمة المستندات المصدرية إلى اللغات الغنية بالموارد، واستخدام التعاملات المتعددة اللغوية، وتطبيق التعلم المتفاعل لتحليل القيود البيانية والاختلافات اللغوية.
أضافة إلى ذلك، نتناول تحدي رئيسي تخفيف الهلوسات في نظم RAG المتعددة اللغوية لضمان توليد المحتوى الدقيق والموثوق. من خلال استكشاف هذه المقاربات الابتكارية، يوفر هذا الفصل دليلًا شاملًا على تسخير قوة RAG للمشاركة والتنوع في معالجة اللغة.
4.1 تطبيقات RAG: إجابة الأسئلة إلى الكتابة الإبداعية
وجد RAG تطبيقات عملية عديدة في مجالات مختلفة، مظهر قدراته على تغيير الطريقة التي نتفاعل بها وننتج معلومات. من خلال استخدام الترجمة والتوليد، وجدت نظم RAG تحسينات كبيرة في الدقة والصلابة وتفاعل المستخدمين.
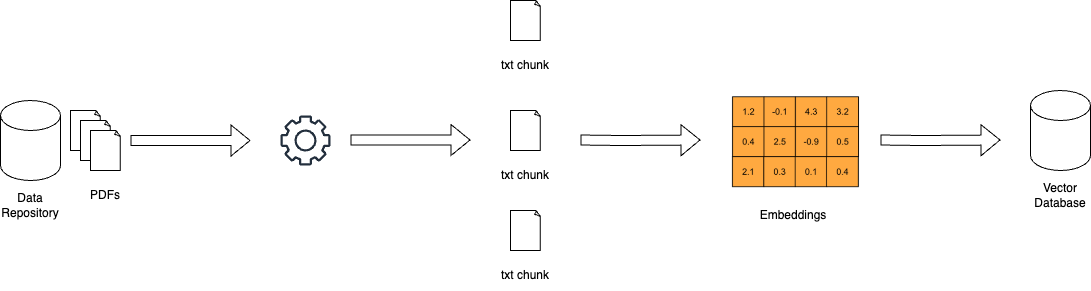
كيف تعمل RAG – miro.medium.com
إجابة الأسئلة
قد أثبتت RAG أنها محور تغيير في مجال الإجابة على الأسئلة. من خلال استعمال مصادر خارجية للبحث عن معلومات متعلقة وتكاملها في عملية توليد الإجابات، يمكن للأنظمة RAG القيام بتوفير إجابات أكثر دقة وتوافرًا واقعيًا للأسئلة المطروحة من المستخدمين. (LangChain و Django Stars)
على سبيل المثال، اقترح إيزاكارد وغراف في (2021) نموذج RAG يدعى Fusion-in-Decoder (FiD), الذي حقق أفضل أداءً على عدة معاملات لإجابة الأسئلة، بما في ذلك Natural Questions و TriviaQA. (Izacard and Grave)
FiD يستخدم محرك إعادة البحث الكائني للحصول على المقالات المتعلقة ونموذج توليدي لتحضير المعلومات التي تم إحتيالها إلى إجابة متكاملة، وهو يتميز بالمائة الكبيرة عن النماذج التوليدية المنفصلة بالفعل. (Izacard and Grave)
الأنظمة الحوسبية التحدثية
RAG أيضًا وجد تطبيقات في خلق أجهزة متكاملة ومعلومات أكثر إشباعًا. من خلال تضمين المعرفة الخارجية من خلال الاسترجاع، يمكن للأنظمة الحاسوبية القائمة على RAG أن تنتج ردودًا لا تنتمي فقط إلى السياق المناسب لكن أيضًا موضوعة بالحقائق. (LlamaIndex و MyScale)
أعرض Shuster والأخرون (2021) نظام محادثات RAG يطلق عليه الاسم BlenderBot 2.0، الذي أظهر قدرات متكاملة أفضل من 其predecessor. (Shuster et al.)
BlenderBot 2.0 يجمع معلومات مناسبة من مجموعة متنوعة من المصادر المعرفية، بما في ذلك ويكيبيديا، ومقالات الأخبار والمعلومات الاجتماعية، مما يسمح له بالمشاركة في محادثات أكثر معرفة وتنظيمًا عبر مجموعة واسعة من المواضيع. (Shuster et al.)
التوحيد
أظهر RAG إمكانية أفضل في تحسين جودة توحيدات المواضيع التي يتضمن معلومات من مصادر عديدة. (Hyperight) أقترحوا Pasunuru والأخرون (2021) نموذج توحيد RAG المسمى PEGASUS-X، الذي يجمع ويدمج مقالات مناسبة من المستندات الخارجية لتوحيد أكثر تعقيدًا وتنظيمًا.
بيجاسوس-إكس أحسن ما يمكن أن يحسنه من النماذج الإيجابية التي تنتج من النماذج التوليدية بشكل فارغ ، موضحاً فعالية إستعمال الاسترجاع في تحسين دقة الحقائق والتوافق للخلال المنتجة.
الكتابة الإبداعية
قدرات RAG تتجاوز مناطق الحقائق وتصل إلى مجال الكتابة الإبداعية. من خلال استرجاع المقالات المتعلقة من تواناء كبيرة من أعمال الأدب، يمكن لنظم RAG إنتاج قصص جديدة ومشوقة أو مقالات.
أعلن راشكين والأخرون (2020) نموذج كتابة إبداعية يعتمد على RAG يسمى CTRL-RAG الذي يسترجع مقالات متعلقة من جهود كبيرة من الأدب الإفتراضي ويدمجها في عملية التوليد. أظهر CTRL-RAG قدرته على توليد قصص متكاملة وثابتة بالمنهجية الأدبية، مظهر قدرات RAG في تطبيقاتها الإبداعية.
دراسات حالات
عدد من الوثائق البحثية والمشاريع أظهرت فعالية RAG في مجالات مختلفة.
على سبيل المثال، أعلن لويس والأخرون (2020) تقدموا إطار RAG وتطبيقه في إجابة الأسئلة في المجالات المفتوحة، وحققوا أفضل performance على معيار الأسئلة الطبيعية. (Lewis et al.) ويبرزون التحديات للاسترجاع الفعال وأهمية تنقيط النموذج التوليدي على المقالات التي تم استرجاعها.
في حالة دراسة أخرى، قام بيتروني والأخرون (2021) بتطبيق RAG على المهمة المتعلقة بالتحقيق في الحقائق، وأظهروا قدرته على تحصيل الأدلة المتعلقة وتوليد الحكمات الدقيقة. أظهروا قدرة RAG في مكافحة المعلومات الخاطئة وتحسين معيشة المعلومات النظامية.
لقد كان تأثير RAG على تجربة المستخدمين ومؤشرات الأعمال كبيرًا. من خلال تقديم الاستجابات الدقيقة والمعلومة بشكل أكبر، قامت أنظمة RAG بتحسين رضا المستخدمين والتعامل المتعلق بهم. (LlamaIndex و MyScale)
في حالة وكلاء المحادثات، قام RAG بتمكين التواصل بطريقة أكثر طبيعة وترتيبية، وتمكينهم بالاستمرار والولاء. (LlamaIndex و MyScale) في مجال الكتابة الإبداعية، تمتلك RAG قدرة على تسريع عمليات إنشاء المحتويات وتوليد أفكار جديدة، مما يوفر الوقت والموارد للشركات.
لذا كما ترون، تطبيقات RAG العملية تنتشر في مجالات واسعة من الإجابة عن الأسئلة والأنظمة التحدثية إلى التوحيد والكتابة الإبداعية. من خلال تسخير قوة الاسترجاع والتوليد، أظهر RAG تحسينات كبيرة في الدقة والتناسق والتعامل المتعلق بالمستخدمين.
ومع تستمر المجال في التطور، يمكننا أن نتوقع رؤوس تطوير أكثر إبداعاً للRAG، مما يحول طريقة تفاعلنا مع المعلومات وتوليدها في إطار مختلف الcontexts.
4.2 RAG لللغات النادرة والبيئات المتعددة اللغات
تأسيس قوة التوليد المساعد على الحصول (RAG) لللغات النادرة والبيئات المتعددة اللغات ليس فقط فرصة- إنه ضرورة. مع أكثر من 7000 لغة تتم تحدثها في جميع أنحاء العالم، معظمها تفتقر إلى موارد رقمية substancial، تحدي الواضح: كيف نضمن ألغات هذه ليست بخلف في العصر الرقمي؟
الترجمة كجسر
إحدى ال策略 الفعالة هي ترجمة المستندات المصدرية إلى لغة تمتلك موارد أكثر قبل التسجيل. هذا النهج يستخدم التربية الكبيرة المتوفرة في لغات مثل الإنجليزية، من ثم يحسن دقة وتناسب البحث بشكل كبير.
بترجمة المستندات الى الإنجليزية، يمكنك استخدام الموارد الهائلة والتقنيات المتقدمة لللغات العالية بالموارد، مما يحسن أداء نظم RAG في بيئات نادرة.
تعقيدات التعامل المتعددة اللغات
تعالي الأحدث في تعقيدات الكلمات المتعاملة باللغات المتعددة يوفر حل آخر. من خلال خلق أساس مشترك لللغات المتعددة، يمكنك تحسين أداء التعامل المتعدد اللغات حتى لللغات النادرة جداً.
لقد أظهرت البحث أن تضمين اللغات الوسطية مع تعقيدات جيدة يُبني جسر بين الأزواج اللغوي
هذه الطريقة تحسين دقة البحث ويتضمن أيضًا تأمين توافر المحتوى المنشأ وتوافر التوافر اللغوي للمحتوى.
التعلم المتواطؤ
يقدم التعلم المتواطؤ طريقة جديدة لمعالجة قيود المشاركة في البيانات والاختلافات اللغوية. من خلال تنقيط النماذج على مصادر بينما غير المركزية، يمكنك حفظ خصوصية المستخدمين وتعزيز أداء النماذج عبر اللغات المتعددة.
وقد أظهرت هذه الطريقة دقة أعلى بنسبة 6.9% وخفض 99% في أولويات التدريب بالمقارنة مع الطرق التقليدية، مما يجعلها حلول فعالة وفعالة لنظم التشعيب المتعددة اللغوية.
تخفيض التخيلات
إحدى التحديات الرئيسية في تنفيذ نظم RAG المتعددة اللغوية هو تخفيض التخيلات — حالات تقوم بتوليد معلومات خطأ أو غير متعلقة بالموضوع.
التقنيات RAG المتقدمة، مثل Modular RAG، تقدم وحدات جديدة واستراتيجيات التنقيط الدقيق لمعالجة هذه القضية. من خلال تحديث القاعدة المعلمة باستمرار واستخدام معايير تقييم جادة، يمكنك خفض بشكل كبير حالات التخيلات وتأكيد توافر المحتوى المنشأ وتوافر التوافر اللغوي للمحتوى.
تطبيق عملي
لتنفيذ هذه الاستراتيجيات بشكل فعال، تأخذ إلى إعتبار خطوات عملية مناسبة:
- استخدام الترجمة: ترجمة المستندات المنخفضة الموارد الى لغة موارد عالية مثل الانجليز
- استخدم التعبيرات المتعددة اللغوية: قم بدمج اللغات الوسطية مع تعبيرات جيدة لتحسين الأداء القواعدي.
- اتبع التعلم التوائم: تنقيط النماذج على مصادر البيانات الموزعة لتحسين الأداء بينما يحمي الخصوصية.
- تخفيف الهلوسات: استخدم تقنيات RAG متقدمة وتحديثات دائمة للمعلومات الرئيسية لضمان دقة ودوائم الحقائق.
بتبني هذه الاستراتيجيات يمكنك تحسين بشكل كبير أداء نظم RAG في البيئات النادرة والمتعددة اللغوية ، متأكدًا من أن لا تبقى أي لغة خلف في الثورة الرقمية.
فصل 5: تقنيات التحسين
يختار هذا الفصل التقنيات المتقدمة للبحث التي تؤسس فعالية نظم RAG المساعدة على التوليد. نتحدث عن كيفية تحسين التجميل، دمج المعلومات الوصفية، التسويق الشبكي، تقنيات الالignment، البحث التنوعي، والترتيب المجدي لزيادة دقة والتكرار والشاملية للبحث المعني.
بفهم هذه الطرق المتقدمة، ستحصل على منظور عن كيفية تطورت نظم RAG من مجرد محركات البحث الى مزودين المعلومات الذكية القادرين على فهم الأسئلة المعقدة وتوفير الإجابات الدقيقة والمتناسقة مع السياق.
5.1 تقنيات البحث المتقدم لتحسين RAG النظم
تغير نظم RAG الطريقة التي نتواصل بها بالحصول على وسائل المعلومات واستخدامها.
لنغوص بعمق في تقنيات الاسترجاع المتقدمة التي تمكن نظم RAG من تقديم إجابات دقيقة ومترابطة بالمحتوى وشاملة.
تحسين الفقاعات: تحسين النزاع من خلال الاسترجاع الجزئي
في عالم نظم RAG، يمكن أن تكون الوثائق الكبيرة مؤثرة. تحسين الفقاعات يعالج هذه التحدية عن طريق تقسيم النصوص الطويلة إلى وحدات أصغر وأكثر إمكانية التحكم بها تُسمى الفقاعات. هذه الدقة تسمح لأنظمة الاسترجاع بتحديد أجزاء محددة من النص التي تتماشى مع مصطلحات الاستعلام، مما يحسن الدقة والكفاءة.
فن تحسين الفقاعات يكمن في تحديد الحجم الافضل للفقاعة والتداخل. قد تفتقر الفقاعة الصغيرة إلى السياق، بينما قد يبطء الحجم الكبير من النزاع. التقسيم التدريجي الديناميكي، تقنية تتكيف حجم الفقاعة بناءً على هيكل وسيمانتيكات المحتوى، تؤكد أن كل فقاعة هي سليمة ومعنوية سياقياً.
تكامل البيانات الوصفية: إستخدام قوة الوسوم المعلوماتية
البيانات الوصفية، التي تُهمم العديد من الأشخاص، يمكن أن تكون معجزة لأنظمة الاسترجاع. من خلال تكامل البيانات الوصفية مثل نوع الوثيقة، الكاتب، تاريخ النشر ووسوم الموضوع، يمكن لنظم RAG أن تقوم ببحوث أكثر تحديداً.
استرجاع الاستعلام الذاتي، تقنية تمكنها تكامل البيانات الوصفية، تسمح للنظام بإنشاء استعلامات إضافية بناءً على النتائج الأولية. هذه العملية التكرارية تقوم بتحسين البحث، مؤكدة أن الوثائق التي تم استرجاعها تطابق الاستعلام وتلبي الحاجة الخاصة واحتياجات السياق للمستخدم.
بنية الفهرسة المتقدمة: الشبكات البيانية القائمة على الجراف للاستعلامات المعقدة
وتقنيات التنقل والبحث عن المؤشرات التقليدية، مثل قواعد المؤشر المعكوس وتسميم المجموعات الكثيفة، تحدد قيود بالتعامل مع التعقيدات المعقدة التي تشمل متعدد الأجسام وعلاقاتها. تقنيات البحث القائمة على الجرافت تقدم حلولاً بتنظيم الوثائق وعلاقاتها في هيكل جرافيكي.
تلك التنظيمات الجرافيكية تسمح بالسرقات والحصول على الوثائق المرتبطة بشكل فعال وحتى في مناخوات معقدة. تسميم المجموعات التسلسلية والبحث القريب للأقرب تميزاً تعزز القدرة المتنامية وسرعة النظم الإستعمالية القائمة على الجرافت.
تقنيات التوافق: ضمان الدقة وخفض الهلوسات
وتعتمد مواهب نظم RAG الموثوقة على قدرتها على تقديم المعلومات الدقيقة. تقنيات التوافق، مثل التrening المقابلي للحالات المفارقة، توجه إلى هذا القضية. من خلال تعريف النموذج بالحالات الإفتراضية، يعلم النموذج أن يتميز بين الحقائق العلمية والمعلومات المنشورة من خلال التخيل، وبذلك يقلل الهلوسات.
في نظم RAG المتعددة الوجهات التي تتكامل مع معلومات من مصادر مختلفة مثل النصوص والصور، يلعب دور مهارات التمايز المقابلي أساسياً. تقنية هذه توافق تمايزاً مع تمثيلات المعاني السيمانية للمعلومات المختلفة الأولويات، متأكدًا من توافق المعلومات المحولة والتناسق بالسياق الوطني.
البحث المزيد: مزيج الدقة مع فهم المعاني
يت
بعدها، يوفر بحث قائم على ال vectores تحسين النتائج بسبب التشابه السيمانيكي. هذه المقاربة فعالة بشكل خاص عندما يتوجب على الكلمات الدقيقة التطابق، لكن يتوجب أيضًا فهم عميق لما يتمتع به المقررة.
الترتيب المجدد: تحسين ال pertinencia للرد الأفضل
في مرحلة البحث الأخيرة، تأخذ خطوات الترتيب المجدد لتنقيح النتائج. تستخدم نماذج التعلم الآلي ، مثل المحاسبات المتقاطعة، لإعادة قياس النتائج المتعلقة بالمستندات التي تم إيجادها. من خلال معالجة المقررة والمستندات معاً، تحصل هذه النماذج على فهم عميق لتعلم علاقتهم.
هذه المقاربة التفاضلية تتأكد من أن أفضل المستندات المترتيبة بالأعلى تتالية بالمقررة التي يقدم للمستخدم السؤال والسياق، وتوفر مساعدة بحث أكثر إرتياحًا ومعلوماتًا كافية.
قوة أنظمة RAG تكمن في قدرتها على الحصول وتقديم المعلومات بشكل سلس. من خلال تطبيق هذه التقنيات المتقدمة المتعددة — تحسين القطع، تضمين المعلومات الفرعية، التسويق القائم على الرسم البياني، تقنيات التوافق، البحث المزدوج، والترتيب المجدد — أصبحت أنظمة RAG أكثر من محركات بحث. إنها تتحول إلى موردات معلومات أكثر ذكاءً، قادرة على فهم الأسئلة المعقدة، والتعرف على التفاصيل، وتوفير ردود فعالة دقيقة ومناسبة وموثوقة.
الفصل 6: التحديات والإبتكارات
يتمحور هذ
نحن نبحث في تعقيدات تقييم نظم RAG، بما في ذلك حاجة لمؤشرات شاملة وأساسات تكيفية لتقييم أداءها بالدقة. ونتناول أيضًا أحداث الأخلاقيات مثل تخفيض التحيز والعدالة في البحث وتوليد المعلومات.
نأخذ أيضًا في الاعتبار أهمية تسريع ال硬件 والاستراتيجيات التنفيذية الفعالة، ونشيد على استخدام ال hardware التخصصي وأدوات التحسين المتخصصة مثل Optimum لتعزيز الأداء والمتوسعة.
من خلال فهم هذه التحديات واستكشاف الحلول المحتملة، يوفر هذا الفصل خارطة شاملة للتقدم المستمر وتطبيق مسؤول لتكنولوجيا RAG.
6.1 التحديات وال方向 المستقبلية
أظهرت نظم RAG قدراتها إستثنائية في تحسين دقة وتوافق وترابط من النص المنتج. ومع ذلك، تطوير وتنفيذ نظم RAG يعتبر تحديات كبيرة تتوجب إلغاءها لتحقيق بشكل كامل قدراتها المحتملة.
“إذا تقييم النظم RAG يتطلب تخمين عدد كبير من المكونات الخاصة وتعقيد اختبار النظام بأكمله.” (Salemi et al.)
تحديات في تقييم RAG النظم
واحد من التحديات التقنية الرئيسية في RAG هو ضمان استخراج المعلومات المتعلقة بشكل فعال من قاعدات المعلومات الكبيرة النموذجية. (Salemi et al. و Yu et al.)
ولأن حجم وتنوع المصادر المعلوماتية يتمدد باستمرار، يصبح تطوير آليات استخراج قابلة للموازنة والمعتمدة أكثر أهمية بشكل متزايد. تقنيات مثل التسمية الهرمية، بحث الأقرب المتقربين بشكل تقريبي، والاستراتيجيات التكافؤية للاستخراج يتوجب البحث فيها لتحسين عملية الاستخراج.
بعض العناصر المعنية بنظام RAG – miro.medium.com
وتحدي آخر هو خفض مشاكل الهلوسة، حيث ينتج النموذج التوليدي معلومات خطأ أو غير متزايدة عن الواقع.
على سبيل المثال، قد تتولد نظام RAG 事件 التاريخي لم يحدث أو تخطأ تسمية اكتشاف علمي. بينما يساعد الاستخراج على توحيد النص المنتج بالمعلومات الواقعية، يبقى معالجة صدق المنتج المنشور وتوافقه مع المعلومات المنتجة معرفيًا معقد مشكلة.
على سبيل المثال، قد تتولد نظام RAG يحصل على معلومات دقيقة عن اكتشاف علمي من مصادر موثوقة مثل ويكيبيديا، لكن النموذج التوليدي قد يهلوس بتركيب هذه المعلومات بطريقة خاطئة أو بإضافة تفاصيل غير موجودة.
تطوير آليات فعالة لكشف ومنع الهلوسات هو مجال أكثر نشاطا في البحث. تتم استكشاف تقنيات مثل التحقق من الحقائق باستخدام قواعد خارجية والتحقق من التوافق من خلال المراجعة من مصادر متعددة. تتمحور هذه الطرق حول ضمان مواصلة توافر المحتويات المنتجة بشكل دقيق وموثوق، بالرغم من التحديات البرمجية التي تواجهها إلتزام العمليات الاسترجاعية والتوليدية.
الدمج الفرعي لمصادر المعرفة المتنوعة مثل القواعد البنية والنصوص الغير منظمة والبيانات المتعددة الأبعاد، يثير تحديات إضافية في نظم RAG. (يو والأخرين. و زيليز) وتوافق التمثيلات والمعاني بين الأوساط المختلف للبيانات والأصول المعرفية يتطلب تقنيات متقدمة مثل الانتباه المتعدد الأبعاد وتضمين المجال الداتا. وضمان التوافر والتفاعل البني للمصادر المعرفية المختلفة يعني شيئًا crucial للعملية الفعالة للأنظمة RAG. (زيليز)
وبشكل خارجي من التحديات التكنولوجية، ترفع أيضًا نظم RAG الأخلاقيات الرئيسية. تضمن ضمان البحث عن المعلومات وتوليدها بدون تحيز وعادلة قلق رئيسي. قد تمتد نظم RAG بتبديد تحيزات موجودة في البيانات التعليمية أو المصادر المعرفية، مما يميز إلى نتائج تمييزية أو خدعية. (Salemi et al. و Banafa)
تطوير تقنيات لكشف وتعديل التحيز، مثل التمرين المعادي والاستيعاب العادل، هو اتجاه بحث هام. (Banafa)
الاتجاهات البحثية المستقبلية
لمعالجة التحديات في تقييم الأنظمة RAG، يمكن استكشاف عدة حلول واتجاهات البحث المحتملة.
تطوير معايير تقييم شاملة تتضمن التفاعل بين دقة الاسترجاع وجودة التوليد من الضروري. (Salemi et al.)
تقييمات تقوم بتقييم التوافق, والترتيب, وصحة الحقائق للنصوص المنتجة بما في ذلك اهمية المكون الاستيعابي، يجب أن تنشأ. (Salemi et al.) هذا يتطلب تنظيم مبدأي شامل يتجاوز معايير البرمجيات التقنية التقليدية مثل BLEU و ROUGE ويشمل تقييمات البشر ومؤشرات خاصة بالمهمة.
إستكشاف إطارات التقييم التكيفية والتي تعمل في الوقت الحقيقي هو اتجاه آخر من الإمكانيات.
تشغل أنظمة RAG في بيئات ديناميكية حيث قمرات المعرفة والأحتياجات المستغيرة قد تتغير عبر الوقت. (Yu et al.) تطوير إطارات تقييم تستطيع التكيف بهذه التغيرات وتوفير تعليمات حية عن الأداء النظامي هو أساسي للتحسين المستمر والمراقبة.
قد يتضمن هذا تقنيات مثل التعلم الإلكتروني المتناول، والتعلم الفعال، والتعلم التعاملي لتحديث المعايير والنماذج التقييمية والنماذج الخاصة بالإعتماد على تقييمات المستخدمين وسلوك النظام. (Yu et al.)
تعاون الجهود التعاونية بين الباحثين وممارسي الصناعة وخبراء المجالات من الضروري لتقدم مجال تقييم RAG. إن تأسيس معايير واحدة وبيانات وprotocols للتقييم يمكن تسهيل المقارنة وإعادة توليد الأنظمة RAG عبر المجالات المختلفة والتطبيقات. (Salemi et al. و Banafa)
المشاركة مع الأصحاب المصادفة ، بما في ذلك المستهلكين النهائيين ومن يتخذ القرارات ، هو أساسي لضمان أن تطوير وتنفيذ الأنظمة RAG يتماشى مع القيم الاجتماعية ومع مبادئ الأخلاقيات. (Banafa)
إذا أظهرت الأنظمة RAG قدرات كبيرة، تحتاج التنبؤ بالتحديات في تقييمها للاستخدام الشامل والثقة. بتطوير معايير تقييم شاملة وباستكشاف أنظمة تقييم تكافؤية وفعالة وتعزيز الجهود التعاونية، يمكننا توزيع طريقة لأنظمة RAG أكثر موثوقية وبدون تحيز وفعالة.
وعندما يستمر المجال في التطور، يتم بحاجة للتوجيه للجهود البحثية التي لا تنتهي فقط بتقدم القدرات التقنية ل RAG ولكن أيضًا تتأكد من تنفيذها المسؤول والأخلاقي في التطبيقات العالمية.
6.2 تسريع الأجهزة وتنفيذ فعال لأنظمة RAG
تفعيل تسريع الأجهزة الخاصة هو الأساسي لنشر نظم الإسترجاع المعزز بالتوليد (RAG) بكفاءة. من خلال تحميل المهام الحساسة والمحتاجة للحوسبة إلى الأجهزة الخاصة، يمكنك تحسين أداء وقابلية التوسع لموديلات RAG الخاصة بك بشكل ملحوظ.
إستفادة من الأجهزة الخاصة
أدوات أوبتيوم لتحسين الأجهزة الخاصة توفر مزايا كبيرة. على سبيل المثال، نشر نظم RAG على معالجات Habana Gaudi يمكن أن يسبب خفضاً ملحوظاً في وقت التشخيص، بينما تحسينات Intel Neural Compressor يمكن أن تحسن مؤشرات التأخير. ويمكن للأجهزة AWS Inferentia التي تم تحسينها من خلال Optimum Neuron أن تعزز قدرات النَّفق، مما يجعل نظامك RAG أكثر استجابة وكفاءة.
تحسين إستخدام الموارد
إستخدام الموارد بكفاءة هو أمرٌ حاسم. تحسينات Optimum ONNX Runtime يمكن أن تؤدي إلى إستخدام أكثر كفاءة للذاكرة، بينما يمكن لموجهة BetterTransformer أن تحسن إستخدام المعالجات الكهربائية والمعالجات الرقمية. هذه التحسينات تضمن أن نظامك RAG يعمل بأداء متقدم، مما يقلل من التكاليف التشغيلية ويحسن الأداء.
القابلية للتوسع والمرونة
يدعم أوبتيوم التحول المتمركز بين محفزات الأجهزة المختلفة، مما يسمح بالقابلية المتحركة. هذا الدعم للأجهزة المتعددة يسمح لك بالتكيف مع الطلبات الحساسة للحوسبة دون إحتياج للتكوين الكبير. وبالإضافة إلى ذلك، تمييز النماذج وميزات التقليص في أوبتيوم يمكن أن تسهّل حجم النموذج، مما يجعل النشر أسهل وأكثر قدرة توظيفية.
دراسات الحالة وتطبيقات العالم الواقعي
تخطيط تطبيق Optimum في استخراج المعلومات في مجال الرعاية الصحية. من خلال تسخير التحسينات التي تخص الأجهزة، يمكن للأنظمة RAG معالجة أحجام المعلومات الكبيرة بكفاءة وفي وقت مناسب، مما يحسن جودة تقديم الرعاية الصحية ويعزز تجربة المستخدم بالكامل. ليس هذا مجرد تحسين جودة تقديم الرعاية الصحية، بل يمكن أيضًا تحسين تجربة المستخدم بأكملها.
خطوات عملية للتنفيذ
- اختيار المعدات المناسبة: اختر المساعدات المحددة مثل Habana Gaudi أو AWS Inferentia وفقاً لتوجهاتك الخاصة بالأداء المطلوب.
- استخدام أدوات التحسين: تطبيق أدوات Optimum لتحسين التأخير، وال throughput واستخدام الموارد.
- تأمين التنمية: تسخير الدعم للمعدات المتعددة لتنمية نظام RAGك بشكل ديناميكي وحسب الحاجة.
- تحسين حجم النماذج: استخدم التكامل النموذجي وتنقيح النماذج لخفض تكاليف المعالجة العام وتسهيل تنفيذها.
بتكامل هذه الاستراتيجيات، يمكنك تحسين بشكل كبير أداء، والتنمية والكفاءة من نظمك الRAG، متأكدًا من أنها معتمدة جيدًا لمعالجة التطبيقات المعقدة الحقيقية.
ختام: قدرات الRAG التحولية
تعد Retrieval-Augmented Generation (RAG) تمثل تحولية كبيرة في مجال التحليل الطبيعي لللغة، التي تدمج بشكل نابض قوة استخراج المعلومات مع قدرات النماذج الكبيرة
بتسخير المصادر الخارجية، أظهرت نظم RAG تحسنات لا تُرمي في الدقة والتناسق والترابط مع النصوص التي ينتج عنها على نطاق واسع من التطبيقات، من الإجابة عن الأسئلة والأنظمة الحاسوبية للحديث إلى التوحيد والكتابة الإبداعية.
تطور نماذج اللغة، من الأنظمة القانونية المبنية على القواعد إلى التقنيات العصبية الحديثة مثل BERT و GPT-3، قد أبرز الطريقة لظهور RAG. تم تعالي قيود الذات الطبيعية في النماذج اللغوية التقليدية، مثل تاريخ حد قابلية المعرفة وتوازنات واقعية غير صحيحة، بتسريع تضمين الذات الغير قابلية للتخمينات من خلال آليات الاستعمال التابعة للبحث.
أعضاء أساسية RAG المعنية بالإستعمال، وهي المحركات الإحتياجية والنماذج التوليدية، تعمل سويًا لإنتاج ناتجات متعلقة بالحالة ومبنية على الحقائق.
المحركات الإحتياجية، وتسخر تقنيات مثل البحث النادر والكثيف، تبحث بكفاءة عن المعلومات الأكثر صلابة في قواعد المعلومات الكبيرة لتحدد المعلومات الأكثر صلابة. والنماذج التوليدية، وتسخر تقنيات مثل GPT و T5، تصيّر المعلومات المحركة إلى النصوص التي تبدو واحدة واحدة واحدة.
الاستراتيجيات التحكمية، مثل التراكم والانتباه المقارب، تحدد كيفية تدمير المعلومات المحركة في عملية التوليد.
تتميز التطبيقات العامة ل RAG على أنها قادرة على تغيير مختلف الصناعات.
في الإجابة عن الأسئلة، أحسنت RAG دقة وتوافق الإجابات، مما يسمح لنا باستيعاب معلومات أكثر منطقة وداعمة. ساعدت RAG الأنظمة الحوارية على جلب المشاركين وجعلت المحادثات أكثر إشباعاً ومنظمة. وزادت مهارات التوصيل القصير بجلب المعلومات المناسبة من مصادر متعددة، مما أحسن جودة وتوافق التوصيل. وقد تم استكشاف حتى الكتابة الإبداعية، حيث أن تقنيات RAG تنتج قصص جديدة وتوافق طريقة الكتابة.
ولكن تطوير وتقييم الأنظمة RAG يعرض على تحديات كبيرة. من التحديات التقنية التي يتضمن حلها تحصيل فعال من قاعدات المعرفة الكبيرة في حجمها، وتخفيض التخيل، ودمج تنوع المصادر المتعددة للبيانات. ويعم الأمور الأخلاقية أيضًا مهمة للتطوير السليم للأنظمة RAG، مثل ضمان تحصيل المعلومات المتوافقة وبدون تحيز والتوليد المتوافق.
لتحقيق قدرات RAG بالكامل، يتوجب تحديد اتجاهات البحث المستقبلية تحكم في تطوير معايير تقييم شاملة تتسبب في مقابلة التوافق بين دقة التحصيل وجودة الإنتاج.
وهي أحاديث التكيف والتقييم الفعال الوقتي القادر على التعامل مع طبيعة التغيير في الأنظمة RAG من الضروري للتحسين المستمر والمراقبة. وتتضمن جهود التعاون بين الباحثين، والممارسين في الصناعة، والخبراء في المجالات الأخرى لتأسيس معايير قياس وبيانات وprotocols التقييم.
ومع تطور مجال راد أكبر له التوقعات الكبيرة لتغيير كيفية تفاعلنا مع المعلومات وإنتاجها. من خلال تحميل قوة بين الاستخراج والتوليد، تحظى أنظمة راد بالقدرة على تغيير مجالات مختلفة، من إستخراج المعلومات والمواطنين المتحدثين إلى إنشاء المحتويات واكتشاف المعلومات.
التوليد المساعد بالاستخراج يمثل معالم هام في رحلة إلى تطور لتوليد اللغة الأكثر ذكاءً، دقةً وتعاطفًا بالسياق.
بمجرد بناء الجسم بين الذاكرة المتعددة المتغيرة وغير المتغيرة، أفقد أنظمة راد الإمكانات الجديدة للتحليل الطبيعي لللغة وتطبيقاته.
ومع تقدم البحث وحل التحديات، يمكننا أن نتوقع أن يلعب راد دورًا أكبر في تشكيل مستقبل التفاعل البشري-الآلي وتوليد المعلومات.
عن المؤلف
هنا فاه أسلانيان في مركزي العلوم الحاسوبية والعلوم البيانية والتطبيقات الذكية. قادم إلى vaheaslanyan.comلرؤية مجموعة من العمل تشهد الدقة والتقدم. تقايد خبرتي بين تطوير التطبيقات الكاملة وتحسين المنتجات الذكية، موجب حل المشاكل بطرق جديدة.
بما يشمل سجل مهني يحتوي على بدء موقع معهد رئيسي للعلوم البيانية والعمل مع أفضل الخبراء في الصناعة، يبقى تركيزي على رفع مستوى التعليم التكنولوجي إلى معايير عالمية.
كيف يمكنك الغوص أعمقاً؟
بعد دراسة هذه الدراسة، إذا كنت مهتمًا بالغوص أعمقاً وهو النموذج المنظم للتعلم، فيمكنك أن تنضم إلينا في LunarTech، نقدم دورات شخصية وموقع تدريبي في العلوم البيانية والتعلم الآلي والتكنولوجيا الذكية.
نقدم برنامج شامل يوفر فهم عميق للمبادئ وتطبيقها العملي الفعال ومواد ممارسة واسعة وتأهيل تعيين المقابلات من أجل تأمين نجاحك في مرحلة خاصة بك.
يمكنك أن تفحص مهمة البحث العلمي النهائية والانضمام لتجربة مجانية لتختبر المحتويات بأيديك. ألزم هذا بأن يكون إعتباره أحد أفضل مهام البحث العلمي النهائية لعام 2023، وتم تقديمه في مناظر مهمة مثل Forbes، Yahoo، الرائد الأعمالي وما إلى ذلك. هذه فرصتك للمشاركة في مجموعة تعمل بتعزيز الإبداع والمعرفة. هذه رسالة مرحباء!
اتصل بي.

مجلة LunarTechالخبرات
- تتبعني على LinkedIn لمجموعة كبيرة من الموارد المجانية في التكنولوجيا الشبكية، المعلومات الحسابية والذكاء
- زور موقعي الشخصي
- اشترك في تقاريري الخبرات العلمية والذكاء
إذا أردت أن تتعلم المزيد عن مجال تخصصك في العلوم التابعة للبيانات، والتعلم الذكي، والذكاء الصناعي، وتعلم كيفية تأمين وظيفة في تخصص البيانات، يمكنك تحميل هذا المعلومات المجانية الخاصة بـ دفعة وظائف العلوم التابعة للبيانات والذكاء.
Source:
https://www.freecodecamp.org/news/retrieval-augmented-generation-rag-handbook/