













Ricerca Collegamenti Generazione (RAG) rappresenta un’avanzamento rivoluzionario nei grandi modelli di linguaggio (LLM). Combina la capacità generativa delle architetture transformer con l’integrazione dinamica di informazioni di ricerca.
Questa integrazione consente ai modelli di linguaggio di accedere e integrare conoscenze esterne appropriate durante la generazione del testo, portando a risultati più accurate, contestuali e coerenti factualmente.
L’evoluzione dai primi sistemi basati su regole agli sofisticati modelli neurali come BERT e GPT-3 ha aperto la strada per RAG, risolvendo i limiti della memoria parametrica statica. Anche l’avvento di RAG Multimodale estende queste capacità integrando diversi tipi di dati come immagini, audio e video. Ciò aumenta la ricchezza e la rilevanza del contenuto generato.
Questo cambiamento di paradigma non solo migliora l’accuratezza e l’interpretabilità degli output di LLM, ma anche supporta applicazioni innovative in diversi domini.
Ciò che tratterremo:
- Capitolo 1. Introduzione a RAG
– 1.1 Cosa è RAG? Un’introduzione
– 1.2 Come RAG risolve problemi complessi - Capitolo 2. Fondamenti tecnici
– 2.1 Passaggio da LM neurali a RAG
– 2.2 Comprendere la memoria di RAG: parametrico contro non-parametrico
– 2.3 RAG multi-modale: integrazione di diversi tipi di dati - Capitolo 3. Mechanismi principali
– 3.1 La potenza della combinazione di Informazione di Recupero e Generazione in RAG
– 3.2 Strategie di integrazione per Recuperatori e Generatori - Capitolo 4. Applicazioni e casi d’uso
– 4.1 RAG al lavoro: dalla QA alla creazione letteraria
– 4.2 RAG per lingue a risorse scarse: estendere la portata e le capacità - Capitolo 5. Tecniche di ottimizzazione
– 5.1 Tecniche avanzate di recupero per l’ottimizzazione dei sistemi RAG - Capitolo 6. Sfide e innovazioni
– 6.1 Sfide attuali e direzioni future per RAG
– 6.2 Accelerazione hardware e efficiente distribuzione di sistemi RAG - Capitolo 7. Pensieri conclusivi
– 7.1 Il futuro di RAG: conclusioni e riflessioni
Prerequisiti
Per impegnarsi con contenuti focalizzati su modelli di linguaggio grandi (LLM) come il Retrieval-Augmented Generation (RAG), due prerequisiti essenziali sono:
- Fondamenti dell’apprendimento automatico: Comprendere i concetti di base dell’apprendimento automatico e degli algoritmi è cruciale, specialmente come li applica all’architettura di reti neurali.
- Processamento del linguaggio naturale (NLP): Conoscenza delle tecniche di NLP, comprese la preelaborazione del testo, la tokenizzazione e l’uso di embedded, è fondamentale per lavorare con i modelli di linguaggio.
Capitolo 1: Introduzione a RAG
Retrieval-Augmented Generation (RAG) rivoluziona il processamento del linguaggio naturale combinando l’informazione di ricerca e i modelli generativi. RAG accede dinamicamente alle conoscenze esterne, migliorando l’accuratezza e la rilevanza del testo generato.
Questo capitolo esplora i meccanismi di RAG, i suoi vantaggi e i suoi svantaggi. Viene approfondito su tecniche di ricerca, l’integrazione con i modelli generativi e l’impatto su varie applicazioni.
RAG attenua le allucinazioni, incorpora informazioni aggiornate e affronta problemi complessi. Viene anche discusso il challenge come l’efficienza della ricerca e le considerazioni etiche. Questo capitolo fornisce una comprensione completa del potenziale rivoluzionario di RAG nel processamento del linguaggio naturale.
1.1 Che cos’è RAG? Una panoramica
Retrieval-Augmented Generation (RAG) rappresenta un cambiamento di paradigma nel processamento del linguaggio naturale, integrando senza problemi i punti forti dell’informazione di ricerca e dei modelli di linguaggio generativi. I sistemi RAG sfruttano le fonti di conoscenza esterne per migliorare l’accuratezza, la rilevanza e la coerenza del testo generato, risolvendo i limiti della memoria parametrica pura nei modelli di linguaggio tradizionali. (Lewis et al., 2020)
Attraverso il recupero dinamico e l’integrazione di informazioni relative durante il processo di generazione, RAG consente output più contestualmente radicati e coerenti in termini di fatti in una vasta gamma di applicazioni, dalla risposta a domande e sistemi di dialogo alle riassunzioni e alla scrittura creativa. (Petroni et al., 2021)
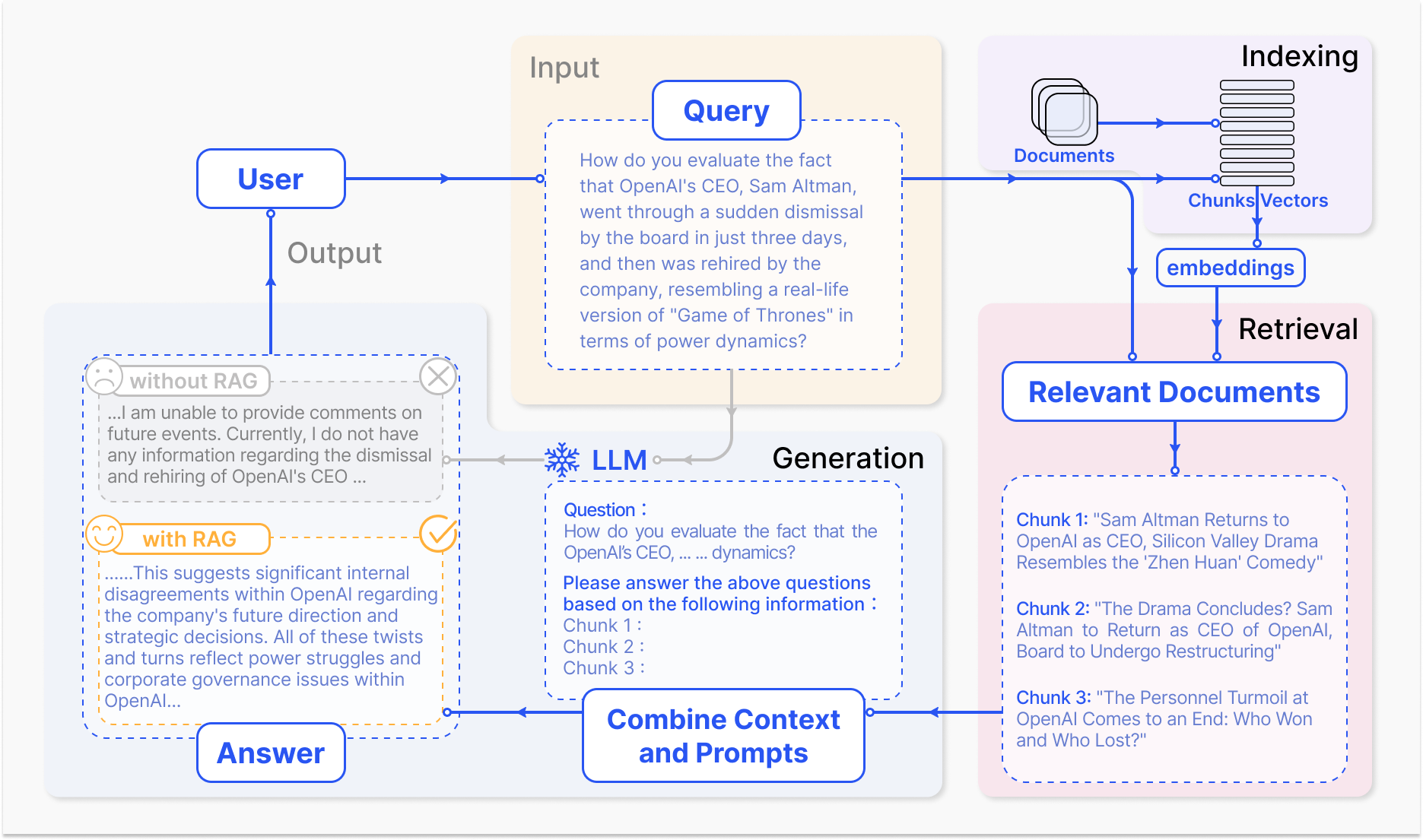
Come funziona un sistema RAG – arxiv.org
Il meccanismo di base di RAG comprende due componenti primarie: recupero e generazione.
Il componente di recupero cerca efficientemente attraverso basi di conoscenza immense per identificare le informazioni più pertinenti in base alla richiesta di input o al contesto. Vengono utilizzate tecniche come lo sparso recupero, che utilizza indici invertiti e corrispondenza basata su termini, e il denso recupero, che impiega rappresentazioni vettoriali dense e similitudine semantica, per ottimizzare il processo di recupero. (Karpukhin et al., 2020)
Le informazioni recuperate vengono poi integrate nel modello generativo, di solito un grande modello di linguaggio come GPT o T5, che sintetizza il contenuto rilevante in una risposta coerente e fluida. (Izacard & Grave, 2021)
y>
L’integrazione della ricerca e della generazione in RAG offre diversi vantaggi rispetto ai modelli di linguaggio tradizionali. Facendo fondare il testo generato su conoscenze esterne, RAG riduce significativamente l’incidenza di allucinazioni o output fattualmente errati (Shuster et al., 2021).
RAG consente inoltre di integrare informazioni aggiornate, assicurando che le risposte generate riflettano le ultime conoscenze e sviluppi in un determinato campo (Lewis et al., 2020). Questa adattabilità è particolarmente importante in settori quali la sanità, la finanza e la ricerca scientifica, in cui l’accuratezza e l’aggiornamento delle informazioni sono di fondamentale importanza (Petroni et al., 2021).
Tuttavia, lo sviluppo e il deployment di sistemi RAG presentano anche notevoli sfide. La ricerca efficiente in basi di conoscenza a grande scala, la mitigazione delle allucinazioni e l’integrazione di diverse modalità di dati sono alcuni degli ostacoli tecnici che devono essere affrontati (Izacard & Grave, 2021).
Anche le considerazioni etiche, come garantire un’estrazione e generazione di informazioni imparziali e fair, sono cruciali per il responsabile impiego di sistemi RAG. (Bender et al., 2021) Lo sviluppo di metriche di valutazione e framework completi che catturino l’interazione tra accuratezza di estrazione e qualità generativa è essenziale per valutare l’efficacia dei sistemi RAG. (Lewis et al., 2020)
Con il proseguimento del campo RAG, le direzioni di ricerca future si concentrano sull’ottimizzazione dei processi di estrazione, sulla espansione delle capacità multimodali, sullo sviluppo di architetture modulari e sull’istituzione di framework di valutazione robusti. (Izacard & Grave, 2021) Questi progressi potranno aumentare l’efficienza, l’accuratezza e l’adattabilità dei sistemi RAG, aprendo la strada a più intelligenti e versatili applicazioni nel processamento del linguaggio naturale.
Ecco un semplice esempio di codice Python che dimostra un setup di Retrieval Augmented Generation (RAG) utilizzando le popolari librerie LangChain e FAISS:
from langchain.embeddings import OpenAIEmbeddings
from langchain.vectorstores import FAISS
from langchain.document_loaders import TextLoader
from langchain.chains import RetrievalQA
from langchain.llms import OpenAI
# 1. Caricare e incorporare documenti
loader = TextLoader('your_documents.txt') # Sostituisci con la tua fonte documentale
documents = loader.load()
embeddings = OpenAIEmbeddings()
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. Recuperare documenti rilevanti
def retrieve_docs(query):
return vectorstore.similarity_search(query)
# 3. Configurare la catena RAG
llm = OpenAI(temperature=0.1) # Regolare la temperatura per la creatività della risposta
chain = RetrievalQA.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# 4. Utilizzare il modello RAG
def get_answer(query):
return chain.run(query)
# Esempio di utilizzo
query = "What are the key features of Company X's latest product?"
answer = get_answer(query)
print(answer)
#Esempio di utilizzo Storia dell'azienda
query = "When was Company X founded and who were the founders?"
answer = get_answer(query)
print(answer)
#Esempio di utilizzo Rendimento finanziario
query = "What were Company X's revenue and profit figures for the last quarter?"
answer = get_answer(query)
print(answer)
#Esempio di utilizzo Outlook futuro
query = "What are Company X's plans for expansion or new product development?"
answer = get_answer(query)
print(answer)
Trascinando il potere del recupero e della generazione, RAG promette un’enorme promessa per trasformare il modo in cui interagiamo con l’informazione e la generazione, rivoluzionando diversi domini e modellando il futuro dell’interazione uomo-macchina.
1.2 Come RAG risolve problemi complessi
La Generazione Augmentata da Recupero (RAG) offre una soluzione potente per i problemi complessi che i tradizionali modelli di grandi linguaggi (LLM) lottano a risolvere, in particolare in scenario con vasti quantità di dati non strutturati.
Un such problema è la capacità di impegnarsi in conversazioni significative riguardo documenti specifici o contenuti multimediali, come ad esempio i video di YouTube, senza un fine-tuning preventivo o un training esplicito sulla materiale di destinazione.
Le tradizionali LLM, nonostante la loro impressionante capacità di generazione, sono limitate dalla loro memoria parametrica, fissa al momento dell’addestramento. (Lewis et al., 2020) Ciò significa che non possono accedere direttamente o integrare nuove informazioni oltre ai dati di addestramento, rendendo difficile impegnarsi in discussioni informate su documenti o video non visti.
Conseguentemente, le LLM possono generare risposte inconsistenti, irrilevanti o erronee factuali quando richiamate con domande relative a contenuti specifici. (Petroni et al., 2021)
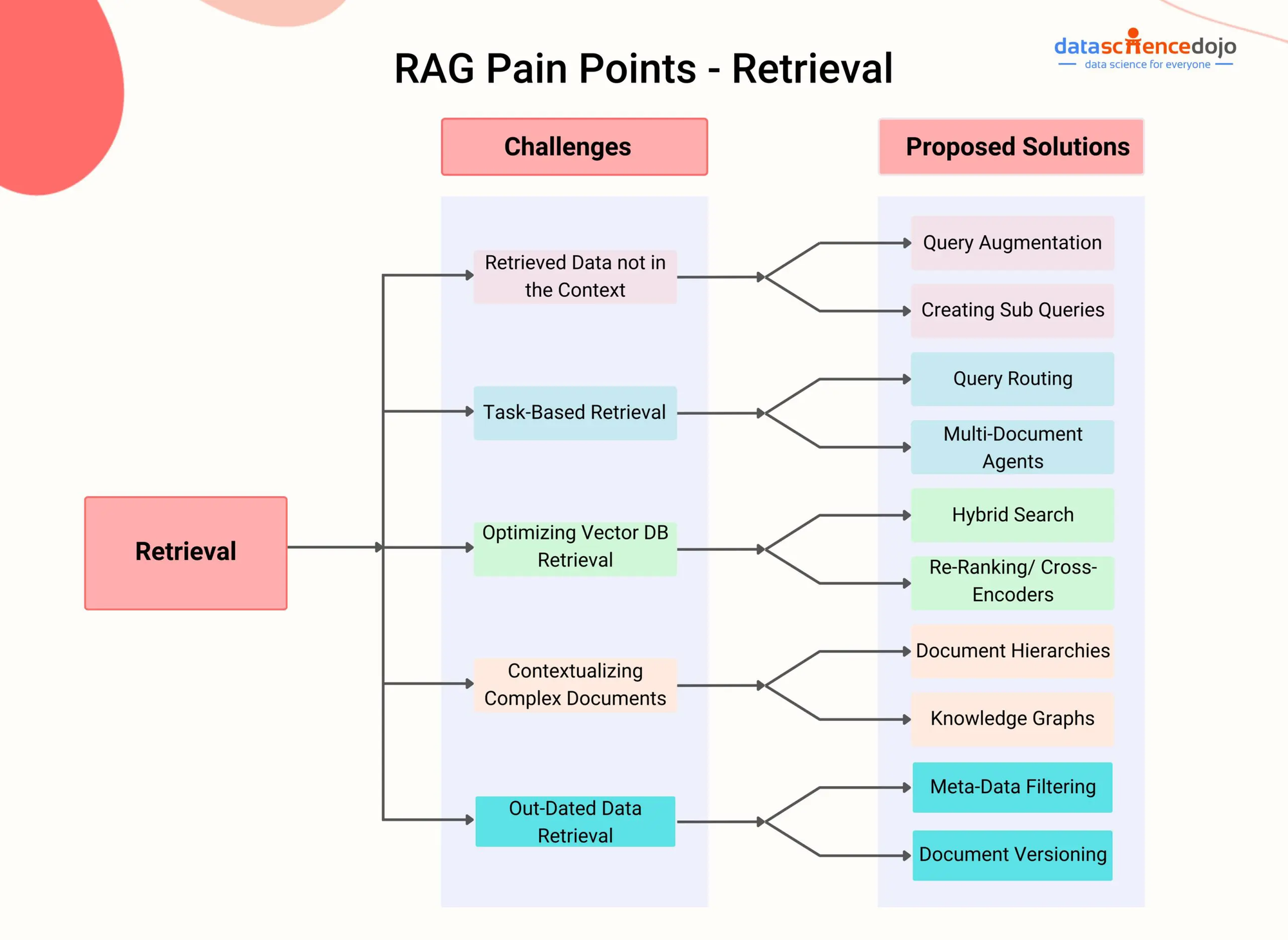
Punti di dolore RAG – DataScienceDojo
RAG affronta questa limitazione integrando un componente di ricerca che consente al modello di accessare dinamicamente e integrare informazioni relevanti da fonti di conoscenza esterne durante il processo di generazione.
Utilizzando tecniche avanzate di ricerca, come la ricerca di passaggi densi (Karpukhin et al., 2020) o la ricerca ibrida (Izacard & Grave, 2021), i sistemi RAG possono identificare efficientemente i passaggi o segmenti più pertinenti da un documento o video dato in base al contesto conversazionale.
Ad esempio, considerate una situazione in cui un utente vuole impegnarsi in una conversazione riguardo un determinato video scientifico su YouTube. Un sistema RAG può prima trascrivere il contenuto audio del video e poi indicizzare il testo risultante utilizzando rappresentazioni vettoriali dense.
Successivamente, quando l’utente fa una domanda legata al video, il componente di recupero del sistema RAG può rapidamente identificare le passaggi più rilevanti dalla trascrizione in base alla similitudine semantica tra la query e il contenuto indicizzato.
I passaggi recuperati vengono quindi forniti alla modella generativa, la quale produce una risposta coerente e informativa che risponde direttamente alla domanda dell’utente e che fa riferimento al contenuto del video. (Shuster et al., 2021)
Questo approcio consente a sistemi RAG di impegnarsi in conversazioni knowledgeable su un ampio range di documenti e contenuti multimediali senza la necessità di una fine-tuning esplicita. Dynamically retrieving e incorporando informazioni rilevanti, RAG può generare risposte più accurate, connesse al contesto e coerenti con i fatti rispetto ai tradizionali LLM. (Lewis et al., 2020)
Anche la capacità di RAG di gestire dati non strutturati da varie modalità, come testo, immagini e audio, lo rende una soluzione versatile per problemi complessi che coinvolgono fonti informazioni eterogenee. (Izacard & Grave, 2021) Man mano che i sistemi RAG si evolvono, la loro capacità di affrontare problemi complessi in diversi domini aumenta.
Utilizzando tecniche avanzate di recupero e integrazione multimodale, RAG può consentire agli agenti conversazionali intelligenti e attenti al contesto, ai sistemi di raccomandazione personalizzati e alle applicazioni basate sulla conoscenza.
Con il progredire della ricerca nei settori come l’indicizzazione efficiente, l’allineamento cross-modal e l’integrazione recupero-generazione, RAG giocherà certamente un ruolo cruciale nel spingere i limiti del possibile con i modelli linguistici e l’intelligenza artificiale.
Capitolo 2: Solidi fondamenti tecnici
Questo capitolo si immerge nella meravigliosa realtà del Multimodal Retrieval-Augmented Generation (RAG), un approcio all’avanguardia che supera i limiti dei tradizionali modelli basati su testo.
Integrando in maniera fluida dati modalità diversi come immagini, audio e video con i Large Language Models (LLM), il Multimodal RAG dà potere ai sistemi AI per ragionare in un panorama informativo più ricco.
Esploreremo i meccanismi dietro questa integrazione, come l’apprendimento contrastivo e l’attenzione cross-modal, e come essi consentano agli LLM di generare risposte più sottili e rilevanti contestualmente.
Anche se i RAG multimodali offrono benefici promettenti come un migliore accuracy e la possibilità di supportare nuovi casi d’uso come la risposta a domande visive, presentano anche sfide uniche. Queste sfide comprendono il bisogno di grandi dataset multimodali, una complessità computazionale incrementata e il potenziale per il bias nell’informazione recuperata.
mentre iniziamo questa avventura, non solo scopriremo il potenziale trasformativo dei RAG multimodali, ma anche esaminerremo criticamente i problemi che ci attendono, aprendo la strada per un approcio più profondo a questo campo in rapida evoluzione.
2.1 Neural LMs ai RAG
L’evuzione dei modelli neurali ha seguito un progressivo sviluppo dai primi sistemi basati su regole ai modelli sempre più sofisticati basati sulla statistica e sulla rete neurale.
Nei primi anni, i modelli linguistici si basavano su regole create a mano e conoscenze linguistiche per generare testo, ottenendo risultati rigidi e limitati. L’avvento dei modelli statistici, come i modelli di n-gramma, ha introdotto un approcio guidato da dati che imparava pattern da grandi corpi di testo, permettendo la generazione di linguaggio più naturale e coerente. (Redis)
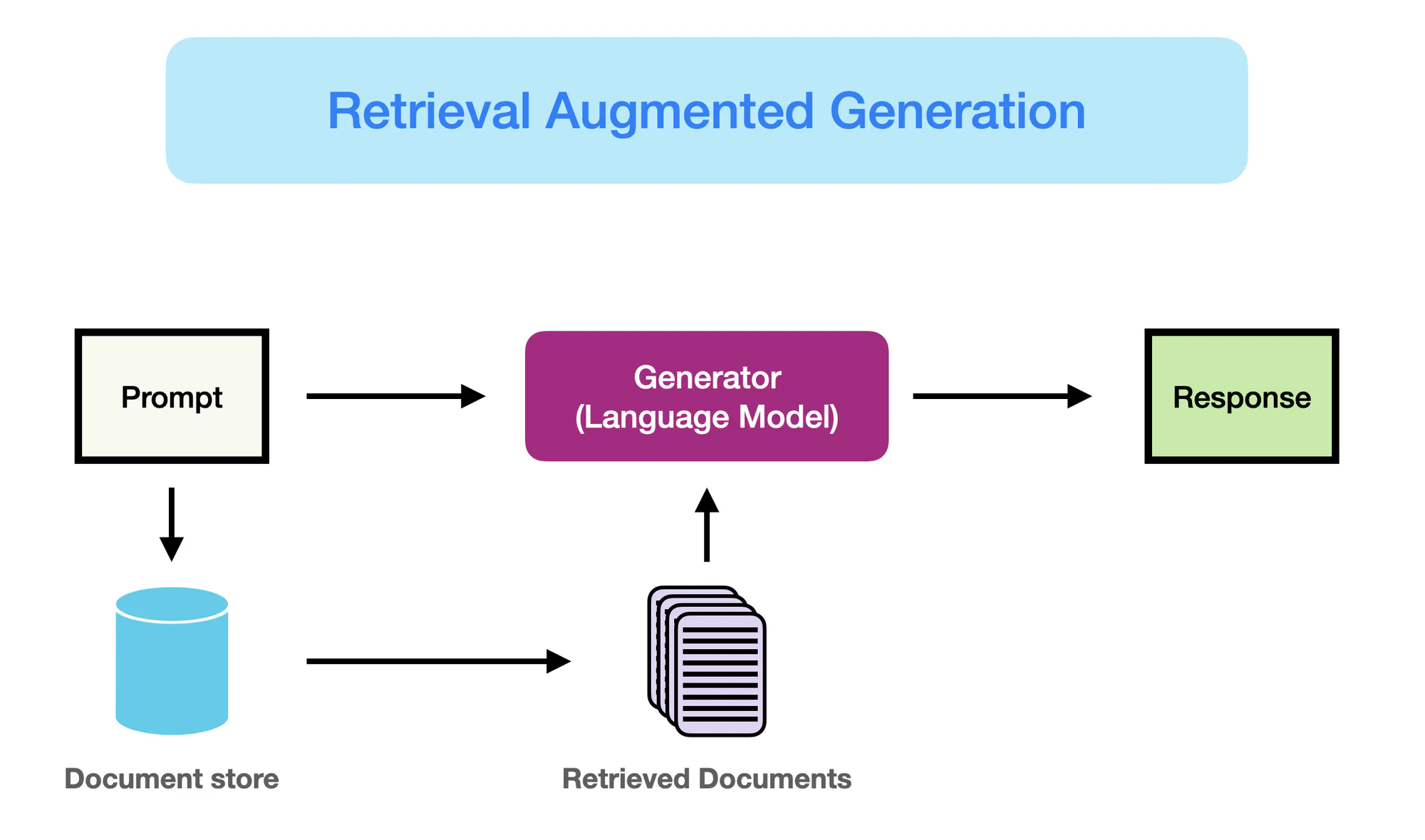
Come funziona RAG – promptingguide.ai
Tuttavia, è stata l’emergenza di modelli basati su reti neurali, in particolare architetture transformer come BERT e GPT-3, ad aver rivoluzionato il campo dell’elaborazione del linguaggio naturale (NLP).
Queste modelli, noti come grandi modelli di linguaggio (LLM), sfruttano il potere dell’apprendimento profondo per catturare pattern linguistici complessi e generare testo umanoide con fluenza e coerenza senza precedenti. (Yarnit) L’aumento della complessità e della scala dei LLM, con modelli come GPT-3 che si orgogliano di oltre 175 miliardi di parametri, ha condotto a capacità eccezionali in task come la traduzione del linguaggio, la risposta alle domande e la creazione del contenuto.
Nonostante la loro impressionante performance, i classici LLM soffrono di limitazioni a causa della loro dipendenza dalla memoria parametrica pura. (StackOverflow) La conoscenza codificata in questi modelli è statica, limitata dalla data di scadenza dei loro dati di addestramento.
Come risultato, LLM possono generare output che sono fattualmente errati o non coerenti con le informazioni più aggiornate. Anche la mancanza di accesso esplicito a fonti di conoscenza esterne limita la loro capacità di fornire risposte accurate e rilevanti in contesto alle query di tipo conoscenza intensivo.
La Retrieval Augmented Generation (RAG) emerge come una soluzione rivoluzionaria per affrontare queste limitazioni. Attraverso l’integrazione fluida delle capacità di informazione di recupero con il potere generativo degli LLM, RAG consente ai modelli di accedere dinamicamente e incorporare conoscenza rilevante da fonti esterne durante il processo di generazione.
Questa fusione tra memoria parametriche e non-parametriche consente agli LLM dotati di RAG di produrre output fluenti e coerenti, ma anche accurate dal punto di vista delle informazioni e informati dal contesto.
RAG rappresenta un salto qualitativo significativo nella generazione del linguaggio, unendo le potenzialità degli LLM con il vastoknowledge disponibile negli archivi esterni. Sfruttando i migliori aspetti di entrambi i mondi, RAG rende i modelli in grado di generare testo più affidabile, informativo e allineato alle conoscenze del mondo reale.
Questo cambiamento di paradigma apre nuove possibilità per le applicazioni NLP, dalla risposta alle domande e dalla creazione di contenuti alle attività knowledge-intensive in ambiti quali la sanità, la finanza e la ricerca scientifica.
2.2 Memoria Parametrica contro Non-Parametrica
La memoria parametrica si riferisce alle conoscenze memorizzate all’interno dei parametri dei modelli di linguaggio pre-addestrati, come BERT e GPT-4. Questi modelli imparano a catturare pattern linguistici e relazioni dai vasti quantità di dati testuali durante il processo di addestramento, codificando queste conoscenze nei loro milioni o miliardi di parametri.
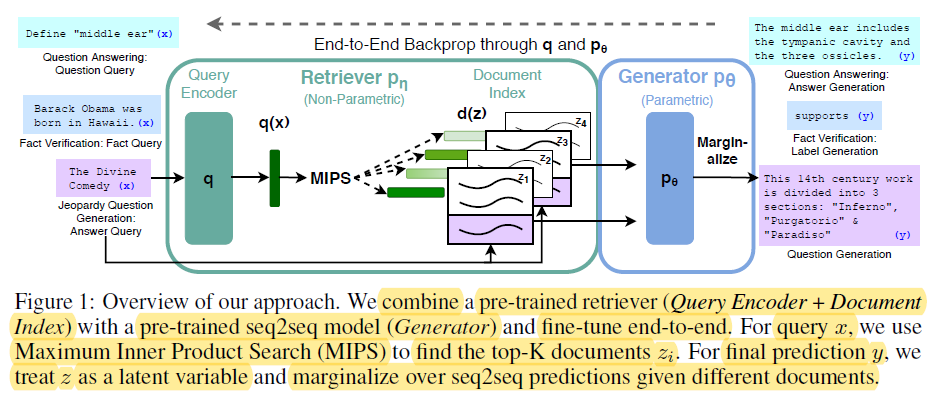
End-t-End Backprop through q and p0 – miro.medium.com
Le potenzialità della memoria parametrica includono:
- Fluenza: I modelli di linguaggio pre-addestrati generano testo simile all’uomo con una fluenza e coerenza notevoli, catturando le sfumature e lo stile della lingua naturale. (Redis e Lewis e altri.)
- Generalizzazione: La conoscenza contenuta nei parametri del modello consente all’algoritmo di generalizzare nuove attività e domini, permettendo l’apprendimento di trasferimento e l’apprendimento a partire da pochi esempi. (Redis e Lewis e altri.)
Tuttavia, la memoria parametrica anche ha limitazioni significative:
- Errori di fatto: I modelli di linguaggio possono generare output che non sono coerenti con i fatti del mondo reale, poiché la loro conoscenza è limitata ai dati su cui sono stati addestrati.
- Conoscenza obsoleta: La conoscenza contenuta nei parametri del modello diventa obsoleta con il tempo, poiché è fissa al momento dell’addestramento e non riflette aggiornamenti o cambiamenti nel mondo reale.
- Costo computazionale elevato: L’addestramento di grandi modelli di linguaggio richiede enormi quantità di risorse computazionali ed energia, rendendone il processo costoso e lungo per aggiornare la sua conoscenza.
- Conoscenza generale: La conoscenza catturata dai modelli basati su linguaggio è ampia e generale, ma manca della profondità e specificità richiesta per molte applicazioni specifiche del dominio.
Invece, la memoria non parametrica si riferisce all’uso di fonti di conoscenza esplicite, come database, documenti e grafi delle conoscenze, per fornire informazioni aggiornate e accurate ai modelli basati su linguaggio. Queste fonti esterne fungono da memoria complementare, permettendo ai modelli di accedere e recuperare informazioni relative in tempo reale durante il processo di generazione.
I benefici della memoria non parametrica comprendono:
- Informazioni aggiornate: Le fonti di conoscenza esterne possono essere facilmente aggiornate e mantenute, garantendo al modello l’accesso alle informazioni più recenti e accurate.
- Riduzione degli allucinazioni: “Ricercando informazioni relative da fonti esterne, RAG riduce significativamente l’incidenza di allucinazioni o output generativi non corretti sulla base di fatti.” (Lewis et al. e Guu et al.)
- Conoscenza specifica del dominio: La memoria non-parametrica consente ai modelli di sfruttare conoscenze specializzate da fonti specifiche del dominio, permettendo output più accurate e contestualmente rilevanti per applicazioni specifiche. (Lewis e altri. e Guu e altri.)
Le limitazioni della memoria parametrica sottolineano la necessità di un cambiamento di paradigma nella generazione del linguaggio.
RAG rappresenta un significativo avanzamento nel processamento del linguaggio naturale, migliorando il rendimento dei modelli generativi attraverso l’integrazione di tecniche di informazione di ricerca. (Redis)
Ecco il codice Python per dimostrare la distinzione tra memoria parametrica e non-parametrica nel contesto di RAG, insieme a un output chiaro che ne evidenzia la differenza:
from sentence_transformers import SentenceTransformer
from langchain.embeddings import HuggingFaceEmbeddings
from langchain.vectorstores import FAISS
from langchain.chains import RetrievalQAWithSourcesChain
from langchain.llms import OpenAI
# Collezione di documenti di esempio (supponiamo documenti più lunghi in una situazione reale)
documents = [
"The Large Hadron Collider (LHC) is the world's largest and most powerful particle accelerator.",
"The LHC is located at CERN, near Geneva, Switzerland.",
"The LHC is used to study the fundamental particles of matter.",
"In 2012, the LHC discovered the Higgs boson, a particle that gives mass to other particles.",
]
# 1. Memoria Non-Parametrica (Ricerca tramite Embedding)
model_name = "sentence-transformers/all-mpnet-base-v2"
embeddings = HuggingFaceEmbeddings(model_name=model_name)
vectorstore = FAISS.from_documents(documents, embeddings)
# 2. Memoria Parametrica (Modello di Linguaggio con Ricerca)
llm = OpenAI(temperature=0.1) # Regolare la temperatura per la creatività dell'output
chain = RetrievalQAWithSourcesChain.from_chain_type(llm=llm, chain_type="stuff", retriever=vectorstore.as_retriever())
# --- Domande e Risposte ---
query = "What was discovered at the LHC in 2012?"
answer = chain.run(query)
print("Parametric (w/ Retrieval): ", answer["answer"])
query = "Where is the LHC located?"
docs = vectorstore.similarity_search(query)
print("Non-Parametric: ", docs[0].page_content)
Output:
Parametric (w/ Retrieval): The Higgs boson, a particle that gives mass to other particles, was discovered at the LHC in 2012.
Non-Parametric: The LHC is located at CERN, near Geneva, Switzerland.
Ecco cosa succede in questo codice:
Memoria Parametrica:
- Utilizza il vasto know-how dell’LLM per generare una risposta completa, comprendendo anche il fatto cruciale che il bosone di Higgs dà massa ad altri particelle. L’LLM è “parametrizzato” da una sua ampia formazione dati.
Memoria Non-Parametrica:
- Esegue una ricerca di similitudine nello spazio vettoriale, trovando il documento più rilevante che risponde direttamente alla domanda sull’ubicazione del LHC. Non si sintetizza nuova informazione, semplicemente recupera il fatto rilevante.
Differenze Chiave:
| Feature | Parametric Memory | Non-Parametric Memory |
|---|---|---|
| Memorizzazione del Knowledge | Incodificato nei parametri del modello (pesi) come rappresentazioni imparate. | Memorizzato direttamente come testo grezzo o in altri formati (ad esempio, embeddings). |
| Recupero | Usa le capacità generative del modello per produrre testo rilevante alla richiesta in base al knowledge imparato. | Involucra la ricerca di documenti che corrispondono da vicino alla richiesta (ad esempio, tramite similitudine o corrispondenza keyword). |
| Flessibilità | Hai una elevata flessibilità e puoi generare risposte innovative, ma puoi anche allucinare (generare informazioni errate). | Meno flessibile, ma meno predisposto agli allucinazioni poiché si affida ai dati esistenti. |
| Stile Risposta | Può produrre risposte più elaborate e sottili, ma potenzialmente con più informazioni irrilevanti. | Fornisce risposte dirette e concise, ma potrebbe mancare di contesto o di sottolineatura. |
| Costo Computazionale | La generazione di risposte può essere computazionalmente intensiva, specialmente per modelli grandi. | Il recupero può essere più veloce, specialmente con algoritmi di indicizzazione e ricerca efficienti. |
Combinando le potenzialità di memorie parametriche e non-parametriche, RAG risolve i limiti delle modelli di linguaggio tradizionali e consente la generazione di output più accurate, aggiornati e contestualmente rilevanti. (Redis, Lewis et al., e Guu et al.)
2.3 RAG multimodale: integrazione del testo
Il RAG multimodale estende il paradigma tradizionale basato su testo del RAG incorporando molteplici modalità di dati, come immagini, audio e video, per migliorare le capacità di recupero e generazione di grandi modelli di linguaggio (LLM).
Utilizzando tecniche di apprendimento contrastivo, i sistemi RAG multimodali imparano a inserire i diversi tipi di dati in uno spazio vettoriale condiviso, consentendo una agevole ricerca cross-modal. Questo permette agli LLM di ragionare in un contesto più ricco, combinando informazioni testuali con evidenze visive e uditive per generare output più dettagliati e contestualmente rilevanti. (Shen et al.)
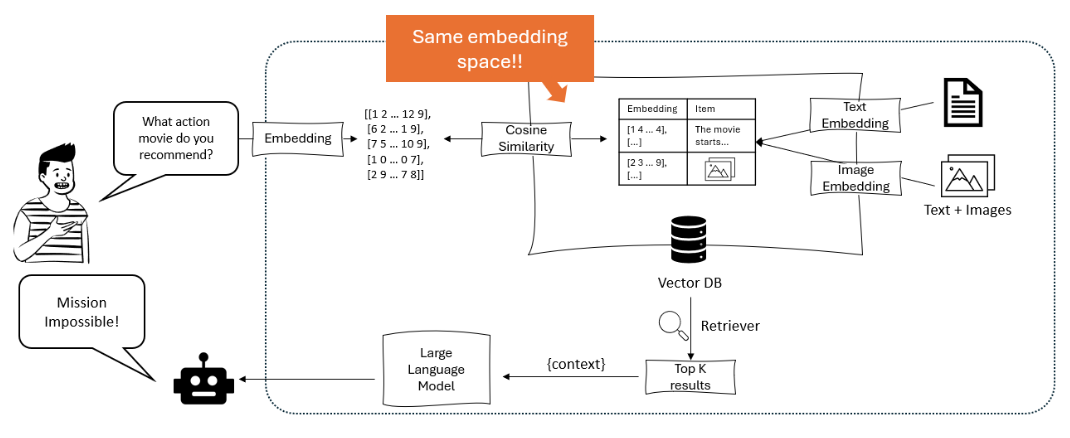
Il diagramma illustra un sistema di raccomandazione in cui un grande modello di linguaggio processa una richiesta utente in embedding, che vengono poi corrisposti utilizzando la similitudine di cosine in un database vettoriale contenente sia embedding testuali che immaginari, per recuperare e raccomandare gli elementi più rilevanti. – opendatascience.com
Un approcio chiave in RAG multimodale è l’uso di modelli basati su trasformatori come ViLBERT e LXMERT che utilizzano meccanismi di attenzione cross-modalità. Questi modelli possono attendere alle regioni rilevanti nelle immagini o ai segmenti specifici nell’audio/video mentre generano testo, catturando interazioni fine-grain tra modalità. Questo consente risposte piu ‘visualmente e contestualmente radicate. (Protecto.ai)
L’integrazione del testo con altre modalità in RAG pipeline comporta sfide come l’allineamento di rappresentazioni semantiche tra diversi tipi di dati e la gestione delle caratteristiche uniche di ogni modalità durante il processo di embedding. Vengono utilizzate tecniche come l’encodering modalità-specifico e l’attenzione cross per affrontare queste sfide. (Zhu et al.)
Ma i potenziali benefici di RAG multimodale sono significativi, inclusa un’accuratezza migliore, una maggiore controllabilità e interpretabilità del contenuto generato, nonché la capacità di supportare nuovi casi d’uso come la risposta a domande visuali e la creazione di contenuti multimodali.
Ad esempio, Li e al. (2020) hanno proposto un framework multimodale RAG per l’interpretazione delle domande visuali che recupera immagini e informazioni testuali relative per generare risposte accurate, superando le precedenti tecniche d’avanguardia sulle benchmark come VQA v2.0 e CLEVR. (MyScale)
Nonostante i risultati promettenti, il multimodale RAG introduce anche nuovi挑战, come l’aumentata complessità computazionale, la necessità di grandi dataset multimodali e il potenziale per il bias e il rumore nell’informazione recuperata.
I ricercatori stanno attivamente esplorando tecniche per mitigare questi problemi, come strutture di indicizzazione efficienti, strategie di data augmentation e metodi di addestramento adattivo. (Sohoni et al.)
Capitolo 3: Mechanismi Centrali di RAG
Questo capitolo esplora l’intricato interscambio tra ricercatori e modelli generativi in Sistemi RAG (Retrieval-Augmented Generation), sottolineando il loro ruolo cruciale nell’indicizzazione, ricerca e sintesi di informazioni per produrre risposte accurate e connesse al contesto.
Scaviamo nelle sottile differenza tra tecniche di ricerca sparse e dense, confrontando le loro forze e debolezze in diversi scenario. Inoltre, esaminiamo varie strategie per integrate informazioni recuperate nei modelli generativi, come la concatenazione e l’attenzione crociata, e discutiamo del loro impatto sull’efficacia complessiva di sistemi RAG.
Conoscendo queste strategie di integrazione, otterrete una valuosa visione d’insieme su come ottimizzare i sistemi RAG per specifici compiti e domini, facendo così strada ad un utilizzo più informato e efficace di questo potente paradigma.
3.1 Il potere della combinazione di Informazione di Recupero e Generazione in RAG
Retrieval-Augmented Generation (RAG) rappresenta un potente paradigma che integra in modo fluido l’information retrieval con i modelli di linguaggio generativi. RAG è composto da due componenti principali, come potete capire dalla sua denominazione: Recupero e Generazione.
La componente di recupero è responsabile dell’indicizzazione e della ricerca in un ampio deposito di conoscenza, mentre la componente di generazione sfrutta le informazioni recuperate per produrre risposte contestualmente appropriate e accurate dal punto di vista delle fatti. (Redis e Lewis et al.)
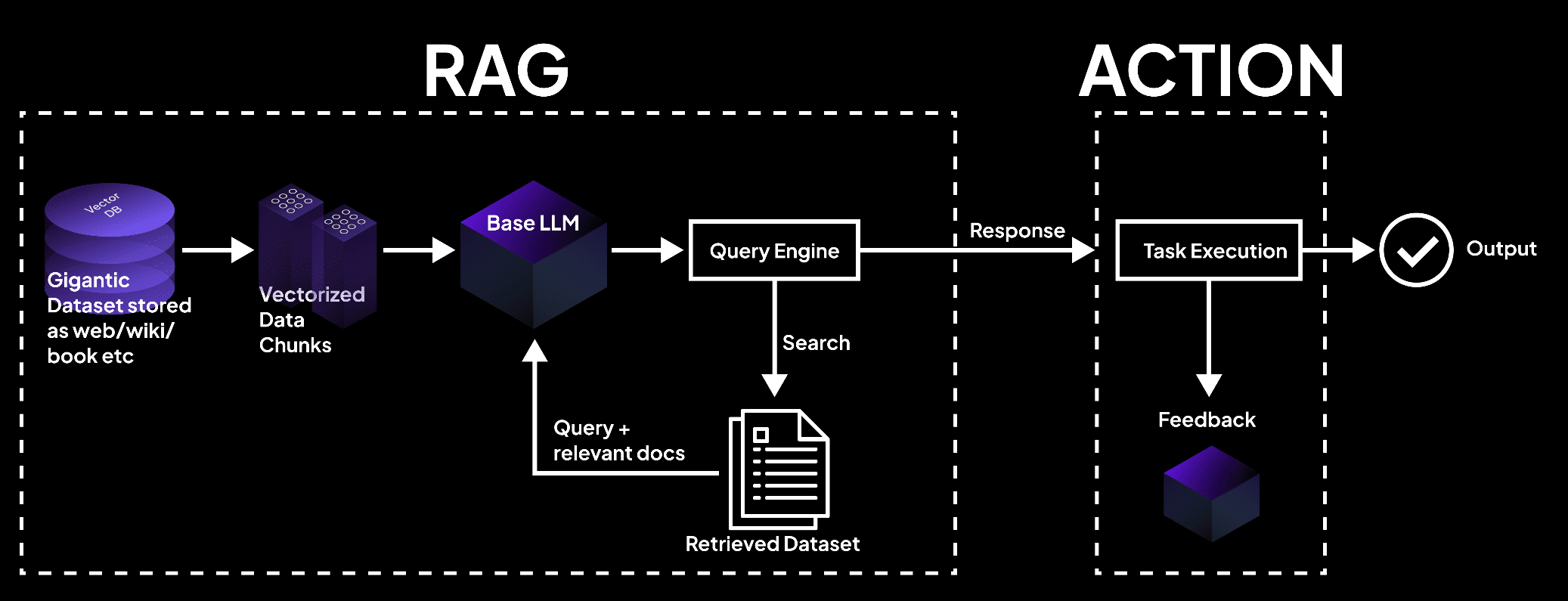
L’immagine mostra un sistema RAG in cui un database vettoriale processa i dati in blocchi, interrogato da un modello di linguaggio per recuperare documenti per l’esecuzione del compito e per ottenere output precisi. – superagi.com
Il processo di recupero inizia con l’indicizzazione di fonti di conoscenza esterne, come database, documenti e pagine web. (Redis e Lewis e al.) I recuperatori e gli indiciatori giocano un ruolo cruciale in questo processo, organizzando e memorizzando l’informazione in un formato che consente una ricerca e un recupero rapidi.
Quando una richiesta viene fatta al sistema RAG, il recuperatore cerca nella base di conoscenza indicizzata per identificare le informazioni più relevanti in base alla similitudine semantica e ad altre metriche di rilevanza.
Una volta che le informazioni relative sono state recuperate, il componente di generazione entra in gioco. Il contenuto recuperato viene utilizzato per promptare e guidare il modello di linguaggio generativo, fornendogli il necessario contesto e le basi fattuali per generare risposte accurate e informative.
Il modello di linguaggio utilizza tecniche avanzate di inferenza, come meccanismi di attenzione e architetture di trasformazione, per sintetizzare le informazioni recuperate con il suo conoscenza preesistente e generare testo coerente e fluente.
Il flusso di informazione all’interno di un sistema RAG può essere illustrato come segue:
graph LR
A[Query] --> B[Retriever]
B --> C[Indexed Knowledge Base]
C --> D[Relevant Information]
D --> E[Generator]
E --> F[Response]
I vantaggi del RAG sono molteplici:
Questa fusione di capacità di recupero e generazione consente la creazione di risposte che non solo sono appropriate in contesto, ma sono anche informate dalla più aggiornata e precisa informazione informazione disponibile. (Guu et al.)
Attraverso l’utilizzo di fonti di conoscenza esterne, RAG riduce significativamente l’incidenza di allucinazioni o di output non corretti in termini di fatti, che sono comuni tra i modelli generativi puri.
Inoltre, RAG consente l’integrazione di informazioni aggiornate, garantendo che le risposte generate riflettano le più recenti conoscenze e sviluppi in un determinato campo. Questo è particolarmente cruciale nei settori come la sanità, le finanze e la ricerca scientifica, nei quali l’accuratezza e la tempestività dell’informazione sono fondamentali. (Guu et al. e NVIDIA)
RAG dimostra anche una straordinaria adattabilità, consentendo ai modelli di linguaggio di svolgere una vasta gamma di attività con un miglioramento della performance. Attraverso il recupero dinamico di informazioni relative in base alla specifica richiesta o al contesto, RAG dà al modello la capacità di generare risposte personalizzate alle esigenze uniche di ogni compito, sia esso la risposta a domande, la generazione di contenuti o l’applicazione specifica del settore.
Numerosi studi hanno dimostrato l’efficacia di RAG nel migliorare l’accuratezza fattuale, la relevanza e l’adattabilità dei modelli di linguaggio generativi.
Ad esempio, Lewis et al. (2020) hanno dimostrato che RAG supera i modelli generativi puri in una serie di compiti di risposta a domande, raggiungendo risultati all’avanguardia su benchmark come Natural Questions e TriviaQA. (Lewis et al.)
Allo stesso modo, Izacard e Grave (2021) hanno dimostrato l’eccellenza di RAG rispetto ai classici modelli linguistici nell’generazione di testi lunghi coerenti e fattualmente consistenti.
La Generazione Augmentata tramite Riconciliazione rappresenta un approcio rivoluzionario alla generazione del linguaggio, sfruttando il potere dell’riconciliazione informatica per migliorare l’accuratezza, la rilevanza e l’adattabilità dei modelli generativi.
Integrando in maniera fluida l’informazione esterna con le capacità linguistiche preesistenti, RAG apre nuove possibilità per la processazione del linguaggio naturale e prepara la strada per sistemi di generazione del linguaggio più intelligenti e affidabili.
3.2 Strategie di integrazione Retriever-Generatore
I sistemi RAG sono basati su due componenti chiave: i retriever e i modelli generativi. I retriever sono responsabili di cercare e recuperare in maniera efficiente informazioni relative da basi di conoscenza a grandezza ridotta.
“Comprende due fasi principali, l’indicizzazione e la ricerca. L’indicizzazione organizza i documenti per consentire un efficiente recupero, utilizzando either inverted indexes per il recupero sparso o l’encoding di vectori densi per il recupero denso.” (Redis)
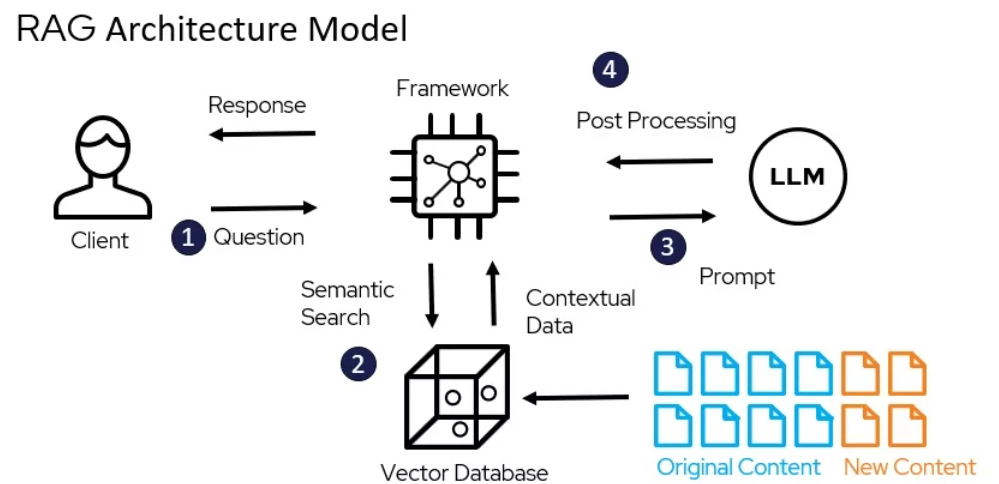
Modello di architettura di RAG – miro.medium.com
Le tecniche di ricerca sparsa, come TF-IDF e BM25, rappresentano i documenti come vettori sparsi ad alta dimensione, dove ogni dimensione corrisponde a un termine unico del vocabolario. La rilevanza di un documento rispetto a una query è determinata dalla sovrapposizione di termini, pesati secondo la loro importanza.
Ad esempio, utilizzando la popolare libreria Elasticsearch, un ricercatore basato su TF-IDF può essere implementato così:
from elasticsearch import Elasticsearch
es = Elasticsearch()
es.index(index="documents", doc_type="_doc", body={"text": "This is a sample document."})
query = "sample"
results = es.search(index="documents", body={"query": {"match": {"text": query}}})
Le tecniche di ricerca densa, come la ricerca di passaggi densi (DPR) e i modelli basati su BERT, rappresentano documenti e query come vettori densi in uno spazio di embedding continuo. La rilevanza è determinata dalla similarità coseno tra i vettori query e documento.
DPR può essere implementato utilizzando la libreria Hugging Face Transformers:
from transformers import DPRContextEncoder, DPRQuestionEncoder
context_encoder = DPRContextEncoder.from_pretrained("facebook/dpr-ctx_encoder-single-nq-base")
question_encoder = DPRQuestionEncoder.from_pretrained("facebook/dpr-question_encoder-single-nq-base")
context_embeddings = context_encoder(documents)
query_embedding = question_encoder(query)
scores = torch.matmul(query_embedding, context_embeddings.transpose(0, 1))
I modelli generativi, come GPT e T5, vengono utilizzati in RAG per generare risposte coerenti e rilevanti in base alle informazioni retrieve. L’addestramento di questi modelli su dati specifici del dominio e l’impiego di tecniche di ingegneria del prompt possono migliorare显著mente il loro rendimento nei sistemi RAG. (Community DEV)
Le strategie di integrazione determinano come il contenuto recuperato è integrato nei modelli generativi.
Il componente generatore utilizza il contenuto recuperato per formulare risposte coerenti e rilevanti contestualmente con le fasi di promossione e inferenza. (Redis)
Due approcchi comuni sono la concatenazione e l’attenzione crociata.
La concatenazione prevede l’aggiunta delle sezioni recuperate all’input query, permettendo al modello generativo di attendere alle informazioni relative durante il processo di decodifica.
Mentre questo approcchio è semplice da implementare, può avere difficoltà con sequenze lunghe e informazioni irrilevanti. (Community DEV) I meccanismi di attenzione crociata, come RAG-Token e RAG-Sequence, consentono al modello generativo di selezionare in modo selectivo le sezioni recuperate in ogni passo di decodifica.
Questo consente un controllo più granulare sul processo di integrazione, ma comporta una complessità computazionale maggiore.
Per esempio, RAG-Token può essere implementato utilizzando la libreria Hugging Face Transformers:
from transformers import RagTokenizer, RagRetriever, RagSequenceForGeneration
tokenizer = RagTokenizer.from_pretrained("facebook/rag-token-nq")
retriever = RagRetriever.from_pretrained("facebook/rag-token-nq", index_name="exact", use_dummy_dataset=True)
model = RagSequenceForGeneration.from_pretrained("facebook/rag-token-nq")
input_ids = tokenizer(query, return_tensors="pt").input_ids
retrieved_docs = retriever(input_ids)
generated_output = model.generate(input_ids, retrieved_docs=retrieved_docs)
La scelta del retriever, del modello generativo e della strategia di integrazione dipende dai requisiti specifici del sistema RAG, come la dimensione e la natura della base di conoscenza, il bilanciamento desiderato tra efficienza e efficacia e il dominio di applicazione target.
Capitolo 4: Applicazioni e casi d’uso.
Questo capitolo esplora il potenziale trasformativo dell’Generazione Augmentata dalla Retrieval (RAG) nella rivoluzione delle applicazioni di linguaggi a risorse scarse e plurilingui. Ci immergiamo in strategie come la traduzione dei documenti di origine in linguaggi con risorse abbondanti, l’utilizzo di embedded multilingui e l’applicazione dell’apprendimento federato per superare i limiti dati e le differenze linguistiche.
Inoltre, affrontiamo il difficile problema di mitigare le allucinazioni nei sistemi RAG plurilingui per assicurare la generazione di contenuti accurate e affidabili. Esplorando queste approcchi innovativi, questo capitolo offre un guida completa per sfruttare il potere di RAG per la inclusività e la diversità nei processi linguistici.
4.1 Applicazioni RAG: da QA alla scrittura creativa
L’Generazione Augmentata dalla Retrieval (RAG) ha trovato numerose applicazioni pratiche in diversi domini, dimostrando il suo potenziale per rivoluzionare il modo in cui interagiamo e generiamo informazioni. Utilizzando il potere della retrieval e della generazione, i sistemi RAG hanno mostrato miglioramenti significativi in termini di accuratezza, rilevanza e coinvolgimento utente.
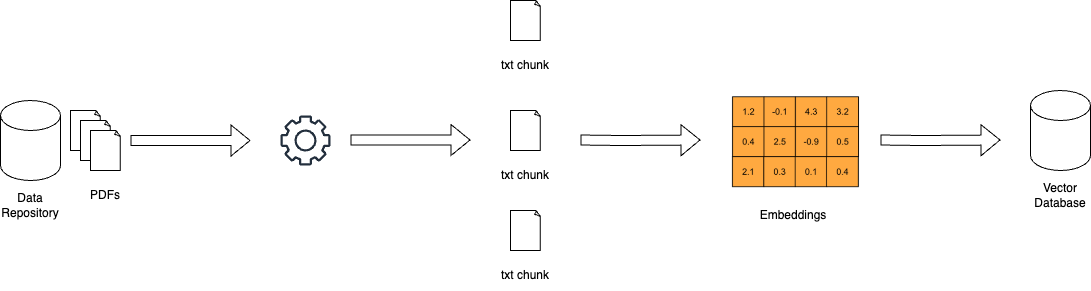
Come funziona RAG – miro.medium.com
Domande e Risposte
RAG ha dimostrato di essere un cambiamento di gioco nel campo delle risposte ad interrogazioni. Recuperando informazioni relevanti the external knowledge sources e integrandole nel processo di generazione, i sistemi RAG possono fornire risposte più accurate e connesse al contesto alle query utente. (LangChain e Django Stars)
Per esempio, Izacard e Grave (2021) hanno proposto un modello a base di RAG chiamato Fusion-in-Decoder (FiD), che ha ottenuto il miglior risultato sulle piattaforme di valutazione delle risposte ad interrogazioni, inclusi Natural Questions e TriviaQA. (Izacard and Grave)
FiD sfrutta un retriever denso per recuperare passaggi rilevanti e un modello generativo per sintetizzare le informazioni recuperate in una risposta coerente, superando i modelli generativi puri con un margine significativo. (Izacard and Grave)
Sistemi di dialogo
RAG è stato anche utilizzato per creare agenti conversazionali più coinvolgenti e informativi. Incorporando conoscenza esterna attraverso il recupero, i sistemi di dialogo basati su RAG possono generare risposte che non solo sono appropriate contestualmente ma anche basate su fatti. (LlamaIndex e MyScale)
Shuster e altri (2021) hanno introdotto un sistema di dialogo basato su RAG chiamato BlenderBot 2.0, che ha dimostrato capacità conversazionali migliorate rispetto al suo predecessore. (Shuster e altri.)
BlenderBot 2.0 recupera informazioni relative da una variegata gamma di fonti di conoscenza, incluso Wikipedia, articoli di giornale e social media, consentendogli di impegnarsi in conversazioni più informate e coerenti su un ampio range di argomenti. (Shuster e altri.)
Riepilogo
RAG ha dimostrato promessa nell’aumentare la qualità delle riepilogazioni generate integrando informazioni relative da fonti multiple. (Hyperight) Pasunuru e altri (2021) hanno proposto un modello di riepilogo basato su RAG chiamato PEGASUS-X, che recupera e integra passaggi relativi da documenti esterni per generare riepilogazioni più informative e coerenti.
PEGASUS-X ha superato i modelli generativi puri in diversi benchmark di sintesi, dimostrando l’efficacia del recupero nell’aumentare l’accuratezza fattuale e la relevanza delle schede generate.
Scrittura creativa
Il potenziale di RAG va oltre i domini fattuali e raggiunge il campo della scrittura creativa. Recuperando passaggi relevanti da un corpus eterogeneo di opere letterarie, i sistemi RAG possono generare storie o articoli nuovi e coinvolgenti.
Rashkin et al. (2020) hanno introdotto un modello di scrittura creativa basato su RAG chiamato CTRL-RAG, che recupera passaggi relevanti da un ampio dataset di opere di fantasia e li integra nel processo di generazione. CTRL-RAG ha dimostrato la capacità di generare storie coerenti e stilisticamente coerenti, mostrando il potenziale di RAG nelle applicazioni creative.
Casi Studio
Several research papers and projects have demonstrated the effectiveness of RAG in various domains.
Per esempio, Lewis et al. (2020) introduced the RAG framework and applied it to open-domain question answering, achieving state-of-the-art performance on the Natural Questions benchmark. (Lewis et al.) They highlighted the challenges of efficient retrieval and the importance of fine-tuning the generative model on retrieved passages.
In un altro caso studio, Petroni e altri (2021) hanno applicato RAG alla task di verifica delle informazioni, dimostrando la sua capacità di recuperare evidenze pertinenti e generare verdetti accurate. Hanno mostrato il potenziale di RAG nel contrastare le informazioni errate e migliorare le capacità di sistemi informativi.
L’impatto di RAG sia sull’esperienza utente che sui metriche aziendali è stato significativo. Fornendo risposte più accurate e informative, i sistemi basati su RAG hanno migliorato la soddisfazione utente e l’engagement. (LlamaIndex e MyScale)
Nel caso degli agenti conversazionali, RAG ha permesso interazioni più naturali e coerenti, portando ad un aumento della retention utente e della fedeltà. (LlamaIndex e MyScale) Nel campo della creatività scrittrice, RAG ha il potenziale per streamline i processi di creazione contenuti e generare idee nuove, risparmiando tempo e risorse per le aziende.
Quindi come potete vedere, le applicazioni pratiche di RAG attraversano una vasta gamma di domini, dalla risposta alle domande e dai sistemi di dialogo alla sintesi e alla creatività scrittrice. Sfruttando il potere del recupero e della generazione, RAG ha dimostrato miglioramenti significativi in accuratezza, rilevanza e engagement utente.
Come il campo evolve continuamente, ci si può aspettare di vedere più applicazioni innovative di RAG, trasformando il modo in cui interagiamo con e generiamo informazioni in diversi contesti.
4.2 RAG per le lingue a risorse limitate e i contesti plurilingui
Utilizzare il potere di Retrieval-Augmented Generation (RAG) per le lingue a risorse limitate e i contesti plurilingui non è solo un’opportunità, ma una necessità. Con oltre 7000 lingue parlate in tutto il mondo, molte delle quali mancano di risorse digitali significative, il problema è chiaro: come garantiamo che queste lingue non vengano lasciate indietro nell’era digitale?
La traduzione come ponte
Una strategia efficace è tradurre i documenti di origine in una lingua con maggiori risorse prima dell’indicizzazione. Questo approcio sfrutta i corpi correnti ampiamente disponibili in lingue come l’inglese, migliorando显著mente l’accuratezza e la rilevanza della ricerca.
Traducendo i documenti in inglese, è possibile sfruttare le vastissime risorse e le tecniche avanzate di ricerca già sviluppate per le lingue a risorse elevate, così come migliorare il rendimento dei sistemi RAG nei contesti a risorse limitate.
Embedding plurilingui
I recenti progressi nelle word embeddings plurilingui offrono un’altra soluzione promettente. Creando spazi di embedding condivisi per più lingue, è possibile migliorare il comportamento cross-linguale anche per lingue a risorse molto limitate.
La ricerca ha dimostrato che l’integrazione di lingue intermedie con embeddings di alta qualità può attraversare il gap tra i coppie di lingue distanti, migliorando complessivamente la qualità degli embedding plurilingui.
Questo metodo non solo migliora l’accuratezza di recupero ma anche garantisce che il contenuto generato sia contestualmente rilevante e linguisticamente coerente.
Apprendimento federato
L’apprendimento federato presenta un approcio innovativo per superare i limiti delle condivisioni dati e le differenze linguistiche. Tramite l’adattamento modelli su fonti dati decentralizzate, è possibile preservare la privacy utente mentre aumenta il rendimento del modello su molteplici lingue.
Questo metodo ha dimostrato un accuracy di 6,9% in più e una riduzione del 99% nei parametri di training rispetto ai metodi tradizionali, rendendolo una soluzione efficiente e efficace per i sistemi RAG multilingue.
Attenuare le allucinazioni
Un critico dei cambiamenti nell’implementazione di sistemi RAG in ambienti multilingui è l’attenuazione delle allucinazioni – istanze in cui il modello genera informazioni factualmente errate o irrilevanti.
Tecniche RAG avanzate come Modular RAG introdicono nuovi moduli e strategie di adattamento per affrontare questo problema. Tramite l’aggiornamento continuo della base di conoscenza e l’utilizzo di metriche di valutazione rigorose, è possibile ridurre significativamente l’incidenza di allucinazioni e garantire che il contenuto generato sia sia preciso che affidabile.
Implementazione pratica
Per implementare queste strategie in modo efficiente, considerare i seguenti passi pratici:
- Utilizzare la traduzione: Tradurre i documenti di lingue a risorse basse in una lingua a risorse alte come l’inglese prima dell’indicizzazione.
- Utilizzare Embededdi Multilingue: Incorporare lingue intermedie con embededdi di alta qualità per migliorare il rendimento cross-linguaggio.
- Adottare L’apprendimento Federato: Rilevare i modelli su fonti dati decentralizzate per migliorare il rendimento preservando la privacy.
- Mitigare le Allucinazioni: Utilizzare tecniche avanzate di RAG e aggiornamenti continui del database delle conoscenze per assicurare l’accuratezza fattuale.
Adottando queste strategie, è possibile significativamente migliorare il rendimento dei sistemi RAG in ambienti a bassi risorse e multilingue, garantendo che nessuna lingua sia lasciata indietro nella rivoluzione digitale.
Capitolo 5: Tecniche di Ottimizzazione
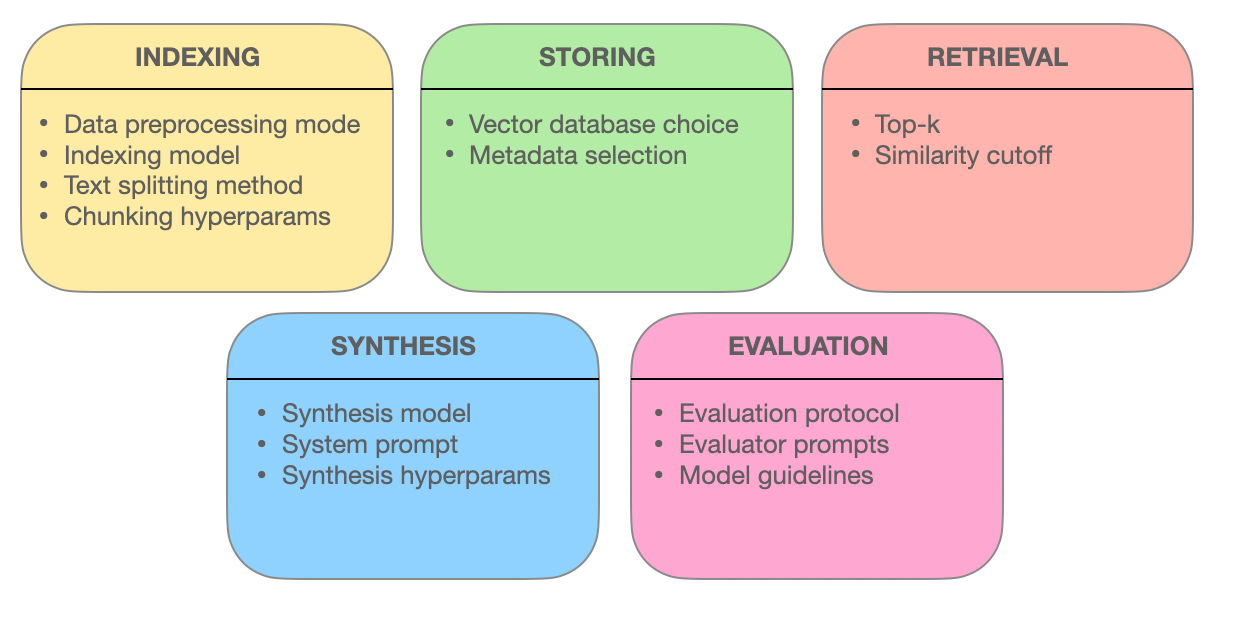
In questo capitolo si approfondisce nelle tecniche avanzate di ricerca che sostengono l’efficacia dei sistemi RAG (Retrieval-Augmented Generation). Esploriamo come l’ottimizzazione delle porzioni, l’integrazione dei metadati, l’indicizzazione basata su grafi, le tecniche di allineamento, la ricerca ibrida e il re-ordinamento incrementano l’accuratezza, la relevanza e la completezza dell’integrazione dell’informazione.
Comprendendo queste metodologie all’avanguardia, otterrete intuizioni su come i sistemi RAG stanno evolvendo da semplici motori di ricerca a intelligenti fornitori di informazioni in grado di capire domande complesse e fornire risposte precise e pertinenti in contesto.
5.1 Tecniche Avanzate di Ricerca per Ottimizzare i Sistemi RAG
I sistemi RAG (Retrieval Augmented Generation) stanno rivoluzionando il modo in cui accediamo e utilizziamo l’informazione. Il cuore di questi sistemi risiede nella loro abilità di recuperare informazioni relative efficientemente.
Indagiamo più a fondo nelle tecniche avanzate di recupero che consentono ai sistemi RAG di fornire risposte accurate, pertinenti nel contesto e completi.
Ottimizzazione dei Chunk: massimizzare la rilevanza tramite il recupero granulare
Nel mondo dei sistemi RAG, i documenti di grandi dimensioni può essere inquietante. L’ottimizzazione dei chunk si rivolge a questo problema dividendo i testi estesi in unità più piccole e gestibili chiamate chunk. questa granularità consente ai sistemi di recupero di identificare precise sezioni di testo che corrispondono ai termini della query, migliorando l’accuratezza e l’efficienza.
L’arte dell’ottimizzazione dei chunk consiste nel determinare l’ dimensione ideale dei chunk e l’overlap. Un chunk troppo piccolo può mancare di contesto, mentre un chunk troppo grande può diluire la rilevanza. Il chunk dinamico, una tecnica che adatta la dimensione dei chunk in base alla struttura e alla semantica del contenuto, assicura che ogni chunk sia coerente e significativo contestualmente.
Integrazione dei Metadati: sfruttare il potere delle etichette informative
I metadati, le informazioni di accompagnamento spesso trascurate che accompagnano i documenti, possono essere una miniera d’oro per i sistemi di recupero. Integrazione dei metadati come il tipo di documento, l’autore, la data di pubblicazione e le etichette di argomento, i sistemi RAG possono eseguire ricerche più mirate.
Il recupero della query stessa, una tecnica consentita dalla integrazione dei metadati, consente al sistema di generare query aggiuntive basate sui risultati iniziali. Questo processo iterativo raffina la ricerca, garantendo che i documenti recuperati non solo corrispondono alla query ma anche soddisfino specifiche richieste e necessità contestuali dell’utente.
Strutture di Indicizzazione Avanzate: reti basate su grafi per query complesse
Metodi di indicizzazione tradizionali, come gli indici inverso e le codifiche vettoriali dense, presentano limitazioni quando si devono affrontare query complesse che coinvolgono multipli entità e le loro relazioni. Gli indici basati su grafi offrono una soluzione organizzando i documenti e le loro connessioni in una struttura grafica.
Quest’organizzazione grafica consente un’esplorazione e un recupero efficienti di documenti relazionati, anche in scenario intricati. L’indicizzazione gerarchica e la ricerca di vicini più vicini approssimativa ulteriormente migliorano la scalabilità e la velocità dei sistemi di recupero basati su grafi.
Tecniche di allineamento: Garantire accuratezza e ridurre allucinazioni
La credibilità dei sistemi RAG dipende dalla loro capacità di fornire informazioni accurate. Le tecniche di allineamento, come l’addestramento counterfactual, affrontano questo problema. Esibendo il modello in situazioni ipotetiche, l’addestramento counterfactual insegna al modello a distinguere tra fatti del mondo reale e informazioni generate, riducendo così le allucinazioni.
Nei sistemi RAG multimodali, che integrano informazioni da fonti diverse, come testo e immagini, l’apprendimento contrastivo gioca un ruolo cruciale. Questa tecnica allinea le rappresentazioni semantiche di diversi modi di dati, garantendo che le informazioni recuperate siano coerenti e integrate in contesto.
Ricerca ibrida: Sintesi della precisione delle parole chiave con l’apprendimento semantico
La ricerca ibrida combina il meglio di due mondi: la velocità e la precisione della ricerca basata su parole chiave con l’apprendimento semantico della ricerca vettoriale. Inizialmente, una ricerca basata su parole chiave rapidamente riduce il numero di documenti potenziali.
Successivamente, una ricerca basata su vettori refina i risultati in base alla similitudine semantica. Questo approcio è particolarmente efficace quando le corrispondenze perfette tra parole chiave sono essenziali, ma è anche necessario una comprensione approfondita dell’intenzione della richiesta per una ricerca accuratezza.
Riordino: Rifinire la Relevance per l’Ottimale Risposta
Nella fase finale del recupero, il riordino entra in gioco per affinare i risultati. Modelli di apprendimento automatico, come i cross-encoder, revalutano le score di relevanza dei documenti recuperati. Processando insieme la richiesta e i documenti, questi modelli ottengono una comprensione approfondita delle loro relazioni.
Questa comparazione sottile garantisce che i documenti in cima alla classifica siano veramente allineati con la richiesta dell’utente e il contesto, fornendo una esperienza di ricerca più soddisfacente e informativa.
La forza dei sistemi RAG sta nel loro capacità di recuperare e presentare informazioni in modo fluido. Impiegando queste tecniche avanzate di recupero – ottimizzazione dei pezzi, integrazione dei metadati, indicizzazione basata su grafi, tecniche di allineamento, ricerca ibrida e riordino – i sistemi RAG diventano più di semplici motori di ricerca. Evolvono in fornitori intelligenti di informazioni, capaci di comprendere richieste complesse, discernere le sottili differenze e fornire risposte precise, rilevanti e fidatevoli.
Capitolo 6: Sfide e Innovazioni
Questo capitolo si immerge nei sfide critici e nelle direzioni future nell’sviluppo e nel deployment di sistemi Retrieval-Augmented Generation (RAG).
Esploriamo le complessità dell’evaluazione dei sistemi RAG, inclusa la necessità di metriche complete e schemi adattivi per accurate valutazioni del loro rendimento.si occupa anche di considerazioni etiche come la mitigazione del bias e la correttezza nell’informazione di ricerca e generazione.
Inoltre, esamina l’importanza dell’accelerazione hardware e delle strategie di distribuzione efficienti, sottolineando l’utilizzo di hardware specializzato e tool di ottimizzazione come Optimum per migliorare il rendimento e la scalabilità.
Conoscendo questi challenge e sperimentando possibili soluzioni, questo capitolo fornisce una guida completa per l’ulteriore sviluppo e l’implementazione responsabile della tecnologia RAG.
6.1 Sfide e Direzioni未来的
I sistemi RAG hanno dimostrato un potenziale eccezionale nell’aumentare l’accuratezza, la rilevanza e la coerenza del testo generato. Ma lo sviluppo e l’implementazione di sistemi RAG presentano anche sfide significative che devono essere affrontate per realizzare appieno il loro potenziale.
“L’evaluazione dei sistemi RAG implica quindi la considerazione di molti componenti specifici e la complessità dell’intera valutazione del sistema.” (Salemi et al.)
Sfide nell’Evaluzione dei Sistemi RAG
Uno dei principali挑战 tecnici in RAG è garantire un efficiente recupero di informazioni relevanti da basi di conoscenza a grande scala. (Salemi et al. e Yu et al.)
Come la dimensione e la diversità delle fonti di conoscenza continuano a crescere, lo sviluppo di meccanismi di recupero scalabili e robusti diventa sempre più critico. Tecniche come l’indicizzazione gerarchica, la ricerca di vicini più vicini approssimativi e le strategie di recupero adattive devono essere esplorate per ottimizzare il processo di recupero.
Alcuni elementi coinvolti in un sistema RAG – miro.medium.com
Un altro significativo challenge è mitigare il problema dell’allucinazione, in cui il modello generativo produce informazioni factualmente errate o incoerenti.
Per esempio, un sistema RAG potrebbe generare un evento storico che non è mai avvenuto o attribuire male una scoperta scientifica. Mentre la recupero aiuta a fissare il testo generato nella conoscenza factuale, garantire la fedeltà e la coerenza dell’output generato rimane un problema complesso.
Ad esempio, un sistema RAG può recuperare informazioni accurate riguardo una scoperta scientifica da una fonte affidabile come Wikipedia, ma il modello generativo potrebbe ancora allucinare combinando queste informazioni in modo sbagliato o aggiungendo dettagli inesistenti.
Lo sviluppo di meccanismi efficaci per la rilevazione e la prevenzione delle allucinazioni è un settore di ricerca attivo. Tecniche quali la verifica delle informazioni utilizzando database esterni e la verifica della coerenza attraverso la cross-referenza di fonti multiple sono state esplorate. Questi metodi intendono garantire che il contenuto generato rimanga preciso e affidabile, nonostante i difficili problemi nella misura in cui si allineano i processi di recupero e generazione.
L’integrazione di fonti di conoscenza diverse, come database strutturati, testi non strutturati e dati multimodali, presenta sfide aggiuntive nei sistemi RAG. (Yu et al. e Zilliz) L’allineamento delle rappresentazioni e della semantica tra differenti modalità di dati e formati di conoscenza richiede tecniche sofisticate, come l’attenzione cross-modal e l’impostazione dell’immagine del grafo delle conoscenze. Garantire la compatibilità e l’interoperabilità di varie fonti di conoscenza è cruciale per il funzionamento efficiente dei sistemi RAG. (Zilliz)
Oltre ai challenge tecnici, i sistemi RAG sollevano anche considerazioni etiche importanti. Garantire un accesso e la generazione dell’informazione imparziale e equi è una preoccupazione critica. I sistemi RAG potrebbero inavvertitamente amplificare i pregiudizi presenti nei dati di addestramento o nelle fonti di conoscenza, portando a risultati discriminativi o ingiustificati. (Salemi et al. e Banafa)
La ricerca sui metodi per rilevare e mitigare questi pregiudizi, come l’addestramento ad attacchi aggiuntivi e il recupero equo consapevole, è una direzione di ricerca importante. (Banafa)
Direzioni di ricerca future
Per affrontare i challenge nell’evaluzione dei sistemi RAG, possono essere esplorate diverse possibili soluzioni e direzioni di ricerca.
Lo sviluppo di metriche di valutazione approfondite che catturino l’interazione tra l’accuratezza del recupero e la qualità della generazione è cruciale. (Salemi et al.)
Le metriche che valutano la rilevanza, la coerenza e la correttezza fattuale del testo generato, considerando anche l’efficacia del componente di recupero, devono essere stabilite. (Salemi et al.) Ciò richiede un approcio olistico che va oltre le metriche tradizionali come BLEU e ROUGE e include valutazioni umane e misure specifiche per la task.
L’esplorazione di schemi di valutazione adattivi e in tempo reale è un’altra direzione promettente.
I sistemi RAG operano in ambienti dinamici nei quali le fonti di conoscenza e i requisiti dell’utente possono evolversi nel tempo. (Yu et al.) La creazione di schemi di valutazione in grado di adattarsi a questi cambiamenti e fornire feedback in tempo reale sulle prestazioni del sistema è essenziale per l’improvvisazione continua e il monitoraggio.
Potrebbe coinvolgere tecniche come l’apprendimento online, l’apprendimento attivo e l’apprendimento tramite reinforcement per aggiornare le metriche di valutazione e i modelli in base al feedback utente e al comportamento del sistema. (Yu et al.)
L’azione collaborativa tra ricercatori, praticanti dell’industria e esperti del settore è necessaria per avanzare nella valutazione delle GAR (Generalized Adversarial Relationships). L’adozione di benchmark standardizzati, dataset e protocolli di valutazione può facilitare la comparazione e la riproducibilità dei sistemi GAR in diversi domini e applicazioni. (Salemi et al. e Banafa)
L’interazione con i stakeholders, inclusi gli utenti finali e i policy maker, è cruciale per assicurarsi che lo sviluppo e la distribuzione dei sistemi GAR siano allineati con i valori sociali e i principi etici. (Banafa)
Pertanto, se i sistemi GAR hanno dimostrato un potenziale immenso, la soluzione ai challenge nella loro valutazione è cruciale per la loro adozione diffusa e la fiducia. Sviluppando metriche di valutazione completive, esplorando frameworks di valutazione adattivi e real-time e sostenendo sforzi collaborativi, possiamo preparare la strada per sistemi GAR più affidabili, imparziali e efficienti.
Con l’evoluzione della disciplina, è essenziale prioritizzare sforzi di ricerca che non solo avanzino le capacità tecniche delle GAR ma anche assicurino la loro distribuzione responsabile ed etica in applicazioni reali.
6.2 Accelerazione Hardware e Distribuzione Efficace di Sistemi GAR
L’utilizzo dell’accelerazione hardware è fondamentale per la distribuzione efficiente dei sistemi RAG (Retrieval-Augmented Generation). Offloadando le attività computazionalmente intensive su hardware specializzato, è possibile notevolmente migliorare le prestazioni e la scalabilità dei modelli RAG.
Sfruttare l’hardware specializzato
Le tool di ottimizzazione hardware specifiche di Optimum offrono vantaggi significativi. Per esempio, la distribuzione di sistemi RAG su processori Habana Gaudi può portare a una riduzione notevole della latenza di inferenza, mentre le ottimizzazioni di Intel Neural Compressor possono ulteriormente migliorare i parametri di latenza. Il hardware AWS Inferentia, ottimizzato attraverso Optimum Neuron, può aumentare le capacità di throughput, rendendo il tuo sistema RAG più reattivo e efficiente.
Ottimizzare l’utilizzo delle risorse
L’utilizzo efficiente delle risorse è fondamentale. Le ottimizzazioni di Optimum ONNX Runtime possono condurre all’uso più efficiente della memoria, mentre l’API BetterTransformer può migliorare l’utilizzo CPU e GPU. Queste ottimizzazioni garantiscono che il tuo sistema RAG operi alla massima efficienza, riducendo i costi operativi e migliorando le prestazioni.
Scalabilità e flessibilità
Optimum supporta una transizione fluida tra differenti acceleratori hardware, permettendo una scalabilità dinamica. Questo supporto multiplo per hardware consente di adattare i requisiti computazionali variando senza una riconfigurazione significativa. Inoltre, le funzionalità di quantizzazione e deflessione del modello in Optimum possono facilitare dimensioni del modello più efficienti, rendendo semplice e economicamente vantaggioso la distribuzione.
Casi studio e applicazioni reali
Pensare all’applicazione di Optimum nella ricerca informatica sanitaria. Utilizzando le ottimizzazioni hardware specifiche, i sistemi RAG sono in grado di gestire efficientemente dataset di grandi dimensioni, fornendo ricerche informatiche precise e tempestive. Ciò non solo migliora la qualità della assistenza sanitaria ma anche l’esperienza utente complessiva.
Step pratici per l’implementazione
- Seleziona Hardware Appropriato: Scegli acceleratori hardware come Habana Gaudi o AWS Inferentia in base alle specifiche richieste di prestazioni.
- Utilizza Strumenti di Ottimizzazione: Implementa gli strumenti di ottimizzazione di Optimum per migliorare la latenza, la throughput e l’utilizzo delle risorse.
- Assicurare la Scalabilità: Sfrutta il supporto multiplo per hardware per scalare dinamicamente il tuo sistema RAG in base alle necessità.
- Ottimizza la Dimensione del Modello: Usa la quantizzazione del modello e la pulizia per ridurre il carico computazionale ed agevolare l’impiego.
Integrando queste strategie, puoi significativamente migliorare le prestazioni, la scalabilità e l’efficienza dei tuoi sistemi RAG, garantendogli di essere ben equipaggiati per affrontare applicazioni complesse e reali.
Conclusione: Il Potenziale Trasformativo di RAG
Retrieval-Augmented Generation (RAG) rappresenta un paradigma trasformativo nella processazione del linguaggio naturale, integrando senza soluzione di continuità il potere della ricerca informatica con le capacità generative di grandi modelli di linguaggio.
Utilizzando fonti di conoscenza esterne, i sistemi RAG hanno dimostrato miglioramenti notevoli nella precisione, nella rilevanza e nella coerenza del testo generato in un vasto range di applicazioni, dalla risposta alle domande e dai sistemi di dialogo alla sintesi e alla scrittura creativa.
L’evoluzione dei modelli di linguaggio, dai primi sistemi basati su regole agli architetture neurali all’avanguardia come BERT e GPT-3, ha aperto la strada all’emergenza di RAG. I limiti della memoria puramente parametrica nei tradizionali modelli di linguaggio, come i limiti di datazione delle conoscenze e inconsistenze factuali, sono stati efficacemente risolti tramite l’integrazione della memoria non-parametrica attraverso i meccanismi di recupero.
I componenti principali dei sistemi RAG, ovvero i retriever e i modelli generativi, lavorano in sinergia per produrre output contestualmente rilevanti e basati su fatti.
I retriever, utilizzando tecniche come il retrivimento sparso e denso, efficacemente attraversano basi di conoscenza di vasta entità per identificare le informazioni più pertinenti. I modelli generativi, basati su architetture come GPT e T5, sinтеizzano il contenuto recuperato in testo coerente e fluente.
Le strategie di integrazione, come la concatenazione e l’attenzione crociata, determinano come l’informazione recuperata è incorporata nel processo di generazione.
Le applicazioni pratiche di RAG spaziano in diversi domini, mostrando il suo potenziale per rivoluzionare varie industrie.
Nel campo della risposta ad interrogazioni, RAG ha notevolmente migliorato l’accuratezza e la rilevanza delle risposte, permettendo un’estrazione di informazioni più informativa e affidabile. I sistemi di dialogo hanno tratto beneficio da RAG, portando a conversazioni più coinvolgenti e coerenti. Le attività di sintesi hanno ottenuto qualità e coerenza migliorate attraverso l’integrazione di informazioni relative da più fonti. Anche la scrittura creativa è stata esplorata, con i sistemi RAG che generano storie nuove e coerenti stilisticamente.
Ma lo sviluppo e l’valutazione di sistemi RAG presentano anche sfide significative. L’estrazione efficiente da basi di conoscenza a scala ridotta, la mitigazione dell’allucinazione e l’integrazione di diversi modalità di dati sono tra le barriere tecniche che devono essere superate. Le considerazioni etiche, come garantire un’estrazione e generazione di informazioni imparziali e equi, sono cruciali per il responsabile impiego di sistemi RAG.
Per realizzare appieno il potenziale di RAG, le futuri direzioni di ricerca devono concentrarsi sullo sviluppo di metriche di valutazione approfondite che catturino l’interazione tra accuratezza di estrazione e qualità generativa.
I framework di valutazione adattivi e in tempo reale capaci di gestire la natura dinamica di sistemi RAG sono essenziali per l’integrazione costante dell’improvedimento e il monitoraggio. Collaborazioni tra ricercatori, praticanti dell’industria e esperti di dominio sono necessarie per stabilire benchmark, dataset e protocolli di valutazione standardizzati.
Come il campo della RAG continua a evolversi, presenta un’enorme promessa per trasformare il modo in cui interagiamo e generiamo informazioni. Sfruttando il potere del recupero e della generazione, i sistemi RAG hanno il potenziale per rivoluzionare diversi domini, dall’integrazione informativa e dagli agenti conversazionali alla creazione del contenuto e alla scoperta del sapere.
La Generazione assistita dal Recupero rappresenta un punto nevralgico nel percorso verso una generazione della lingua più intelligente, precisa e contestualmente rilevante.
Connesso il divario tra la memoria parametrica e non parametrica, i sistemi RAG hanno aperto nuove possibilità per la processazione del linguaggio naturale e le sue applicazioni.
Con il progresso della ricerca e la risoluzione dei challenge, ci si può aspettare che la RAG assumesse un ruolo sempre più chiave nella formazione futura dell’interazione uomo-macchina e della generazione del sapere.
Riguardo l’Autore
Ecco Vahe Aslanyan, al centro dell’informatica, delle scienze dati e dell’IA. visitare vaheaslanyan.com per vedere un portafoglio che testimonia precisione e progresso. La mia esperienza collega il full-stack development e l’ottimizzazione del prodotto AI, guidata dalla risoluzione di problemi in modi nuovi.
Con un curriculum che comprende il lancio di un più importante bootcamp di scienze dati e il lavoro con i migliori specialisti dell’industria, il mio focus rimane sull’elevazione dell’educazione tecnica a standard universali.
Come puoi approfondire?
Dopo aver studiato questo guida, se sei interessato ad approfondire e il metodo strutturato è il tuo stile di apprendimento, considera di unirti a noi a LunarTech, offriamo corsi individuali e Bootcamp in Data Science, Machine Learning e AI.
Forniamo un programma completo che offre una comprensione approfondita della teoria, una pratica implementazione pratica, materiale di allenamento esteso e una preparazione personalizzata alle interviste per impostare il tuo successo a tuo passo.
Puoi controllare il nostro Ultimate Data Science Bootcamp e unirti al periodo di prova gratuito per provare i contenuti direttamente. Questo bootcamp è stato riconosciuto come uno dei Migliori Bootcamp di Data Science del 2023 ed è stato menzionato in pubblicazioni rispettabili come Forbes, Yahoo, Entrepreneur e altri. Questa è la tua occasione per far parte di una comunità che si nutre di innovazione e conoscenza. Ecco il messaggio di benvenuto!
Connettiti con me.

LunarTechNewsletter
- Seguimi su LinkedIn per un sacco di risorse gratuite in CS, ML e AI
- Visita il mio sito personale
- Iscriviti al mio The Data Science and AI Newsletter
Se vuoi imparare di più riguardo una carriera in Data Science, Machine Learning e AI, e come ottenere un lavoro di Data Science, puoi scaricare questo libero Guide alla Carriera in Data Science e AI.
Source:
https://www.freecodecamp.org/news/retrieval-augmented-generation-rag-handbook/