













Grafana Loki is een horizontaal schaalbaar, zeer beschikbaar logaggregatiesysteem. Het is ontworpen voor eenvoud en kostenefficiëntie. Gemaakt door Grafana Labs in 2018, is Loki snel opgekomen als een overtuigend alternatief voor traditionele logging systemen, met name voor cloud-native en Kubernetes omgevingen.
Loki kan een uitgebreide logreis bieden. We kunnen de juiste logstreams selecteren en vervolgens filteren om ons te concentreren op de relevante logs. Vervolgens kunnen we gestructureerde loggegevens analyseren en formatteren voor onze aangepaste analytische behoeften. Logs kunnen ook passend worden getransformeerd voor presentatie, bijvoorbeeld, of verdere verwerking in de pipeline.
Loki integreert naadloos met het bredere Grafana-ecosysteem. Gebruikers kunnen logs opvragen met behulp van LogQL – een querytaal die opzettelijk is ontworpen om op Prometheus PromQL te lijken. Dit biedt een vertrouwde ervaring voor gebruikers die al met Prometheus-metrics werken en maakt een krachtige correlatie mogelijk tussen metrics en logs binnen Grafana-dashboards.
Dit artikel begint met de basisprincipes van Loki, gevolgd door een basis architecturaal overzicht. Daarna volgen de basisbeginselen van LogQL, en we sluiten af met de afwegingen die daarbij komen kijken.
Loki Fundamentals
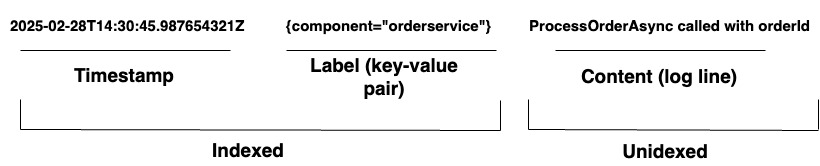
Voor organisaties die complexe systemen beheren, biedt Loki een geïntegreerde logging oplossing. Het ondersteunt het opnemen van logs vanuit elke bron via een breed scala aan agents of de API, wat zorgt voor een uitgebreide dekking van diverse hardware en software. Loki slaat zijn logs op als logstreams, zoals weergegeven in Diagram 1. Elk item heeft het volgende:
- Een tijdstempel met nanoseconde precisie
- Key-value paren genaamd labels worden gebruikt om logs te doorzoeken. Labels bieden de metadata voor de logregel. Ze worden gebruikt voor de identificatie en het ophalen van gegevens. Ze vormen de index voor de logstreams en structureren de logopslag. Elke unieke combinatie van labels en hun waarden definieert een afzonderlijke logstream. Logitems binnen een stream worden gegroepeerd, gecomprimeerd en opgeslagen in segmenten.
- De daadwerkelijke loginhoud. Dit is de ruwe logregel. Het is niet geïndexeerd en wordt opgeslagen in gecomprimeerde blokken.
Architectuur
We zullen de architectuur van Loki analyseren op basis van drie basisfuncties. Het lezen, schrijven en opslaan van logs. Loki kan werken in monolithische (enkele binair) of microservices modus, waarbij componenten zijn gescheiden voor onafhankelijke schaalbaarheid. Lees- en schrijffunctionaliteit kunnen onafhankelijk worden geschaald om specifieke use cases te ondersteunen. Laten we elk pad gedetailleerder bekijken.
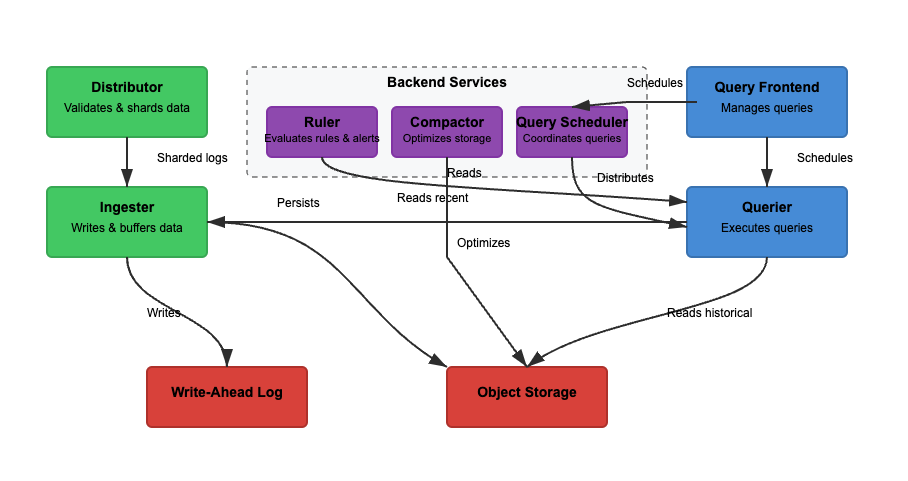
Schrijven
In Diagram 2 is het schrijfpad het groene pad. Wanneer logs Loki binnenkomen, verdeelt de distributeur logs op basis van labels. De ingester slaat vervolgens logs op in het geheugen en de compactor optimaliseert de opslag. De belangrijkste stappen zijn de volgende.
Stap 1: Logs komen Loki binnen
Writes voor de inkomende logs komen aan bij de distributeur. Logs zijn gestructureerd als streams, met labels (zoals {job="nginx", level="error"}). De distributeur verdeelt logs in shards, partitioneert logs en stuurt logs naar de ingesters. Het hash elke stream’s labels en wijst het toe aan een ingester met behulp van consistente hashing. Distributeurs valideren logs en voorkomen onjuiste gegevens. Consistente hashing kan een gelijkmatige logverdeling over ingesters garanderen.
Stap 2: Korte termijn opslag
De ingester slaat logs op in het geheugen voor snelle opvraging. Logs worden gebundeld en geschreven naar Write-Ahead Logs (WAL) om gegevensverlies te voorkomen. WAL helpt bij duurzaamheid maar is niet direct doorzoekbaar – ingesters moeten nog steeds online blijven voor het opvragen van recente logs.
Periodiek worden logs van ingesters naar objectopslag geflushed. De vragensteller en regel lezen de ingester om toegang te krijgen tot de meest recente gegevens. De vragensteller kan bovendien toegang krijgen tot de objectopslaggegevens.
Stap 3: Logs verplaatsen naar langetermijnopslag
De compactor verwerkt periodiek opgeslagen logs uit langetermijnopslag (object-storage). Objectopslag is goedkoop en schaalbaar. Het stelt Loki in staat om enorme hoeveelheden logs op te slaan zonder hoge kosten. De compactor verwijdert dubbele logs, comprimeert logs voor opslagefficiëntie en verwijdert oude logs op basis van retentie-instellingen. Logs worden opgeslagen in gechunkte indeling (niet volledig tekst-geïndexeerd).
Lezen
In Diagram 2 is het leespad het blauwe pad. Queries gaan naar de query-frontend en de querier haalt logs op. Logs worden gefilterd, geparsed en geanalyseerd met behulp van LogQL. De belangrijkste stappen zijn als volgt.
Stap 1: Query Frontend optimaliseert verzoeken
Gebruikers raadplegen logs met LogQL in Grafana. De query-frontend breekt grote queries op in kleinere stukken en verdeelt ze over meerdere queriers omdat parallelle uitvoering queries versnelt. Het is verantwoordelijk voor het versnellen van query-uitvoering en het zorgen voor herhalingen in geval van fouten. De query-frontend helpt time-outs en overbelasting te voorkomen, terwijl mislukte queries automatisch opnieuw worden geprobeerd.
Stap 2: Querier haalt logs op
Queriers parsen de LogQL en bevragen ingestors en objectopslag. Recentere logs worden opgehaald bij ingestors en oudere logs worden opgehaald uit de objectopslag. Logs met dezelfde tijdstempel, labels en inhoud worden gedupliceerd.
Bloomfilters en indexlabels worden gebruikt om logs efficiënt te vinden. Aggregatiequeries, zoals count_over_time(), worden sneller uitgevoerd omdat Loki logs niet volledig indexeert. In tegenstelling tot Elasticsearch indexeert Loki niet de volledige loginhoud.
In plaats daarvan indexeert het metagegevenslabels ({app="nginx", level="error"}), wat helpt bij het efficiënt en goedkoop vinden van logs. Er worden alleen volledige zoekopdrachten uitgevoerd op relevante logchunks, waardoor opslagkosten worden verlaagd.
LogQL-basics
LogQL is de querytaal die wordt gebruikt in Grafana Loki om logs efficiënt te doorzoeken, filteren en transformeren. Het bestaat uit twee primaire componenten:
- Streamselector – Selecteert logstreams op basis van labelmatchers
- Filteren en transformeren – Haalt relevante logregels eruit, analyseert gestructureerde gegevens en formatteert queryresultaten
Door deze functies te combineren, stelt LogQL gebruikers in staat om op efficiënte wijze logs op te halen, inzichten te extraheren en nuttige statistieken te genereren uit loggegevens.
Streamselector
Een streamselector is de eerste stap in elke LogQL-query. Het selecteert logstreams op basis van labelmatchers. Om queryresultaten te verfijnen naar specifieke logstreams, kunnen we basisoperators gebruiken om te filteren op Loki-labels. Door de precisie van onze logstreamselectie te verbeteren, wordt het aantal gescande streams geminimaliseerd, wat de querysnelheid verhoogt.
Voorbeelden
{app="nginx"} # Selects logs where app="nginx"
{env=~"prod|staging"} # Selects logs from prod or staging environments
{job!="backend"} # Excludes logs from the backend jobRegelfilters
Zodra logs zijn geselecteerd, verfijnen regelfilters resultaten door te zoeken naar specifieke tekst of logische voorwaarden toe te passen. Regelfilters werken op de loginhoud, niet op labels.
Voorbeelden
{app="nginx"} |= "error" # Select logs from nginx that contain "error"
{app="db"} != "timeout" # Exclude logs with "timeout"
{job="frontend"} |~ "5\d{2}" # Match HTTP 500-series errors (500-599)Parsers
Loki kan ongestructureerde, semi-gestructureerde of gestructureerde logs accepteren. Het is echter cruciaal om de logindelingen die we gebruiken te begrijpen bij het ontwerpen en bouwen van observatiemogelijkheden. Op deze manier kunnen we loggegevens effectief inlezen, opslaan en analyseren. Loki ondersteunt JSON, logfmt, patroon, regexp en uitpakparsers.
Voorbeelden
{app="payments"} | json # Extracts JSON fields
{app="auth"} | logfmt # Extracts key-value pairs
{app="nginx"} | regexp "(?P<status>\d{3})" # Extracts HTTP status codesLabelfilters
Na het parsen kunnen logs worden gefilterd op geëxtraheerde velden. Labels kunnen worden geëxtraheerd als onderdeel van de log-pijplijn met behulp van parser- en formatteringsuitdrukkingen. De labelfilteruitdrukking kan vervolgens worden gebruikt om onze logregel te filteren met een van deze labels.
Voorbeelden
{app="web"} | json | status="500" # Extract JSON, then filter by status=500
{app="db"} | logfmt | user="admin" # Extract key-value logs, filter by user=adminRegelindeling
Wordt gebruikt om loguitvoer te wijzigen door velden te extraheren en te formatteren. Dit bepaalt hoe logs worden weergegeven in Grafana.
Voorbeeld
{app="nginx"} | json | line_format "User {user} encountered {status} error"Labelindeling
Wordt gebruikt om labels te hernoemen, wijzigen, maken of verwijderen. Het accepteert een door komma’s gescheiden lijst van gelijkheidswerkingen, waardoor meerdere bewerkingen tegelijk kunnen worden uitgevoerd.
Voorbeelden
1. {app="nginx"} | label_format new_label=old_label. #If a log has {old_label="backend"}, it is renamed to {new_label="backend"}. The original old_label is removed.
2. {app="web"} | label_format status="HTTP {{.status}}" #If {status="500"}, it becomes {status="HTTP 500"}.
3. {app="db"} | label_format severity="critical". #Adds {severity="critical"} to all logs.
4. {app="api"} | drop log_level # Drops log_level Afwegingen
Grafana Loki biedt een kostenefficiënte, schaalbare loggingoplossing die logs opslaat in gecomprimeerde blokken met minimaal indexeren. Dit gaat gepaard met afwegingen in queryprestaties en ophaalsnelheid. In tegenstelling tot traditionele logbeheersystemen die de volledige loginhoud indexeren, versnelt Loki’s op labels gebaseerde indexering het filteren.
Echter kan het de complexiteit van tekstzoekopdrachten vertragen. Bovendien blinkt Loki uit in het omgaan met high-throughput, gedistribueerde omgevingen, maar het is afhankelijk van objectopslag voor schaalbaarheid. Dit kan latentie introduceren en vereist zorgvuldige labelselectie om hoge cardinaliteitsproblemen te voorkomen.
Schaalbaarheid en Multi-tenancy
Loki is ontworpen voor schaalbaarheid en multi-tenancy. Echter, schaalbaarheid gaat gepaard met architectonische compromissen. Het opschalen van schrijfoperaties (ingesters) is eenvoudig vanwege de mogelijkheid om logs te sharden op basis van labelgebaseerde partities. Het opschalen van leesoperaties (queriers) is lastiger omdat het opvragen van grote datasets uit objectopslag traag kan zijn. Multi-tenancy wordt ondersteund, maar het beheren van specifieke quotumlimieten per tenant, labeluitbreiding en beveiliging (per-tantalisolatie van gegevens) vereist zorgvuldige configuratie.
Eenvoudige Ingestie Zonder Voorverwerking
Loki vereist geen voorverwerking omdat het geen index maakt van volledige loginhoud. Het slaat logs op in ruwe indeling in gecomprimeerde brokken. Omdat Loki geen full-text indexering heeft, vereist het opvragen van gestructureerde logs (bijv. JSON) LogQL-analyse. Dit betekent dat de queryprestaties afhankelijk zijn van hoe goed de logs zijn gestructureerd vóór de ingestie. Zonder gestructureerde logs lijdt de query-efficiëntie omdat filteren moet plaatsvinden bij ophalingstijd, niet bij ingestie.
Opslag in Objectopslag
Loki schrijft logbrokken weg naar objectopslag (bijv. S3, GCS, Azure Blob). Dit vermindert de afhankelijkheid van dure blokopslag zoals bijvoorbeeld vereist is bij Elasticsearch.
Het lezen van logs van objectopslag kan echter traag zijn in vergelijking met directe vragen aan een database. Loki compenseert hiervoor door recente logs in ingesters te bewaren voor snellere opvraging. Compacting vermindert de opslagoverhead, maar log-opvragingslatentie kan nog steeds een probleem zijn voor grootschalige vragen.
Labels en Cardinaliteit
Aangezien labels worden gebruikt om logs te doorzoeken, zijn ze cruciaal voor efficiënte vragen. Slechte labeling kan leiden tot hoge cardinaliteitsproblemen. Het gebruik van labels met een hoge cardinaliteit (bijv. user_id, session_id) verhoogt het geheugengebruik en vertraagt de vragen. Loki hashed labels om logs over ingesters te verdelen, dus een slecht labelontwerp kan zorgen voor een ongelijke logdistributie.
Vroeg filteren
Aangezien Loki gecomprimeerde ruwe logs in objectopslag bewaart, is het belangrijk om vroeg te filteren als we willen dat onze vragen snel worden verwerkt. Het verwerken van complexe parsing op kleinere datasets zal de responstijd verhogen. Volgens deze regel zou een goede query Query 1 zijn, en een slechte query zou Query 2 zijn.
Query 1
{job="nginx", status_code=~"5.."} | jsonQuery 1 filtert logs waar job="nginx" en de status_code begint met 5 (500–599 fouten). Vervolgens worden gestructureerde JSON-velden geëxtraheerd met | json. Dit minimaliseert het aantal logs dat door de JSON-parser wordt verwerkt, waardoor het sneller wordt.
Query 2
{job="nginx"} | json | status_code=~"5.."Query 2 haalt eerst alle logs op van nginx. Dit kunnen miljoenen items zijn. Vervolgens wordt voor elke logboekvermelding JSON geparseerd voordat er wordt gefilterd op status_code. Dit is inefficiënt en aanzienlijk langzamer.
Afronding
Grafana Loki is een krachtig, kostenefficiënt logaggregatiesysteem dat is ontworpen voor schaalbaarheid en eenvoud. Door alleen metadata te indexeren, houdt het de opslagkosten laag terwijl het snelle queries mogelijk maakt met behulp van LogQL.
De microservices-architectuur ondersteunt flexibele implementaties, waardoor het ideaal is voor cloud-native omgevingen. In dit artikel worden de basisprincipes van Loki en zijn querytaal behandeld. Door door de belangrijkste kenmerken van Loki’s architectuur te navigeren, kunnen we een beter inzicht krijgen in de afwegingen die hierbij komen kijken.
Source:
https://dzone.com/articles/grafana-loki-fundamentals-and-architecture