













Op 11 december 2024 ondervonden de OpenAI-diensten aanzienlijke uitvaltijd als gevolg van een probleem dat voortkwam uit de implementatie van een nieuwe telemetriedienst. Dit voorval had invloed op de API-, ChatGPT- en Sora-diensten, wat resulteerde in verstoringen die meerdere uren duurden. Als een bedrijf dat ernaar streeft om nauwkeurige en efficiënte AI-oplossingen te bieden, heeft OpenAI een gedetailleerd post-mortemrapport gedeeld om transparant te bespreken wat er misging en hoe ze van plan zijn soortgelijke voorvallen in de toekomst te voorkomen.
In dit artikel zal ik de technische aspecten van het voorval beschrijven, de oorzaken uiteenzetten en de belangrijkste lessen onderzoeken die ontwikkelaars en organisaties die gedistribueerde systemen beheren uit dit evenement kunnen leren.
De Tijdlijn van het Voorval
Hier is een overzicht van hoe de gebeurtenissen zich op 11 december 2024 ontvouwden:
| Time (PST) | Event |
|---|---|
| 15:16 |
Minimale impact op klanten begon; servicedegradatie waargenomen |
| 15:27 | Ingenieurs begonnen het verkeer om te leiden van de getroffen clusters |
| 15:40 | Maximale impact op klanten geregistreerd; grote uitval over alle diensten |
| 16:36 | Het eerste Kubernetes-cluster begon te herstellen |
| 17:36 | Aanzienlijk herstel van API-diensten begon |
| 17:45 | Aanzienlijk herstel van ChatGPT waargenomen |
| 19:38 | Alle diensten volledig hersteld over alle clusters |
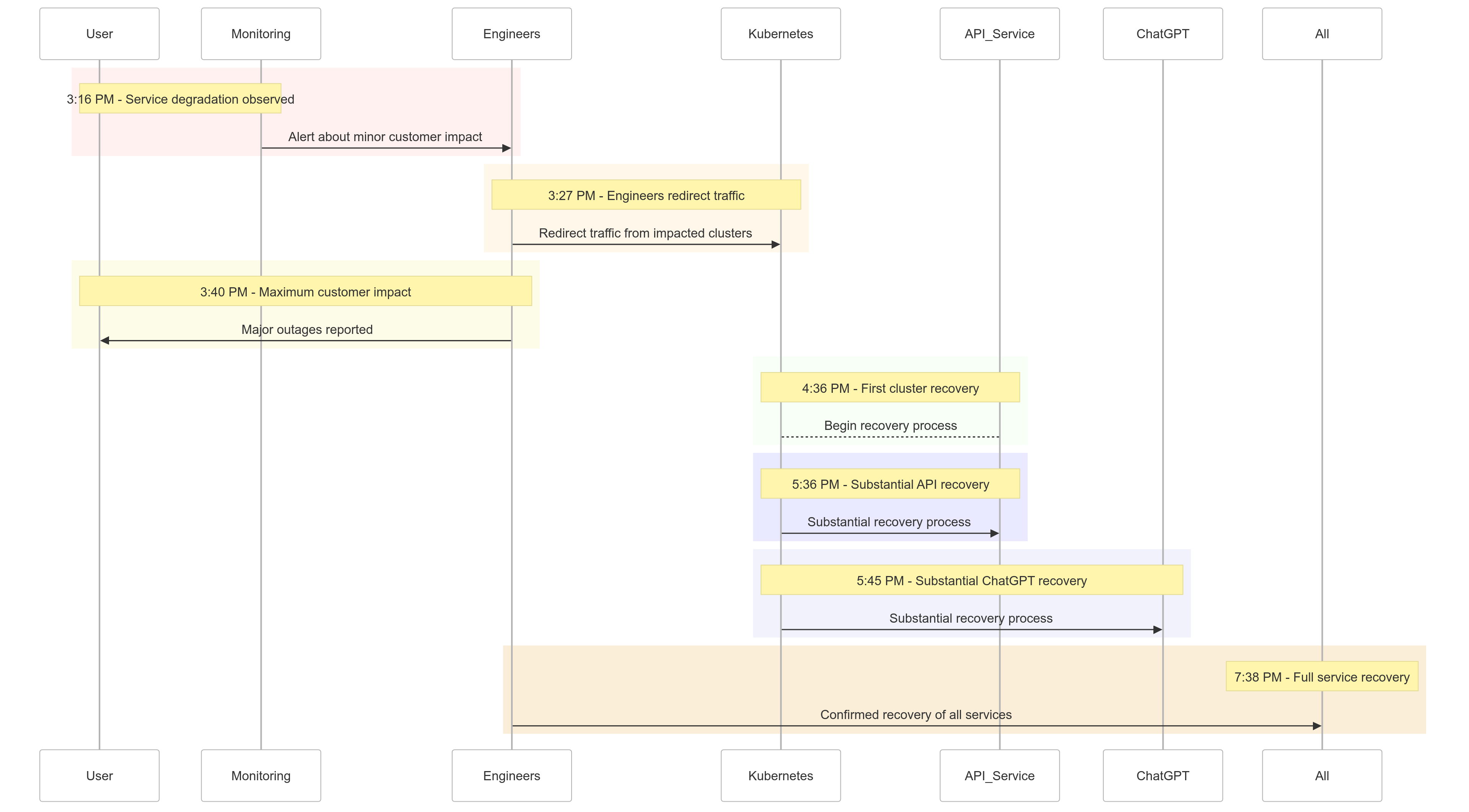
Figuur 1: OpenAI Incident Tijdlijn – Service Degradatie tot Volledig Herstel.
Oorzaakanalyse
De oorzaak van het incident lag in een nieuwe telemetrieservice die om 15:12 uur PST werd ingezet om de observatiemogelijkheden van Kubernetes-controlevlakken te verbeteren. Deze service overspoelde per ongeluk Kubernetes API-servers over meerdere clusters, wat leidde tot opeenvolgende storingen.
Uiteenzetting
Implementatie van Telemetrieservice
De telemetrieservice was ontworpen om gedetailleerde Kubernetes-controlevlakmetingen te verzamelen, maar de configuratie activeerde onbedoeld resource-intensieve Kubernetes API-bewerkingen over duizenden nodes tegelijkertijd.
Overbelast Controlevlak
Het Kubernetes-controlevlak, verantwoordelijk voor clusterbeheer, raakte overbelast. Terwijl het dataplatform (dat gebruikersverzoeken afhandelt) gedeeltelijk functioneel bleef, was het afhankelijk van het controlevlak voor DNS-oplossing. Naarmate gecachte DNS-records verliepen, begonnen services die afhankelijk waren van realtime DNS-oplossing te falen.
Onvoldoende Testen
De implementatie werd getest in een testomgeving, maar de testclusters weerspiegelden niet de schaal van productieclusters. Hierdoor bleef het probleem van de belasting van de API-server onopgemerkt tijdens het testen.
Hoe het Probleem is Verminderd
Toen het incident begon, identificeerden OpenAI-engineers snel de oorzaak, maar ze werden geconfronteerd met uitdagingen bij het implementeren van een oplossing omdat het overbelaste Kubernetes-controlepaneel de toegang tot de API-servers belemmerde. Er werd een meerledige aanpak aangenomen:
- Clustergrootte verkleinen: Het verminderen van het aantal knooppunten in elke cluster verlaagde de belasting van de API-server.
- Netwerktoegang tot Kubernetes-beheer-API’s blokkeren: Voorkwam extra API-verzoeken, waardoor servers konden herstellen.
- Kubernetes API-servers opschalen: Het toewijzen van extra middelen hielp bij het verwerken van wachtende verzoeken.
Deze maatregelen stelden ingenieurs in staat om weer toegang te krijgen tot de controle-infrastructuur en de problematische telemetrieservice te verwijderen, waardoor de servicefunctionaliteit werd hersteld.
Leerpunten
Dit incident benadrukt het belang van robuuste testen, monitoring en fail-safe mechanismen in gedistribueerde systemen. Dit is wat OpenAI heeft geleerd (en geïmplementeerd) van de storing:
1. Robuuste gefaseerde implementaties
Alle infrastructuurwijzigingen zullen voortaan gefaseerde implementaties volgen met continue monitoring. Dit zorgt ervoor dat problemen vroegtijdig worden gedetecteerd en aangepakt voordat ze van invloed zijn op de volledige vloot.
2. Foutinjectietesten
Door storingen te simuleren (bijvoorbeeld het uitschakelen van het controlepaneel of het doorvoeren van slechte wijzigingen), zal OpenAI verifiëren dat hun systemen automatisch kunnen herstellen en problemen kunnen detecteren voordat klanten er last van ondervinden.
3. Noodtoegang tot de controlelaag
Met een “noodmechanisme” zullen ingenieurs toegang hebben tot Kubernetes API-servers, zelfs bij zware belasting.
4. Ontkoppelen van de controle- en gegevenslagen
Om afhankelijkheden te verminderen, zal OpenAI de Kubernetes-gegevenslaag (die workloads afhandelt) loskoppelen van de controlelaag (verantwoordelijk voor orchestratie), zodat kritieke services kunnen blijven draaien zelfs tijdens uitval van de controlelaag.
5. Snellere herstelmechanismen
Nieuwe caching- en rate-limiting-strategieën zullen de opstarttijden van clusters verbeteren, zodat sneller herstel bij storingen mogelijk is.
Voorbeeldcode: Voorbeeld van gefaseerde implementatie
Hier volgt een voorbeeld van het implementeren van een gefaseerde uitrol voor Kubernetes met behulp van Helm en Prometheus voor zichtbaarheid.
Uitrol met Helm met gefaseerde uitrol:
# Deploy the telemetry service to 10% of clusters
helm upgrade --install telemetry-service ./telemetry-chart \
--set replicaCount=10 \
--set deploymentStrategy=phased-rollout
Prometheus-query voor het monitoren van de belasting van de API-server:
# PromQL Query to monitor Kubernetes API server load
sum(rate(apiserver_request_duration_seconds_sum1m)) by (cluster) /
sum(rate(apiserver_request_duration_seconds_count1m)) by (cluster)
Deze query helpt bij het bijhouden van responstijden voor API-serververzoeken, waardoor vroegtijdige detectie van belastingpieken mogelijk is.
Voorbeeld van foutinjectie
Met chaos-mesh kan OpenAI storingen simuleren in de Kubernetes-controlelaag.
# Inject fault into Kubernetes API server to simulate downtime
kubectl create -f api-server-fault.yaml
api-server-fout.yaml:
apiVersionchaos-mesh.org/v1alpha1
kindPodChaos
metadata
nameapi-server-fault
spec
actionpod-kill
modeone
selector
namespaces
kube-system
labelSelectors
appkube-apiserver
Deze configuratie beëindigt opzettelijk een API-server-pod om de systeemweerbaarheid te verifiëren.
Wat dit voor u betekent
Dit voorval benadrukt het belang van het ontwerpen van veerkrachtige systemen en het aannemen van rigoureuze testmethodologieën. Of je nu gedistribueerde systemen op schaal beheert of Kubernetes implementeert voor je workloads, hier zijn enkele belangrijke punten:
- Simuleer Regelmatig Falen: Gebruik chaos engineering tools zoals Chaos Mesh om de robuustheid van systemen onder realistische omstandigheden te testen.
- Monitor op Meerdere Niveaus: Zorg ervoor dat je observability stack zowel service-niveau metrics als clustergezondheidsmetrics bijhoudt.
- Ontkoppel Kritieke Afhankelijkheden: Verminder de afhankelijkheid van enkele punten van falen, zoals DNS-gebaseerde serviceontdekking.
Conclusie
Hoewel geen enkel systeem immuun is voor falen, herinneren incidenten zoals deze ons aan de waarde van transparantie, snelle remedie en continue leren. De proactieve benadering van OpenAI om deze post-mortem te delen biedt een blauwdruk voor andere organisaties om hun operationele praktijken en betrouwbaarheid te verbeteren.
Door prioriteit te geven aan robuuste gefaseerde uitrol, foutinjectietests en veerkrachtig systeemontwerp, geeft OpenAI een sterk voorbeeld van hoe om te gaan met en te leren van grootschalige uitval.
Voor teams die gedistribueerde systemen beheren, is dit voorval een geweldige casestudy over hoe risico’s te beheren en de downtime van kern bedrijfsprocessen te minimaliseren.
Laten we dit gebruiken als een kans om samen betere, veerkrachtigere systemen te bouwen.
Source:
https://dzone.com/articles/what-we-should-learn-from-openais-downtime-incident