













Sinds het Java-platform een releasecyclus van zes maanden heeft aangenomen, zijn we voorbij de eeuwige vragen zoals “Zal Java dit jaar sterven?” of “Is het de moeite waard om naar de nieuwe versie te migreren?”. Ondanks 28 jaar sinds de eerste release, blijft Java bloeien en is het een populaire keuze als de primaire programmeertaal voor veel nieuwe projecten.
Java 17 was een belangrijke mijlpaal, maar Java 21 heeft nu de plaats van 17 ingenomen als de volgende long-term support release (LTS). Het is essentieel voor Java-ontwikkelaars om op de hoogte te blijven van de veranderingen en nieuwe functies die deze versie met zich meebrengt. Geïnspireerd door mijn collega Darek, die Java 17-functies in zijn artikel heeft beschreven, heb ik besloten om JDK 21 op een vergelijkbare manier te bespreken (ik heb ook Java 23-functies geanalyseerd in een vervolgartikel, dus kijk daar ook eens naar).
JDK 21 bestaat uit in totaal 15 JEPs (JDK Enhancement Proposals). Je kunt de complete lijst bekijken op de officiële Java-site. In dit artikel zal ik verschillende Java 21 JEPs benadrukken die ik bijzonder opmerkelijk vind. Namelijk:
- String Templates
- Geordende Collecties
- Patroonherkenning voor
switchen Recordpatronen - Virtuele Threads
Zonder verder oponthoud, laten we de code induiken en deze updates verkennen.
String Templates (Voorbeeld)
De Spring Templates-functie is nog steeds in de voorbeeldmodus. Om deze te gebruiken, moet je de --enable-preview vlag aan je compilerargumenten toevoegen. Ik heb echter besloten het te vermelden ondanks de voorbeeldstatus. Waarom? Omdat ik erg geïrriteerd raak elke keer dat ik een logbericht of SQL-instructie moet schrijven die veel argumenten bevat of moet ontcijferen welk plaatsaanduiding met een gegeven arg zal worden vervangen. En Spring Templates belooft me (en jou) daarbij te helpen.
Zoals de JEP-documentatie zegt, is het doel van Spring Templates om “het schrijven van Java-programma’s te vereenvoudigen door het gemakkelijk te maken om strings uit te drukken die waarden bevatten die tijdens runtime zijn berekend.”
Laten we controleren of het echt eenvoudiger is.
De “oude manier” zou zijn om de formatted() methode op een String-object te gebruiken:
var msg = "Log message param1: %s, pram2: %s".formatted(p1, p2);
Nu, met StringTemplate.Processor (STR), ziet het er als volgt uit:
var interpolated = STR."Log message param1: \{p1}, param2: \{p2}";
Met een korte tekst zoals de bovenstaande, is de winst misschien niet zo zichtbaar – maar geloof me, als het gaat om grote tekstblokken (JSON’s, SQL-instructies, enz.), zullen benoemde parameters je enorm helpen.
Geordende Collecties
Java 21 heeft een nieuwe Java Collection Hiërarchie geïntroduceerd. Kijk naar het diagram hieronder en vergelijk het met wat je waarschijnlijk hebt geleerd tijdens je programmeerlessen. Je zult opmerken dat er drie nieuwe structuren zijn toegevoegd (gemarkeerd met de groene kleur).
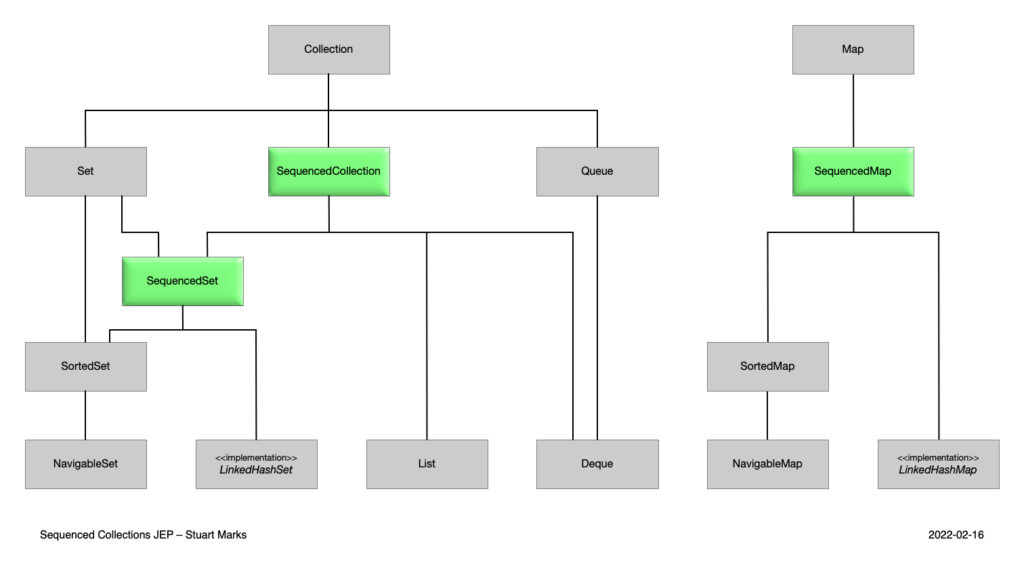 Afbeeldingsbron: JEP 431
Afbeeldingsbron: JEP 431
Geordende collecties introduceren een nieuwe ingebouwde Java API, die de bewerkingen op geordende datasets verbetert. Deze API stelt niet alleen in staat om op een handige manier toegang te krijgen tot de eerste en laatste elementen van een collectie, maar maakt ook efficiënte traversie, invoeging op specifieke posities en het ophalen van sub-sequenties mogelijk. Deze verbeteringen maken bewerkingen die afhankelijk zijn van de volgorde van elementen eenvoudiger en intuïtiever, wat zowel de prestaties als de leesbaarheid van de code verbetert bij het werken met lijsten en vergelijkbare datastructuren.
Dit is de volledige lijst van de SequencedCollection interface:
public interface SequencedCollection<E> extends Collection<E> {
SequencedCollection<E> reversed();
default void addFirst(E e) {
throw new UnsupportedOperationException();
}
default void addLast(E e) {
throw new UnsupportedOperationException();
}
default E getFirst() {
return this.iterator().next();
}
default E getLast() {
return this.reversed().iterator().next();
}
default E removeFirst() {
var it = this.iterator();
E e = it.next();
it.remove();
return e;
}
default E removeLast() {
var it = this.reversed().iterator();
E e = it.next();
it.remove();
return e;
}
}Dus, in plaats van:
var first = myList.stream().findFirst().get();
var anotherFirst = myList.get(0);
var last = myList.get(myList.size() - 1);Kunnen we gewoon schrijven:
var first = sequencedCollection.getFirst();
var last = sequencedCollection.getLast();
var reversed = sequencedCollection.reversed();Dit is een kleine wijziging, maar IMHO is het zo’n handige en bruikbare functie.
Patroonmatching en Recordpatronen
Vanwege de gelijkenis van Pattern Matching voor switch en Record Patterns, zal ik ze samen beschrijven. Record patterns zijn een nieuwe functie: ze zijn geïntroduceerd in Java 19 (als een preview). Aan de andere kant is Pattern Matching voor switch een soort voortzetting van de uitgebreide instanceof expressie. Het biedt nieuwe mogelijke syntaxis voor switch statements, waarmee je complexe data-georiënteerde queries gemakkelijker kunt uitdrukken.
Laten we de basisprincipes van OOP vergeten voor de duidelijkheid van dit voorbeeld en het werknemersobject handmatig deconstrueren (employee is een POJO klasse).
Voor Java 21 zag het er zo uit:
if (employee instanceof Manager e) {
System.out.printf("I’m dealing with manager of %s department%n", e.department);
} else if (employee instanceof Engineer e) {
System.out.printf("I’m dealing with %s engineer.%n", e.speciality);
} else {
throw new IllegalStateException("Unexpected value: " + employee);
} Wat als we van de lelijke instanceof af konden? Nou, dat kunnen we nu, dankzij de kracht van Pattern Matching in Java 21:
switch (employee) {
case Manager m -> printf("Manager of %s department%n", m.department);
case Engineer e -> printf("I%s engineer.%n", e.speciality);
default -> throw new IllegalStateException("Unexpected value: " + employee);
} Terwijl we het over de switch verklaring hebben, kunnen we ook de Record Patterns functie bespreken. Bij het werken met een Java Record, stelt het ons in staat om veel meer te doen dan met een standaard Java klasse:
switch (shape) { // shape is a record
case Rectangle(int a, int b) -> System.out.printf("Area of rectangle [%d, %d] is: %d.%n", a, b, shape.calculateArea());
case Square(int a) -> System.out.printf("Area of square [%d] is: %d.%n", a, shape.calculateArea());
default -> throw new IllegalStateException("Unexpected value: " + shape);
}Zoals de code laat zien, zijn recordvelden met die syntaxis gemakkelijk toegankelijk. Bovendien kunnen we wat extra logica aan onze case statements toevoegen:
switch (shape) {
case Rectangle(int a, int b) when a < 0 || b < 0 -> System.out.printf("Incorrect values for rectangle [%d, %d].%n", a, b);
case Square(int a) when a < 0 -> System.out.printf("Incorrect values for square [%d].%n", a);
default -> System.out.println("Created shape is correct.%n");
} We kunnen een vergelijkbare syntaxis gebruiken voor de if statements. Ook in het onderstaande voorbeeld zien we dat Record Patterns ook werken voor geneste records:
if (r instanceof Rectangle(ColoredPoint(Point p, Color c),
ColoredPoint lr)) {
//sth
}Virtuele Threads
De functie Virtuele Draad is waarschijnlijk de meest opwindende functie van Java 21 — of in ieder geval een waar Java-ontwikkelaars het meest op gewacht hebben. Zoals de JEP-documentatie (vermeld in de vorige zin) zegt, was een van de doelen van de virtuele draden om “servertoepassingen die zijn geschreven in de eenvoudige thread-per-request-stijl in staat te stellen te schalen met bijna optimale hardwarebenutting”. Betekent dit echter dat we onze volledige code die gebruikmaakt van java.lang.Thread moeten migreren?
Eerst laten we het probleem onderzoeken met de aanpak die bestond vóór Java 21 (in feite, vrijwel sinds de eerste release van Java). We kunnen schatten dat één java.lang.Thread (afhankelijk van het besturingssysteem en de configuratie) ongeveer 2 tot 8 MB geheugen verbruikt. Het belangrijke hier is echter dat één Java-draad 1:1 is gekoppeld aan een kernel-draad. Voor eenvoudige webapps die een “één draad per verzoek” benadering gebruiken, kunnen we gemakkelijk berekenen dat ofwel onze machine “vermoord” zal worden wanneer het verkeer toeneemt (het zal de belasting niet kunnen aan) of dat we gedwongen zullen worden een apparaat met meer RAM aan te schaffen, en onze AWS-rekeningen zullen als gevolg daarvan toenemen.
Natuurlijk zijn virtuele draden niet de enige manier om dit probleem aan te pakken. We hebben asynchrone programmering (frameworks zoals WebFlux of de native Java API zoals CompletableFuture). Om de een of andere reden — misschien vanwege de “ongunstige API” of de hoge instapdrempel — zijn deze oplossingen echter niet zo populair.
Virtuele threads worden niet beheerd of gepland door het besturingssysteem. In plaats daarvan wordt hun planning afgehandeld door de JVM. Terwijl echte taken moeten worden uitgevoerd in een platformthread, gebruikt de JVM zogenaamde draagthreads — in wezen platformthreads — om een virtuele thread “mee te nemen” wanneer deze klaar is voor uitvoering. Virtuele threads zijn ontworpen om lichtgewicht te zijn en gebruiken veel minder geheugen dan standaard platformthreads.
Het onderstaande diagram toont aan hoe virtuele threads zijn verbonden met platform- en OS-threads:
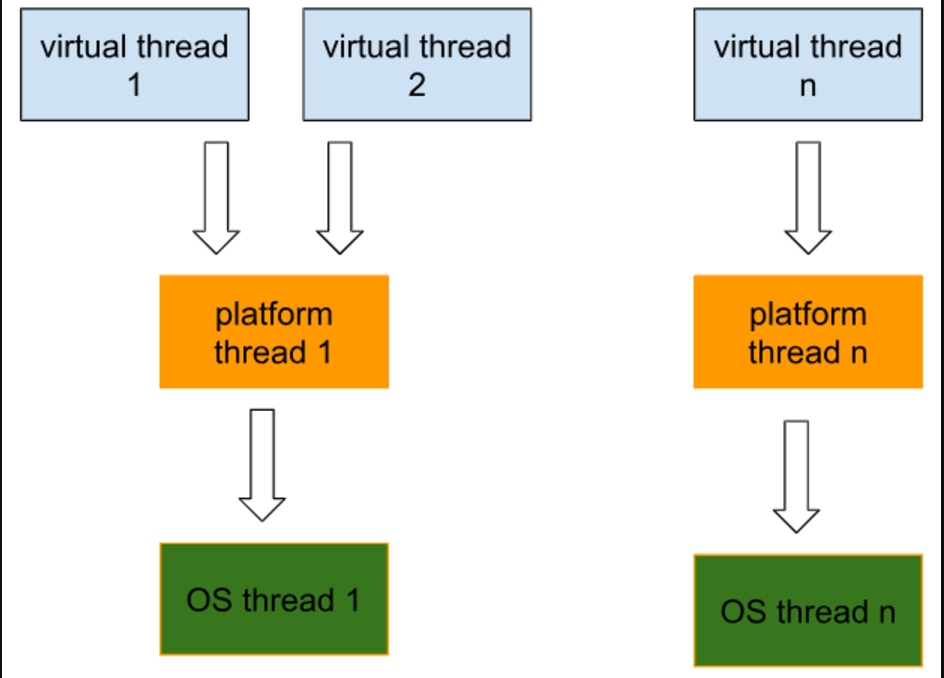
Dus, om te zien hoe virtuele threads worden gebruikt door platformthreads, laten we code uitvoeren die (1 + het aantal CPU’s dat de machine heeft, in mijn geval 8 cores) virtuele threads start.
var numberOfCores = 8; //
final ThreadFactory factory = Thread.ofVirtual().name("vt-", 0).factory();
try (var executor = Executors.newThreadPerTaskExecutor(factory)) {
IntStream.range(0, numberOfCores + 1)
.forEach(i -> executor.submit(() -> {
var thread = Thread.currentThread();
System.out.println(STR."[\{thread}] VT number: \{i}");
try {
sleep(Duration.ofSeconds(1L));
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}));
}De uitvoer ziet er als volgt uit:
[VirtualThread[#29,vt-6]/runnable@ForkJoinPool-1-worker-7] VT number: 6
[VirtualThread[#26,vt-4]/runnable@ForkJoinPool-1-worker-5] VT number: 4
[VirtualThread[#30,vt-7]/runnable@ForkJoinPool-1-worker-8] VT number: 7
[VirtualThread[#24,vt-2]/runnable@ForkJoinPool-1-worker-3] VT number: 2
[VirtualThread[#23,vt-1]/runnable@ForkJoinPool-1-worker-2] VT number: 1
[VirtualThread[#27,vt-5]/runnable@ForkJoinPool-1-worker-6] VT number: 5
[VirtualThread[#31,vt-8]/runnable@ForkJoinPool-1-worker-6] VT number: 8
[VirtualThread[#25,vt-3]/runnable@ForkJoinPool-1-worker-4] VT number: 3
[VirtualThread[#21,vt-0]/runnable@ForkJoinPool-1-worker-1] VT number: 0Dus, ForkJonPool-1-worker-X Platformthreads zijn onze draagthreads die onze virtuele threads beheren. We observeren dat virtuele threads nummer 5 en 8 dezelfde draagthread nummer 6 gebruiken.
Het laatste dat ik je wil laten zien over virtuele threads is hoe ze je kunnen helpen met de blokkering I/O-operaties.
Telkens wanneer een virtuele thread een blokkering tegenkomt, zoals I/O-taken, ontkoppelt de JVM deze efficiënt van de onderliggende fysieke thread (de draagthread). Deze ontkoppeling is cruciaal omdat het de draagthread vrijmaakt om andere virtuele threads uit te voeren in plaats van inactief te zijn en te wachten tot de blokkering is voltooid. Als gevolg hiervan kan een enkele draagthread veel virtuele threads multiplexen, wat kan oplopen tot duizenden of zelfs miljoenen, afhankelijk van het beschikbare geheugen en de aard van de uitgevoerde taken.
Laten we proberen dit gedrag te simuleren. Hiervoor dwingen we onze code om slechts één CPU-kern te gebruiken, met slechts 2 virtuele threads — voor betere duidelijkheid.
System.setProperty("jdk.virtualThreadScheduler.parallelism", "1");
System.setProperty("jdk.virtualThreadScheduler.maxPoolSize", "1");
System.setProperty("jdk.virtualThreadScheduler.minRunnable", "1");Thread 1:
Thread v1 = Thread.ofVirtual().name("long-running-thread").start(
() -> {
var thread = Thread.currentThread();
while (true) {
try {
Thread.sleep(250L);
System.out.println(STR."[\{thread}] - Handling http request ....");
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
}
}
);Thread 2:
Thread v2 = Thread.ofVirtual().name("entertainment-thread").start(
() -> {
try {
Thread.sleep(1000L);
} catch (InterruptedException e) {
throw new RuntimeException(e);
}
var thread = Thread.currentThread();
System.out.println(STR."[\{thread}] - Executing when 'http-thread' hit 'sleep' function");
}
);Uitvoering:
v1.join(); v2.join();Resultaat:
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#23,entertainment-thread]/runnable@ForkJoinPool-1-worker-1] - Executing when 'http-thread' hit 'sleep' function
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....
[VirtualThread[#21,long-running-thread]/runnable@ForkJoinPool-1-worker-1] - Handling http request ....We observeren dat beide Virtuele Threads (long-running-thread en entertainment-thread) worden gedragen door slechts één Platform Thread, namelijk ForkJoinPool-1-worker-1.
Samenvattend stelt dit model Java-toepassingen in staat om hoge niveaus van gelijktijdigheid en schaalbaarheid te bereiken met veel lagere overhead dan traditionele threadmodellen, waarbij elke thread direct overeenkomt met een enkele besturingssysteemthread. Het is vermeldenswaard dat virtuele threads een enorm onderwerp zijn, en wat ik heb beschreven is slechts een klein deel. Ik moedig je sterk aan om meer te leren over de planning, pinned threads en de interne werking van Virtuele Threads.
Samenvatting: De Toekomst van de Java Programmeertaal
De hierboven beschreven functies zijn de belangrijkste die ik beschouw in Java 21. De meeste zijn niet zo baanbrekend als sommige van de dingen die zijn geïntroduceerd in JDK 17, maar ze zijn nog steeds erg nuttig en prettig om te hebben QOL (Quality of Life) veranderingen.
Echter, je moet ook andere verbeteringen in JDK 21 niet onderschatten — ik moedig je sterk aan om de complete lijst te analyseren en verder alle functies te verkennen. Een ding dat ik bijzonder opmerkelijk vind, is de Vector API, die vectorberekeningen op enkele ondersteunde CPU-architecturen mogelijk maakt — wat daarvoor niet mogelijk was. Momenteel bevindt het zich nog in de incubatorstatus/externe fase (wat de reden is dat ik het hier niet in meer detail heb belicht), maar het biedt grote belofte voor de toekomst van Java.
Over het geheel genomen signaleert de vooruitgang die Java op verschillende gebieden heeft geboekt de voortdurende toewijding van het team om de efficiëntie en prestaties in veelgevraagde toepassingen te verbeteren.
Source:
https://dzone.com/articles/java-21-features-a-detailed-look