













Inleiding
In data science en vooral in Natural Language Processing is samenvatting altijd een onderwerp van intense belangstelling geweest. Hoewel textuur samenvatting methodes al een tijdje bestaan, hebben de laatste jaren significante ontwikkelingen in Natural Language Processing en diep leren gezien. Er is een flits van publicaties verschenen op dit onderwerp door internet giganters, zoals de recente ChatGPT. Hoewel er veel werk wordt gedaan aan dit onderzoeksonderwerp, is er erg weinig geschreven over de praktische implementatie van AI-gebaseerde samenvatting. Het lastige ontleden van alomvattende, alomtegenwoordige stellingen is een obstakel voor effectieve samenvatting.
Samenvatting van een nieuwsartikel en een financiële winstrapport zijn twee verschillende taken. Bij het behandelen van tekstkenmerken die in lengte of onderwerpgebied verschillen (tech, sport, financiën, reizen, enzovoort), wordt samenvatting een uitdaging voor de data wetenschap. Het is essentieel om een aantal grondslagkenmerken voor samenvatting te behandelen voordat je gaat overslaan op een overzicht van toepassingen.
Uitgebreide Samenvatting
Het proces van extractieve samenvatting bestaat erin de meest relevante zinnen uit een artikel te kiezen en ze systematisch te organiseren. De zinnen die de samenvatting uitmaken zijn letterlijk afkomstig uit de bronmateriaal.
Extractieve samenvattingssystemen, zoals we ze nu kennen, draaien om drie fundamentele bewerkingen:
Bouwen van een tussenstadium van de invoertekst
Topscholen en indicatorrepresentaties zijn voorbeelden van representatiesgebaseerde methodes. Om de onderwerpen genoemd in het tekst te begrijpen, converteert de topiekrepresentatie het tekst naar een tussenstadium.
Scores geven aan de zinnen op basis van de representatie
Bij het genereren van het tussenstadium wordt elke zin een significantie score toegekend. Bij het gebruik van een methode die afhankelijk is van de topiekrepresentatie, wordt de score van een zin gereflecteerd door hoe effectief ze kritieke concepten in het tekst uitlicht. Bij indicatorrepresentatie wordt de score berekend door de beweringen van verschillende gewogen indicatoren samen te voegen.
Kies een samenvatting uit meerdere zinnen
Om een samenvatting te genereren, kiest de samenvattingsoftware de top k zinnen. Bijvoorbeeld, sommige methodes gebruiken greedy-algoritmen om te kiezen en te bepalen welke zinnen het meest relevant zijn, terwijl andere de selectie van zinnen misschien omvatten tot een optimeringsprobleem waarin een set zinnen wordt gekozen onder de voorwaarde dat het maximeren van de algemene belang en coherente behoeft en het minimaliseren van de hoeveelheid redundante informatie moet doen.
Laten we diepgaam in de methodes die we hebben genoemd:
Topisch representatietypen
Topische woorden: Met deze methode kun je termen relateren aan het thema in een invoerdocument vinden. Het belang van een zin kan op twee manieren berekend worden: eerst als een functie van het aantal topische handtekeningen die ze bevat; tweede, als een fractie van de topische handtekeningen die ze bevat.
Terwijl de eerste methode hogere scores geeft aan langere zinnen met meer woorden, meet de tweede de dichtheid van de topische woorden.
Frequentiegerichte aanpakken: door deze methode worden woorden een relatieve belangschap gegeven. Als het term past bij het onderwerp, krijgt het 1 punt; anders gaat het naar nul. Afhankelijk van hoe ze zijn geïmplementeerd, kunnen de gewichten continue zijn. Tema’s kunnen worden weergegeven door middel van een van twee methodes:
Woord Kans: Het neemt alleen de frequentie van een woord om zijn significantie te aangeven. Om de kans van een woord w te berekenen, delen we de frequentie waarmee het voorkomt, f (w), door het totaal aantal woorden, N.
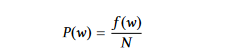
De gemiddelde significantie van de woorden in een zin geeft de belangschap van de zin bij gebruik van woordkansen.
TFIDF (Term Frequency Inverse Document Frequency): Deze methode is een verbetering van de aanpak van woordkansen. Hierbij worden de gewichten bepaald door middel van de TF-IDF aanpak. Het Techniek van Term Frequency Inverse Document Frequency (TFIDF) geeft minder belang aan termen die vaak in de meeste documenten voorkomen. Het gewicht van elk woord w in document d wordt berekend als volgt:
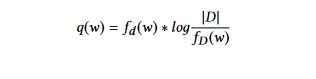
waarin fd (w) de term frequentie van woord w in document d is,
fD (w) het aantal documenten dat het woord w bevat, en |D| het aantal documenten in de collectie D is.
Latente Semantic Analyse: Latente semantic analyse (LSA) is een ongeleid methodiek voor het extraheren van een representatie van tekstsemantieken gebaseerd op geobserveerde woorden. Het LSA-proces begint met de constructie van een termen-zinmatrix (n x m), waarbij elke rij een woord uit de invoer (n-woorden) representeert en elke kolom een zin (m-zinnen). In de matrix is de waarde van het woord i in de zin j gedefinieerd door de cel aij. Volgens de TFIDF-techniek wordt elk woord in een zin een bepaalde waarde toegekend, met een waarde van nul voor termen die niet in de zin voorkomen.
Indicatorrepresentatieapproches
Graafgebaseerde methodes
Grafische methoden, geïnspireerd door de PageRank-algoritme, representeren de documenten als een verbonden graaf. Zinnen vormen de vertices van de graaf, en de verbindingen tussen zinnen geven de mate van verband tussen twee zinnen weer. Een veelgebruikte methode om twee vertices te koppelen is het beoordelen van de mate van overeenkomst tussen twee zinnen, en als de mate van overeenkomst hoger is dan een bepaald drempelgetal, worden de vertices verbonden. Er zijn twee mogelijke uitkomsten met deze grafische representatie. Eerst worden de delen (sub-grafen) van de graaf de individuele categorieën van informatie die door de documenten worden beschermd. Het tweede resultaat is dat de belangrijkste zinnen van het document zijn gemarkeerd. Zinnen die met veel andere zinnen in de partitie zijn verbonden kunnen mogelijk het centrum van de graaf zijn en zijn waarschijnlijker opgenomen in de samenvatting. Zowel eenvoudige als meerdocumentaire samenvattingen kunnen profiteren van het gebruik van grafiek-gebaseerde technieken.
Machine Learning
Machine learning-technieken zien het samenvattingprobleem als een classificatie uitdaging. Modellen proberen zinnen te categoriseren in samenvatting- en niet-samenvattingscategorieën op basis van hun kenmerken. We hebben een trainingsset die bestaat uit documenten en door mensen gecontroleerde geëxtraheerde samenvattingen waar we onze algoritmen op kunnen trainen. Dit wordt vaak gedaan met Naive Bayes, beslissingsboom of steunvectormachine.
Abstracte Samenvatting
In tegenstelling tot extractieve samenvatting is abstracte Samenvatting een effectiever method. De mogelijkheid om unieke zinnen te maken die cruciale informatie uit tedrukken bronnen van tekst, heeft hieraan bijgedragen aan de opkomende populariteit.
Een abstracte samenvatting presenteert de inhoud in een logische, goed georganiseerde en grammaticaal correcte vorm. De kwaliteit van een samenvatting kan worden verbeterd door de leesbaarheid te verhogen of de taalkwaliteit te verbetern. (voeg afbeelding toe).
Er zijn twee aanpakken: De Struktuur gebaseerde aanpak en de Semantische gebaseerde aanpak.
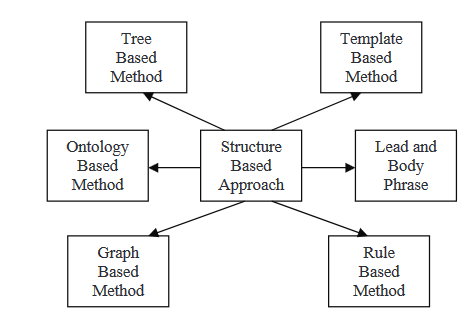
STRUKTUUR GEBASEERDE APPROACH
Bij een structuur eerst gebaseerde methode wordt de meest belangrijke informatie uit het document (en) gecodeerd met behulp van psychologische kenmerk schema’s zoals templates, extractie regels en alternatieve structuren, inclusief boom, ontologie, kop en lichaam, regel en grafiek gebaseerde structuur. We zullen hieronder lezen over enkele van de vele methoden die in deze strategie zijn geïntegreerd.
Boomgebaseerde methoden
In deze methode wordt de inhoud van een document weergegeven als een afhankelijkheidsboom. De inhoudselectie voor een samenvatting kan worden uitgevoerd via verschillende technieken, zoals een algoritme voor themaoverlap of een die gebruik maakt van deelnemende alignering over geparseerde zinnen. Deze aanpak gebruikt ofwel een taalgenerator of een associëerdegeneeskunde-algoritme voor het genereren van samenvattingen. In dit onderzoek bieden de auteurs een zinfusie-methode die gebruik maakt van onder-up lokale multi-sequencealignment om de algemeen informatieve frases te vinden. Samenvattingssystemen voor meergenen gebruiken een techniek genaamd zinfusie.
In deze methode wordt een set documenten gebruikt als invoer, behandeld met een algoritme voor themaselectie om de centrale thema’s te extraheren, en vervolgens wordt een clusteringalgoritme gebruikt om de frases in waardeordening te rangschikken. Na de zinnen te zijn geordend, worden ze gefuseerd met behulp van zinfusie, en wordt een statistische samenvatting gegenereerd. De gestructureerde methode codeert de belangrijkste data uit het document(en) met behulp van cognitieve schema’s zoals templates, extractieregels en alternatieve structuren zoals boom, ontologie, kop en lichaam, regel en structuur op basis van grafiek.
Template-gebaseerde methoden
Bij deze methode wordt een handleiding gebruikt om een gehele document te representeren. Taalklassen of extractiecriteria worden vergeleken om tekstfragmenten te identificeren die kunnen worden gemapt naar sloten in de handleiding. Deze tekstfragmenten zijn de indicatoren van de ruimtelijke eenheden van de structuurinhoud. Dit onderzoek heeft twee methodes voor document Samenvatting voorgesteld (eenvoudige en meerdocument Samenvatting). Om uit documenten extracties en abstracten te maken, hebben zij de methodes gevolgd die beschreven zijn in GISTEXTER.
GESTEXTER is een Samenvattingssysteem dat is geïmplementeerd voor informatie-extractie. Het identificeert themagerelateerde informatie in het inkomstekst en converteert het naar database-entries. De zinnen worden vervolgens toegevoegd aan het samenvatting afhankelijk van de gebruikersverzoeken.

Ontologie-gebaseerde methoden
Vele onderzoekers hebben geëxperimenteerd met het verbeteren van de effectiviteit van samenvattingen door middel van een ontologie (kennisbase). De meeste internetdocumenten behoren tot een gemeenschappelijk domein, wat betekent dat zij allemaal over hetzelfde algemeen onderwerp gaan. Een ontologie is een krachtige representatie van de unieke informatiestructuur van elk domein.
Dit onderzoek voorstelt het gebruik van de onzekerheidsontologie, die onzekerheid modelleert en accurate beschrijvingen van domeinkennis uitvoert, om Chineese nieuwsberichten samenvattingen te maken. In deze methode wordt de domeinontologie voor nieuwsevenementen eerst gedefinieerd door domeinexperts, en dan wordt de fase van document voorbereiding uitgevoerd om semantische woorden uit de nieuwscorpus en de Chineese nieuwsdictieboeken te extraheren.
Kop- en hoofdpaginamethode
Deze aanpak bestaat uit het herschrijven van de kopzin door operaties uit te voeren op frases (toevoeging en vervanging) met dezelfde syntactische kopgroep in de kop- en hoofdpagina van de zin. Met behulp van syntactische analyse van fraseelementen heeft Tanaka een techniek voor het samenvatten van uitgezonden nieuws voorgesteld. Sinds de invoering van deze methode wordt de basis van dit concept afgeleid.
Samenvatting van nieuwsuitzendingen bestaat erin om zinnen die door de kop- en lichaamsecties gedeeld worden te vinden, en daarna deze zinnen in te voegen en te vervangen om zo een samenvatting te produceren via zinbewerking. Eerst wordt een syntactische parser toegepast op de kop- en lichaamsecties. Vervolgens worden triggersearchparen geïdentificeerd, en tenslotte worden zinnen gecorreleerd met verschillende gelijkenis- en aligneringscriteria. Het laatste stadium kan ofwel een invoering of vervanging zijn of zelfs beide.
Het invoeringsproces omvat het kiezen van een invoeringspunt, het controleren van redundantie en het kijken naar de interne coherente van de diskusie om zekerheid te krijgen van de samenhang en het verwijderen van redundantie. Het stappen voor vervanging biedt meer informatie door de lichaamszin in de koppartij te vervangen.
Regelgebaseerd methodiek
Bij deze techniek worden de documenten die samengevat moeten worden weergegeven in termen van klassen en lijsten van aspecten. Het module voor inhoudkeuze selecteert de meest effectieve kandidaat uit die gegenereerd worden door data-uitvoeringsregels om een of meerdere aspecten van een categorie te beantwoorden. Uiteindelijk worden generatiepatronen gebruikt voor de opbouw van opsommingszinnen.
Om zinnen en werkwoorden die semantisch gerelateerd zijn te identificeren, hebben Pierre-Etienne en zijn collega’s een set criteria voor informatie-extractie voorgesteld. Na de extractie wordt de gegevens verstuurd naar de stap van inhoudselectie, die pogingen maakt om gemengde kandidaten uit te filteren. Het wordt gebruikt voor zinstructuur en woorden in een directe generatiepatroon. Na de generatie wordt contentgeleid Samenvatting uitgevoerd.
Grafiekgebaseerde methodes
Vele onderzoekers gebruiken een grafiekgegevensstructuur om taaldocumenten weer te geven. Grafieken zijn een populairkeuze voor het weergeven van documenten binnen de taalkunde-studiecommunity. Elk knooppunt in het systeem vertegenwoordigt een woordeenheid, samen met geïnstalleerde richtingsverbindingen, die de structuur van een zin definiëren. Om de prestaties van de Samenvatting te verbeteren, heeft Dingding Wang en zijn kollega’s een multidocumentensamenvattingssystemen voorgesteld dat een breed scala aan strategieën gebruikt, zoals het gebaseerd op de centroïde methode, de grafiekgebaseerde methode, enzovoort, om verschillende basiscombinaties van methodes te evalueren, zoals gemiddelde score, gemiddelde rang, Bordacount, gemiddelde aggregatie, enzovoort.
Een unieke gewogen consensusmethode is ontwikkeld om de resultaten van verschillende samenvattingstrategieën te verzamelen. Bij een semantiekgebaseerde aanpak wordt een taalgebruiksillustratie van een document of -documenten gebruikt om een natuurlijk taalgeneratie (NLG) systeem aan te steken. Deze techniek specialiseert zich in het identificeren van naamruimten en werkruimten aan de hand van taalgegevens.
SEMANTIEKGEBASEERDE APPROACH
Semantiekgebaseerde methodes gebruiken een documenttaalgebruiksillustratie om een natuurlijk taalgeneratie (NLG) systeem aan te steken. Deze methode verwerkt taalgegevens om naamruimten en werkruimten te identificeren.
- Multimodale semantische model: In deze methode wordt een taalkundig model ontwikkeld dat concepten en relaties tussen ideeën vastlegt om de inhoud van multimodale documenten zoals tekst en afbeeldingen te beschrijven. De belangrijkste ideeën worden beoordeeld aan de hand van verschillende criteria, en de gekozen concepten worden dan uitgedrukt als zinnen om een samenvatting te vormen.
- Informatieitemgebaseerd model: Bij deze aanpak wordt geen gebruik gemaakt van zinnen uit de brondocumenten, maar wordt de abstracte representatie van deze documenten gebruikt om de inhoud van de samenvatting te genereren. De abstracte weergave is een informatieitem, het kleinste deel van een samenhangende informatie in een tekst.
- Semantische Graphmodel: Deze techniek heeft als doel een document samenvatten door een rijke semantische grafiek (RSG) voor het brondocument te maken, deze taalkundige grafiek te reduceren en de uiteindelijke samenvatting vanuit de verkleinde taalkundige grafiek te genereren.
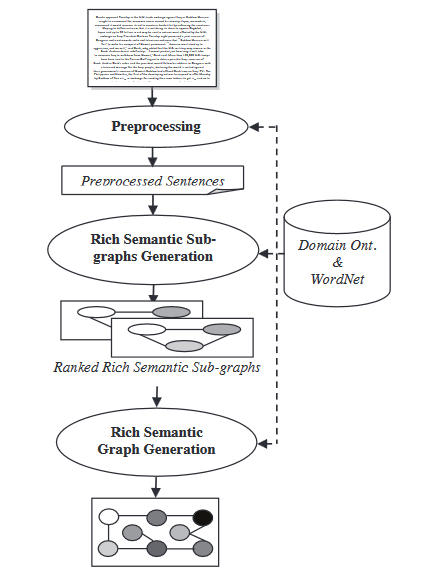
Tijdens het module van de rijke semantische grafiek wordt een set van heuristische regels toegepast op de gegenereerde rijke semantische grafiek om deze te reduceren door samenvoeging, verwijdering of consolidering van de grafieknoden.
- Semantisch tekstmodel: Deze techniek analyseert de ingevoerde tekst door middel van de semantiek van woorden in plaats van de syntaxis/structuur van de tekst.
Case studies in business
- Bedrijfsgerelateerde case studies: Meerdere pogingen zijn ondernomen om AI-technologie ontwikkelen die in staat is om code te schrijven en websites te ontwikkelen zonder menselijke hulp. In de toekomst kunnen programmeurs kunnen opgaan in speciale “code samenvatters” om de kern van nieuwe projecten te ontgrendelen.
- Hulp aan mensen met een lichamelijke beperking: Mensen met hoorproblemen kunnen ontdekken dat een samenvatting hen helpt beter mee te komen met de inhoud, mede dankzij de vooruitgang van stem-naar-tekst technologie.
- Conferenties en andere videovergaderingen: Met de uitbreiding van thuiskantoorwerk, wordt de mogelijkheid om significante ideeën en inhoud uit interacties op te nemen steeds meer nodig. Het zou een wonder zijn als uw teamvergaderingen konden worden samengevat met behulp van stem-naar-tekst methodes.
- Zoeken naar patenten: Het vinden van relevante patentinformatie kan tijdconsumptie zijn. Een patent samenvattinggenerator zou u tijd besparen, of u nu marktintelligentieonderzoek doet of een nieuw patent aanmeldt.
- Boeken en literatuur: Samenvattingen zijn handig omdat ze lezers een korte overzicht van hetgeen ze zullen ontvangen in een boek bieden, voordat ze kiezen of ze het willen aanschaffen.
- Reclame via sociale media: Organisaties die whitepapers, e-boeken en bedrijfspublikaties schrijven kunnen samenvattingen gebruiken om hun werk leesbaarder en delenbaarder te maken op platformen zoals Twitter en Facebook.
- Economieonderzoek: De investeringsbankensector investeert massa’s geld in gegevensaquisitie voor het maken van beslissingen, zoals geautomatiseerde aandelenhandel. Elke financieel analist die de hele dag door marktgegevens en nieuws blijft kijken zal uiteindelijk informatieoverlast bereiken. Financiële documenten, zoals resultatenverslagen en financiële nieuws, kunnen profijt maken van samenvattingssystemen die analisten in staat stellen markt信号 uit de inhoud snel te extraheren.
- Uw bedrijf promoten met ZoekmachineOptimalisatie: Zoekmachineoptimalisatie (SEO) evaluaties vereisen een diepgaande bekendheid met de onderwerpen die in de inhoud van de concurrenten worden besproken. Dit is van cruciale belang gezien Google’s recente algoritme aanpassing en de daaropvolgende nadruk op onderwerpsautoriteit. De mogelijkheid om verschillende documenten snel samenvatten, commonaliteiten vast te stellen en kritische informatie te doorzoeken, kan een krachtige onderzoeksgereedschap zijn.
Conclusie
Hoewel abstractief samenvatten minder betrouwbaar is dan extractief aanpakken, biedt het meer ontzagkelijke beloftes voor het produceren van samenvattingen die overeenkomen met hoe mensen ze zouden schrijven. Daardoor zijn er waarschijnlijk vele nieuwe computationele, cognitieve en taalkundige technieken die in dit gebied zullen ontstaan.
Referenties
Source:
https://www.digitalocean.com/community/tutorials/extractive-and-abstractive-summarization-techniques