













Machine learning (ML) feature stores hebben aandacht en gebruik voor bedrijfskritische toepassingen aangetrokken sinds Uber het concept introduceerde met Michelangelo in 2017. In deze blogpost gaan we in op de basisbeginselen van ML feature stores en onderzoeken waarom en hoe ScyllaDB een kritiek onderdeel van uw feature store-architectuur kan zijn.
Om te begrijpen wat feature stores zijn, is het eerst belangrijk om te begrijpen wat features zijn.
Wat Is Een Feature?
In Machine Learning is een feature een verzameling gegevenspunten die gebruikt kunnen worden om een model te leren en voorspellingen te doen over de toekomst op basis van historische gegevens. Bijvoorbeeld, onze feature store voorbeeldtoepassing stelt je in staat voorspellingen te doen over vluchtvertragingen op basis van historische vluchtgegevens.
Features zijn het resultaat van complexe gegevensverwerkings- en transformatiepijplijnen. Gigantische hoeveelheden featuregegevens maken nauwkeurige voorspellingen en succesvolle machine-learning projecten mogelijk.
Wat Is Een Feature Store?
A feature store is a central database in your machine-learning architecture that contains your real-time and historical features. Feature stores allow your data engineers and data scientists to use the same central repository to discover, monitor, and analyze features.
What does a feature store architecture look like?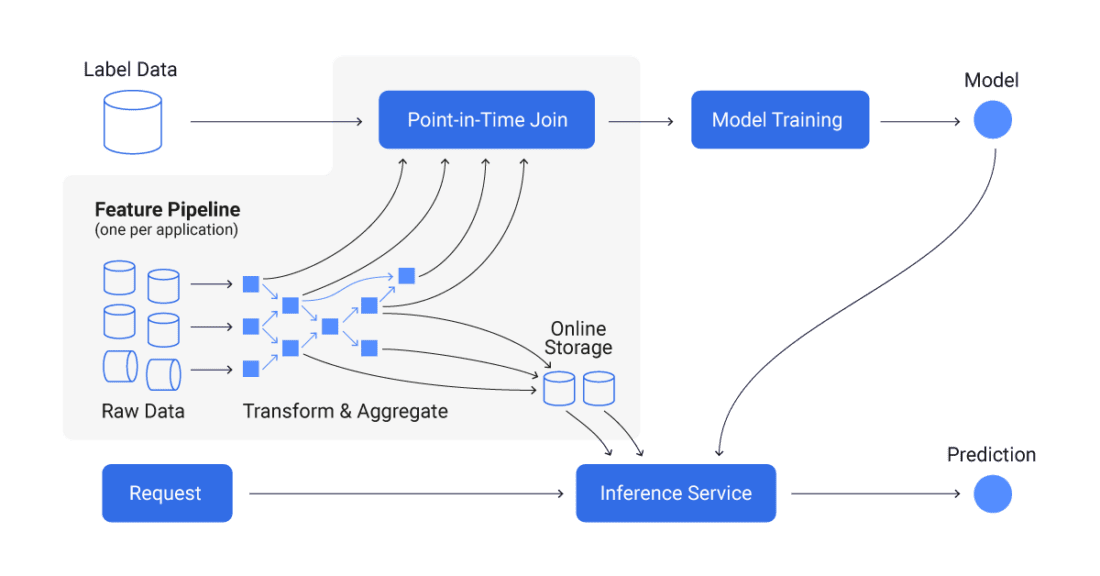
Online en Offline Databases in de Feature Store
Bij het praten over feature stores, onderscheiden gebruikers meestal twee soorten databases in hun architectuur. Aan de ene kant gebruiken ze een online database, en aan de andere kant kunnen ze ook een offline database hebben. Deze databases dienen verschillende doeleinden.
Offline database: Dit soort database slaat historisch verwerkte kenmerken op, meestal in batches geïngepast. Offline databases hebben kenmerkendata die een groot tijdsbestek uit de geschiedenis bestrijken; daarom zijn ze nuttig voor het werken met een set kenmerken in een specifieke periode uit de geschiedenis.
Online database: Deze database kan gegevens bevatten van realtime datastromen en de offline database ook. Online opslag wordt gebruikt om het productiemodel en andere realtime toepassingen te dienen met de meest actuele kenmerkendata. Prestaties en lage latentie zijn hier echt belangrijk. Als uw database niet in staat is om realtime kenmerken snel genoeg te leveren, kan uw model verouderde of onnauwkeurige gegevens gebruiken om voorspellingen te maken.
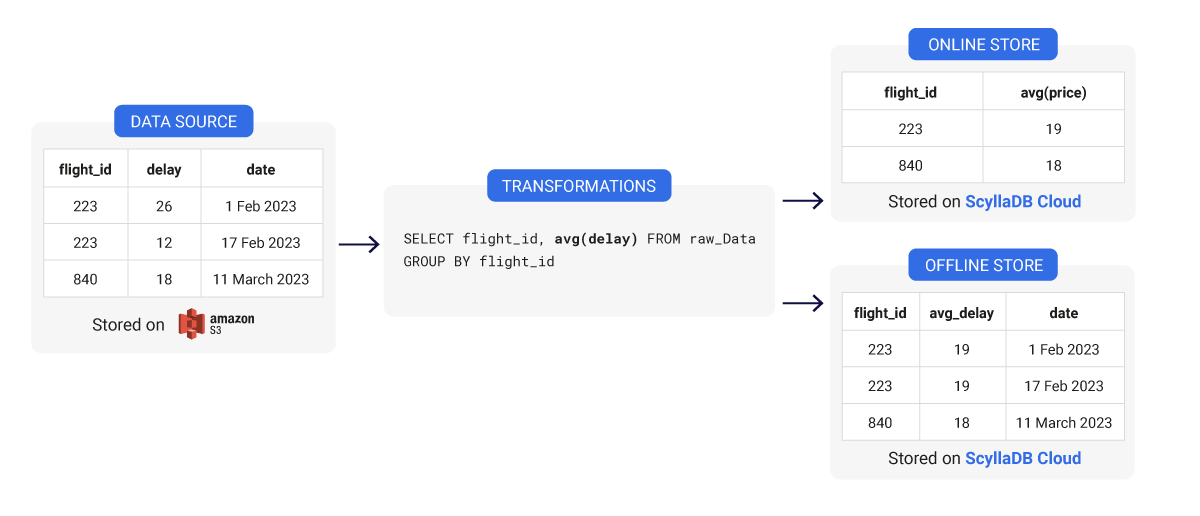
Feature Store Data Modeling: Wide vs. Narrow Table Design
Bij het ontwerpen van de datamodel binnen uw feature store, of het nu een offline of online store is, kunt u kiezen tussen twee soorten tabelontwerpen: breed en smal. Elk heeft zijn eigen voordelen en nadelen. Laten we echte voorbeelden bekijken voor beide en waarom ze misschien wel of niet het beste zijn voor uw gebruiksgeval:
Breed Tabelontwerp
Het breed tabelontwerp bevat afzonderlijke kolommen voor elk kenmerk. Hoe meer soorten kenmerken u in de tabel wilt opslaan, hoe meer kolommen u moet aanmaken.
Breed Tabellayout Voorbeeld
| create table feature_store.wide_example( | |
| date TIMESTAMP, | |
| feature_id INT, | |
| feature_col1 FLOAT, | |
| feature_col2 FLOAT, | |
| feature_col3 FLOAT, | |
| feature_col4 FLOAT, | |
| feature_col5 FLOAT, | |
| feature_col6 FLOAT, | |
| feature_col7 FLOAT | |
| ) |
Dit soort layout kan gemakkelijk aan de slag zijn, maar wordt ook ingewikkelder om te onderhouden en moeilijk te wijzigen. Wanneer u een nieuw kenmerk wilt introduceren (of een bestaand kenmerk wilt laten vallen), moet u het schema wijzigen, wat ingewikkeld kan zijn.
Smal Tabelontwerp
Smalle tafelontwerpen zijn eenvoudig en gemakkelijker te onderhouden. Dit komt omdat het aantal kolommen niet bedoeld is om in de toekomst te veranderen, zelfs als je functies toevoegt of verwijdert.
Voorbeeld van smalle tabelindeling
| create table feature_store.narrow_example( | |
| feature_id INT, | |
| feature_name TEXT, | |
| feature_value FLOAT | |
| ) |
Met deze indeling kun je langetermijn alleen met twee vaste kolommen toe om functies op te slaan. Eén voor de naam van de functie (bijvoorbeeld LATE_AIRCRAFT_DELAY) en één voor de waarde van die functie.
Over het algemeen kunnen smalle tabellen casten vereisen bij het ophalen van gegevens omdat het niet in de juiste vorm is (bijvoorbeeld de kolomtype is FLOAT, maar in werkelijkheid is de gegevenswaarde een INTEGER. Gelukkig, als we het over functiestoren hebben, hebben online en offline stores al de gegevens in de juiste, schone nummer (FLOAT) formaat, en alle waarden hebben hetzelfde gegevenstype, wat betekent dat dit geen nadeel is in het geval van functiestoren.
Wat is ScyllaDB en hoe kan het worden gebruikt in uw functiestore-architectuur?
Om machine learning teams in staat te stellen real-time inferentie toepassingen te bouwen, hebben ze databases nodig die functies op schaal kunnen teruggeven met lage latentie. ScyllaDB is een high-performance, low-latency NoSQL database die hoge volumes van lees- en schrijfoperaties kan verwerken. Bovendien is ScyllaDB een vertrouwde database voor missiekritische functiestore workloads bij bedrijven zoals GE Healthcare of ShareChat. Door zijn hoge beschikbaarheid en fouttolerantie, kan het de zware klus doen in uw infrastructuur waar prestatie en betrouwbaarheid van belang zijn.
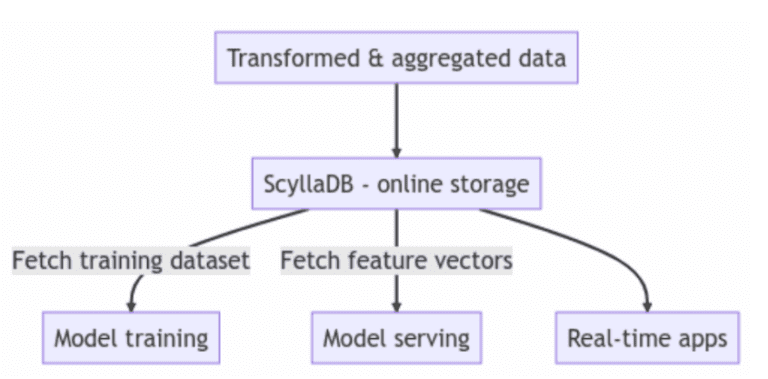
Naast het gebruik van ScyllaDB als online opslag in uw feature store-architectuur, wordt ScyllaDB ook gebruikt als een hybride online/offline opslagoplossing. Met deze aanpak kunt u de onderhoudsbelasting voor uw team verminderen door één database te hebben die al uw feature store-werkbelastingen dient.
Gebruikers plaatsen vaak ScyllaDB in het midden van hun architectuur om functies en feature store metagegevens te bewaren en op te vragen. In dit geval fungeert ScyllaDB als online opslag. Andere gebruikers gebruiken ook ScyllaDB als hun hybride online/offline opslag. Prestaties zijn een belangrijke vereiste om de ontwikkeling van modellen te versnellen, en de lees- en schrijfprestaties van ScyllaDB voldoen consistent aan of overtrefen de verwachtingen van gebruikers.
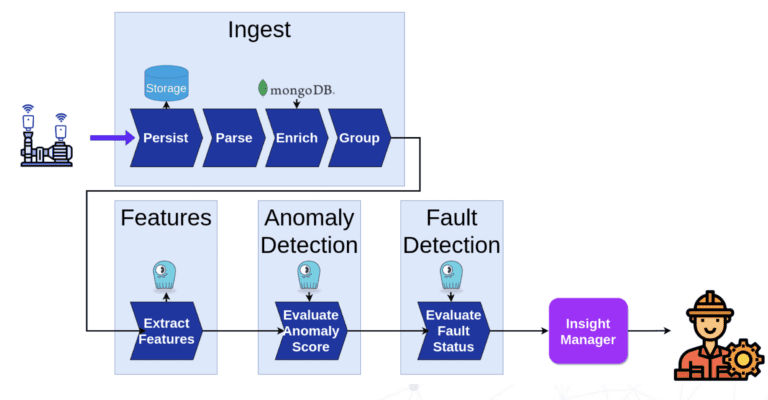
In feite vonden sommige gebruikers dat ScyllaDB meerdere databases kon vervangen en als één centrale opslag kon dienen voor al hun machinaal-leerdatabehoeften. Bijvoorbeeld, ScyllaDB kan Redis (online opslag) en PostgreSQL (offline opslag) vervangen – waardoor infrastructuuronderhoud goedkoper en eenvoudiger wordt.
ScyllaDB komt vooral tot zijn recht in gebruiksvoorbeelden waar u lage latentie en hoge prestaties nodig hebt. Bovendien is ScyllaDB compatibel met Cassandra en DynamoDB, wat betekent dat als u al één van deze databases gebruikt, u soepel kunt migreren zonder uw query’s aan te hoeven passen.
Tutorial: ScyllaDB Online Store
Om u op weg te helpen met ScyllaDB als uw online opslag, hebben we een voorbeeldtoepassing (ook beschikbaar op GitHub) gemaakt.
- Kloon het repository
- Meld u aan voor ScyllaDB Cloud of installeer ScyllaDB lokaal
- Maak de schema:
cqlsh “node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud” 9042 -u scylla -p “password” -f schema.cql - Maak verbinding met de instantie met cqlsh en importeer een voorbeelddataset
cqlsh “node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud” 9042 -u scylla -p “password” scylla@cqlsh> COPY feature_store.flight_features FROM ‘flight_features.csv’;
Deze opdracht neemt een voorbeeldvluchtdataset op:
| op_carrier_fl_num|actual_elapsed_time|air_time|arr_delay|arr_time|cancellation_code|cancelled|carrier_delay|crs_arr_time|crs_dep_time|crs_elapsed_time|dep_delay|dep_time|dest|distance|diverted|fl_date |late_aircraft_delay|nas_delay|op_carrier|origin|security_delay|taxi_in|taxi_out|weather_delay|wheels_off|wheels_on| | |
| —————–+——————-+——–+———+——–+—————–+———+————-+————+————+—————-+———+——–+—-+——–+——–+——————-+——————-+———+———-+——+————–+——-+——–+————-+———-+———+ | |
| 4317| 96.0| 73.0| -19.0| 2113.0| | 0.0| | 2132| 2040| 112.0| -3.0| 2037.0|MLI | 373.0| 0.0|2018-12-31 02:00:00| | |OO |DTW | | 5.0| 18.0| | 2055.0| 2108.0| | |
| 3372| 94.0| 74.0| 81.0| 1500.0| | 0.0| 0.0| 1339| 1150| 109.0| 96.0| 1326.0|RNO | 564.0| 0.0|2018-12-31 02:00:00| 81.0| 0.0|OO |SEA | 0.0| 3.0| 17.0| 0.0| 1343.0| 1457.0| | |
| 1584| 385.0| 348.0| -21.0| 2023.0| | 0.0| | 2034| 1700| 394.0| -9.0| 1658.0|SFO | 2565.0| 0.0|2018-12-31 02:00:00| | |UA |EWR | | 13.0| 33.0| | 1731.0| 2019.0| | |
| 4830| 119.0| 85.0| -35.0| 1431.0| | 0.0| | 1437| 1245| 136.0| -13.0| 1232.0|MSP | 546.0| 0.0|2018-12-31 02:00:00| | |OO |MSP | | 16.0| 18.0| | 1250.0| 1415.0| | |
| 2731| 158.0| 146.0| -19.0| 1911.0| | 0.0| | 1930| 1800| 160.0| -8.0| 1800.0|MSP | 842.0| 0.0|2018-12-31 02:00:00| | |WN |PVD | | 7.0| 7.0| | 1807.0| 1904.0| |
view rawgistfile1.txt hosted with ❤ by GitHub.
ScyllaDB + Feast
ScyllaDB integreert ook met feature store tools zoals Feast. Feast is een populaire open-source feature store voor productie ML. U kunt verschillende databases gebruiken als uw online feature store bij het gebruik van Feast, waaronder ScyllaDB.
Om ScyllaDB in te stellen als een Feast online store, moet u het configuratiebestand van Feast bewerken en uw ScyllaDB referenties toevoegen. ScyllaDB is Cassandra-compatibel, dus u kunt Feast’s ingebouwde Cassandra connector gebruiken.
| # feature_store.yaml | |
| project: scylla_feature_repo | |
| registry: data/registry.db | |
| provider: local | |
| online_store: | |
| type: cassandra | |
| hosts: | |
| – node-0.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| – node-1.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| – node-2.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| keyspace: feast | |
| username: scylla | |
| password: password |
view rawgistfile1.txt hosted with ❤ by GitHub.
Afsluiten
Feature stores zijn noodzakelijk voor feature engineering en het bouwen van machine learning modellen. Als u een real-time feature store infrastructuur aan het bouwen bent, moet u de prestaties goed bekijken. Lage latentie, hoge prestaties en hoge doorvoervereisten maken NoSQL databases tot een perfecte kandidaat als online opslagoplossing in uw feature store.
Source:
https://dzone.com/articles/tutorial-whats-an-aiml-feature-store-and-how-to-bu