













Python Pandas Module
- Pandas is een open source bibliotheek in Python. Het biedt kant-en-klare, high-performance datastructuren en data-analysetools.
- De Pandas-module draait bovenop NumPy en wordt veel gebruikt voor data science en data-analyse.
- NumPy is een low-level datastructuur die multidimensionale arrays ondersteunt en een breed scala aan wiskundige array-operaties. Pandas heeft een interface op een hoger niveau. Het biedt ook gestroomlijnde uitlijning van tabulaire gegevens en krachtige functionaliteit voor tijdreeksen.
- DataFrame is de belangrijkste datastructuur in Pandas. Hiermee kunnen we tabulaire gegevens opslaan en manipuleren als een 2-D datastructuur.
- Pandas biedt een rijke set functies op het DataFrame. Bijvoorbeeld, gegevensuitlijning, gegevensstatistieken, slicing, groeperen, samenvoegen, gegevens concatenaten, enz.
Installeren en aan de slag gaan met Pandas
U moet Python 2.7 en hoger hebben om de Pandas-module te installeren. Als u conda gebruikt, kunt u het installeren met onderstaand commando.
conda install pandas
Als u PIP gebruikt, voert u de onderstaande opdracht uit om de pandas-module te installeren.
pip3.7 install pandas
Om Pandas en NumPy in uw Python-script te importeren, voegt u het onderstaande stukje code toe:
import pandas as pd
import numpy as np
Omdat Pandas afhankelijk is van de NumPy-bibliotheek, moeten we deze afhankelijkheid importeren.
Datastructuren in de Pandas-module
De Pandas-module biedt 3 datastructuren, namelijk:
- Series: Het is een 1-D formaat-onveranderlijke array-achtige structuur met homogene gegevens.
- DataFrames: Het is een 2-D formaat-veranderlijke tabellaire structuur met heterogeen getypeerde kolommen.
- Panel: Het is een 3-D, formaat-veranderlijke array.
Pandas DataFrame
DataFrame is de belangrijkste en meest gebruikte datastructuur en is een standaard manier om gegevens op te slaan. DataFrame heeft gegevens uitgelijnd in rijen en kolommen zoals de SQL-tabel of een spreadsheet-database. We kunnen gegevens hard coderen in een DataFrame of een CSV-bestand, tsv-bestand, Excel-bestand, SQL-tabel, enz. importeren. We kunnen de onderstaande constructor gebruiken voor het maken van een DataFrame-object.
pandas.DataFrame(data, index, columns, dtype, copy)
Hieronder volgt een korte beschrijving van de parameters:
- gegevens – maak een DataFrame-object van de invoergegevens. Het kan een lijst, een dictionary, een serie, Numpy-ndarrays of zelfs een ander DataFrame zijn.
- index – heeft de rijlabels
- kolommen – gebruikt om kolomlabels te maken
- dtype – gebruikt om het gegevenstype van elke kolom aan te geven, optionele parameter
- kopie – gebruikt voor het kopiëren van gegevens, indien aanwezig
Er zijn veel manieren om een DataFrame te maken. We kunnen een DataFrame-object maken van Woordenboeken of lijst van woordenboeken. We kunnen het ook maken van een lijst van tuples, CSV, Excel-bestand, enz. Laten we een eenvoudige code uitvoeren om een DataFrame te maken van de lijst van woordenboeken.
import pandas as pd
import numpy as np
df = pd.DataFrame({
"State": ['Andhra Pradesh', 'Maharashtra', 'Karnataka', 'Kerala', 'Tamil Nadu'],
"Capital": ['Hyderabad', 'Mumbai', 'Bengaluru', 'Trivandrum', 'Chennai'],
"Literacy %": [89, 77, 82, 97,85],
"Avg High Temp(c)": [33, 30, 29, 31, 32 ]
})
print(df)
Uitvoer:  De eerste stap is om een woordenboek te maken. De tweede stap is om het woordenboek door te geven als een argument in de DataFrame() methode. De laatste stap is om de DataFrame af te drukken. Zoals je ziet, kan de DataFrame worden vergeleken met een tabel met heterogene waarden. Ook kan de grootte van de DataFrame worden aangepast. We hebben de gegevens geleverd in de vorm van de map en de sleutels van de map worden door Pandas beschouwd als de rijlabels. De index wordt weergegeven in de meest linkse kolom en heeft de rijlabels. De kolomkop en de gegevens worden weergegeven in een tabelformaat. Het is ook mogelijk om geïndexeerde DataFrames te maken. Dit kan worden gedaan door de indexparameter te configureren in de
De eerste stap is om een woordenboek te maken. De tweede stap is om het woordenboek door te geven als een argument in de DataFrame() methode. De laatste stap is om de DataFrame af te drukken. Zoals je ziet, kan de DataFrame worden vergeleken met een tabel met heterogene waarden. Ook kan de grootte van de DataFrame worden aangepast. We hebben de gegevens geleverd in de vorm van de map en de sleutels van de map worden door Pandas beschouwd als de rijlabels. De index wordt weergegeven in de meest linkse kolom en heeft de rijlabels. De kolomkop en de gegevens worden weergegeven in een tabelformaat. Het is ook mogelijk om geïndexeerde DataFrames te maken. Dit kan worden gedaan door de indexparameter te configureren in de DataFrame() methode.
Gegevens importeren van CSV naar DataFrame
We kunnen ook een DataFrame maken door een CSV-bestand te importeren. Een CSV-bestand is een tekstbestand met één gegevensrecord per regel. De waarden binnen het record zijn gescheiden door het “komma” teken. Pandas biedt een handige methode, genaamd read_csv(), om de inhoud van het CSV-bestand in een DataFrame te lezen. Bijvoorbeeld, we kunnen een bestand met de naam ‘steden.csv’ maken met details van Indiase steden. Het CSV-bestand wordt opgeslagen in dezelfde directory als de Python-scripts. Dit bestand kan worden geïmporteerd met behulp van:
import pandas as pd
data = pd.read_csv('cities.csv')
print(data)
. Ons doel is om gegevens te laden en te analyseren om conclusies te trekken. Dus, we kunnen elke handige methode gebruiken om de gegevens te laden. In deze tutorial coderen we de gegevens van het DataFrame hard.
Gegevens inspecteren in DataFrame
Het uitvoeren van het DataFrame met behulp van zijn naam geeft de volledige tabel weer. In realtime zullen de te analyseren datasets duizenden rijen bevatten. Voor het analyseren van gegevens moeten we gegevens inspecteren uit enorme hoeveelheden datasets. Pandas biedt veel handige functies om alleen de gegevens te inspecteren die we nodig hebben. We kunnen df.head(n) gebruiken om de eerste n rijen te krijgen of df.tail(n) om de laatste n rijen af te drukken. Bijvoorbeeld, de onderstaande code drukt de eerste 2 rijen en de laatste 1 rij uit het DataFrame af.
print(df.head(2))
Output: 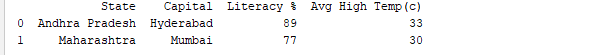
print(df.tail(1))
Output: 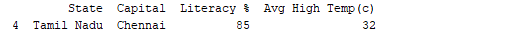 Op dezelfde manier,
Op dezelfde manier, print(df.dtypes) drukt de datatypen af. Output: 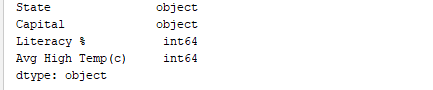
print(df.index) drukt de index af. Output: 
print(df.columns) drukt de kolommen van het DataFrame af. Output: 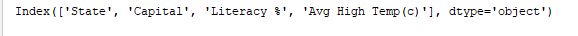
print(df.values) geeft de tabelwaarden weer. Output: 
1. Het verkrijgen van statistische samenvatting van records
We kunnen een statistische samenvatting (aantal, gemiddelde, standaarddeviatie, min, max, enz.) van de gegevens krijgen met behulp van de df.describe()-functie. Laten we nu deze functie gebruiken om de statistische samenvatting van de kolom “Geletterdheid %” weer te geven. Om dit te doen, kunnen we de onderstaande code toevoegen:
print(df['Literacy %'].describe())
Output: 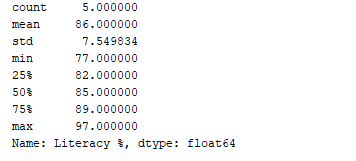 De
De df.describe()-functie geeft de statistische samenvatting weer, samen met het gegevenstype.
2. Records sorteren
We kunnen records sorteren op elke kolom met behulp van de df.sort_values()-functie. Bijvoorbeeld, laten we de kolom “Geletterdheid %” sorteren in aflopende volgorde.
print(df.sort_values('Literacy %', ascending=False))
Output: 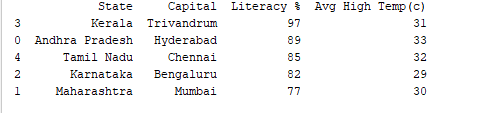
3. Records slicen
Het is mogelijk om gegevens van een bepaalde kolom te extraheren door de kolomnaam te gebruiken. Bijvoorbeeld, om de kolom ‘Hoofdstad’ te extraheren, gebruiken we:
df['Capital']
of
(df.Capital)
Uitvoer:  Het is ook mogelijk om meerdere kolommen te selecteren. Dit wordt gedaan door meerdere kolomnamen in te sluiten in 2 vierkante haken, waarbij de kolomnamen gescheiden zijn door komma’s. De volgende code selecteert de kolommen ‘State’ en ‘Capital’ van de DataFrame.
Het is ook mogelijk om meerdere kolommen te selecteren. Dit wordt gedaan door meerdere kolomnamen in te sluiten in 2 vierkante haken, waarbij de kolomnamen gescheiden zijn door komma’s. De volgende code selecteert de kolommen ‘State’ en ‘Capital’ van de DataFrame.
print(df[['State', 'Capital']])
Uitvoer:  Het is ook mogelijk om rijen te selecteren. Meerdere rijen kunnen worden geselecteerd met de “:” operator. De onderstaande code geeft de eerste 3 rijen terug.
Het is ook mogelijk om rijen te selecteren. Meerdere rijen kunnen worden geselecteerd met de “:” operator. De onderstaande code geeft de eerste 3 rijen terug.
df[0:3]
Uitvoer:  Een interessante functie van de Pandas-bibliotheek is het selecteren van gegevens op basis van de rij- en kolomlabels met behulp van de
Een interessante functie van de Pandas-bibliotheek is het selecteren van gegevens op basis van de rij- en kolomlabels met behulp van de iloc[0] functie. Vaak hebben we misschien slechts enkele kolommen nodig om te analyseren. We kunnen ook selecteren op index met behulp van loc['index_one']). Bijvoorbeeld, om de tweede rij te selecteren, kunnen we df.iloc[1,:] gebruiken. Laten we zeggen dat we het tweede element van de tweede kolom moeten selecteren. Dit kan worden gedaan met de functie df.iloc[1,1]. In dit voorbeeld geeft de functie df.iloc[1,1] “Mumbai” als uitvoer.
4. Gegevens filteren
Het is ook mogelijk om te filteren op kolomwaarden. Bijvoorbeeld, de onderstaande code filtert de kolommen met een Geletterdheid% boven 90%.
print(df[df['Literacy %']>90])
Elke vergelijkingsoperator kan worden gebruikt om te filteren op basis van een voorwaarde. Output:  Een andere manier om gegevens te filteren, is door gebruik te maken van de
Een andere manier om gegevens te filteren, is door gebruik te maken van de isin-functie. Hieronder staat de code om alleen de staten ‘Karnataka’ en ‘Tamil Nadu’ te filteren.
print(df[df['State'].isin(['Karnataka', 'Tamil Nadu'])])
Output: 
5. Kolom hernoemen
Het is mogelijk om de df.rename()-functie te gebruiken om een kolom te hernoemen. De functie neemt de oude kolomnaam en de nieuwe kolomnaam als argumenten. Bijvoorbeeld, laten we de kolom ‘Literacy %’ hernoemen naar ‘Literacy percentage’.
df.rename(columns = {'Literacy %':'Literacy percentage'}, inplace=True)
print(df.head())
Het argument `inplace=True` zorgt ervoor dat de wijzigingen in het DataFrame worden aangebracht. Output: 
6. Gegevensmanipulatie
Data Science houdt zich bezig met het verwerken van gegevens zodat de gegevens goed kunnen samenwerken met de gegevensalgoritmen. Data Wrangling is het proces van het verwerken van gegevens, zoals samenvoegen, groeperen en concatenatie. De Pandas-bibliotheek biedt handige functies zoals merge(), groupby() en concat() om Data Wrangling-taken te ondersteunen. Laten we 2 DataFrames maken en de Data Wrangling-functies tonen om het beter te begrijpen.
import pandas as pd
d = {
'Employee_id': ['1', '2', '3', '4', '5'],
'Employee_name': ['Akshar', 'Jones', 'Kate', 'Mike', 'Tina']
}
df1 = pd.DataFrame(d, columns=['Employee_id', 'Employee_name'])
print(df1)
Output:  Laten we het tweede DataFrame maken met de onderstaande code:
Laten we het tweede DataFrame maken met de onderstaande code:
import pandas as pd
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Tia', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data, columns=['Employee_id', 'Employee_name'])
print(df2)
Output: 
a. Merging
Laten we nu de 2 DataFrames die we hebben gemaakt samenvoegen, langs de waarden van ‘Employee_id’ met behulp van de merge()-functie:
print(pd.merge(df1, df2, on='Employee_id'))
Output:  We zien dat de merge() functie de rijen teruggeeft van zowel de DataFrames met dezelfde kolomwaarde die is gebruikt tijdens het samenvoegen.
We zien dat de merge() functie de rijen teruggeeft van zowel de DataFrames met dezelfde kolomwaarde die is gebruikt tijdens het samenvoegen.
b. Grouping
Groeperen is een proces van het verzamelen van gegevens in verschillende categorieën. Bijvoorbeeld, in het onderstaande voorbeeld heeft het veld “Employee_Name” de naam “Meera” twee keer. Laten we het groeperen op de kolom “Employee_name”.
import pandas as pd
import numpy as np
data = {
'Employee_id': ['4', '5', '6', '7', '8'],
'Employee_name': ['Meera', 'Meera', 'Varsha', 'Williams', 'Ziva']
}
df2 = pd.DataFrame(data)
group = df2.groupby('Employee_name')
print(group.get_group('Meera'))
Het veld ‘Employee_name’ met de waarde ‘Meera’ wordt gegroepeerd op de kolom “Employee_name”. Het voorbeelduitvoer is als volgt: Output: 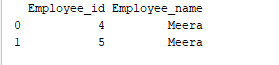
c. Concatenating
Het samenvoegen van gegevens houdt in dat je één set gegevens toevoegt aan een andere. Pandas biedt een functie genaamd `concat()` om DataFrames samen te voegen. Bijvoorbeeld, laten we de DataFrames `df1` en `df2` samenvoegen, met behulp van:
“`python
pd.concat([df1, df2])
“`
print(pd.concat([df1, df2]))
Uitvoer:

Maak een DataFrame door een Dictionary van Series door te geven
Om een Serie te maken, kunnen we de methode `pd.Series()` gebruiken en er een array aan doorgeven. Laten we een eenvoudige Serie maken zoals volgt:
“`python
s = pd.Series([1, 2, 3, 4, 5])
“`
series_sample = pd.Series([100, 200, 300, 400])
print(series_sample)
Uitvoer:

We hebben een Serie gemaakt. Je kunt zien dat er 2 kolommen worden weergegeven. De eerste kolom bevat de indexwaarden die beginnen bij 0. De tweede kolom bevat de elementen die als Serie zijn doorgegeven. Het is mogelijk om een DataFrame te maken door een dictionary van `Series` door te geven. Laten we een DataFrame maken die wordt gevormd door de indexen van de series samen te voegen en door te geven.
Voorbeeld:
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df)
Voorbeelduitvoer
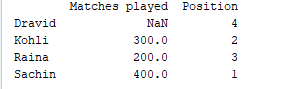
Voor serie één, omdat we label ‘d’ niet hebben gespecificeerd, wordt NaN geretourneerd.
Kolomselectie, Toevoeging, Verwijdering
Het is mogelijk om een specifieke kolom uit het DataFrame te selecteren. Bijvoorbeeld, om alleen de eerste kolom weer te geven, kunnen we de bovenstaande code herschrijven als:
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
print(df['Matches played'])
De bovenstaande code geeft alleen de kolom “Wedstrijden gespeeld” van het DataFrame weer. Uitvoer 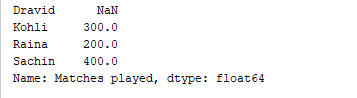 Het is ook mogelijk om kolommen toe te voegen aan een bestaand DataFrame. Bijvoorbeeld, de onderstaande code voegt een nieuwe kolom met de naam “Runrate” toe aan het bovenstaande DataFrame.
Het is ook mogelijk om kolommen toe te voegen aan een bestaand DataFrame. Bijvoorbeeld, de onderstaande code voegt een nieuwe kolom met de naam “Runrate” toe aan het bovenstaande DataFrame.
d = {'Matches played' : pd.Series([400, 300, 200], index=['Sachin', 'Kohli', 'Raina']),
'Position' : pd.Series([1, 2, 3, 4], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])}
df = pd.DataFrame(d)
df['Runrate']=pd.Series([80, 70, 60, 50], index=['Sachin', 'Kohli', 'Raina', 'Dravid'])
print(df)
Uitvoer:  We kunnen kolommen verwijderen met behulp van de `delete` en `pop` functies. Bijvoorbeeld, om de kolom ‘Wedstrijden gespeeld’ in het bovenstaande voorbeeld te verwijderen, kunnen we het op een van de onderstaande twee manieren doen:
We kunnen kolommen verwijderen met behulp van de `delete` en `pop` functies. Bijvoorbeeld, om de kolom ‘Wedstrijden gespeeld’ in het bovenstaande voorbeeld te verwijderen, kunnen we het op een van de onderstaande twee manieren doen:
del df['Matches played']
of
df.pop('Matches played')
Uitvoer: 
Conclusie
In deze tutorial hebben we een korte introductie gehad tot de Python Pandas-bibliotheek. We hebben ook praktische voorbeelden gedaan om de kracht van de Pandas-bibliotheek die wordt gebruikt in het veld van data science te ontketenen. We zijn ook door verschillende gegevensstructuren in de Python-bibliotheek gegaan. Referentie: Officiële website van Pandas
Source:
https://www.digitalocean.com/community/tutorials/python-pandas-module-tutorial