













Als je een Azure DevOps Pipeline hebt gebouwd als oplossing voor een CI/CD-pijplijn, ben je ongetwijfeld situaties tegengekomen waarin het dynamisch beheren van configuratiewaarden in builds en releases vereist is. Of het nu gaat om het verstrekken van een buildversie aan een PowerShell-script, het doorgeven van dynamische parameters aan buildtaken of het gebruiken van teksten in builds en releases, je hebt variabelen nodig.
Als je jezelf ooit hebt afgevraagd:
- Hoe gebruik ik Azure DevOps build Pipeline-variabelen in een PowerShell-script?
- Hoe deel ik variabelen tussen builds en releases?
- Hoe verschillen vooraf gedefinieerde, door de gebruiker gedefinieerde en geheime variabelen van elkaar?
- Hoe werken variabelengroepen?
…dan heb je geluk! In dit artikel zullen we elk van deze vragen en meer beantwoorden.
Tegen het einde van dit artikel zul je begrijpen hoe Azure DevOps build-variabelen werken in Azure Pipelines!
Wat zijn Azure DevOps Pipeline-variabelen?
Voordat we ingaan op de details van variabelen, wat zijn ze en hoe helpen ze je bij het bouwen en automatiseren van efficiënte build- en releasepijplijnen?
Variabelen stellen je in staat om stukjes gegevens door verschillende delen van je pijplijnen te sturen. Variabelen zijn ideaal voor het opslaan van tekst en cijfers die kunnen veranderen in de workflow van een pijplijn. In een pijplijn kun je variabelen bijna overal instellen en lezen, in plaats van waarden hard coderen in scripts en YAML-definities.
Let op: Dit artikel zal zich alleen richten op YAML-pipelines. We zullen geen informatie behandelen over legacy-classic-pipelines. Ook zul je, met een paar kleine uitzonderingen, niet leren hoe je met variabelen werkt via de web-UI. We houden ons strikt aan YAML.
Variabelen worden tijdens runtime gerefereerd en sommige worden gedefinieerd (zie door de gebruiker gedefinieerde variabelen). Wanneer een pipeline een taak start, beheren verschillende processen deze variabelen en geven hun waarden door aan andere delen van het systeem. Dit systeem biedt een manier om pipeline-taken dynamisch uit te voeren zonder je zorgen te maken over het wijzigen van build-definities en scripts telkens wanneer dit nodig is.
Maak je geen zorgen als je het concept van variabelen op dit moment niet helemaal begrijpt. De rest van dit artikel leert je alles wat je moet weten.
Variabele omgevingen
Voordat we ingaan op de variabelen zelf, is het eerst belangrijk om de variabele omgevingen van Azure Pipeline te behandelen. Je zult gedurende het artikel verschillende verwijzingen naar deze term zien.
Binnen een pipeline zijn er twee informeel genoemde omgevingen waarin je met variabelen kunt werken. Je kunt ofwel met variabelen werken binnen een YAML-builddefinitie, genaamd de pipeline-omgeving, of binnen een script dat wordt uitgevoerd via een taak genaamd de script-omgeving.
De Pipeline Omgeving
Wanneer je build-variabelen definieert of leest vanuit een YAML-builddefinitie, wordt dit de pipeline-omgeving genoemd. Hieronder zie je bijvoorbeeld de variabelen-sectie gedefinieerd in een YAML-builddefinitie, waarin een variabele genaamd foo is ingesteld op bar. In deze context wordt de variabele gedefinieerd binnen de pipeline-omgeving
De Script Omgeving
Je kunt ook werken met variabelen vanuit code die is gedefinieerd in de YAML-definitie zelf of in scripts. Wanneer je nog geen bestaand script hebt, kun je variabelen definiëren en lezen binnen de YAML-definitie, zoals hieronder getoond. Je leert later de syntaxis om met deze variabelen in deze context te werken.
Je kunt er ook voor kiezen om binnen de scriptomgeving te blijven door dezelfde syntaxis toe te voegen aan een Bash-script en het uit te voeren. Dit is hetzelfde algemene concept.
Omgevingsvariabelen
Binnen de scriptomgeving, wanneer een pipeline-variabele beschikbaar wordt gesteld, gebeurt dit door een omgevingsvariabele te creëren. Deze omgevingsvariabelen kunnen vervolgens worden benaderd via de gebruikelijke methoden van de gekozen programmeertaal.
Pipeline-variabelen die worden blootgesteld als omgevingsvariabelen, zullen altijd in hoofdletters zijn en eventuele punten worden vervangen door underscores. Zoals hieronder te zien is, kan elke scripttaal toegang krijgen tot de foo pipeline-variabele.
- Batch –
%FOO% - PowerShell –
$env:FOO - Bash-script –
$FOO
Pipeline “Uitvoeringsfasen”
Wanneer een pipeline “loopt”, loopt deze niet zomaar. Net als de stages die het bevat, doorloopt een pipeline ook verschillende fasen wanneer deze wordt uitgevoerd. Vanwege het ontbreken van een officiële term in de Microsoft-documentatie, noem ik dit “uitvoeringsfasen”.
Wanneer een pipeline wordt geactiveerd, doorloopt deze drie ruwe fasen – Wachtrij, Compileren en Uitvoeren. Het is belangrijk om deze contexten te begrijpen, want als je door de Microsoft-documentatie navigeert, zie je verwijzingen naar deze termen.
Wachttijd
De eerste fase waar een pipeline doorheen gaat wanneer deze in de wachtrij staat. In deze fase is de pipeline nog niet gestart, maar staat deze in de wachtrij en is klaar om te starten wanneer de agent beschikbaar is. Bij het definiëren van variabelen kun je instellen dat ze beschikbaar worden gesteld bij het wachten door ze niet te definiëren in het YAML-bestand.
Je kunt variabelen definiëren bij het wachten wanneer de pipeline in eerste instantie in de wachtrij staat, zoals hieronder wordt getoond. Wanneer deze variabele is toegevoegd, wordt deze vervolgens beschikbaar gesteld als een wereldwijde variabele in de pipeline en kan deze worden overschreven door dezelfde variabelenaam in het YAML-bestand.
Compileren
Uiteindelijk, wanneer een pijplijn een YAML-bestand verwerkt en bij de stappen komt die scriptuitvoering vereisen, bevindt de pijplijn zich in de “compile” fase. In deze context voert de agent de code uit die is gedefinieerd in de scriptstappen.
Runtime
De volgende fase is runtime. Dit is de fase waarin het YAML-bestand wordt verwerkt. Tijdens deze fase worden elke fase, taak en stap verwerkt maar niet worden er scripts uitgevoerd.
Variabele Uitbreiding
Nog een belangrijk onderwerp om te begrijpen is variabele uitbreiding. Variabele uitbreiding, in de eenvoudigste bewoordingen, is wanneer de variabele een statische waarde retourneert. De variabele breidt uit om de waarde te onthullen die deze vasthoudt. Dit gebeurt automatisch wanneer je een variabele leest, maar die uitbreiding kan op verschillende momenten tijdens een pijplijnrun worden uitgevoerd, wat verwarrend kan zijn.
Dit concept van variabele uitbreiding en compileer versus runtime zal vaak naar voren komen wanneer je de syntaxis van variabelen begrijpt.
Zoals je hierboven hebt geleerd, doorloopt de pijplijn verschillende “fasen” wanneer deze wordt uitgevoerd. Je moet waarschijnlijk op de hoogte zijn van deze fasen bij het oplossen van problemen met variabele uitbreiding.
Je kunt hieronder een voorbeeld zien. Het concept van deze “fasen” is nauw verbonden met variabele omgevingen.
Variabelen worden eenmaal uitgebreid wanneer de uitvoering van de pijplijn wordt gestart, en opnieuw aan het begin van elke stap. Hieronder zie je een eenvoudig voorbeeld van dit gedrag.
Variabele Syntax
Zoals je hebt geleerd, kun je variabelen instellen of lezen in twee “omgevingen” – de pijplijn- en scriptomgevingen. Terwijl je in elke omgeving bent, is de manier waarop je naar variabelen verwijst een beetje anders. Er zijn nogal wat nuances waar je op moet letten.
Pijplijnvariabelen
Pijplijnvariabelen worden gerefereerd in de YAML-builddefinities en kunnen worden benaderd via drie verschillende syntactische methoden – macro, sjabloonexpressie en runtime-expressie.
Macro-syntaxis
De meest voorkomende syntaxis die je zult vinden, is macro-syntaxis. Macro-syntaxis verwijst naar een waarde voor een variabele in de vorm van $(foo). De haakjes vertegenwoordigen een expressie die wordt geëvalueerd tijdens runtime.
Wanneer Azure Pipelines een variabele verwerkt die is gedefinieerd als een macro-expressie, zal het de expressie vervangen door de inhoud van de variabele. Bij het definiëren van variabelen met macro-syntaxis volgen ze het patroon <variabelenaam>: $(<variabelewaarde>), bijv. foo: $(bar).
Als je probeert een variabele met macro-syntaxis te verwijzen en de waarde bestaat niet, zal de variabele eenvoudigweg niet bestaan. Dit gedrag verschilt een beetje tussen syntypen.
Sjabloonexpressie-syntaxis
Een ander soort variabele syntax wordt een sjabloonexpressie genoemd. Het definiëren van pipeline-variabelen op deze manier ziet eruit als ${{ variabelen.foo }} : ${{ variabelen.bar }}. Zoals je kunt zien, is het iets langer dan de macro-syntaxis.
Sjabloonexpressie-syntaxis heeft ook een toegevoegde functie. Met deze syntaxis kun je ook sjabloonparameters uitbreiden. Als een variabele die is gedefinieerd met de syntaxis van sjabloonaanduiding wordt aangeroepen, geeft de pipeline een lege string terug in plaats van een nulwaarde met de macro-syntaxis.
Sjabloonexpressievariabelen worden tijdens de compilatie verwerkt en vervolgens overschreven (indien gedefinieerd) tijdens runtime.
Runtime Expressie Syntaxis
Als syntaxistype worden voorgestelde runtime expressievariabelen alleen uitgebreid tijdens runtime. Deze soorten variabelen worden weergegeven via het formaat $[variabelen.foo]. Net als variabelen met sjabloonaanduiding retourneren deze types variabelen een lege string als ze niet worden vervangen.
Net als bij macro-syntaxis vereist runtime-expressiesyntaxis de variabelenaam aan de linkerkant van de definitie, zoals foo: $[variabelen.bar].
Scriptvariabelen
Werken met variabelen binnen scripts verschilt enigszins van pipeline-variabelen. Het definiëren en verwijzen naar pipeline-variabelen die zijn blootgesteld in taakscripts kan op twee manieren worden gedaan; met logcommando-syntaxis of omgevingsvariabelen.
Logging Commands
Een manier om pipeline-variabelen in scripts te definiëren en ernaar te verwijzen, is door gebruik te maken van de syntaxis van logboekopdrachten. Deze syntaxis is wat ingewikkeld, maar je zult merken dat het nodig is in bepaalde situaties. Variabelen die op deze manier worden gedefinieerd, moeten als een tekenreeks in het script worden gedefinieerd.
Het instellen van een variabele genaamd foo met een waarde van bar met behulp van de syntaxis van logboekopdrachten zou er als volgt uitzien.
I could not find a way to get the value of variables using logging commands. If this exists, let me know!
Omgevingsvariabelen
Wanneer pipeline-variabelen worden omgezet in omgevingsvariabelen in scripts, worden de variabelennamen iets gewijzigd. Je zult merken dat variabelennamen hoofdletters krijgen en punten worden omgezet in underscores. Je zult zien dat veel vooraf gedefinieerde of systeemvariabelen punten bevatten.
Als bijvoorbeeld een pipeline-variabele genaamd [foo.bar](<http://foo.bar>) is gedefinieerd, zou je die variabele verwijzen via de native omgevingsvariabelenverwijzingsmethode van het script, zoals $env:FOO_BAR in PowerShell of $FOO_BAR in Bash.
We hebben meer over omgevingsvariabelen behandeld in de Scriptomgeving-sectie hierboven.
Variabele Scope
A pipeline has various stages, tasks and jobs running. Many areas have predefined variable scopes. A scope is namespace where when a variable is defined, its value can be referenced.
Er zijn in wezen drie verschillende variabelenbereiken in een hiërarchie. Ze zijn variabelen gedefinieerd op:
- het rootniveau waardoor variabelen beschikbaar zijn voor alle taken in de pipeline
- het stageniveau waardoor variabelen beschikbaar zijn voor een specifiek stadium
- het takenniveau waardoor variabelen beschikbaar zijn voor een specifieke taak
Variabelen die op “lagere” niveaus zijn gedefinieerd, zoals een taak, zullen variabelen met dezelfde naam overschrijven die op het stadium- en rootniveau zijn gedefinieerd. Bijvoorbeeld, variabelen die op het stadiumniveau zijn gedefinieerd, zullen variabelen overschrijven die op het “root” niveau zijn gedefinieerd, maar zelf worden overschreven door variabelen die op het taakniveau zijn gedefinieerd.
Hieronder kunt u een voorbeeld zien van een YAML-builddefinitie waarin elke scope wordt gebruikt.
Variabele voorrang
Soms zult u een situatie zien waarin een variabele met dezelfde naam wordt ingesteld in verschillende scopes. In dit geval wordt de waarde van die variabele overschreven volgens een specifieke volgorde, waarbij de hoogste prioriteit wordt gegeven aan de dichtstbijzijnde “actie”.
Hieronder ziet u de volgorde waarin de variabelen worden overschreven, te beginnen met een variabele die is ingesteld binnen een taak. Deze heeft de hoogste prioriteit.
- Variabele ingesteld op taakniveau (ingesteld in het YAML-bestand)
- Variabele ingesteld op stadiumniveau (ingesteld in het YAML-bestand)
- Variabele ingesteld op pijplijnniveau (globaal) (ingesteld in het YAML-bestand)
- Variabele ingesteld op wachttijd
- Pijplijnvariabele ingesteld in de gebruikersinterface van Pijplijninstellingen
Bijvoorbeeld, kijk naar de onderstaande YAML-definitie. In dit voorbeeld wordt dezelfde variabele op veel verschillende plaatsen ingesteld, maar eindigt uiteindelijk met de waarde die in de taak is gedefinieerd. Bij elke actie wordt de waarde van de variabele overschreven terwijl de pijplijn bij de taak komt.
Variabele Types
Je hebt geleerd wat variabelen zijn, hoe ze eruit zien, in welke contexten ze uitgevoerd kunnen worden en nog veel meer in dit artikel. Maar wat we nog niet hebben besproken, is dat niet alle variabelen gelijk zijn. Sommige variabelen bestaan al wanneer een pijplijn start en kunnen niet worden veranderd, terwijl je andere kunt maken, veranderen en verwijderen naar believen.
Er zijn vier algemene soorten variabelen – vooraf gedefinieerde of systeemvariabelen, door de gebruiker gedefinieerde variabelen, uitvoervariabelen en geheime variabelen. Laten we elk van deze behandelen en elk type variabele begrijpen.
Vooraf gedefinieerde Variabelen
Binnen alle builds en releases vind je veel verschillende variabelen die standaard bestaan. Deze variabelen worden vooraf gedefinieerd of systeem variabelen genoemd. Vooraf gedefinieerde variabelen zijn allemaal alleen-lezen en, zoals andere soorten variabelen, vertegenwoordigen ze eenvoudige strings en getallen.
Een Azure pijplijn bestaat uit veel componenten, van de software agent die de build uitvoert, taken die worden opgestart wanneer een deployment draait en andere diverse informatie. Om al deze gebieden te vertegenwoordigen, worden vooraf gedefinieerde of systeemvariabelen informeel opgesplitst in vijf verschillende categorieën:
- Agent
- Build
- Pipeline
- Implementatie taak
- Systeem
Er zijn tientallen variabelen verspreid over elk van deze vijf categorieën. Je zult niet over allemaal leren in dit artikel. Als je een lijst wilt van alle vooraf gedefinieerde variabelen, kijk dan naar de Microsoft-documentatie.
Gebruikersgedefinieerde variabelen
Wanneer je een variabele aanmaakt in een YAML-definitie of via een script, creëer je een gebruikersgedefinieerde variabele. Gebruikersgedefinieerde variabelen zijn eenvoudigweg alle variabelen die jij, de gebruiker, definieert en gebruikt in een pijplijn. Je kunt voor deze variabelen bijna elke naam gebruiken die je wilt, met een paar uitzonderingen.
Je kunt geen variabelen definiëren die beginnen met het woord endpoint, input, secret, of securefile. Deze labels zijn verboden omdat ze zijn gereserveerd voor systeemgebruik en hoofdletteronafhankelijk zijn.
Bovendien moeten eventuele door jou gedefinieerde variabelen alleen bestaan uit letters, cijfers, punten of underscores. Als je probeert een variabele te definiëren die niet aan dit formaat voldoet, zal je YAML-builddefinitie niet werken.
Uitvoervariabelen
A build definition contains one or more tasks. Sometimes a task sends a variable out to be made available to downstream steps and jobs within the same stage. These types of variables are called output variables.
Uitvoervariabelen worden gebruikt om informatie te delen tussen componenten van de pijplijn. Bijvoorbeeld, als één taak een waarde uit een database opvraagt en daaropvolgende taken het resultaat nodig hebben, kan een uitvoervariabele worden gebruikt. Je hoeft dan niet elke keer de database te bevragen. In plaats daarvan kun je eenvoudig verwijzen naar de variabele.
Let op: Uitvoervariabelen zijn beperkt tot een specifieke fase. Verwacht niet dat een uitvoervariabele beschikbaar is in zowel uw “build” fase als uw “test” fase, bijvoorbeeld.
Geheime Variabelen
Het laatste type variabele is de geheime variabele. Technisch gezien is dit niet een op zichzelf staand type omdat het een systeem- of door de gebruiker gedefinieerde variabele kan zijn. Maar geheime variabelen moeten in hun eigen categorie vallen omdat ze anders behandeld worden dan andere variabelen.
A secret variable is a standard variable that’s encrypted. Secret variables typically contain sensitive information like API keys, passwords, etc. These variables are encrypted at rest with a 2048-bit RSA key and are available on the agent for all tasks and scripts to use.
– Definieer GEEN geheime variabelen in uw YAML-bestanden
– Geef geheimen NIET terug als uitvoervariabelen of inloginformatie
Geheime variabelen moeten worden gedefinieerd in de pipeline-editor. Dit beperkt geheime variabelen op het wereldwijde niveau, waardoor ze beschikbaar zijn voor taken in de pipeline.
Geheime waarden worden gemaskeerd in de logs, maar niet volledig. Daarom is het belangrijk om ze niet op te nemen in een YAML-bestand. U moet ook weten dat u geen “gestructureerde” gegevens als een geheim moet opnemen. Als bijvoorbeeld { "foo": "bar" } als geheim is ingesteld, wordt bar niet gemaskeerd in de logs.
Geheimen worden niet automatisch gedecodeerd en toegewezen aan omgevingsvariabelen. Als u bijvoorbeeld een geheime variabele definieert, verwacht dan niet dat deze beschikbaar is via
$env:FOOin een PowerShell-script, bijvoorbeeld.
Variabelegroepen
Tenslotte komen we bij variabelegroepen. Variabelegroepen zijn, zoals u zou verwachten, “groepen” van variabelen die als één kunnen worden gerefereerd. Het belangrijkste doel van een variabelegroep is het opslaan van waarden die u beschikbaar wilt maken over meerdere pipelines.
In tegenstelling tot variabelen worden variabelengroepen niet gedefinieerd in het YAML-bestand. In plaats daarvan worden ze gedefinieerd op de pagina Bibliotheek onder Pipelines in de UI.
Gebruik een variabelengroep om waarden op te slaan die u wilt beheren en beschikbaar wilt maken in meerdere pipelines. U kunt variabelengroepen ook gebruiken om geheimen en andere waarden op te slaan die mogelijk moeten worden doorgegeven aan een YAML-pipeline. Variabelengroepen worden gedefinieerd en beheerd op de pagina Bibliotheek onder Pipelines zoals hieronder wordt weergegeven.
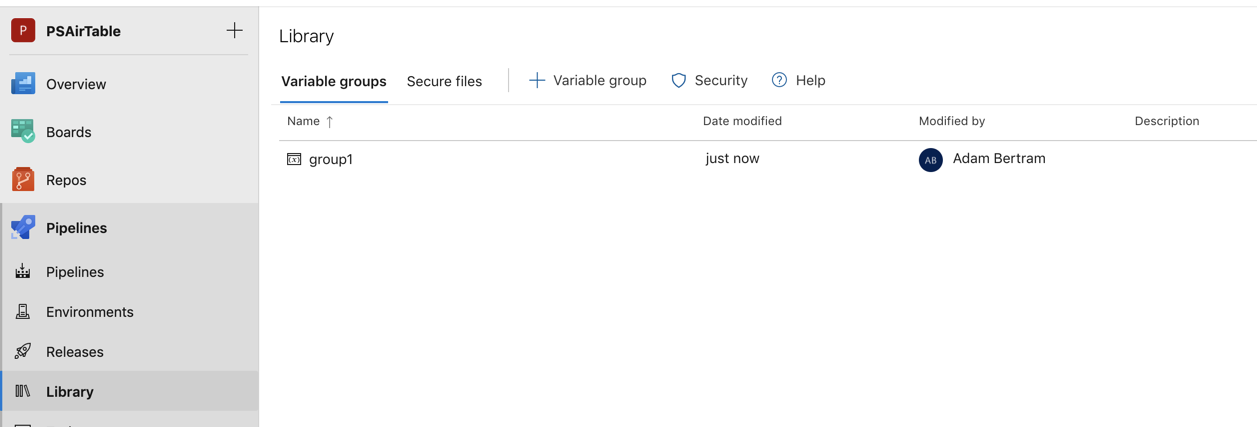
Eenmaal gedefinieerd in de pipelinelibrary, kunt u vervolgens die variabelengroep toegang verlenen in het YAML-bestand met behulp van de onderstaande syntaxis.
Variabelengroepen zijn standaard niet beschikbaar voor alle pipelines. Deze instelling is beschikbaar bij het maken van de groep. Pipelines moeten gemachtigd zijn om een variabelengroep te gebruiken.
Zodra een variabelengroep toegang heeft in het YAML-bestand, kunt u vervolgens de variabelen binnen de groep op dezelfde manier benaderen als elke andere variabele. De naam van de variabelengroep wordt niet gebruikt bij het verwijzen naar variabelen in de groep.
Bijvoorbeeld, als u een variabelengroep genaamd groep1 heeft gedefinieerd met een variabele genaamd foo erin, zou u de foo-variabele net als elke andere kunnen verwijzen, bijv. $(foo).
Geheime variabelen gedefinieerd in een variabelengroep kunnen niet rechtstreeks via scripts worden benaderd. In plaats daarvan moeten ze als argumenten aan de taak worden doorgegeven.
Als er een wijziging wordt aangebracht in een variabele binnen een variabelengroep, wordt die wijziging automatisch beschikbaar gesteld aan alle toegestane pipelines die die groep mogen gebruiken.
Samenvatting
Je zou nu een stevige kennis van Azure Pipelines-variabelen moeten hebben. Je hebt zo ongeveer elk concept geleerd dat er is als het gaat om variabelen in dit artikel! Ga er nu op uit, pas deze kennis toe op je Azure DevOps Pipelines en automatiseer alles!
Source:
https://adamtheautomator.com/azure-devops-variables/