













소개
이 튜토리얼에서는 입력 비디오에서 오디오를 추출하고 추출된 오디오를 전사하여 전사에 기반한 자막 파일을 생성한 다음 자막을 입력 비디오의 사본에 추가할 수 있는 Python 애플리케이션을 만들 것입니다.
이 애플리케이션을 구축하기 위해 FFmpeg을 사용하여 입력 비디오에서 오디오를 추출할 것입니다. 추출된 오디오에 대한 전사를 생성하기 위해 OpenAI의 Whisper를 사용하고, 이 전사를 사용하여 자막 파일을 생성할 것입니다. 또한, 생성된 자막 파일을 입력 비디오의 사본에 추가하기 위해 FFmpeg을 사용할 것입니다.
FFmpeg은 오디오 및 비디오 처리 작업을 포함한 멀티미디어 데이터를 처리하기 위한 강력하고 오픈 소스 소프트웨어 스위트입니다. 사용자들이 다양한 형식과 코덱을 가진 멀티미디어 파일을 변환, 편집 및 조작할 수 있도록 하는 명령 줄 도구를 제공합니다.
OpenAI의 Whisper는 말로 된 언어를 쓴 텍스트로 변환하기 위해 설계된 자동 음성 인식(ASR) 시스템입니다. 다양한 오디오 콘텐츠를 높은 정확도로 전사하는 데 뛰어난 성능을 발휘하기 위해 다양한 언어 및 다중 작업 지도 데이터로 훈련되었습니다.
이 튜토리얼을 마치면 비디오에 자막을 추가할 수 있는 애플리케이션이 완성됩니다.
사전 요구 사항
이 자습서를 따라가기 위해 독자는 다음 도구가 필요합니다:
단계 1 — 프로젝트 루트 디렉토리 생성
이 섹션에서는 프로젝트 디렉토리를 생성하고 입력 비디오를 다운로드하고 가상 환경을 생성하고 활성화하며 필요한 Python 패키지를 설치합니다.
터미널 창을 열고 프로젝트에 적합한 위치로 이동합니다. 다음 명령을 실행하여 프로젝트 디렉토리를 생성합니다:
프로젝트 디렉토리로 이동합니다.
이 편집된 동영상을 다운로드해서 프로젝트의 루트 디렉토리에 input.mp4로 저장하세요. 이 동영상은 러쇼운이라는 아이가 제르메인 에드워드의 “뷰티풀 데이”를 부르는 모습을 보여줍니다. 이 튜토리얼에서 사용할 편집된 동영상은 다음의 YouTube 동영상에서 가져왔습니다.
새로운 가상 환경을 만들고 이름을 env로 지정하세요.
가상 환경을 활성화하세요.
이 애플리케이션을 빌드하는 데 필요한 패키지를 설치하기 위해 다음 명령어를 사용하세요.
위의 명령으로 다음 라이브러리들이 설치되었습니다.
-
faster-whisper:는 OpenAI의 Whisper 모델을 활용하는 CTranslate2를 사용하는 재설계된 버전입니다. 이 구현은 openai/whisper와 비교 가능한 정확도를 유지하면서 최대 4배 더 빠른 속도와 더 적은 메모리 사용량을 달성합니다. -
ffmpeg-python: FFmpeg 도구를 둘러싸는 래퍼(wrapper) 기능을 제공하는 Python 라이브러리로, 사용자가 Python 스크립트에서 FFmpeg 기능을 쉽게 사용할 수 있도록 합니다. Pythonic 인터페이스를 통해 편집, 변환, 조작 등 비디오 및 오디오 처리 작업을 수행할 수 있습니다.
다음 명령을 실행하여 가상 환경에 pip로 설치된 패키지를 ‘requirements.txt’라는 파일에 저장합니다:
‘requirements.txt’ 파일은 다음과 유사한 모습을 가져야 합니다:
av==10.0.0
certifi==2023.7.22
charset-normalizer==3.3.2
coloredlogs==15.0.1
ctranslate2==3.20.0
faster-whisper==0.9.0
ffmpeg-python==0.2.0
filelock==3.13.1
flatbuffers==23.5.26
fsspec==2023.10.0
future==0.18.3
huggingface-hub==0.17.3
humanfriendly==10.0
idna==3.4
mpmath==1.3.0
numpy==1.26.1
onnxruntime==1.16.1
packaging==23.2
protobuf==4.25.0
PyYAML==6.0.1
requests==2.31.0
sympy==1.12
tokenizers==0.14.1
tqdm==4.66.1
typing_extensions==4.8.0
urllib3==2.0.7
이 섹션에서는 프로젝트 디렉토리를 생성하고, 이 튜토리얼에서 사용할 입력 비디오를 다운로드하고, 가상 환경을 설정하고, 활성화하며, 필요한 Python 패키지를 설치했습니다. 다음 섹션에서는 입력 비디오에 대한 트랜스크립트를 생성합니다.
2단계 – 비디오 트랜스크립트 생성
이 섹션에서는 응용 프로그램이 존재할 Python 스크립트를 생성합니다. 이 스크립트 내에서는 이전 섹션에서 다운로드한 입력 비디오에서 오디오 트랙을 추출하고 WAV 파일로 저장하기 위해 ffmpeg-python 라이브러리를 사용합니다. 그 다음, 추출된 오디오에 대한 대본을 생성하기 위해 faster-whisper 라이브러리를 사용합니다.
프로젝트 루트 디렉토리에서 main.py라는 파일을 생성하고 다음 코드를 추가합니다:
여기에서 코드는 time, math, ffmpeg from ffmpeg-python 및 faster_whisper에서 WhisperModel이라는 사용자 정의 모듈을 포함하여 다양한 라이브러리와 모듈을 가져옵니다. 이러한 라이브러리는 비디오 및 오디오 처리, 대본 및 자막 생성에 사용될 것입니다.
다음으로, 코드는 입력 비디오 파일 이름을 설정하고 이를 input_video라는 상수에 저장한 다음, .mp4 확장자 없이 비디오 파일 이름을 input_video_name이라는 상수에 저장합니다. 여기에서 입력 파일 이름을 설정하면 자막 및 출력 비디오 파일을 생성할 때 여러 입력 비디오에서 작업할 수 있습니다.
main.py의 맨 아래에 다음 코드를 추가하세요:
위의 코드는 입력 비디오에서 오디오를 추출하는 extract_audio()라는 함수를 정의합니다.
먼저, 입력 비디오의 기본 이름에 audio-를 추가하고 .wav 확장자를 붙여 생성된 이름을 상수인 extracted_audio에 저장합니다.
다음으로, 코드는 ffmpeg 라이브러리의 ffmpeg.input() 메서드를 호출하여 입력 비디오를 열고, stream이라는 입력 스트림 객체를 생성합니다.
코드는 그런 다음, 입력 스트림과 정의된 추출된 오디오 파일 이름을 사용하여 출력 스트림 객체를 생성하기 위해 ffmpeg.output() 메서드를 호출합니다.
출력 스트림을 설정한 후, 코드는 ffmpeg.run() 메서드를 호출하여 출력 스트림을 매개변수로 전달하여 오디오 추출 프로세스를 시작하고 프로젝트의 루트 디렉토리에 추출된 오디오 파일을 저장합니다. 또한, overwrite_output=True라는 부울 매개변수가 포함되어 있어, 이미 해당 파일이 있는 경우에는 새로 생성된 파일로 기존의 출력 파일을 대체합니다.
마지막으로, 코드는 추출된 오디오 파일의 이름을 반환합니다.
extract_audio() 함수 아래에 다음 코드를 추가하세요:
여기에서, 코드는 run()이라는 함수를 정의하고 호출합니다. 이 함수는 비디오에 자막을 생성하고 추가하기 위해 필요한 모든 함수를 호출합니다.
함수 내부에서, 코드는 비디오에서 오디오를 추출하기 위해 extract_audio() 함수를 호출하고, 반환된 오디오 파일 이름을 extracted_audio라는 변수에 저장합니다.
main.py 스크립트를 실행하려면 터미널로 돌아가서 다음 명령을 실행하세요:
위의 명령을 실행한 후, 터미널에 FFmpeg 출력이 표시되며, 입력 비디오에서 추출된 오디오가 포함된 audio-input.wav라는 파일이 프로젝트의 루트 디렉토리에 저장됩니다.
main.py 파일로 돌아가서 extract_audio()와 run() 함수 사이에 다음 코드를 추가하세요:
위의 코드는 입력 비디오에서 추출된 오디오 파일을 전사하는 역할을 하는 transcribe라는 함수를 정의합니다.
먼저, 코드는 WhisperModel 객체의 인스턴스를 생성하고 모델 유형을 small로 설정합니다. OpenAI의 Whisper는 다음과 같은 모델 유형을 갖고 있습니다: tiny, base, small, medium, large. tiny 모델은 가장 작고 빠르며 large 모델은 가장 크고 느리지만 가장 정확합니다.
다음으로, 코드는 추출된 오디오를 인자로 사용하여 model.transcribe() 메서드를 호출하여 segments 함수와 오디오 정보를 검색하고 각각 info와 segments라는 변수에 저장합니다. segments 함수는 파이썬 제너레이터이므로 코드가 이를 반복할 때 전사가 시작됩니다. 전사는 segments를 list나 for 루프로 수집하여 완료될 수 있습니다.
다음으로, 코드는 오디오에서 감지된 언어를 상수인 info에 저장하고 콘솔에 출력합니다.
언어 감지 후, 코드는 전사 세그먼트를 수집하여 전사를 실행하기 위해 list에 저장하고, 수집된 세그먼트를 segments라는 변수에 저장합니다. 그런 다음 코드는 전사 세그먼트 목록을 루프 돌며 각 세그먼트의 시작 시간, 종료 시간 및 텍스트를 콘솔에 인쇄합니다.
마지막으로, 코드는 오디오에서 감지된 언어와 전사 세그먼트를 반환합니다.
run() 함수 내에 다음 코드를 추가하세요:
추가된 코드는 추출한 오디오를 인수로 사용하여 전사 함수를 호출하고, 반환된 값을 language와 segments라는 상수에 저장합니다.
터미널로 돌아가서 다음 명령을 실행하여 main.py 스크립트를 실행하세요:
이 스크립트를 처음 실행할 때, 코드는 먼저 Whisper Small 모델을 다운로드하고 캐시합니다. 그 후에는 실행 속도가 훨씬 빨라집니다.
위의 명령을 실행한 후에는 콘솔에서 다음 출력을 볼 수 있어야 합니다:
…
Transcription language en
[0.00s -> 4.00s] This morning I wake up and I look in the mirror
[4.00s -> 8.00s] Every part of my body was in the place many people lie
[8.00s -> 11.00s] I don't wanna act too high and mighty
[11.00s -> 15.00s] Cause tomorrow I may fall down on my face
[15.00s -> 17.00s] Lord I thank You for sunshine
[17.00s -> 19.00s] Thank You for rain
[19.00s -> 20.00s] Thank You for joy
[20.00s -> 22.00s] Thank You for pain
[22.00s -> 25.00s] It's a beautiful day
[25.00s -> 28.00s] It's a beautiful day
위의 출력은 오디오에서 감지된 언어가 영어(en)임을 보여줍니다. 또한 각 전사 세그먼트의 시작 시간과 종료 시간(초) 및 텍스트를 표시합니다.
경고: OpenAI의 Whisper 음성 인식은 매우 정확하지만 100% 정확하지는 않으며, 특히 언어적이거나 오디오적으로 어려운 상황에서는 가끔 제한과 오류가 발생할 수 있습니다. 따라서 항상 전사를 수동으로 확인하도록 해야 합니다.
이 섹션에서는 애플리케이션을 위한 Python 스크립트를 작성했습니다. 스크립트 내부에서는 ffmpeg-python을 사용하여 다운로드한 비디오에서 오디오를 추출하고 WAV 파일로 저장했습니다. 그런 다음 faster-whisper 라이브러리를 사용하여 추출한 오디오에 대한 트랜스크립트를 생성했습니다. 다음 섹션에서는 트랜스크립트를 기반으로 자막 파일을 생성한 후 비디오에 자막을 추가합니다.
단계 3 — 자막 생성 및 비디오에 추가하기
이 섹션에서는 먼저 자막 파일이 무엇이고 어떻게 구성되는지 이해합니다. 다음으로, 이전 섹션에서 생성된 트랜스크립트 세그먼트를 사용하여 자막 파일을 생성합니다. 자막 파일을 생성한 후에는 ffmpeg-python 라이브러리를 사용하여 입력 비디오의 사본에 자막 파일을 추가합니다.
자막 이해: 구조와 유형
A subtitle file is a text file that contains timed text information corresponding to spoken or written content in a video or film. It typically includes information about when each subtitle should appear and disappear on the screen. There are many subtitle formats, however, in this tutorial, we will focus on the widely used format named SubRip (SRT).
A subtitle file is organized into a series of subtitle entries, each typically following a specific format. The common structure of a subtitle entry includes:
-
자막 인덱스: 파일 내 자막의 순서를 나타내는 순차적인 번호입니다.
-
타임코드: 자막 텍스트가 표시되어야 할 시간을 지정하는 시작 및 종료 시간 표시자입니다. 타임코드는 일반적으로
HH:MM:SS,sss(시간, 분, 초, 밀리초) 형식으로 포맷됩니다. -
자막 텍스트: 실제로 음성이나 글로 표현된 자막 항목의 텍스트입니다. 이 텍스트는 지정된 시간 간격 동안 화면에 표시됩니다.
예를 들어, SRT 파일의 자막 항목은 다음과 같을 수 있습니다:
1
00:00:10,500 --> 00:00:15,000
This is an example subtitle.
이 예제에서 인덱스는 1이며, 타임코드는 자막이 10.5초부터 15초까지 표시되어야 함을 나타내며, 자막 텍스트는 이것은 예제 자막입니다.입니다.
자막은 주로 두 가지 주요 유형으로 나뉠 수 있습니다:
-
소프트 자막: 클로즈드 캡션(Closed Caption)으로도 알려져 있으며, 별도의 파일(SRT와 같은)로 외부에 저장되어 동영상과 독립적으로 추가 또는 제거할 수 있습니다. 시청자에게 유연성을 제공하여 토글, 언어 전환 및 설정의 사용자 정의를 가능하게 합니다. 그러나 소프트 자막의 효과는 동영상 플레이어의 지원에 의존하며, 모든 플레이어가 일관된 방식으로 소프트 자막을 지원하는 것은 아닙니다.
-
하드 자막: 편집이나 인코딩 중에 비디오 프레임에 영구적으로 삽입되어 비디오의 고정된 부분으로 남습니다. 이들은 외부 자막 파일을 지원하지 않는 플레이어에서도 일관된 가시성을 보장하지만, 수정이나 끄기 위해서는 영상 전체를 재인코딩해야 하므로 사용자 제어가 제한됩니다.
자막 파일 생성하기
main.py 파일로 돌아가서 transcribe()와 run() 함수 사이에 다음 코드를 추가하세요.
여기에서 코드는 주어진 전사 세그먼트의 시작 및 종료 시간을 초 단위에서 시, 분, 초 및 밀리초를 표시하는 자막 호환 시간 형식으로 변환하는 format_time()라는 함수를 정의합니다.
코드는 먼저 주어진 시간을 초 단위로 변환하여 시간, 분, 초 및 밀리초를 계산하고 이를 적절한 형식으로 포맷한 후 형식화된 시간을 반환합니다.
format_time()과 run() 함수 사이에 다음 코드를 추가하세요:
추가한 코드는 generate_subtitle_file()라는 함수를 정의합니다. 이 함수는 추출된 오디오의 감지된 언어와 전사 세그먼트를 매개변수로 받아 해당 언어와 전사 세그먼트에 기반한 SRT 자막 파일을 생성하는 역할을 합니다.
먼저, 코드는 자막 파일의 이름을 입력 비디오의 기본 이름에 “sub-“와 감지된 언어를 추가하여 “srt” 확장자로 형성한 이름으로 설정하고 이 이름을 subtitle_file라는 상수에 저장합니다. 또한, 코드는 자막 항목을 저장할 text라는 변수를 정의합니다.
그다음, 코드는 전사된 세그먼트를 반복하며 format_time() 함수를 사용하여 시작 및 종료 시간을 포맷하고, 이러한 포맷된 값을 세그먼트 인덱스 및 텍스트와 함께 자막 항목을 생성한 후 각 자막 항목을 구분하기 위해 빈 줄을 추가합니다.
마지막으로, 코드는 이전에 설정한 이름으로 프로젝트 루트 디렉토리에 자막 파일을 생성하고, 파일에 자막 항목을 추가한 뒤 자막 파일 이름을 반환합니다.
다음 코드를 run() 함수의 맨 아래에 추가하세요:
추가된 코드는 감지된 언어와 전사 세그먼트를 인수로 하여 generate_subtitle_file() 함수를 호출하고, 반환된 자막 파일 이름을 subtitle_file이라는 상수에 저장합니다.
터미널로 돌아가서 다음 명령을 실행하여 main.py 스크립트를 실행하세요:
위 명령을 실행한 후에는 sub-input.en.srt라는 이름의 자막 파일이 프로젝트의 루트 디렉토리에 저장됩니다.
sub-input.en.srt 자막 파일을 열면 다음과 유사한 내용이 표시됩니다:
1
00:00:0,000 --> 00:00:4,000
This morning I wake up and I look in the mirror
2
00:00:4,000 --> 00:00:8,000
Every part of my body was in the place many people lie
3
00:00:8,000 --> 00:00:11,000
I don't wanna act too high and mighty
4
00:00:11,000 --> 00:00:15,000
Cause tomorrow I may fall down on my face
5
00:00:15,000 --> 00:00:17,000
Lord I thank You for sunshine
6
00:00:17,000 --> 00:00:19,000
Thank You for rain
7
00:00:19,000 --> 00:00:20,000
Thank You for joy
8
00:00:20,000 --> 00:00:22,000
Thank You for pain
9
00:00:22,000 --> 00:00:25,000
It's a beautiful day
10
00:00:25,000 --> 00:00:28,000
It's a beautiful day
비디오에 자막 추가하기
generate_subtitle_file() 함수와 run() 함수 사이에 다음 코드를 추가하세요:
여기서, 코드는 부드러운 자막이나 강한 자막을 추가할지 여부를 결정하는 부울 값, 자막 파일 이름 및 전사에서 감지된 언어를 매개변수로 하는 add_subtitle_to_video() 함수를 정의합니다. 이 함수는 입력 비디오의 사본에 부드러운 자막이나 강한 자막을 추가하는 역할을 합니다.
먼저, 코드는 ffmpeg.input() 메서드를 사용하여 입력 비디오 및 자막 파일을 사용하여 입력 비디오 및 자막 파일의 입력 스트림 객체를 생성하고 각각 video_input_stream 및 subtitle_input_stream 상수에 저장합니다.
입력 스트림을 생성한 후, 코드는 출력 비디오 파일의 이름을 입력 비디오의 기본 이름에 “output-“를 추가하고 “mp4” 확장자를 붙인 이름으로 설정하고 이 이름을 output_video 상수에 저장합니다. 또한, 자막 트랙의 이름을 자막 파일 이름에서 .srt 확장자를 제외한 이름으로 설정하고 이 이름을 subtitle_track_title 상수에 저장합니다.
그다음, 코드는 부울형 변수 soft_subtitle이 True로 설정되어 있는지 확인하여 소프트 자막을 추가해야 하는지 여부를 확인합니다.
그렇다면, 코드는 ffmpeg.output() 메서드를 호출하여 입력 스트림, 출력 비디오 파일 이름 및 다음과 같은 출력 비디오 옵션을 사용하여 출력 스트림 객체를 생성합니다:
-
"c": "copy": 비디오 코덱 및 기타 비디오 매개변수를 재인코딩하지 않고 입력에서 출력으로 직접 복사해야 함을 지정합니다. -
"c:s": "mov_text": 입력에서 출력으로 자막 코덱과 매개변수를 다시 인코딩하지 않고 복사해야 함을 지정합니다.mov_text은 MP4/MOV 파일에서 사용되는 일반적인 자막 코덱입니다. -
”metadata:s:s:0”: f"language={subtitle_language}": 자막 스트림에 대한 언어 메타데이터를 설정합니다. 언어는subtitle_language에 저장된 값으로 설정됩니다. -
"metadata:s:s:0": f"title={subtitle_track_title}": 자막 스트림에 대한 제목 메타데이터를 설정합니다. 제목은subtitle_track_title에 저장된 값으로 설정됩니다.
마지막으로, 코드는 ffmpeg.run() 메소드를 호출하며, 출력 스트림을 매개변수로 전달하여 소프트 자막을 비디오에 추가하고 출력 비디오 파일을 프로젝트의 루트 디렉토리에 저장합니다.
add_subtitle_to_video() 함수의 맨 아래에 다음 코드를 추가하세요.
만약 soft_subtitle 불리언이 False로 설정되어 있다면 강조된 코드가 실행됩니다. 이는 하드 자막을 추가해야 함을 나타냅니다.
이 경우, 코드는 먼저 입력 비디오 스트림, 출력 비디오 파일 이름 및 vf=f"subtitles={subtitle_file}" 매개변수를 사용하여 출력 스트림 객체를 생성하기 위해 ffmpeg.output() 메서드를 호출합니다. vf는 “비디오 필터”를 의미하며, 비디오 스트림에 필터를 적용하는 데 사용됩니다. 이 경우, 적용되는 필터는 자막 추가입니다.
마지막으로, 코드는 ffmpeg.run() 메서드를 호출하여 출력 스트림을 매개변수로 전달하여 비디오에 하드 자막을 추가하고 출력 비디오 파일을 프로젝트의 루트 디렉토리에 저장합니다.
run() 함수에 다음 강조된 코드를 추가하세요:
강조된 코드는 soft_subtitle 매개변수를 True로 설정하여 입력 비디오의 사본에 소프트 자막을 추가하기 위해 add_subtitle_to_video()를 호출합니다. 이때 자막 파일 이름과 자막 언어도 함께 전달됩니다.
터미널로 돌아가서 다음 명령을 실행하여 main.py 스크립트를 실행하세요:
위의 명령을 실행한 후, output-input.mp4라는 출력 비디오 파일이 프로젝트의 루트 디렉토리에 저장됩니다.
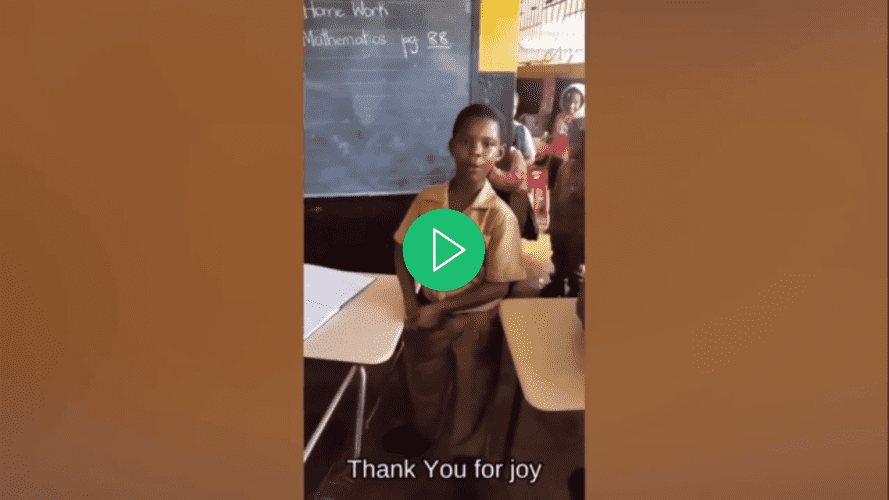
선호하는 비디오 플레이어에서 비디오를 열어서 비디오에 자막을 선택하고, 선택하기 전까지는 자막이 표시되지 않는 것을 확인하세요.
main.py 파일로 돌아가서 run() 함수로 이동하고 add_subtitle_to_video() 함수 호출에서 soft_subtitle 매개변수를 False로 설정하세요:
여기에서 soft_subtitle 매개변수를 False로 설정하여 비디오에 강제로 자막을 추가합니다.
터미널로 돌아가서 다음 명령을 실행하여 main.py 스크립트를 실행하세요:
위의 명령을 실행한 후 프로젝트 루트 디렉토리에 있는 output-input.mp4 비디오 파일이 덮어쓰기됩니다.
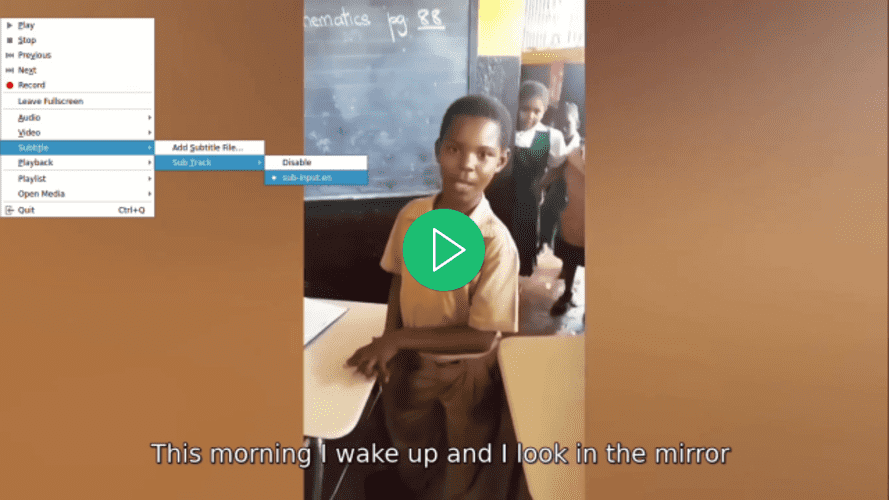
선호하는 비디오 플레이어를 사용하여 비디오를 열고 비디오에 대한 자막을 선택하려고 시도하면 자막이 없는데도 자막이 표시되는 것을 확인하세요:

이 섹션에서는 SRT 자막 파일의 구조를 이해하고 이전 섹션에서 생성한 전사 세그먼트를 활용하여 자막 파일을 생성했습니다. 이후 ffmpeg-python 라이브러리를 사용하여 생성된 자막 파일을 비디오에 추가했습니다.
결론
이 자습서에서는 ffmpeg-python과 faster-whisper 파이썬 라이브러리를 사용하여 입력 비디오에서 오디오를 추출하고 추출된 오디오를 전사하며, 전사에 기반한 자막 파일을 생성하고 입력 비디오의 사본에 자막을 추가할 수 있는 애플리케이션을 구축했습니다.