













컴퓨팅 초기에는 애플리케이션이 작업을 순차적으로 처리했습니다. 사용자 수가 수백만으로 증가하면서 이 접근 방식은 비현실적이 되었습니다. 비동기 처리는 여러 작업을 동시에 처리할 수 있게 했지만, 단일 머신에서 스레드/프로세스를 관리하는 것은 자원 제약과 복잡성을 초래했습니다.
여기서 분산 병렬 처리가 등장합니다. 작업의 일부에 전념하는 여러 머신에 작업 부담을 분산시킴으로써 확장 가능하고 효율적인 솔루션을 제공합니다. 대량의 파일을 처리하는 함수가 있다면, 작업 부담을 여러 머신에 나누어 파일을 동시에 처리할 수 있으며, 단일 머신에서 순차적으로 처리하는 대신에 처리할 수 있습니다. 또한, 결합된 자원을 활용하여 성능을 향상시키고 확장성과 내결함성을 제공합니다. 수요가 증가함에 따라, 사용 가능한 자원을 늘리기 위해 더 많은 머신을 추가할 수 있습니다.
대규모로 분산 애플리케이션을 구축하고 실행하는 것은 도전적이지만, 이를 도와줄 여러 프레임워크와 도구가 있습니다. 이 블로그 포스트에서는 그런 오픈 소스 분산 컴퓨팅 프레임워크 중 하나인 Ray를 살펴보겠습니다. 또한 클라우드 네이티브 환경에서 분산 컴퓨팅을 위한 Kubernetes 클러스터와의 원활한 Ray 통합을 가능하게 하는 Kubernetes 운영자인 KubeRay도 살펴보겠습니다. 하지만 먼저, 분산 병렬성이 도움이 되는 지점을 이해해봅시다.
분산 병렬 처리는 어디에 도움이 될까요?
여러 대상에서 작업 부하를 분산시키는 것이 이득을 가져오는 작업은 분산 병렬 처리를 활용할 수 있습니다. 이 접근 방식은 웹 크롤링, 대규모 데이터 분석, 기계 학습 모델 훈련, 실시간 스트림 처리, 유전체 데이터 분석, 그리고 비디오 렌더링과 같은 시나리오에 특히 유용합니다. 여러 노드에 작업을 분산시킴으로써 분산 병렬 처리는 성능을 크게 향상시키고 처리 시간을 줄이며 자원 활용을 최적화하여, 고 처리량과 신속한 데이터 처리가 필요한 응용 프로그램에 필수적입니다.
분산 병렬 처리가 필요하지 않은 경우
- 소규모 응용 프로그램: 소규모 데이터 집합이나 처리 요구 사항이 적은 응용 프로그램의 경우, 분산 시스템을 관리하는 오버헤드가 정당화되지 않을 수 있습니다.
- 강력한 데이터 의존성: 작업이 매우 의존적이고 쉽게 병렬화할 수 없는 경우, 분산 처리는 거의 이점이 없을 수 있습니다.
- 실시간 제약 조건: 일부 실시간 응용 프로그램(예: 금융 및 티켓 예매 웹 사이트)은 매우 낮은 지연 시간을 요구하므로, 분산 시스템의 추가 복잡성으로 인해 달성하기 어려울 수 있습니다.
- 제한된 자원: 사용 가능한 인프라가 분산 시스템의 오버헤드를 지원할 수 없는 경우(예: 네트워크 대역폭 부족, 노드 수 제한), 단일 기기의 성능을 최적화하는 것이 더 나을 수 있습니다.
Ray가 분산 병렬 처리를 지원하는 방법
Ray는 분산 병렬 처리 프레임워크로, 분산 컴퓨팅의 모든 이점과 우리가 논의한 도전에 대한 해결책을 캡슐화합니다. 이는 파이썬 스타일의 프레임워크로, 기존 라이브러리와 시스템을 함께 사용할 수 있습니다. Ray의 도움으로 프로그래머는 병렬 처리 계산 레이어의 조각을 처리할 필요가 없습니다. Ray가 지정된 리소스 요구에 따라 스케줄링과 오토스케일링을 처리해줍니다.
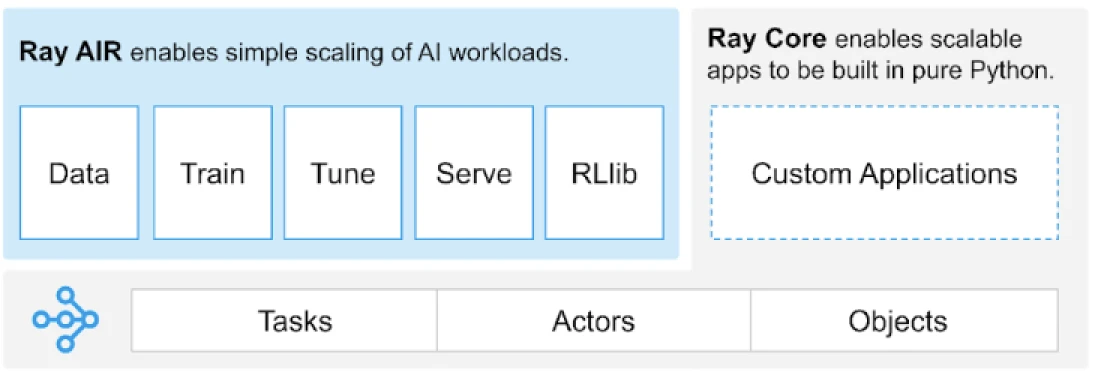
Ray는 분산 애플리케이션을 구축하기 위한 작업, 액터, 객체에 대한 범용 API를 제공합니다.
(이미지 출처)
Ray는 핵심 기본 요소인 작업, 액터, 객체, 드라이버, 작업에 기반한 라이브러리 세트를 제공합니다. 이들은 다양한 API를 제공하여 분산 애플리케이션을 구축하는 데 도움을 줍니다. 이제 Ray Core, 즉 핵심 기본 요소를 살펴보겠습니다.
Ray Core 기본 요소
- 작업: Ray 작업은 Ray 클러스터 노드의 별도 Python 작업자에서 비동기적으로 실행되는 임의의 Python 함수입니다. 사용자는 CPU, GPU 및 클러스터 스케줄러가 병렬 실행을 위해 작업을 분배하는 데 사용하는 사용자 정의 리소스 측면에서 리소스 요구 사항을 지정할 수 있습니다.
- 액터: 작업이 함수에 해당하는 것처럼, 액터는 클래스에 해당합니다. 액터는 상태를 가진 작업자로, 액터의 메소드는 특정 작업자에서 스케줄되고 해당 작업자의 상태에 접근하고 변형할 수 있습니다. 작업과 마찬가지로, 액터는 CPU, GPU 및 사용자 정의 리소스 요구 사항을 지원합니다.
- 객체: Ray에서 작업과 액터는 객체를 생성하고 계산합니다. 이러한 원격 객체는 Ray 클러스터의 어디에나 저장될 수 있습니다. 객체 참조는 이를 참조하는 데 사용되며, Ray의 분산 공유 메모리 객체 저장소에 캐시됩니다.
- 드라이버: 프로그램 루트 또는 “메인” 프로그램: 이는
ray.init()을 실행하는 코드입니다. - 작업: 동일한 드라이버에서 유래(재귀적으로)하는 작업, 객체 및 액터의 모음과 이들의 런타임 환경입니다.
프리미티브에 대한 정보는 Ray Core 문서를 통해 확인할 수 있습니다.
Ray Core 주요 메서드
아래는 일반적으로 사용되는 Ray Core 내의 주요 메서드입니다:
-
ray.init()– Ray 런타임을 시작하고 Ray 클러스터에 연결합니다.import ray ray.init()
-
@ray.remote– 다른 프로세스에서 작업(원격 함수) 또는 액터(원격 클래스)로 실행될 Python 함수 또는 클래스를 지정하는 데코레이터입니다.@ray.remote def remote_function(x): return x * 2
-
.remote– 원격 함수 및 클래스에 대한 접미사; 원격 작업은 비동기적입니다.result_ref = remote_function.remote(10)
-
ray.put()– 객체를 인메모리 객체 저장소에 저장합니다; 객체를 모든 원격 함수 또는 메서드 호출에 전달하는 데 사용되는 객체 참조를 반환합니다.data = [1, 2, 3, 4, 5] data_ref = ray.put(data)
-
ray.get()– 객체 참조를 지정하여 객체 저장소에서 원격 객체를 가져옵니다.result = ray.get(result_ref) original_data = ray.get(data_ref)
기본 키 메서드의 대부분을 사용하는 예제입니다:
import ray
ray.init()
@ray.remote
def calculate_square(x):
return x * x
# .remote를 사용하여 작업 생성
future = calculate_square.remote(5)
# 결과 가져오기
result = ray.get(future)
print(f"The square of 5 is: {result}")Ray가 어떻게 작동하는가?
Ray 클러스터는 프로그램 실행 작업을 공유하는 컴퓨터 팀과 같습니다. 이는 헤드 노드와 여러 워커 노드로 구성됩니다. 헤드 노드는 클러스터 상태 및 스케줄링을 관리하며, 워커 노드는 작업을 실행하고 액터를 관리합니다
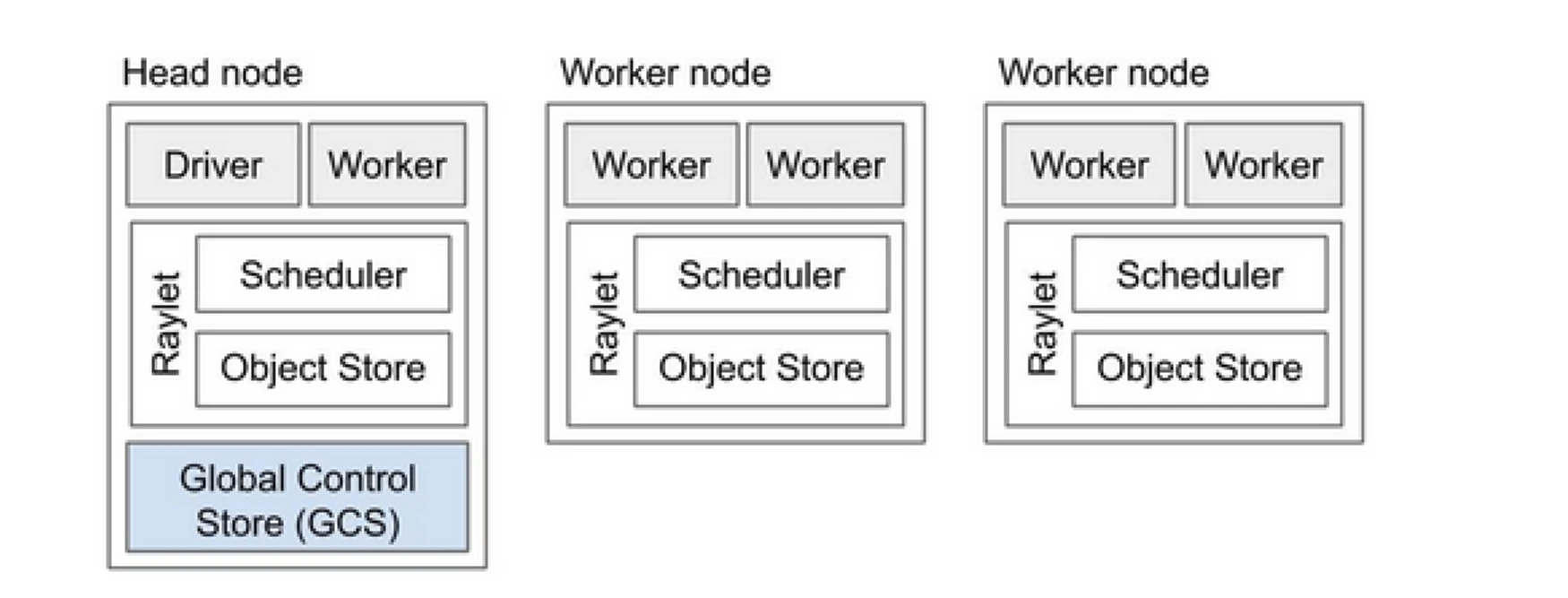
Ray 클러스터 구성 요소
- 전역 제어 저장소 (GCS): GCS는 Ray 클러스터의 메타데이터와 전역 상태를 관리합니다. 작업, 액터 및 리소스 가용성을 추적하여 모든 노드가 시스템의 일관된 보기를 갖도록 보장합니다.
- 스케줄러: 스케줄러는 가능한 노드에 작업과 액터를 분배합니다. 리소스 요구 사항과 작업 종속성을 고려하여 효율적인 리소스 활용과 작업 부하 분산을 보장합니다.
- 헤드 노드: 헤드 노드는 전체 Ray 클러스터를 조정합니다. GCS를 실행하고 작업 스케줄링을 처리하며 워커 노드의 상태를 모니터링합니다.
- 워커 노드: 워커 노드는 작업과 액터를 실행합니다. 실제 계산을 수행하고 로컬 메모리에 객체를 저장합니다.
- Raylet: 각 노드에서 공유 리소스를 관리하며, 동시에 실행 중인 모든 작업에서 공유됩니다.
더 자세한 정보는 Ray v2 아키텍처 문서를 참조할 수 있습니다.
기존 Python 애플리케이션 작업은 많은 변경이 필요하지 않습니다. 필요한 변경 사항은 주로 자연스럽게 분산되어야 하는 함수나 클래스에 관한 것입니다. 데코레이터를 추가하고 이를 작업 또는 액터로 변환할 수 있습니다. 이 예제를 살펴보겠습니다.
Python 함수를 Ray 작업으로 변환하기
# (Normal Python function)
def square(x):
return x * x
# Usage
results = []
for i in range(4):
result = square(i)
results.append(result)
print(results)
# Output: [0, 1, 4, 9]
# (Ray Implementation)
# Define the square task.
.remote
def square(x):
return x * x
# Launch four parallel square tasks.
futures = [square.remote(i) for i in range(4)]
# Retrieve results.
print(ray.get(futures))
# -> [0, 1, 4, 9]
Python 클래스를 Ray 액터로 변환하기
# (Regular Python class)
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create an instance of the Counter class
c = Counter()
# Call the incr method on the instance
for _ in range(10):
c.incr(1)
# Get the final state of the counter
print(c.get()) # Output: 10
# (Ray implementation in actor)
# Define the Counter actor.
.remote
class Counter:
def __init__(self):
self.i = 0
def get(self):
return self.i
def incr(self, value):
self.i += value
# Create a Counter actor.
c = Counter.remote()
# Submit calls to the actor. These
# calls run asynchronously but in
# submission order on the remote actor
# process.
for _ in range(10):
c.incr.remote(1)
# Retrieve final actor state.
print(ray.get(c.get.remote()))
# -> 10
Ray 객체에 정보 저장하기
import numpy as np
# (Regular Python function)
# Define a function that sums the values in a matrix
def sum_matrix(matrix):
return np.sum(matrix)
# Call the function with a literal argument value
print(sum_matrix(np.ones((100, 100)))) # Output: 10000.0
# Create a large array
matrix = np.ones((1000, 1000))
# Call the function with the large array
print(sum_matrix(matrix)) # Output: 1000000.0
# (Ray implementation of function)
import numpy as np
# Define a task that sums the values in a matrix.
.remote
def sum_matrix(matrix):
return np.sum(matrix)
# Call the task with a literal argument value.
print(ray.get(sum_matrix.remote(np.ones((100, 100)))))
# -> 10000.0
# Put a large array into the object store.
matrix_ref = ray.put(np.ones((1000, 1000)))
# Call the task with the object reference as argument.
print(ray.get(sum_matrix.remote(matrix_ref)))
# -> 1000000.0
개념에 대해 자세히 알아보려면 Ray Core Key Concept 문서를 참조하세요.
Ray와 전통적인 분산 병렬 처리 접근 방식 비교
아래는 전통적인 (Ray 없이) 접근 방식과 Kubernetes에서의 Ray를 통한 분산 병렬 처리 활성화 간의 비교 분석입니다.
| Aspect | Traditional Approach | Ray on Kubernetes |
|---|---|---|
| 배포 | 수동 설정 및 구성 | KubeRay Operator를 통한 자동화 |
| 확장성 | 수동 확장 | RayAutoScaler 및 Kubernetes를 통한 자동 확장 |
| 장애 허용 | 맞춤형 장애 허용 메커니즘 | Kubernetes 및 Ray의 내장 장애 허용 기능 |
| 자원 관리 | 수동 자원 할당 | 자동화된 자원 할당 및 관리 |
| 부하 분산 | 맞춤형 부하 분산 솔루션 | Kubernetes의 내장 로드 밸런싱 |
| 의존성 관리 | 수동 의존성 설치 | 도커 컨테이너를 통한 일관된 환경 |
| 클러스터 조정 | 복잡하고 수동적 | Kubernetes 서비스 검색 및 조정을 통한 간소화 |
| 개발 오버헤드 | 높음, 맞춤형 솔루션 필요 | 감소, Ray와 Kubernetes가 많은 측면을 처리 |
| 유연성 | 변경되는 워크로드에 대한 제한된 적응성 | 동적 확장 및 자원 할당으로 높은 유연성 |
Kubernetes는 강력한 오케스트레이션 기능 덕분에 Ray와 같은 분산 애플리케이션을 실행하기 위한 이상적인 플랫폼을 제공합니다. 아래는 Kubernetes에서 Ray를 실행하는 가치를 설정하는 주요 포인터입니다:
- 자원 관리
- 확장성
- 오케스트레이션
- 생태계와의 통합
- 쉬운 배포 및 관리
KubeRay Operator는 Kubernetes에서 Ray를 실행할 수 있게 해줍니다.
KubeRay란?
KubeRay Operator는 배포, 확장 및 유지 관리와 같은 작업을 자동화하여 Kubernetes에서 Ray 클러스터를 관리하는 과정을 간소화합니다. Ray 특정 자원을 관리하기 위해 Kubernetes 사용자 정의 리소스 정의(CRDs)를 사용합니다.
KubeRay CRDs
그것은 세 가지 다른 CRD를 가지고 있습니다:
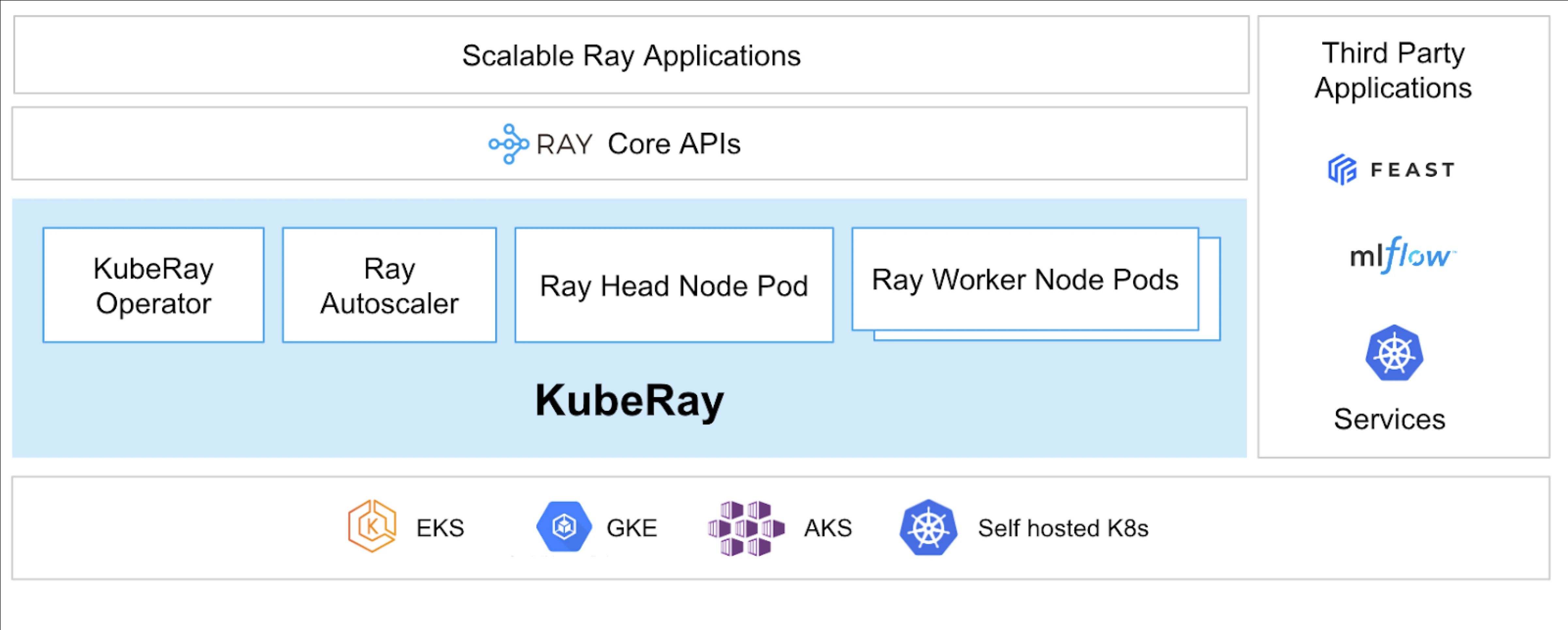
- RayCluster: 이 CRD는 RayCluster의 라이프사이클을 관리하고 구성에 따라 자동 스케일링을 담당합니다.
- RayJob: 항시 RayCluster를 유지하는 대신 일회성 작업을 실행하고 싶을 때 유용합니다. 준비가 되면 RayCluster를 생성하고 작업을 제출합니다. 작업이 완료되면 RayCluster를 삭제합니다. 이를 통해 RayCluster를 자동으로 재활용할 수 있습니다.
- RayService: 이 또한 RayCluster를 생성하고 RayServe 응용 프로그램을 배포합니다. 이 CRD를 사용하면 응용 프로그램에 인-플레이스 업데이트를 수행하여 제로 다운타임 업그레이드 및 업데이트를 보장하여 응용 프로그램의 고가용성을 확보할 수 있습니다.
KubeRay의 사용 사례
RayService를 사용하여 온디맨드 모델 배포
RayService를 사용하면 Kubernetes 환경에서 온디맨드로 모델을 배포할 수 있습니다. 이미지 생성 또는 텍스트 추출과 같은 응용 프로그램의 경우 필요할 때만 모델을 배포할 수 있습니다.
안정적인 확산의 예시입니다. Kubernetes에 적용하면 RayCluster를 생성하고 RayService를 실행하여 리소스를 삭제할 때까지 모델을 제공합니다. 사용자가 리소스를 제어할 수 있습니다.
RayJob을 사용하여 GPU 클러스터에서 모델을 훈련시키기
RayService는 사용자에게 다양한 요구 사항을 제공하며, 모델 또는 응용 프로그램을 수동으로 삭제할 때까지 배포된 상태를 유지합니다. 반면에 RayJob은 모델 훈련, 데이터 전처리 또는 지정된 프롬프트의 고정된 횟수에 대한 추론과 같은 사용 사례에 대한 일회성 작업을 허용합니다.
RayService 또는 RayJob을 사용하여 Kubernetes에서 추론 서버 실행하기
일반적으로 우리는 롤링 업데이트를 중단시키지 않고 배포에서 응용 프로그램을 실행합니다. 마찬가지로 KubeRay에서는 RayService를 사용하여 모델이나 응용 프로그램을 배포하고 롤링 업데이트를 처리할 수 있습니다.
그러나 추론 서버나 응용 프로그램을 오랜 시간 실행하는 대신 일괄적인 추론을 수행하고 싶은 경우가 있을 수 있습니다. 이때 RayJob을 활용할 수 있으며, 이는 Kubernetes Job 리소스와 유사합니다.
Huggingface Vision Transformer를 사용한 이미지 분류 일괄 추론은 RayJob의 예시로, 일괄적인 추론을 수행합니다.
이것들은 Kubernetes 클러스터에서 더 많은 작업을 수행할 수 있도록 하는 KubeRay의 사용 사례입니다. KubeRay의 도움을 받아 동일한 Kubernetes 클러스터에서 혼합 워크로드를 실행하고 GPU 기반 워크로드 스케줄링을 Ray에게 전담할 수 있습니다.
결론
분산 병렬 처리는 대규모 자원 집약적 작업을 처리하기 위한 확장 가능한 솔루션을 제공합니다. Ray는 분산 애플리케이션 구축의 복잡성을 단순화하며, KubeRay는 Ray를 Kubernetes와 통합하여 원활한 배포와 확장을 지원합니다. 이 조합은 성능, 확장성 및 내결함성을 향상시켜 웹 크롤링, 데이터 분석 및 기계 학습 작업에 이상적입니다. Ray와 KubeRay를 활용하면 분산 컴퓨팅을 효율적으로 관리할 수 있어 오늘날 데이터 기반 세상의 요구를 쉽게 충족할 수 있습니다.
뿐만 아니라 우리의 컴퓨팅 자원 유형이 CPU에서 GPU 기반으로 변화함에 따라 AI든 대규모 데이터 처리든 모든 종류의 애플리케이션을 위한 효율적이고 확장 가능한 클라우드 인프라가 중요해집니다.
이 게시물이 유익하고 흥미롭다고 생각하신다면, 이 게시물에 대한 여러분의 의견을 듣고 싶습니다. LinkedIn에서 대화를 시작해 보세요.
Source:
https://dzone.com/articles/primer-on-distributed-parallel-processing-with-ray