













거리 metrics는 데이터 과학과 머신 leaning에서 많은 알고리즘의 기반을 제공하며, 데이터 포인트 간의 유사성 또는 상 triggership을 측정하는 것이 가능하다. 이 가이드에서는 Minkowski 거리의 기반을 탐구하고, 수학적 속성을 알아보며, 구현을 다룬다. 다른 일반적인 거리 측정과의 관계를 조사하고 Python과 R에서 코딩 예제로 사용하는 것을 보여주며.
클러스터링 알고리즘 개발을 하는 것과 이상 감지를 하는 것이나 분류 모델을 精 조정하는 것이든지, Minkowski 거리를 이해하면 데이터 분석 및 모델 開発에 있어 접근 방식을 향상시키는 것이 가능하다. 让我们来看一下。
Minkowski 거리는 무엇인가?
Minkowski 거리는 规范化 벡터 공간에서 사용되는 다양한 용도의 지수로, 독일 수학자 Hermann Minkowski의 이름을 따서 불린다. 여러 知名的 거리 지수를 일반화하는 것이 使其 다양한 领域에서 기본적인 개념이 되었다. 수학, 컴퓨터 과학, 데이터 분석 등에서 중요한 개념이며, 여러 지수 지정 가능하다.
Minkowski 거리는 다차원 공간 两点间의 거리를 측정하는 것을 제공하며, 특정 기Parameter p를 통해 다른 거리 지수를 特殊情况로 포함할 수 있다. 이 파라미터를 통해 Minkowski 거리가 다양한 문제 공간과 데이터 특성에 따라 적절하게 대응할 수 있다. Minkowski 거리의 일반적인 수식은 다음과 같다:
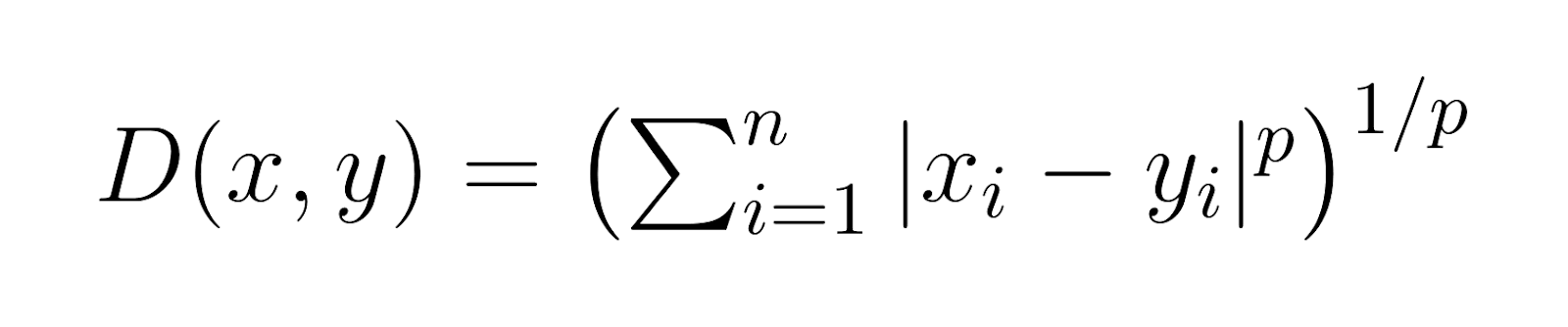
이곳에 적용되는 것은:
-
x와y는 n-차원 공간의 두 点 -
p는 거리의 유형을 결정하는 Parameter (p ≥ 1) -
|xi - yi|는 각 維에서 x와 y의 坐標 간의 絶对方位 차이를 나타낸다.
闵可夫斯基距离가 유용한 이유는 두 가지가 있습니다. 첫째, 필요에 따라 曼哈顿 거리나 欧几里得 거리를 切换할 수 있는 靈活성을 제공합니다. 둘째, 모든 데이터셋(高维 공간을 생각하세요)이 정확하게 曼哈顿 거리나 欧几里得 거리에 잘 어울린다고 인식합니다.
실제로, パラ미터 p는 一般的히 트레인/테스트 검증 workflow를 통해 선택합니다. 교차 validation 过程中에서 p의 다양한 값을 시험하여, 특정 데이터셋에 대해 가장 좋은 모델 パフォーマン스를 제공하는 값을 결정할 수 있습니다.
闵可夫斯基 거리가 어떻게 작동하는지
闵可夫斯基 거리가 다른 거리 수식과 관련이 어떻게 ある지 보고, 예시를 통해 이해하는 것을 봅시다.
다른 거리 지표의 일반화
먼저 고려해야 하는 것은, 闵可夫斯基 거리 수식은 曼哈顿, 欧几里得, � Chevyshev 거리의 수식을 포함하고 있다는 것입니다.
曼哈顿 거리 (p = 1):
当 p 가 1로 설정되면, 闵可夫斯基 거리가 曼哈顿 거리가 되ます.
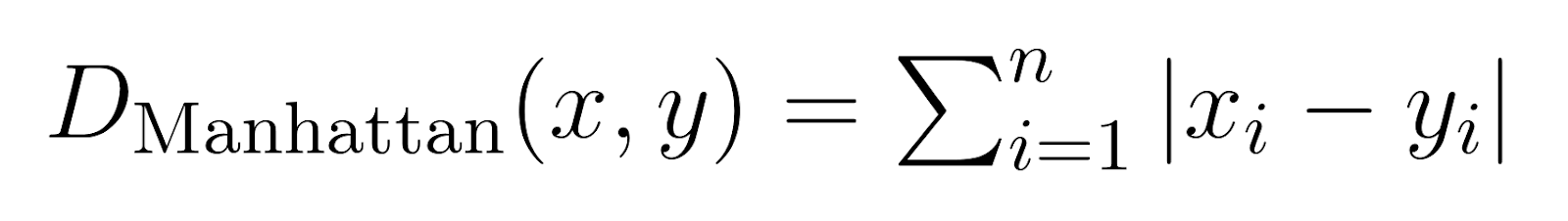
또한 도시 블록 거리나 L1 norm이라고 불립니다.曼哈顿 거리는 絶対 차이의 합을 측정합니다.
欧几里得 거리 (p = 2):
当 p 가 2로 설정되면, 闵可夫斯基 거리가 欧几里得 거리가 되ます.
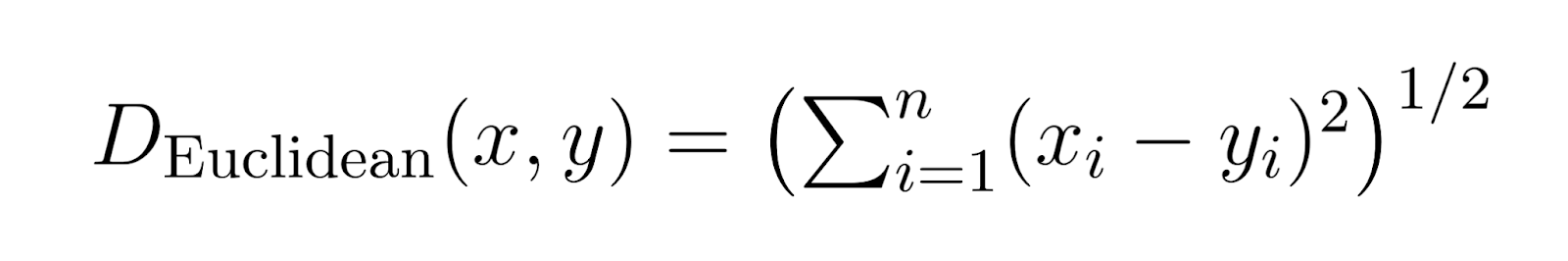
EUCLIDEAN 거리는 가장 일반적인 거리 지수로, 두 지점之间的 직선적 거리를 나타냅니다.
Chebyshev 거리 (p → ∞):
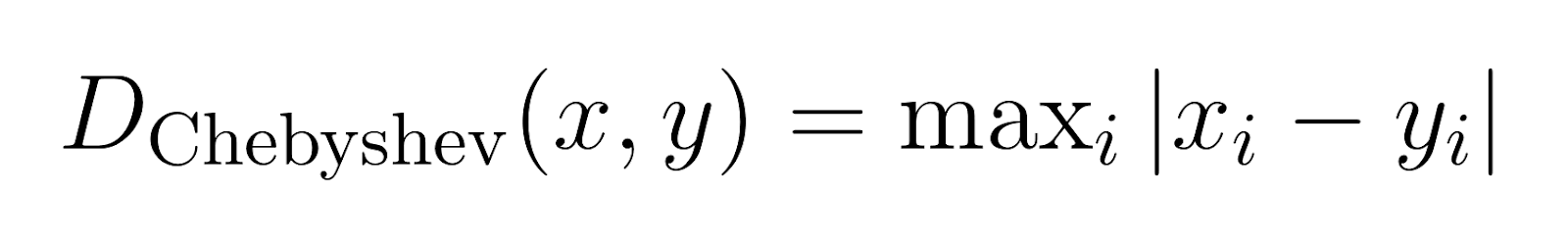
Chebyshev 거리, 또한 체스borad 거리と呼ばれ, 모든 维度에 대해 최대 차이를 測定합니다.
예제를 통한 이해
Minkowski 거리의 기능과 힘을 真に 이해하기 위해, 예제를 통해 다양한 p 값에 따라 이 지점사之间的 Minkowski 거리를 계산하고 해석하는 방법을 배울 것입니다.
2D 공간의 두 지점을 고려해 봅시다:
- 지점 A: (2, 3)
- 지점 B: (5, 7)
이러한 지점사之间的 Minkowski 거리를 다양한 p 값에 따라 계산할 것입니다.

p 값은 Minkowski 거리 수식에서 지수의 чувствительность을 제어합니다:
- p=1 일 때: 모든 차이는 선형적으로 기여합니다.
- p=2 일 때: 제곱하는 영향으로 큰 차이는 더욱 중요합니다.
- p>2 일 때: 더욱 큰 차이에 더욱 중요한 emphasis를 부여합니다.
- p→∞ 일 때: 모든 维度之间的 가장 큰 차이만 중요합니다.
p 값이 증가하면, Minkowski 거리는 일반적으로 감소하며 Chebyshev 거리로 가까이 approximation되는 것을 볼 수 있습니다. 이는 더 높은 p 값은 큰 차이에 더 많은 가중치를 주고, 작은 차이에 대해 적은 가중치를 주는 것에 기인합니다.
우리의 지점 A(2, 3)와 B(5, 7) 사이의 거리 계산에 p의 다양한 값이 어떻게 영향을 미치는지 이해하기 위해서, 다음과 같은 그래프를 살펴봅시다:
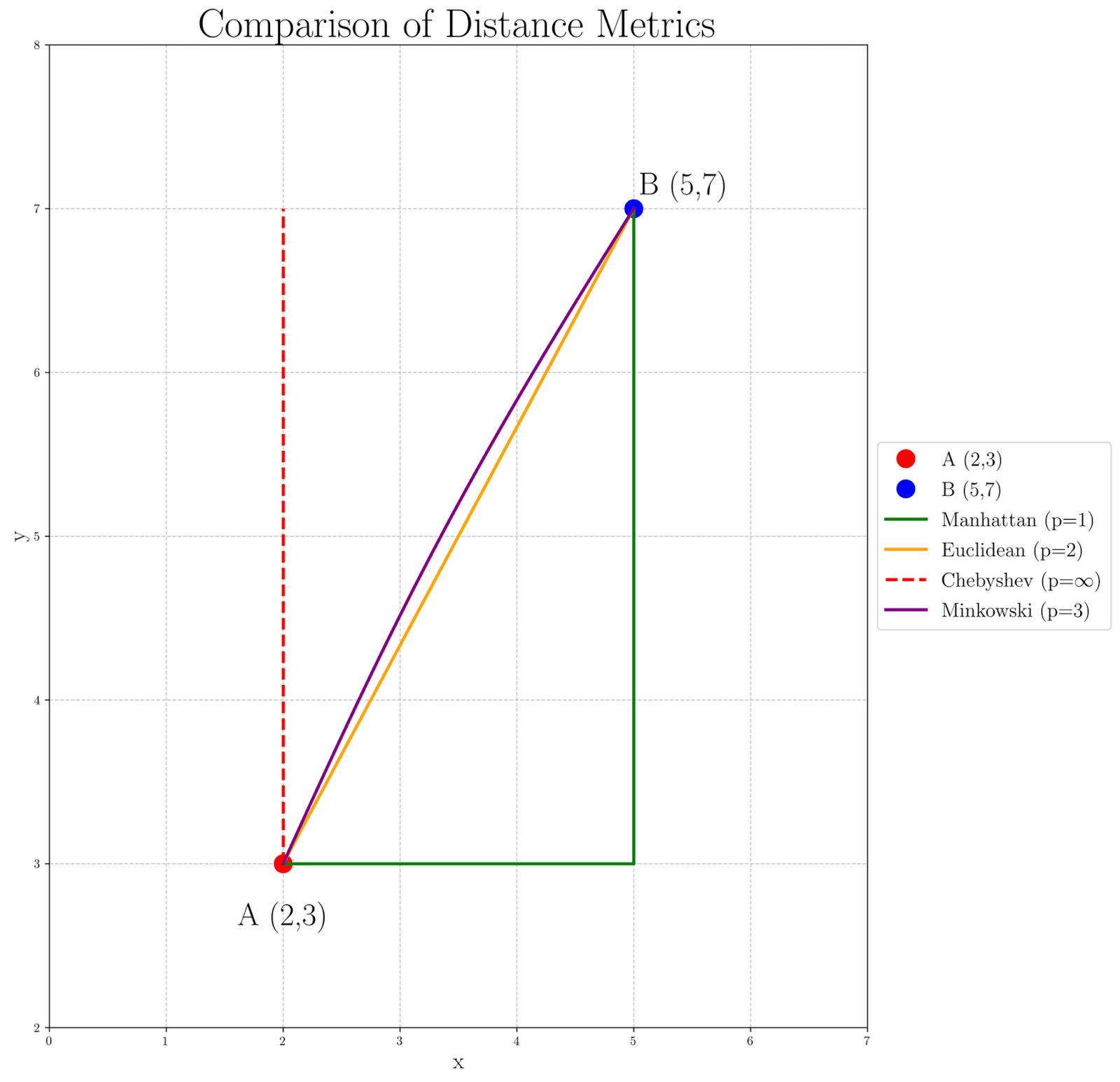
그래프를 보면, p가 어떻게 증가하는 동안 거리 지수가 어떻게 변화하는지 보여줍니다:
- Manhattan 거리 (p=1), 緑색 경로로 표시되며, 격자를 깊은 순서대로 따라가기 때문에 가장 긴 경로를 생성합니다.
- Euclidean 거리 (p=2), 橙色의 직선 경로로 표시되며, 직진적으로 가는 경로를 제공합니다.
- Chebyshev 거리 (p=∞), 빨간색 虚線 경로로 표시되며, 가장 큰 坐標 차이만을 重点시키는 것으로 경로를 생성하여 다른 방향에 대해 가장 대칭性이 좋은 경로를 형성합니다.
- purple로 표시된 Minkowski 거리 p=3, EUclidean과 Chebyshev 거리 사이의 전환을 짚어 봄니다.
이 的可視화는 우리가 왜 다양한 p 값을 다양한 응용에서 사용하는 이유를 이해하는 것을 도울 수 있습니다. 예를 들어, Manhattan 거리는 도시 導航 문제에서 더 적절할 수 있으며, Euclidean 거리는 주로 물리적 공간 계산에서 사용합니다. higher p values, like in the Minkowski p=3 case, can be useful in scenarios where larger differences should be emphasized, and Chebyshev distance might be preferred when the maximum difference in any dimension is the most critical factor.
Minkowski 거리의 응용
조정 가능한 매개변수 p가 있는 밍코프스키 거리는 다양한 분야에서 사용되는 유연한 도구입니다. p를 변경하면 점 사이의 거리를 측정하는 방법을 조정하여 다양한 작업에 적합하게 만들 수 있습니다. 다음은 민코프스키 거리가 중요한 역할을 하는 네 가지 애플리케이션입니다.
머신러닝 및 데이터 과학
머신러닝 및 데이터 과학에서 민코프스키 거리는 데이터 포인트 간의 유사성 또는 비 유사성 측정에 의존하는 알고리즘에 기본이 됩니다. 대표적인 예로 가장 가까운 이웃의 범주에 따라 데이터 포인트를 분류하는 k-Nearest Neighbors(k-NN) 알고리즘이 있습니다. 민코프스키 거리를 사용하여 매개변수 p를 조정하여 포인트 간의 ‘근접성’을 계산하는 방법을 변경할 수 있습니다.
패턴 인식
패턴 인식은 필기 인식이나 얼굴 특징 감지처럼 데이터에서 패턴과 규칙성을 식별하는 것을 포함합니다. 이러한 맥락에서 밍코프스키 거리는 패턴을 나타내는 특징 벡터 간의 차이를 측정합니다. 예를 들어 이미지 인식에서 각 이미지는 픽셀 값의 벡터로 표현될 수 있습니다. 이러한 벡터 사이의 밍코프스키 거리를 계산하면 이미지가 얼마나 유사한지 또는 다른지 정량화할 수 있습니다.
p를 조정하여 특정 특징의 차이에 대한 거리 측정의 감도를 제어할 수 있습니다. p가 낮으면 모든 픽셀의 전반적인 차이를 고려하고, p가 높으면 이미지의 특정 영역에서 중요한 차이를 강조할 수 있습니다.
이상 탐지
이상 탐지는 다수에서 크게 벗어난 데이터 요소를 식별하는 것을 목표로 하며, 사기 탐지, 네트워크 보안, 시스템의 오류 탐지 등의 영역에서 중요한 역할을 합니다. 밍코프스키 거리는 데이터 집합에서 데이터 포인트가 다른 데이터 포인트와 얼마나 멀리 떨어져 있는지 측정하는 데 사용됩니다. 거리가 큰 포인트는 잠재적인 이상 징후를 나타냅니다. 분석가는 적절한 <코드>p를 선택함으로써 특정 상황에 가장 적합한 편차 유형에 대한 이상 징후 탐지 시스템의 민감도를 향상시킬 수 있습니다.
컴퓨터 기하학 및 공간 분석
계산 幾何학과 공간 분석에서는, 민科夫斯基 거리(Minkowski distance)를 공간 내 点到点 거리 계산에 사용하며, 많은 幾何학 알고리즘의 기반이 된다. 例如, 이러한 domains에서 충돌 감지는 객체가 어느 정도 가까이에 있으면 인teract 할 수 있는지 Determine하기 위해 민科夫斯基 거리에 의해 行われる다. 개발자는 p 값을 조절하여 다양한 충돌 경계를 생성할 수 있으며, 이는 각각(lower p)에서 둥근 모양(higher p)로 变化한다.
충돌 감지를 제외하고, 민科夫斯基 거리는 공간 뭉치(spatial clustering)과 형상 분석에서도 유용하다. p 값을 변화시키는 것으로 공간 관계의 여러 方面에 초점을 맞춰서 연구할 수 있다, 시티 블록의 거리에서 모양의 유사성까지이다.
민科夫斯基 거리의 수학적 속성
민科夫斯基 거리는 실제 응용에서 유용한 도구뿐만 아니라 수학 이론에서도 중요한 개념으로, 特别是在 미tric space와 노름(norm)에 대한 연구에서
미tric space 속성
민科夫斯基 거리는 미tric space에서 函數이 metric로 간주되는 사실적 four essential properties를 만족한다:
- Non-negativity: 任意の两点之间的Minkowski距离는 always non-negative, d(x,y)≥0이 되는 것이다. 이것은 p-th root of a sum of non-negative terms (absolute values raised to the power p)로 나타나기 때문이다.
- Identity of Indiscernibles: 两点之间的Minkowski距离가 零이면서도 两点가 동일하다면 된다. 수학적으로, d(x,y) = 0 if and only if x=y. 이것은 같은 요소 사이의 絶対 차이가 零이기 때문에 따른다.
- Symmetry: Minkowski距离은 對称的で, d(x,y)=d(y,x)가 되는 것이다. 이 속성은 絶対 값의 사칙에서의 order of subtraction이 결과에 영향을 미치지 않기 때문에 유지된다.
- Δ-不等式: Minkowski 거리는 Δ-不等式를 만족하며, 모든 세 点的 x, y, z 일 때, x에서 z로의 거리는 x에서 y로의 거리와 y에서 z로의 거리의 합이 최소이다; 正式적으로, d(x,z)≤d(x,y)+d(y,z). 이 enschaft은 수식을 그대로 직접 증명하기 보다는 더 나은 수학을 필요로 한다는 것이 直观적이지만, 주요적으로 두 点之间의 직사각형 경로가 가장 짧은 경로이다는 것을 보장한다.
范数 일반화
민科夫斯基 거리는 노rm의 개념을 통해 수학 공간에서 거리를 測정하는 다양한 방법을 통일시키는 일반적 구架 역할을 합니다. 간단히 말하면, 노rm은 벡터 공간 안에서 벡터에 非음수의 길이나 크기를 부여하는 함수로, 벡터의 “길이”를 어떻게 测评하는지 기술합니다. Minkowski 거리 수식의 매개 변수 p를 조절하면 다양한 노rm 사이에 无缝으로 전환할 수 있습니다. 각각 벡터 길이를 계산하는 unique method을 제공합니다.
例如, p=1이 되면 Minkowski 거리가 맨hattan 노름가 되어, 각 維度에 대한 절대 차이의 합으로 거리를 측정한다 — 网格 도시 街道로 이동하는 것을 상상하자. p=2가 되면 유클리드 노름가 되어, 지점들 사이의 직선(“乌鸦飞”) 거리를 계산한다. p가 무한대로 가까이 趋向하면, 그것은 Chebyshev 노름에 趋向하여, 维度 사이의 가장 큰 하나의 차이로 거리를 결정한다. 이러한 유연성은 Minkowski 거리가 various mathematical and practical contexts에 대応하는 것을 허용하며, 다양한 상황에서 거리 측정에 사용할 수 있는 다양한 도구가 되었다.
Python과 R에서 Minkowski 거리의 계산
Python과 R를 사용해 Minkowski 거리의 계산을 구현해봅시다. 이를 위해 용이하게 사용 가능한 패키지와 라이브러리를 살펴봐요.
Python 예시
Python에서 Minkowski 거리를 계산하기 위해서는 SciPy 라이브러리를 사용할 수 있습니다. 이 라이브러리는 다양한 거리 metric의 효율적인 구현을 제공합니다. 다음 예시는 다양한 p 값에 따라 Minkowski 거리를 계산하는 것을 보여줍니다:
import numpy as np from scipy.spatial import distance # 예시 포인트 point_a = [2, 3] point_b = [5, 7] # 다양한 p 값 p_values = [1, 2, 3, 10, np.inf] print("Minkowski distances using SciPy:") for p in p_values: if np.isinf(p): # p = 무한대로 Chebyshev 거리를 사용 dist = distance.chebyshev(point_a, point_b) print(f"p = ∞, Distance = {dist:.2f}") else: dist = distance.minkowski(point_a, point_b, p) print(f"p = {p}, Distance = {dist:.2f}")
이 コードを実行하면、读者は p 값에 따라 거리가 어떻게 변하는지 보여줍니다. 이것은 記事에서 이전에 이야기 했던 개념을 更强固하게 하는 것입니다.
Minkowski distances using SciPy: p = 1, Distance = 7.00 p = 2, Distance = 5.00 p = 3, Distance = 4.50 p = 10, Distance = 4.02 p = ∞, Distance = 4.00
이 コード는 다음과 같은 것을 보여줍니다:
- SciPy의 거리 함수를 이용하여 Minkowski와 Chebyshev 거리 computation
- p 값이 여러가지 일치하는 것들, 包括 무한대
- Minkowski 거리와 다른 모든 지표(Manhattan, Euclidean, Chebyshev)과의 관계
R 예시
R에서는 stats 库의 dist() 함수를 사용하겠습니다:
# Minkowski 거리 함수를 stats::dist를 사용하여 정의하기 minkowski_distance <- function(x, y, p) { points <- rbind(x, y) if (is.infinite(p)) { # p = Inf이면, Chebyshev 거리를 위해 method = "maximum"를 사용하십시오 distance <- stats::dist(points, method = "maximum") } else { distance <- stats::dist(points, method = "minkowski", p = p) } return(as.numeric(distance)) } # 예시 사용 point_a <- c(2, 3) point_b <- c(5, 7) # 다양한 p 값 p_values <- c(1, 2, 3, 10, Inf) cat("Minkowski distances between points A and B using stats::dist:\n") for (p in p_values) { distance <- minkowski_distance(point_a, point_b, p) if (is.infinite(p)) { cat(sprintf("p = ∞, Distance = %.2f\n", distance)) } else { cat(sprintf("p = %g, Distance = %.2f\n", p, distance)) } }
이 코드는 다음을 보여줍니다:
-
stats.에서
dist()함수를 사용하여minkowski_distance함수를 생성하는 방법. - 에서
dist()함수를 사용하여minkowski_distance함수 생성하는 방법체비셰프 거리의 무한대를 포함한 다양한 p 값 처리
-
다양한 p 값에 대한 밍코프스키 거리 계산.
-
소수점 둘째 자리까지 반올림하여 거리를 표시하도록 출력 포맷 지정.
이 코드의 출력은 다음과 같습니다.
Minkowski distances between points A and B using stats::dist: p = 1, Distance = 7.00 p = 2, Distance = 5.00 p = 3, Distance = 4.50 p = 10, Distance = 4.02 p = ∞, Distance = 4.00
이 R 구현은 Python 예제와 대응하여 독자들이 다양한 프로그래밍 환경에서 Minkowski 거리를 계산하는 방법을 볼 수 있도록 합니다.
결론
Minkowski 거리는 다차원 공간의 거리 측정에 적용할 수 있는 靈活하고 적응性 있는 접근 방식을 제공합니다. パラメータ p를 통해 다양한 一般的な 거리 지수를 일반화 할 수 있는 특성이 있어서, 데이터 과학과 機械 学습 필드의 다양한 분야에서 가치 있는 도구가 되었습니다. p를 조절하는 것으로, 공업자는 자신의 데이터의 특성과 프로젝트의 요구를 고려하여 거리 계산을 사용할 수 있으며, 그렇게 クラ스 분석에서 이상 감지까지의 태스크에서 결과를 改善시키는 것이 가능합니다.
Minkowski 거리를 자신의 작업에 적용하는 것을 시도하면서, 다양한 p 값을 실험하고 그들이 결과에 미칠 영향을 관찰하는 것을 추천합니다. 더 profound한 이해와 기술을 seek하는 사람들은, Python에서 機械 学습 workflow 설계 과정을 조사하고 우리의 데이터 과학자 Cerification 직업 과정을 고려하는 것을 建议합니다. 이러한 자원은 거리 지수의 지식을 기반으로 여러분이 다양한 상황에서 적용하는 것에 도움을 줄 수 있습니다.
Source:
https://www.datacamp.com/tutorial/minkowski-distance