













귀사의 경영진은 회사의 재무와 생산성에 대해 모든 것을 알고 싶지만 최고급 IT 관리 도구에는 돈을 투자하지 않을까요? 재고, 청구 및 티켓 시스템을 위해 다른 도구를 사용하는 일을 피하세요. 한 가지 중앙 시스템만 필요합니다. Power BI Python을 고려해보는 것은 어떨까요?
Power BI는 지루하고 시간이 많이 소요되는 작업을 자동화할 수 있습니다. 이 자습서에서는 데이터를 잘라내고 결합하는 방법을 배울 수 있습니다.
과도한 보고서를 직접 확인하는 스트레스에서 벗어나세요!
사전 준비 사항
이 자습서는 실습을 통해 진행됩니다. 함께 따라하려면 다음 사항을 확인해야 합니다:
- Power BI 구독 – 무료 평가판을 사용하면 됩니다.
- A Windows Server – This tutorial uses a Windows Server 2022.
- Windows Server에 설치된 Power BI Desktop – 이 자습서에서는 Power BI Desktop v2.105.664.0을 사용합니다.
- 설치된 MySQL Server – 이 자습서에서는 MySQL Server v8.0.29를 사용합니다.
- 데스크톱 버전을 사용할 외부 장치에 온프레미스 데이터 게이트웨이가 설치되어 있어야 합니다.
- Visual Studio Code (VS Code) – 이 튜토리얼은 VS Code v17.2를 사용합니다.
- Python v3.6 이상이 설치되어 있어야 함 – 이 튜토리얼은 Python v3.10.5를 사용합니다.
- DBeaver가 설치되어 있어야 함 – 이 튜토리얼은 DBeaver v22.0.2를 사용합니다.
MySQL 데이터베이스를 구축합니다.
Power BI는 데이터를 아름답게 시각화할 수 있지만 시각화하기 전에 데이터를 가져와 저장해야 합니다. 데이터를 저장하는 가장 좋은 방법 중 하나는 데이터베이스에 저장하는 것입니다. MySQL은 무료이며 강력한 데이터베이스 도구입니다.
1. 관리자 권한으로 명령 프롬프트를 엽니다. 아래의 mysql 명령을 실행하고 프롬프트가 나타날 때 루트 사용자 이름 (-u)과 암호 (-p)를 입력합니다.
기본적으로 루트 사용자만 데이터베이스에 변경을 할 수 있는 권한이 있습니다.
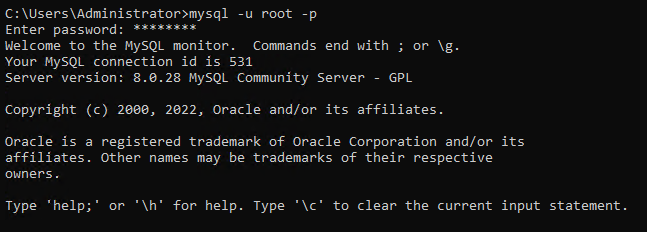
2. 다음으로 아래 쿼리를 실행하여 새로운 데이터베이스 사용자 (CREATE USER)를 비밀번호 (IDENTIFIED BY)와 함께 생성하십시오. 사용자 이름을 다르게 지정할 수 있지만, 이 튜토리얼에서는 ata_levi로 선택하였습니다.

3. 사용자를 생성한 후에는 아래 쿼리를 실행하여 새 사용자에게 모든 권한 (ALL PRIVILEGES)을 부여하십시오. 이는 서버에서 데이터베이스를 만들 수 있는 권한과 같습니다.

4. 이제 MySQL에서 로그아웃하기 위해 아래의 \q 명령을 실행하십시오.

5. 새로 생성된 데이터베이스 사용자(ata_levi)로 로그인하기 위해 아래의 mysql 명령을 실행하십시오.
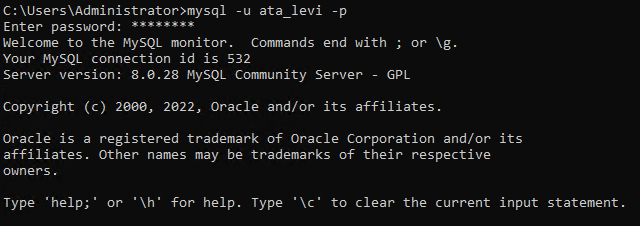
6. 마지막으로, 아래의 쿼리를 실행하여 ata_database라는 새로운 데이터베이스를 생성하십시오. 물론 데이터베이스의 이름은 다르게 지정할 수 있습니다.

DBeaver를 사용하여 MySQL 데이터베이스 관리하기
데이터베이스를 관리할 때 일반적으로 SQL 지식이 필요합니다. 그러나 DBeaver를 사용하면 몇 번의 클릭으로 데이터베이스를 관리할 수 있으며, DBeaver가 SQL 문을 대신 처리해줍니다.
1. 데스크톱 또는 시작 메뉴에서 DBeaver를 엽니다.
2. DBeaver가 열리면 “New Database Connection” 드롭다운을 클릭하고 MySQL을 선택하여 MySQL 서버에 연결을 시작하십시오.
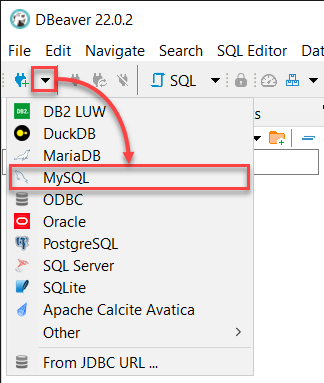
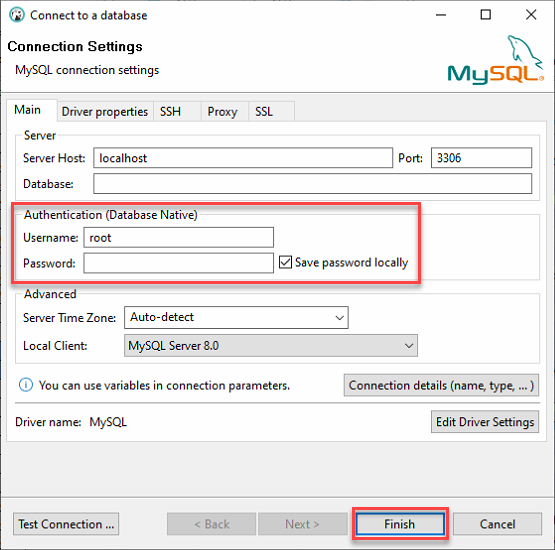
3. 다음과 같이 로컬 MySQL 서버에 로그인하십시오:
- Server Host를 localhost로, Port를 3306으로 유지하십시오. 이는 로컬 서버에 연결하는 것입니다.
- 2단계에서 “MySQL 데이터베이스 구축” 섹션에서 제공된 ata_levi 사용자의 자격 증명(사용자 이름 및 비밀번호)을 입력하고 완료를 클릭하여 MySQL에 로그인하십시오.
4. 이제 데이터베이스(Navigator) 아래의 데이터베이스(ata_database)를 확장하십시오. (왼쪽 패널) → 테이블에서 오른쪽으로 마우스 오른쪽 단추를 클릭하고 새 테이블 만들기를 선택하여 새 테이블을 만드세요.
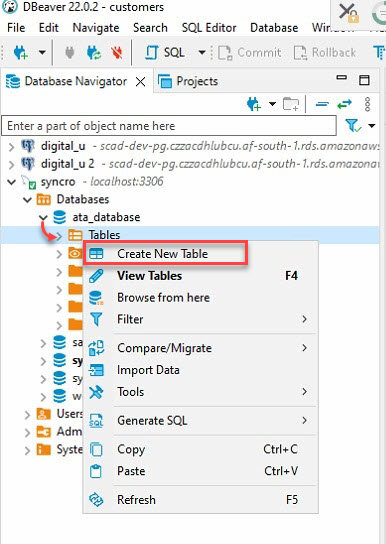
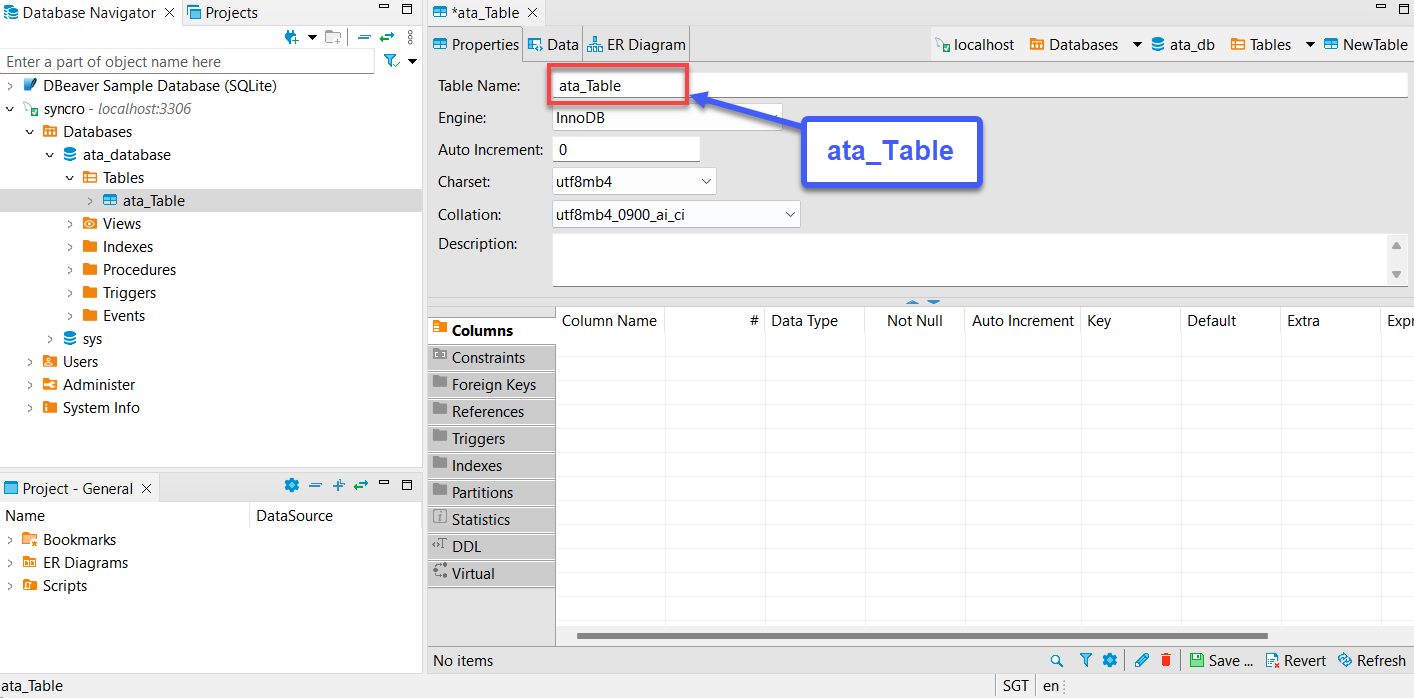
5. 새 테이블에 이름을 지정하되, 본 자습서의 선택은 ata_Table입니다. 아래에 표시된 대로 선택하세요.
새 테이블 이름이 “to_sql(‘테이블 이름’)” 단계의 “API 데이터 가져오기 및 사용하기” 섹션에서 지정할 테이블 이름과 일치하는지 확인하세요.
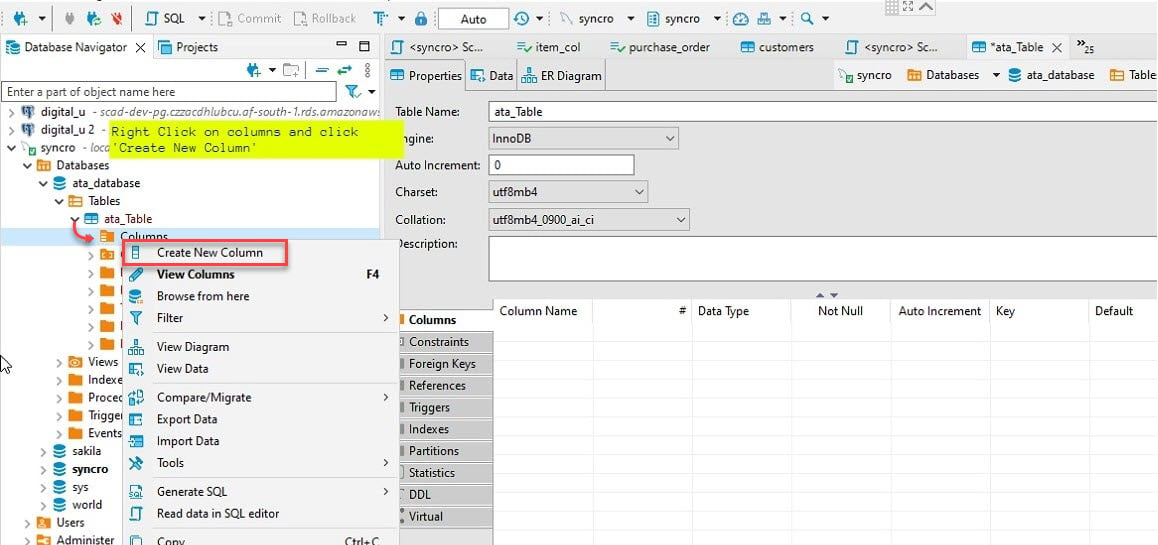
6. 이제 새 테이블(ata_table)을 확장하십시오. → 오른쪽 단추로 열 → 새 열 만들기를 선택하여 새 열을 만드세요.
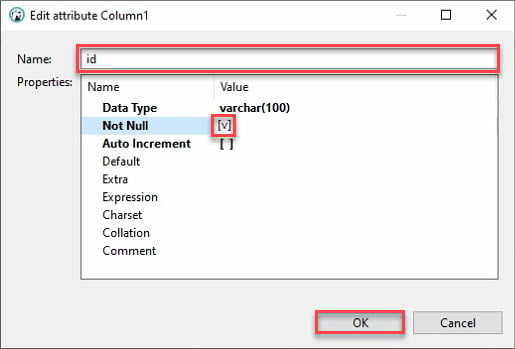
7. 새 열을 만들려면 열 이름을 제공하고 아래에 표시된 대로 Not Null 상자를 선택하고 확인을 클릭하세요.
이상적으로는 “id”라는 열을 추가하고 싶을 것입니다. 왜냐하면 대부분의 API에는 id가 있고 Python의 판다 데이터 프레임이 다른 열을 자동으로 채울 것이기 때문입니다.
8. 변경 사항을 확인한 후 저장(우측 하단)을 클릭하거나 Ctrl+S를 눌러 변경 사항을 저장하세요.
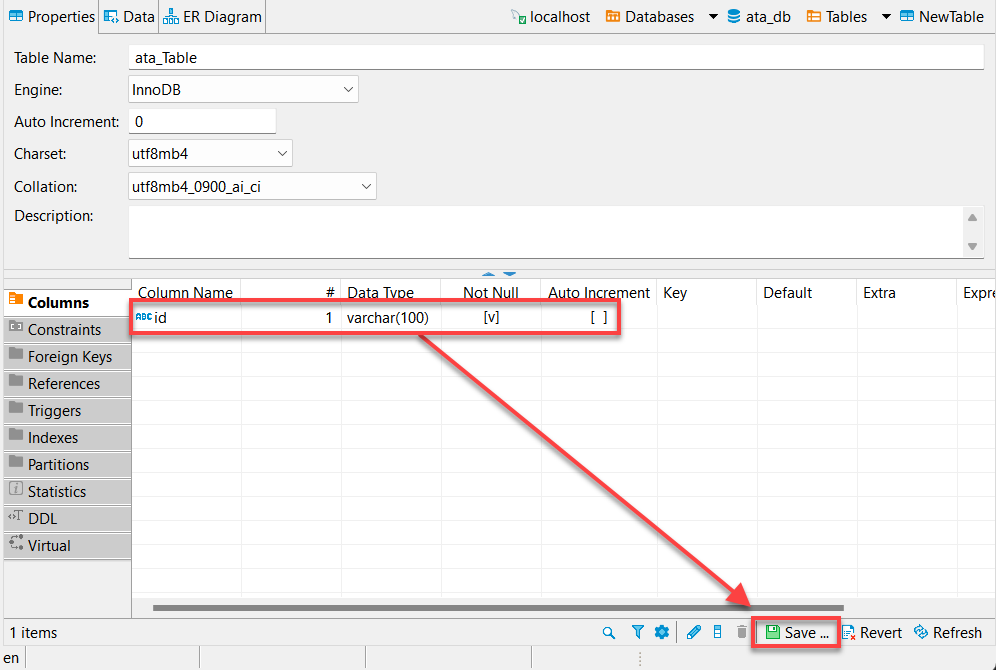
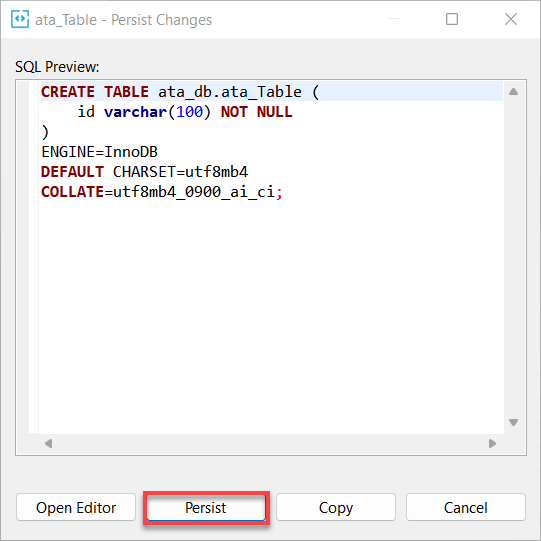
9. 마지막으로 변경한 내용을 영속화하려면 저장(우측 하단)을 클릭하세요.
API 데이터 가져오기 및 사용하기
데이터를 저장할 데이터베이스를 만들었으므로 해당 API 제공 업체에서 데이터를 가져와 Python을 사용하여 데이터베이스에 넣어야 합니다. Power BI에서 시각화할 데이터를 소스로 사용하게 될 것입니다.
API 제공 업체에 연결하려면 권한 부여 방법, API 기본 URL 및 API 엔드포인트의 세 가지 핵심 정보가 필요합니다. 이 정보에 대해 확실하지 않으면 API 제공 업체의 문서 사이트를 방문하세요.
다음은 Syncro의 문서 페이지입니다.
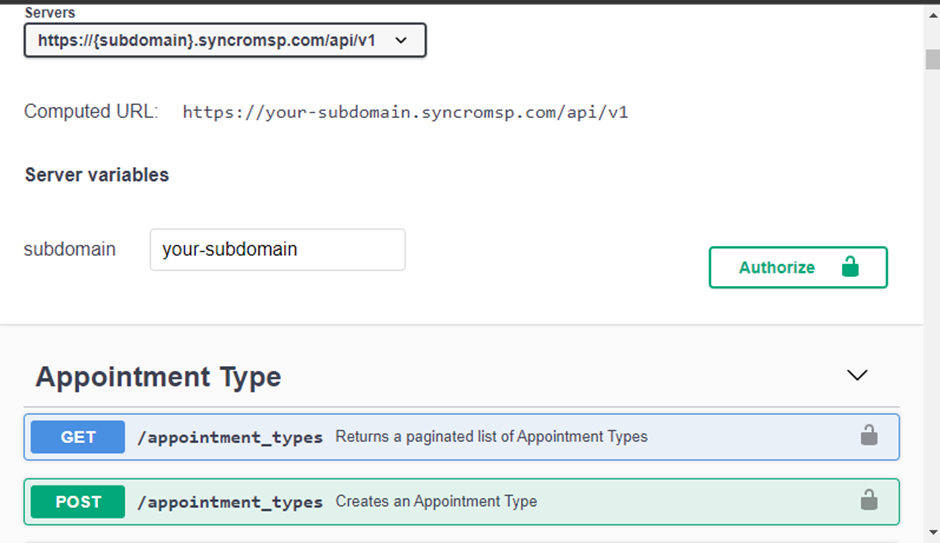
1. VS Code를 열고 Python 파일을 만들고 파일을 API 데이터에서 기대하는대로 명명합니다. 이 파일은 API 데이터를 데이터베이스에 가져오고 푸시하는 역할을 담당할 것입니다 (데이터베이스 연결).
데이터베이스 연결에 도움을 주는 여러 Python 라이브러리가 있지만, 이 튜토리얼에서는 SQLAalchemy를 사용합니다.
아래의 pip 명령을 VS Code의 터미널에서 실행하여 환경에 SQLAalchemy를 설치하십시오.

2. 그 다음, connection.py라는 파일을 만들고 아래의 코드를 채우고 값을 적절히 바꾼 다음 파일을 저장하십시오.
데이터베이스와 통신하는 스크립트를 작성하기 시작하면 데이터베이스가 명령을 수락하기 전에 데이터베이스에 대한 연결이 설정되어야 합니다.
그러나 모든 스크립트를 작성할 때마다 데이터베이스 연결 문자열을 다시 작성하는 대신, 아래의 코드는 다른 스크립트에서 호출/참조할 수 있도록이 연결을 만드는 데 전용되어 있습니다.
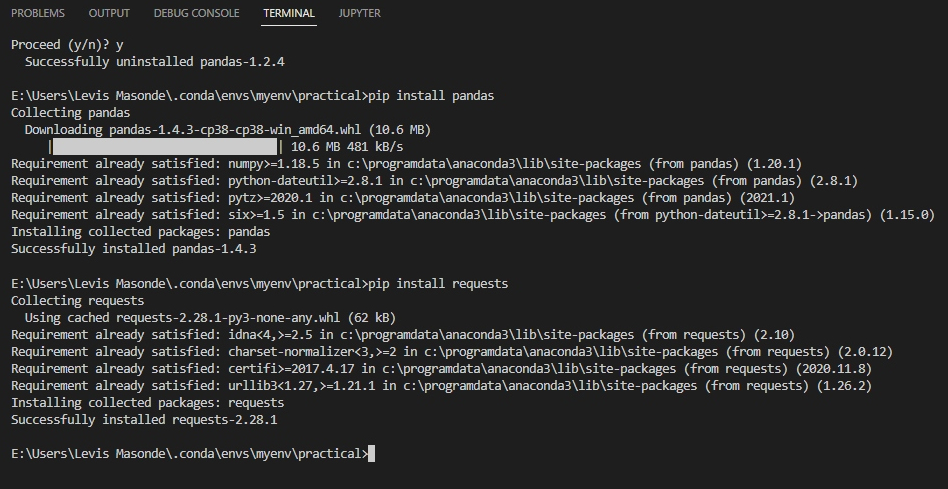
3. Visual Studio의 터미널을 엽니다 (Ctrl+Shift+`), 그리고 아래 명령어를 실행하여 pandas와 requests를 설치합니다.
4. 다른 Python 파일을 만들고 invoices.py라고 이름 짓습니다 (또는 다른 이름으로 지정할 수 있습니다), 그리고 아래 코드를 파일에 채웁니다.
향후 각 단계에서 invoices.py 파일에 코드 조각을 추가할 수 있지만, 전체 코드는 ATA의 GitHub에서 확인할 수 있습니다.
invoices.py 스크립트는 다음 섹션에서 설명하는 주 스크립트에서 실행됩니다. 이 주 스크립트는 처음 API 데이터를 가져옵니다.
아래 코드는 다음을 수행합니다:
- API에서 데이터를 소비하고 데이터베이스에 기록합니다.
- 인증 방법, 키, 기본 URL 및 API 엔드포인트를 API 제공자 자격 증명으로 바꿉니다.
5. 아래 코드 조각을 invoices.py 파일에 추가하여 헤더를 정의합니다. 예를 들어:
- API에서 예상하는 데이터 형식입니다.
- 기본 URL 및 엔드포인트는 해당 키와 인증 방법과 함께 제공되어야 합니다.
아래 값을 귀사의 것으로 변경하십시오.
6. 다음으로, 다음 비동기 함수를 invoices.py 파일에 추가하십시오.
아래 코드는 AsyncIO를 사용하여 한 개의 메인 스크립트에서 여러 스크립트를 관리합니다. 프로젝트가 여러 API 엔드포인트를 포함하게 되면 API 소비 스크립트를 자체 파일로 가지는 것이 좋은 실습 방법입니다.
7. 마지막으로, API의 페이지네이션을 처리하는 get_pages 함수가 있는 invoices.py 파일에 아래 코드를 추가하십시오.
이 함수는 API의 총 페이지 수를 반환하고 range 함수가 모든 페이지를 반복할 수 있도록 돕습니다.
API 제공 업체의 페이지네이션 방법에 대해 API 개발자에게 문의하십시오.
데이터에 더 많은 API 엔드포인트를 추가하려면:
- “DBeaver로 MySQL 데이터베이스 관리” 섹션의 네 번째부터 여섯 번째 단계를 반복하십시오.
- “API 데이터 가져오기 및 사용” 섹션의 모든 단계를 반복하십시오.
- 다른 사용하려는 API 엔드포인트로 API 엔드포인트 변경.
API 엔드포인트 동기화
이제 데이터베이스와 API 연결이 준비되었으며, invoices.py 파일의 코드를 실행하여 API 소비를 시작할 준비가되었습니다. 그러나 이렇게하면 동시에 하나의 API 엔드포인트만 사용할 수 있습니다.
한계를 넘어가는 방법은 무엇인가요? 여러 Python 파일에서 API 함수를 호출하고 AsyncIO를 사용하여 함수를 비동기적으로 실행하는 중앙 파일로서 다른 Python 파일에서 API 함수를 호출하는 방법을 알려드리겠습니다. 이렇게 하면 프로그래밍이 깔끔하게 유지되며 여러 함수를 번들로 묶을 수 있습니다.
1. central.py라는 새로운 Python 파일을 만들고 아래의 코드를 추가하세요.
invoices.py 파일과 비슷하게 central.py 파일에 각 단계마다 코드 조각을 추가하지만 전체 코드는 ATA의 GitHub에서 확인할 수 있습니다.
아래의 코드는 필수 모듈 및 다른 파일에서 from <filename> import <function name> 구문을 사용하여 스크립트를 가져옵니다.
2. 다음으로, invoices.py의 스크립트를 central.py 파일에서 제어하기 위해 다음 코드를 추가하세요.
invoices.py에서 call_invoices 함수를 central.py에서의 AsyncIO 작업(invoice_task)에 참조/호출해야 합니다.
3. AsyncIO 작업을 생성한 후, 체인 함수(단계 두에서)가 실행되기 시작할 때 invoice.py에서 call_invoices 함수를 가져와 실행하는 작업을 기다립니다.
4. AsyncIOScheduler를 만들어 스크립트를 실행할 작업을 예약합니다. 이 코드에서 추가된 작업은 1초 간격으로 체인 함수를 실행합니다.
이 작업은 프로그램이 데이터를 최신 상태로 유지하기 위해 스크립트를 계속 실행하는 것을 보장하는 데 중요합니다.
5. 마지막으로, 아래에 표시된대로 VS Code에서 central.py 스크립트를 실행합니다.
스크립트를 실행한 후에는 아래처럼 터미널에서 출력을 확인할 수 있습니다.
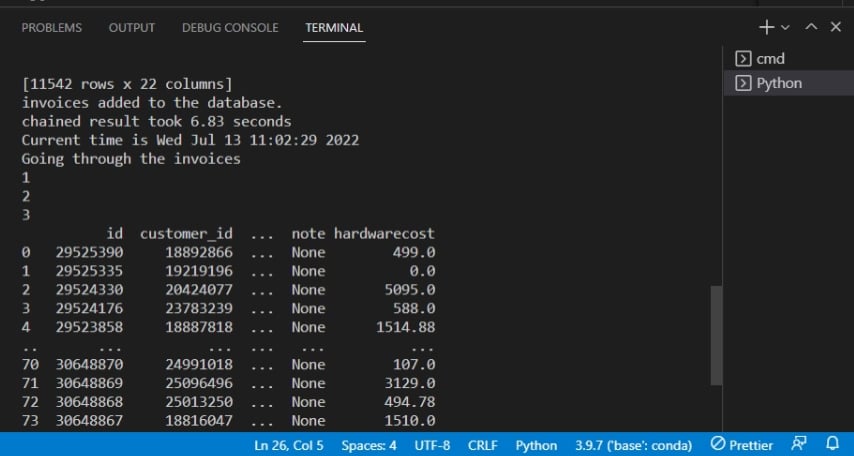
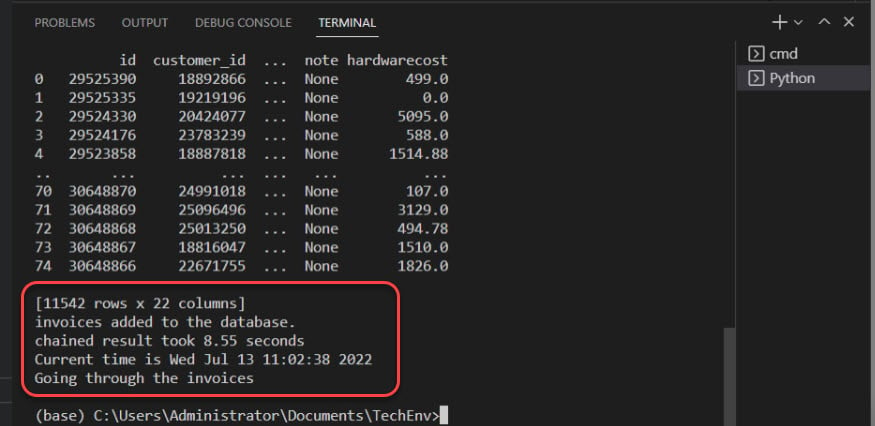
아래에서 출력은 데이터베이스에 인보이스가 추가되었음을 확인합니다.
Power BI Visuals 개발
API 데이터에 연결하고 사용하고 데이터를 데이터베이스에 푸시하는 프로그램을 코딩한 후에는 거의 데이터를 수확할 준비가되었습니다. 그러나 먼저 데이터베이스의 데이터를 시각화를위한 Power BI로 푸시합니다, 최종 목표입니다.
많은 양의 데이터가 있더라도 데이터를 시각화하고 깊은 연결을 만들지 못하면 무용지물입니다. 다행스럽게도, Power BI 비주얼은 그래프가 복잡한 수학 방정식을 간단하고 예측 가능하게 만드는 방법과 같습니다.
1. 데스크톱이나 시작 메뉴에서 Power BI를 엽니다.
2. 파워 BI의 주 창에 있는 데이터 가져오기 드롭다운 위의 데이터 소스 아이콘을 클릭하십시오. 팝업 창이 나타나며, 여기에서 사용할 데이터 소스를 선택할 수 있습니다 (3단계).
3. mysql을 검색하고 MySQL 데이터베이스를 선택한 다음, MySQL 데이터베이스에 연결을 시작하려면 연결을 클릭하십시오.
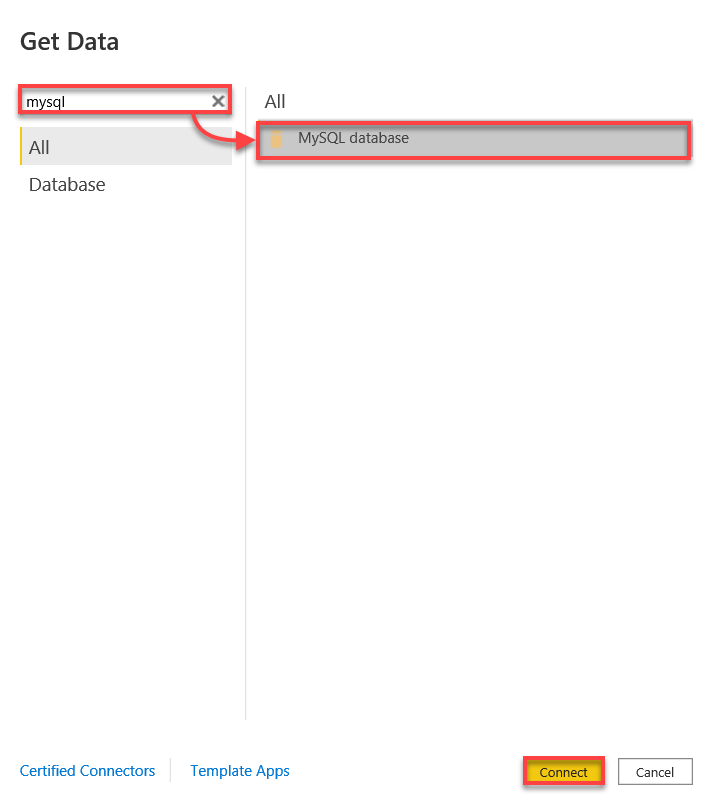
4. 이제 다음과 같이 MySQL 데이터베이스에 연결하십시오:
- 로컬 MySQL 서버의 포트 3306에 연결하므로 localhost:3306을 입력하십시오.
- 데이터베이스의 이름을 제공하십시오. 이 경우에는 ata_db입니다.
- MySQL 데이터베이스에 연결하려면 확인을 클릭하십시오.

5. 이제 데이터 개요를 보려면 데이터 변환을 클릭하십시오 (오른쪽 아래) (5단계에서 파워 BI의 쿼리 편집기에서).

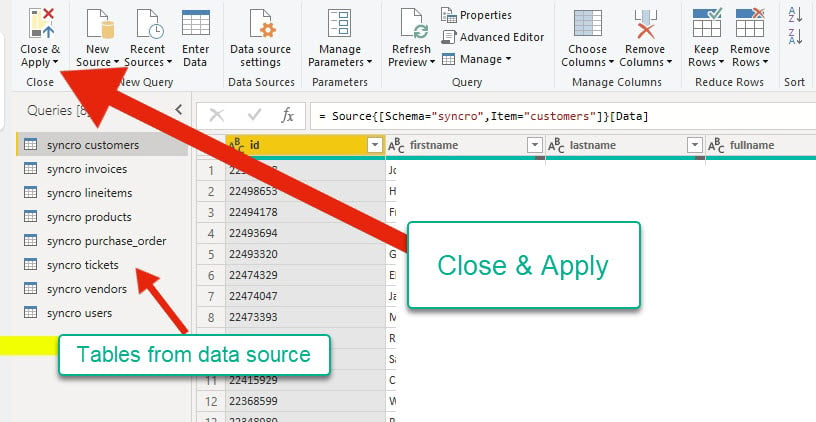
6. 데이터 소스를 미리보고 난 후, Close & Apply를 클릭하여 기본 응용 프로그램으로 돌아가고 변경 사항이 적용되었는지 확인하십시오.
쿼리 편집기는 데이터 소스의 테이블을 왼쪽에서 표시합니다. 동시에 주 응용 프로그램으로 진행하기 전에 데이터의 형식을 확인할 수 있습니다.
7. 테이블 도구 리본 탭을 클릭하고 필드 패널에서 테이블을 선택한 다음, 관계 관리를 클릭하여 관계 마법사를 엽니다.
시각화를 생성하기 전에 테이블 간의 관계가 설정되어 있는지 확인해야 합니다. 왜냐하면 파워 BI는 복잡한 테이블 상관 관계를 자동으로 감지하지 못하기 때문입니다.

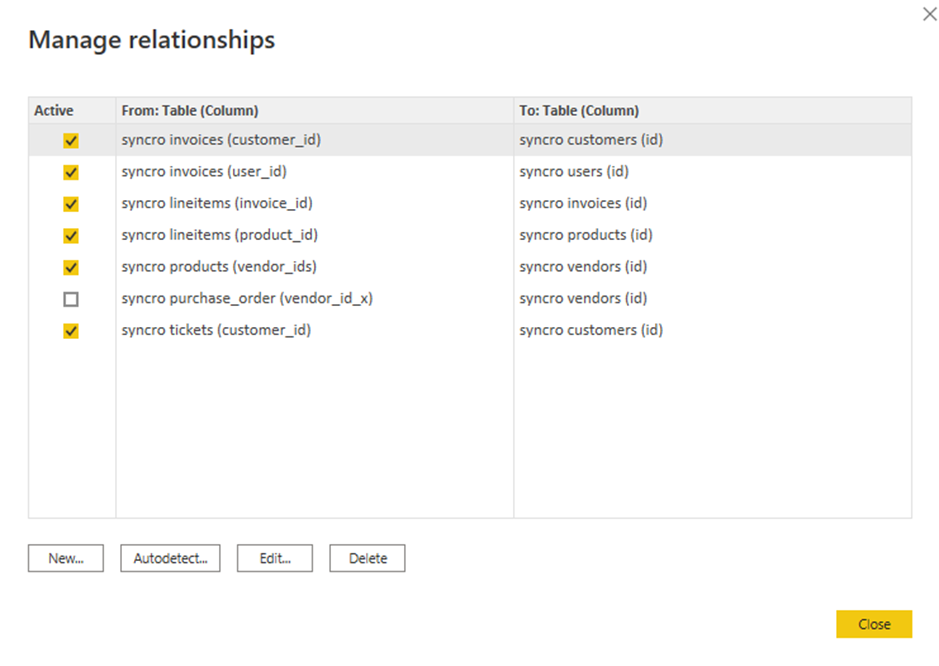
8. 편집하려는 기존 관계 상자에 체크를 하고, 편집을 클릭하십시오. 팝업 창이 나타나며, 선택한 관계를 편집할 수 있습니다 (9단계).
하지만 새로운 관계를 추가하려면 새로 만을 클릭하세요.
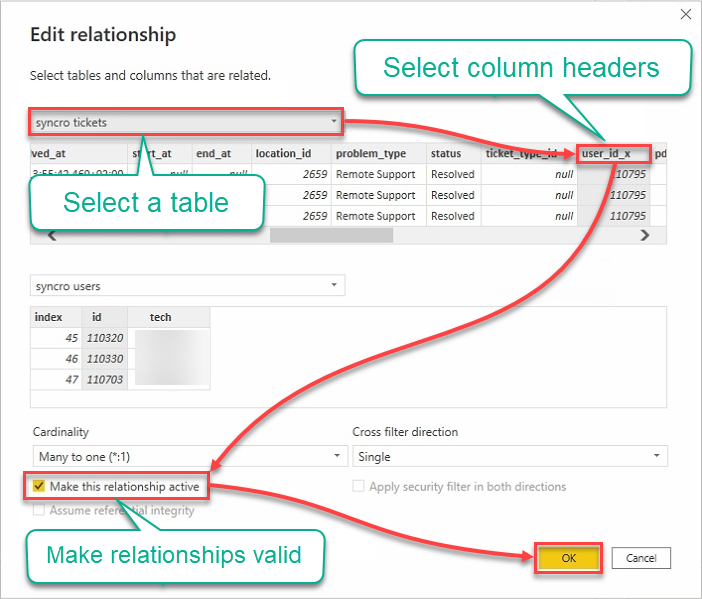
9. 다음과 같이 관계를 편집하십시오:
- 테이블 드롭다운 필드를 클릭하고 테이블을 선택하십시오.
- 사용할 열을 선택하려면 헤더를 클릭하십시오.
- 관계를 활성화하려면 이 관계를 활성화 상자를 선택하십시오.
- 관계를 설정하고 편집 관계 창을 닫으려면 확인을 클릭하십시오.
10. 이제 첫 번째 시각적 표를 만들려면 시각화 창 (가장 오른쪽)에서 테이블 시각 유형을 클릭하십시오. 빈 테이블 시각이 나타납니다 (단계 11).
11. 테이블 시각과 데이터 필드 (필드 창에 표시됨)를 선택하여 테이블 시각에 추가하십시오. 아래 그림과 같이.
12. 마지막으로, 다른 시각적 표를 추가하려면 슬라이서 시각 유형을 클릭하십시오. 이름에서 알 수 있듯이, 슬라이서 시각은 다른 시각적 요소를 필터링하여 데이터를 슬라이스합니다.
슬라이서를 추가한 후에는 필드 창에서 데이터를 선택하여 슬라이서 시각에 추가하십시오.
시각 변경
기본 시각의 외관은 꽤 괜찮습니다. 그러나 시각적 외관을 조금 덜 단조롭게 변경할 수 있다면 어떨까요? Power BI가 그 일을 해줄 것입니다.
시각화에 액세스하려면 시각화 아이콘을 클릭하고 아래와 같이 시각화 편집기에 액세스하십시오.
원하는 시각적 외관을 얻기 위해 시각화 설정을 조정하는 데 시간을 할애하십시오. 시각적 요소 간에 관계를 설정하는 한 시각화는 상관 관계가 있을 것입니다.
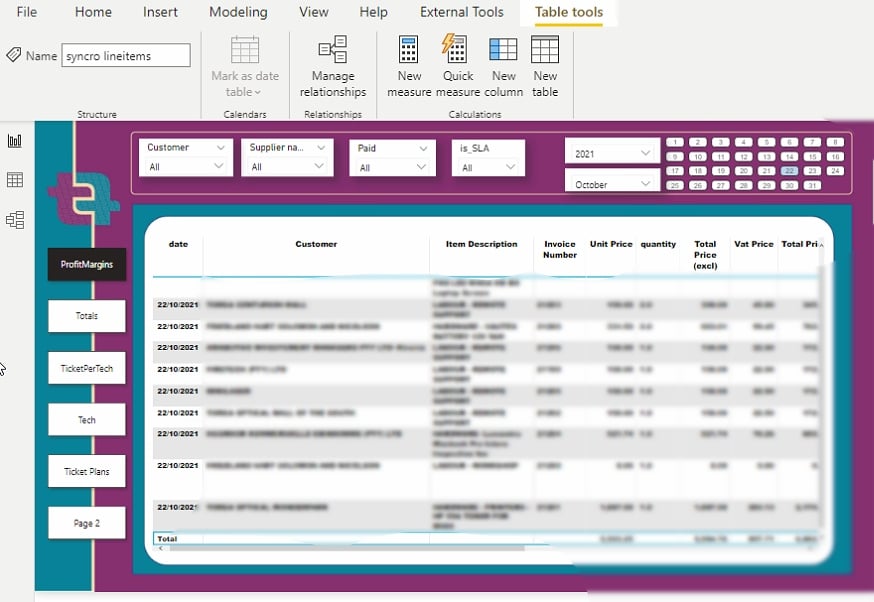
시각화 설정을 변경한 후에는 다음과 같은 리포트를 추출할 수 있습니다.
이제 복잡하지 않고 눈을 아프게 하지 않고 데이터를 시각화하고 분석할 수 있습니다.
다음 시각화를 통해 트렌드 그래프를 살펴보면, 2020년 4월에 무언가 잘못되었다는 것을 알 수 있습니다. 그 시기에는 코로나19로 인한 봉쇄가 처음으로 남아프리카를 강타했습니다.
이 결과는 Power BI가 정확한 데이터 시각화를 제공하는 능력을 입증합니다.

결론
본 자습서는 API 엔드포인트에서 데이터를 가져와 실시간 동적 데이터 파이프라인을 구축하는 방법을 보여주고 있습니다. 추가로 Python을 사용하여 데이터를 처리하고 데이터베이스와 Power BI로 데이터를 전송합니다. 이 새로운 지식으로 이제 API 데이터를 소비하고 자체 데이터 시각화를 만들 수 있습니다.
더 많은 기업이 Restful API 웹 앱을 생성하고 있습니다. 그리고 이 시점에서 Python을 사용하여 API를 소비하고 Power BI로 데이터 시각화를 만드는 데 자신감을 가지고 있으므로 이는 비즈니스 결정에 영향을 줄 수 있습니다.