













당신의 원시 데이터를 조직화된 행동 가능한 정보로 변환하는 것은 복잡해 보일 수 있습니다. 하지만 빠르고 효율적인 솔루션이 있다면 그렇지 않습니다. 걱정하지 마세요! 이 초보자 친화적인 AWS Glue 튜토리얼이 당신을 지원할 것입니다.
이 튜토리얼에서는 AWS Glue를 사용하여 데이터 변환을 구성하고 실행하는 중요한 단계를 배우게 됩니다.
클라우드 기반 분석을 위한 데이터 준비를 탐색하고 간소화하세요!
사전 요구 사항
AWS Glue를 사용하기 전에, 활성화된 Amazon Web Services (AWS) 계정과 결제가 가능한 상태인지 확인하세요. 이 튜토리얼에는 무료 계정이면 충분합니다.
AWS Glue를 위한 IAM 역할 생성
변환 작업을 실행하기 전에, AWS Glue 서비스에 대한 허가를 부여하는 Identity and Access Management (IAM) 역할을 생성해야 합니다. 이 역할은 AWS Glue가 귀하의 AWS 계정에서 어떤 유형의 리소스에 액세스할 수 있는지를 정의합니다.
IAM 역할을 생성하려면 아래 단계를 따르세요:
1. 선호하는 웹 브라우저를 열고 AWS 관리 콘솔에 로그인하세요.
2. 결과 목록에서 IAM을 검색하고 선택하여 IAM 콘솔에 액세스합니다.
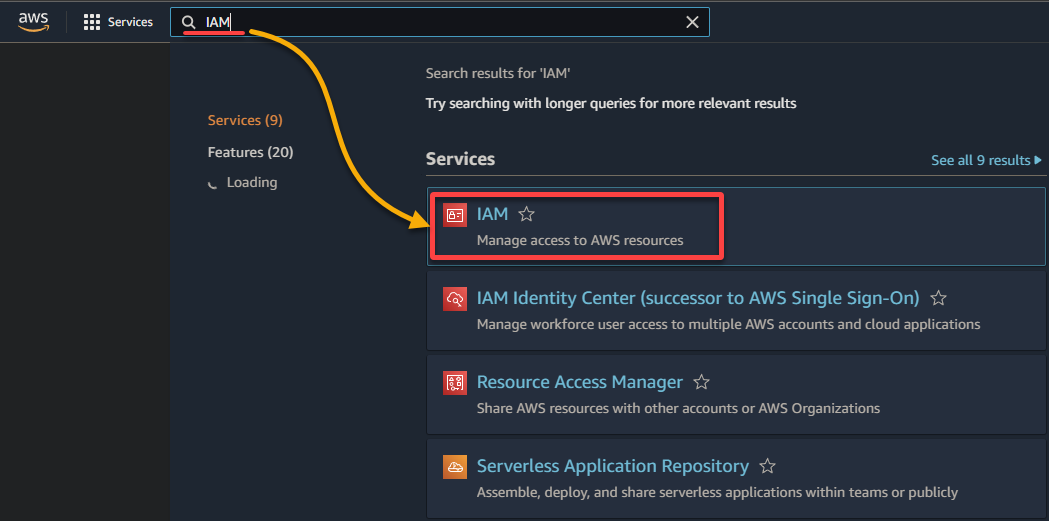
3. IAM 콘솔에서 왼쪽 창의 역할로 이동하고 오른쪽 상단의 역할 생성을 클릭하여 역할을 구성하는 새로운 페이지로 이동합니다.

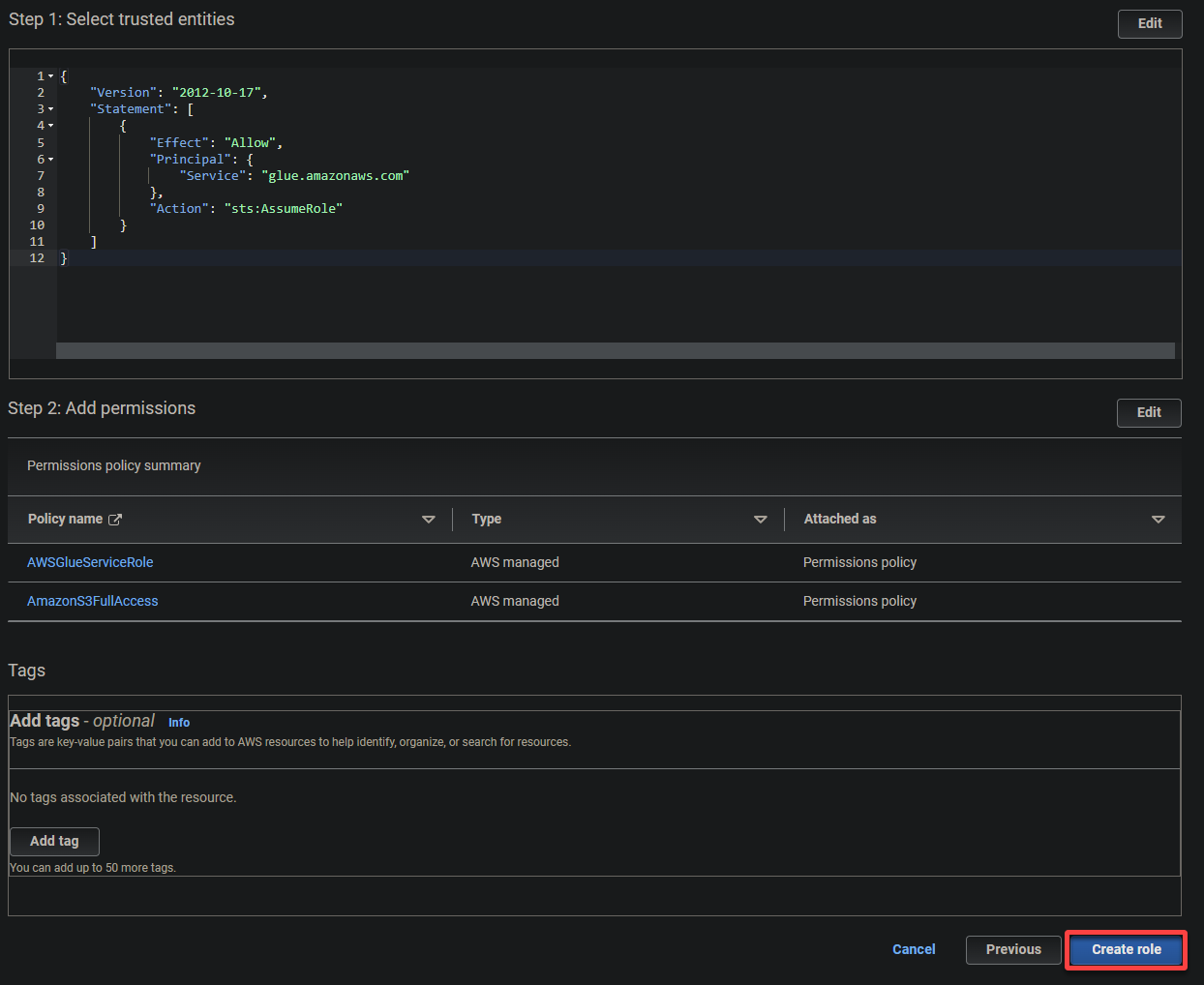
4. 이제 역할에 대한 다음 설정을 구성합니다:
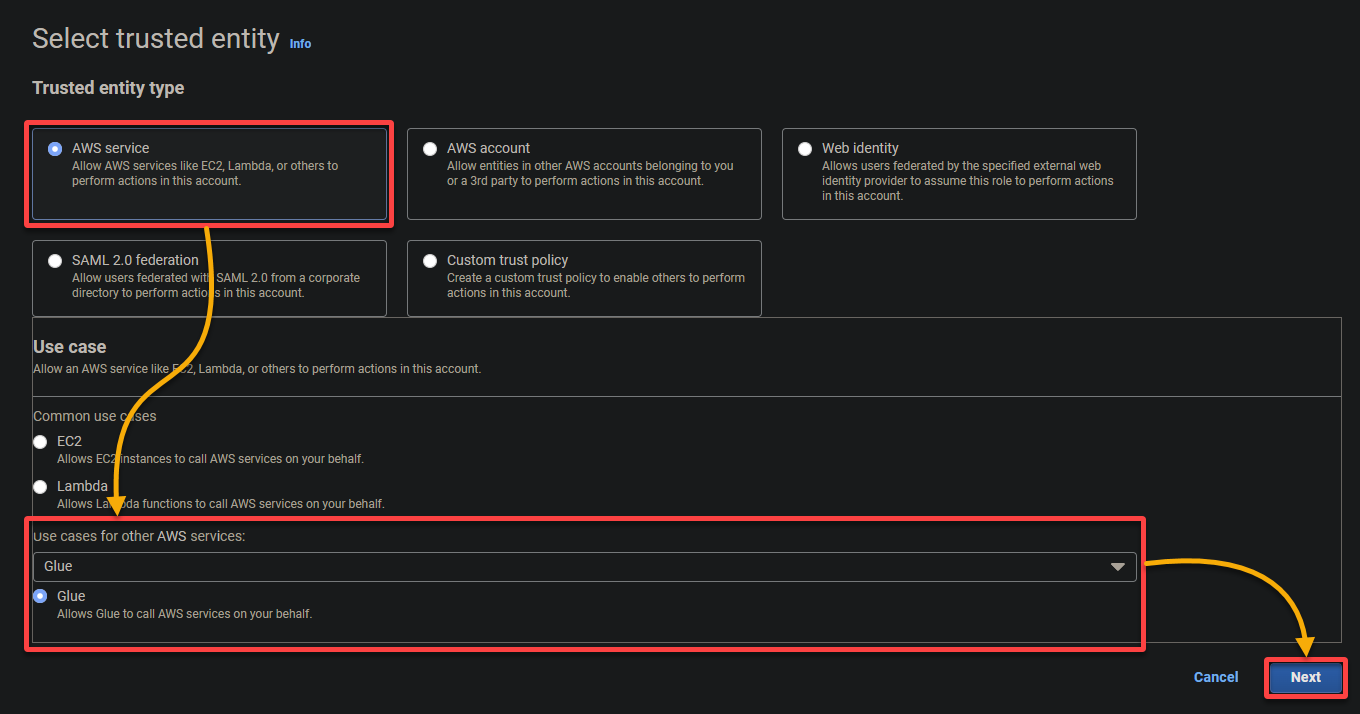
- 신뢰할 수 있는 엔티티 유형 – AWS 서비스를 선택하여 AWS 서비스가 역할을 신뢰하도록 설정합니다. 이렇게 하면 해당 서비스가 역할을 취할 수 있고 사용자 대신 작업을 수행할 수 있습니다.
- 사용 사례 – 다른 AWS 서비스를 위한 사용 사례 섹션에서 Glue를 선택하여 IAM 역할을 AWS Glue에 특정하고 다음을 클릭합니다.
5. 다음 정책을 검색하고 선택한 후 다음을 클릭합니다.
- AWSGlueServiceRole – AWS Glue 서비스가 작업을 수행하는 데 필요한 권한을 부여합니다.
- S3FullAccess – S3 리소스에 대한 완전한 액세스 권한을 부여하여 AWS Glue가 S3 버킷에서 읽고 쓸 수 있게 합니다.
AWS Glue는 데이터 추출, 변환 및 로딩 (ETL) 작업을 효과적으로 수행하기 위해 S3 버킷에서 읽고 쓰는 데에 대한 광범위한 권한이 필요합니다.
? 보안 위험을 초래할 수 있는 불필요한 과도한 권한 부여를 피하십시오.
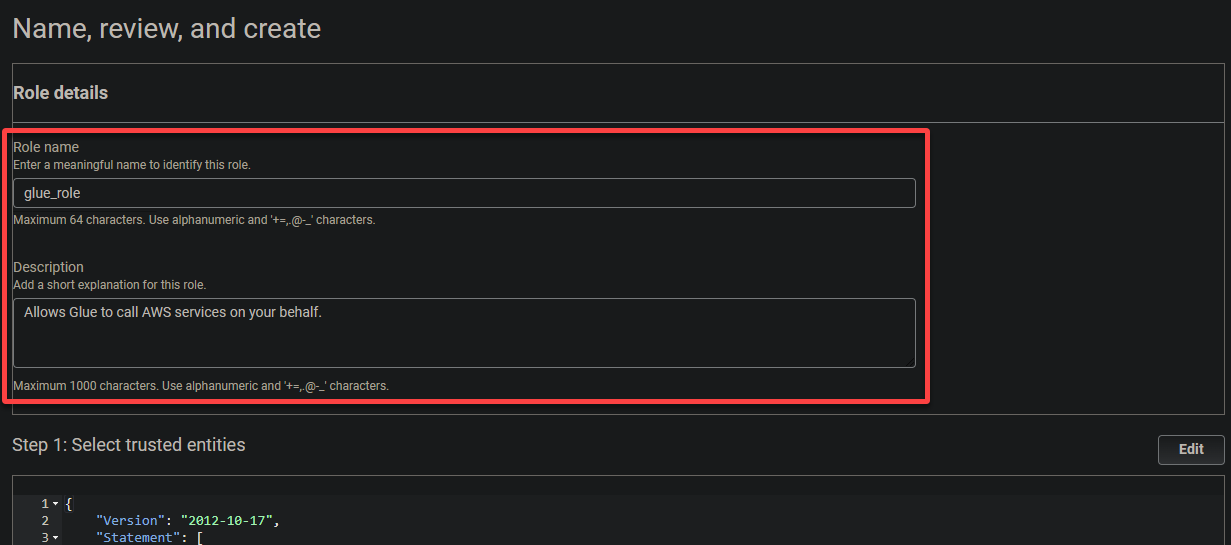
6. 역할에 대한 설명적인 이름 (예: glue_role)과 설명을 제공합니다.
7. 마지막으로 아래로 스크롤하여 설정을 검토한 다음 역할 생성을 클릭하여 역할 생성을 완료합니다.
S3 버킷 생성 및 샘플 파일 업로드
AWS Glue를 위한 IAM 역할이 있으므로 데이터를 저장할 장소인 S3 버킷이 필요합니다. S3 버킷은 AWS Glue가 처리할 데이터를 중앙 위치에 제공합니다.
이 예제에서는 AWS Glue가 데이터 추출, 변환 및 로딩(ETL) 작업과 같은 다양한 작업에 대해 AWS S3를 데이터 스토어로 사용할 것입니다.
S3 버킷을 생성하고 샘플 파일을 업로드하려면 다음 단계를 따르세요:
1. 로컬 기기에 샘플 데이터 파일 (예: Every Politician 데이터 세트 예제)을 다운로드합니다. 이 파일은 AWS Glue 변환 작업의 입력으로 사용될 비구조화된 레코드 컬렉션을 포함합니다.
2. 검색하여 S3 서비스를 선택하여 S3 콘솔에 액세스합니다.
3. 버킷 생성을 클릭하여 새로운 S3 버킷을 생성합니다.

4. 이제 버킷에 대한 고유한 이름 (예: sampledata54675)을 제공하고 버킷이 위치할 지역을 선택합니다.
A unique name lets you avoid conflicts with existing bucket names is crucial, while the region selection determines the physical location of your bucket’s data.
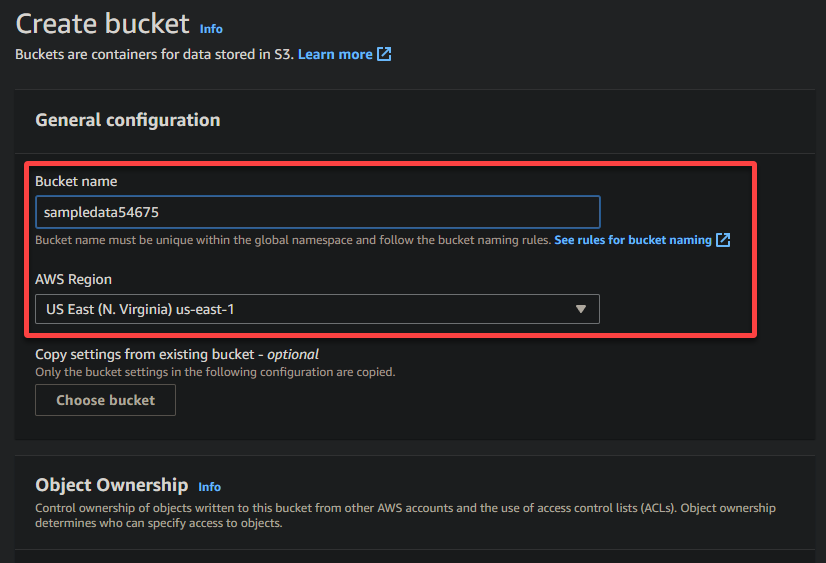
5. 아래로 스크롤하여 다른 옵션은 그대로 유지한 후 버킷 생성을 클릭하여 버킷을 생성합니다.

6. 생성된 버킷의 하이퍼링크를 클릭하여 버킷으로 이동합니다.

7. 업로드를 클릭하고 업로드하려는 샘플 파일을 찾습니다.
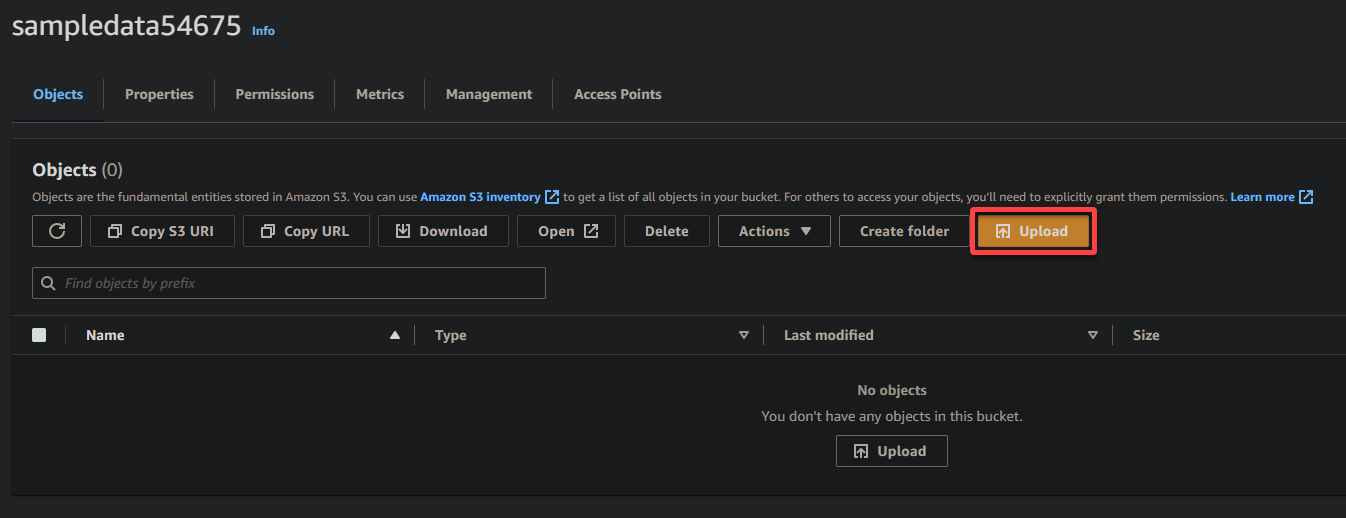
8. 마지막으로, 다른 설정은 그대로 두고 업로드를 클릭하여 샘플 파일을 새로 생성한 버킷에 업로드하세요.
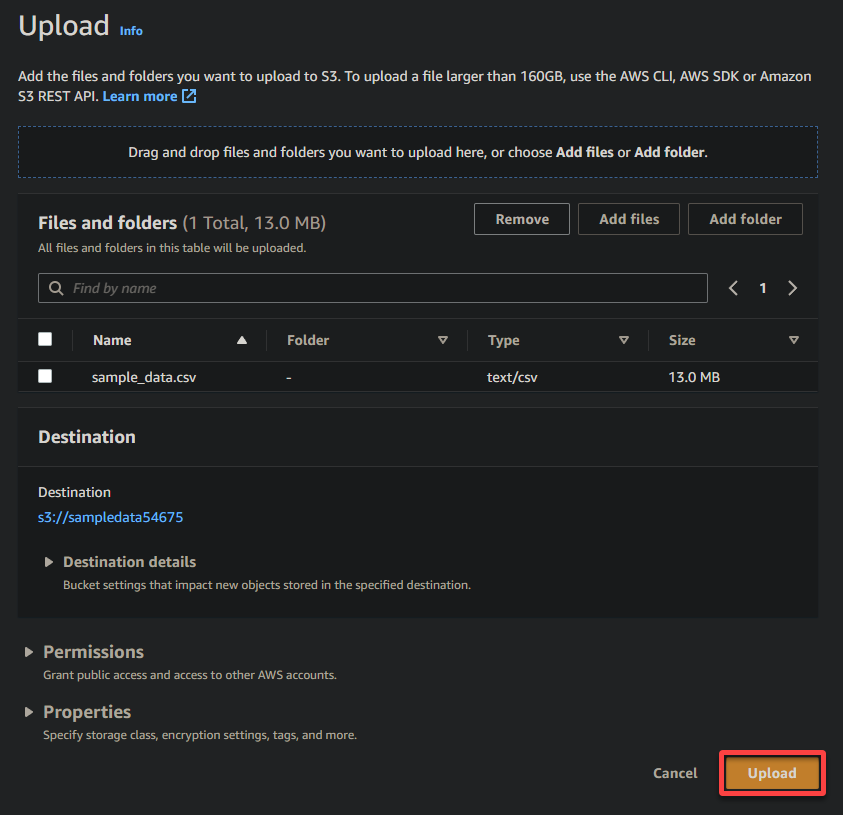
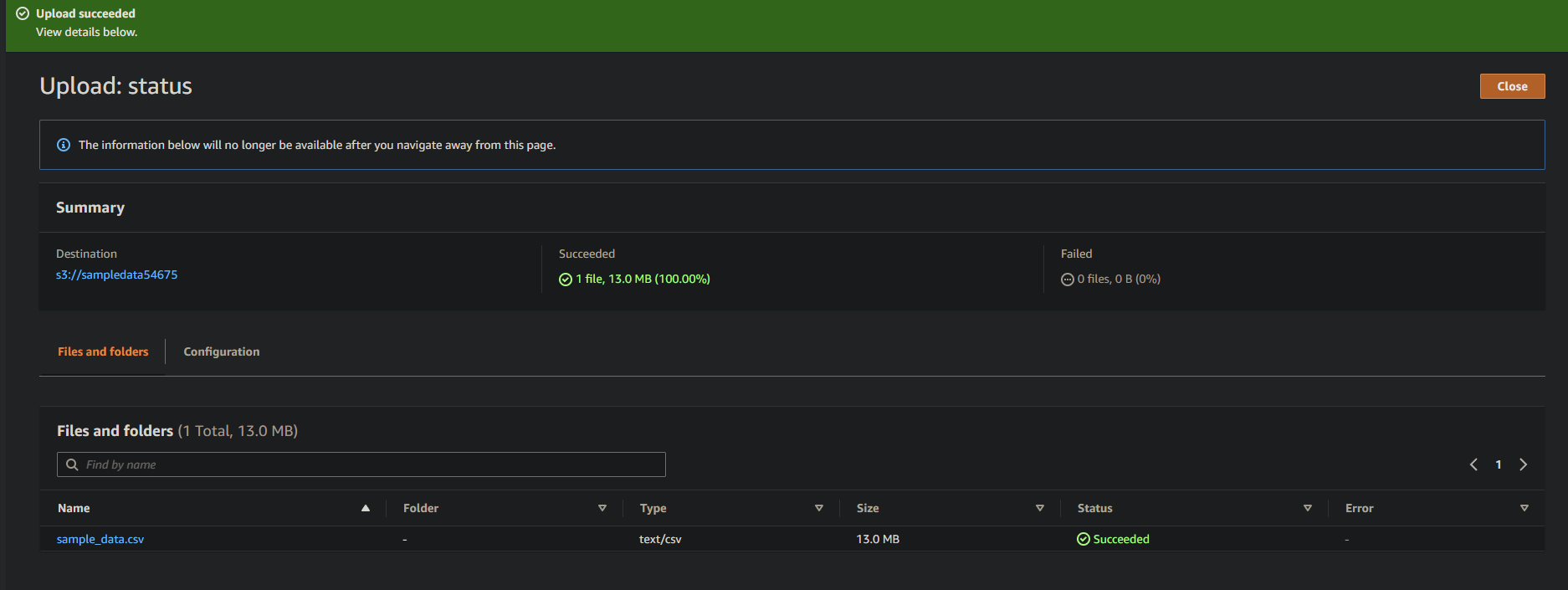
성공적으로 업로드되었다면 아래와 같이 새로 업로드한 파일이 버킷에 표시됩니다.
데이터를 스캔하고 카탈로그화하기 위해 Glue 크롤러 생성
샘플 데이터를 S3 버킷에 업로드했지만, 현재는 구조화되지 않은 상태이므로 데이터를 읽고 메타데이터 카탈로그를 구축할 방법이 필요합니다. 어떻게 할까요? 데이터를 자동으로 스캔하고 카탈로그를 생성하는 Glue 크롤러를 만들어서 수행합니다.
Glue 크롤러를 생성하려면 아래 단계를 따르세요:
1. AWS Glue 콘솔로 이동하려면 AWS 관리 콘솔을 통해 이동하세요. 아래와 같이 표시됩니다.
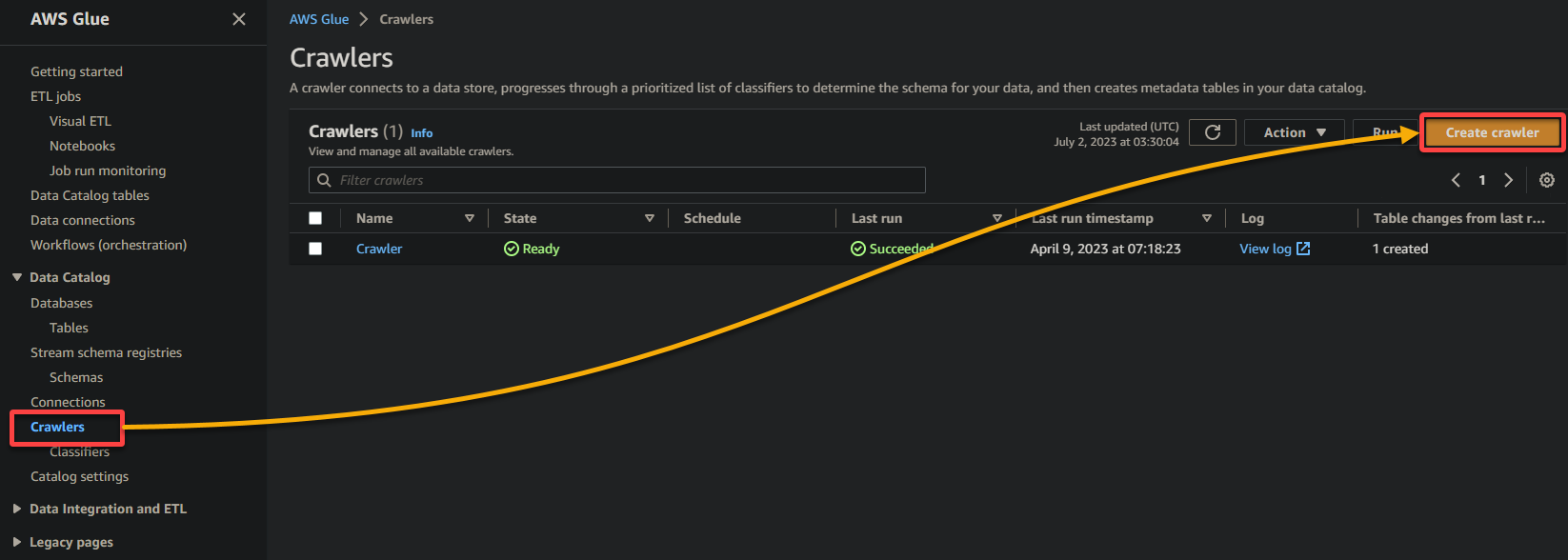
2. 다음으로, 크롤러 (왼쪽 패널)로 이동하여 크롤러 추가 (오른쪽 상단)를 클릭하여 새로운 Glue 크롤러 생성을 시작하세요.
3. 크롤러에 대한 설명적인 이름 (예: glue_crawler)과 설명을 제공하고, 다른 설정은 그대로 두고 다음을 클릭하세요.
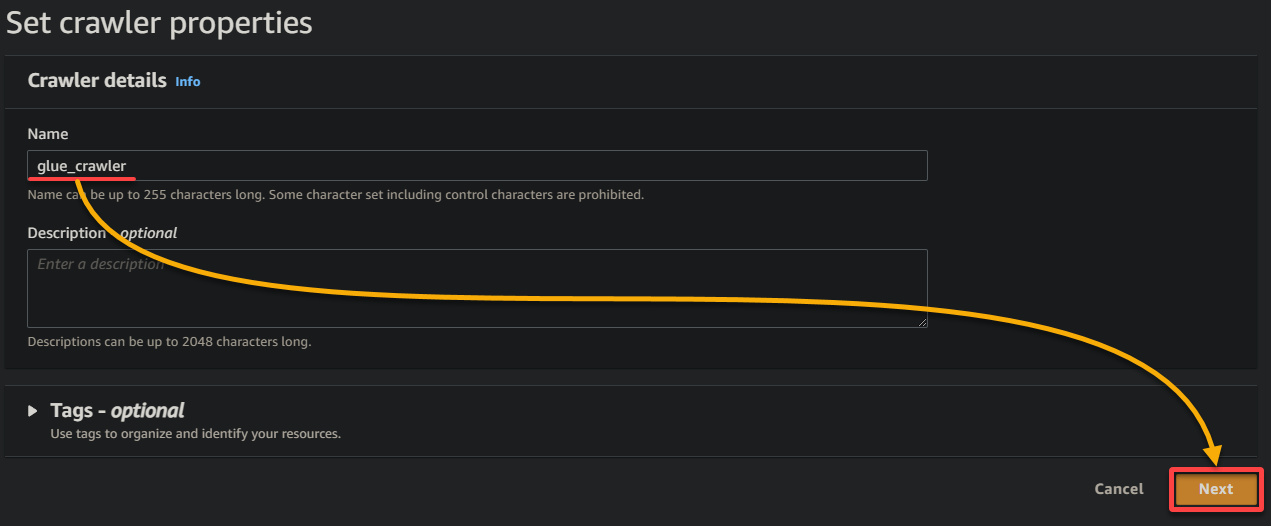
4. 이제 데이터 원본에서 데이터 원본 추가를 클릭하여 크롤러에 새 데이터 원본을 추가하세요.
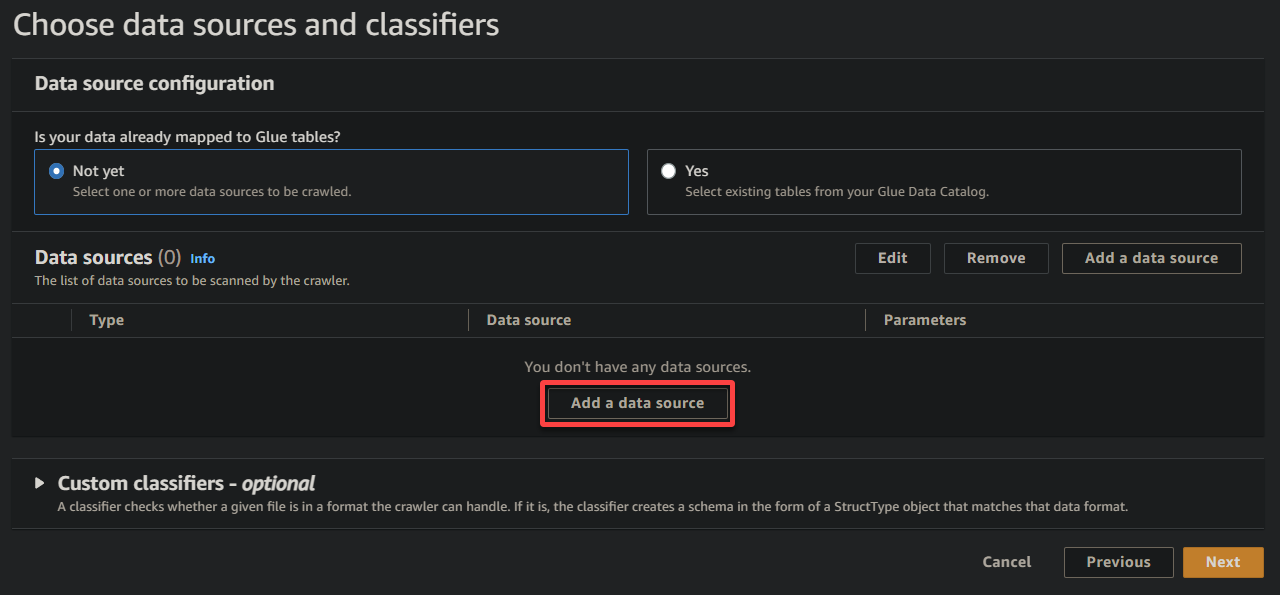
5. 팝업 창에서 다음과 같이 데이터 원본을 구성하세요:
- 데이터 원본 – 데이터가 S3 버킷에 있는 경우 S3을 선택합니다.
- S3 경로 – S3 찾아보기를 클릭하고 업로드한 샘플 데이터 (sampledata54675)가 포함된 버킷을 선택하십시오.
- 다른 설정을 유지한 채로 S3 데이터 소스 추가를 클릭하여 샘플 데이터를 크롤러에 추가하십시오.
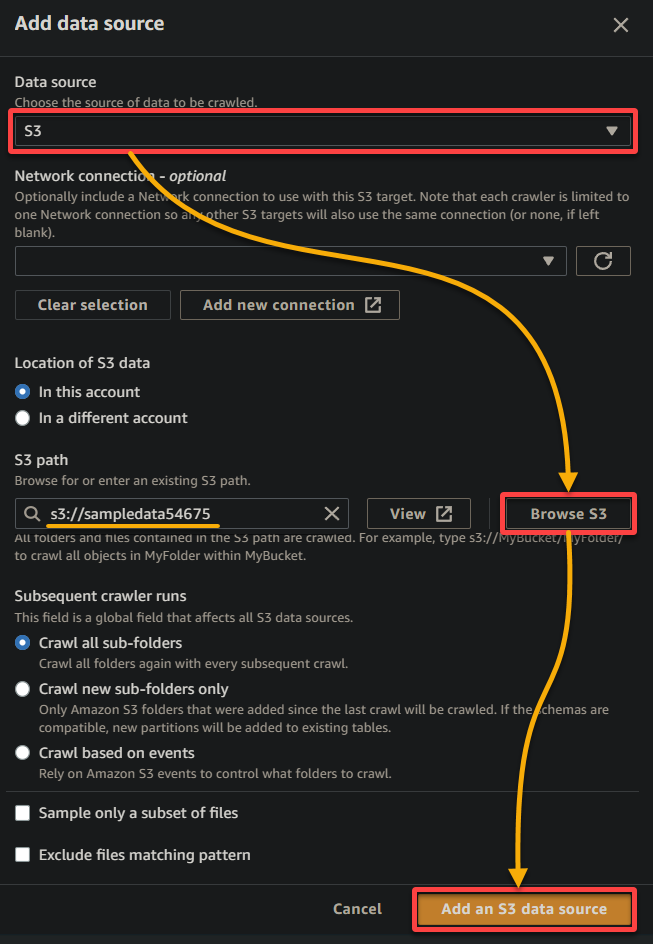
6. 설정이 완료되면 아래에 표시된대로 데이터 소스를 확인하고 다음을 클릭하여 계속 진행하십시오.
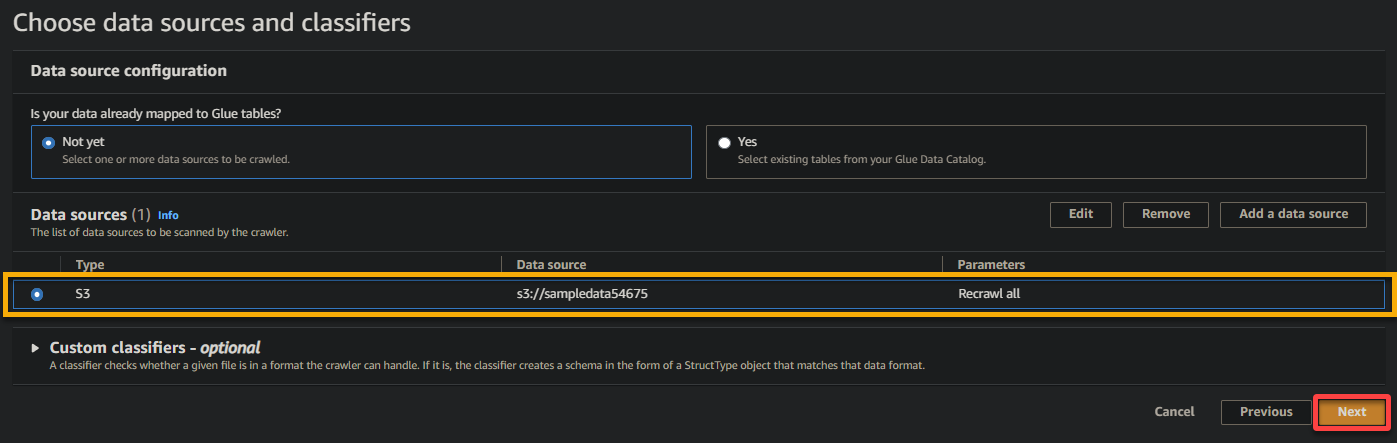
7. 다음 화면에서 이전에 생성한 IAM 역할 (glue_role)을 선택하고 다른 설정은 유지한 채로 다음을 클릭하십시오.
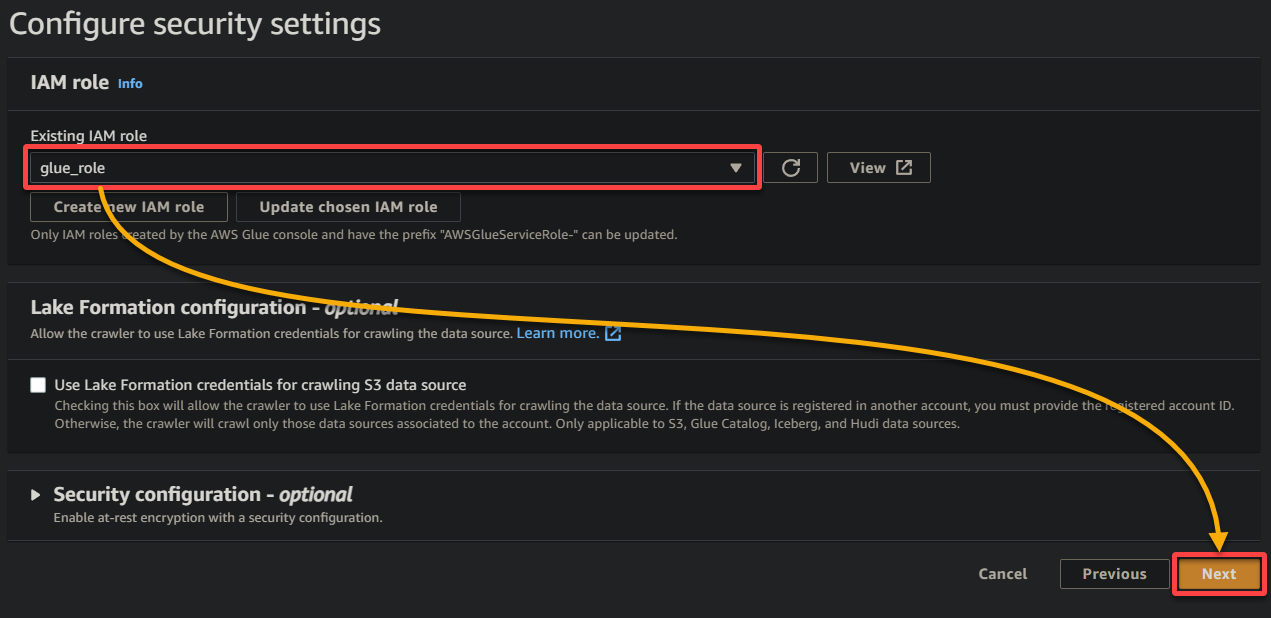
8. 출력 및 일정 설정에서 데이터베이스 추가를 클릭하여 Glue 크롤러가 생성한 처리된 데이터와 메타데이터를 저장할 새 데이터베이스를 추가합니다. 이 작업은 새로운 브라우저 탭에서 데이터베이스 세부정보를 구성할 수 있는 창을 엽니다 (8단계).
이 데이터베이스는 쿼리와 분석을 위한 구조화된 데이터 표현을 제공합니다.
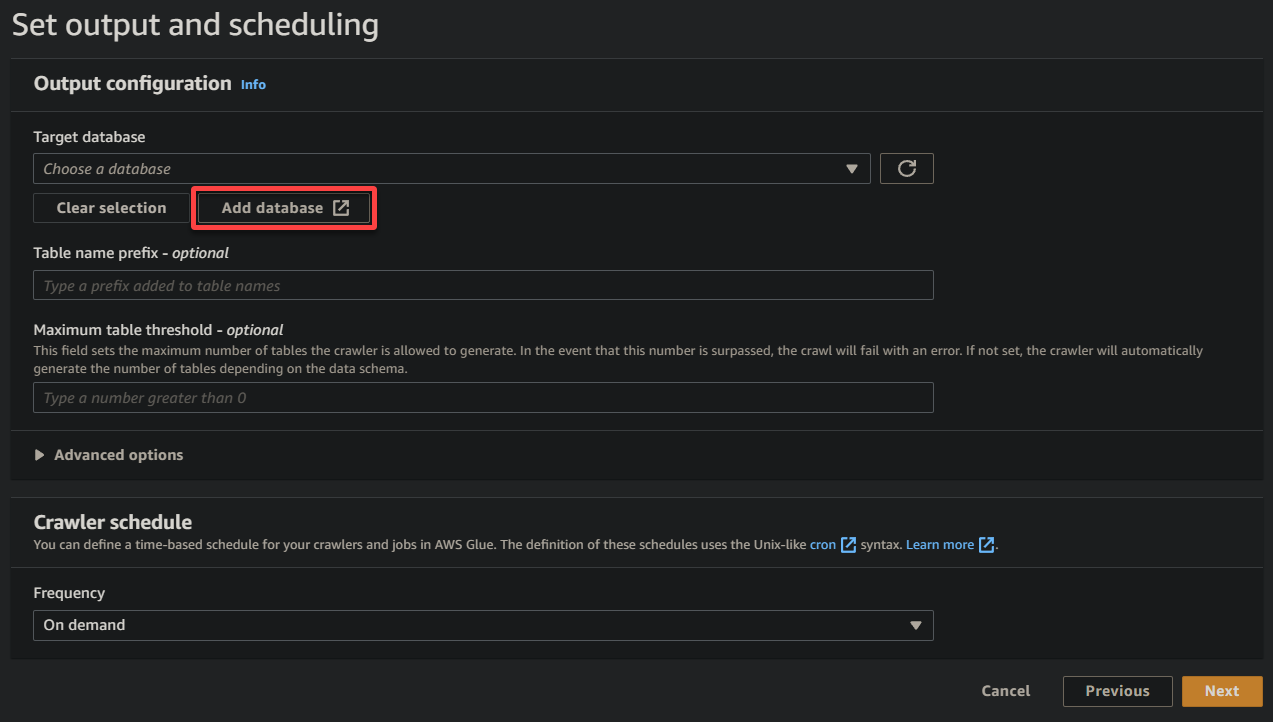
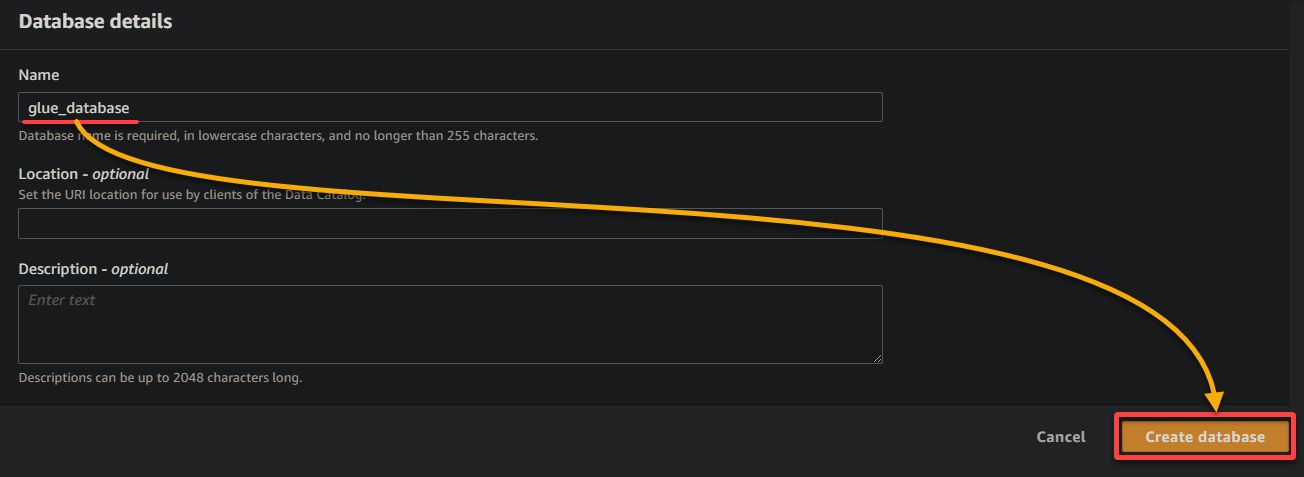
9. 새로운 브라우저 탭에서 설명적인 데이터베이스 이름을 제공하십시오 (예: glue_database) 그리고 데이터베이스 생성을 클릭하여 데이터베이스를 생성하십시오.
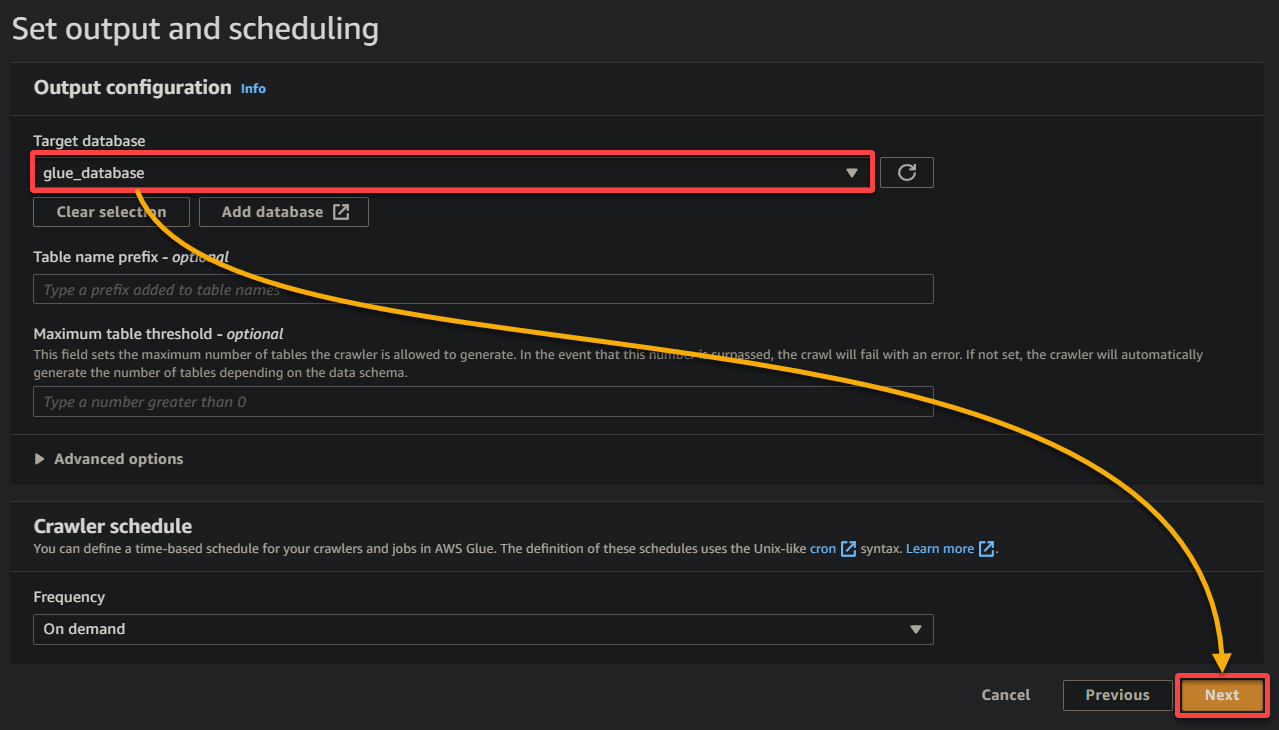
10. 이전 브라우저 탭으로 전환하고, 드롭다운에서 새로 생성한 데이터베이스 (glue_database)를 선택하고 다른 설정은 유지한 채로 다음을 클릭하십시오.
11. 마지막 화면에서 설정을 검토하여 정확한지 확인한 후, 새 크롤러를 생성하기 위해 오른쪽 하단의 크롤러 생성을 클릭하십시오.
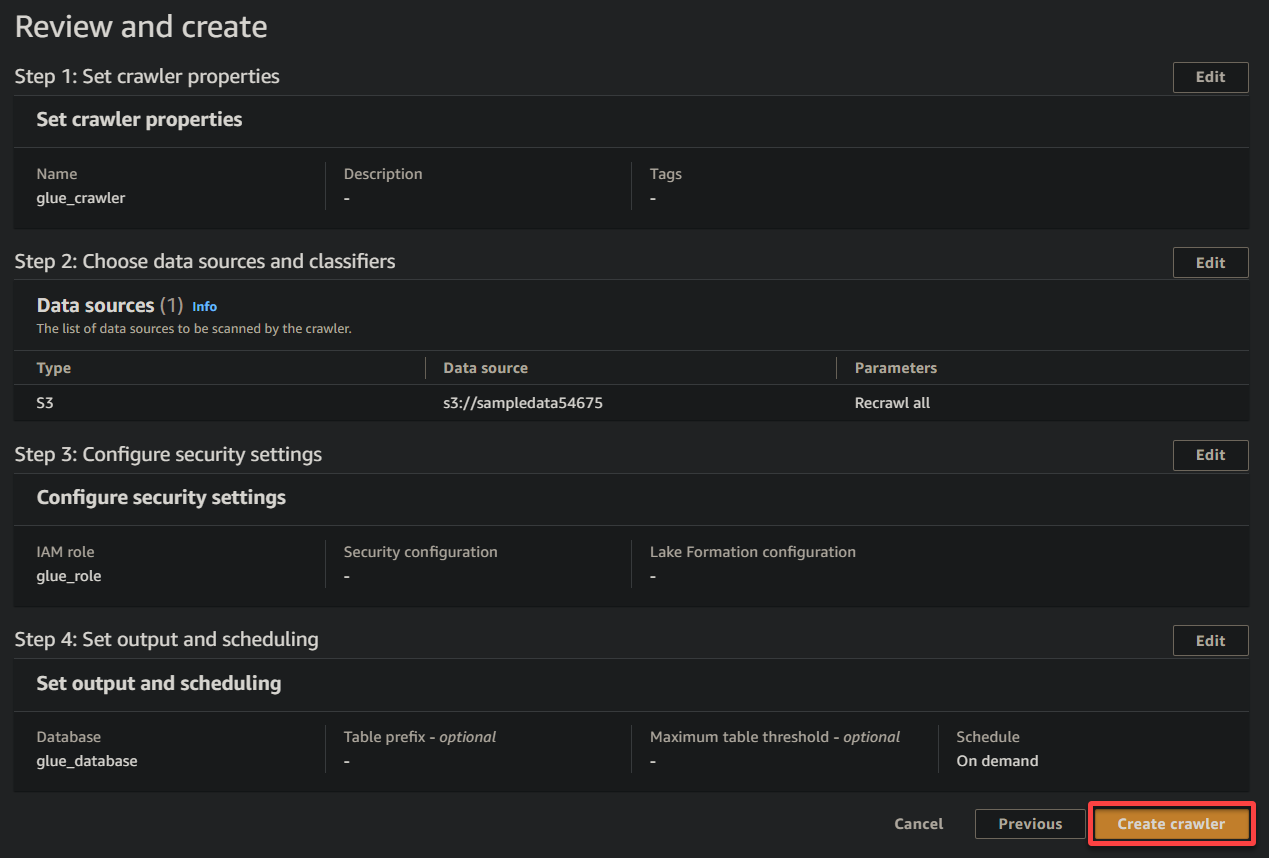
모든 것이 정상적으로 진행되면 크롤러 생성이 성공적으로 확인되는 화면이 표시됩니다. 이 화면을 아직 닫지 마세요. 다음 섹션에서 이 크롤러를 실행할 것입니다.
메타데이터 카탈로그를 구축하기 위해 Glue 크롤러 실행
새로운 크롤러를 사용할 수 있게 되었으므로 크롤러를 실행하는 것은 스캔 및 카탈로그화 프로세스를 시작하는 데 필수적입니다. Glue 크롤러는 쿼리 및 분석 목적을 위해 데이터의 구조화된 표현을 제공하는 메타데이터 카탈로그를 구축합니다.
새로 생성한 Glue 크롤러를 실행하려면:
1. 크롤러 세부정보 페이지에서 크롤러 실행을 클릭하고 크롤러 실행 탭 아래에서 크롤러 실행을 시작합니다.
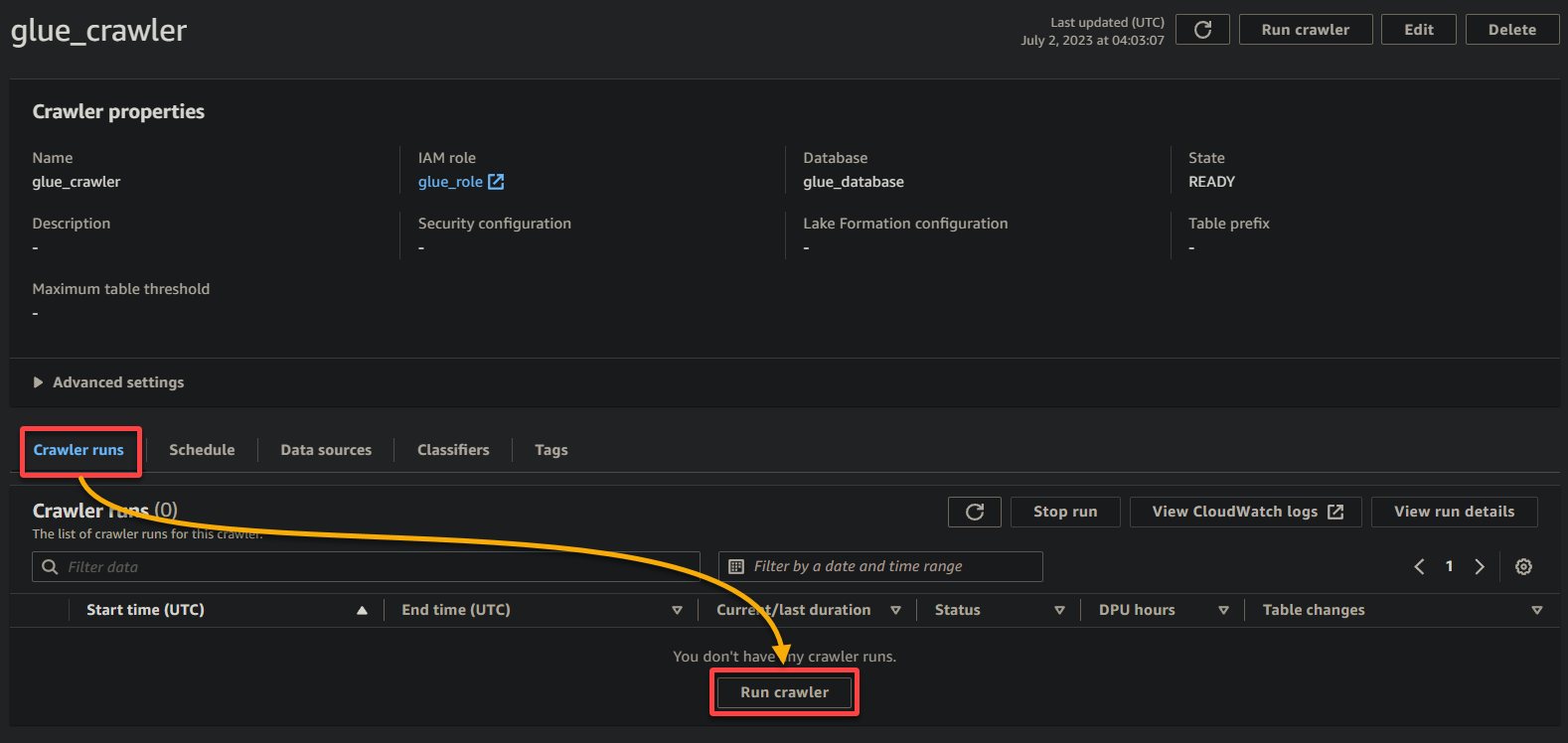
크롤러가 실행되기 시작하면 크롤러 세부정보 페이지에서 상태와 진행 상황을 확인할 수 있습니다.
데이터의 크기와 복잡성에 따라 크롤러가 실행 완료되기까지 시간이 걸릴 수 있습니다. 업데이트된 크롤러 상태를 확인하기 위해 주기적으로 페이지를 새로 고칠 수 있습니다.
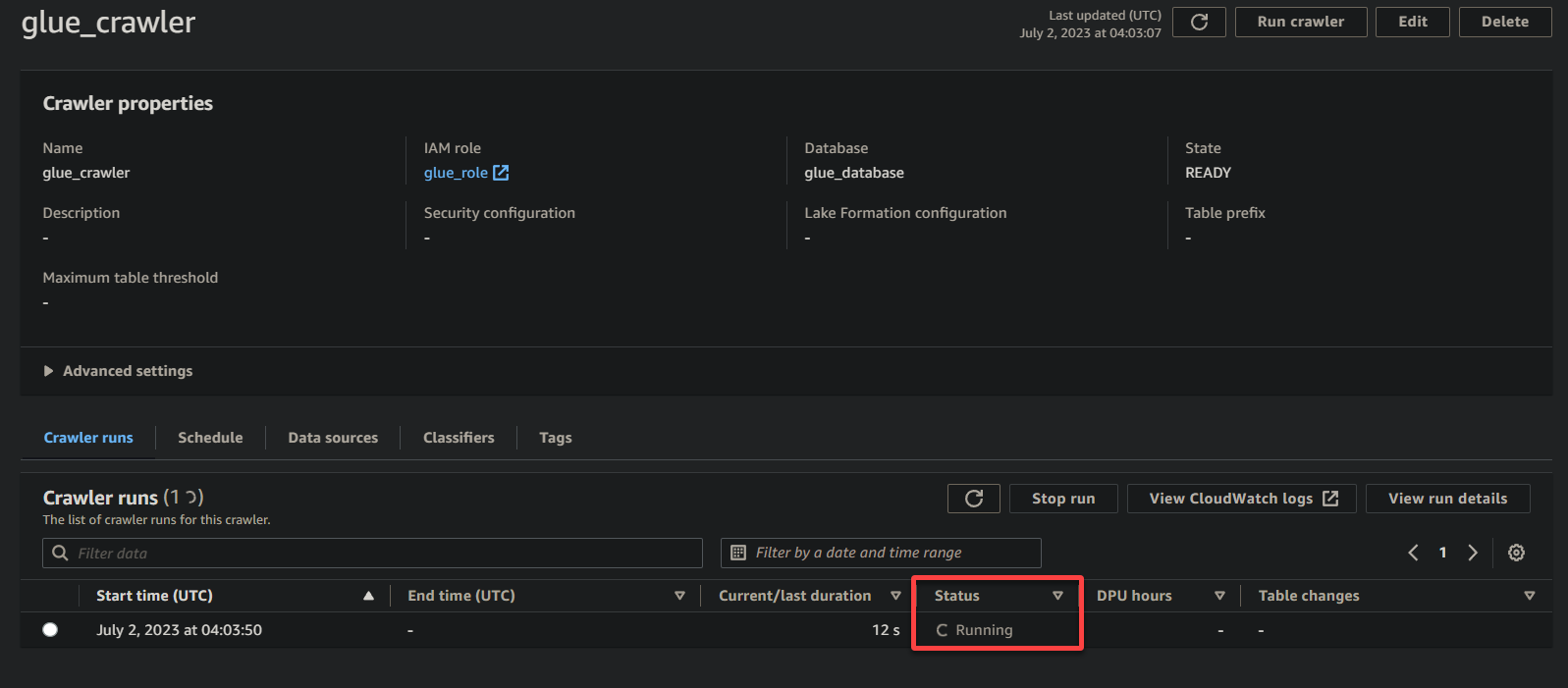
크롤러의 실행이 완료되면 아래와 같이 상태가 완료됨으로 변경됩니다. 이 시점에서 데이터를 쿼리할 수 있습니다.
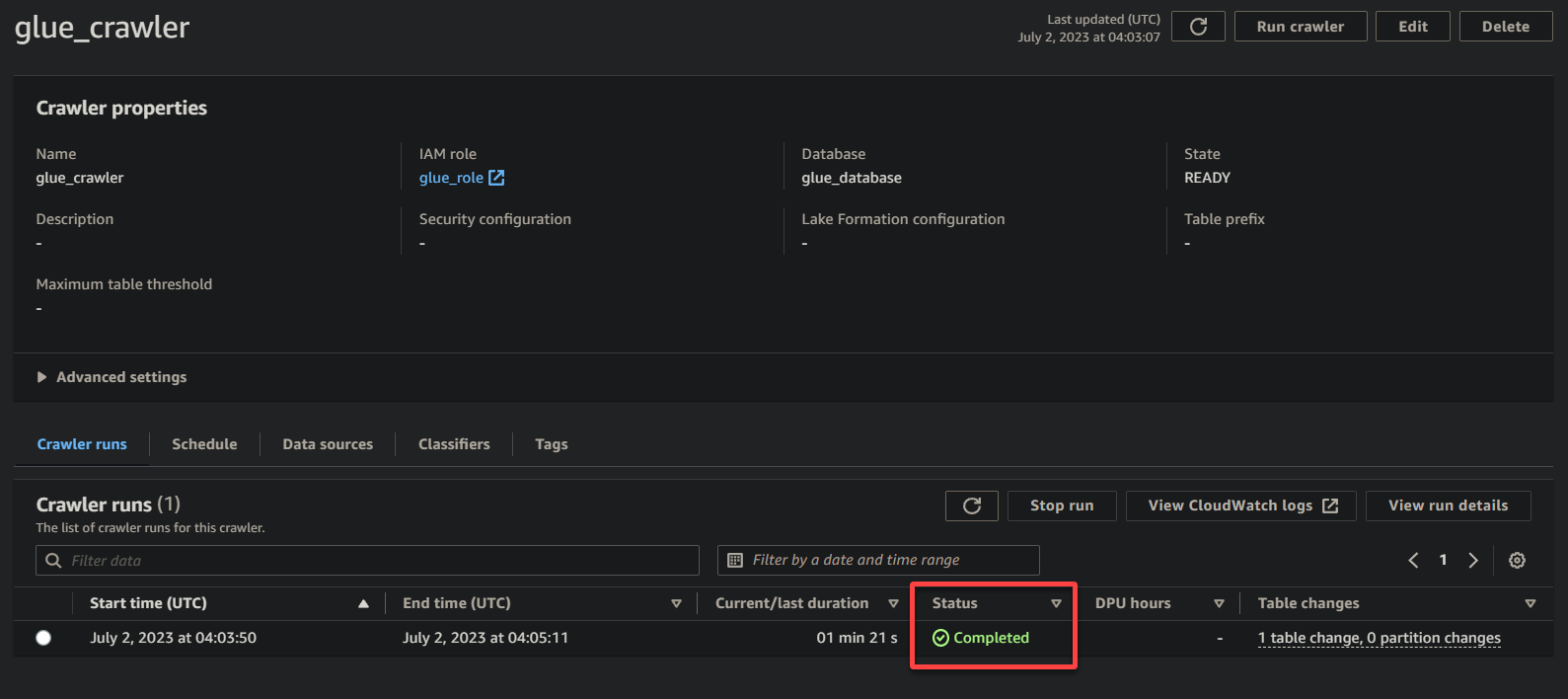
2. 다음으로, 데이터베이스 (왼쪽 창)로 이동하고 속성과 테이블에 액세스하기 위해 데이터베이스를 클릭합니다.
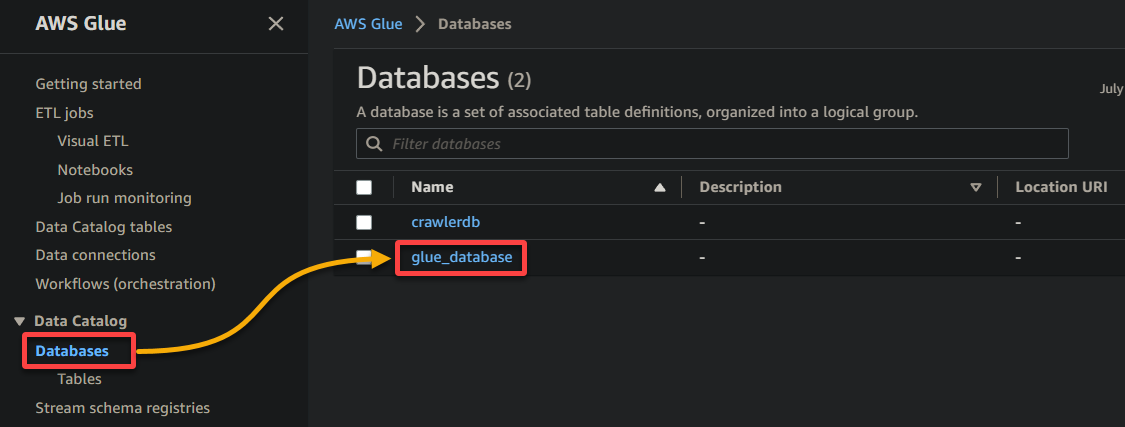
3. 마지막으로, 버킷 이름 (sampledata54675)인 테이블로 변환된 버킷을 클릭하여 저장된 데이터를 확인합니다.
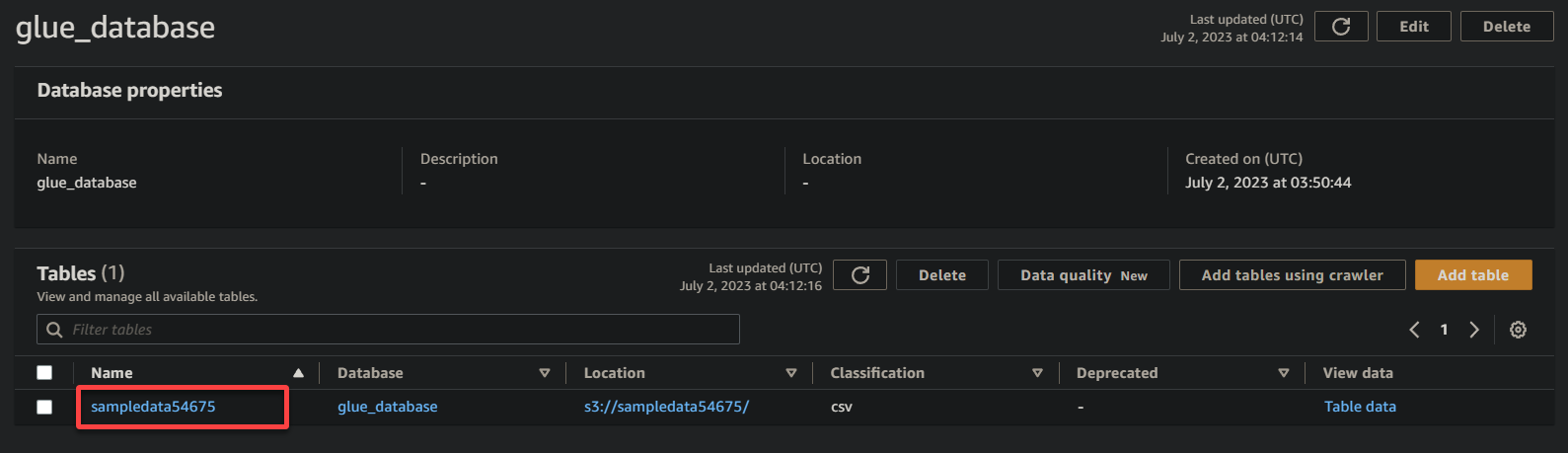
성공적으로 완료되면 아래와 유사한 정보가 표시됩니다. 이 정보는 데이터가 데이터베이스 테이블로 성공적으로 변환되어 가치 있는 세부 정보를 제공함을 확인합니다.
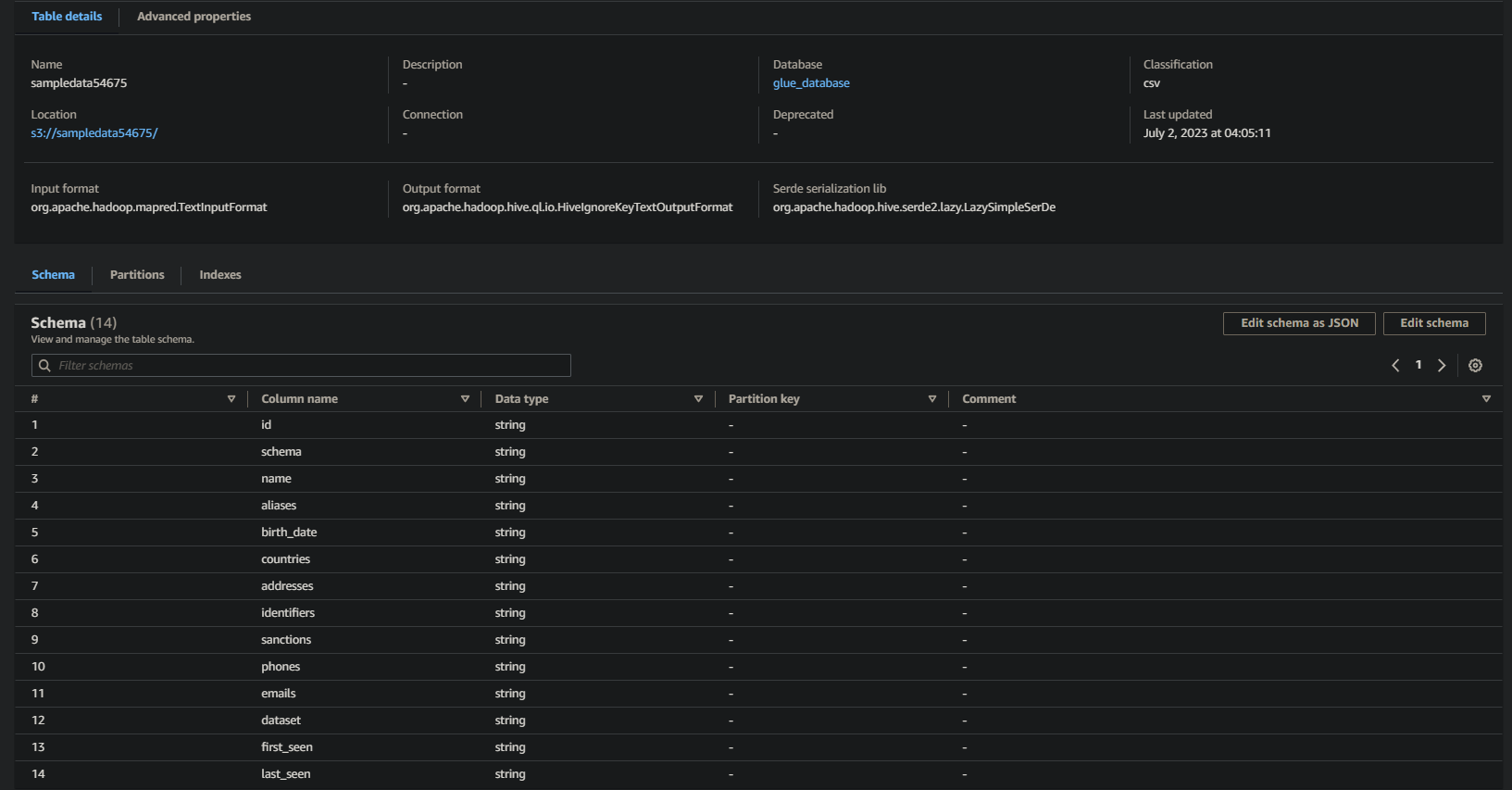
AWS Athena를 통해 카탈로그화된 데이터 쿼리하기
이제 데이터가 AWS Glue 데이터 카탈로그에 사용 가능하므로 다양한 도구를 사용하여 데이터를 쿼리하고 분석할 수 있습니다. 그 중 하나는 AWS Athena입니다. 이는 표준 SQL을 사용하여 클라우드에서 데이터를 분석할 수 있는 대화식 쿼리 서비스입니다.
AWS Athena를 사용하여 데이터를 쿼리하려면 다음 단계를 따르세요:
1. Athena 콘솔을 검색하고 액세스합니다.
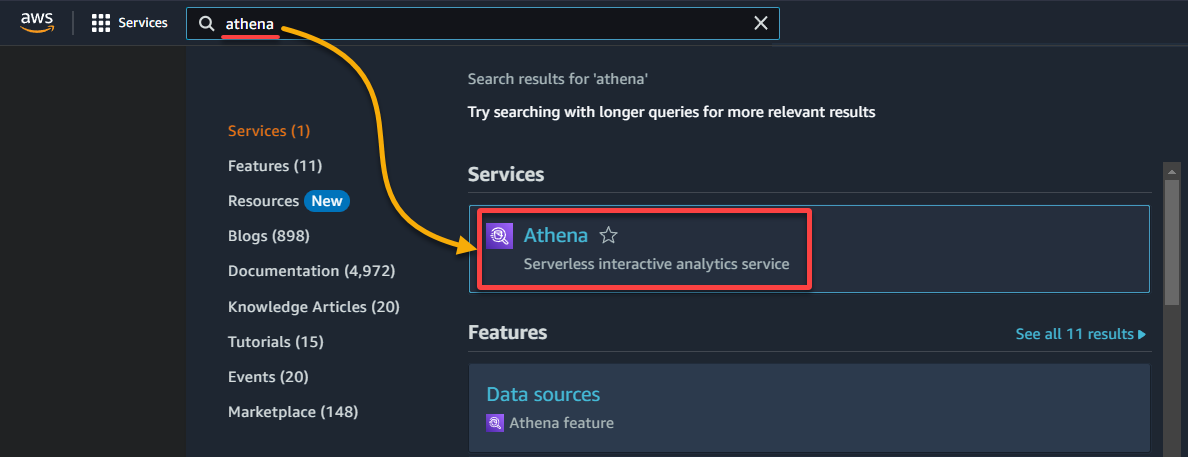
2. 다음과 같이 Data 섹션 아래에 데이터가 카탈로그화된 데이터베이스를 선택합니다:
- 데이터 원본 – AWS Glue에서 카탈로그화된 데이터를 쿼리하려는 경우 AwsDataCatalog를 선택합니다.
- 데이터베이스 – 드롭다운 필드에서 적절한 데이터베이스를 선택합니다 (예: glue_database).
? 드롭다운에서 원하는 데이터베이스가 표시되지 않으면 크롤러가 실행을 완료하고 데이터를 카탈로그화 했는지 확인하세요.
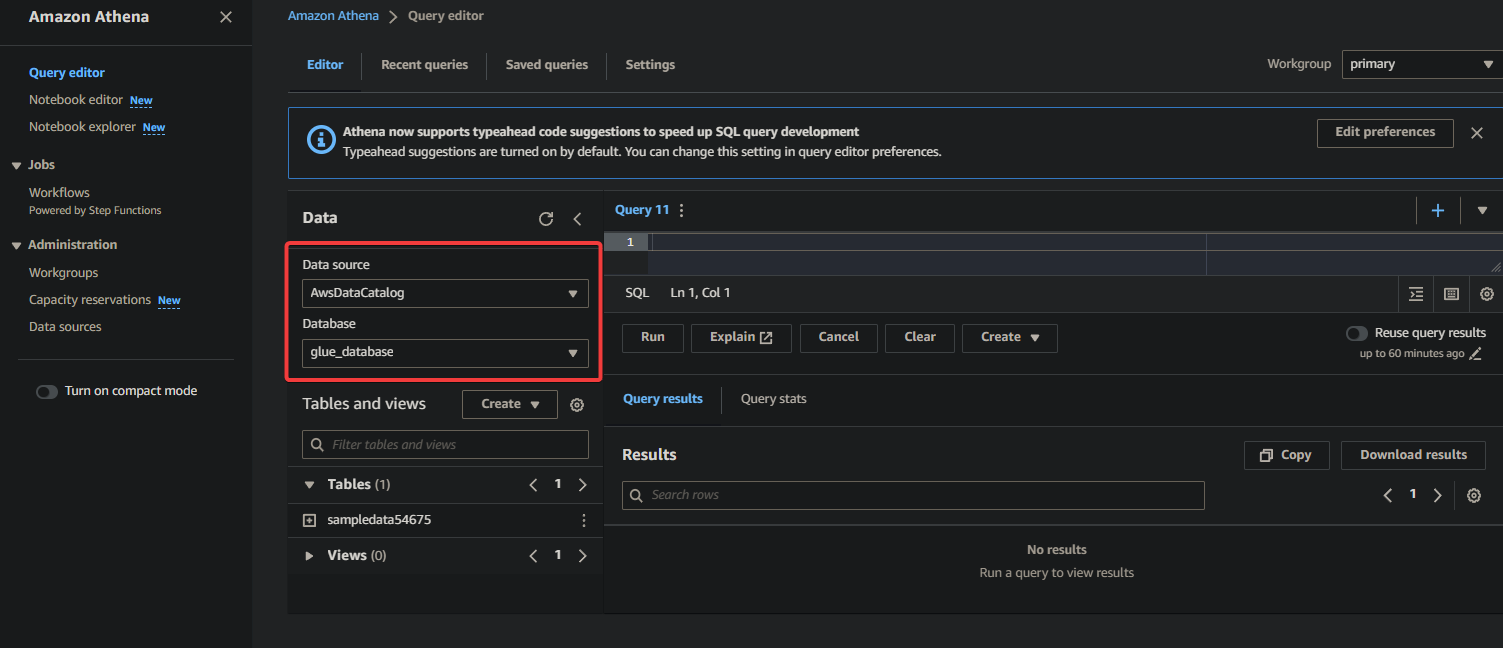
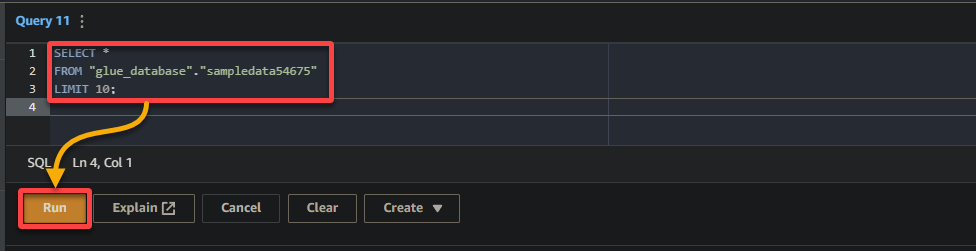
3. 마지막으로, 오른쪽의 쿼리 편집기에 다음 쿼리를 입력하고 실행합니다.
이 쿼리는 glue_database 데이터베이스의 sampledata54675 테이블에서 첫 10개 행을 반환합니다. 필요에 따라 쿼리를 수정하여 특정 요구 사항에 맞게 사용할 수 있습니다.
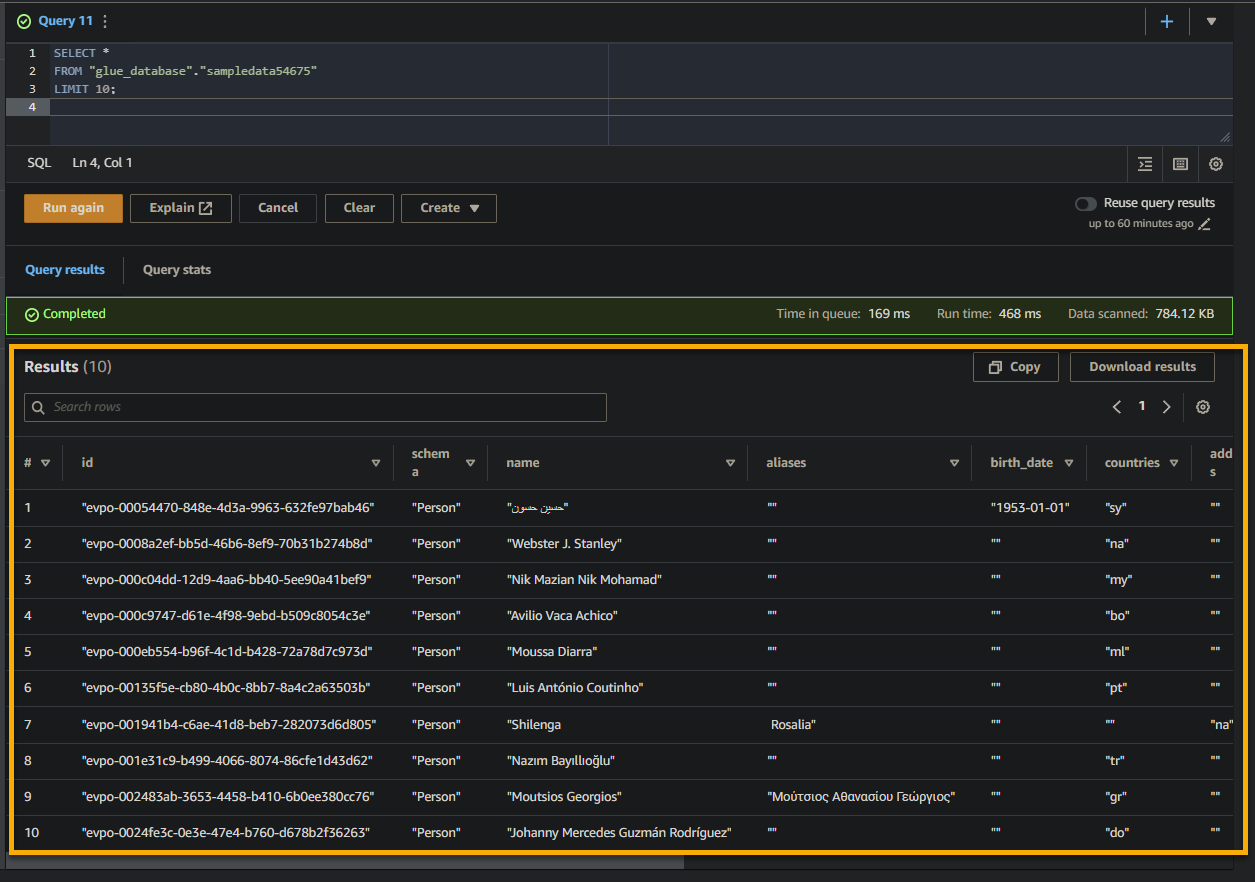
쿼리가 성공적이면 아래에 표시된 것처럼 결과가 결과 창에 표시됩니다. 결과에는 SQL 쿼리를 기반으로 테이블에 저장된 레코드에 대한 정보가 포함됩니다.
결과 집합에 반환된 열 이름, 데이터 유형 및 값에 유의하십시오. 이 정보는 쿼리된 데이터의 구조와 내용을 이해하는 데 도움이 됩니다.
결론
이 튜토리얼에서는 AWS Glue를 사용하여 Glue 크롤러를 생성하고 데이터를 카탈로그화하며 AWS Athena를 사용하여 데이터를 쿼리하는 기본 사항을 배웠습니다. 데이터 준비 및 분석은 데이터 주도 애플리케이션에 필수적입니다. 그리고 AWS Glue와 같은 도구는 다양한 소스에서 데이터를 추출, 변환 및 로드(ETL)하여 데이터베이스 테이블로 쉽게 이동할 수 있는 빠른 방법을 제공합니다.
AWS Glue를 사용하면 데이터를 빠르게 관리하고 조직화하여 데이터에서 인사이트를 도출하는 데 더욱 집중할 수 있습니다. 그러나 여기에서 본 것은 빙산의 일각에 불과합니다. AWS Glue가 제공할 수 있는 다양한 기능과 기능을 탐색해 보세요!
왜 AWS Glue 연결을 활용하여 Amazon RDS 또는 Amazon Redshift와 같은 다른 AWS 서비스와 원활하게 통합하지 않으시겠습니까? 이 통합을 통해 복잡한 ETL 파이프라인을 구축하고 더 큰 데이터 분석 능력을 얻을 수 있습니다.