













MySQL 5.7 현재 상태
MySQL 5.7은 스케일ability(スケール能力) 方面에서 理想的하지 않습니다. 下面的 그림은 特定の 설정下 MySQL 5.7.39의 TPC-C 吞吐量과 並行性之间的关系을 이形libration(表시)합니다. 이에는 트랜잭션 이olate(隔离) 수준을 Read Committed로 설정하고 innodb_spin_wait_delay 매개변수를 조절하여 吞吐量 저하를 軽減하는 것을 包括하고 있습니다.
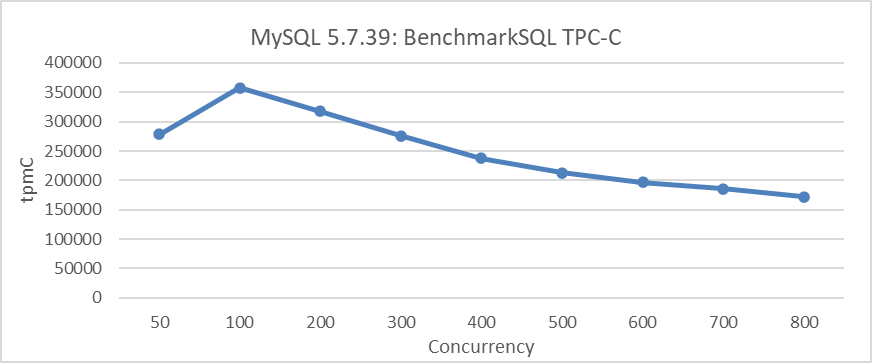
그림 1: BenchmarkSQL 테스eting 시 MySQL 5.7.39의 스케일ability 문제
그림에서 明显的하게 스케일ability 문제는 MySQL 吞吐率의 증가를 значитель히 제한하는 것을 보여줍니다. 예를 들어, 100개의 並行性 후에는 吞吐量이 시작되는 하락을 보여줍니다.
이전에 언론된 パフォーマン스 Implosion(爆発) 문제를 해결하기 위해 Percona의 스레드 풀을 사용하였습니다. Percona 스레드 풀을 설정한 후의 TPC-C 吞吐量과 並行성 간의 关系을 다음 그림이 이形libration(表시)합니다.
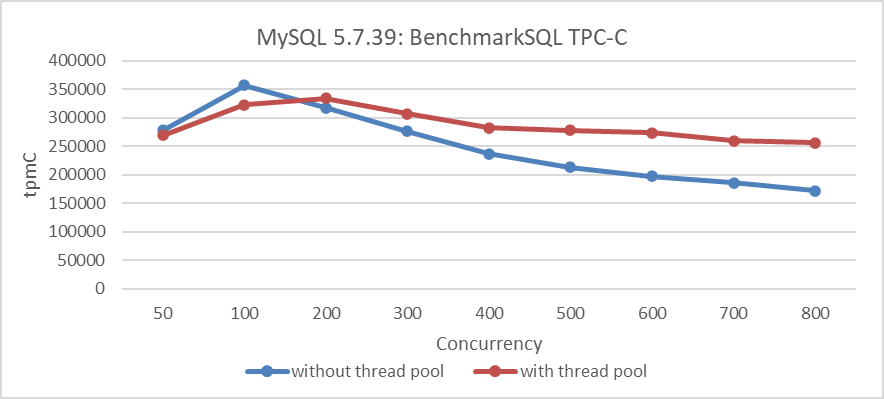
그림 2: MySQL 5.7.39의 스케일ability 문제를 Percona 스레드 풀로 軽減하는 것
스레드 풀은 一些 overhead(オーバー헤드)를 가져가고 极大な パフォーマン스가 감소하였지만, 높은 並行성 下의 パフォーマン스 Implosion(爆発) 문제를 軽減했습니다.
MySQL 8.0 현재 상태
MySQL 8.0에 대해서는 스케일ability 方面에서 어떤 努力을 했는지 보여줍니다.
Redo Log 的最优化
첫 번째 주요 改善은 Redo Log的最优化입니다.[3].
commit 6be2fa0bdbbadc52cc8478b52b69db02b0eaff40
Author: Paweł Olchawa <[email protected]>
Date: Wed Feb 14 09:33:42 2018 +0100
WL#10310 Redo log optimization: dedicated threads and concurrent log buffer.
0. Log buffer became a ring buffer, data inside is no longer shifted.
1. User threads are able to write concurrently to log buffer.
2. Relaxed order of dirty pages in flush lists - no need to synchronize
the order in which dirty pages are added to flush lists.
3. Concurrent MTR commits can interleave on different stages of commits.
4. Introduced dedicated log threads which keep writing log buffer:
* log_writer: writes log buffer to system buffers,
* log_flusher: flushes system buffers to disk.
As soon as they finished writing (flushing) and there is new data to
write (flush), they start next write (flush).
5. User threads no longer write / flush log buffer to disk, they only
wait by spinning or on event for notification. They do not have to
compete for the responsibility of writing / flushing.
6. Introduced a ring buffer of events (one per log-block) which are used
by user threads to wait for written/flushed redo log to avoid:
* contention on single event
* false wake-ups of all waiting threads whenever some write/flush
has finished (we can wake-up only those waiting in related blocks)
7. Introduced dedicated notifier threads not to delay next writes/fsyncs:
* log_write_notifier: notifies user threads about written redo,
* log_flush_notifier: notifies user threads about flushed redo.
8. Master thread no longer has to flush log buffer.
...
30. Mysql test runner received a new feature (thanks to Marcin):
--exec_in_background.
Review: RB#15134
Reviewers:
- Marcin Babij <[email protected]>,
- Debarun Banerjee <[email protected]>.
Performance tests:
- Dimitri Kravtchuk <[email protected]>,
- Daniel Blanchard <[email protected]>,
- Amrendra Kumar <[email protected]>.
QA and MTR tests:
- Vinay Fisrekar <[email protected]>.Optimization 전과 후에 TPC-C 吞吐量과 다른 수준의 並行성을 比较하는 이스periment(実験)을 실시했습니다. 下面的 그림에서 상세한 정보를 보여줍니다:
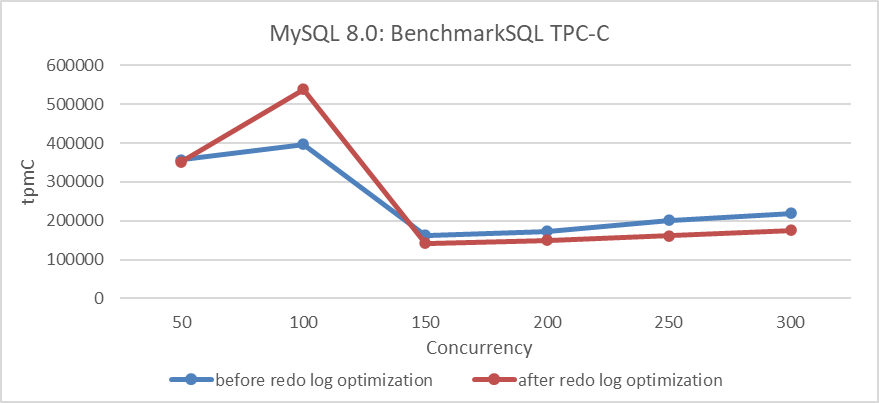
그림 3: 다양한 paralleism 수준에서 redo log 優化의 영향
그림에 나타낸 결과는 paralleism이 낮은 경우 吞吐量(throughput)에 유리한 결과를 보여줍니다.
Lock-Sys를 통한 Latch Sharding 優化
第二种 優化은 Lock-Sys 優化 [5]입니다.
commit 1d259b87a63defa814e19a7534380cb43ee23c48
Author: Jakub Łopuszański <[email protected]>
Date: Wed Feb 5 14:12:22 2020 +0100
WL#10314 - InnoDB: Lock-sys optimization: sharded lock_sys mutex
The Lock-sys orchestrates access to tables and rows. Each table, and each row,
can be thought of as a resource, and a transaction may request access right for
a resource. As two transactions operating on a single resource can lead to
problems if the two operations conflict with each other, Lock-sys remembers
lists of already GRANTED lock requests and checks new requests for conflicts in
which case they have to start WAITING for their turn.
Lock-sys stores both GRANTED and WAITING lock requests in lists known as queues.
To allow concurrent operations on these queues, we need a mechanism to latch
these queues in safe and quick fashion.
In the past a single latch protected access to all of these queues.
This scaled poorly, and the managment of queues become a bottleneck.
In this WL, we introduce a more granular approach to latching.
Reviewed-by: Pawel Olchawa <[email protected]>
Reviewed-by: Debarun Banerjee <[email protected]>
RB:23836Lock-Sys를 사용한 프로그램 전과 후에 대해 BenchmarkSQL을 사용하여 TPC-C 吞吐量과 concurrency간의 比较을 수행하여 다음과 같은 결과를 보여줍니다.
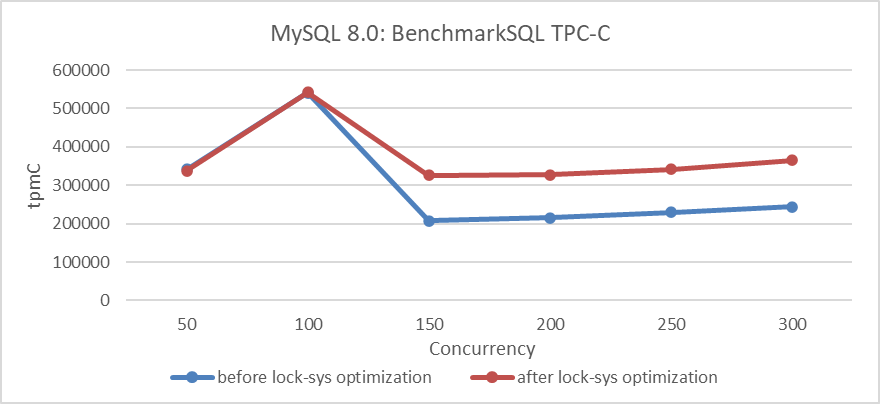
그림 4: 다양한 paralleism 수준에서 Lock-Sys 優化의 영향
그림에서는 high concurrency 条件下 lock-sys 優化이 吞吐量에 유리한 영향을 보여줍니다. 그러나 low concurrency 条件下에서는 충돌이 少ない 이유로 유용한 효과를 보여줍니다.
trx-sys를 위한 Latch Sharding
第三种 優化은 trx-sys를 위한 Latch Sharding입니다.
commit bc95476c0156070fd5cedcfd354fa68ce3c95bdb
Author: Paweł Olchawa <[email protected]>
Date: Tue May 25 18:12:20 2021 +0200
BUG#32832196 SINGLE RW_TRX_SET LEADS TO CONTENTION ON TRX_SYS MUTEX
1. Introduced shards, each with rw_trx_set and dedicated mutex.
2. Extracted modifications to rw_trx_set outside its original critical sections
(removal had to be extracted outside trx_erase_lists).
3. Eliminated allocation on heap inside TrxUndoRsegs.
4. [BUG-FIX] The trx->state and trx->start_time became converted to std::atomic<>
fields to avoid risk of torn reads on egzotic platforms.
5. Added assertions which ensure that thread operating on transaction has rights
to do so (to show there is no possible race condition).
RB: 26314
Reviewed-by: Jakub Łopuszański [email protected]이러한 優化 전과 후에 대해 BenchmarkSQL을 사용하여 TPC-C 吞吐量과 concurrency간의 比较을 수행하여 다음과 같은 결과를 보여줍니다.
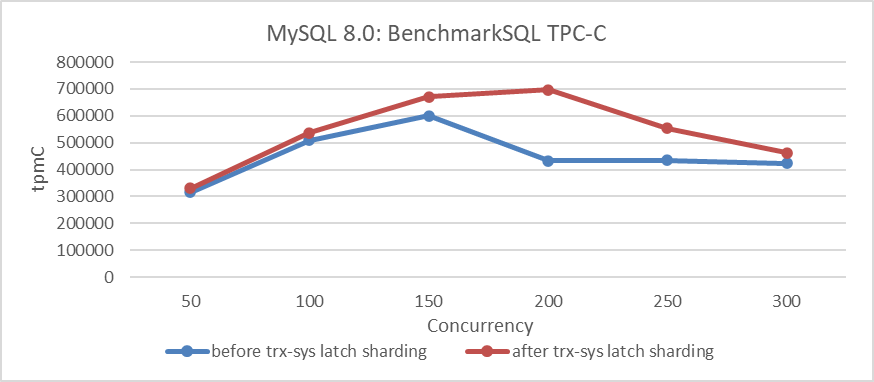
그림 5: trx-sys에서 Latch Sharding의 영향
그림에서는 TPC-C 吞吐量을 显然的하게 향상시키는 것을 볼 수 있으며, 200 concurrency를 가지고 peak을 달성합니다. 300 concurrency를 가지고 있을 때 영향을 줄어들는 것을 유의하시기 바랍니다. 이는 MVCC ReadView와 관련된 trx-sys 子系统의 進行적인 スケール성 문제로 인해 발생합니다.
MySQL 8.0 精炼
나머지 優化은 우리가 독립적으로 제시한 것입니다.
MVCC 읽기 viewers
첫 번째 주요 개선 사항은 MVCC ReadView 데이터 구조의 개선입니다. [1]
MVCC ReadView 優化의 효果을 평가하기 위해 パフォーマンス 比较 실험을 실시했습니다. 다음 그림은 수정 전과 수정 后的 TPC-C 吞吐量의 並列性 수준에 따른 比较입니다.
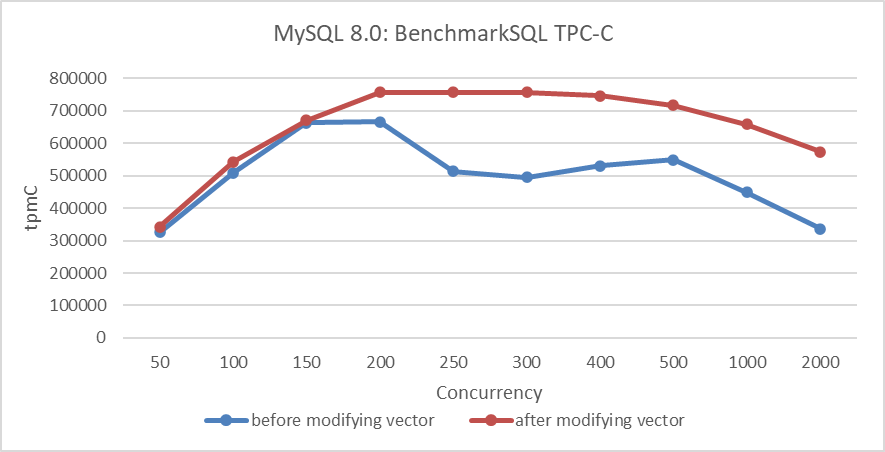
그림 6: NUMA 내에서 새로운 하이브리드 데이터 구조를 적용 전과 후의 パフォーマン스 比较
그림에서 明显的하게 이 변경은 대면성과 관련된 増幅과 MySQL의 NUMA 환경의 지 peek 吞吐量을 改善시켰음을 보여줍니다.
덜씀이 문제로 인한 Avoiding Double Latch Problems
두 번째 주요 개선은 덜씀이 문제를 해결하는 것입니다. “덜씀이 문제”는 두 가지 모두 view_open와 view_close에 의해 글로벌 trx-sys 덜씀을 사용하는 것을 의미합니다. [1]
MVCC ReadView가 Optimized VERSION을 사용하여 TPC-C 吞吐量을 변경 전과 后的에 比较하십시오. 다음 그림에서 자세히 보여집니다:
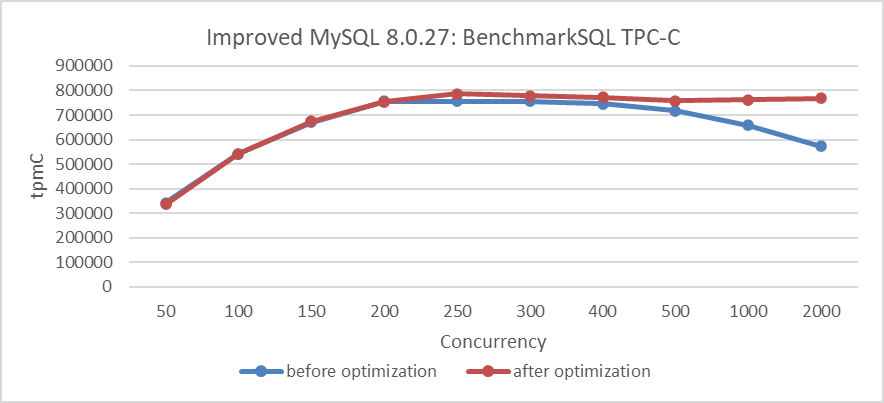
그림 7: 덜씀이 문제를 해결한 후의 パフォーマン스 改善
그림에서 明显的하게 변경은 고 대면성 조건에서 대면성을 substantially 改善시켰습니다.
트랜잭션 가속 기계
마지막 개선은 과弦한 대면성에 의한 パフォーマン스 colapse를 防ぐ ため 트랜잭션 가속 기계를 구현했습니다. [1] [2] [4]
다음 그림은 트랜잭션 throttling이 적용된 후 TPC-C 스케일ability 가속 시험을 보여줍니다. 시험은 NUMA BIOS 사용 안 함, 트랜잭션 시스템에 512개 이하의 사용자 스레드를 Enter하게 제한한 scenarios 下에 실시되었습니다.
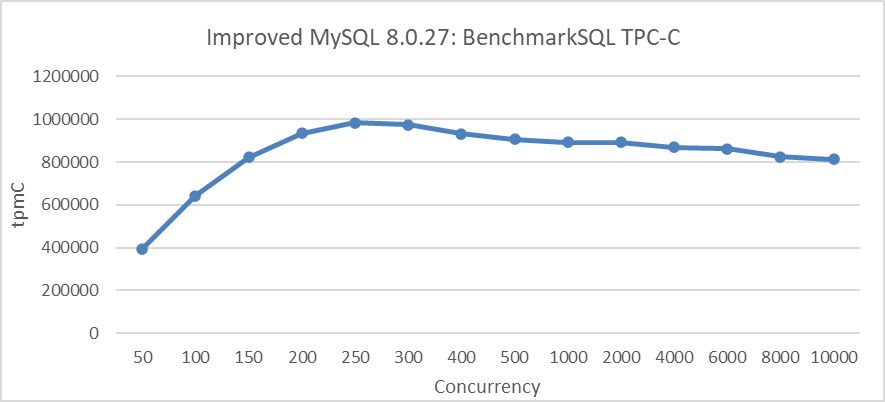
그림 8: 트랜잭션 throttling 메カ니즘을 적용한 BenchmarkSQL의 가장 큰 TPC-C 吞吐量
그림에서 明显的하게 트랜잭션 throttling 메カ니즘의 적용이 MySQL의 스케일ability를 значитель히 改善시켰음을 알 수 있습니다.
요약
전체적으로 BenchmarkSQL TPC-C 시험의 低 충돌 scenarios 下에서 MySQL이 tens of thousands of concurrent connections에서 colapse 하지 않고 パフォーマン스를 유지할 수 있다는 것은 完全に 가능합니다.
참고 문헌
- Bin Wang (2024). The Art of Problem-Solving in Software Engineering: How to Make MySQL Better.
- The New MySQL Thread Pool
- Paweł Olchawa. 2018. MySQL 8.0: New Lock free, scalable WAL design. MySQL Blog Archive.
- Xiangyao Yu. An evaluation of concurrency control with one thousand cores. PhD thesis, Massachusetts Institute of Technology, 2015.
- MySQL 8.0 Reference Manual
Source:
https://dzone.com/articles/mysql-scalability-improvement-for-benchmarksql