













Huidige toestand van MySQL 5.7
MySQL 5.7 is niet ideaal qua schaalbaarheid. De volgende figuur illustreert de relatie tussen TPC-C doorput en concurrency in MySQL 5.7.39 onder een specifieke configuratie. Dit omvat het instellen van de transactieisolatiegraad op Gelezen Gewijs en het aanpassen van het parameter innodb_spin_wait_delay om de doorputdaling te verminderen.
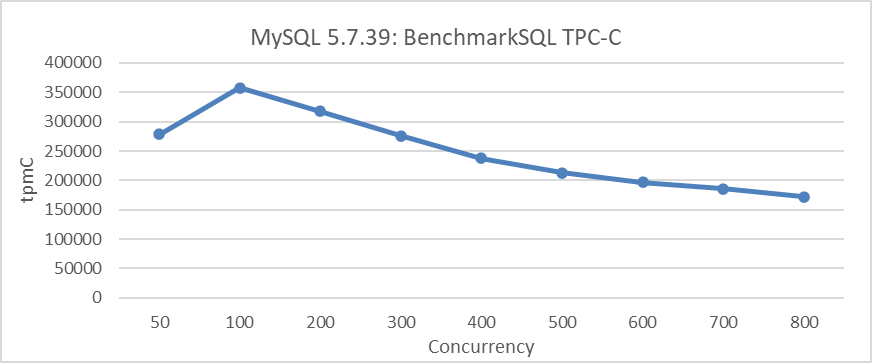
Figuur 1: Schaalbaarheidproblemen in MySQL 5.7.39 tijdens BenchmarkSQL-testen
Van de figuur blijkt dat de schaalbaarheidproblemen de toegenomen doorput van MySQL significant beperken. Bijvoorbeeld, na 100 concurrency beginnen de doorputwaarden af te nemen.
Om de eerdergenoemde performancedaling op te lossen, is Percona’s thread pool ingevoerd. De volgende figuur illustreert de relatie tussen TPC-C doorput en concurrency nadat de Percona thread pool is geconfigureerd.
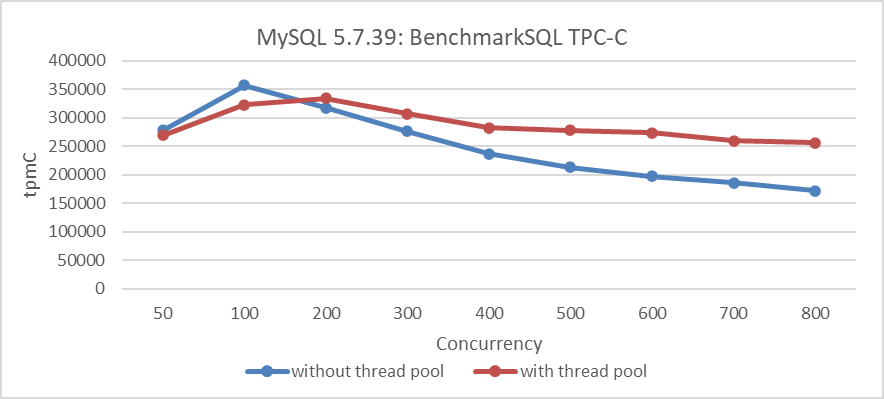
Figuur 2: Percona thread pool helpt bij het verminderen van schaalbaarheidproblemen in MySQL 5.7.39
Alhoewel de thread pool enige overhead introduceert en de piekperformance is afgenomen, heeft het de issue van de performancedaling onder hoge concurrency opgelost.
Huidige toestand van MySQL 8.0
Bekijk nu de pogingen die MySQL 8.0 heeft gedaan qua schaalbaarheid.
Optimalisatie van de Redo Log
De eerste grote verbetering is de optimalisatie van de redo log [3].
commit 6be2fa0bdbbadc52cc8478b52b69db02b0eaff40
Author: Paweł Olchawa <[email protected]>
Date: Wed Feb 14 09:33:42 2018 +0100
WL#10310 Redo log optimization: dedicated threads and concurrent log buffer.
0. Log buffer became a ring buffer, data inside is no longer shifted.
1. User threads are able to write concurrently to log buffer.
2. Relaxed order of dirty pages in flush lists - no need to synchronize
the order in which dirty pages are added to flush lists.
3. Concurrent MTR commits can interleave on different stages of commits.
4. Introduced dedicated log threads which keep writing log buffer:
* log_writer: writes log buffer to system buffers,
* log_flusher: flushes system buffers to disk.
As soon as they finished writing (flushing) and there is new data to
write (flush), they start next write (flush).
5. User threads no longer write / flush log buffer to disk, they only
wait by spinning or on event for notification. They do not have to
compete for the responsibility of writing / flushing.
6. Introduced a ring buffer of events (one per log-block) which are used
by user threads to wait for written/flushed redo log to avoid:
* contention on single event
* false wake-ups of all waiting threads whenever some write/flush
has finished (we can wake-up only those waiting in related blocks)
7. Introduced dedicated notifier threads not to delay next writes/fsyncs:
* log_write_notifier: notifies user threads about written redo,
* log_flush_notifier: notifies user threads about flushed redo.
8. Master thread no longer has to flush log buffer.
...
30. Mysql test runner received a new feature (thanks to Marcin):
--exec_in_background.
Review: RB#15134
Reviewers:
- Marcin Babij <[email protected]>,
- Debarun Banerjee <[email protected]>.
Performance tests:
- Dimitri Kravtchuk <[email protected]>,
- Daniel Blanchard <[email protected]>,
- Amrendra Kumar <[email protected]>.
QA and MTR tests:
- Vinay Fisrekar <[email protected]>.Er is een test uitgevoerd die de TPC-C doorput vergelijkt met verschillende niveaus van concurrency voor en na de optimalisatie. De specifieke details zijn weergegeven in de volgende figuur:
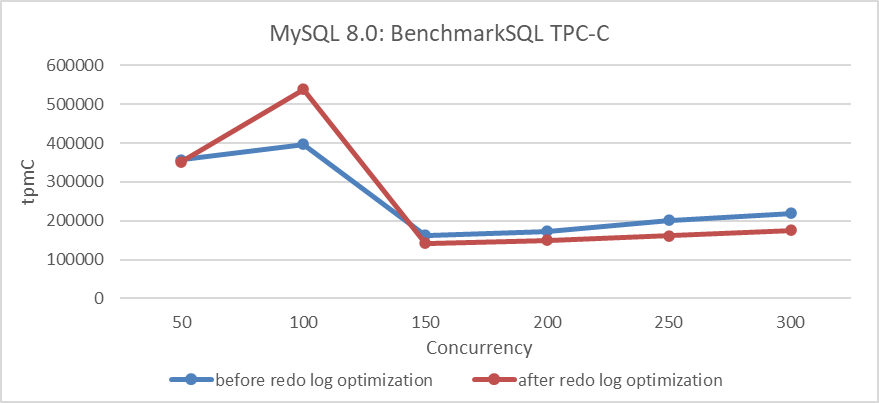
Figuur 3: Impact van redo log-optimalisatie onder verschillende gelijktijdigheidsniveaus
De resultaten in de figuur tonen een aanzienlijke verbetering in throughput bij lage gelijktijdigheidsniveaus.
Optimalisatie van Lock-Sys door Latch Sharding
De tweede grote verbetering is de optimalisatie van lock-sys [5].
commit 1d259b87a63defa814e19a7534380cb43ee23c48
Author: Jakub Łopuszański <[email protected]>
Date: Wed Feb 5 14:12:22 2020 +0100
WL#10314 - InnoDB: Lock-sys optimization: sharded lock_sys mutex
The Lock-sys orchestrates access to tables and rows. Each table, and each row,
can be thought of as a resource, and a transaction may request access right for
a resource. As two transactions operating on a single resource can lead to
problems if the two operations conflict with each other, Lock-sys remembers
lists of already GRANTED lock requests and checks new requests for conflicts in
which case they have to start WAITING for their turn.
Lock-sys stores both GRANTED and WAITING lock requests in lists known as queues.
To allow concurrent operations on these queues, we need a mechanism to latch
these queues in safe and quick fashion.
In the past a single latch protected access to all of these queues.
This scaled poorly, and the managment of queues become a bottleneck.
In this WL, we introduce a more granular approach to latching.
Reviewed-by: Pawel Olchawa <[email protected]>
Reviewed-by: Debarun Banerjee <[email protected]>
RB:23836Op basis van het programma vóór en na optimalisatie met lock-sys, waarbij BenchmarkSQL wordt gebruikt om de TPC-C throughput met gelijktijdigheid te vergelijken, zijn de specifieke resultaten te zien in de volgende figuur:
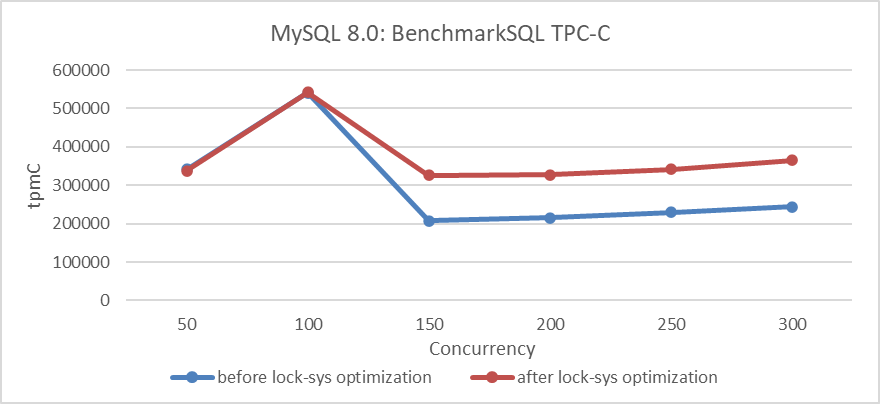
Figuur 4: Impact van lock-sys optimalisatie onder verschillende gelijktijdigheidsniveaus
Uit de figuur blijkt dat het optimaliseren van lock-sys de throughput aanzienlijk verbetert onder hoge gelijktijdigheidsomstandigheden, terwijl het effect minder uitgesproken is bij lage gelijktijdigheid vanwege minder conflicten.
Latch Sharding voor trx-sys
De derde grote verbetering is latch sharding voor trx-sys.
commit bc95476c0156070fd5cedcfd354fa68ce3c95bdb
Author: Paweł Olchawa <[email protected]>
Date: Tue May 25 18:12:20 2021 +0200
BUG#32832196 SINGLE RW_TRX_SET LEADS TO CONTENTION ON TRX_SYS MUTEX
1. Introduced shards, each with rw_trx_set and dedicated mutex.
2. Extracted modifications to rw_trx_set outside its original critical sections
(removal had to be extracted outside trx_erase_lists).
3. Eliminated allocation on heap inside TrxUndoRsegs.
4. [BUG-FIX] The trx->state and trx->start_time became converted to std::atomic<>
fields to avoid risk of torn reads on egzotic platforms.
5. Added assertions which ensure that thread operating on transaction has rights
to do so (to show there is no possible race condition).
RB: 26314
Reviewed-by: Jakub Łopuszański [email protected]Op basis van deze optimalisaties vóór en na, met behulp van BenchmarkSQL om TPC-C throughput met gelijktijdigheid te vergelijken, worden de specifieke resultaten getoond in de volgende figuur:
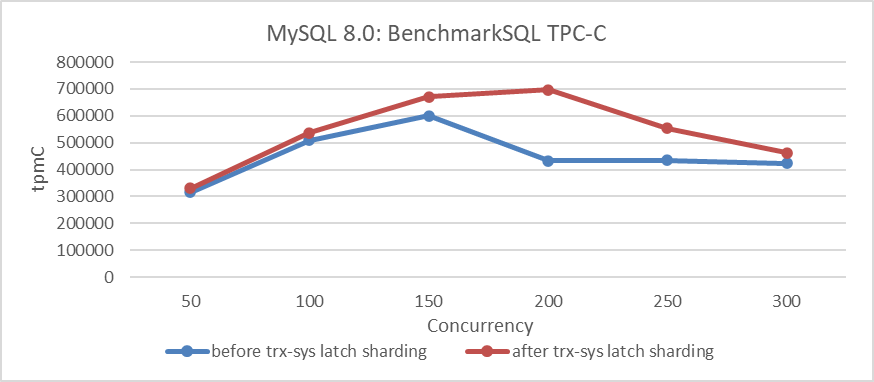
Figuur 5: Impact van latch sharding in trx-sys onder verschillende gelijktijdigheidsniveaus
Uit de figuur blijkt dat deze verbetering de TPC-C throughput aanzienlijk verhoogt en zijn piek bereikt bij 200 gelijktijdigheden. Het is opmerkelijk dat de impact afneemt bij 300 gelijktijdigheden, voornamelijk door aanhoudende schaalbaarheidsproblemen in het trx-sys-subsysteem gerelateerd aan MVCC ReadView.
Verbetering van MySQL 8.0
De overige verbeteringen zijn onze eigen onafhankelijke aanpassingen.
Verbeteringen bij MVCC ReadView
De eerste grote verbetering is de verbetering van de MVCC ReadView-datastructuur [1].
Er zijn prestatievergelijkingsproeven uitgevoerd om de effectiviteit van de MVCC ReadView-optimalisatie te evalueren. Het onderstaande diagram toont een vergelijking van de TPC-C doorput bij verschillende concurrency-niveaus, voor en na de wijziging van de MVCC ReadView-datastructuur.
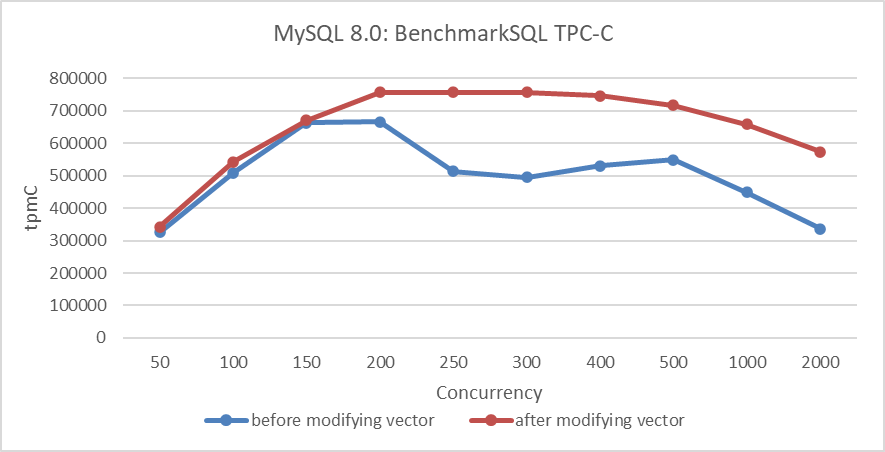
Figure 6: Prestatievergelijking voor en na de invoering van de nieuwe hybride datastructuur in NUMA
Uit het diagram blijkt duidelijk dat deze transformatie vooral de schaalbaarheid optimaliseerde en de piekdoorvoer van MySQL in NUMA-omgevingen verbeterde.
Problemen met dubbele latches voorkomen
De tweede grote verbetering die we hebben uitgevoerd, betreft het aanpakken van het probleem met de dubbele latch, waar “dubbele latch” verwijst naar de vereiste voor de globale trx-sys latch door zowel `view_open` als `view_close` [1].
Met de MVCC ReadView-geoptimaliseerde versie, vergelijk de TPC-C doorput voor en na de wijzigingen. Details zijn weergegeven in het volgende diagram:
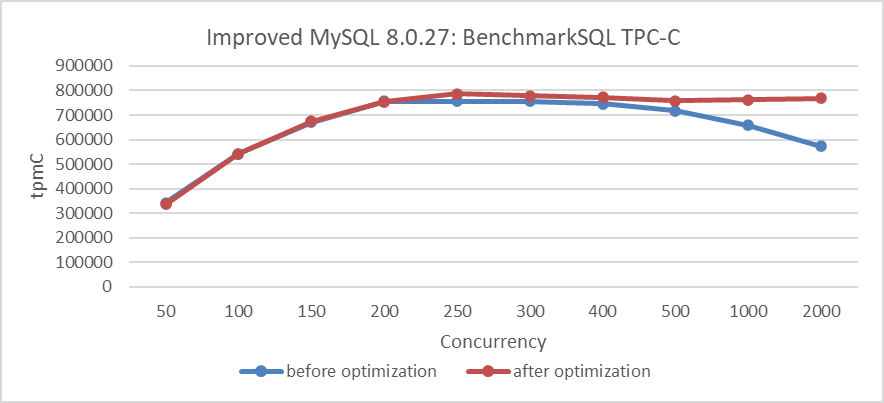
Figure 7: Prestatieverbetering na de eliminatie van de dubbele latch-bottleneck
Uit het diagram blijkt duidelijk dat de wijzigingen de schaalbaarheid significant verbeterden bij hoge concurrency-condities.
Transactieremmingmechanisme
De laatste verbetering is de implementatie van een transactieremmingmechanisme om tegen performance collapse aan te vallen bij extreem hoge concurrency [1] [2] [4].
Het volgende figuur toont de TPC-C-scaleringsstressproef die werd uitgevoerd nadat transactieremming was geïmplementeerd. De test werd uitgevoerd in een scenario waarin de NUMA BIOS uitgeschakeld was, waardoor tot 512 gebruikersthreads in het transactiebestand werden beperkt.
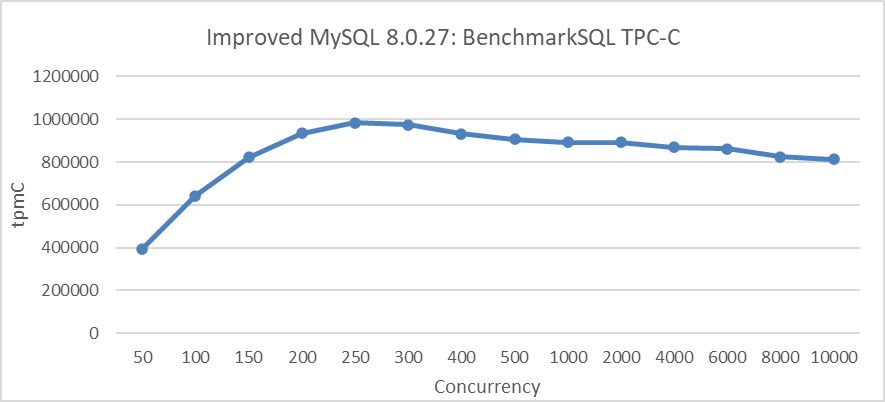
Figuur 8: Maximale TPC-C-doorvoersnelheid in BenchmarkSQL met transactieremmingmechanismen
Uit het figuur blijkt duidelijk dat de implementatie van transactieremmingmechanismen de schaalbaarheid van MySQL significant verbeterd heeft.
Overzicht
In het algemeen is het volledig mogelijk voor MySQL om zonder instabilititeit de performance bij tienduizenden gelijktijdige verbindingen in laagconflictaande scenario’s van de BenchmarkSQL TPC-C-testen te behouden.
Referenties
- Bin Wang (2024). The Art of Problem-Solving in Software Engineering: How to Make MySQL Better.
- The New MySQL Thread Pool
- Paweł Olchawa. 2018. MySQL 8.0: New Lock free, scalable WAL design. MySQL Blog Archive.
- Xiangyao Yu. An evaluation of concurrency control with one thousand cores. PhD thesis, Massachusetts Institute of Technology, 2015.
- MySQL 8.0 Reference Manual
Source:
https://dzone.com/articles/mysql-scalability-improvement-for-benchmarksql