













組織は、災害が発生した場合にデータを保護し、事業の継続を確保するために、ますますバックアップに依存しています。しかし、推定では、72%以上の企業が、復旧ポイント目標(RPO)と復旧時間目標(RTO)に関連するIT復旧の期待を満たすことができないとされています。
効率的な復旧計画を作成するのに役立つためには、RTOとRPOについて完全に理解し、その違いについて学ぶことが不可欠です。この投稿では、信頼性の高い災害復旧戦略のためにこれらの2つのパラメータについて知っておくべきすべてを説明します。災害後でできるだけ早くデータ損失を最小限に抑え、通常の事業運営を再開するために、より緊密なRPOとRTOを実現する方法をご紹介します。
RTOとは何ですか?
復旧時間目標(RTO)とは、組織が障害発生後に許容できる最大のダウンタイムを指します。言い換えれば、RTOは災害発生から影響を受けた重要なワークロードの回復までの期間です。
RTOの計算は一般的に、災害復旧計画、利用可能なリソース、および予算に依存します。ITインフラストラクチャーが利用できない間、障害の原因を特定し、問題を修正するための必要な措置を講じるために時間が必要です。ただし、災害復旧手順は、本番の問題が解決される間に、重要なシステムとワークロードがアクセス可能で利用可能であることを保証するために必要です。RTOは、障害発生からバックアップまたはレプリカワークロードを介したシステムの可用性までの時間です。
RPOとは何ですか?
復旧ポイント目標(RPO)は、重大な影響なしに組織が災害で失うことができる最大のデータ量を表します。この指標は、最後のバックアップ/レプリケーションプロセスからの時間/分で測定されます。データ損失を軽減するためにデータバックアップとレプリカをどのくらい頻繁に作成する必要があるかを決定するために使用します。
理想的な状況では、バックアップまたはレプリケーションジョブは、元のマシンが失敗する直前に完了します。ただし、これは現実ではまれです。したがって、最後の成功したバックアップが作成された時点と元のマシンが失敗した時点との間にギャップがあります。この間、VMは操作を実行しデータを保存しており、おそらくこのデータは失われるでしょう。
災害復旧におけるRTOとRPOとは何ですか
データ保護の究極の目標は明確です:何かがうまくいかない場合に重要なデータが失われないことを確認し、組織の稼働時間と可用性に関するSLAを満たすことができるようにしたいと考えています。ただし、仮想環境のすべての変更を災害復旧(DR)サイトにリアルタイムでミラーリングするのはかなりコストがかかります。そのため、ある程度のデータが失われ、ITサービスが中断される可能性があるという考えを受け入れる必要があります。したがって、あなたの課題は、それらの損失と中断を最小限に抑えることです。
簡単な図を使ってRPOとRTOの概念を説明しましょう:
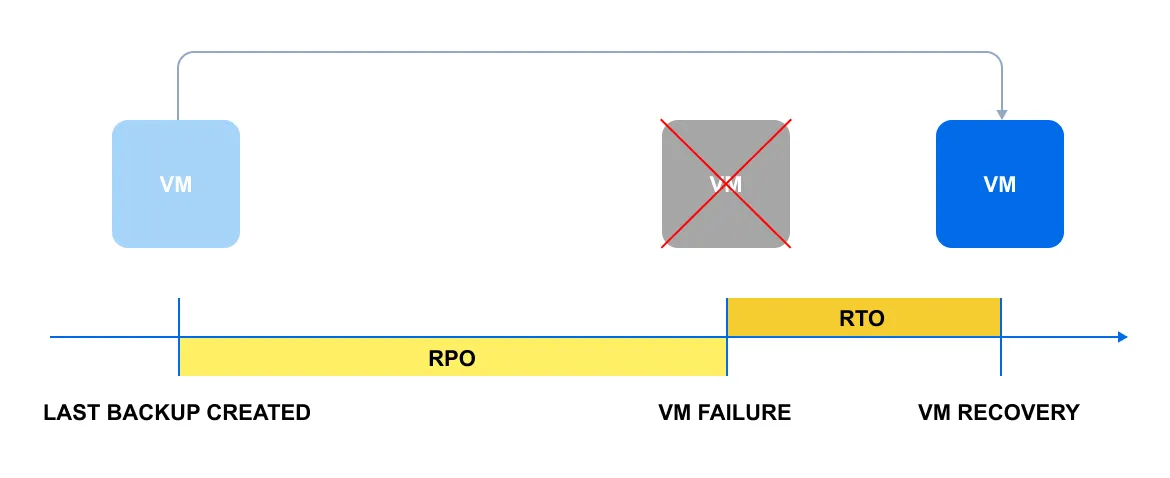
この図は一般的なシナリオを示しています:ある理由で仮想マシンがクラッシュします。黄色の線はRPOを表し、最後のバックアップと中断の間の時間です。オレンジの線はRTOで、VMを復元するのに必要な時間を反映しています。
RTOとRPOの違い
RTOとRPOを決定する方法を理解するには、それらの違いとDRプロセスでの役割を見てみる必要があります。
評価
- RTOは、災害発生時にビジネスオペレーションが再開される期間に関心を持っています。考慮すべきポイントは次のとおりです:
- 組織のニーズと優先事項を評価します。これらは各組織に固有のものです。
- 組織の生存にとって最も重要なサービスおよびアプリケーションにとって最も重要なアプリケーションを考慮し、これらのアプリケーションが失敗した場合の影響を考えます。
- 各システム/アプリケーションを復旧する順序を決定し、最小のダウンタイムでの損失をもたらす成功した災害復旧を確保します。
- RPOは、組織の収益に深刻な損害をもたらすことなく、ダウンタイム中に失われることができるデータ量に焦点を当てています。考慮すべきポイントは次のとおりです:
- バックアップ/レプリケーションの頻度を特定し、最新のVMバックアップと実際の災害の間で失われるデータ量を把握します。
- 組織が各種ワークロードごとに失うことができるデータ量を考慮します。
コスト
RTOとRPOの主な違いは、前者がビジネス構造とDRプロセス全体を考慮し、後者がデータとアプリケーションの重要性のみをビジネスの継続性に関して考慮する点です。したがって、RTO値を満たすことは、迅速な回復を保証するために費用がかかる可能性があります。同様に、より小さいRPOを持つことは、より多くのバックアップを実行し、追加のリカバリーポイントを作成する必要があるため、ストレージコストが増加する可能性があります。
自動化
- RPOはデータとシステムの耐障害性に焦点を当てているため、頻繁なデータバックアップを実行することが推奨されています。多くの現代のバックアップソリューションでは、自動化されたVMバックアップを実行できるようになっており、これによりバックアップ戦略を効率的に達成し、あなたの手間を最小限に抑えることができます。
- RTOの達成はより複雑なプロセスですが、DRイベント中に復旧する必要のあるすべてのビジネスプロセスとシステムコンポーネントを考慮に入れる必要があります。そのため、RTOの目標を達成するために、開始から終了までのDRプロセス全体を自動化し、オーケストレーションすることが推奨されます。
計算の容易さ
- RPO メトリックは、回復プロセスの一つの側面であるデータのみをカバーするため、計算が簡単です。
- RTO は、データやサービスの重要性、ダウンタイムのコスト、DR活動への投資など、組織全体のすべての側面を考慮します。RTOを計算する際には、異なる種類のワークロードやアプリケーションを考慮する必要があります。ビジネス継続計画に基づいてRTOを計算することをお勧めします。これにより、可能なビジネスリスクや脅威が明確になり、業務の再開に必要な手順が記載されます。
組織の異なるワークロードに適用されるRTO を定義するために、以下の質問に答えます。
特定のアプリケーション/システム/マシンがダウンしても組織の主要業務に著しい影響を与えない期間はどのくらいですか?
異なるマシンに対してこの質問に答えた後、期待される結果が現在のビジネスニーズを満たしているかどうかを考慮します。満たしていない場合は、バックアップとDR戦略を改善して、バックアップされたデータをできるだけ最新に保つ方法を考えます。
NAKIVOを使用してより緊密なRPOとRTOを達成する方法
NAKIVO Backup & Replicationを使用すると、仮想および物理マシンのバックアップをより頻繁に作成してRPOを改善できます。目標とする間隔よりも頻繁に定期的なバックアップをスケジュールするだけで十分です。
ソリューションは、即座のVMリカバリとVMware vSphere、Microsoft Hyper-V、およびAmazon EC2のレプリケーション機能により、RTOを短縮します。ネットワークモニタリングサービスを統合し、VMが利用できなくなった直後にリカバリプロセスをトリガーします。重要なVMのオフサイトレプリカ(完全なコピー)も作成できます。元のVMが失敗した場合、レプリカは自動的に起動します。レプリカの維持に必要なリソースが予算を超える場合は、バックアップからの即座のVMブート機能を選択できます。
最も短いRTOを達成するために、NAKIVO Backup&Replicationはサイトリカバリオーケストレーション機能を導入しました。さまざまなDRシナリオに対してVMフェイルオーバーとフェイルバックを完全自動化し、期待される時間枠内でのリカバリを確認する非中断テストを実行します。