













Grafana Lokiは、水平スケーラブルで高可用性のログ集約システムです。シンプルさとコスト効率を重視して設計されています。2018年にGrafana Labsによって作成され、特にクラウドネイティブおよびKubernetes環境向けの従来のログシステムに対する魅力的な代替手段として急速に台頭しています。
Lokiは包括的なログの経過を提供できます。適切なログストリームを選択し、その後関連するログに焦点を当てるためにフィルタリングできます。構造化されたログデータを解析して、カスタマイズされた分析ニーズに応じた形式に整形することもできます。ログは、プレゼンテーション向けに適切に変換されることもあります。たとえば、またはさらなるパイプライン処理。
Lokiは、幅広いGrafanaエコシステムとシームレスに統合します。ユーザーはLogQLを使用してログをクエリできます。LogQLは、意図的にPrometheus PromQLに似せて設計されたクエリ言語であり、既にPrometheusメトリクスで作業しているユーザーにとっては馴染み深い体験を提供し、Grafanaダッシュボード内でメトリクスとログの強力な相関を実現します。
この記事は、Lokiの基本から始まり、基本的なアーキテクチャの概要に続きます。LogQLの基礎については後日説明し、関連するトレードオフで締めくくります。
Lokiの基礎
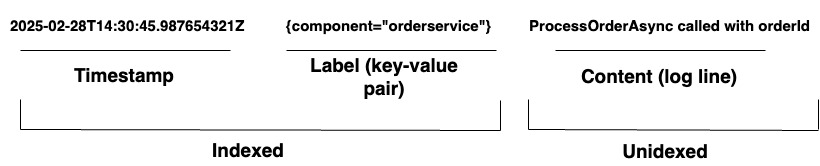
組織が複雑なシステムを管理する場合、Loki は統合されたログソリューションを提供します。広範なエージェントまたはAPIを介して任意のソースからログを取り込み、多様なハードウェアやソフトウェアの包括的なカバレッジを確保します。Loki はログをログストリームとして保存し、Diagram 1 に示されているように、各エントリには以下があります:
- ナノ秒単位の精度を持つタイムスタンプ
- ラベルと呼ばれるキーと値のペアはログの検索に使用されます。ラベルはログ行のメタデータを提供します。データの識別と取得に使用されます。ラベルはログストリームのインデックスを形成し、ログストレージを構造化します。ラベルとその値のユニークな組み合わせごとに異なるログストリームが定義されます。ストリーム内のログエントリはグループ化され、圧縮され、セグメントに保存されます。
- 実際のログコンテンツ。これは生のログ行です。インデックス付けされず、圧縮されたチャンクに保存されます。
アーキテクチャ
Loki のアーキテクチャを、読み取り、書き込み、ログの保存という3つの基本機能に基づいて分析します。Loki は単一のバイナリ(モノリシック)またはマイクロサービスモードで動作し、コンポーネントが独立して拡張可能になります。特定のユースケースに合わせて読み取りと書き込み機能を独立して拡張できます。各パスを詳細に検討してみましょう。
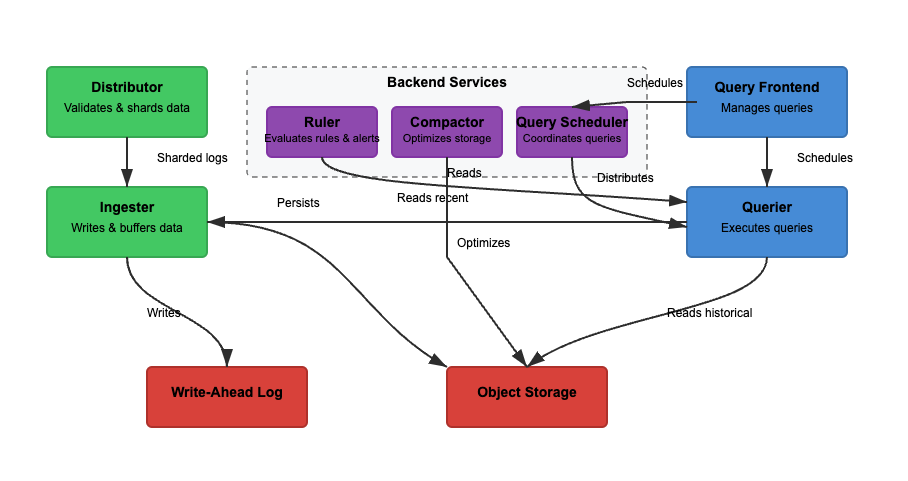
書き込み
図2では、ライトパスは緑色のパスです。ログがLokiに入ると、ディストリビュータはラベルに基づいてログをシャードに分割します。その後、インジェスタはログをメモリに保存し、コンパクタがストレージを最適化します。関与する主なステップは以下の通りです。
ステップ1:ログがLokiに入る
到着したログの書き込みはディストリビュータに到着します。ログはストリームとして構造化され、ラベル(例:{job="nginx", level="error"})が付いています。ディストリビュータはログをシャードに分割し、ログをパーティション化してインジェスタに送信します。各ストリームのラベルをハッシュ化し、一貫性のあるハッシングを使用してインジェスタに割り当てます。ディストリビュータはログを検証し、不正なデータを防ぎます。一貫性のあるハッシングは、インジェスタ全体にわたって均等にログを分散させることができます。
ステップ2:短期ストレージ
インジェスタはログを迅速に取得するためにメモリに保存します。ログはバッチ処理され、データの損失を防ぐためにWrite-Ahead Logs(WAL)に書き込まれます。WALは耐久性に役立ちますが、直接クエリできません。インジェスタは引き続き最近のログのクエリのためにオンラインである必要があります。
定期的に、ログはインジェスタからオブジェクトストレージにフラッシュされます。クエリャとルーラはインジェスタを読み取り、最新のデータにアクセスします。クエリャはさらにオブジェクトストレージのデータにアクセスできます。
ステップ3:ログが長期ストレージに移動
コンパクタは、定期的に長期保存(object-storage)されたログを処理します。オブジェクトストレージは安価でスケーラブルです。これにより、Lokiは高コストをかけずに大量のログを保存できます。コンパクタは重複するログを削除し、ストレージ効率のためにログを圧縮し、保持設定に基づいて古いログを削除します。ログはチャンク形式で保存されます(フルテキストインデックス化されていません)。
読み取り
図2では、読み取りパスは青色のパスです。クエリはクエリフロントエンドに送信され、クエリャがログを取得します。ログはフィルタリング、解析、およびLogQLを使用して分析されます。関連する主なステップは以下の通りです。
ステップ1: クエリフロントエンドがリクエストを最適化
ユーザーはGrafanaでLogQLを使用してログをクエリします。クエリフロントエンドは大きなクエリを複数のクエリャに分割し、並列実行によりクエリを高速化します。クエリの実行を高速化し、失敗時に再試行を保証する責任があります。クエリフロントエンドはタイムアウトや過負荷を回避し、失敗したクエリは自動的に再試行されます。
ステップ2: クエリャがログを取得
クエリャはLogQLを解析し、インジェスタとオブジェクトストレージからクエリを実行します。最新のログはインジェスタから取得し、古いログはオブジェクトストレージから取得します。同じタイムスタンプ、ラベル、コンテンツを持つログは重複排除されます。
ブルームフィルタとインデックスラベルを使用してログを効率的に検索します。count_over_time()のような集計クエリは、Lokiはログを完全にインデックス化しないため、高速に実行されます。Elasticsearchとは異なり、Lokiはログのフルコンテンツをインデックス化しません。
代わりに、メタデータラベル({app="nginx", level="error"})を索引化しており、ログを効率的かつ安価に検索できるようにしています。全文検索は関連するログチャンクのみで実行され、ストレージコストが削減されます。
LogQLの基礎
LogQLは、Grafana Lokiで使用されるクエリ言語であり、ログを効率的に検索、フィルタリング、変換するために使用されます。LogQLには、2つの主要なコンポーネントがあります:
- ストリームセレクタ – ラベルマッチャに基づいてログストリームを選択します
- フィルタリングおよび変換 – 関連するログ行を抽出し、構造化されたデータを解析し、クエリ結果をフォーマットします
これらの機能を組み合わせることで、LogQLを使用してユーザーはログを効率的に取得し、洞察を抽出し、ログデータから有用なメトリクスを生成することができます。
ストリームセレクタ
ストリームセレクタは、すべてのLogQLクエリの最初のステップです。ラベルマッチャに基づいてログストリームを選択します。特定のログストリームにクエリ結果を絞り込むために、私たちはLokiラベルでフィルタリングするための基本演算子を使用できます。ログストリーム選択の精度を高めることで、スキャンされるストリームのボリュームが最小化され、クエリの速度が向上します。
例
{app="nginx"} # Selects logs where app="nginx"
{env=~"prod|staging"} # Selects logs from prod or staging environments
{job!="backend"} # Excludes logs from the backend job行フィルタ
ログが選択されると、行フィルタは特定のテキストを検索したり、論理条件を適用したりして、結果を絞り込みます。行フィルタはラベルではなくログコンテンツに対して機能します。
例
{app="nginx"} |= "error" # Select logs from nginx that contain "error"
{app="db"} != "timeout" # Exclude logs with "timeout"
{job="frontend"} |~ "5\d{2}" # Match HTTP 500-series errors (500-599)パーサ
Lokiは非構造化、半構造化、または構造化されたログを受け入れることができます。ただし、観測性ソリューションを設計および構築する際には、作業しているログ形式を理解することが重要です。これにより、ログデータを効果的に取り込み、保存し、解析することができます。LokiはJSON、logfmt、pattern、regexp、およびunpackパーサーをサポートしています。
例
{app="payments"} | json # Extracts JSON fields
{app="auth"} | logfmt # Extracts key-value pairs
{app="nginx"} | regexp "(?P<status>\d{3})" # Extracts HTTP status codesラベルフィルター
解析されたログは、抽出されたフィールドでフィルタリングすることができます。ラベルは、パーサーとフォーマッター式を使用してログパイプラインの一部として抽出されることができます。その後、ラベルフィルター式を使用して、これらのラベルのいずれかでログ行をフィルタリングできます。
例
{app="web"} | json | status="500" # Extract JSON, then filter by status=500
{app="db"} | logfmt | user="admin" # Extract key-value logs, filter by user=admin行フォーマット
ログの出力を変更するために使用され、フィールドの抽出およびフォーマットを行います。これにより、ログがGrafanaで表示される方法がフォーマットされます。
例
{app="nginx"} | json | line_format "User {user} encountered {status} error"ラベルフォーマット
ラベルの名前を変更、修正、作成、または削除するために使用されます。複数の操作を同時に実行できるように、等号演算のカンマ区切りリストを受け入れます。
例
1. {app="nginx"} | label_format new_label=old_label. #If a log has {old_label="backend"}, it is renamed to {new_label="backend"}. The original old_label is removed.
2. {app="web"} | label_format status="HTTP {{.status}}" #If {status="500"}, it becomes {status="HTTP 500"}.
3. {app="db"} | label_format severity="critical". #Adds {severity="critical"} to all logs.
4. {app="api"} | drop log_level # Drops log_level トレードオフ
Grafana Lokiは、圧縮されたチャンクにログを格納し、最小限のインデックス付きでコスト効率の良いスケーラブルなログ管理ソリューションを提供します。これには、クエリのパフォーマンスと取得速度に関するトレードオフが伴います。ログ全体をインデックス化する従来のログ管理システムとは異なり、Lokiのラベルベースのインデックス付きはフィルタリングの高速化を実現します。
ただし、複雑なテキスト検索を遅くする可能性があります。さらに、Lokiは高スループット、分散環境の処理に優れていますが、スケーラビリティのためにオブジェクトストレージに依存しています。これによりレイテンシが発生し、高カーディナリティの問題を回避するために注意深いラベル選択が必要です。
スケーラビリティとマルチテナンシー
Lokiはスケーラビリティとマルチテナンシーを考慮して設計されています。ただし、スケーラビリティにはアーキテクチャ上のトレードオフが伴います。書き込み(インジェスタ)のスケーリングは、ラベルベースのパーティショニングに基づいてログをシャーディングできるため、簡単です。一方、読み取り(クエリヤー)のスケーリングは難しく、オブジェクトストレージから大規模なデータセットをクエリすることが遅くなる可能性があります。マルチテナンシーはサポートされていますが、テナント固有のクォータ管理、ラベルの爆発、セキュリティ(テナントごとのデータ分離)の管理には慎重な構成が必要です。
事前解析なしでの簡単なデータ取り込み
Lokiはフルログコンテンツをインデックス化しないため、事前解析が必要ありません。ログは圧縮されたチャンク形式で生データで保存されます。Lokiにはフルテキストインデックスがないため、構造化ログ(例:JSON)のクエリにはLogQLの解析が必要です。これは、クエリのパフォーマンスがデータ取り込み前にログの構造化がどれだけうまく行われているかに依存することを意味します。構造化されたログがない場合、フィルタリングは取得時に行われるため、クエリの効率が低下します。
オブジェクトストアへの保存
Lokiはログチャンクをオブジェクトストレージ(例:S3、GCS、Azure Blob)にフラッシュします。これにより、Elasticsearchなどの高価なブロックストレージへの依存が削減されます。
ただし、オブジェクトストレージからのログの読み取りは、データベースから直接クエリを実行するよりも遅い場合があります。 Lokiは、最近のログをインジェスタに保持して高速な取得を実現することでこれを補償します。 圧縮はストレージのオーバーヘッドを減らしますが、大規模なクエリにおいてログの取得遅延が問題となることがあります。
ラベルと基数
ログを検索するためにラベルが使用されるため、効率的なクエリには重要です。 ラベルが不適切な場合、高基数の問題が発生する可能性があります。 高基数のラベル(例:user_id、session_id)を使用すると、メモリ使用量が増加し、クエリの処理が遅くなります。 Lokiはラベルをハッシュ化してログをインジェスタに分散させるため、悪いラベル設計はログの均等な分散を妨げる可能性があります。
早期のフィルタリング
Lokiはオブジェクトストレージに圧縮された生のログを保存しているため、クエリを迅速に行いたい場合は早期にフィルタリングすることが重要です。 小規模なデータセットで複雑な解析を行うと、応答時間が増加します。 このルールによると、良いクエリはクエリ1であり、悪いクエリはクエリ2です。
クエリ1
{job="nginx", status_code=~"5.."} | jsonクエリ1は、job="nginx"およびstatus_codeが5で始まる(500~599のエラー)ログをフィルタリングし、| jsonを使用して構造化されたJSONフィールドを抽出します。 これにより、JSONパーサーによって処理されるログの数が最小限に抑えられ、より高速になります。
クエリ2
{job="nginx"} | json | status_code=~"5.."クエリ2はまず、nginxからすべてのログを取得します。 これは何百万ものエントリーになる可能性があります。 次に、status_codeでフィルタリングする前に、すべてのログエントリーに対してJSONを解析します。 これは非効率であり、かなり遅くなります。
結び
Grafana Lokiは、拡張性とシンプリシティを備えた強力で費用対効果の高いログ集約システムです。メタデータのみをインデックス化することで、ストレージコストを低く抑えながら、LogQLを使用した高速なクエリを可能にしています。
そのマイクロサービスアーキテクチャは柔軟な展開をサポートしており、クラウドネイティブ環境に最適です。この記事では、Lokiとそのクエリ言語の基本に焦点を当てました。Lokiのアーキテクチャの要点を通じて、関連するトレードオフをより良く理解することができます。
Source:
https://dzone.com/articles/grafana-loki-fundamentals-and-architecture