













Amazon Pollyの設定
さあ、Amazon Pollyの設定を始めましょう!このセクションでは、その方法の概要を説明します。
ステップ1:AWSアカウントの作成
Amazon Pollyを使用するには、まずAWSアカウントが必要です。まだアカウントをお持ちでない場合は、AWSサインアップページにアクセスして、アカウントを作成してください。AWSのサービス、Pollyを含むものは使用量に応じて請求されるため、有効な請求情報を提供するようにしてください。
権限のIAMセットアップ
必要な権限を持つIAM(Identity and Access Management)ユーザーを設定することをお勧めします。ユーザーがすべてのPolly機能にアクセスできるように、AmazonPollyFullAccessポリシーを割り当ててください。
ステップ2:Amazon Pollyへの移動
AWS Management Consoleにログインした後、上部の検索バーでPollyを検索します。
AWSコンソールの検索メニュー。
Amazon Pollyサービスをクリックして、Pollyインターフェースに移動します。
テキスト読み上げのためのAmazon Polly
通常、開発者はAmazon Polly APIを使用してテキスト読み上げ機能をアプリケーションに直接統合します。ただし、コードを書かずに異なる声や設定を素早く試すためにAWS Pollyインターフェイスも使用できます。これを行うには、Pollyインターフェース内の試す Polly ボタンをクリックします。このボタンを使用すると、AWSコンソールからさまざまなテキスト入力、音声タイプ、出力形式を試すことができ、Pollyの機能をプログラムで実装する前に簡単に探ることができます。
基本的なテキスト読み上げ変換
基本的なテキスト読み上げ変換を行うには、入力ボックスに「こんにちは、Amazon Pollyへようこそ!」のような文を入力してください。エンジンタイプ(例:Generative、long-form、neural、standard)、言語、声も選択できます。出力をすぐに聞くにはListenをクリックし、Downloadをクリックして.mp3ファイルとしてダウンロードします。
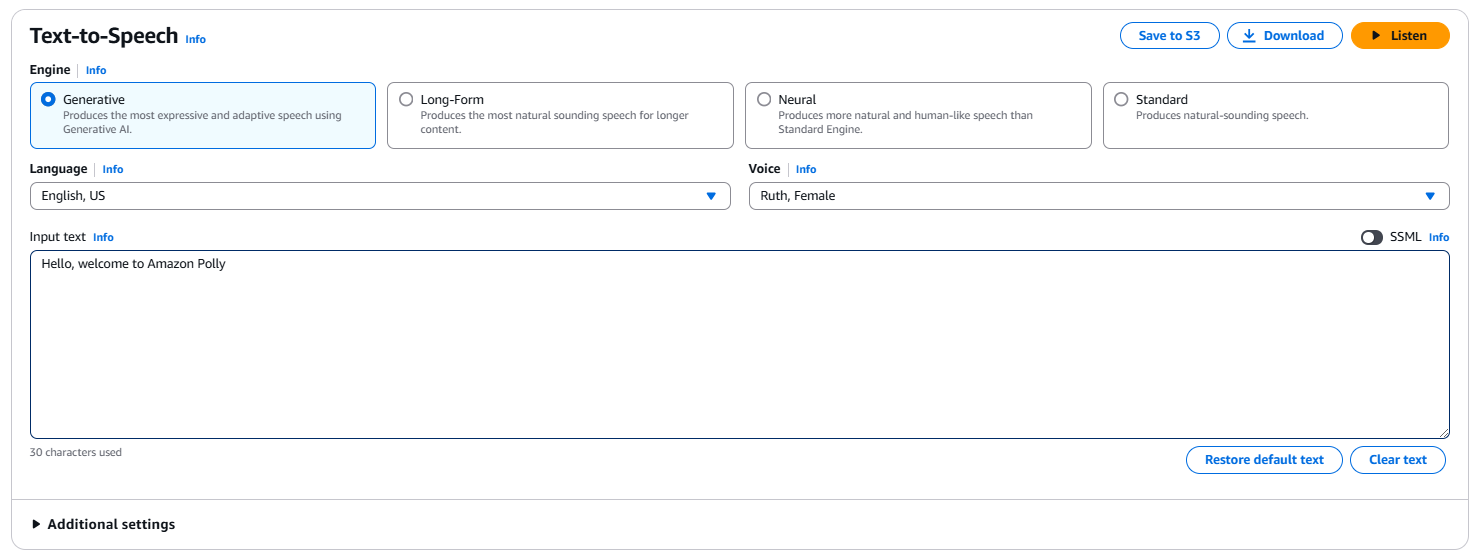
AWSコンソール内のAmazon Pollyインターフェース。
テキスト読み上げのためのAWS SDKのセットアップ
AWS SDKを設定して、アプリケーションにAmazon Pollyをプログラム的に統合する必要があります。これにより、コードから直接Amazon Pollyと対話でき、よりダイナミックでカスタマイズ可能なテキスト読み上げ機能を実現できます。
このチュートリアルでは、Python SDK(boto3)を使用します。pipを使用してboto3をインストールします:
pip install boto3
次に、 AWS CLIを使用してAWS資格情報を構成します:
aws configure
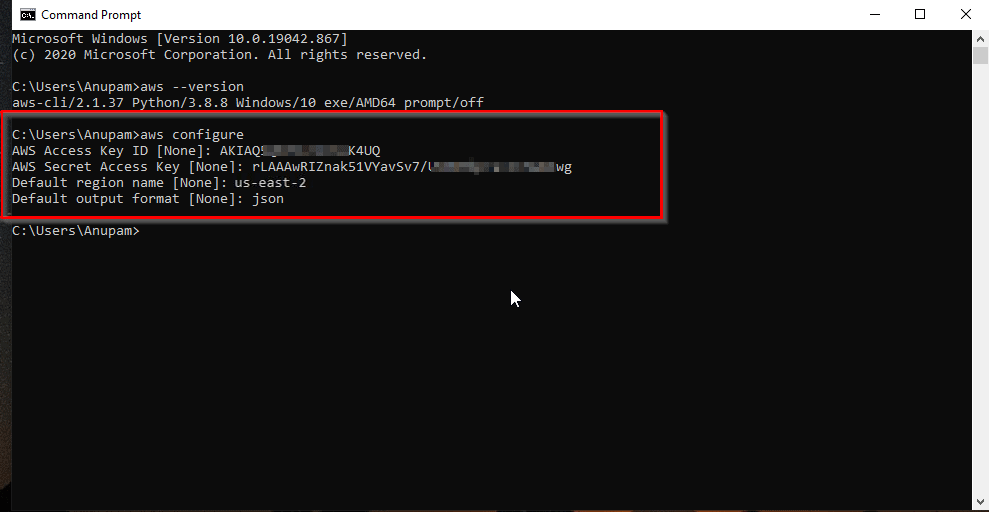
CLI上のaws configureコマンド。SDK経由で音声を生成する
以下はAmazon Pollyを使用してテキストを音声に変換するための簡単なPythonスクリプトです:
import boto3 polly = boto3.client('polly') response = polly.synthesize_speech( Text='Hello, this is a test of Amazon Polly.', OutputFormat='mp3', VoiceId='Joanna' ) with open('speech.mp3', 'wb') as file: file.write(response['AudioStream'].read())
このスクリプトはテキストから音声を生成し、mp3ファイルとして保存します。
Amazon Pollyの高度な機能
Amazon Pollyは基本的なテキスト読み上げ機能で広く知られていますが、開発者がより洗練されたインタラクティブな音声体験を作成するためのさまざまな高度な機能も提供しています。
SSML(音声合成マークアップ言語)を使用すると、ピッチ、速度、音量、強調など、さまざまな音声の側面を制御でき、オーディオ出力をより表現豊かで自然にすることができます。
SSMLタグを使用すると、一時停止を追加したり、話し方を調整したり、略語をアルファベットでスペルアウトしたりすることができます。この柔軟性は、物語、eラーニングプラットフォーム、および顧客サービスアプリケーションなどのシナリオに特に有用であり、トーンやデリバリースタイルがユーザーエンゲージメントに大きな影響を与える場合に役立ちます。
たとえば、特定の単語を強調して重要性を伝えたり、指示コンテンツの話す速度を変更して明瞭さを確保したりすることができます。
Polly SDKを使用してSSMLをどのように使用するか:
response = polly.synthesize_speech( Text="<speak><emphasis level='strong'>Important</emphasis> message!</speak>", TextType='ssml', OutputFormat='mp3', VoiceId='Matthew' ) # オーディオファイルを保存します with open('speech_ssml.mp3', 'wb') as file: file.write(response['AudioStream'].read())
この例は、「重要」という単語を強調して、話されたメッセージの中で目立たせ、聞き手に感情的な影響を与えることを目的としています。SSMLは、音素の発音、囁き、効果音の追加などの高度な機能もサポートしており、開発者に音声体験に対する完全なコントロールを提供します。
リップシンク用のスピーチマーク
スピーチマークは時間に合わせたメタデータを提供し、開発者が音声をアニメーション、テキストのハイライト、またはキャラクターの口の動きと同期させることを可能にします。
この機能は、バーチャルキャラクター、教育ゲーム、またはカラオケスタイルのテキストハイライトなどのインタラクティブなアプリケーションに特に価値があります。
音声合成とともにスピーチマークを要求することで、各単語や文の詳細なタイミング情報を取得でき、動的で同期されたマルチメディア体験を作成することができます。
たとえば、キャラクターの口の動きを話された言葉に合わせてアニメーションさせたり、ナレーションされるテキストをリアルタイムで強調表示したりすることができます。音声マークをリクエストする方法は次のとおりです:
response = polly.synthesize_speech( Text='Hello, world!', OutputFormat='json', VoiceId='Emma', SpeechMarkTypes=['word'] ) # 音声マークをJSONファイルに保存 with open('speech_marks.json', 'wb') as file: file.write(response['AudioStream'].read())
出力JSON:
{"time":6,"type":"word","start":0,"end":5,"value":"Hello"} {"time":714,"type":"word","start":7,"end":12,"value":"world"}
上記の例では、各単語の音声マークをリクエストし、タイムスタンプとテキストデータを含むJSONオブジェクトを返します。開発者はこの情報を使用して、アニメーションをフレームごとに同期させることができ、オーディオビジュアル体験をより魅力的かつリアルにすることができます。
Amazon Pollyによるリアルタイムストリーミング
音声アシスタント、ライブ解説、またはインタラクティブなチャットボットなどのリアルタイムアプリケーションには、Amazon PollyがWebSocketプロトコルを使用したストリーミングやHLS(HTTP Live Streaming)をサポートしています。
これにより、アプリケーションは音声が合成されると同時に再生を開始でき、レイテンシを減らし、より応答性の高いユーザー体験を提供します。リアルタイムストリーミングは、ライブカスタマーサポートや会話型AIなど、即時性が重要なシナリオに最適です。
開発者はこの機能を活用して、音声アクティブデバイス、ニュースリーダー、またはユーザー入力に即座に応答するインタラクティブストーリーテリングアプリケーションを構築できます。
Amazon Pollyリソースの管理
Amazon Pollyリソースの効果的な管理は、パフォーマンス、コスト、スケーラビリティを最適化するために重要です。音声ファイルを戦略的に保存し、使用状況を監視することで、高品質なユーザー体験を維持しながら、効率的なリソース利用を確保できます。
Amazon Pollyは、ストレージ用のAmazon S3やAWS請求ダッシュボードなど、他のAWSサービスとシームレスに統合されており、リソース管理を容易にしています。Amazon Pollyコスト監視。
音声ファイルの作成と管理
Amazon Pollyを使用すると、合成音声をAmazon S3に保存してスケーラブルなストレージと簡単な取得が可能です。このアプローチは、eラーニングプラットフォーム、オーディオブック、またはカスタマーサポートボットなど、繰り返しオーディオが必要なアプリケーションに特に役立ちます。ここでは、各回合成音声を作成する代わりにオーディオファイルを再利用できます。
S3に頻繁に使用される音声出力を保存することで、コストを削減し、クラウドから直接キャッシュされたオーディオファイルを提供することでパフォーマンスを向上させることができます。
s3 = boto3.client('s3') s3.upload_file('speech.mp3', 'your-bucket-name', 'speech.mp3')
使用状況とコストの監視
AWSの請求とコスト管理ダッシュボードを活用して、使用状況とコストを効率的にモニタリングします。このダッシュボードには、詳細なコストの内訳、使用状況レポート、予算やアラートの設定が可能で、予期しない料金を回避するのに役立ちます。
ニューラル音声を使用する際には、コストが標準音声よりも高額になるため、コストをモニタリングすることが特に重要です。また、合成された文字数やAPIコールの頻度などの使用状況メトリクスを追跡することで、リソースの利用を最適化するのに役立ちます。
AWSコストダッシュボードの例。
Amazon Pollyの使用に関するベストプラクティス
Amazon Pollyを使用する際には、ベストプラクティスを採用することで、最適なパフォーマンス、コスト効率、およびユーザーエクスペリエンスを確保できます。以下はいくつかの主要なガイドラインです:
適切な音声の選択
適切な音声を選択することは、アプリケーションの目的やターゲットオーディエンスに依存します。Amazon Pollyには、標準音声やニューラル音声を含むさまざまな音声が用意されており、それぞれ独自の音色や特性を持っています。
- ニューラル音声はより自然で表現豊かな音声を提供しますが、より高価です。そのため、オーディオブックやストーリーテリングなど、高い感情的関与が必要なアプリケーションに最適です。
- 標準音声は、顧客サポートチャットボットなどのユーティリティベースのアプリケーションに費用対効果の高いソリューションを提供します。ユーザーフィードバックを活用して異なる音声をテストし、アプリケーションのニーズに最適な音声を選択するのに役立ちます。
音声出力の最適化
SSML(音声合成マークアップ言語)を活用して、ピッチ、速度、音量のパラメータを調整して音声の品質を向上させる。これらの設定を微調整することで、よりダイナミックで魅力的なオーディオ体験を作成できる。
たとえば、話す速度を遅くすることで、指示内容の明瞭さが向上し、キーフレーズを強調することでストーリーテリングが向上する。さまざまなSSMLタグを試して、最も自然な音声を実現するのに役立つ。
コストの削減
Amazon Pollyを使用する際にコストを最適化するために、音声生成の頻度を管理し、頻繁に使用されるオーディオファイルをS3に保存して再利用する戦略が考慮されるべきだ。このアプローチにより、反復的なAPIコールが最小限に抑えられ、合成コストが削減される。
さらに、標準ボイスとニューラルボイスのミックスを戦略的に使用することで、コストと品質のバランスを取ることができる。
例えば、ウェルカムメッセージのような重要なタッチポイントにはニューラルボイスのみを使用し、情報コンテンツには標準ボイスを使用します。AWS請求ダッシュボードでの使用制限やコストアラートの設定により、予算管理を維持し、予期せぬ支出を回避できます。
結論
Amazon Pollyは、高度なディープラーニング技術を活用してテキストをリアルな音声に変換する強力なテキスト読み上げサービスであり、ユーザーエクスペリエンスとアクセシビリティを向上させます。
このチュートリアルでは、AWS SDKのセットアップからプログラムによる音声生成まで、Amazon Pollyの基本的な機能を探求しました。また、カスタマイズされた音声出力のためのSSMLの使用、リップシンクやアニメーションのためのSpeech Marksの活用、ダイナミックな音声アプリケーションのためのリアルタイムストリーミングの実装など、高度な機能も紹介しました。
アマゾンポリーをアプリケーションに統合することで、世界中のオーディエンスに対応した非常にインタラクティブでパーソナライズされた音声体験を作り出すことができます。バーチャルアシスタント、オーディオブック、教育プラットフォーム、アクセシビリティツールを構築している場合でも、アマゾンポリーはアイデアを実現するために必要な柔軟性、スケーラビリティ、そして高度な機能を提供します。
AWSに不慣れでクラウドスキルを強化したい場合は、これらの関連コースを検討してみてください:
- AWSの概念 – AWSクラウドコンピューティングの基本概念を学びます。
- AWSクラウド技術とサービス – 主要なAWSサービスとその実践的な応用について実践的に学びます。
- AWSセキュリティとコスト管理 – AWSリソースのセキュリティとコスト最適化のためのベストプラクティスを理解します。
- AWSクラウドプラクティショナー認定トラック – 構造化された学習パスでAWSクラウドプラクティショナーCLF-C02試験の準備をします。