













使用しAmazon Auroraをさまざまな企業で使ってきた結果、これは高性能、スケーラビリティ、信頼性を提供する完全に管理されたリレーショナルデータベースエンジンとして優れていることを直接確認しました。
MySQLとPostgreSQLをサポートするクラウドネイティブソリューションとして、Auroraは高可用性と自動スケーリングを必要とする企業にとって優れた選択肢です。AWSがバックアップ、フェイルオーバー、レプリケーションを自動的に管理するため、Auroraを使用することでデータベースの効率を高めつつ、メンテナンスコストを削減することができます。
このチュートリアルでは、Auroraインスタンスの設定、効率的な管理、パフォーマンスの最適化、セキュリティとコスト効率の確保について案内します。
AWS Auroraとは何ですか?
Amazon Auroraは、ストレージやコンピューティングリソースを動的にスケーリングすることで、従来のMySQLやPostgreSQLを凌駕するクラウドベースのリレーショナルデータベースです。
AWSによると、Auroraは、標準のMySQLの5倍のスループットおよび標準のPostgreSQLの3倍のパフォーマンスを提供できます – これは分散型で高可用性なアーキテクチャによるものです。up to five times
Auroraには、自動バックアップ、水平スケーリングのためのリードレプリカ、最小限のダウンタイムを確保するフェイルオーバーメカニズムなどの機能が備わっています。
Auroraのストレージレイヤーは、障害耐性があり自己修復するよう設計されています。
さらに、データは複数の可用性ゾーン(AZs)に自動的にレプリケートされ、耐久性が確保されています。
以下の画像は、Amazon Auroraのアーキテクチャと主な機能の概要を示しています。
Auroraクラスター内のクラスターボリューム、ライターDBインスタンス、およびリーダーDBインスタンスの関係。ソース: AWSドキュメント
データベースエンジンはクエリを継続的に監視し、実行計画を最適化して効率の改善をもたらします。
オーロラの主な利点の一つは、既存のMySQLおよびPostgreSQLデータベースとの互換性があり、企業がアプリケーションを大幅に変更することなく移行できる点です。
オーロラのコスト構造も魅力的です。コンピュートとストレージリソースの実際の使用量に基づいて課金されます。このコストモデルにより、インフラを過剰にプロビジョニングする必要がなくなり、結果的にコストを節約できます。
> AWSストレージオプションについてより広い理解を得たい場合は、このAWSストレージチュートリアルをチェックしてください。
AWSオーロラの設定
AWS Auroraのセットアップには、データベースクラスターの作成、セキュリティ設定の構成、適切なネットワークアクセスの確保が含まれます。このセクションでそれらを行いましょう!
> AWSが初めての方は、Auroraに取り組む前に基礎的なトピックを学んでみることを検討してください。Introduction to AWSコースをご覧ください。
Auroraデータベースクラスターの作成
Auroraデータベースクラスターのセットアップには、適切なデータベースエンジンの選択、セキュリティ設定の構成、インスタンス仕様の定義など、いくつかの重要なステップが必要です。
- 始めるには、AWS Management Consoleにログインして、RDS(リレーショナルデータベースサービス)ダッシュボードに移動します。
- AWS マネジメントコンソールの検索パネルで「Aurora」を検索してください – 以下の画像に示すように。
- そこに移動したら、「データベースの作成」をクリックしてください – 以下の画像に示すように。
- その後、データベースエンジンとして「Amazon Aurora」を選択できます。
- オーロラはMySQLとPostgreSQLの両方をサポートしているため、アプリケーションの要件に最も適したバージョンを選択することが重要です。
以下の画像は現在利用可能なエンジンオプションを示しています。これらは将来変更される可能性がありますが、最初の2つのオプションであるAurora(MySQL互換)とAurora(PostgreSQL互換)がオーロラのエンジンです。
- エンジンを選択した後、インスタンスタイプとストレージ構成を指定する必要があります。
- オーロラは128TBまで自動的にスケーリングする柔軟性を提供し、成長するワークロードを手動介入なしで効率的に処理します。
- 次のステップは複製設定を定義することです。単一のインスタンス展開を選択するか、読み取りレプリカを有効にしてデータベーストラフィックを効果的に分散させることができます。
- 読み取りレプリカを使用することで、可用性と障害耐性が向上し、障害が発生した場合にもより高い耐久性が確保されます。
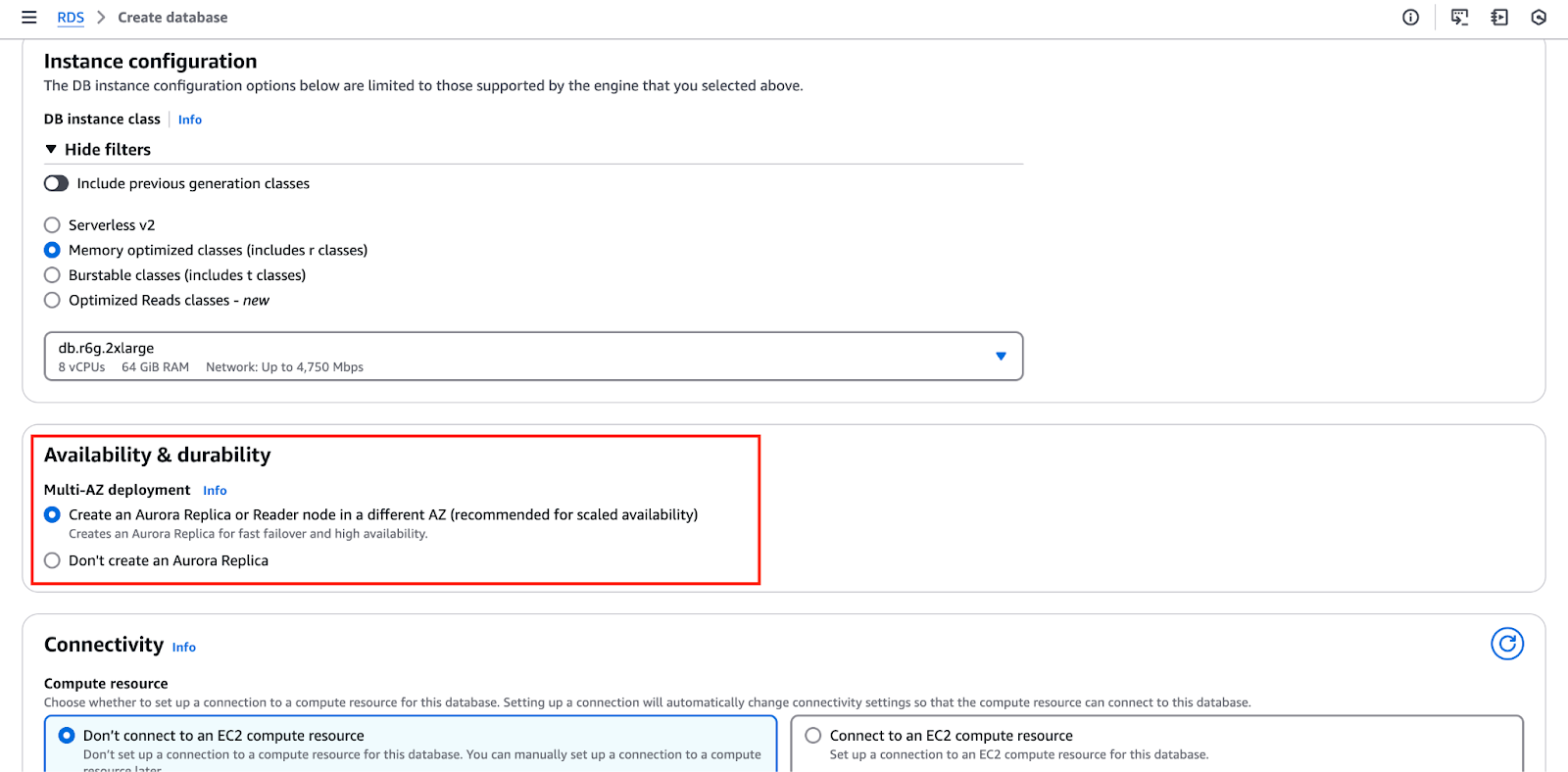
以下の画像は、「可用性と耐久性」セクションを強調しており、これらの設定を構成できます。
- ネットワーキング構成の段階は重要です。これには、仮想プライベートクラウド(VPC)の設定、セキュリティグループの選択、およびアクセス制御の定義が含まれます。
- セキュリティグループは、インバウンドおよびアウトバウンドのデータベーストラフィックを規制するファイアウォールとして機能します。セキュリティを強化するために、信頼されたIPアドレスとアプリケーションからのアクセスのみを許可することが推奨されています。
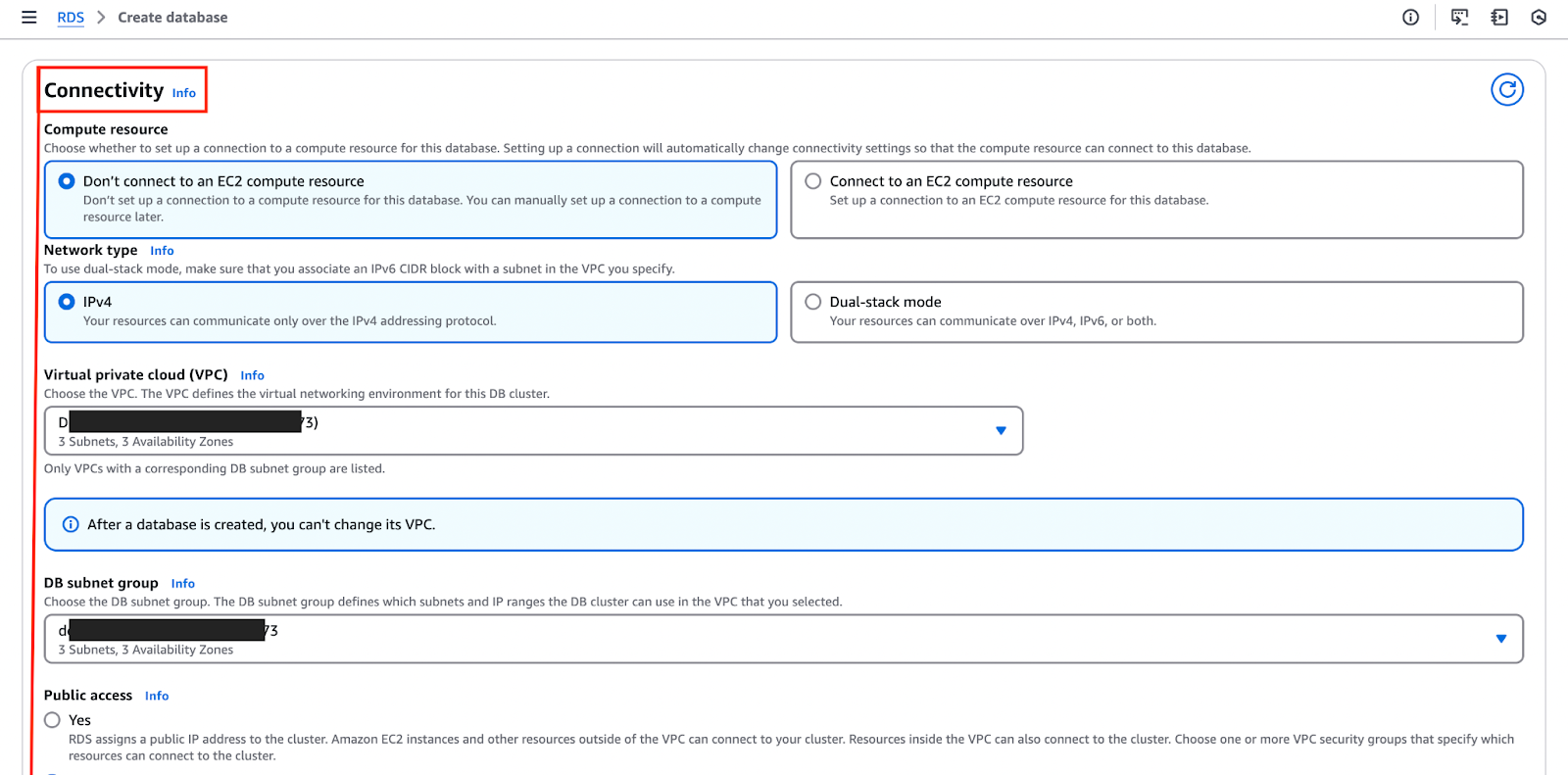
以下の画像は、“接続性”セクションを強調しており、ここでこれらの設定を設定およびカスタマイズできます。
- データベースの資格情報もセットアップ中に設定する必要があります。ここで、接続を認証するために使用されるマスターユーザー名とパスワードを割り当てます。
- Auroraは自動バックアップとポイントインタイムリカバリーオプションを有効にすることができます。これにより、データベースのスナップショットが一貫して作成され、データ損失を防ぎます。
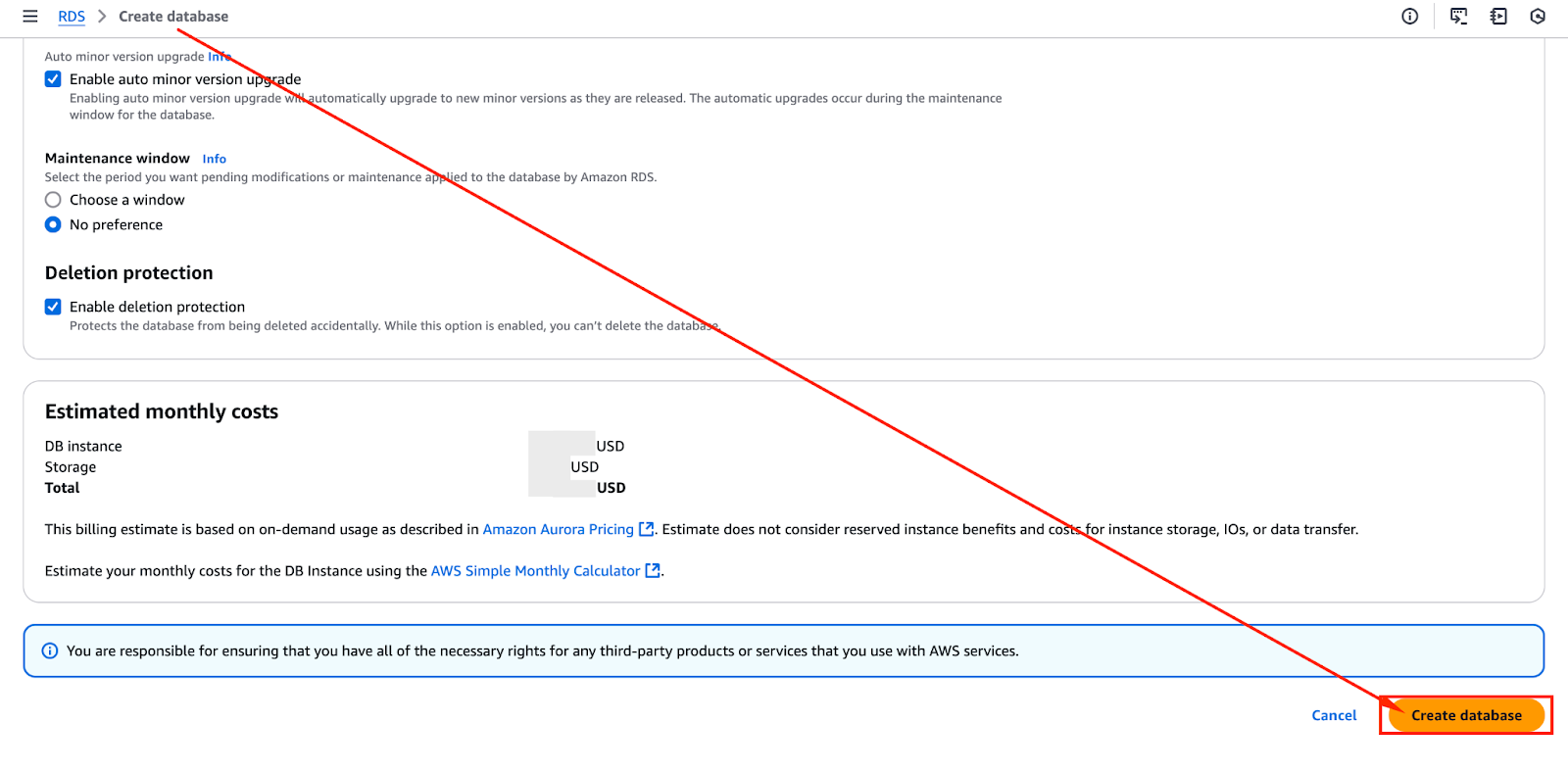
すべての構成を確認した後、Auroraクラスターの作成を進めることができます。以下の画像は、「データベースを作成」ボタンをクリックして作成プロセスを開始できることを示しています。
プロビジョニングプロセスは、選択したインスタンスサイズやネットワーク設定に応じて数分かかる場合があります。
> AWSサービスを初めて利用する場合、こちらのAWSクラウド技術とサービスコースを確認することで、Auroraセットアップに関連する主要なAWSの概念を理解するのに役立ちます。
ネットワークとセキュリティの構成
セキュリティはAuroraデータベースの管理において重要であり、AWSは強力なアクセス制御を実施するための複数のツールを提供しています。
- Auroraインスタンスを保護する最初のステップは、VPCセキュリティグループを設定することです。これらのセキュリティグループは、どのIPアドレスやサービスがデータベースと相互作用できるかを決定します。
- 不正な接続を防ぐために、アクセスを特定のアプリケーションサーバーや管理者に制限するべきです。
- AWS Identity and Access Management (IAM) を使用して、データベース操作に対する細かい権限を定義することもできます。
- IAM ロールを統合することで、特定のユーザーロールや責任に応じてデータベースアクセスを調整できます。
- 例えば、アプリケーション開発者には読み取りアクセスのみが許可され、管理者はデータベースの変更に完全な制御権限を持ちます。
- 機密データを保護するために暗号化も有効にするべきです。AWS Auroraは、AWS Key Management Service(KMS)を使用したデータの安全な保管と転送の両方をサポートしています。
- データを安全に保管するために暗号化を有効にすると、ストレージメディアが侵害されても、適切な復号キーなしにはデータにアクセスできないようになります。
- 同様に、データの転送のためにSecure Sockets Layer(SSL)暗号化を有効にすると、データベース通信の不正な傍受を防ぎます。
> AWS環境のセキュリティを深く掘り下げたい場合は、AWSセキュリティとコスト管理コースを確認してください。IAMの仕組みとその効果的な実装方法についてさらに学びたい場合は、こちらのAWSアイデンティティおよびアクセス管理(IAM).
AWS Auroraへの接続
AWS Auroraに接続することは、データベースとやり取りするために不可欠です。クライアントツールまたはアプリケーションを通じてこれを行うことができます。このセクションでその方法を見てみましょう!
Aurora MySQLへの接続
Auroraデータベースが稼働している場合、データベースとやり取りを開始するために接続を確立する必要があります。
Aurora MySQLでは、MySQL WorkbenchやHeidiSQLなどの一般的なデータベースクライアントを使用して接続することができます。また、コマンドラインインターフェースを使用することもできます。
接続にはデータベースエンドポイントを指定する必要があり、これはAWS管理コンソールで見つけることができます。
MySQL CLIを使用して接続を確立するには、次のコマンドを使用します:
mysql -h your-cluster-endpoint -u admin -p
マスターパスワードを入力した後、SQLクエリを実行したり、テーブルを作成したり、データを管理したりできるはずです。
Aurora PostgreSQLへの接続
Aurora PostgreSQLには、pgAdminやPostgreSQLコマンドラインインターフェース(psql)などのツールを使用して接続できます。
psqlでの接続コマンドはこの形式に従います:
psql -h your-cluster-endpoint -U admin -d yourdatabasename
MySQLと同様に、データベースにアクセスするためには正しい資格情報を入力する必要があります。
アクセス権を取得したら、SQLクエリを実行したり、テーブルを作成したり、データを管理したりできるはずです。
アプリケーションの接続設定
Auroraとやり取りする必要があるアプリケーションは、適切なデータベース接続文字列で構成する必要があります。通常、これらの接続文字列にはユーザー名、パスワード、ポート番号、エンドポイントが含まれます。
パフォーマンスを最適化し、各リクエストごとに新しい接続を確立するオーバーヘッドを減らすために、コネクションプーリングを使用することが推奨されています。
Python向けのSQLAlchemyやJava向けのJDBCなど、一般的なライブラリは、アプリケーション環境での接続管理を効率的に行う方法を提供しています。
AWS Auroraの管理
AWS Auroraを効果的に管理するには、データ保護、パフォーマンスの監視、リソースのスケーリングが必要です。このセクションでは、これらのベストプラクティスについて検討します。
バックアップとスナップショット
AWS Auroraは、データベースの変更を連続的にキャプチャしてAmazon S3に保存する自動バックアップを提供しています。これらのバックアップはユーザーが定義した設定に基づいて保持され、保持期間内の任意のポイントに復元することができます。
自動バックアップに加えて、保持期間を超えて永続化する手動スナップショットも作成できます。手動スナップショットは、長期的なアーカイブや重要なデータベース更新の前に特に役立ちます。
重要なアプリケーションを扱ったプロジェクトでは、自動バックアップを2時間ごとにスケジュールしていました。ただし、アプリケーションの変更や更新を行う前に、必要に応じて手動でバックアップを作成して、必要に応じてロールバックできるようにしていました。これは、自動バックアップと手動バックアップの両方が効果的に組み合わされる方法を示しています。
以下は、AWS BackupがAmazon Auroraの災害復旧にどのように使用されるかを示す画像です。
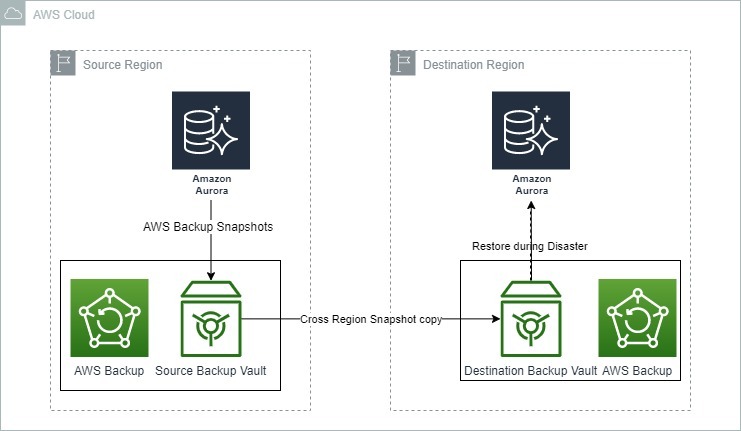
Amazon Auroraのバックアップと復旧オプション。出典:AWS ブログ
CloudWatchを使用したAuroraのモニタリング
パフォーマンスモニタリングは健全なデータベースを維持するために不可欠です。
AWS CloudWatchは、CPU利用率、メモリ使用量、ディスクI/O、ネットワークトラフィックを追跡するリアルタイムメトリクスを提供します。
CloudWatchアラームの設定は、パフォーマンスのしきい値を超えた際に管理者に通知することで、積極的なデータベース管理を可能にします。
さらに、AWS Performance Insightsは詳細なクエリ分析を提供し、遅いクエリを特定して最適化する手助けをします。
以下の画像は、AWS Performance Insightsがデータベースパフォーマンスに関する洞察を提供する方法を示しています。
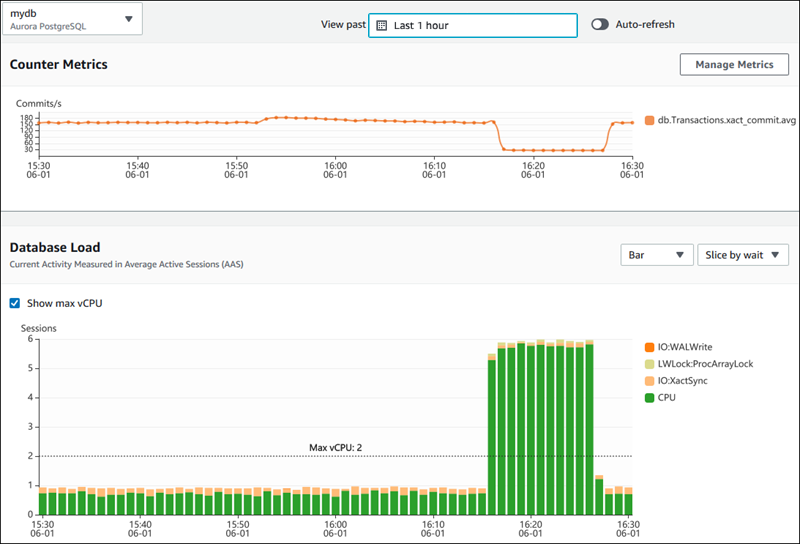
AWS Performance Insightsダッシュボードに表示されるデータベースパフォーマンスメトリクス。出典:AWS ドキュメント
Auroraのスケーリング
Auroraは、必要に応じてストレージ容量を調整することで自動的にスケーリングされるように設計されています。ただし、CPUやメモリなどのコンピューティングリソースは、ワークロードに応じて手動で調整する必要がある場合があります。
Auroraは、読み取りレプリカを追加することで読取り容量を拡張するオプションを提供し、読み取りトラフィックを分散してパフォーマンスを向上させます。
高可用性が重要な場合、Auroraクラスタは複数のレプリカを異なる利用可能ゾーンに構成してフェイルオーバー冗長性を確保できます。
AWS Auroraにおけるパフォーマンス最適化
Amazon Auroraでのパフォーマンスを最適化することは、効率的なクエリ実行とスケーラビリティを確保することにつながります。このセクションでは、いくつかのベストプラクティスを見ていきましょう。
インデックスとクエリの最適化
Amazon Auroraでのクエリパフォーマンスの最適化は、高性能なデータベースを維持するために重要です。
- インデックス作成は、クエリの実行時間を短縮しデータベースの効率性を向上させる効果的な方法の1つです。
- 頻繁にクエリされる列にインデックスを作成することで、データを迅速に見つけるのに役立ち、フルテーブルスキャンの必要性を最小限に抑えることができます。
- クエリパターンやワークロードの要求に合わせて主キーとセカンダリインデックスを戦略的に使用するべきです。
- 上記に加えて、複数の列を対象とするクエリに対して複合インデックスを使用することで、検索時間をさらに短縮することができます。
- クエリの最適化もデータベースのパフォーマンスに大きく影響します。効率的なSQLクエリを書くことで、Auroraはリクエストを高速に処理し、リソースの消費を最小限に抑えます。
EXPLAINまたはEXPLAIN ANALYZEを使用すると、SQLクエリ内のボトルネックを特定し、実行計画について洞察を提供できます。不要なデータを取得するSELECT *を避ける、データベーススキーマを正規化して冗長性を減らす、およびパーティション戦略を活用するなどのテクニックを使用すると、パフォーマンスが向上する可能性があります。- Auroraのクエリプラン最適化プログラムは、データベースのワークロードパターンに基づいて調整を行い、実行計画を継続的に改良するため、全体的な効率が向上します。
Auroraのリードレプリカを使用すると、Amazon Auroraはリードレプリカをサポートしており、リード集中型クエリを複数のインスタンスに分散させるのに役立ちます。
リードレプリカは、読み取りリクエストを別々に処理することにより、主要なデータベースインスタンスへの負荷を軽減し、応答性を向上させ、レイテンシを低下させます。
Auroraのリードレプリカを設定するには、既存のAuroraクラスターを選択し、最小限の構成でレプリケーションを有効にする必要があります。Auroraは、プライマリインスタンスとそのリプリカ間でデータを自動的に同期し、手動での介入なしにデータの一貫性を確保します。
Auroraのレプリケーションメカニズムは非常に効率的であり、1秒未満のレプリケーション遅延でほぼリアルタイムのデータ同期を実現します。
レポートダッシュボードや分析サービスなど、頻繁な読み取り操作を行うアプリケーションは、リードレプリカによって読み取り重視のクエリをこれらのインスタンスに向けることで大きな利益を得ることができます。
プライマリインスタンスの障害が発生した場合、リードレプリカを昇格させて新しいプライマリインスタンスにすることで、最小限のダウンタイムで高可用性と事業継続性を確保できます。
以下の画像は、クロスリージョンのAuroraレプリカが災害復旧や高可用性にどのように役立つかを示しています。
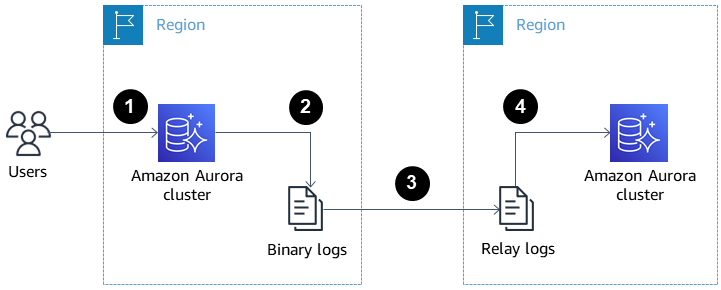
災害復旧と高可用性のためのクロスリージョンAuroraリードレプリカ。出典:AWSドキュメント
Auroraのキャッシュ戦略
キャッシュは、Auroraへの直接クエリ負荷を減らすことでデータベースパフォーマンスを向上させる強力なテクニックです。キャッシュレイヤーは、頻繁にアクセスされるクエリのデータ取得を大幅に高速化できます。
Amazon ElastiCacheはRedisとMemcachedをサポートしており、クエリ結果を保存して冗長なデータベースクエリを防ぐためにAuroraと共によく使用されています。
キャッシュをアプリケーションアーキテクチャに統合することで、レスポンス時間を改善し、データベースの計算リソースを保存することができます。
書き込みスルーキャッシング(データをキャッシュとAuroraの両方に同時に書き込む)やレイジーローディング(データが要求されたときにのみキャッシュされる)などのキャッシュ戦略は、使用パターンに基づいてパフォーマンスを最適化するのに役立ちます。
キャッシュされたデータの適切な有効期限(TTL)を設定することで、キャッシュが新鮮なままで、古いデータの取得を防ぎます。
AWS Auroraにおけるセキュリティとコンプライアンス
Auroraデータベースのセキュリティを確保することは、機密データを保護しコンプライアンスを確保するために非常に重要です。このセクションでは、ベストプラクティスを見直しましょう。
データの暗号化
データセキュリティはデータベース管理にとって基本的であり、AWS Auroraは機密データを保護するための堅牢な暗号化メカニズムを提供しています。
- Auroraは、データの静的暗号化をAWS Key Management Service(KMS)を使用して行い、格納された情報が基礎となるストレージが危険にさらされても安全であることを保証します。
- データベース作成時に暗号化を有効にすると、すべての自動バックアップ、スナップショット、レプリカが同じ暗号化設定を引き継ぎます。
- 移動中のデータについて、AuroraはSSL/TLS暗号化をサポートしており、データベース接続を保護し、データ送信の不正アクセスや傍受を防ぎます。
- Auroraに接続するアプリケーションは、セキュアな通信を維持するためにSSL証明書を使用するように構成されるべきです。
これらの暗号化対策は、セキュリティのベストプラクティスや規制要件に準拠するのに役立ちます。
以下の画像は、AWS KMSがAmazon Auroraと統合してデータベースを暗号化する方法を示しています。
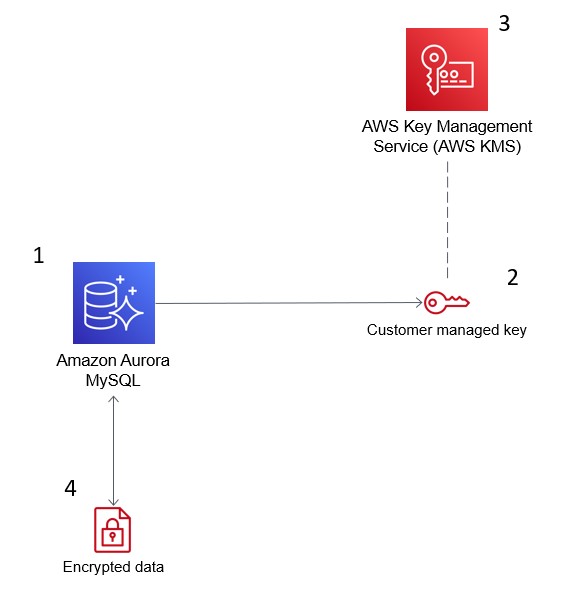
AWS Key Management Service(KMS)は、セキュリティコンプライアンスのためにAmazon Aurora内のデータを暗号化します。出典:AWS Blogs
IAM統合によるアクセス制御
Auroraでのアクセス制御は、AWS IAMを介して管理され、管理者がユーザーロールに基づいて細かい権限を定義できるようにします。
- IAMポリシーを使用して、データベースインスタンスへのアクセスを制限し、データの変更や管理タスクなどの重要な操作を不正なユーザーが行うことを防ぎます。
- IAM認証は、従来のパスワード認証に比べてより安全な代替手段を提供します。アプリケーションが一時的なセキュリティ資格情報を使用して接続できるようにします。これにより、データベースのパスワードを保存および管理する必要がなくなり、資格情報の露出リスクが低減されます。
データベースへのアクセス権限を最小限に抑える最小特権アクセス原則を適用すべきです。これにより、セキュリティリスクが最小限に抑えられ、データベースへのアクセスが厳密に制御されます。
以下の画像は、IAM認証がAmazon Aurora PostgreSQLデータベースアクセスを保護するように構成される方法を示しています。
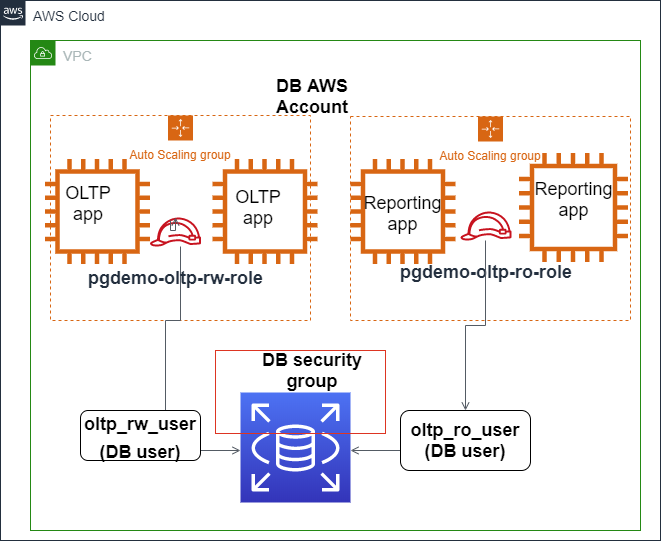
IAM認証はAmazon Aurora PostgreSQLと統合されています。ソース: AWS Blogs
オーロラログを使用した監査
データベースの活動を監視および監査することは、セキュリティコンプライアンスとトラブルシューティングに不可欠です。
オーロラは、エラーログ、遅延クエリログ、一般ログなど、複数のログメカニズムを提供しており、これらは管理者がデータベースの活動を追跡し、潜在的な問題を特定するのに役立ちます。これらのログは、AWS Management Consoleを介して有効にでき、Amazon CloudWatchに保存して集中分析できます。
- エラーログは、データベースエンジンのエラーや警告をキャプチャします。
- 遅延クエリログは、パフォーマンスに影響を与える可能性がある効率の悪いクエリを特定するのに役立ちます。
これらのログを分析することで、管理者はクエリの実行を最適化し、未承認のアクセス試行を検出し、データベースの安定性を確保できます。
Cost Management and Optimization in AWS Aurora
Amazon Auroraでコストを効果的に管理および最適化するには、その価格設定構造を理解する必要があります。それを見てみましょう!
Understanding Aurora pricing
Amazon Auroraの価格モデルは、インスタンス時間、ストレージ消費量、I/Oリクエスト、およびデータ転送など、いくつかの要因に基づいています。
従来のデータベースが事前のインフラ構築を必要とするのに対し、Auroraの従量課金モデルでは、ビジネスが消費するリソースにのみ支払いが発生します。
コンピュートインスタンスはインスタンスクラスと稼働時間に基づいて請求され、ストレージは動的にスケーリングされるため、手動で調整する必要がありません。
以下の画像は、Amazon Auroraの異なる価格構成要素の内訳を示しています。ただし、価格は変更される可能性があるため、常に最新情報を確認するためにAuroraの価格ページを参照するのが最善です。
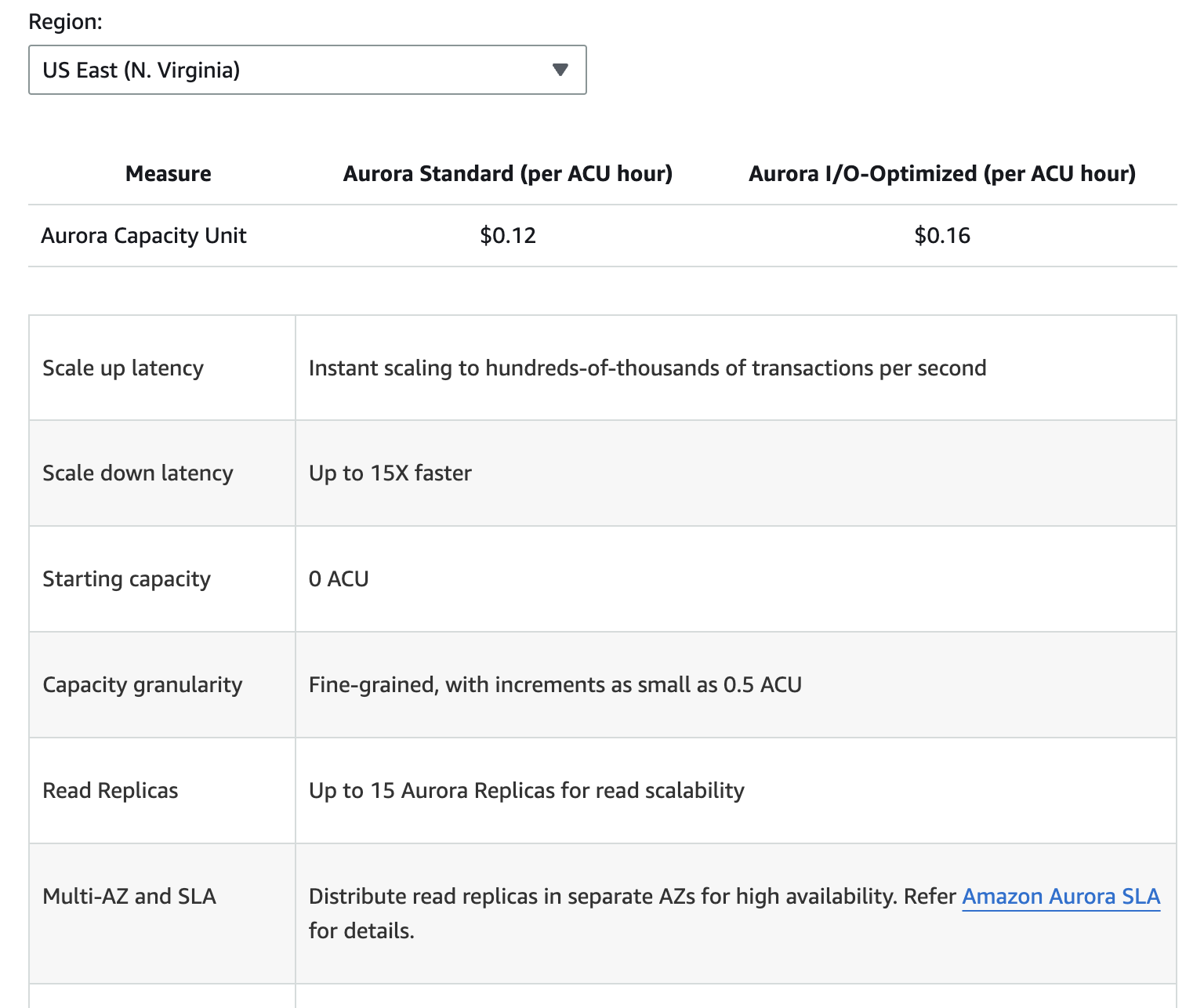
追加のコストには、割り当てられた無料枠を超えるバックアップストレージ、読み書きのI/Oリクエスト、およびリージョン間レプリケーションのデータ転送料金が含まれます。
これらの価格構成要素を理解することで、経費を予測し、データベースの使用に関する情報に基づいた意思決定を行うことができます。
Auroraとコストを最適化する
コストを効果的に管理するために、組織は複数の最適化戦略を実装することができます。
適切なインスタンスサイズを選択することで、データベースリソースが過剰に供給されることなく、ワークロードの需要に合わせることができます。
- 予測可能なワークロードがある場合は、予約済みインスタンスを使用すると、オンデマンド価格と比較して大幅なコスト削減が可能です。
- ストレージの最適化技術、例えば使用されていないまたは過少利用されているリソースを監視することは、コストを削減するのに役立ちます。
- オーロラのオートスケーリング機能はストレージを動的に調整し、不要なストレージ費用を防ぎます。
- また、読み取りレプリカを実装することで、プライマリインスタンスからクエリをオフロードし、より高いインスタンスの必要性を軽減する可能性があります。
- 可変ワークロードを持つアプリケーション向けのもう1つの費用対効果の高いオプションとして、Aurora Serverlessを活用してください。 Aurora Serverlessは需要に応じてコンピューティングリソースを自動的にスケーリングし、ビジネスが継続的に稼働するインスタンスを維持するのではなく、実際の使用料金のみ支払うことを保証します。
>コスト管理に関するさらなる洞察を得たい場合、AWSセキュリティとコスト管理コースを参照してください。
結論
私は長い間複数の企業でAmazon Auroraを使用してきましたが、それは強力でスケーラブルなデータベースソリューションであり、パフォーマンスを犠牲にすることなく管理を容易にします。このチュートリアルを終えた後、おそらく同意するでしょう。
MySQLとPostgreSQLをサポートし、運用オーバーヘッドを削減しながらクラウドネイティブのリレーショナルデータベースを探している場合、Auroraを検討する価値があります。私のいくつかのプロジェクトでは革命的であり、AWSデータベースを使用している場合は、その能力を調べることを強くお勧めします。
AWSデータベースに初めて取り組む場合、AWS Cloud Practitioner (CLF-C02)などのコースを通じて基本的な概念を学ぶことが役立ちます!