













2024年12月11日、OpenAIのサービスは、新しいテレメトリーサービスの展開に起因する問題により、大規模なダウンタイムを経験しました。このインシデントはAPI、ChatGPT、およびSoraサービスに影響を与え、数時間にわたるサービスの中断をもたらしました。正確で効率的なAIソリューションを提供することを目指す企業として、OpenAIは、将来同様の事象を防ぐための計画や何が問題となったかについて透明性を持って議論する詳細な事後報告書を共有しました。
この記事では、インシデントの技術的側面、ルート原因の詳細、および開発者や分散システムを管理する組織がこの出来事から得られる重要な教訓について説明します。
インシデントのタイムライン
以下は、2024年12月11日に起こった出来事のスナップショットです:
| Time (PST) | Event |
|---|---|
| 3:16 PM |
軽微な顧客への影響が始まり、サービスの劣化が観察されました |
| 3:27 PM | エンジニアが影響を受けたクラスターからのトラフィックのリダイレクトを開始しました |
| 3:40 PM | 最大の顧客への影響が記録され、全サービスで大規模な停止が発生しました |
| 4:36 PM | 最初のKubernetesクラスターが回復を開始しました |
| 5:36 PM | APIサービスの大規模な回復が開始されました |
| 5:45 PM | ChatGPTの大規模な回復が観察されました |
| 7:38 PM | 全クラスターで全サービスが完全に回復しました |
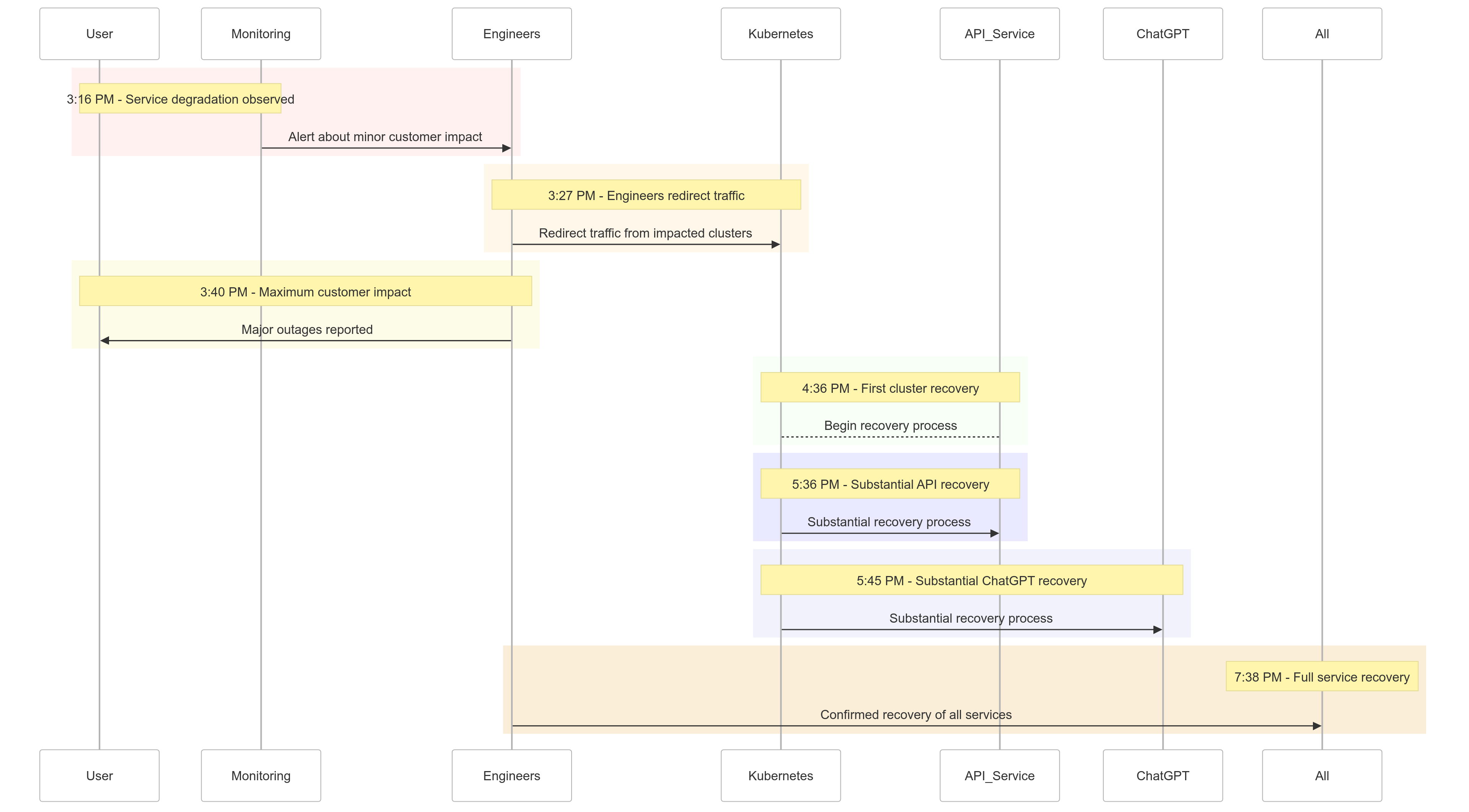
図1: OpenAIインシデントタイムライン – サービスの劣化から完全な回復まで。
ルート原因分析
インシデントのルートは、午後3:12に展開された新しいテレメトリーサービスにありました。これはKubernetesコントロールプレーンの観測性を向上させるために展開されたものでした。このサービスが複数のクラスター全体にわたってKubernetes APIサーバーを圧倒し、連鎖的な障害を引き起こしました。
詳細化
テレメトリーサービスの展開
テレメトリーサービスは詳細なKubernetesコントロールプレーンのメトリクスを収集するように設計されていましたが、その構成が不慮にも同時に数千のノード全体でリソース集約的なKubernetes API操作を引き起こしました。
過負荷のコントロールプレーン
Kubernetesコントロールプレーンは、クラスター管理を担当していましたが、圧倒されました。データプレーン(ユーザーリクエストの処理)は部分的に機能していましたが、DNS解決にはコントロールプレーンが依存していました。キャッシュされたDNSレコードが期限切れになると、リアルタイムDNS解決に依存するサービスが障害を起こしました。
不十分なテスト
展開はステージング環境でテストされましたが、ステージングクラスターはプロダクションクラスターのスケールを反映していませんでした。その結果、テスト中にAPIサーバーの負荷問題が検出されませんでした。
問題の緩和方法
インシデントが始まったとき、OpenAIのエンジニアは迅速に根本原因を特定しましたが、過負荷のKubernetesコントロールプレーンがAPIサーバーへのアクセスを妨げたため、修正の実施に課題がありました。複数のアプローチが採用されました:
- クラスターサイズの縮小: 各クラスターのノード数を減らすことで、APIサーバーの負荷が軽減されました。
- Kubernetes管理APIへのネットワークアクセスのブロック: 追加のAPIリクエストを防ぎ、サーバーが回復できるようにしました。
- Kubernetes APIサーバーのスケールアップ: 追加のリソースを調達することで、保留中のリクエストをクリアするのに役立ちました。
これらの対策により、エンジニアはコントロールプレーンへのアクセスを取り戻し、問題のあるテレメトリーサービスを削除して、サービス機能を復元しました。
学んだ教訓
このインシデントは、分散システムにおける堅牢なテスト、監視、およびフェイルセーフメカニズムの重要性を浮き彫りにしています。OpenAIがダウンタイムから学び(および実施した)ことは以下の通りです:
1. 堅牢な段階的ロールアウト
すべてのインフラ変更は、今後段階的ロールアウトが行われ、継続的な監視が行われます。これにより、問題が早期に検出され、全体のフリートにスケーリングする前に軽減されます。
2. フォルトインジェクションテスト
制御プレーンを無効にする、または不適切な変更をロールアウトするなどの失敗をシミュレーションすることで、OpenAIはシステムが自動的に回復でき、顧客に影響を与える前に問題を検出できることを確認します。
3. 緊急制御プレーンアクセス
「ブレイクグラス」メカニズムにより、エンジニアは重負荷時でもKubernetes APIサーバーにアクセスできるようになります。
4. 制御プレーンとデータプレーンの分離
依存関係を減らすために、OpenAIはKubernetesデータプレーン(ワークロードを処理)を制御プレーン(オーケストレーションを担当)から分離し、制御プレーンの障害時でも重要なサービスが継続して動作できるようにします。
5. より迅速な回復メカニズム
新しいキャッシングおよびレート制限戦略により、クラスターの起動時間が改善され、障害時の迅速な回復が確保されます。
サンプルコード:段階的ロールアウトの例
Kubernetesの段階的ロールアウトを実装する例として、HelmとPrometheusを使用した可観測性の例を示します。
段階的ロールアウトを使用したHelmデプロイメント:
# Deploy the telemetry service to 10% of clusters
helm upgrade --install telemetry-service ./telemetry-chart \
--set replicaCount=10 \
--set deploymentStrategy=phased-rollout
APIサーバーの負荷を監視するためのPrometheusクエリ:
# PromQL Query to monitor Kubernetes API server load
sum(rate(apiserver_request_duration_seconds_sum1m)) by (cluster) /
sum(rate(apiserver_request_duration_seconds_count1m)) by (cluster)
このクエリはAPIサーバーのリクエストに対する応答時間を追跡し、負荷の急増を早期に検出するのに役立ちます。
障害注入の例
chaos-meshを使用することで、OpenAIはKubernetes制御プレーンの障害をシミュレートできます。
# Inject fault into Kubernetes API server to simulate downtime
kubectl create -f api-server-fault.yaml
api-server-fault.yaml:
apiVersionchaos-mesh.org/v1alpha1
kindPodChaos
metadata
nameapi-server-fault
spec
actionpod-kill
modeone
selector
namespaces
kube-system
labelSelectors
appkube-apiserver
この設定は、システムの耐障害性を確認するためにAPIサーバーポッドを意図的に停止させます。
これがあなたにとって意味すること
このインシデントは、強靭なシステムを設計し、厳密なテスト手法を採用する重要性を強調しています。規模の大きな分散システムを管理しているか、ワークロードにKubernetesを導入している場合でも、以下のポイントを考慮してください:
- 定期的に障害をシミュレートする:Chaos Meshなどのカオスエンジニアリングツールを使用して、実世界の条件下でシステムの堅牢性をテストします。
- 複数のレベルで監視する: サービスレベルのメトリクスとクラスタの健全性メトリクスの両方を追跡する可観測性スタックを確保します。
- 重要な依存関係を分離する:DNSベースのサービス検出など、単一障害点への依存を減らします。
結論
どんなシステムも障害に免疫性があるわけではありませんが、このようなインシデントは、透明性、迅速な是正、継続的な学習の価値を思い出させてくれます。OpenAIのこの事後分析を共有する積極的なアプローチは、他の組織が運用プラクティスと信頼性を向上させるための設計図となっています。
堅牢な段階的展開、障害注入テスト、そして強靭なシステム設計を優先することで、OpenAIは大規模な障害からの対処と学び方の手本を示しています。
分散システムを管理するチームにとって、このインシデントはリスク管理へのアプローチや主要ビジネスプロセスのダウンタイムを最小限に抑える方法の素晴らしいケーススタディです。
これをより良い、より強靭なシステム構築の機会として活用しましょう。
Source:
https://dzone.com/articles/what-we-should-learn-from-openais-downtime-incident