













SettingWithCopyWarningは、PandasがDataFrameへの代入時に発生する警告です。これは、チェーンされた代入やスライスから作成されたDataFrameを使用した場合に起こります。これはPandasコードでよくあるバグの原因であり、誰もが遭遇したことがあるかもしれません。これは、正常に動作するはずのコードで警告が表示されることがあるため、デバッグが困難な場合があります。
SettingWithCopyWarningを理解することは重要です。なぜなら、これはデータ操作に関する潜在的な問題を示唆しているからです。この警告は、コードが意図した通りにデータを変更していない可能性があり、意図しない結果や追跡が難しいバグが発生する可能性があります。
この記事では、PandasのSettingWithCopyWarningについて探求し、それを回避する方法について説明します。また、Pandasの将来と、copy_on_writeオプションがDataFramesとの作業方法を変える方法についても議論します。
DataFrameのビューとコピー
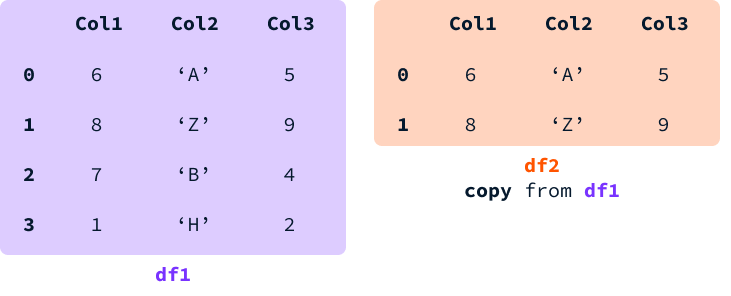
DataFrameのスライスを選択して変数に代入すると、ビューまたは新しいDataFrameコピーを取得することができます。
ビューの場合、両方のDataFrame間でメモリが共有されます。つまり、両方のDataFrameに存在するセルの値を変更すると、両方が変更されます。

コピーの場合、新しいメモリが割り当てられ、元のDataFrameと同じ値を持つ独立したDataFrameが作成されます。この場合、両方のDataFrameは異なるエンティティであり、どちらかの値を変更しても他方に影響を与えません。
Pandasはパフォーマンスを最適化するためにコピーを作成することを避けようとします。ただし、事前にビューかコピーかを予測することは不可能です。 SettingWithCopyWarning は、DataFrameに値を割り当てる際に、それが他のDataFrameからのビューかコピーか不明確な場合に発生します。
実データで SettingWithCopyWarning を理解する
私たちは、この Kaggle データセット「不動産データロンドン2024」を使用して、SettingWithCopyWarning が発生する方法と修正方法を学びます。
このデータセットには、ロンドンの最近の不動産データが含まれています。データセットに含まれる列の概要は次のとおりです:
addedOn: リストが追加された日付。title: リストのタイトル。descriptionHtml: リストのHTML説明。propertyType: 物件のタイプ。「Not Specified」の場合、タイプが指定されていないことを示します。sizeSqFeetMax: 平方フィートでの最大サイズ。bedrooms: ベッドルームの数。listingUpdatedReason: リストを更新した理由(新規リスト、価格の引き下げなど)。price: ポンドでのリストの価格。
明示的な一時変数を使用した例
指定されていないプロパティタイプを持つプロパティは家であると言われたとします。したがって、propertyTypeが"Not Specified"であるすべての行を"House"に更新したいとします。これを行う1つの方法は、非指定のプロパティタイプを持つ行を一時的なDataFrame変数にフィルタリングし、propertyType列の値を次のように更新することです:
import pandas as pd dataset_name = "realestate_data_london_2024_nov.csv" df = pd.read_csv(dataset_name) # 指定されていないプロパティタイプを持つすべての行を取得 no_property_type = df[df["propertyType"] == "Not Specified"] # これらの行のプロパティタイプを「House」に更新 no_property_type["propertyType"] = "House"
このコードを実行すると、pandasはSettingWithCopyWarningを生成します:
SettingWithCopyWarning: A value is trying to be set on a copy of a slice from a DataFrame. Try using .loc[row_indexer,col_indexer] = value instead See the caveats in the documentation: https://pandas.pydata.org/pandas-docs/stable/user_guide/indexing.html#returning-a-view-versus-a-copy no_property_type["propertyType"] = "House"
これは、pandasがno_property_type DataFrameがdfのビューなのかコピーなのかを知ることができないためです。
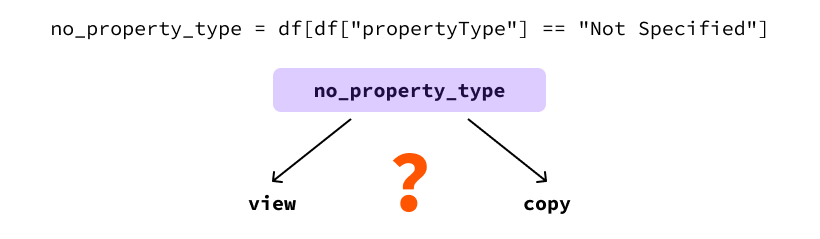
これは問題です。なぜなら、次のコードの動作は、それがビューなのかコピーなのかによって非常に異なる可能性があるからです。
この例では、元のDataFrameを修正することが目標です。これはno_property_typeがビューである場合にのみ起こります。コードの残り部分がdfが修正されたと仮定している場合、それがそうであることを保証する方法がないため、誤る可能性があります。この不確かな振る舞いのため、Pandasはその事実を知らせるために警告を発します。
コードがビューを取得したために正常に実行されたとしても、後続の実行でコピーを取得する可能性があり、コードは意図したとおりに動作しません。したがって、この警告を無視せず、常にコードが望む動作をするように確認することが重要です。
一時変数を使用した例
前の例では、DataFrameの一部をno_property_typeという変数に明示的に割り当てているため、一時変数が使用されていることが明確です。
ただし、一部の場合では、これがそう明示的ではありません。 SettingWithCopyWarningが発生する最も一般的な例は、チェーンされたインデックスを使用する場合です。最後の2行を1行に置き換えると仮定します:
df[df["propertyType"] == "Not Specified"]["propertyType"] = "House"
一見すると、一時変数が作成されていないようには見えません。 ただし、実行するとSettingWithCopyWarningが発生します。
このコードの実行方法は次のとおりです:
df[df["propertyType"] == "Not Specified"]が評価され、一時的にメモリに保存されます。- その一時メモリ位置のインデックス
["propertyType"]がアクセスされます。

インデックスアクセスは1つずつ評価されるため、チェーンされたインデックスは中間結果がビューなのかコピーなのかわからないため、同じ警告が発生します。 上記のコードは、実質的に次のことと同じです:
tmp = df[df["propertyType"] == "Not Specified"] tmp["propertyType"] = "House"
この例はしばしば[]を使用してインデックスアクセスを連鎖させることから、チェーンされたインデックスと呼ばれることがよくあります。最初に[df["propertyType"] == "Not Specified"]にアクセスし、次に["propertyType"]にアクセスします。

SettingWithCopyWarningの解決方法
コードを書く方法を学びましょう。曖昧さがなくなり、SettingWithCopyWarning がトリガーされないようにします。この警告は、DataFrame が他のDataFrameのビューかコピーかについての曖昧さから生じることを学びました。
問題を修正する方法は、作成する各DataFrameがコピーであるか、ビューであるかを明確にすることです。
locを使用して元のDataFrameを安全に修正する
上記の例から元のDataFrameを修正したい場合のコードを修正しましょう。一時変数を使用せずに、locインデクサプロパティを使用します。
df.loc[df["propertyType"] == "Not Specified", "propertyType"] = "House"
このコードでは、locインデクサプロパティを介して元のdf DataFrameに直接アクセスしているため、中間変数は必要ありません。これは、元のDataFrameを直接変更したいときに行う必要があることです。
最初に見ると、チェーンされたインデックスのように見えるかもしれませんが、そうではありません。各インデックスを定義するのは角かっこの[]です。

locを使用する場合は、上記のように値を直接代入する場合にのみ安全です。代わりに一時変数を使用すると、同じ問題に再び陥ります。問題を修正しない2つのコード例を以下に示します。
locを一時変数と一緒に使用する方法:
# locと一時変数を一緒に使用しても問題は解決されません no_property_type = df.loc[df["propertyType"] == "Not Specified"] no_property_type["propertyType"] = "House"
locをインデックスと組み合わせて使用する方法(チェインされたインデックスと同じ):
# locとインデックスを使用した場合、チェインされたインデックスと同じです df.loc[df["propertyType"] == "Not Specified"]["propertyType"] = "House"
これらの例は、一般的な誤解として、locがあれば元のデータが変更されると考えられているため、人々を混乱させる傾向があります。これは誤りです。元のDataFrameに値が割り当てられていることを確実にする唯一の方法は、単一のlocを使用して直接割り当てることです。
元のDataFrameのコピーを使用して安全に作業する方法:copy()
データフレームのコピーで操作していることを確認したい場合は、.copy()メソッドを使用するべきです。
例えば、物件の1平方フィートあたりの価格を分析するように求められたとします。元のデータを変更したくないので、分析結果を別のチームに送るために新しいデータフレームを作成することが目標です。
最初のステップは、いくつかの行をフィルタリングしてデータをクリーンアップすることです。具体的には、次のようにする必要があります:
sizeSqFeetMaxが定義されていない行を削除します。priceが"POA"(price on application) の行を削除します。- 価格を数値に変換します(元のデータセットでは、価格は次の形式の文字列です:
"£25,000,000")
以下のコードを使用して上記の手順を実行できます:
# 1. サイズや価格のないすべての物件をフィルタリングします properties_with_size_and_price = df[df["sizeSqFeetMax"].notna() & (df["price"] != "POA")] # 2. 価格列から £ と , の文字を削除します properties_with_size_and_price["price"] = properties_with_size_and_price["price"].str.replace("£", "", regex=False).str.replace(",", "", regex=False) # 3. 価格列を数値に変換します properties_with_size_and_price["price"] = pd.to_numeric(properties_with_size_and_price["price"])
1平方フィート当たりの価格を計算するには、price列をsizeSqFeetMax列で割った結果を値とする新しい列を作成します。
properties_with_size_and_price["pricePerSqFt"] = properties_with_size_and_price["price"] / properties_with_size_and_price["sizeSqFeetMax"]
このコードを実行すると、再びSettingWithCopyWarningが表示されます。これは、明示的に作成および変更された一時的なDataFrame変数properties_with_size_and_priceがあるためです。
元のDataFrameではなく、データのコピーで作業したいため、properties_with_size_and_priceが新しいDataFrameのコピーであり、ビューではないことを確認することで問題を修正できます.copy()メソッドを最初の行で使用します:
properties_with_size_and_price = df[df["sizeSqFeetMax"].notna() & (df["price"] != "POA")].copy()
新しい列の安全な追加
新しい列の作成は値の割り当てと同様に動作します。コピーかビューかが曖昧な場合、pandasはSettingWithCopyWarningを発生させます。
データのコピーで作業したい場合は、.copy()メソッドを使用して明示的にコピーする必要があります。その後、新しい列を自由に割り当てることができます。前の例でpricePerSqFt列を作成したときに行いました。
一方、元のDataFrameを変更したい場合、考慮するべき2つのケースがあります。
- 新しい列がすべての行にまたがる場合、元のDataFrameを直接変更できます。これにより、行のサブセットを選択しないため、警告が発生しません。例えば、家のタイプが欠落しているすべての行に
note列を追加できます:
df["notes"] = df["propertyType"].apply(lambda house_type: "Missing house type" if house_type == "Not Specified" else "")
- 新しい列が行のサブセットの値のみを定義する場合は、
locインデクサーを使用できます。例:
df.loc[df["propertyType"] == "Not Specified", "notes"] = "Missing house type"
この場合、選択されなかった列の値は未定義になるため、最初のアプローチが好ましいです。各行に値を指定できるためです。
SettingWithCopyWarning Pandas 3.0のエラー
現時点では、SettingWithCopyWarningは警告であり、エラーではありません。コードは実行され、Pandasは単に注意を促しています。
公式のPandasドキュメントによると、SettingWithCopyWarningは、バージョン3.0からはもはや使用されず、実際のエラーに置き換えられ、より厳しいコード規範が適用されます。
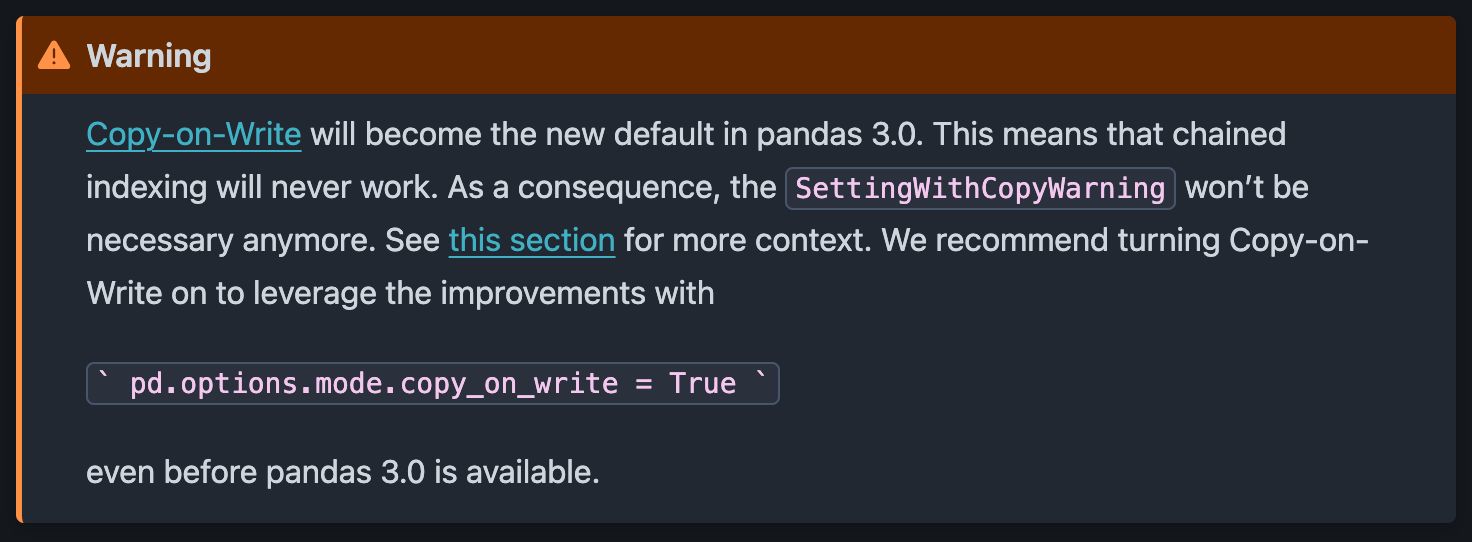
将来のpandasのバージョンと互換性を保つために、警告ではなくエラーを発生させるようコードを更新することが推奨されています。
これは、pandasをインポートした後に次のオプションを設定することで行われます:
import pandas as pd pd.options.mode.copy_on_write = True
既存のコードにこれを追加すると、コード内の曖昧な代入ごとに対処し、pandas 3.0 に更新した際にもコードが動作することを確認できます。
結論
SettingWithCopyWarning は、コードが修正している値がビューなのかコピーなのかが曖昧な場合に発生します。私たちが望む動作を常に明示することで修正できます:
- コピーで作業したい場合は、
copy()メソッドを使用して明示的にコピーする必要があります。 - 元のDataFrameを変更したい場合は、データにアクセスする際に中間変数を使用せずに直接値を代入するために、
locインデクサー プロパティを使用する必要があります。
エラーではないが、この警告を無視すべきではない。なぜなら、予期せぬ結果をもたらす可能性があるからだ。さらに、Pandas 3.0からは、デフォルトでエラーになるため、現在のコードでpd.options.mode.copy_on_write = Trueを使用してCopy-on-Writeをオンにすることで、コードが将来のPandasのバージョンでも機能するようにする必要がある。
Source:
https://www.datacamp.com/tutorial/settingwithcopywarning-pandas