













機械学習(ML)のフィーチャーストアは、Uberが2017年にミケラエロで概念を導入して以来、ビジネスクリティカルなアプリケーションで注目と利用が集まっています。このブログ記事では、MLフィーチャーストアの基本を掘り下げ、なぜScyllaDBがあなたのフィーチャーストアアーキテクチャの重要な一部になりうるのか、そしてどのようになるのかを探ります。
フィーチャーストアが何であるかを理解するためには、まず特徴量が何であるかを理解することが重要です。
特徴量とは何か?
機械学習において、特徴量は、モデルを教えるために使用でき、過去のデータに基づいて将来を予測するためのデータポイントの集合です。例えば、私たちのフィーチャーストアサンプルアプリケーションは、過去のフライト記録に基づいてフライトの遅延に関する予測を行うことができます。
特徴量は、複雑なデータ処理および変換パイプラインの結果であり、膨大な量の特徴量データにより、正確な予測と成功した機械学習プロジェクトが可能になります。
フィーチャーストアとは?
A feature store is a central database in your machine-learning architecture that contains your real-time and historical features. Feature stores allow your data engineers and data scientists to use the same central repository to discover, monitor, and analyze features.
What does a feature store architecture look like?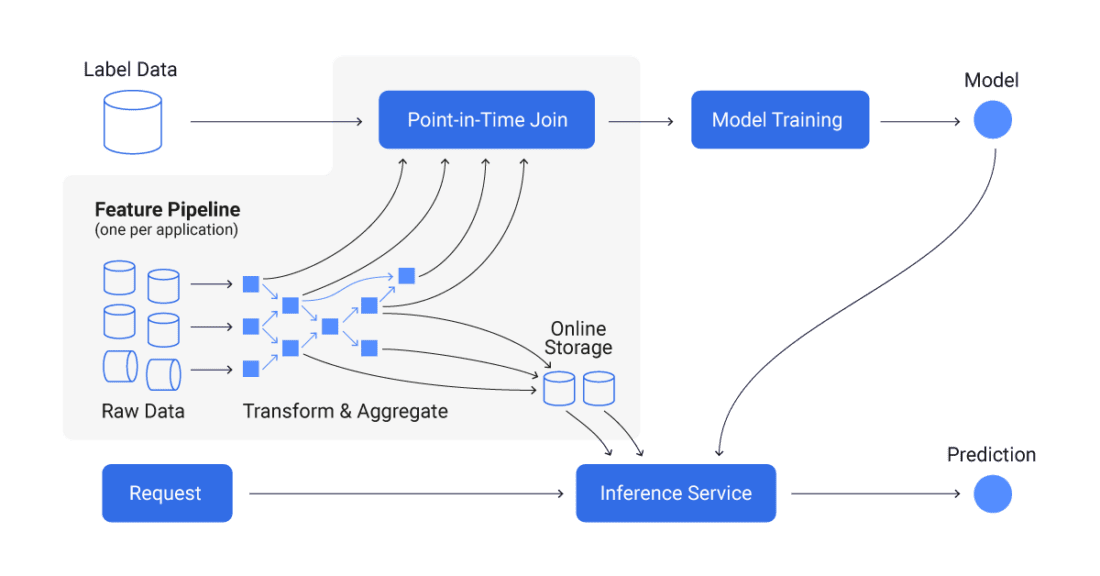
フィーチャーストア内のオンラインおよびオフラインデータベース
フィーチャーストアについて話すとき、ユーザーは通常、アーキテクチャ内の2種類のデータベースを区別します。一方でオンラインデータベースを使用し、他方ではオフラインデータベースも持つことがあります。これらのデータベースは異なる目的を果たします。
オフラインデータベース: この種のデータベースは、通常バッチで取り込まれた履歴の処理済み特徴を保存します。オフラインデータベースは、過去からの大きな時間枠をカバーする特徴データを持っているため、特定の歴史的期間における一連の特徴とともに作業するために有用です。
オンラインデータベース: このデータベースは、リアルタイムデータストリームやオフラインデータベースからのデータを含む場合があります。オンラインストレージは、最新の特徴データで生産モデルやその他のリアルタイムアプリケーションをサービスするために使用されます。パフォーマンスと低待ち時間がここで本当に重要です。データベースがリアルタイムの特徴を十分に速く提供できない場合、モデルは古いデータや不正確なデータを使用して予測を行う可能性があります。
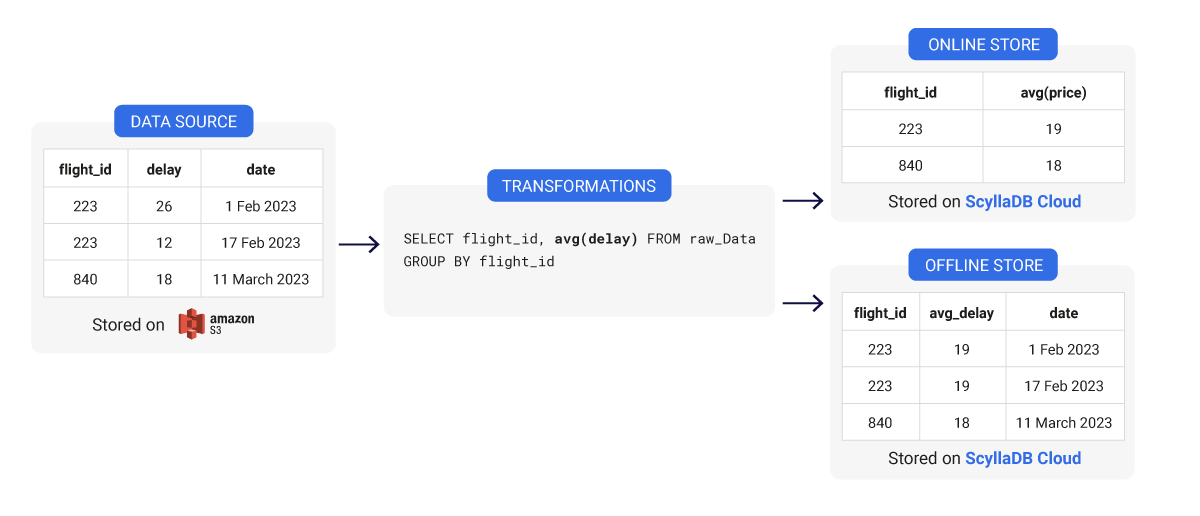
フィーチャストアデータモデリング: ワイド対ナロータブルデザイン
フィーチャストア内のデータモデルを設計する際、オフラインストアであろうとオンラインストアであろうと、ワイドとナローの2種類のテーブルデザインの間で選択できます。それぞれに独自の利点と欠点があります。それぞれの実際の例と、それがあなたのユースケースに最適かどうかを見てみましょう。
ワイドテーブルデザイン
ワイドテーブルデザインでは、各特徴に個別の列が含まれます。テーブルに保存したい特徴の種類が多いほど、作成する列が多くなります。
ワイドテーブルレイアウトの例
| create table feature_store.wide_example( | |
| date TIMESTAMP, | |
| feature_id INT, | |
| feature_col1 FLOAT, | |
| feature_col2 FLOAT, | |
| feature_col3 FLOAT, | |
| feature_col4 FLOAT, | |
| feature_col5 FLOAT, | |
| feature_col6 FLOAT, | |
| feature_col7 FLOAT | |
| ) |
この種のレイアウトは、始めるのが簡単ですが、時間が経つにつれて維持が複雑になり、変更が難しくなります。新しい特徴を導入したい(または既存のものを削除したい)場合は、スキーマを変更する必要があり、これは複雑な場合があります。
ナローテーブルデザイン
狭いテーブル設計はシンプルで維持が容易です。これは、将来の機能の追加や削除に関わらず、列の数が増減しないためです。
狭いテーブルレイアウトの例
| create table feature_store.narrow_example( | |
| feature_id INT, | |
| feature_name TEXT, | |
| feature_value FLOAT | |
| ) |
このレイアウトを使用することで、長期的には機能の名前(例えば、LATE_AIRCRAFT_DELAY)とその値を格納するために2つの固定列のみを使用できます。
一般的に、狭いテーブルはデータを取得する際にデータ型のキャストが必要になることがあります。これは、列の型がFLOATであるのに対し、実際のデータ値がINTEGERである場合です。幸いなことに、機能ストアの話では、オンラインおよびオフラインストアで既に適切なクリーンな数値(FLOAT)形式のデータがあり、すべての値が同じデータ型であるため、これは機能ストアの場合の欠点ではありません。
ScyllaDBとは何か、そしてどのように機能ストアアーキテクチャで使用できるのか?
マシンラーニングチームがリアルタイムの推論アプリケーションを構築するためには、スケールで低遅延で機能を返すことができるデータベースが必要です。ScyllaDBは、高いパフォーマンスと低遅延を持つNoSQLデータベースであり、大量の読み書き操作を処理できます。さらに、GEヘルスケアやShareChatのような企業で重要な機能ストアのワークロードに信頼されているデータベースです。その高い可用性と耐障害性のため、パフォーマンスと信頼性が重要なインフラストラクチャで重い負荷を担うことができます。
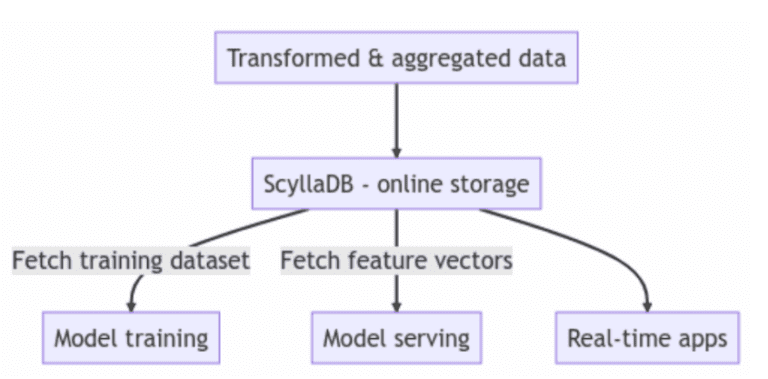
シングルのデータベースですべてのフィーチャストアのワークロードをサービスすることで、メンテナンスの負担を軽減できます。
ユーザーはしばしばScyllaDBをアーキテクチャの中心に置いて、フィーチャとフィーチャストアのメタデータを永続化および取得します。この場合、ScyllaDBはオンラインストアとして機能します。他のユーザーもScyllaDBをオンライン/オフラインハイブリッドストレージとして使用しています。モデル開発を高速化するためには、パフォーマンスが重要であり、ScyllaDBのリードアンドライトパフォーマンスは常にユーザーの期待を上回っています。
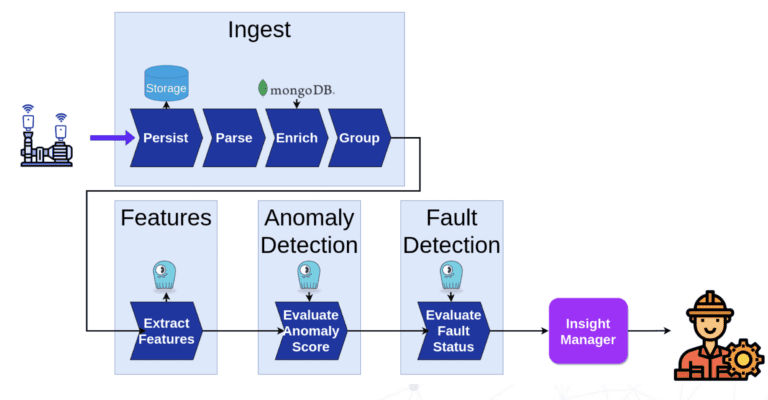
実際、一部のユーザーはScyllaDBが複数のデータベースを置き換え、すべての機械学習データの要件に対するシングルの中央ストアとして機能できることを発見しました。例えば、ScyllaDBはRedis(オンラインストア)とPostgreSQL(オフラインストア)を置き換えることができ、インフラストラクチャのメンテナンスをより経済的かつシンプルにします。
ScyllaDBは、低遅延と高パフォーマンスが求められるユースケースで特に輝きます。さらに、ScyllaDBはCassandraやDynamoDBと互換性があるため、既にこれらのデータベースのいずれかを使用している場合、クエリを変更することなくシームレスに移行できます。
チュートリアル: ScyllaDB オンラインストア
ScyllaDBをオンラインストアとして始めるための手助けとして、サンプルアプリケーション(GitHubでも利用可能)を作成しました。
- リポジトリ
- ScyllaDB Cloudにサインアップするか、ローカルにScyllaDBをインストール
- スキーマを作成:
cqlsh "node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud" 9042 -u scylla -p "password" -f schema.cql - cqlshを使用してインスタンスに接続し、サンプルデータセットをインポート
cqlsh "node-0.aws_us_east_1.xxxxxxxxx.clusters.scylla.cloud" 9042 -u scylla -p "password" scylla@cqlsh> COPY feature_store.flight_features FROM 'flight_features.csv';
このコマンドはサンプルのフライトデータセットを取り込みます:
| op_carrier_fl_num|actual_elapsed_time|air_time|arr_delay|arr_time|cancellation_code|cancelled|carrier_delay|crs_arr_time|crs_dep_time|crs_elapsed_time|dep_delay|dep_time|dest|distance|diverted|fl_date |late_aircraft_delay|nas_delay|op_carrier|origin|security_delay|taxi_in|taxi_out|weather_delay|wheels_off|wheels_on| | |
| —————–+——————-+——–+———+——–+—————–+———+————-+————+————+—————-+———+——–+—-+——–+——–+——————-+——————-+———+———-+——+————–+——-+——–+————-+———-+———+ | |
| 4317| 96.0| 73.0| -19.0| 2113.0| | 0.0| | 2132| 2040| 112.0| -3.0| 2037.0|MLI | 373.0| 0.0|2018-12-31 02:00:00| | |OO |DTW | | 5.0| 18.0| | 2055.0| 2108.0| | |
| 3372| 94.0| 74.0| 81.0| 1500.0| | 0.0| 0.0| 1339| 1150| 109.0| 96.0| 1326.0|RNO | 564.0| 0.0|2018-12-31 02:00:00| 81.0| 0.0|OO |SEA | 0.0| 3.0| 17.0| 0.0| 1343.0| 1457.0| | |
| 1584| 385.0| 348.0| -21.0| 2023.0| | 0.0| | 2034| 1700| 394.0| -9.0| 1658.0|SFO | 2565.0| 0.0|2018-12-31 02:00:00| | |UA |EWR | | 13.0| 33.0| | 1731.0| 2019.0| | |
| 4830| 119.0| 85.0| -35.0| 1431.0| | 0.0| | 1437| 1245| 136.0| -13.0| 1232.0|MSP | 546.0| 0.0|2018-12-31 02:00:00| | |OO |MSP | | 16.0| 18.0| | 1250.0| 1415.0| | |
| 2731| 158.0| 146.0| -19.0| 1911.0| | 0.0| | 1930| 1800| 160.0| -8.0| 1800.0|MSP | 842.0| 0.0|2018-12-31 02:00:00| | |WN |PVD | | 7.0| 7.0| | 1807.0| 1904.0| |
view rawgistfile1.txt hosted with ❤ by GitHub.
ScyllaDB + Feast
ScyllaDBはFeastのような特徴ストアツールとも統合されています。Feastは、生産MLのための人気のあるオープンソースの特徴ストアです。Feastを使用する際にオンラインの特徴ストアとして複数のデータベースを使用でき、ScyllaDBを含みます。
ScyllaDBをFeastのオンラインストアとして設定するには、Feastの設定ファイルを編集し、ScyllaDBの資格情報を追加する必要があります。ScyllaDBはCassandra互換なので、Feastの組み込みのCassandraコネクタを使用できます。
| # feature_store.yaml | |
| project: scylla_feature_repo | |
| registry: data/registry.db | |
| provider: local | |
| online_store: | |
| type: cassandra | |
| hosts: | |
| – node-0.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| – node-1.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| – node-2.aws_us_east_1.xxxxxxxx.clusters.scylla.cloud | |
| keyspace: feast | |
| username: scylla | |
| password: password |
view rawgistfile1.txt hosted with ❤ by GitHub.
まとめ
特徴ストアは特徴エンジニアリングと機械学習モデルの構築に不可欠です。リアルタイムの特徴ストアインフラを構築する場合、パフォーマンスを慎重に検討する必要があります。低遅延、高性能、高スループットの要件は、NoSQLデータベースを特徴ストア内のオンラインストレージソリューションとして理想的な候補にします。
Source:
https://dzone.com/articles/tutorial-whats-an-aiml-feature-store-and-how-to-bu